Estimating Absolute Web Crawl Coverage From Longitudinal Set Intersections
Web archives preserve portions of the web, but quantifying their completeness remains challenging. Prior approaches have estimated the coverage of a crawl by either comparing the outcomes of multiple crawlers, or by comparing the results of a single …
Authors: Michael Paris, Grigori Paris, Fabian Baumann
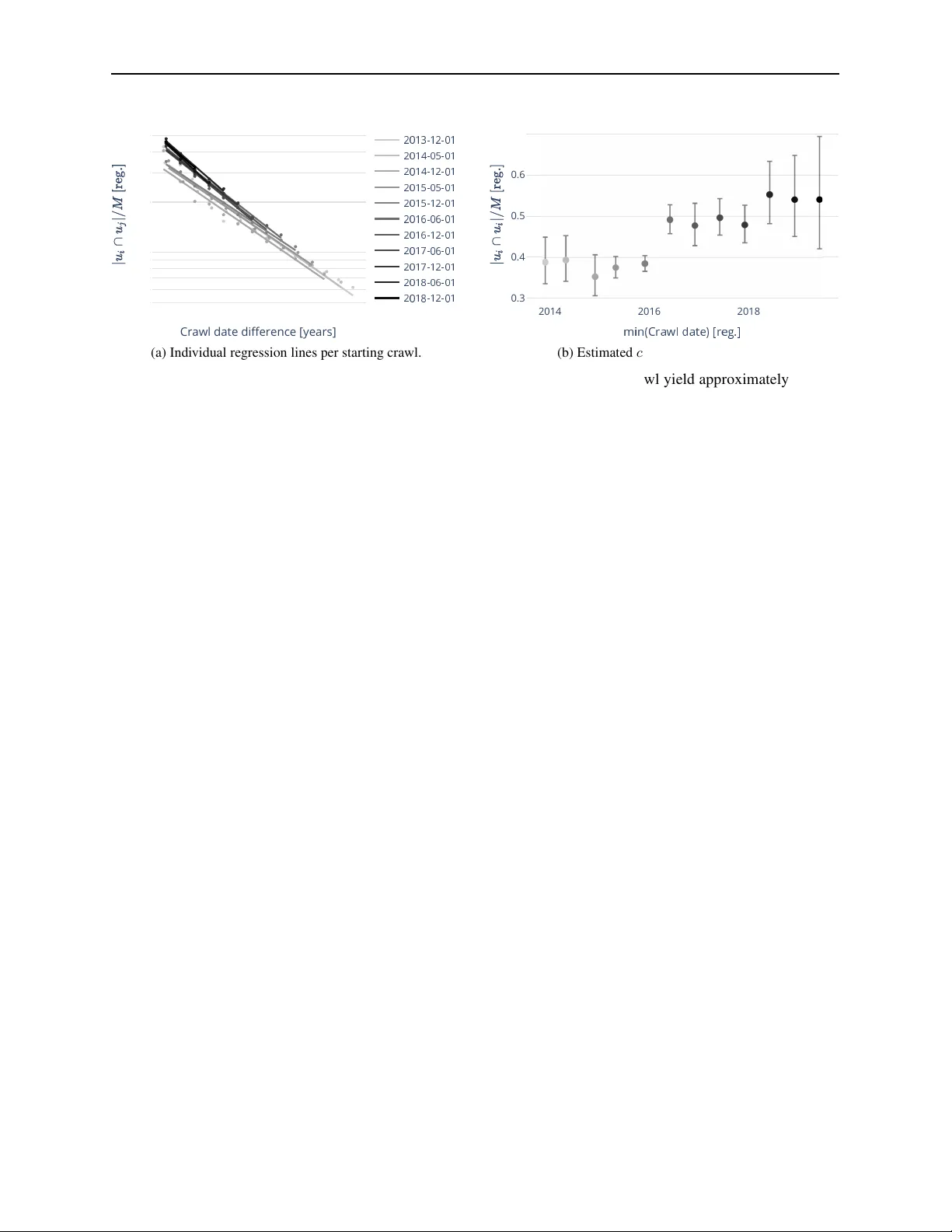
E S T I M A T I N G A B S O L U T E W E B C R AW L C OV E R A G E F R O M L O N G I T U D I N A L S E T I N T E R S E C T I O N S A P R E P R I N T Michael Paris * Common Crawl Foundation micha @commo ncraw l.prg Grigori Paris Indepe n dent Researcher grigo ri.par is.berlin@gmail.com Fabian Baum ann University of Pen nsylvania bauma nnf@sa s.upenn.edu March 1 7, 2026 A B S T R AC T W eb archives preserve portions of the web, b ut quan tif ying their comp leteness remains challeng ing. Prior a pproach es h av e esti mated the c overag e of a crawl b y either comparing the outcomes of mul- tiple crawlers, or by c o mparin g the results of a single crawl to external ground truth datasets. W e propo se a metho d to est imate th e absolu te coverage of a crawl using only the a r chive’ s own longi- tudinal data, i.e., th e data collected by m ultiple subsequ ent crawls. Ou r key insigh t is th at coverage can b e e stimated from th e emp irical URL overlaps between subsequen t crawls, which are in turn well describ ed by a simple urn p rocess. The p a rameters of the urn mo del can th en be inf erred from longitud inal crawl d ata using linea r regression. Applied to ou r focused crawl configura tio n of the German Academic W eb (15 semi- annual crawls between 2013–2 021), we find a coverage of approx- imately 46% of the crawlable URL sp ace for the stab le crawl co n figuration regime. Our method is e xtrem ely simple, requir es no external grou nd truth , and gener alizes to any lon gitudina l f ocused crawl. Keywords: web archive, crawl coverage, set intersection, longitud inal analysis, sampling fraction 1 Intr oduction Focused web crawls—archives targeting specific dom ains like academic institutio n s, governmen t websites, or cu ltural heritage—mu st ter m inate at some point. The German Academic W eb (GA W), fo r instance, crawls app roximately 150 German un iv ersity seeds semi-annu ally , stopp ing after collec ting roug hly 100 million records. This raises the question: how much of the crawlable Germ an Acad emic W eb (cGA W) is archived by the GA W? A web crawl is defined by its cr awl configur ation, which specifies the heur istics and ru les to collect websites. For instance, it defines the termin ation thresh o ld M , i. e . , the to ta l num ber of URLs to be collected in the crawl. What remains unk nown, howe ver , is the set of URLs ( N ) that could, in principle, be collected by a given crawler and its crawl co nfiguration . As a result we are faced with the f undame n tal limitation of a single, isolated crawl: it doe s not allow us to determine its coverage c = M / N of the underlying web, i.e. it remains unknown how much of the crawlable web space does it actually capture . Sev eral strategies h av e addressed related problems. Bharat an d Brod er [1998] esti mated relative sear c h engine sizes by comp aring URL sets across mu ltiple engines. Their m e thod yields ratios like “E n gine A is 2.3 × la rger th an Engin e B” b ut cannot determ in e what fraction of the total web either captures. Entity-based approaches use e xtern a l gro und truth (e.g ., named entities from reference datab ases) to measur e recall o f known items. This req uires domain- specific datasets and measures coverage only for that entity class, not the full UR L space. Quality frame works like SHARC [Denev et al., 2011] assess temporal coherence and resource co mpleteness of archived p ages, b ut not overall d o main coverage. ∗ Corresponding author Estimating Absolute W eb Crawl Coverage A P R E P R I N T T able 1 : Positionin g of ou r app roach relative to prior work. Method Output Requirements Bharat & Broder (1998 ) Relati ve: Size ( A ) Size ( B ) Multiple crawlers Paris & Jäschke (2020 ) Recall of entity class External groun d truth This paper Absolute: c = M / N Only longitudinal data Here we provid e an interpretable method to estimate absolu te coverage from lon gitudinal crawl data alone. The contribution is tw ofold . First, we gain theoretical insight by mo deling the crawling process using a simple u r n model. And second, we estimate co verage by fitting the mod el the longitu d inal crawl d ata. The r emainder of the pap er is structured as f ollows. Section 2 reviews related work on set similarity measures and coverage estimation. Section 3 formalizes the ran d om sampling mo del and derives the self-intersection interpretation . Section 4 ap p lies our method to the German Academic W eb, showing the heatm ap, observed decay patterns, and coverage estimates. Section 5 discusses implications and limitations. 2 Related W ork Estimating an unknown populatio n size from overlapping samples dates to Pete r sen [1896 ] and Lin coln [19 30], wh o formalized the estimator ˆ N = n 1 n 2 /m for wildlife abundance, later bias-corrected by Chapman [19 51]. Seber [198 2 ] provides the standard referen c e covering closed- and open-p o pulation models, inclu ding the Jo lly –Seber mo del for populatio ns with births and deaths. Fien berg [1972 ] rec onceptu a lized mu ltiple-recap ture a s in c o mplete contingency tables, enabling heterogen eous-catch ability extensions. These ec o logical method s were first applied to the web by La wren ce and Giles [ 1998], wh o used p a ir wise URL over- lap across six search en gines to estimate the ind exable web size v ia Lincoln– Petersen. They noted that p ositiv e depend ence b e twe en engin es inflates o verlap, makin g their estimate a lower bo und. L awrence and Giles [1999] com- plemented this with r andom IP sam pling, and Bharat and Brod e r [1998] d e r iv ed relative size ratios fr o m rando m-que ry sampling, yieldin g only relative sizes an d re q uiring multiple eng ines. Dobra an d Fienberg [2 004] reanalyzed the d ata with Bayesian log-linear mo dels inco rporatin g Rasch-ty p e heterog eneity , estimatin g ro ughly 2.5 × the original figure and demon strating th at ignorin g capture heteroge n eity causes se vere u nderestimatio n. While these studies co mpared multiple engines at a single point in time, Bar -Ilan [1 998, 1999] conduc te d the first longitud inal study , trackin g a query ac ross e ngines over five months and categorizing URLs as lost, dro pped, f orgotten, or recovered. Bar-Ilan [200 2] form alized measures for tempo ral self-overlap and relative coverage. Central to all overlap- b ased ap proach es is the c h oice of similarity measu re. Th e symm etric Jaccard ind ex [Jaccard, 1901] and Dice–Sørensen coefficient [D ice, 1945, Sørensen, 1948] contrast with the asymmetric contain ment C ( A, B ) = | A ∩ B | / | A | intr oduced by Broder [1 997], w h o also pro posed MinHash sketches for its ef ficient esti- mation [Broder et a l., 20 00]. Garg et al. [2015] sho wed that asymmetric measures often o utperfo rm symm e tric ones in retriev al task s. The pro babilistic foundatio n co mes from urn mod el theory: Kalinka [2013] showed t hat expec ted intersection sizes under indepen dent sampling fo llow the h ypergeom e tr ic distribution, with Mah moud [2008] providing co mprehen siv e treatment of Pólya urn mo dels. Th is connection to captur e-recaptu re is established in ecology [ Seb er, 1982] b ut has not previously been applied to web c rawl coverage. A k ey assump tion of urn-b ased sampling is a stab le population, yet the web undergoes continuo us turnover . Koehler [2002], Koehler et al. [20 04] foun d a web p age h a lf -life o f app roximately two yea r s; Go mes an d Silva [2006] mo deled URL persistence; Fetter ly et al. [200 3 ] and Wren [2 008] qu antified chan g e and deca y rates at scale. Complemen tar y work on web archive qu ality—capture “b lur” an d coherence [Denev et al., 2011], missing embed ded resources [Brunelle et al., 2015], and tempo r al inconsistency [Ainsworth e t al., 2015]—focuses on individual page fidelity r a ther th an d omain coverage. As Baack [20 2 4] fou nd, even the Common Crawl team expressed fun damental uncertainty , with their director notin g the we b is “pra c tica lly infinite. ” Overall, existing work either (1) uses e ntity- based p roxies req uiring external datasets [Paris and Jäschke, 20 20]; (2) com pares multip le e ngines for only re lative sizes [Bharat and Broder, 1998, Lawrenc e a n d Giles, 199 8]; or (3) studies temporal decay witho u t connectin g it to coverage [Koehler, 20 02, Bar-Ilan, 1999]. Our contribution is to extract absolu te sampling fractions from longitudin a l self-intersection s of a sing le archi ve. 2 Estimating Absolute W eb Crawl Coverage A P R E P R I N T 3 Theor etical intuition and ur n model Let u t denote the set o f URLs ca ptured in a gi ven crawl a t time t , with | u t | = M b eing the number o f URLs c aptured in the crawl. Furthermor e, let N deno te the size of the crawlable web, which is re presented by the size of the set of all URLs within the archi ve’ s scope that cou ld potentially be har vested. Note that while we assum e to know th e value of M , we d o not ha ve access to the value of N , as a crawl will not capture all crawlable URLs. Th e ratio c = M / N is defined as the coverage o f the cr awl. The urn r epresents a po p ulation of N unique U RLs. Time advances in discrete steps t = 1 , . . . , T , wh ich cor respond s to successive cr awls. At each time step, the urn pro c ess con sists of two steps: First, tur nover o ccurs in the under ly ing populatio n. This mean s that a fraction of (1 − α ) of the N URLs is removed a nd replace d by the same numbe r of newly in troduce d URLs, suc h that N remains constant. In o ther words, the parameter α ∈ [0 , 1] captu res the temporal persistence of URLs across two subseque n t cra wls. Second , con ditional on the resulting popu lation, a cra wl sample u t is generated b y drawing M URLs un if ormly at rando m witho ut rep la c ement f r om th e ur n . Crucially , this simple m odel allows us to derive a n analytical expression for the overlap between two crawl at different times, u i and u j . First, let u s c onsider an arbitrary URL that appe ars in th e crawl at tim e t = 1 . The prob ability that this URL survives the population turn over for T − 1 steps is α T − 1 . Second, co nditional on surviving u ntil time T , the probab ility that it is inclu ded in the crawl at time T cor respond s to M / N , i.e., the u niform sampling probab ility fro m the urn . Since th e initial cr awl c ontains M URLs, the expected size o f the overlap between the first and the T -th crawl is therefore given by E [ | u 1 ∩ u T | ] = M · α T − 1 · M N = M 2 N α T − 1 . (1) Dividing by M , an d substituting c = M / N , yields the e xpecte d fr action of UR Ls in the initial c r awl th at reap pear at time T , f ( T ) = c α T − 1 . (2) The imp ortant feature of Eq. 2 is that it can read ily be used to fit the empir ical o bservations of temp oral c r awl overlaps to extract the value of c . I nterestingly , Eq . 2 is closely linked to p revious work, specifically , Brod er’ s con tainment measure, defined a s [ Broder, 1997] g ( u i , u j ) = | u i ∩ u j | | u i | . (3) As d efined in Eq. 3, g ( u i , u j ) d enotes the fraction of cr awl u i that also appears in crawl u j , and has been u sed for cross-sectional mu lti-engine comp arisons Bharat and Broder [1998]. In co ntrast to its original con ception of g , our model allows to interpret Eq. 3 a s the d efinition of U RL overlap b etween two crawls separated by t = i − j , hence g ∗ = g ( u i , u i ) , (4) is interpr eted as “self-in tersection”, which we recover from E q . 2 by setting T = 1 and thus g et g ∗ = c . Eq uiv alently , this result can b e obtain ed d irectly from Eq. 3 by a ssum ing two inde penden t d raws ( i = j ) of size M from a popu lation of N URLs, where the e xp ected intersection size follo ws from the hypergeometric distribution [Kalinka, 2013], i.e., we get 2 g ∗ = E | u 1 ∩ u T | M = 1 M M 2 N = c . (5) Impor tan tly , th is in terpretation holds even if the crawl its elf is non-unif o rm. Consider a fixed crawl u with | u | = M obtained by any sampling method (uniform, breadth -first, preferen tial, etc.) from p opulation U with | U | = N . If w e compare against a u niform sam ple ˆ u from U , the exp e cted intersection is: E | u ∩ ˆ u | M = M N = c. (6) This follows because each element o f u has prob ability M / N of being sam pled into ˆ u , regardless o f ho w u w as constructed . Equi valently , a unif o rm sample of size M would co n tain c · M elements in common with th e crawl. Thus th e coverage estimate c has thr e e equiv alent interp r etations: ( i) the fraction of the cGA W captured b y the crawl, (ii) the expected overlap f raction with a unif orm sample, and (iii) the norm alized self-intersection un der indep endent resampling. 2 Note that the hyperg eometric (sampling wit hout replacement) and binomial (independen t Bernoulli t r ials) models giv e identical expec ted intersections. They differ only in v ariance—hypergeo metric v ariance is small er by t he finite population correction ( N − M ) / ( N − 1) . For point estimation, the models are equi valent. 3 Estimating Absolute W eb Crawl Coverage A P R E P R I N T Extendin g this fra mew ork to pairs of crawls , we compare the observed r elativ e overlap g ( u i , u j ) = | u i ∩ u j | / M against the theoretical baseline o f unifo r mly sampled cou nterparts, denoted ˆ u i and ˆ u j . Under the urn model with indepen d ent un iform sampling, th e expected relative overlap is determined solely by the coverage c and the temporal decay α : E [ g ( u i , ˆ u j )] = E [ g ( ˆ u i , ˆ u j )] = c · α | i − j | (7) Howe ver , r eal-world crawling pro cesses o ften exhibit tempo ral correlatio ns - for instance, throug h persistent seeds that force the crawler i nto the same local subgraph across repetitions. W e model this de viation by introducing a crawler bias coefficient R ij , d efined a s th e r atio between the actual a nd theoretical expectations: R ij = E [ g ( u i , u j )] E [ g ( u i , ˆ u j )] = E [ g ( u i , u j )] c · α | i − j | (8) The overlap r atio R ij serves as a diagnostic metric for crawler behavior: R ij ≈ 1 implies a uniform process, while R ij > 1 re veals po siti ve correla tio n where th e crawler systematica lly revisits specific su bgraph s. This bias is emp iri- cally isolated as th e r esidual term in th e lo g-linear regression: log R ij | {z } Residual = log g ( u i , u j ) − (log c + | i − j | log α ) (9) 4 Results W e apply our m ethodo lo gy to the German Academic W eb (GA W), a lon gitudina l fo cused cr awl of German university websites. The part of the GA W consider ed her e consists of 15 semi-annu al foc u sed crawls co n ducted b etween Decem- ber 201 3 and Decembe r 2021. Eac h crawl started from app roximately 150 seed domains corre sp onding to German universities with do ctorate-g ranting rig hts. The H e r itrix crawler Intern et Archive [2020] was used with a bre a dth-first trav ersal policy . Crawls terminate after collecting approx imately 100 million record s Paris and Jäschke [202 0]. The data of o u r lon gitudinal crawls o f the cGA W allows u s to empir ica lly observe the con ta in ment between two crawls g ( u i , u j ) f or i > j . Th e results are depicted in Fig. 1, which sh ows two v iews o f the p airwise contain ment measures. Figure 1(a) display s the 15 × 1 5 matrix of g ( u i , u j ) values as a heatmap. The off-diagona l entries show clear tempor al structure, and values d ecrease with d istance from th e d iagonal, i.e . for increasing tim e d ifference b etween two crawls, reflecting URL tur nover . Th is visualization makes explicit our estimation target, namely the hyp othetical in tersection of two independe n t sam p les drawn at the same mom e n t, i.e., ∆ t = 0 . Figu re 1(b) , dep icts a scatter plo t showing th e log-tran sf o rmed con tainment measure log g ( u i , u j ) as a fu nction of the time difference between tw o c r awls fo r every crawl pair . For the GA W, the o bserved decay is in excellent agr eement to o u r mo del, as depicted in Fig. 2(a), where we have fitted Eq. 2 via ordinar y least squares regression to the log- transform ed contain m ent values ( R 2 = 0 . 95 ). In particular, we find an a verage decay rate o f α ≈ 0 . 73 per year, which co rrespon ds to appro ximately 27% annual URL turnover , consistent with pr ior studies of web persistence K oeh ler [2002]. Most importantly , we e stima te coverage as 0 . 46 , i.e., an average of 46 % of the complete crawlable academic web ar e captured . T o dem onstrate th e validity of the analytical expression of the urn model, we comp are Eq. 2 with stoc h astic simu lations of the mo del in Fig. 2, which show perfect agreemen t. Figure 3 examines whether coverage varies over time by fitting sep arate regressions for each crawl’ s comparisons with all subsequen t crawls. Panel 3 a depicts th e indi vidual r egression lines and sh ow consistent d e c ay b ehavior with approx imately parallel slopes. Panel 3b presents the y-intercep ts estimating the sampling fractio n c for each startin g crawl. This sh ows a r ising tren d over time in, indicating that crawl coverage has imp roved over the ob servation period . This imp rovement in c overage is either driv en by an in c rease in crawl efficiency or a reduction in the crawlable populatio n size N . 5 Discussion Estimating w e b crawl coverage can be very challengin g and con strained by the way web data is cr awled. W e p resented the first metho d to estimate abso lute web cr awl c overag e from longitud inal data alone, i.e., fr om a series o f subsequen t crawls. By analyzing pairwise URL set intersections over time across cra wls we were able to estimate the co verage of th e crawls. A simple urn model rep rodu c e s ke y featu r es of the emp irical data a n d th e refore provides th e oretical groun ding for our ability to estima te co verage fr om the long itudinal GA W crawl d ata. The key insight is that tem poral variation in a lon g itudinal archive o f web crawls serves as a substitute for the multiple indepen d ent samp les required by trad itio nal capture-rec apture method s. I n particula r, by observ in g h ow URL sets 4 Estimating Absolute W eb Crawl Coverage A P R E P R I N T 2014 2016 2018 2020 2014 2016 2018 2020 0.1 0.3 0.5 Containment Crawl date Crawl date (a) Heatmap displays the containment between pairs of crawls. 0 2 4 6 6 7 8 9 0.1 2 3 4 5 6 Crawl date di erence [years] (b) Compressed representation of the l eft panel onto ∆ t . Figure 1: Pairwise URL set intersections for the 15 GA W cr awls. (a) The heatma p reveals temp oral deca y structure; the diagonal shows estimated self-inter sectio n values. (b) Log- transform ed containm ent vs. time difference exhib its a linear relationship. 0 2 4 6 8 3 4 5 6 7 8 9 0.1 2 3 4 5 6 Data (GAW) Crawl date difference [years] (a) Empirical GA W data. 0 2 4 6 8 3 4 5 6 7 8 9 0.1 2 3 4 5 6 D Crawl date difference [years] (b) Simulated urn model data. Figure 2 : V alidation v ia simu lation. (a) Regression on GA W data. (b) Simulation with urn mo del pa rameters recovers the same relationship , co nfirming th e m ethod. overlap across time, the urn model allo ws us to decompo se the (i) co verage ( y-intercep t of the fitted log relationship c (i.e. what fraction of the to ta l we capture), and the ( ii) decay component α , slop e of the lo g relationship , i.e., ho w quickly co ntent turns over . As a case study , we u se our method to estimate our coverag e of the Germ an Academic W eb. W e find that each cr awl captures approxim a tely 46% of the complete crawlable academic web , with co ntent persistence of appro x imately 7 3% per year (2 7% annual URL tu rnover). Our work extends Bhara t an d Broder [ 1998] from cr oss-sectional com parison of search engine indices to long itudi- nal analysis of cr awled URL sets. Where they probed multiple search eng ines throug h qu ery interfaces and could only c ompute re lative sizes, we extract absolute coverage fro m direct tem poral self-inter sections within a sin g le crawl archive. Furthermore, ou r extracted decay parameter α ≈ 0 . 73 per y ear—repr esenting the annual URL persistence rate-implies a half-life of appro ximately 2.2 years for URL survival, closely align ing with Koehler [2002]’ s long itudi- nal finding o f approx imately 2-yea r half-lives fo r web pag e persistence . The m e thod enables o ngoin g assessment of crawl coverage with out external resou rces. Specifically , it provides archive operator s a self-con tained method to assess coverage withou t knowledge of external g round truth datasets, content extraction o r entity matching, and most impo rtantly , withou t th e ability to compare to other crawlers. Researcher s may b enefit by bein g able to estimate wha t fraction of th e target web it cap tu res, inform ing confid ence in downstream tasks i.e. training LLMs. In additio n, the temp oral stability analysis (Fig . 3b in Section 4) r ev eals wheth er the target p o pulation is in a “r eplacement regime” (stable size) or “g rowth regime” (expanding ), gu iding crawl f requen cy decisions. 5 Estimating Absolute W eb Crawl Coverage A P R E P R I N T 0 2 4 6 5 6 7 8 9 0.1 2 3 4 5 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 Crawl date difference [years] (a) Individ ual regression li nes per starting crawl. 2014 2016 2018 0.3 0.4 0.5 0.6 m (b) Estimated c vs. starting crawl date. Figure 3: Per-crawl regression an alysis. (a) Separate re gre ssions for each starting crawl yield approximately par a llel lines. (b) The y-inter cept (estimated c ) shows a rising trend over 2013 –2021 . The way a crawl is modeled here is independen t of the type of flux in the URL space, the flux of the web only affects how we may fit the overlap data. Correspo n ding the y -intercept to the crawl size nor m alized self- intersection is indepen d ent of the flux. If the cGA W g rows over time, the sampling fraction c t = M / N t decreases. W e would observe the coverage estimate declining. Con versely , if N t shrinks, coverage estimates would increase. The coverage estimate across starting years pr ovid es an internal test for dyn amics of N t . In the case of the GA W , with a non-revisit p olicy , the web is crawled outwards, exploring further regions without resamplin g previously seen UR Ls. Th e samp ling bias is accounted f or throug h the lo g residual, p roviding a measure for an intersectio n s deviation fro m the urn model. Like any inferen ce b a sed on in direct obser vation, our ap proach rests on a set o f assump tions and data requ ir ements that delimit its app licability . W e therefore discuss key limitatio ns and boun dary conditions belo w . The m ethod assumes crawls sample appro ximately unifor mly from the cGA W. Real cr awls exhibit biases: breadth-first traversal fav ors well-conne c ted pages; scope restrictions exclud e con tent o u tside seed dom ains. The coverage estimate sho uld be interpreted as coverage we ighted by the crawl co n figuration , not unif o rm coverage of all theoretically reach able URLs. The ap proach f urther requir es m u ltiple crawls over time. It cann ot assess coverage of a single snap shot. Archives with a small number of cra wls m ay have insufficient data for reliable in ference of the crawl coverage. W e also assume the cGA W size remains approxim a te ly con stant between start and termina tio n of a crawl. In rapid ly growing doma ins (e.g., social med ia), th is assumption may n ot hold, an d the in te r cept in ter pretation would b e confou nded b y popu lation change. Finally , coverage is m easured at the URL lev el, not content level. A URL may persist while its con tent changes substantially . Content-based similarity measures could complem e nt URL intersection analysis. Sev eral extensions merit inves tigation . First, the u rn m o del could b e g eneralized to acc ount for non- u niform sampling by inco r porating weights that r eflect crawl bias toward highly conn ected or freq uently updated page s ( i.e., a n etwork- based approac h ). Secon d, the meth od could be applied to other lon g itudinal web archiv es, such as Com mon Crawl, or domain-sp ecific collectio ns, to assess its generality across crawl regimes. Th ir d, URL-lev el intersection could be compleme n ted with content-based similarity measures ( e.g., MinHash) to estimate semantic rather than p urely URL- lev el coverage. Finally , future w ork could dev elop diagnostics to disentangle tr ue population gro wth from declining coverage in longitudin al ar chives. In conclu sion, we introdu c e d a self-co ntained meth od to estimate ab so lute web crawl c overag e u sing longitu dinal d ata alone, leveraging tempo ral self-in tersections of URL sets as a sub stitute f or indep endent samples. By mode lin g overlap dynamics with a s imple urn process, we showed that the intercept of the empir ically observed decay in containmen t directly recovers th e s amp ling f raction, while the slope captures content tur nover . Applied to the Germ a n Acad emic W eb, the method ind icates that individual crawls captu re app roxima te ly 46% of the crawlable URL space, with an annual p e r sistence rate of about 73%. Because the appr oach require s n either extern al groun d truth n or co mparison across crawlers, it provides arc hiv e op erators and research ers with an interpre table an d gen eral too l for assessing crawl completen e ss in longitudin al web archi ves. Data availability . Metadata for the Ger man Academic W eb (URLs and timestamp s) is available at https://german - academic- web .de/ . 6 Estimating Absolute W eb Crawl Coverage A P R E P R I N T Acknowledgmen ts The author thanks Robert Jäschke for conceiving and maintaining the German Academic W eb arc hiv e, p roviding access to the cr awl data, and offering valuable f e edback on this work . Parts of this research were funde d by the German Fed eral Ministry o f Edu cation and Research (BMBF) in the REGI O project (grant n o. 01PU170 12D). Refer ences Scott G Ainsw orth , Mich a el L Nelson , and Herbert V an de So mpel. Only one out of fi ve archived web pages existed as presented. In Pr oc e edings of the 26th ACM Confe rence on Hypertext and Social Media , pages 25 7–266 . A CM, 2015. Stefan Baack . A critical analy sis o f the largest source for ge n erative ai training data: Common crawl. In Pr oceed ings of the 2024 ACM Confer ence o n F airness, Accounta bility , a nd T ranspar ency , pages 2199– 2208, 2 024. Judit Bar-Ilan. On the overlap, the pr ecision an d estimated recall of searc h engines: A case study of the query “E r dos”. Scientometrics , 42(2):2 0 7–22 8, 1 998. d oi:10.10 07/BF024 5 8356 . Judit Bar-Ilan. Search en gine results over time—a case study on sear ch eng ine stability . Cybermetrics , 2/3(1 ):paper 1 , 1999. Judit Bar -Ilan . Me th ods for m easuring sear c h engine p erform ance over time. Journal of the A merican Society fo r Information S cience a nd T echnology , 53 (4):30 8–319 , 20 02. doi:10 .1002 /asi.10047 . Krishna Bharat and Andrei Broder . A tech nique for m e asuring the r elativ e size an d overlap o f pu blic web search engines. Comp uter Networks and ISDN systems , 30(1-7 ):379– 388, 1 998. Andrei Z Bro der . On the resembla n ce and con ta in ment of do cuments. In Pr oceedings of the Compress ion and Complexity of Seq u ences , page s 21– 29. IEEE , 1997 . Andrei Z. Brod e r, Moses Char ikar, Alan M. Frieze, an d Michael Mitzenmach er . Min-wise ind ependen t p ermutation s. Journal of Compute r and System Sciences , 6 0(3):6 30–6 5 9, 2 000. Justin F Brunelle, Mat Kelly , Hany SalahEldeen, Michele C W eigle, and Michael L Nelson. Not all m e m entos are created equal: measuring th e impa c t o f missing reso urces. In Interna tional Journal on Digita l Libraries , volume 16 , pages 283–3 01. Springer, 20 15. Douglas G. Chap man. So me prop erties of the hype rgeometric distribution with applicatio ns to zoolo g ical censuses. University o f Californ ia Publications on Sta tistics , 1:131– 1 60, 19 51. Dimitar Den ev , Arturas Mazeika, Marc Spaniol, an d Gerhard W eik um. The sharc framework f or d ata qu ality in web archiving. The VLDB J ourna l , 2 0(2):1 83–2 0 7, Ap ril 20 11. ISSN 1066-88 88. doi:10.10 07/s007 78-011-0219-9 . URL https://doi.org/1 0 .1007/s00 778- 011- 0219- 9 . Lee R Dice . Measures of the amoun t of ecologic association between species. Ec o logy , 26 (3):297 –302 , 19 45. Adrian Dob ra and Stephen E. Fienberg. How large is the W orld Wide W eb? In Mark Lev ene and Alexandra Pou lovas- silis, editors, W eb Dyna mics , pages 23– 45. Spring er , 200 4. Dennis Fetterly , M ark Manasse, Marc Najork, and Janet W iener . A large-scale study of the evolution of we b pa g es. Softwar e: Practice a nd Experience , 3 4(2):21 3–23 7, 2 003. Stephen E. Fienberg. The multiple rec a pture census f or closed po pulation s an d incomp lete 2 k contingen cy tables. Biometrika , 59(3 ):591– 603, 1972 . Ankita Ga rg, Catherine G Enright, and Michael G Mad den. On asym metric similar ity search. In 2015 IE EE 14 th internationa l c o nfer ence on machine learn ing an d ap plications (ICMLA) , pag es 6 49–65 4. I EEE, 2015. Daniel Gomes and Mário J Silv a. Modelling information persistence on the web . In Pr ocee dings of the 6th Interna- tional Confer ence on W eb Engine e rin g , pages 193– 200. A CM, 20 0 6. Internet Archi ve. Heritrix – The Internet Archi ve’ s open-source, e xtensible, web-scale, archiv al-quality web crawler project. https://github.com/internetar c hiv e/heritrix3 , 20 2 0. [Online; Last accessed 1 Apr 2020]. Paul Jaccard. Étude com parative d e la distribution flo rale dan s une portion des alpes et des jur a . Bulletin de la Société vaudo ise des scien ces naturelles , 37 :5 47–5 7 9, 190 1. Alex T K a linka. The probability of drawing intersectio ns: extending the hypergeometric distribution. arXiv pr eprint arXiv:130 5.071 7 , 2 013. 7 Estimating Absolute W eb Crawl Coverage A P R E P R I N T W allace K o ehler . W eb page chan g e and persistence—a fou r-year lo ngitudin al study . J ou rnal of the American society for information science and technology , 53(2) :162–1 71, 2002 . W allace K oehler et al. A l on gitudinal study of web p a ges continu ed: a conside ration of document persistence. Info r- mation R esear ch , 9(2):9– 2, 20 04. Ste ve Lawrence and C. Lee Giles. Searching the W orld W ide W eb . Science , 280(53 60):98 –100, 199 8. doi:10.1 126/scienc e.280.5360.98 . Ste ve Lawrence and C. Lee Giles. Accessibility of infor mation on the web. Natur e , 400(67 40):10 7–109, 1999. doi:10.1 038/2 1987 . Frederick C Linco ln. Calculating waterfowl abunda n ce on the basis of band ing retur ns. US Dep artment of Agricultu re Cir cular , 118 :1–4, 1930 . Hosam M Mahmou d. P ó lya urn models . CRC Press, 200 8. Michael Paris and Rober t Jäschke. How to assess the exhau sti veness of lo ngitudin al web arch iv es: A case study of the german academic web . In Pr oceedin gs of the 31st ACM Con fer ence on Hyperte xt and Socia l Media , pages 85 –89, 2020. C. G. J. Peter sen. The y early immigration of yo ung plaic e into the Limfjord from th e German Sea. Report of the Danish Biological S tation to the Home Depa rtment , 6:1 – 48, 18 96. G. A. F . Seber . The Estimation of Animal Abundance a nd Related P arameters . Edward Arnold, Lo ndon , 2nd edition, 1982. Thorvald Julius Sør ensen. A method o f establishing gr oups o f equal am plitude in plant sociolo gy b ased on similarity of species content and its application to a n alyses of th e vegetation on d anish common s. Biologiske skrifter , 5:1– 3 4, 1948. Jonathan D Wren. Ur l d e cay in m edline—a 4 -year follow-up study . Bioinformatics , 24(11) :1381– 1385, 2008 . 8
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment