Neural Network-Based Time-Frequency-Bin-Wise Linear Combination of Beamformers for Underdetermined Target Source Extraction
Extracting a target source from underdetermined mixtures is challenging for beamforming approaches. Recently proposed time-frequency-bin-wise switching (TFS) and linear combination (TFLC) strategies mitigate this by combining multiple beamformers in …
Authors: Changda Chen, Yichen Yang, Wei Liu
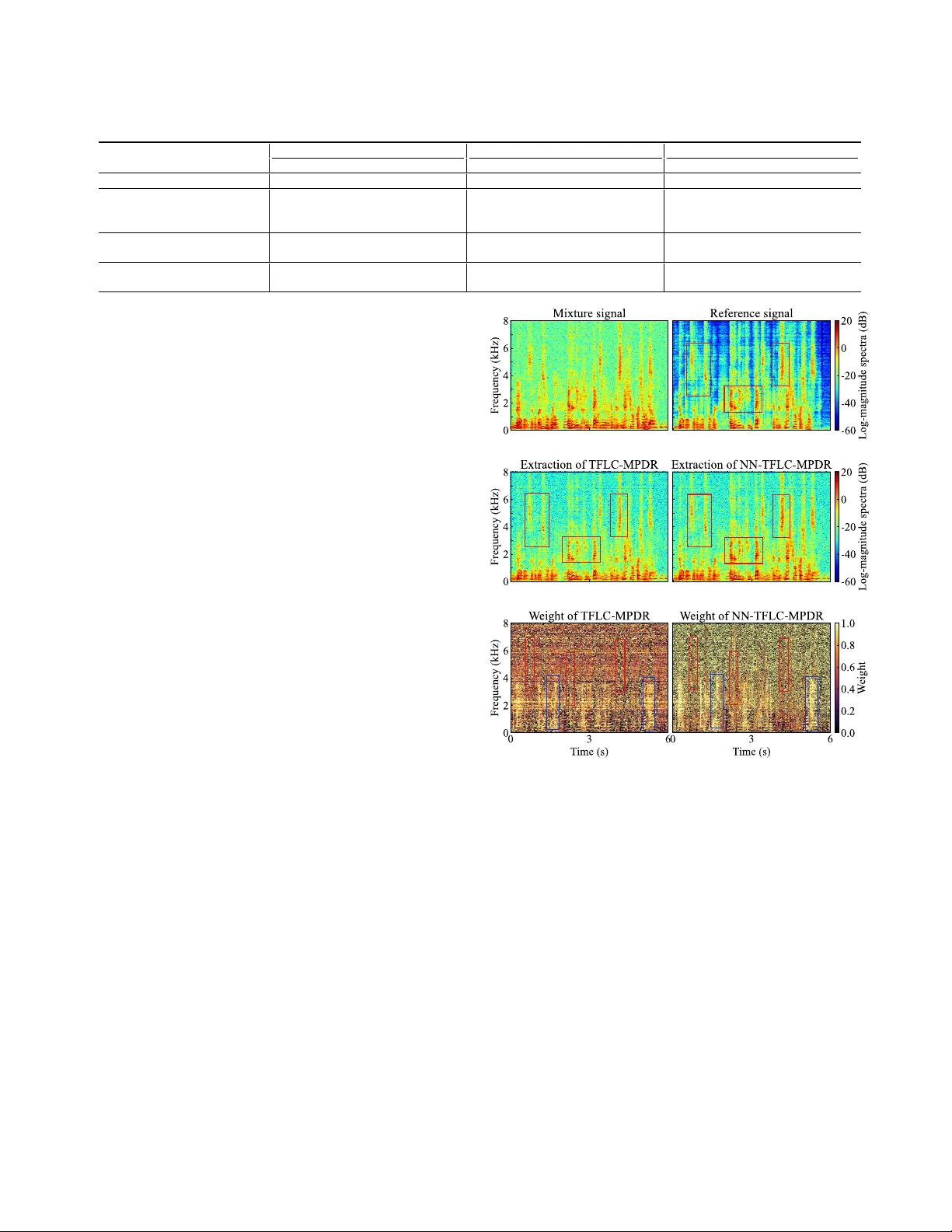
NEURAL NETWORK-B ASED TIME-FREQUENCY -BIN-WISE LINEAR COMBINA TION OF BEAMFORMERS FOR UNDERDETERMINED T ARGET SOURCE EXTRA CTION Changda Chen 1 , Y ichen Y ang 1 , 2 , W ei Liu 1 , 3 , and Shoji Makino 1 1 W aseda Uni versity , Japan 2 Northwestern Polytechnical Uni versity , Xi’an, China 3 School of Electronic Information, W uhan Uni versity , W uhan, China ABSTRA CT Extracting a target source from underdetermined mixtures is chal- lenging for beamforming approaches. Recently proposed time- frequency-bin-wise switching (TFS) and linear combination (TFLC) strategies mitigate this by combining multiple beamformers in each time-frequency (TF) bin and choosing combination weights that minimize the output power . Howe ver , making this decision inde- pendently for each TF bin can weaken temporal-spectral coherence, causing discontinuities and consequently degrading extraction per - formance. In this paper , we propose a no vel neural netw ork-based time-frequency-bin-wise linear combination (NN-TFLC) framework that constructs minimum power distortionless response (MPDR) beamformers without explicit noise cov ariance estimation. The net- work encodes the mixture and beamformer outputs, and predicts temporally and spectrally coherent linear combination weights via a cross-attention mechanism. On dual-microphone mixtures with multiple interferers, NN-TFLC-MPDR consistently outperforms TFS/TFLC-MPDR and achiev es competitive performance with TFS/TFLC built on the minimum v ariance distortionless response (MVDR) beamformers that require noise priors. Index T erms — T arget source extraction, underdetermined situ- ations, beamforming, linear combination, neural networks 1. INTRODUCTION In acoustic signal processing, multi-microphone arrays provide spa- tial di versity for target source extraction (TSE) from observ ed sig- nals [1–3]. Classical spatial filters such as the minimum power dis- tortionless response (MPDR) and minimum v ariance distortionless response (MVDR) beamformers [4, 5], utilize array geometry to sup- press interference while preserving the source signal from the target direction of arriv al (DOA). Recently , neural network-based beam- forming has advanced along se veral primary directions: estimating time-frequency (TF) masks to deri ve the noise covariance [6–8]; predicting the target relativ e transfer function (R TF) to strengthen MPDR or MVDR beamformers [9, 10]; and directly learning beam- former weights [11]. In parallel, time-domain methods such as F aS- Net achiev e learned beamforming on the waveform for lower la- tency [12]. Howe ver , in underdetermined situations, where the number of activ e sources e xceeds the number of microphones, the performance of beamforming methods se verely degrades. A recently proposed strategy is to e xploit TF sparsity by constructing multiple candi- date beamformers that share the same target steering while placing nulls at different DO As of the interferers. Time-frequenc y-bin-wise switching (TFS) [13, 14] makes a hard choice, selecting one beam- former in each TF bin, whereas time-frequenc y-bin-wise linear com- bination (TFLC) [15] uses soft weights to combine multiple beam- formers. Both TFS and TFLC choose combination weights that min- imize the output power (min-selection) in each TF bin under a dis- tortionless constraint and can be extended to MPDR or MVDR [14]. Here, MVDR typically requires prior information of the interfer- ers to make the combination directly minimize their po wer, which is rarely attainable in practice. MPDR remov es this requirement, but minimizing observed power risks suppressing the target. More- ov er, independent per-bin selection weakens TF correlation, leading to spectral discontinuities and consequently poorer extraction perfor- mance. By contrast, neural networks can aggregate information ov er frequency bins within each frame, yielding more consistent weights and a better trade-off between target leakage and interference reduc- tion. Existing neural beam combination approaches usually fix a set of pre-designed beamformers and learn a global selection at the frame level or spectrogram lev el [16, 17] to perform source separa- tion, which cannot fully e xploit TF sparsity and generally relies on the beamformers designed in ov erdetermined situations. T o this end, we propose a neural network-based time-frequency- bin-wise linear combination (NN-TFLC) framew ork that encodes the mixture and each beamformed signal with inplace con volutional gated linear unit (ICGLU) [18, 19] and frequency-independent Bi- LSTM to preserve the full TF resolution. A cross-attention module then consumes mixture and beam features to produce combination weights with temporal and spectral context in each TF bin. W e use the prior R TF to form phase cues and to update several can- didate MPDR beamformers without explicitly estimating noise co- variances. The pipeline supports a v ariable number of input beam- formers and requires only a single update step. In experiments, NN-TFLC-MPDR consistently outperforms TFS/TFLC-MPDR and achiev es competitiv e performance with TFS/TFLC-MVDR in dual- microphone scenarios where multiple interferers coexist. 2. TFS AND TFLC OF BEAMFORMERS Consider an M -element microphone array observing one target source, N − 1 interferers, and additive background noise. The observation in the short-time F ourier transform (STFT) domain is x f ,t = a f S ref ,f ,t + N − 1 X n =1 h n,f I n,f ,t + n f ,t , (1) where f = 1 , . . . , F and t = 1 , . . . , T are the indices of the fre- quency bins and time frames, respectiv ely , x f ,t ∈ C M contains the observed signals, a f ∈ C M is the R TF of the tar get source signal, and S ref ,f ,t ∈ C is the target source image at the reference micro- phone, I n,f ,t ∈ C and h n,f ∈ C M denote the signal of the n -th Observ ed si gnals STFT EIPD Init ial izat ion (Null beam f orm ers) C Mixt ure encoder Beam encoder C Att ent io n gate MPDR beam f orm er iSTFT C : Herm it ia n inn er p rod u ct : Ele m ent - wis e prod uct : Co n ca te n at i o n : Su m Extract ed signal (a) Encod er res h ap e t o res h ap e t o × 4 × 2 In place C GLU + GN Bi - LSTM Linea r (b) Atte n ti o n g at e re s ha pe to Su m So f tm ax (c) Fig. 1 . Overview and detailed components of the proposed framework. (a) Overall structure of NN-TFLC-MPDR; (b) Structure of mixture encoder and beam encoder; (c) Structure of attention gate. interferer and its corresponding transfer function, respectiv ely , and n f ,t ∈ C M is the additiv e background noise. Our goal is to estimate S ref ,f ,t . Theoretically , an M -dimensional time-inv ariant beamformer can impose at most M independent linear constraints (one unit re- sponse plus M − 1 nulls), so when more than M − 1 interferers are simultaneously activ e, con ventional beamforming cannot fully suppress them. T o address this limitation, we consider combining different beamformers to process the observ ed signals. Under the M -disjoint orthogonality assumption mentioned in [15], at most M − 1 sources are active in each TF bin. In the dual-microphone scenarios, this assumption reduces to W -disjoint orthogonality [20, 21]. Therefore, we construct J ( ≥ N − 1 ) candi- date beamformers, each suppressing one interferer , and estimate the target via a combination in each TF bin, e xpressed as ˆ S ref ,f ,t = J X j =1 α ( j ) f ,t ( w ( j ) f ) H x f ,t , (2) where α ( j ) f ,t is the corresponding linear weight of the j -th beam- former w ( j ) f , satisfying 0 ≤ α ( j ) f ,t ≤ 1 and P J j =1 α ( j ) f ,t = 1 , and ( · ) H denotes the Hermitian transpose. Estimating the linear weights in each TF bin reduces to output-power minimization: the hard case α ( j ) f ,t ∈ { 0 , 1 } yields TFS [13], whereas the soft case α ( j ) f ,t ∈ [0 , 1] yields TFLC [15]. In practice, it is difficult to directly obtain predesigned beam- formers whose nulls are precisely aligned with the DO As of the in- terferers. Therefore, prior work [14, 15] adopts an iterati ve update strategy , where beamformers initialized with random values or with nulls placed in random DO As are used as the starting points. Then the linear weights α ( j ) f ,t are updated, and the updated weights are ap- plied as masks to deriv e new beamformers, as w ( j ) f = ( Φ ( j ) f ) − 1 a f a H f ( Φ ( j ) f ) − 1 a f for 1 ≤ j ≤ J, (3) where Φ ( j ) f = E [( α ( j ) f ,t x f ,t )( α ( j ) f ,t x f ,t ) H ] is the cov ariance matrix for the j -th beamformer . Here, when x f ,t is the full mixture including the target, this update corresponds to MPDR, and when x f ,t contains only the noise components, this update corresponds to MVDR. 3. PROPOSED METHOD 3.1. An overview of the pr oposed framework The overall structure of the proposed NN-TFLC-MPDR is illustrated in Fig. 1. Gi ven dual-microphone observed signals, the wav eforms are transformed to the STFT domain. The cosine and sine of the expected inter-channel phase difference (EIPD) [22] deriv ed from the R TF serve as the target phase cues, which are concatenated with the real and imaginary parts of the mixture along the channel di- mension and fed into a mixture encoder . W e prepare J null beam- formers { w ( j ) f } J j =1 with randomly selected null DO As { θ ( j ) } J j =1 to provide initial directional information. Like wise, the real and imag- inary parts of their beamformed signals are concatenated along the channel dimension and encoded by a shared beam encoder . An attention gate takes the outputs of the mixture encoder and beam encoder as its inputs, and yields TF-bin-wise linear weights. W e adopt a single iteration, in which the weights are used once to refine the MPDR beamformers. The updated candidate beamformed signals are re-encoded, and the same attention gate then yields the fi- nal combination weights, which are used to synthesize the estimated target source signal. 3.2. Mixture encoder and Beam encoder Each initial null beamformer is constructed with two linear con- straints: a unit response to ward the target DOA, and a null tow ard a DO A sampled from the angular range of the interferers. In the dual-microphone scenarios, this construction is determined. Both the mixture encoder and beam encoder share the same ar- chitecture in Fig. 1b. The encoder begins with four ICGLU blocks [18], whose stride is set to 1 so that the TF resolution does not change. This preserves an alignment with the later prediction of TF-bin-wise linear weights. In the beam encoder, we stack J beam- formed signals along the batch dimension to share weights, enabling the model to naturally support a variable number of beamformer in- puts. In addition, each ICGLU block is followed by a batch-size- agnostic group normalization (GN) [23], which is more robust than batch normalization due to the distribution shifts induced by differ- ent beam patterns. After GN, the exponential linear unit (ELU) acts as the activ ation function. T emporal context is then modeled by a two-layer frequency- independent Bi-LSTM shared across frequenc y bins to consistently capture the time-delay characteristics ov er frequencies. A final lin- ear layer halves the channel dimension, and the features are reshaped back to the original TF structure before entering the attention gate. 3.3. Attention gate In each TF bin, a cross-attention mechanism is emplo yed. The linear weights of e very candidate beamformer are obtained by the attention gate using softmax on a scaled dot product, expressed as α ( j ) f ,t = exp Q T f ,t K ( j ) f ,t / √ C P J j ′ =1 exp Q T f ,t K ( j ′ ) f ,t / √ C for 1 ≤ j ≤ J, (4) where Q f ,t ∈ R C is the query from the mixture encoder , K ( j ) f ,t ∈ R C is the j -th key from the beam encoder , ( · ) T denotes the trans- pose, and C is the encoded channel dimension. The linear weights α ( j ) f ,t first serve as masks to form masked co- variances and update J MPDR beamformers via (3), where x f ,t includes the target. Then, the refined beamformers are fed back through the shared beam encoder , re-encoded, and passed through the attention gate to obtain the final combination weights, which yield the target estimate in (2), follo wed by in verse STFT (iSTFT). 3.4. T raining strategy W e use two loss functions to train the neural network: a scale- in variant signal-to-distortion ratio (SI-SDR) [24], and an entropy regularization term. T o help the network learn to recover the target source signals from the mixture, the ne gativ e SI-SDR loss is employed, e xpressed as L SI-SDR = − 10 log 10 E ( | β s | 2 ) E ( | β s − ˆ s | 2 ) , (5) where s and ˆ s denote the time-domain reference and enhanced sig- nals, respectively , via iSTFT from S ref ,f ,t and ˆ S ref ,f ,t , and β = ˆ s T s / ∥ s ∥ 2 2 is the scaling factor . In the early stage of training, we observed that the final estimated linear weights are nearly uniform, e.g., α ( j ) f ,t ≈ 1 /J , which sev erely stalls the training process. There- fore, an entropy regularization term is proposed, e xpressed as L Ent = − 1 F T J F X f =1 T X t =1 J X j =1 α ( j ) f ,t ln( α ( j ) f ,t + ϵ ) , (6) where ϵ > 0 prev ents taking ln 0 . Minimizing this term not only helps the linear weights deviate from the uniform distribution, which accelerates training and con vergence, but also encourages more deci- siv e selection, allowing the difference in co variance statistics during the update of MPDR beamformers to be amplified, thereby enhanc- ing the complementarity among the candidate beamformers. The final loss function is summarized as L = L SI-SDR + λ L Ent , (7) where λ is the weight of the entropy regularization term. 4. EXPERIMENTS 4.1. Mixing conditions W e synthesize mixtures from clean utterances of LibriSpeech [25]. For each mixture, a simulated room is generated with length sampled from [6 , 10] m, width from [5 , 8] m, height from [2 . 5 , 3 . 5] m, and rev erberation time T 60 from [0 . 2 , 0 . 5] s. A dual-microphone linear array with 2 cm spacing is randomly placed within the room at a height of 1 . 5 m, and its center is at least 2 . 5 m from an y wall. The source-to-array distance is chosen from [1 . 5 , 2 . 0] m, and the source height is between 1 . 4 m and 1 . 6 m. The target DO A is selected from [80 ◦ , 100 ◦ ] , whereas DO As of the interferers are limited to [0 ◦ , 65 ◦ ] and [115 ◦ , 180 ◦ ] , with at most two interferers in each range. Clean signals are con volved with simulated RIRs using the image method [26]. Each interferer is then scaled to achie ve an input SIR of [0 , 5] dB. Additive noise comprises simulated dif fuse noise [27] and white Gaussian noise. The diffuse-to-white power ratio is in [15 , 25] dB, and the overall additiv e noise is adjusted to yield an SNR in [10 , 25] dB with respect to the rev erberant target. All the abov e random choices follow a uniform distribution. In total, we create 25,000 mixtures for training, 3,000 for vali- dation, and 3,000 for testing, each 6-second-long. The training set contains 15,000 mixtures with two interferers (2I), 5,000 with three (3I), and 5,000 with four (4I). The v alidation and test sets hav e a similar composition with 2,000 (2I), 500 (3I), and 500 (4I). 4.2. Model configurations In each ICGLU block, the kernel size is set as (5 × 1) , and the number of encoded channels is set to C = 32 . All audio is sampled at 16 kHz, with a 1024-sample Hanning window and a 256-sample shift. The weight of the entropy regularization term is λ = 0 . 05 . The Adam optimizer [28] is emplo yed, together with a StepLR scheduler that reduces the learning rate by a factor of 0 . 8 e very 10 epochs. The batch size is set to B = 4 . In our proposed method, we e valuate two model variants. NN- TFLC-MPDR (w/o Full) is trained only on the 2I subset with an initial learning rate of 6 × 10 − 4 , and its inputs are two beamform- ers whose null DO As are randomly drawn from [10 ◦ , 55 ◦ ] and [125 ◦ , 170 ◦ ] respectively , to augment the directional diversity of the training data. The best model is chosen by the a verage SI-SDR on the 2I validation split ov er 100 epochs. NN-TFLC-MPDR (w/ Full) is initialized from the 2I model and then continues training on the 3I and 4I subsets, with an initial learning rate of 2 × 10 − 4 , using four input beamformers with nulls randomly drawn from [10 ◦ , 30 ◦ ] , [35 ◦ , 55 ◦ ] , [125 ◦ , 145 ◦ ] , and [150 ◦ , 170 ◦ ] . Its best model is selected by the av erage SI-SDR on the entire validation set ov er another 100 epochs. For v alidation and testing, we fix the null angles. In the 2I case, the nulls of two initial beamformers are set to 32 . 5 ◦ and 147 . 5 ◦ . In the 3I and 4I cases, we use 16 . 25 ◦ , 48 . 75 ◦ , 131 . 25 ◦ , and 163 . 75 ◦ . 4.3. Results and discussions For comparison, MVDR, TFS-MVDR [14], and TFLC-MVDR [15], TFS-MPDR [14], and TFLC-MPDR [15] are used as the baselines. All methods, including ours, share the same R TF , estimated as the principal eigen vector of the cov ariance matrix of the re verberant tar- get source signals. For MVDR-based methods, the re verberant clean signals of interferers act as additional priors, and the min-selection rule is applied directly to minimize the interference and build the noise cov ariance for each beamformer, which is considered to have T able 1 . A verage SI-SDR (dB), SI-SIR (dB), and PESQ scores for processed signals with 2/3/4 interferers (mean ± standard deviation ). Method 2I (2 beamformers) 3I (4 beamformers) 4I (4 beamformers) SI-SDR SI-SIR PESQ SI-SDR SI-SIR PESQ SI-SDR SI-SIR PESQ Unprocessed -0.81 ± 1.00 -0.69 ± 1.04 1.13 ± 0.07 -2.48 ± 0.82 -2.40 ± 0.83 1.09 ± 0.07 -3.88 ± 0.77 -3.81 ± 0.78 1.09 ± 0.09 MVDR 0.93 ± 1.07 2.61 ± 1.40 1.16 ± 0.08 -0.95 ± 0.90 0.33 ± 1.09 1.11 ± 0.08 -2.46 ± 0.81 -1.35 ± 0.95 1.09 ± 0.06 TFS-MVDR [14] 4.16 ± 1.38 8.35 ± 2.16 1.24 ± 0.12 3.98 ± 1.29 8.62 ± 1.81 1.22 ± 0.13 2.84 ± 1.09 6.88 ± 1.59 1.16 ± 0.08 TFLC-MVDR [15] 4.52 ± 1.43 8.04 ± 2.02 1.25 ± 0.13 4.54 ± 1.32 7.87 ± 1.61 1.23 ± 0.14 3.37 ± 1.13 6.16 ± 1.40 1.17 ± 0.08 TFS-MPDR [14] 2.45 ± 1.51 6.06 ± 2.36 1.20 ± 0.10 0.03 ± 1.55 4.04 ± 2.21 1.13 ± 0.08 -0.51 ± 1.42 3.09 ± 1.98 1.10 ± 0.05 TFLC-MPDR [15] 2.86 ± 1.55 5.56 ± 2.12 1.21 ± 0.10 1.31 ± 1.58 3.82 ± 1.97 1.14 ± 0.09 0.32 ± 1.39 2.53 ± 1.72 1.11 ± 0.05 NN-TFLC-MPDR (w/o Full) 4.80 ± 1.55 7.70 ± 2.19 1.28 ± 0.12 3.19 ± 1.44 5.85 ± 1.93 1.20 ± 0.11 1.27 ± 1.31 3.67 ± 1.73 1.14 ± 0.06 NN-TFLC-MPDR (w/ Full) 4.51 ± 1.52 7.00 ± 2.06 1.26 ± 0.12 4.71 ± 1.54 9.82 ± 2.55 1.26 ± 0.13 2.65 ± 1.52 7.08 ± 2.42 1.17 ± 0.07 oracle performance in the original framework. All TFS/TFLC base- lines run for fiv e iterations. After processing, we calculate their SI- SDR, scale-in variant signal-to-interference ratio (SI-SIR) [29], and perceptual evaluation of speech quality (PESQ) scores [30] as the objectiv e metrics. The first microphone of the array is set as the ref- erence microphone, and the rev erberant clean source image of the target is set as the reference signal for all the abo ve metrics. First, we compare the baselines with the proposed NN-TFLC- MPDR in the 2I, 3I, and 4I cases of the test set, respectiv ely . As shown in T able 1, the performance of a single MVDR beamformer degrades sharply in underdetermined scenes. In contrast, our NN- TFLC-MPDR consistently outperforms TFS/TFLC MPDR across 2I/3I/4I. Although NN-TFLC-MPDR (w/o Full) is trained only on 2I with two initial beamformers as inputs, it can still yield around 1 dB higher SI-SDR than TFS/TFLC-MPDR when more interfer- ers exist in the en vironment, which demonstrates the e xtensibility of our model to adapt to varying numbers of input beamformers. NN- TFLC-MPDR (w/ Full) undergoes the full training process, and can then ha ve substantial improv ements in both SI-SDR and SI-SIR in 3I/4I, with a minor performance loss in 2I. Importantly , our method can match or surpass TFS/TFLC-MVDR in 2I/3I and yields a SI- SDR gap of less than 1 dB in 4I without requiring the prior informa- tion of the interferers, while achieving comparable PESQ scores. Next, we visualize the spectrograms of estimated signals and the beamformer combination weights in the TF plane processed by TFLC-MPDR and NN-TFLC-MPDR, respecti vely , on a sample from the 2I case. In Fig. 2, the bright bands of TFLC-MPDR ap- pear dimmer and more fragmented than the tar get’ s, as highlighted by the red boxes. This indicates that MPDR with per-bin min- selection does not fully preserve the target under the distortionless constraint, leading to potential suppression. While the bright bands of NN-TFLC-MPDR nearly coincide with those of the reference, which demonstrates the NN-based selection reduces target distor- tion and achieves a better trade-off between target preservation and suppression of interference. W e further plot the combination weights for one of the two can- didate beamformers in Fig. 2. It is obvious that per -bin min-selection of TFLC yields fragmented weight maps with weak cross-bin cor - relation. The discontinuities make the weights noisy and irregular across TF bins, potentially introducing phase inconsistencies and ar - tifacts. By contrast, the NN-derived weights are coherent over time and frequency , and transition smoothly , especially in low-frequency regions and along several frequency bands. This behavior arises because attention in each TF bin operates on features that already encode TF context. As highlighted by the red boxes, in these tar get- dominant regions, the network tends to blend two beamformers rather than producing the patchwork mixing seen in TFLC-MPDR. This reduces the risk of directly selecting a beamformer whose null lies near the target, and thus helps preserve the target component. Also, in interference-dominant regions, shown by the blue boxes, Fig. 2 . Log-magnitude spectrogram and combination weights of a beamformer in the TF plane for a sample from the 2I case. the network makes more decisiv e selections, including at high fre- quencies where background noise is prominent, which strengthens beam selectivity and impro ves suppression of different interferers. 5. CONCLUSIONS In this paper , we present an NN-TFLC framework that constructs MPDR beamformers. It uses a neural network to estimate TF- bin-wise linear weights for combining multiple beamformers to extract the target source from underdetermined mixtures, without explicit noise covariance estimation. Across mixtures with multi- ple interferers, our method consistently outperforms conv entional TFS/TFLC-MPDR and achiev es competitive performance with TFS/TFLC-MVDR, which le verages prior information of the in- terferers to directly minimize their power . Moreover , experiments show that the proposed netw ork adapts seamlessly to different num- bers of input beamformers, demonstrating strong scalability and practicality . 6. REFERENCES [1] J. Benesty , S. Makino, and J. Chen, Speech enhancement , Springer , 2006. [2] J. Benesty , I. Cohen, and J. Chen, Fundamentals of signal enhancement and array signal pr ocessing , John Wile y & Sons, 2017. [3] S. Makino, Audio Source Separation , Springer, Switzerland, 2018. [4] J. Li, P . Stoica, and Z. W ang, “On robust capon beamforming and diagonal loading, ” IEEE T rans. Signal Pr ocess. , vol. 51, no. 7, pp. 1702–1715, Jul. 2003. [5] J. Benesty , J. Chen, and Y . Huang, Micr ophone array signal pr ocessing , Springer , 2008. [6] J. He ymann, L. Drude, and R. Haeb-Umbach, “Neural netw ork based spectral mask estimation for acoustic beamforming, ” in Pr oc. IEEE ICASSP , 2016, pp. 196–200. [7] H. Erdogan, J. R. Hershey , S. W atanabe, M. I. Mandel, and J. Le Roux, “Improved MVDR beamforming using single- channel mask prediction networks., ” in Pr oc. Interspeech , 2016, pp. 1981–1985. [8] X. Xiao, S. Zhao, D. L. Jones, E. S. Chng, and H. Li, “On time- frequency mask estimation for MVDR beamforming with ap- plication in robust speech recognition, ” in Pr oc. IEEE ICASSP , 2017, pp. 3246–3250. [9] A. Aroudi and S. Braun, “DBNet: DOA-dri ven beamforming network for end-to-end reverberant sound source separation, ” in Pr oc. IEEE ICASSP , 2021, pp. 211–215. [10] Y . Y ang, C. Pan, Q. Gao, J. Benesty , S. Makino, and J. Chen, “Neural network-assisted joint DO A estimation and beam- forming with first-order reflection modeling, ” in Pr oc. APSIP A ASC , 2025, pp. 19–23. [11] Z. Zhang, Y . Xu, M. Y u, S.-X. Zhang, L. Chen, and D. Y u, “ADL-MVDR: All deep learning MVDR beamformer for tar- get speech separation, ” in Pr oc. IEEE ICASSP , 2021, pp. 6089–6093. [12] Y . Luo, C. Han, N. Mesgarani, E. Ceolini, and S.-C. Liu, “F as- net: Lo w-latency adaptiv e beamforming for multi-microphone audio processing, ” in Pr oc. IEEE ASR U , 2019, pp. 260–267. [13] K. Y amaoka, A. Brendel, N. Ono, S. Makino, M. Buer ger , T . Y amada, and W . Kellermann, “Time-frequenc y-bin-wise beamformer selection and masking for speech enhancement in underdetermined noisy scenarios, ” in Pr oc. EUSIPCO , 2018, pp. 1582–1586. [14] K. Y amaoka, N. Ono, S. Makino, and T . Y amada, “T ime- frequency-bin-wise switching of minimum v ariance distortion- less response beamformer for underdetermined situations, ” in Pr oc. IEEE ICASSP , 2019, pp. 7908–7912. [15] K. Y amaoka, N. Ono, and S. Makino, “Time-frequenc y-bin- wise linear combination of beamformers for distortionless sig- nal enhancement, ” IEEE/ACM T rans. Audio, Speech, Lang. Pr ocess. , vol. 29, pp. 3461–3475, Nov . 2021. [16] Z. Chen, T . Y oshioka, X. Xiao, L. Li, M. L. Seltzer, and Y . Gong, “Efficient inte gration of fixed beamformers and speech separation networks for multi-channel far-field speech separation, ” in Pr oc. IEEE ICASSP , 2018, pp. 5384–5388. [17] R. Liu, Y . Zhou, H. Liu, X. Xu, J. Jia, and B. Chen, “ A new neural beamformer for multi-channel speech separation, ” J. Signal Pr ocess. Syst. , v ol. 94, no. 10, pp. 977–987, May 2022. [18] J. Liu and X. Zhang, “Inplace gated con volutional recur - rent neural network for dual-channel speech enhancement, ” in Pr oc. Interspeech , 2021, pp. 1852–1856. [19] J. Bai, H. Li, X. Zhang, and F . Chen, “ Attention-based beam- former for multi-channel speech enhancement, ” in Pr oc. IEEE ICASSP , 2025, pp. 1–5. [20] A. Jourjine, S. Rickard, and O. Y ilmaz, “Blind separation of disjoint orthogonal signals: Demixing N sources from 2 mix- tures, ” in Pr oc. IEEE ICASSP , 2000, vol. 5, pp. 2985–2988. [21] O. Y ilmaz and S. Rickard, “Blind separation of speech mix- tures via time-frequency masking, ” IEEE T rans. Signal Pr o- cess. , vol. 52, no. 7, pp. 1830–1847, Jul. 2004. [22] Z. W ang and D. W ang, “On spatial features for supervised speech separation and its application to beamforming and ro- bust ASR, ” in Pr oc. IEEE ICASSP , 2018, pp. 5709–5713. [23] Y . W u and K. He, “Group normalization, ” in Pr oc. ECCV , 2018, pp. 3–19. [24] J. Le Roux, S. W isdom, H. Erdog an, and J. R. Hershe y , “SDR– half-baked or well done?, ” in Pr oc. IEEE ICASSP , 2019, pp. 626–630. [25] V . Panayotov , G. Chen, D. Pov ey , and S. Khudanpur , “Lib- rispeech: an ASR corpus based on public domain audio books, ” in Pr oc. IEEE ICASSP , 2015, pp. 5206–5210. [26] J. B. Allen and D. A. Berkley , “Image method for ef ficiently simulating small-room acoustics, ” J. Acoust. Soc. Am. , vol. 65, no. 4, pp. 943–950, Apr . 1979. [27] E. A. P . Habets, I. Cohen, and S. Gannot, “Generating non- stationary multisensor signals under a spatial coherence con- straint, ” J. Acoust. Soc. Am. , vol. 124, no. 5, pp. 2911–2917, Nov . 2008. [28] D. P . Kingma and J. Ba, “ Adam: A method for stochastic opti- mization, ” arXiv preprint , 2014. [29] R. Scheibler , “SDR—medium rare with f ast computations, ” in Pr oc. IEEE ICASSP , 2022, pp. 701–705. [30] J. G. Beerends, A. P . Hekstra, A. W . Rix, M. P . Hollier, et al., “Perceptual ev aluation of speech quality (PESQ): The new ITU standard for end-to-end speech quality assessment part ii- psychoacoustic model, ” J . Audio Eng. Soc. , vol. 50, no. 10, pp. 765–778, Oct. 2002.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment