신경망 기반 시간‑주파수 구간별 빔포머 선형 결합으로 언더디터미ined 타깃 추출 강화
본 논문은 언더디터미ined(마이크 수보다 소스가 많은) 상황에서 목표 음원을 추출하기 위해, 다중 빔포머를 시간‑주파수(TF) 구간별로 선형 결합하는 신경망 기반 프레임워크(NN‑TFLC)를 제안한다. 네트워크는 혼합 신호와 각 빔포머 출력의 특징을 인코딩하고, 교차‑어텐션을 통해 TF 구간마다 일관된 가중치를 예측한다. 이를 통해 명시적인 잡음 공분산 추정 없이 MPDR 빔포머를 구성하고, 기존 TFS/TFLC‑MPDR 대비 SI‑SDR을 …
저자: Changda Chen, Yichen Yang, Wei Liu
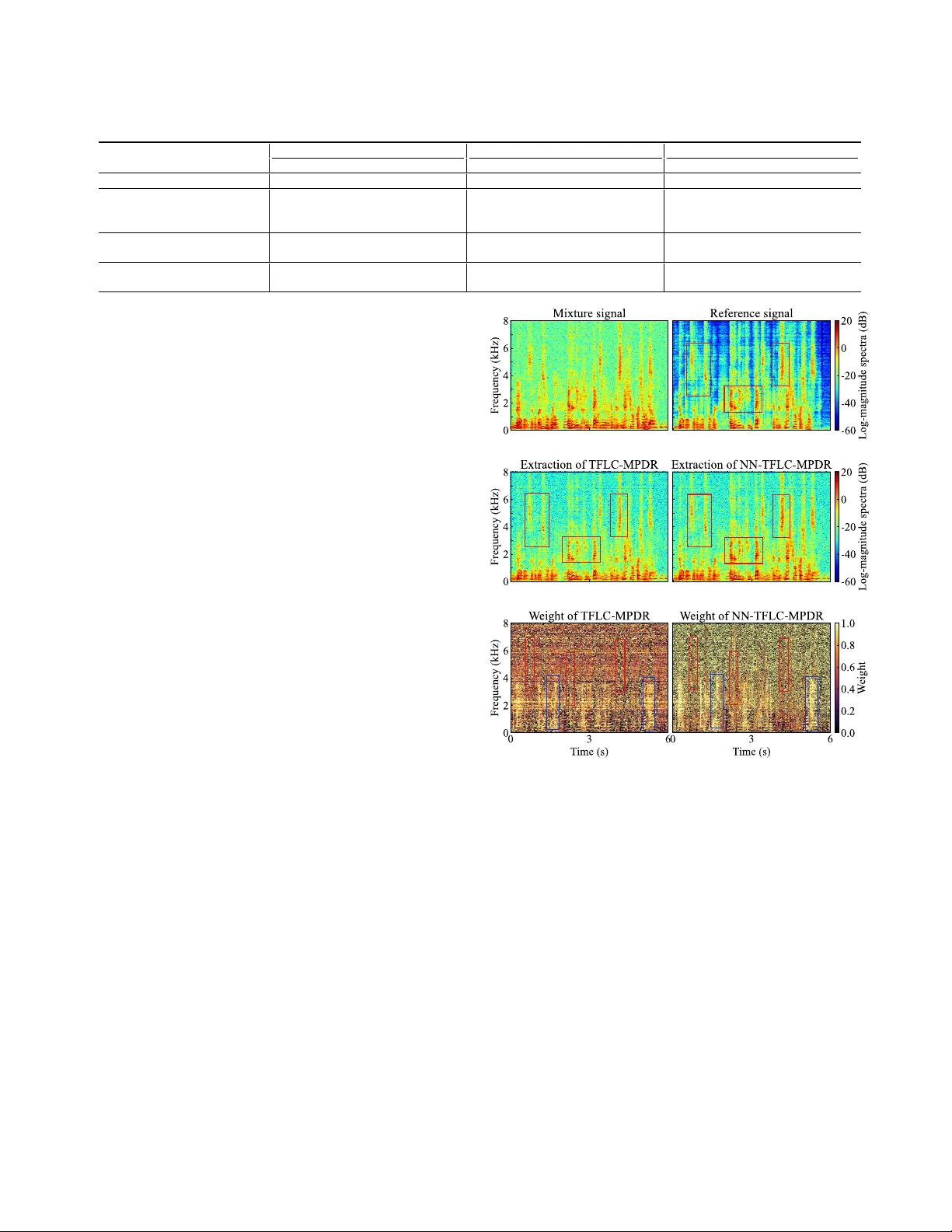
본 논문은 다중 마이크 어레이를 활용한 목표 음원 추출(TSE) 분야에서, 특히 소스 수가 마이크 수보다 많은 언더디터미ined 상황에 대한 새로운 접근법을 제시한다. 기존의 최소 전력 왜곡 없는 응답(MPDR) 및 최소 분산 왜곡 없는 응답(MVDR) 빔포머는 목표 방향에 대한 단일 제약과 최대 M‑1개의 널 제약만을 가질 수 있어, 다수의 간섭원을 동시에 억제하기에 한계가 있다. 최근에는 시간‑주파수 구간별 스위칭(TFS)과 선형 결합(TFLC) 기법이 제안되어, 여러 후보 빔포머를 TF 구간마다 선택하거나 가중합함으로써 TF 희소성을 활용하고자 했다. 그러나 TFS는 각 구간을 독립적으로 하드 선택해 시간‑주파수 연속성을 파괴하고, TFLC는 가중치가 초기에는 거의 균등하게 분포해 학습이 정체되는 문제가 있었다.
이에 저자들은 신경망 기반 시간‑주파수 구간별 선형 결합(NN‑TFLC) 프레임워크를 설계하였다. 전체 파이프라인은 다음과 같다. 1) 입력은 듀얼 마이크 STFT 스펙트로그램이며, 목표 RTF(전달 함수)로부터 기대되는 인터채널 위상 차이(EIPD)의 코사인·사인 값을 추출해 목표 위상 정보를 제공한다. 2) 초기 후보 빔포머는 목표 DOA에 대한 단위 응답과 무작위 간섭원 DOA에 대한 널을 동시에 만족하도록 구성한다. 이때 널 DOA는 사전에 정의된 각 구간에 따라 무작위로 선택된다. 3) 혼합 신호와 각 후보 빔포머의 출력(복소수 실·허수) 를 채널 차원으로 결합해 혼합 인코더와 빔 인코더에 입력한다. 인코더는 4개의 인플레이스 컨볼루션 게이트 선형 유닛(ICGLU) 블록을 사용해 TF 해상도를 유지하면서 특징을 추출하고, 각 블록 뒤에 그룹 정규화(GN)와 ELU 활성화를 적용한다. 4) 인코더 출력은 주파수 독립적인 2‑계층 Bi‑LSTM을 통과해 시간적 맥락을 포착하고, 마지막 선형 레이어로 차원을 절반으로 축소한다. 5) 교차‑어텐션 게이트는 혼합 인코더의 출력 Q와 각 빔 인코더의 키 K₍j₎를 이용해 스케일드 닷‑프로덕트 어텐션을 수행하고, 소프트맥스를 적용해 TF 구간별 가중치 α₍j₎(f,t)를 산출한다. 6) 이 가중치는 마스크 역할을 하여 각 후보 빔포머의 관측 공분산 Φ₍j₎(f)=E
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기