웹 크롤링 커버리지 추정: 장기 집합 교차를 활용한 절대 비율 계산
본 논문은 동일 아카이브의 연속적인 크롤링 결과만을 이용해 전체 크롤링 가능한 웹 공간에 대한 절대 커버리지를 추정하는 방법을 제안한다. URL 집합 간 겹침을 단순한 urn 모델로 설명하고, 로그 선형 회귀를 통해 커버리지 c와 시간당 지속성 파라미터 α를 추정한다. 독일 학술 웹(GAW) 15회 연속 크롤링에 적용한 결과, 평균 커버리지는 약 46 %이며 연간 URL 교체율은 27 %에 해당하는 α≈0.73 을 보였다. 외부 기준 데이터 없…
저자: Michael Paris, Grigori Paris, Fabian Baumann
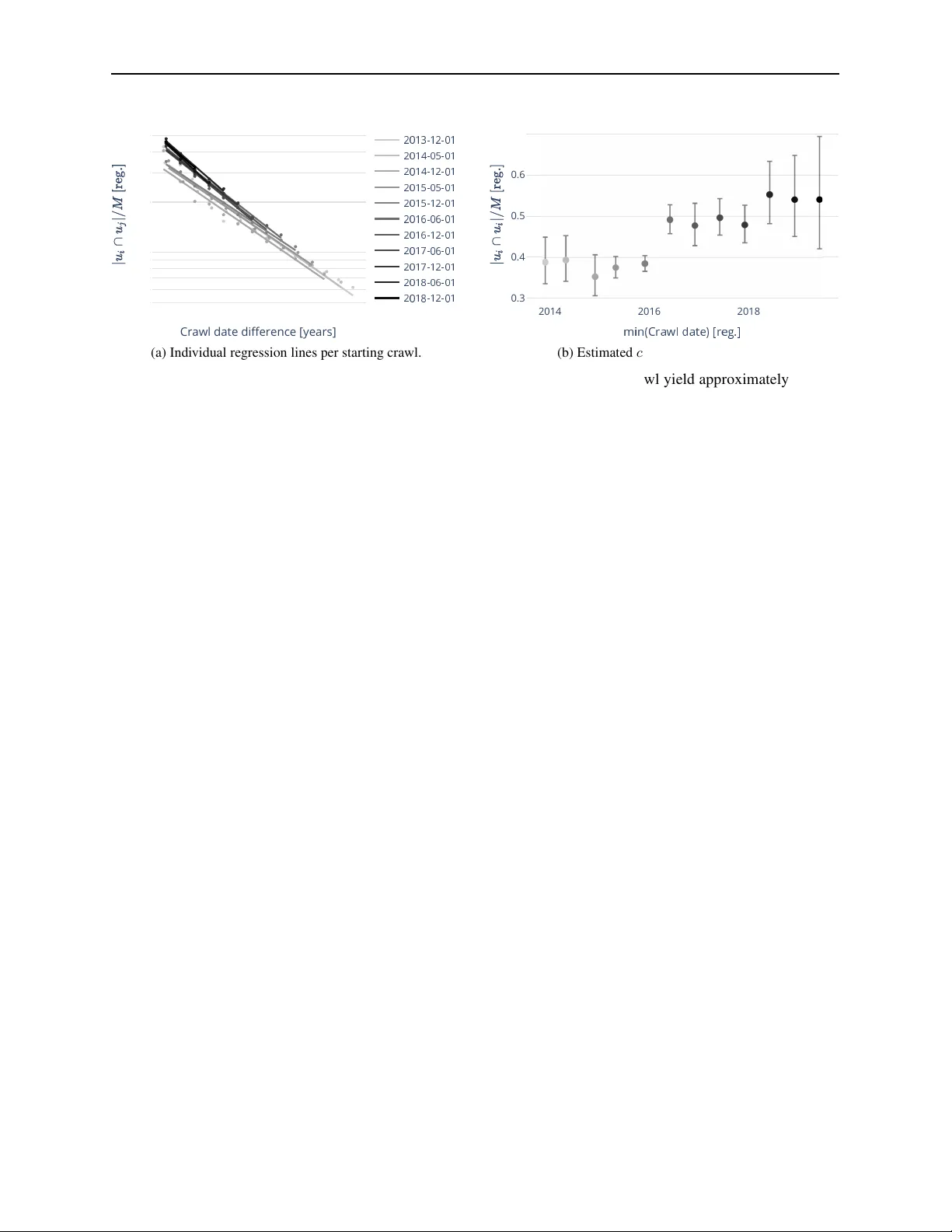
본 논문은 웹 아카이브가 수행한 연속적인 크롤링 결과만을 이용해 전체 크롤링 가능한 웹 공간에 대한 절대적인 커버리지를 추정하는 새로운 방법론을 제시한다. 기존 연구는 다중 엔진 비교를 통한 상대적 규모 추정이나, 외부 엔티티 기반 데이터셋을 활용한 특정 도메인에 한정된 리콜 측정에 머물렀으며, 절대적인 “전체 대비 차지율”을 제공하지 못했다. 이러한 한계를 극복하고자 저자들은 URL 집합 간 겹침(overlap)을 단순한 urn 모델로 설명하고, 로그 선형 회귀를 통해 두 핵심 파라미터인 커버리지 c와 시간당 지속성 파라미터 α를 동시에 추정한다.
**모델 정의**
전체 크롤링 가능한 URL 풀을 크기 N인 urn으로 가정한다. 매 크롤링 시점 t 에서는 (1) 일정 비율 α 에 따라 기존 URL이 사라지고 새로운 URL이 동일 수만큼 추가되는 “turnover”가 일어나며, (2) 크롤러가 M 개의 URL을 무작위(비복원)으로 샘플링한다. 여기서 c = M/N 은 궁극적으로 추정하고자 하는 절대 커버리지를 의미한다. 두 시점 i, j 사이의 겹침 기대값은
E
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기