Space Upper Bounds for $α$-Perfect Hashing
In the problem of perfect hashing, we are given a size $k$ subset $\mathcal{A}$ of a universe of keys $[n] = \{1,2, \cdots, n\}$, for which we wish to construct a hash function $h: [n] \to [b]$ such that $h(\cdot)$ maps $\mathcal{A}$ to $[b]$ with no…
Authors: Ryan Song, Emre Telatar
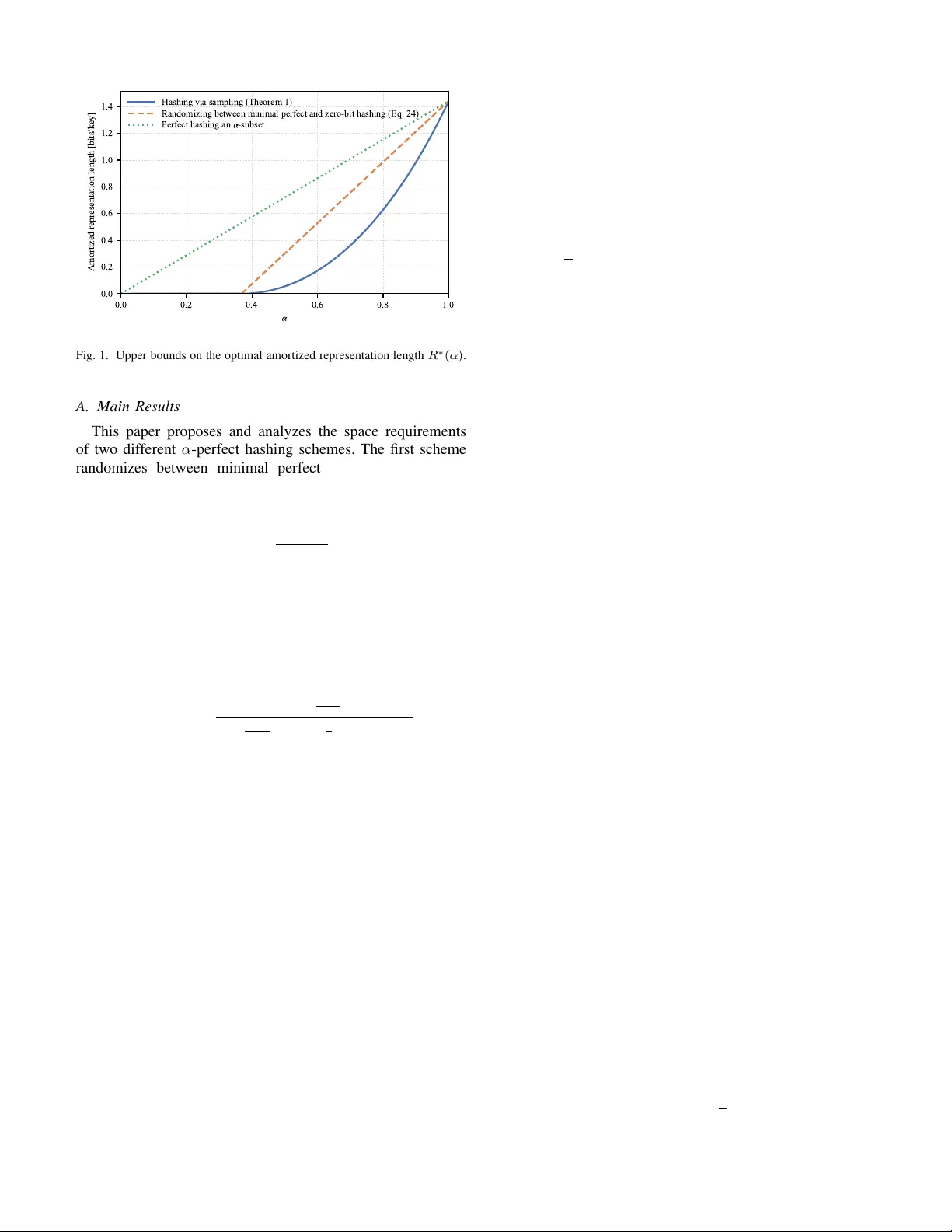
Space Upper Bounds for α -Perfect Hashing Ryan Song and Emre T elatar School of Computer and Communication Sciences École Polytechnique Fédérale de Lausanne (EPFL), Switzerland Emails: ryan.song@epfl.ch, emre.telatar@epfl.ch Abstract —In the problem of perfect hashing, we are given a size k subset A of a universe of k eys [ n ] = { 1 , 2 , · · · , n } , f or which we wish to construct a hash function h : [ n ] → [ b ] such that h ( · ) maps A to [ b ] with no collisions, i.e., the restriction of h ( · ) to A is injective. When b = k , the problem is r eferr ed to as minimal perfect hashing. In this paper , we extend the study of minimal perfect hashing to the approximate setting. F or some α ∈ [0 , 1] , we say that a randomized hashing scheme is α -perfect if f or any input A of size k , it outputs a hash function which exhibits at most (1 − α ) k collisions on A in expectation. One important performance consideration f or any hashing scheme is the space requir ed to stor e the hash functions. For minimal perfect hashing, i.e., b = k , it is well known that approximately k log ( e ) bits, or log( e ) bits per key , is requir ed to store the hash function. In this paper , we propose schemes for constructing minimal α - perfect hash functions and analyze their space requirements. W e begin by presenting a simple base-line scheme which randomizes between perfect hashing and zero-bit random hashing. W e then present a more sophisticated hashing scheme based on sampling which significantly impro ves upon the space requirement of the afor ementioned strategy for all values of α . I . I N T R O D U C T I O N In the problem of minimal perfect hashing, we are gi ven a univ erse of keys [ n ] = { 1 , · · · , n } and a subset A ⊂ [ n ] of size |A| = k , and are tasked with constructing a hash function h : [ n ] → [ k ] which exhibits no collisions on A , i.e., h ( · ) is a bijection when restricted to A . In this case, we say that h ( · ) is a minimal perfect hash function for A , where "minimal" refers to the range of h ( · ) being the same cardinality as A . Perfect hashing sees many applications throughout computer science, for example, in the design of hash tables, where we wish to map a large univ erse of keys to a smaller set of values representing positions on a lookup table [1]. When a collision occurs, costly followup measures are typically required which degrade performance. In many cases ho we ver , the set of keys that we wish to hash are known a priori. In such cases, we can employ a minimal perfect hashing scheme to construct a hash function a priori for the gi v en set of ke ys, thus av oiding collisions during future use. More recently , perfect hashing has also found applications in communications, particularly in massiv e random access settings, where a central base-station wishes to provide con- nectivity to a small random subset of activ e users among a large pool of potential users. Instead of relying on a traditional contention based scheme such as ALOHA [2], which requires frequent collision resolution, it has been proposed in [3], [4] that the base-station can instead first detect the identities the activ e users, then construct a perfect hash function which maps each active user to a unique transmission slot. Then, by communicating this perfect hashing function to the users prior to their transmissions, collisions between users can be av oided entirely . These ideas were then generalized to tackle the problem of communicating arbitrary information sources in a massiv e random access setting [5], [6]. When ev aluating the performance of a perfect hashing scheme, an important consideration is the number of bits required to store/communicate the hash function. Naively , any hash function h : [ n ] → [ k ] can be stored using n log( k ) bits, which for large n , is infeasible. T o design a more efficient scheme, we make tw o observ ations. Firstly , we only care about the output of the hash function h ( · ) over A , the k keys of interest. Secondly , although we require that h ( · ) be a bijection ov er A , we do not necessarily need to describe a particular bijection among the k ! possibilities. Lev eraging these two observations, it has been shown that the theoretically optimal amount of space required to store a perfect hash function is approximately k log( e ) bits, or log ( e ) bits per key [3], [7]– [9]. Although deterministic schemes are theoretically capable of achieving the optimal log( e ) bits per key , most modern practical perfect hashing schemes rely on randomization in the construction process [10], [11]. In this paper , we ask the following question. If we relax the strict collision-free requirement to instead only requiring that, in expectation, an α -proportion of keys be hashed without collision, ho w much space would then be needed to store the hash function? This problem, which we call minimal α -perfect hashing, extends the minimal perfect hashing to the approximate setting, since when α = 1 , we recov er the problem of minimal perfect hashing. The goal of this paper is to characterize the tradeoff between α and the space required to store an α -perfect hash function. At first glance, one may be tempted to approach α -perfect hashing along the follo wing lines. Gi v en a size k subset A , first select an αk sized subset of A , then construct a perfect hash function for this subset, which can be stored using αk log ( e ) bits. The problem with this approach is that although the αk keys are guaranteed to be collision-free among each other , the y may still end up being in v olved in collisions with the other (1 − α ) k keys in A . Further , it turns out that for the problem of α -perfect hashing, we can de v elop schemes with space requirements much less than αk log ( e ) bits. This is because by constructing and storing a perfect hash function for a specific αk subset of A , we implicitly store unnecessary information pertaining to that particular subset. Fig. 1. Upper bounds on the optimal amortized representation length R ∗ ( α ) . A. Main Results This paper proposes and analyzes the space requirements of two different α -perfect hashing schemes. The first scheme randomizes between minimal perfect hashing and zero-bit hashing to achiev e a space requirement of λ ( α ) log ( e ) bits per key in expectation, where λ ( α ) = max α − 1 /e 1 − 1 /e , 0 . (1) This essentially achie ves a linear tradeoff between the number of collisions and the amount of space required. W e then show that this linear relationship is not optimal. Using results from sampling theory [12], [13], we develop a sampling-based minimal α -perfect hashing scheme which achiev es a space requirement of λ ( α ) log( e ) − log 1 − λ ( α ) 2 1 − λ ( α ) 2 − 1 − 1 e (1 − λ ( α )) !! (2) bits per key in expectation. This improves upon the aforemen- tioned scheme for all α . From Figure 1, we can see a surprising tradeoff between α and the bits per ke y needed to store the hash function. F or example, storing a minimal 0 . 9 -perfect hash function requires roughly 1 bit per key compared to the log( e ) ≈ 1 . 44 bits per key required to store a minimal perfect hash function. Note that when α = 1 , both hashing schemes achiev e the optimal log( e ) bits per key . B. Notation Unless stated otherwise, lowercase letters denote scalars, lowercase boldface letters denote vectors, capital letters de- note random variables, boldface capital letters denote random vectors, and calligraphic letters, e.g. S , denote sets. All infor- mation measures are expressed in bits, including entropy H ( · ) and the Kullback–Leibler div ergence D ( ·∥· ) . W e let log( · ) denote the base 2 logarithm and use the shorthand notations ( x ) + = max { x, 0 } , [ n ] = { 1 , · · · , n } , and [ n ] k to denote the set of all size k subsets of [ n ] . I I . P RO B L E M F O R M U L A T I O N This paper considers the problem of minimal α -perfect hashing. Let H n,k = [ k ] n denote the set of all functions mapping [ n ] to [ k ] and α ∈ [0 , 1] . Given a set A ∈ [ n ] k , we say that a ∈ A collides under h ( · ) if there exists another a ′ ∈ A such that h ( a ) = h ( a ′ ) . Define d : [ n ] k × H n,k → R to be the function which computes the proportion of A that collides under h ( · ) , i.e., d ( A , h ) = 1 k a ∈ A : ∃ a ′ ∈ A , a ′ = a, h ( a ) = h ( a ′ ) . (3) A hash function h ( · ) is said to be α -perfect for A if h ( · ) exhibits at most (1 − α ) k collisions when restricted to A , i.e., d ( A , h ) ≤ 1 − α. (4) A randomized hashing scheme takes as input a set A and stochastically constructs a hash function h ( · ) . If the constructed hash function is α -perfect in expectation, we say that this scheme is an α -perfect hashing scheme. The goal of this paper is to design and analyze the space requirements of such hashing schemes. T o do so, we define a randomized hashing scheme to consist of an encoder , a decoder, and common randomness Z ∈ Z which is accessible by both the encoder and decoder . The encoder f : [ n ] k × Z → { 0 , 1 } ∗ (5) maps a set A and a realization of the common randomness z to a v ariable-length binary description. T o ensure that the decoder knows when to stop reading the binary input, we require that for each fixed z , the set of all possible strings output by the encoder f forms a prefix-free collection. Using the encoder output along with the same z , the decoder g : { 0 , 1 } ∗ × Z → H n,k (6) recov ers a hash function h ( · ) . W e say that a randomized hashing scheme ( f , g , Z ) is α -perfect if for all A ∈ [ n ] k , the output hash function is α -perfect in expectation, i.e., max A∈ ( [ n ] k ) E [ d ( A , g ( f ( A , Z ) , Z ))] ≤ 1 − α . (7) It is worth remembering that the distribution of Z is designed apriori, without knowledge of A . The encoder output is a binary representation of the hash function. Therefore, we define the space required by a hashing scheme ( f , g , Z ) to be the maximum expected representation length ov er all inputs: L = max A∈ ( [ n ] k ) E [ len ( f ( A , Z ))] . (8) W e then define the optimal expected representation length L ∗ ( n, k , α ) to be the infimum expected representation length ov er all minimal α -perfect hashing schemes with parameters n and k . Another quantity of interest is the number of bits per key required as n and k become large. W e define the optimal amortized expected representation length to be R ∗ ( α ) = lim sup k →∞ lim sup n →∞ 1 k L ∗ ( n, k , α ) . (9) I I I . M I N I M A L P E R F E C T A N D Z E R O - B I T H A S H I N G In this section, we present a strategy for minimal α -perfect hashing which consists of randomizing between minimal per- fect hashing and zero-bit hashing. This strategy relies on the following observation. Giv en an α 1 -perfect hashing scheme ( f 1 , g 1 , Z 1 ) and an α 2 -perfect hashing scheme ( f 2 , g 2 , Z 2 ) which hav e e xpected representation lengths L 1 and L 2 , respec- tiv ely . Then, for any λ ∈ [0 , 1] , we can randomize between the two schemes by using the first scheme with probability λ and the second scheme with probability 1 − λ . The resulting new hashing scheme is ( λα 1 + (1 − λ ) α 2 ) -perfect and has expected representation length λL 1 + (1 − λ ) L 2 . As a consequence of this observation, we hav e that for any fixed n and k , the function L ∗ ( n, k , α ) is con ve x in α . A. Minimal P erfect Hashing W e begin by considering the problem of minimal 1 -perfect hashing where we ensure no collisions. From [3], we know that the expected representation length L ∗ ( n, k , 1) ≤ k log ( e ) + 3 (10) is achie v able. Therefore, the amortized e xpected representation length is bounded from abov e as R ∗ (1) ≤ log ( e ) . (11) W e recap the proof of these bounds as the ideas and techniques employed will become useful in later sections. The main argument hinges on the use of uniformly ran- dom hash functions which are identically and independently distributed (i.i.d.). Let Z = C (1) , C (2) , · · · (12) be a sequence of i.i.d. random hash functions av ailable at both the encoder and decoder , where each C ( t ) ∼ Uniform( H n,k ) . Giv en a set A ∈ [ n ] k and a realization z = c (1) , c (2) , · · · , one can search through z to find the first index t such that d A , c ( t ) = 0 , and then provide a binary description of t , that is, we define l ( A , z ) = min n t > 0 : d A , c ( t ) = 0 o (13) and let f ( A , z ) be the binary description of the positive inte ger l ( A , z ) via a prefix-free source code. W e may design this source code optimally based on the probability distribution of l ( A , Z ) . The decoder g : { 0 , 1 } ∗ × Z → H n,k , giv en the binary description and z ∈ Z , can recover l ( A , z ) first then use z to produce the hash function c ( l ( A ,z )) . Since ev ery C ( t ) is i.i.d. uniform ov er H n,k , for every A ∈ [ n ] k , the index l ( A , Z ) is geometrically distributed as Pr( l ( A , Z ) = t ) = 1 − k ! k k t − 1 k ! k k . (14) As the entropy H ( l ( A , Z )) is upper bounded by H ( l ( A , Z )) ≤ log k k k ! + log( e ) (15) ≤ k log( e ) + 2 , (16) we can find a binary prefix-fix free code c for the positive integers with E [ len ( c ( l ( A , Z )))] ≤ k log( e ) + 3 . Therefore L ∗ ( n, k , 0) ≤ H ( l ( A , Z )) + 1 (17) ≤ k log( e ) + 3 . (18) The upper bound on R ∗ (0) follows immediately . B. Minimal Zer o-Bit Hashing W e now consider the conceptual opposite of perfect hashing, where regardless of the input, the encoder outputs the empty string and the decoder outputs a hash function selected uni- formly at random from H n,k . Since the representation length is 0 bits, we refer to this strategy as zero-bit hashing. Fix n , k , and a set A ∈ [ n ] k . Let ( a 1 , · · · , a k ) be the elements of A arranged in an arbitrary order and C ∼ Uniform( H n,k ) be a uniformly random hash function. Define random variables ( B 1 , · · · , B k ) ∈ { 0 , 1 } k to be B i = ( 1 , if ∃ ! j ∈ A such that C ( j ) = i 0 , otherwise. (19) Notice that the number of elements in A which are in v olv ed in a collision is exactly D = k − k X i =1 B i . (20) Observing that E [ B i ] = k 1 1 k 1 − 1 k k − 1 ≥ 1 e (21) and applying the linearity of expectation, we ha ve that E [ D ] ≤ k 1 − 1 e . (22) Since in expectation, at least a 1 e -proportion of A are mapped without collision, the zero-bit hashing scheme is a 1 e -perfect hashing scheme. Therefore, for 0 ≤ α ≤ 1 e , we have that L ∗ ( n, k , α ) = 0 and R ∗ ( α ) = 0 . C. Randomizing Between P erfect and Zer o-Bit Hashing For values of α between 1 e and 1 , we can randomize between the aforementioned minimal perfect and zero-bit hashing schemes by using the minimal perfect hashing scheme with some probability λ ∈ [0 , 1] and the zero-bit hashing scheme otherwise. Doing so yields a hashing scheme that is λ + (1 − λ ) 1 e -perfect and achieves an expected representa- tion length of λ ( k log( e ) + 3) bits. Rearranging and finding the relationship between λ and α , we can see that the randomized scheme is α -perfect as long as λ ≥ α − 1 e 1 − 1 e . This implies that, L ∗ ( n, k , α ) ≤ α − 1 /e 1 − 1 /e ( k log( e ) + 3) + (23) and R ∗ ( α ) ≤ α − 1 /e 1 − 1 /e + log( e ) . (24) In the next section, we present a hashing scheme based on sampling which improv es upon the abov e strategy for all α . I V . H A S H I N G V I A S A M P L I N G In this section, we revie w techniques from sampling and apply them to develop an improved α -perfect hashing scheme. Let M = X (1) , X (2) , · · · be an infinite sequence of random variables which are i.i.d. according to distribution q ( x ) and take values on a countable set X . In the problem of sampling, we are giv en a realization of the sequence x (1) , x (2) , · · · from which we wish to select a single sample x ( t ) such that x ( t ) is distributed according to distrib ution p ( x ) . T o incorporate randomized strate gies, we let U ∈ U be a random variable which is independent of M which is to be designed a priori. Formally , the problem of sampling is to find a function s : X ∗ × U → N (25) such that the s ( M , U ) ’th term in M is distributed according to p ( x ) , i.e., X ( s ( M ,U )) ∼ p ( x ) . (26) Beyond finding an s ( · ) which generates the correct target distribution p ( x ) , it is also of interest to find an s ( · ) whose entropy H ( s ( M , U )) is small. T o this end, we apply the results of [12], which takes advantage of the properties of the Poisson point process to perform sampling. In [12, Theorem 1], it is shown that there exists a s ( · ) and U such that X ( s ( M ,U )) ∼ p ( x ) (27) which also has entropy bounded from abov e as H ( s ( M , U )) ≤ D ( p ∥ q ) + log( D ( p ∥ q ) + 1) + 4 . (28) W e refer this sampling scheme as the Poisson Function Rep- resentation (PFR) sampling scheme. W e can now apply the above results on sampling towards α -perfect hashing. Similar to how we designed scheme for minimal perfect hashing, let Z = C (1) , C (2) , · · · (29) be an infinite sequence of i.i.d. random hash functions, where each C ( t ) ∼ Uniform( H n,k ) . Note that for any set A = { a 1 , · · · , a k } ∈ [ n ] k , the restriction of C ( t ) to A X ( t ) = C ( t ) ( a 1 ) , · · · , C ( t ) ( a k ) (30) are i.i.d. uniformly ov er [ k ] k for all positiv e integers t > 0 . Therefore, given a distribution p ( x ) on [ k ] k , the PFR sampling scheme provides us with an index selection method s ( A , Z, U ) which ensures that for all A , we hav e that X ( s ( A ,Z,U )) ∼ p ( x ) . (31) Further , the entropy is bounded from above as H ( s ( A , Z, U )) ≤ D ( p ∥ q ) + log ( D ( p ∥ q ) + 1) + 4 . (32) Since the hash functions are distributed uniformly o ver H n,k , the distribution of s ( A , Z, U ) is the same for any choice of A . Therefore, there exists a binary prefix-free code c for the positiv e inte gers such that E [ len ( c ( s ( A , Z , U )))] ≤ H ( s ( A , Z, U )) + 1 , (33) regardless of the choice of A . W ith this, we define the follo wing hashing scheme. Let ( Z, U ) be common randomness. Giv en input A , the encoder computes s ( A , z , u ) then compresses s ( A , z , u ) using binary prefix-free code c . Gi v en this binary description, the decoder first recov ers s ( A , z , u ) then the hash function c ( s ( A ,z ,u )) . The e xpected number of collisions for this hashing scheme depends only on the choice of p ( x ) . T o ensure that the scheme is α -perfect, we should choose p ( x ) so that E [ d ( X )] ≤ 1 − α , (34) where X ∼ p ( x ) and d ( x ) = 1 k i ∈ [ k ] : ∃ j ∈ [ k ] , j = i, x j = x i . (35) The expected representation length on the other hand scales with the diver gence D ( p ∥ q ) . Since the distribution q ( x ) is the uniform distribution over [ k ] k , we hav e that D ( p ∥ q ) = k log ( k ) − H ( X ) , (36) where X ∼ p ( x ) . Thus, for α -perfect hashing, we wish to design a distribution p ( x ) which maximizes the entropy subject to the constraint E [ d ( X )] ≤ 1 − α . The following lemma restates the abov e reasoning in terms of L ∗ ( n, k , α ) . Lemma 1: Let X = ( X 1 , · · · , X k ) be a sequence of random variables each taking values on [ k ] such that E [ d ( X )] ≤ 1 − α . (37) Then, the optimal representation length L ∗ ( n, k , α ) for mini- mal α -perfect hashing is bounded from abov e as L ∗ ( n, k , α ) ≤ k log ( k ) − H ( X ) + log( k log ( k ) − H ( X ) + 1) + 5 . (38) V . S P AC E B O U N D S F O R M I N I M A L α - P E R F E C T H A S H I N G In this section, we dev elop upper bounds on L ∗ ( n, k , α ) and R ∗ ( α ) by first constructing a suitable sequence of random variables X = ( X 1 , · · · , X k ) which satisfy the collision constraint E [ d ( X )] ≤ 1 − α while simultaneously having large entropy , then applying Lemma 1. Let X ∈ [ k ] k be defined in the following way: 1) Fix a value λ ∈ [0 , 1] . 2) Let w = ⌈ λk ⌉ . 3) Construct random variables ( Y 1 , · · · , Y k ) ∈ [ k ] k as fol- lows. Let ( Y 1 , · · · , Y w ) be the sequence resulting from w draws without r eplacement from an urn containing elements [ k ] . Next, let ( Y w +1 , · · · , Y k ) be the sequence resulting from k − w additional draws with replacement from the same urn. 4) Let π ( · ) denote a uniformly random permutation of [ k ] and let X be a random permutation of Y , i.e., X = ( X 1 , · · · , X k ) = ( Y π (1) , · · · , Y π ( k ) ) . (39) For some X generated with parameter λ , we denote the distribution of X as r λ ( x ) . Lemma 2: Let λ ∈ [0 , 1] and X = ( X 1 , · · · , X k ) be distributed according to distribution r λ ( x ) . Then, E [ d ( X )] ≤ 1 − 1 e (1 − λ ) . (40) Pr oof: By the definition of X , exactly ⌈ λk ⌉ entries of X are associated with a draw without replacement, and therefore are guaranteed to not be inv olv ed in any collision. The remaining k − ⌈ λk ⌉ entries of X are mapped randomly to the remaining k − ⌈ λk ⌉ elements in the urn. Therefore, in expectation, the expected number of collisions is bounded from abov e as 1 − 1 e ( k − ⌈ k λ ⌉ ) ≤ k 1 − 1 e (1 − λ ) . Lemma 3: Let λ ∈ [0 , 1] and X = ( X 1 , · · · , X k ) be distributed according to the distribution r λ ( x ) . Then, H ( X ) ≥ k log ( k ) − λk log( e ) + λk log 1 − λ − 1 /k 2 1 − λ − 1 /k 2 − 1 − 1 e (1 − λ − 1 /k ) ! . (41) Pr oof: T o lower bound H ( X ) , we use the intermediate random v ariables Y , which are the values of X prior to being randomly permuted. The idea is to first bound H ( Y ) , then bound the dif ference H ( X ) − H ( Y ) . For H ( Y ) , we can use Stirling’ s approximation to show that H ( Y ) = log k w w ! + ( k − w ) log( k − w ) (42) ≥ k log( k ) − w log ( e ) , (43) where w = ⌈ λk ⌉ . Next, we wish to lo wer bound the dif ference H ( X ) − H ( Y ) , which is the entropy increase attributed to randomly permuting Y . Let v : [ k ] k → { 0 , 1 } k be the collision indicator function, i.e., giv en x ∈ [ k ] k , v ( x ) i = 1 if and only if there exists a j = i such that x i = x j . Notice that H ( X ) − H ( Y ) = H ( X , v ( X )) − H ( Y , v ( Y )) (44) = H ( X | v ( X )) − H ( Y | v ( Y )) + H ( v ( X )) − H ( v ( Y )) . (45) W e claim that H ( X | v ( X )) = H ( Y | v ( Y )) . W e omit a formal proof and provide some intuition instead. Observe that the conditional probability Pr( X = x | v ( X ) = v ) depends only on the weight of v , and not the ordering. This, along with Bayes’ rule, can be used to show that Pr( X = x | v ( X ) = v ) is equal to Pr( Y = y | v ( Y ) = v ) for all v such that Pr( v ( Y ) = v ) > 0 . This implies that the conditional entropies are equal and hence H ( X ) − H ( Y ) = H ( v ( X )) − H ( v ( Y )) . (46) Let D = wt( v ( X )) , where wt( · ) denotes the weight func- tion. Since X is a permutation of Y , D = wt( X ) = wt( Y ) , which implies that H ( v ( X )) − H ( v ( Y )) = H ( v ( X ) | D ) − H ( v ( Y ) | D ) . (47) Conditioned on D , the sequence X is uniformly distributed ov er binary strings of weight D , and Y is uniformly distributed ov er strings of weight D which begin with w zeros. Using this fact and along with multiple applications of Jensen’ s inequality , we get H ( v ( X ) | D ) − H ( v ( Y ) | D ) = E log k D − E log k − w D (48) = E " w − 1 X i =0 log k − i k − i − D # (49) ≥ E w log k − w − 1 2 k − w − 1 2 − D (50) ≥ λk log 1 − λ − 1 /k 2 1 − λ − 1 /k 2 − 1 − 1 e (1 − λ − 1 /k ) ! . (51) The last line follo ws from the fact that w ≥ λk and E [ D ] ≥ k 1 − 1 e (1 − λ − 1 /k ) . Combining (51) with (42) yields the desired result. T ogether with Lemmas 2 and 3, Lemma 1 immediately implies the following upper bounds on L ∗ ( n, k , α ) and R ∗ ( α ) . Theor em 1: Consider the problem of minimal α -perfect hashing. For fixed n and k , the optimal representation length and optimal amortized representation length for α -perfect hashing are bounded from abov e as L ∗ ( n, k , α ) ≤ λ ( α ) k log ( e ) − λ ( α ) k log 1 − λ ( α ) − 1 /k 2 1 − λ ( α ) − 1 /k 2 − 1 − 1 e (1 − λ ( α ) − 1 /k ) ! + O (log k ) (52) and R ∗ ( α ) ≤ λ ( α ) log ( e ) − λ ( α ) log 1 − λ ( α ) 2 1 − λ ( α ) 2 − 1 − 1 e (1 − λ ( α )) ! , (53) respectiv ely , where λ ( α ) = α − 1 /e 1 − 1 /e + . (54) For a comparison between the results of Theorem 1 and the bound (24) achieved through randomizing between minimal perfect and zero-bit hashing, refer to Figure 1. V I . C O N C L U S I O N This paper introduces the problem of α -perfect hashing, an extension of minimal perfect hashing to the approximate setting, where we require only that an α -proportion of keys be hashed without collision rather than all. W e present two different α -perfect hashing schemes and analyze their re- spectiv e space requirements. The first scheme randomizes between minimal perfect and zero-bit hashing. The second lev erages results from sampling theory to develop an α -perfect hashing scheme which significantly improv es upon the space requirement of the aforementioned scheme for all α . R E F E R E N C E S [1] H.-P . Lehmann, T . Mueller, R. Pagh, G. E. Pibiri, P . Sanders, S. V igna, and S. W alzer, “Modern minimal perfect hashing: A survey , ” 2026. [Online]. A vailable: https://arxiv .org/abs/2506.06536 [2] N. Abramson, “Development of the alohanet, ” IEEE Tr ans. Inf. Theory , vol. 31, no. 2, pp. 119–123, 1985. [3] J. Kang and W . Y u, “Minimum feedback for collision-free scheduling in massi ve random access, ” IEEE T r ans. Inf . Theory , vol. 67, no. 12, pp. 8094–8108, 2021. [4] ——, “Scheduling versus contention for massive random access in massiv e mimo systems, ” IEEE T rans. Commun. , vol. 70, no. 9, pp. 5811– 5824, 2022. [5] R. Song, K. M. Attiah, and W . Y u, “Coded downlink massive random access and a finite de finetti theorem, ” IEEE T r ans. Inf. Theory , vol. 71, no. 9, pp. 6932–6949, 2025. [6] R. Song and W . Y u, “Downlink massi v e random access with lossy source coding, ” in 2025 IEEE International Symposium on Information Theory (ISIT) , 2025, pp. 1–6. [7] M. L. Fredman and J. Komlós, “On the size of separating systems and families of perfect hash functions, ” SIAM J ournal on Algebraic Discrete Methods , vol. 5, no. 1, pp. 61–68, 1984. [8] J. Körner, “Fredman–Komlós bounds and information theory , ” SIAM Journal on Algebraic Discrete Methods , vol. 7, no. 4, pp. 560–570, 1986. [9] J. K orner and K. Marton, “Ne w bounds for perfect hashing via infor- mation theory , ” Eur opean Journal of Combinatorics , vol. 9, no. 6, pp. 523–530, 1988. [10] D. Belazzougui, F . C. Botelho, and M. Dietzfelbinger, “Hash, displace, and compress, ” in Algorithms - ESA 2009 , A. Fiat and P . Sanders, Eds. Berlin, Heidelberg: Springer Berlin Heidelberg, 2009, pp. 682–693. [11] H.-P . Lehmann, P . Sanders, and S. W alzer , “Shockhash: T owards optimal-space minimal perfect hashing beyond brute-force, ” in 2024 Pr oceedings of the Symposium on Algorithm Engineering and Exper - iments (ALENEX) , 2024, pp. 194–206. [12] C. T . Li and A. El Gamal, “Strong functional representation lemma and applications to coding theorems, ” IEEE T rans. Inf. Theory , vol. 64, no. 11, pp. 6967–6978, 2018. [13] P . Harsha, R. Jain, D. McAllester, and J. Radhakrishnan, “The com- munication complexity of correlation, ” in T wenty-Second Annual IEEE Confer ence on Computational Complexity (CCC’07) , 2007, pp. 10–23.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment