POLCA: Stochastic Generative Optimization with LLM
Optimizing complex systems, ranging from LLM prompts to multi-turn agents, traditionally requires labor-intensive manual iteration. We formalize this challenge as a stochastic generative optimization problem where a generative language model acts as …
Authors: Xuanfei Ren, Allen Nie, Tengyang Xie
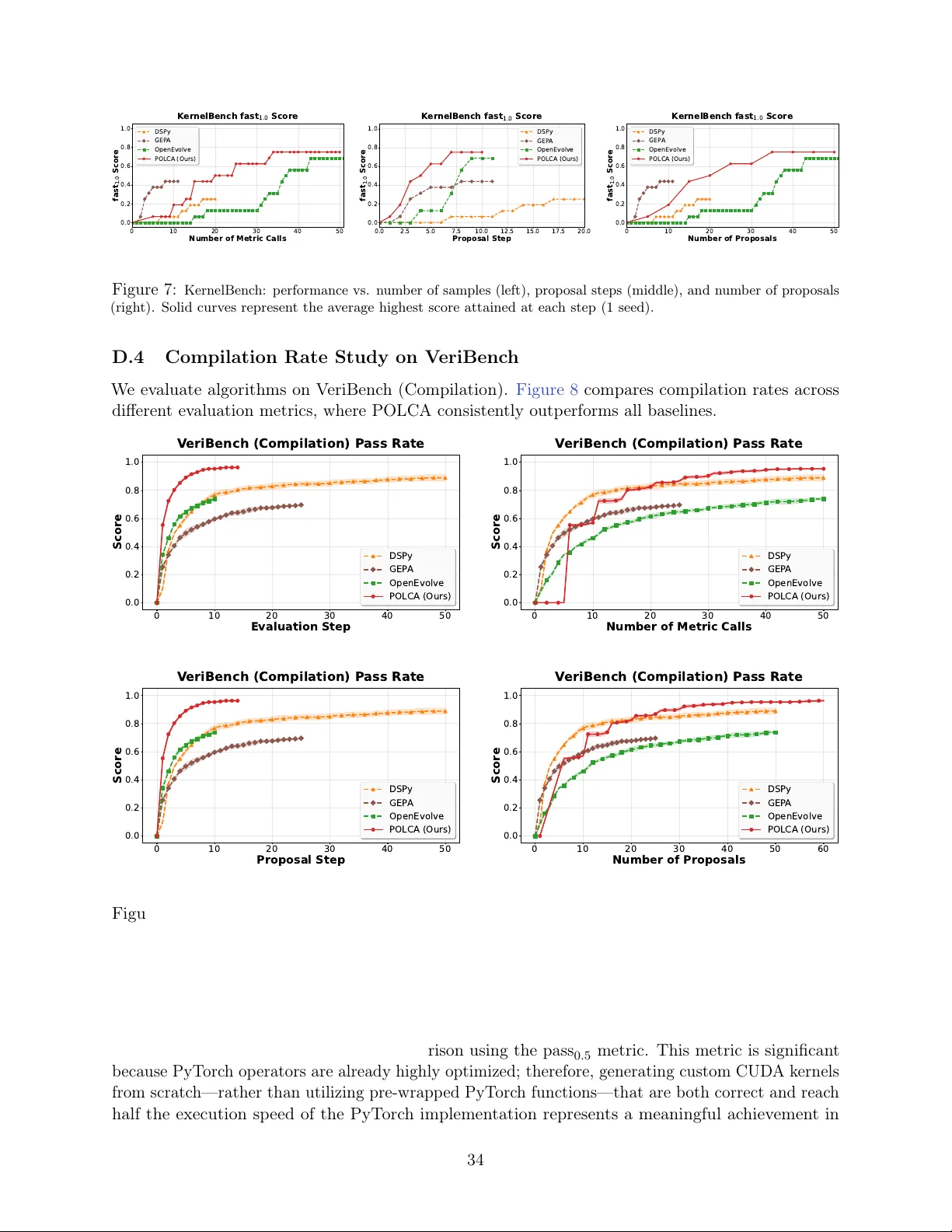
POLCA: Sto c hastic Generativ e Optimization with LLM Xuanfei Ren Univ ersity of Wisconsin-Madison Madison, WI xuanfeiren@cs.wisc.edu Allen Nie Go ogle DeepMind Moun tain View, CA allennie@google.com T engy ang Xie ∗ Univ ersity of Wisconsin-Madison Madison, WI tx@cs.wisc.edu Ching-An Cheng ∗ Go ogle Researc h Kirkland, W A chingan@google.com Abstract Optimizing complex systems, ranging from LLM prompts to m ulti-turn agents, traditionally requires lab or-in tensiv e manual iteration. W e formalize this challenge as a stochastic generativ e optimization problem where a generativ e language mo del acts as the optimizer, guided by n umerical rewards and text feedbac k to disco ver the b est system. W e introduce P rioritized O ptimization with L o cal C ontextual A ggregation (POLCA), a scalable framework designed to handle sto c hasticity in optimization—such as noisy feedback, sampling minibatches, and sto c hastic system b eha viors—while effectiv ely managing the unconstrained expansion of solution space. POLCA maintains a priorit y queue to manage the exploration-exploitation tradeoff, systematically tracking candidate solutions and their ev aluation histories. T o enhance efficiency , w e integrate an ε -Net mec hanism to maintain parameter div ersity and an LLM Summarizer to p erform meta-learning across historical trials. W e theoretically prov e that POLCA conv erges to near-optimal candidate solutions under sto c hasticity . W e ev aluate our framework on diverse b enc hmarks, including τ -b enc h, Hotp otQA (agent optimization), V eriBenc h (co de translation) and KernelBench (CUDA k ernel generation). Experimental results demonstrate that POLCA ac hieves robust, sample and time-efficien t p erformance, consistently outp erforming state-of-the- art algorithms in b oth deterministic and sto chastic problems. The co debase for this work is publicly av ailable at https://github.com/rlx- lab/POLCA . 1 In tro duction Optimizing complex systems – from large language mo del (LLM) prompts to co de generators to m ulti-turn agents – traditionally requires manual iteration by domain exp erts. Recen tly , generative optimization algorithms ha ve demonstrated successes in automating this pro cess and ha v e been applied to scientific discov ery , co de revision, and end-to-end system optimization ( Cheng et al. , 2024 ; Novik ov et al. , 2025 ; Agra wal et al. , 2025 ). The solution to each of these problems can b e view ed as a parameterized computer program. 1 Generativ e optimization is a pro cess in which a ∗ Corresp onding authors. 1 The term p ar ameter is used here to distinguish the changeable part of a program, as defined b y the programmer. In the most general case, the en tire program can b e treated as a parameter. 1 θ θ θ LLM Optimizer θ 2 θ 1 θ 3 Reject Memory Summarize F Feedback Eval(θ, x) θ 1 C F Samper minibatch x accept Filtering Eval(θ 1 , x) θ θ θ θ 3 θ 2 Select Parameter Proposal ε-Net Mechanism Dataset Step 0 1 Normalized score GEP A OpenEvolve POLCA (Ours) Figure 1: Left : The POLCA framew ork for generative optimization. POLCA maintains a memory buffer as an ε -Net to ensure diverse program storage. In eac h iteration, it selects promising parameter candidates from the ε -Net, ev aluates them against a sampled minibatch, and generates new candidate parameters based on the feedbac k. These candidates undergo a seman tic Filtering stage; accepted parameters are ev aluated on the minibatc h and integrated in to the ε -Net. Finally , a Summarize step compresses the memory to pro vide concise global context C for the next optimization cycle. Right : Normalized p erformance av eraged across b enchmarks ( τ -Benc h, Hotp otQA, V eriBench, and KernelBenc h). The solid curve represents the mean, while the shaded region indicates the standard error across all benchmarks. Results are aggregated by standardizing scores and computational budgets to a scale of [0 , 1] . generativ e mo del, typically an LLM, mo difies the parameter(s), v alidates the mo dification, and then further revises it using feedback from v alidation. This pro cess is rep eated for many iterations, either sequen tially or under the co ordination of a search algorithm, and the feedback can take the form of n umerical scores, text, or multimodal signals such as images, video, or audio. When provided with the righ t feedback ( Pryzant et al. , 2023 ; Chen et al. , 2024 ; Xu et al. , 2025 ), generativ e optimization algorithms can significantly sp eed up the optimization pro cess compared with black-box algorithms that uses reward or preference as the only learning signals ( Huang et al. , 2023 ; W ei et al. , 2024 ; Agra wal et al. , 2025 ). Nonetheless, optimization instability and plateaus hav e also b een rep orted, suc h as LLM rep eating the same mistak es multiple times ( Kumar et al. , 2024 ; Chen et al. , 2024 ). The limitation arises when the LLM as the optimizer do es not observe sufficien t information from feedbac k to deriv e an impro vemen t direction of the parameter. This problem is exacerbated when it is costly to obtain a lo w-v ariance estimation of the parametrized program’s p erformance is exp ensive, either b ecause the environmen t is sto c hastic or b ecause feedbac k from humans or ultra-large LLMs is costly . The former o ccurs when the program must b e ev aluated many inputs or tasks to estimate its a verage p erformance, or when the program itself exhibits inheren t sto c hastic b ehaviors. In such cases, obtaining high-quality feedback requires multiple ev aluations, which can b e to o exp ensiv e to p erform at ev ery optimization step. Therefore, optimization often relies on sto c hastic estimates from only a few ev aluations. On the other hand, language feedbac k from LLM judges or human users ma y b e noisy and sub jectiv e, making optimization difficult when the feedbac k is inconsistent or highly v ariable. These c hallenges b ecome even more severe when an LLM is used as the optimizer ( Y ang et al. , 2023 ; Nie et al. , 2024 ). Sto c hastic v ariation can cause the optimizer to generate many semantically similar parameters, so the search space grows linearly while semantically useful information do es not ( Shi et al. , 2022 ; Li et al. , 2022 ; W ang et al. , 2025a ; Lange et al. , 2025a ). V erifying these redundant programs requires additional ev aluations, making generative optimization exp ensiv e to scale. T ake optimizing an LLM agent as an example, where the parameter may b e its system prompt or orc hestration co de. The agent needs handle a v ariety of task requests, and yet running the agent with eac h task takes minutes; therefore, only a subset of tasks can b e used at a time for making an up date in optimization. The feedback is likely generated by querying another LLM (using privileged task information or execution trace) ( Y ao et al. , 2024 ; Lin et al. , 2024 ; W u et al. , 2025 ), which can lead to sto c hastic ev aluation and feedback. Lastly , the agent itself is sto c hastic as well b ecause of the 2 use of LLM inside. Other applications ma y manifest only a subset of these sources of sto c hasticity . F or example, if the outcome of the program is verifiable by a computer script, then the scoring can b e deterministic. If the inputs to the program can b e efficiently enumerated (such as a small set of unit tests), then sampling is not necessary . How ever, not all tasks are verifiable and LLM-as-a-Judge is getting more common ( Zheng et al. , 2023 ; Gu et al. , 2024 ; Lee et al. , 2025a ). In addition, running the program for all inputs is not alw ays practical when problems get more complex, since such full batc h up date requires linear complexit y p er optimization step. It is desirable that algorithms can up date based on sampled minibatches. In this work, we introduce P rioritized O ptimization with L o cal C on textual A ggregation (POLCA), a scalable framework for sto c hastic generative optimization with LLMs ( Figure 1 ). Under mild assumptions on LLM capabilities, we sho w that an em b edding-based memory mechanism with an accept/reject rule, which w e call the ε -Net criterion, can address tw o primary limitations of generative optimization: parameter up date instability and ev aluation sto c hasticit y . This mechanism naturally b ounds the total num b er of parameters that need to b e ev aluated. Without the ε -Net criterion, an LLM optimizer ma y contin ue prop osing new parameters indefinitely , resulting in unbounded ev aluation costs. Sufficien t exploration of the parameter space is controlled b y ε , which dictates a co verage-cost tradeoff, sp ecified by the user. The core of our metho d is a reward-free embedding for each parameter that captures signals ab out the true underlying reward without o verfitting to noisy empirical rewards. W e argue that such embeddings are increasingly a v ailable in mo dern LLMs and that they are essential for building robust and scalable generativ e optimization algorithms ( Lee et al. , 2025b ). Incorp orating search into generativ e optimization is common. How ever, regardless of the underlying algorithm, suc h as evolutionary search ( No viko v et al. , 2025 ), m ulti-candidate P areto fron tier searc h ( Agraw al et al. , 2025 ), or b eam search ( Pryzant et al. , 2023 ), existing metho ds often assume an effectiv ely unlimited ev aluation budget and do not explicitly address ev aluation sto c hasticit y . In con trast, POLCA uses embeddings to construct an ε -Net that a voids ov erfitting to noisy ev aluations and decides whether a new parameter is sufficien tly no v el to ev aluate. This mechanism yields a search pro cess that is robust to sto chasticit y: it av oids discarding candidates to o early while naturally b ounding the num b er of distinct programs in the pro cess. Prior work has also used filtering to promote nov elty . F or example, AlphaCo de ( Li et al. , 2022 ) uses test-based filters, and Shink aEvolv e ( Lange et al. , 2025a ) uses em b edding-based filtering. Ho wev er, these c hoices are empirically motiv ated. W e show that an embedding-based mechanism is theoretically necessary for efficien t generative optimization under ev aluation sto chasticit y and finite compute. Theoretically , w e analyze POLCA with the UCB score as the priority function for ranking candidate parameters, which enables prov ably systematic exploration. Under the assumption that the optimizer can achiev e strict improv ement within a certain rew ard range, we prov e that POLCA even tually con verges to near-optimal candidates under sto c hasticity . The conv ergence rate is primarily influenced b y tw o factors: the efficiency of the optimization oracle, which captures the capability of the optimizer LLM, and the sto c hasticity of the ev aluations, which is determined b y the task. The former determines the num b er of iteration steps required to prop ose a near-optimal candidate, while the latter determines the n umber of samples necessary to accurately estimate the reward for each accepted candidate. W e conduct exp erimen ts to v alidate our algorithm across v arious sources of sto chasticit y . In τ - b enc h ( Y ao et al. , 2024 ), w e optimize a to ol-use LLM agent’s prompts for multi-step problems. POLCA effectively handles sto c hasticity arising from b oth mini-batc hing and the agent’s in ternal randomness, improving p erformance o ver multiple held-out tasks. It also ac hieves sup erior results in Hotp otQA ( Y ang et al. , 2018 ) prompt optimization. In formal v erification (V eriBench) ( Miranda 3 et al. , 2025 ), w e test POLCA’s abilit y to learn from compilation signals and stochastic LLM feedbac k when translating Python programs into Lean 4 co de. W e also v alidate POLCA in a deterministic setup using KernelBench ( Ouy ang et al. , 2025 ) to optimize CUDA kernel co de. Across all b enc hmarks, POLCA consisten tly outp erforms state-of-the-art baselines, GEP A ( Agraw al et al. , 2025 ) and Op enEvolv e ( Sharma , 2025 ) – an op en-source implementation of AlphaEvolv e ( Novik o v et al. , 2025 ), in b oth conv ergence sp eed and final p erformance. W e additionally verify that parametric rew ard mo deling via an ensem ble is prone to ev aluation sto c hasticit y . This highlights the need to use a p ersisten t memory mechanism suc h as ε -Net to ensure a robust and principled framework for scaling LLM optimizers in the face of sto chasticit y . 2 Problem Setup The optimization problem of a complex systems using generative mo dels can b e form ulated as an abstract problem, which we call sto chastic gener ative optimization of a parameterized program P θ . Our goal is to design a scalable algorithm to automate this pip eline and to address the instability caused b y sto c hasticity in sampling inputs, ev aluations, and the program itself. While our primary fo cus in the exp erimen ts will b e on prompt and co de optimization, as we will show b elo w, this form ulation is generic and extends to broader domains including general discrete structures and functional solutions. T raditionally these tasks relied on a manual exp ert lo op where h uman researc hers iterativ ely refined parameters. By treating these systems as programs with parameters, w e take a unified approac h to handle sto c hasticity inherent in trial-and-error cycles. Problem F orm ulation W e denote a sto c hastic generativ e optimization problem as a tuple { P , θ 0 , D , Θ , G , O } . The parameterized program P θ is a mapping that takes input x and returns output y ∼ P θ ( x ) 2 . W e aim to change parts of the program θ whic h we call the p ar ameter . The parameter can include numerical v alues, text strings, co des, or a mixture of them. W e denote θ 0 as the initial parameter, whic h can b e a placeholder, and let Θ represent all p ossible program parameters. Our goal is to improv e the program’s p erformance on a data distribution D . Each data ( x, ω ) ∼ D con tains an input x to the program and some asso ciated side information ω . Given ( ω , x, y ) , there is an oracle G , which we call the guide , to provide a n umerical score r ∈ R and feedbac k f (e.g., error messages, critiques, or gradients) (with sto c hasticit y) to guide the optimization pro cess. In other words, the score r and feedback f implicitly encapsulate the optimization ob jectiv e, just as gradien ts in first-order optimization. Lastly , we supp ose there is an LLM Optimizer O that can prop ose new parameters after seeing ( θ , x, y , r , f , c ) , where c denotes additional context ab out the optimization problem (which may include with ω ). This LLM Optimizer acts as an oracle to prop ose new candidate parameters θ ′ ∈ Θ by in terpreting the guide’s feedback, but we do not assume θ ′ w ould alwa ys b e b etter than θ . F ailure to improv e ma y b e due to the lack of information in ( θ , x, y , r , f ) or due to the sto chasticit y of the LLM Optimizer. Ev aluation and Ob jective The p erformance of a program P θ parameterized by θ is characterized b y its exp ected reward µ ( θ ) , defined as: µ ( θ ) = E ω ,x ∼D E y ∼ P θ ( x ) [ G r ( ω , y , x )] , where G r denotes the score r returned b y the guide. Given a computational resource budget (e.g., wall-clock time or n umber of ev aluation metric calls), we wish to design an algorithm Alg to maximize the exp ected rew ard of the selected agent: max Alg E [ µ ( θ best )] , where θ best denotes the b est parameter Alg returns, and the exp ectation is taken o ver the joint sto c hasticit y of the data sampling of D , the program 2 The program can b e a constant function of the parameter, i.e., P θ ( x ) ≡ θ , provided the entire program structure is sub ject to mo dification during the optimization pro cess. 4 P and the LLM optimizer O , the noisy ev aluations provided by the guide G , and the inherent randomness of the algorithm Alg . The algorithm needs to co ordinates the in teractions b etw een the dataset D , the guide G , and the LLM optimizer O to balance b et ween exploring nov el parameters and accurately iden tifying high-p erforming candidates amidst sto chastic v ariations due to them. Expansiv e Searc h Space One imp ortan t property is that the parameter space Θ is often exp onen tially large and discrete without a natural ordering (e.g., the space of all v alid Python programs). This prop ert y makes this optimization setting differ significan tly from standard scenarios suc h as finite-arm bandits, where a learner either has access to the full action set up front. In con trast, the action space (namely the parameter space) here can only b e accessed through querying the LLM optimizer O , and the prop osal distribution of the LLM optimizer is highly dep enden t on the sp ecific information in ( θ , x, y , r , f , c ) provided at each iteration. Consequen tly , to effectively optimize, w e also need to select meaningful impro ving parameter θ and data x , curate go o d context c (e.g., by integrating historical ev aluations and feedback) in order to steer the LLM optimizer to ward generating increasingly sup erior candidates. 3 Algorithm In this pap er, we design a generative optimization algorithm, P rioritized O ptimization with L o cal C on textual A ggregation (POLCA), whic h utilizes a con tinuously up dated memory and an ε -Net criterion to handle sto c hasticit y from program ev aluations. The optimization pro cedure is formally presen ted in Algorithm 1 . W e maintain a priority queue Q —initialized with the base program θ 0 —whic h functions as a memory and is contin uously up dated with empirical results. Eac h iteration of the optimization lo op b egins by sampling a minibatc h B ⊂ D via SampleMiniba tch and selecting a subset of the empirically b est-performing programs, Θ explore ⊂ Q , via SelectPr ograms . W e then collect data S b y ev aluating each θ ∈ Θ explore on B ; these results are used to directly up date the p erformance statistics in Q . Subsequen tly , w e inv ok e ProposePr ograms , in which the optimizer O utilizes the newly collected data S , in conjunction with a broader context c history , to prop ose a set of raw program parameters Θ raw . Here, c history is pro vided by another external LLM comp onen t called the Summarizer , which pro cesses the en tire up dated priorit y queue Q to generate high-lev el optimization instructions for the optimizer O . T o preven t the memory Q from b eing o verwhelmed by seman tically similar candidates, Θ raw is filtered through an ε -Net-based SemanticFil ter op eration to obtain Θ new . This filtering mechanism constrains the size of the parameter space within Q while ensuring structural and semantic diversit y . Finally , the candidates in Θ new are ev aluated on the same minibatc h B to obtain initial p erformance estimates b efore b eing added to the memory . In the follo wing sections, we elab orate on the sp ecific mechanics of each comp onen t and their contributions to the optimization pro cess. Minibatc h Ev aluation The scale of the dataset D presen ts a primary b ottlenec k, when doing a full ev aluation of P θ in every iteration is computationally out of reach. This mak es obtaining a precise, reliable score prohibitively exp ensive for every generated candidate. Instead, minibatch sampling is emplo yed to estimate the p erformance of proposed programs and pro vide v aluable feedbac k for further optimization. W e implement a SampleMiniba tch pro cess in POLCA, where in eac h iteration, a minibatc h of tasks B = { ( ω i , x i ) } B i =1 is randomly sampled from the dataset D with replacemen t. A program P θ ev aluated on B yields sto chastic observ ations { ( θ , ω i , x i , y i , r i , f i ) } B i =1 . The sto c hasticity in the scores of P θ arises from the minibatc h sampling, the program execution, and the guide ev aluation, as discussed in Section 2 . The same minibatch ev aluation is p erformed for 5 b oth Θ explore and the newly prop osed Θ new to ensure a fair comparison, thereby mitigating p oten tial bias arising from task-sp ecific v ariance. Both ev aluation pro cesses are fully parallelized 3 , whic h we elab orate on further in Algorithm 2 in Section B . Algorithm 1 POLCA Require: Dataset D , base agent θ 0 , Guide G , Optimizer O Ensure: Best program θ best iden tified during search 1: Initialize: Q ← { θ 0 } 2: while Budget not exhausted do 3: B ← SampleMiniba tch ( D ) 4: Θ explore ← SelectPrograms ( Q ) 5: S ← Ev alua te (Θ explore , B , G ) 6: Q ← Upda teSt a ts ( Q , S ) 7: Θ raw ← ProposePr ograms ( O , S , Q ) 8: Θ new ← SemanticFil ter (Θ raw , Q ) 9: S ← Ev alua te (Θ new , B , G ) 10: Q ← Upda teSt a ts ( Q , S ) 11: end while 12: return θ best ∈ Q with the highest empirical mean score Priorit y Queue Memory T o handle the sto c hasticit y inherent in program ev aluation, we maintain Q as a priority queue . F or each program θ ∈ Q , w e assign an exploration priority derived from its data. Sp ecifically , for a program θ with data { ( θ , w n , x n , y n , r n , f n ) } N n =1 , we define the priority as the empirical mean score 4 : p explore ( θ ) = 1 N P N n =1 r n . T o identify programs for impro vemen t at the start of eac h iteration of POLCA, we inv oke Θ ← SelectPrograms ( Q ) to retrieve the candidates with the highest p explore . During the optimization pro cess, newly collected data S = { ( θ , w, x, y , r , f ) } is in tegrated via Q ← Upda teSt a ts ( Q , S ) . This function up dates the priorities for all relev ant θ ∈ Q and reorders the queue to facilitate efficient exploration. This arc hitecture directly addresses the three sources of sto c hasticity by contin uously up dating the dynamic priority queue Q . Under this design, program P θ with sup erior empirical p erformance are ev aluated consecutively , and p explore ( θ ) even tually conv erges to the true exp ected reward µ ( θ ) as v ariance is a veraged out. This design ensures that promising candidates with temp orarily low empirical means can b e revisited and refined later, while those with low p otential are even tually deprioritized after sufficien t sampling. Generativ e P arameter Space Gro wth W e assume our generativ e optimizer oracle O has a prop osal distribution Π( · | C ) , where C represen ts the input context. T o enhance the optimization tra jectory , w e first utilize an external LLM called the Summarizer to aggregate the history of successes and failures from Q in to a c history , providing high-level context for the optimizer. Then, for eac h program parameter θ ∈ Θ explore , the optimizer is inv ok ed using the minibatch collected in this iteration, S θ = { ( θ , ω i , x i , y i , r i , f i ) } B i =1 , augmented by c history to synthesize information from previous iterations. In this formulation, utilizing only the current minibatc h S θ is analogous to a 3 When program execution or guide ev aluation rely heavily on LLM calls, this parallelization b ecomes significantly more efficien t, as the parallelization of LLM API calls can b e easily implemented. 4 In particular, if the empirical mean is slightly modified to a UCB score, we can obtain a theoretically guaranteed result ( Section 4 ). Other priority functions could b e utilized to realize alternative search strategies ( Section C ). 6 standard first-or der up date in numerical optimization. By incorp orating c history from the Summarizer, the pro cess mirrors Momentum-b ase d metho ds ( Cui et al. , 2024 ), lev eraging the tra jectory of past ev aluations to stabilize the search and escap e lo cal optima. In parallel, the optimizer analyzes the lo cal context S θ and the global summary c history to prop ose a candidate θ ′ designed to ac hieve sup erior p erformance: θ ′ ∼ Π( · | C θ ) , where C θ = { ( θ , x i , y i , r i , f i , c history ) } B i =1 . W e collect the prop osed program parameters as Θ raw . A more detailed description of the program generation pro cess can b e found in Algorithm 3 and Section B . Seman tic Filtering based on ε -Net While we tackle the sto c hasticity of individual program ev aluations by a contin uously up dated memory Q , indiscriminately adding all new programs to the memory would cause Q to grow linearly with the num b er of iterations. This gro wth can lead to prohibitiv e sample complexit y when attempting to iden tify the b est program. This can b e a voided, b ecause the input context to O often exhibits comparatively low v ariance. This is due to 1) minibatches may ov erlap or rep eat, and 2) sp ecific programs (or highly similar ones) are rep eatedly selected for exploration. Consequen tly , LLM-based optimizers tend to prop ose man y semantically similar parameters o ver time, meaning the growth of useful information in Q do es not scale at the same rate as the n umber of programs. T o navigate this complexit y , we leverage the laten t semantic structure of the parameter space to discretize Θ . Let ϕ : Θ → R d b e an embedding function that maps parameters into a dense vector space. W e then define a semantic distance metric ˜ d ( θ , θ ′ ) = ∥ ϕ ( θ ) − ϕ ( θ ′ ) ∥ 2 to measure the semantic similarit y b et ween any tw o parameters θ , θ ′ ∈ Θ . All newly generated program parameters θ ′ ∈ Θ raw are subsequen tly pro cessed by the SemanticFil ter comp onen t. This comp onen t ensures that the priority queue Q is maintained as an ε -Net, such that any tw o programs in memory maintain a distance greater than ε . A new program parameter is admitted only if its semantic distance to ev ery existing parameter in Q exceeds ε , thereb y pruning redundan t prop osals and maintaining p opulation diversit y . The diversit y within Q also facilitates the retriev al of a high-qualit y historical con text c history , as a more semantically diverse Q pro vides a more representativ e set of observ ations to the Summarizer. Detailed implementation of this filtering pro cess is pro vided by Algorithm 4 in Section B . 4 Theoretical Analysis In this section, we theoretically analyze POLCA ( Algorithm 1 ). F or clarity , w e analyze a version of the algorithm that, in each iteration, selects only one program to gather observ ations and prop oses only one new program. Unlik e the implemen tation in Section 3 , this version selects the program with the highest UCB score rather than the empirical mean; such optimistic exploration is standard in online learning theory . Assume the reward function µ : Θ → [0 , B ] . F or any program θ ∈ Θ , we assume the score observ ation r ( θ ) is sampled from a σ 2 sub-Gaussian distribution with mean µ ( θ ) . W e analyze the following simplified version of POLCA: The optimization pro cess starts with the original program θ 0 . Let n b e the time horizon. At each step t , let T θ ( t ) denote the n umber of reward observ ations for program θ , and b µ θ,s denote the empirical mean of program θ o ver the first s observ ations. The algorithm calculates UCB scores based on ( 1 ) for all current programs: U C B θ ( t ) = b µ θ,T θ ( t ) + 2 σ s log( n ) T θ ( t ) . (1) 7 It then selects the program θ with the highest UCB score to obtain a rew ard observ ation r ( θ ) . The optimizer prop oses a new program θ ′ based on the lo cal observ ation C θ . If θ ′ passes the semantic filtering based on ε -Net, it is ev aluated once to obtain a reward observ ation r ( θ ′ ) . By the design of the ε -Net filtering mec hanism, the total num b er of distinct programs ev aluated during the pro cess is b ounded. W e use N ε (dep ending only on the program space Θ and ε ) to denote this upp er b ound, whic h is used in the subsequent analysis. W e in tro duce Assumption 1 , whic h assumes the optimizer has the abilit y to mak e a γ -strict impro vemen t with p ositiv e probability , pro vided the seed program θ satisfies µ ( θ ) ∈ [0 , B − γ ] . Assumption 1 (Strict improv ement) . Ther e exist c onstants γ > 0 and δ 0 ∈ (0 , 1) . F or any θ ∈ Θ with µ ( θ ) ≤ B − γ , we assume the optimization or acle satisfies: P θ ′ ∼ Π( ·|C θ ) [ µ ( θ ′ ) > µ ( θ ) + γ ] ≥ δ 0 . Based on Assumption 1 , in this generative optimization problem, we only hav e control ov er improving programs with rewards in [0 , B − γ ] , whereas w e lac k a guaran tee from the given optimizer for prop osing b etter programs when the seed program has a reward in the range ( B − γ , B ] . Let Θ t ⊂ Θ denote the set of programs accepted during the first t iterations. Theorem 1 demonstrates that POLCA with a UCB priority function con verges to near-optimal programs with rewards in [ B − γ , B ] , whic h the optimizer cannot b e guaran teed to improv e further. Theorem 1. Supp ose µ : Θ → [0 , B ] . If we run POLCA with the UCB priority define d in ( 1 ) for n iter ations, then the exp e cte d total numb er of sele ctions for pr o gr ams with r ewar ds in [0 , B − γ ] is b ounde d by E X θ ∈ Θ n : µ ( θ ) ≤ B − γ T θ ( n ) ≲ B 2 γ δ 0 + 64 σ 2 N ε γ 2 log( n ) . (2) When the r ewar d observations ar e deterministic ( σ = 0 ), the b ound b e c omes indep endent of the pr o gr am sp ac e and dep ends only on the r ewar d sp ac e and the optimization or acle: E X θ ∈ Θ n : µ ( θ ) ≤ B − γ T θ ( n ) ≲ B log( n ) 2 γ δ 0 . W e provide the complete pro of of Theorem 1 in Section A , but w e can intuitiv ely in terpret the tw o terms in the upp er b ound ( 2 ) . The first term, B log ( n ) / 2 γ δ 0 , represents the num b er of iterations required to generate a near-optimal program with reward in [ B − γ , B ] under the uncertaint y of the optimizer, as describ ed in Assumption 1 . The second term, with order O ( σ 2 N ε log ( n ) /γ 2 ) , is the n umber of samples needed to estimate the exp ected reward of each program given sto c hastic observ ations. In the deterministic case, only one sample is needed to determine the rew ard of each program θ , so the second term v anishes. Theoretical analysis highlights the adv an tages of POLCA in main taining a comprehensive historical record of all programs. Sp ecifically , our ε -Net-based semantic filter prev ents the memory buffer from gro wing linearly by rejecting semantically redundant candidates, ensuring the search remains scalable. A naive implementation of generative optimization t ypically relies on sequential up dates, where each iteration ev aluates a single program to prop ose its successor. Belo w, we compare these algorithms with POLCA under the assumption of deterministic reward observ ations, where the algorithm 8 has access to µ ( θ ) for each generated θ . F ormally , at each step t , a se quential up dating algorithm generates a new program prop osal based on the most recent observ ation: θ ′ t ∼ Π( · | C θ t − 1 ) . (3) In con trast, POLCA up dates b y improving up on the b est program found th us far: θ ′ t ∼ Π( · | C ˜ θ t ) , where ˜ θ t : = argmax θ ∈ Θ t µ ( θ ) . (4) Theorem 2 compares the rates at which up dating rules ( 3 ) and ( 4 ) yield a near-optimal program. Theorem 2. Supp ose µ : Θ → [0 , B ] and the r ewar d observation is deterministic. Under Assumption 1 , the exp e cte d numb er of steps for a se quential up dating algorithm ( 3 ) to pr op ose a pr o gr am with r ewar d in ( B − γ , B ] is O (1 /δ B /γ 0 ) . In c ontr ast, POLCA with up dating rule ( 4 ) r e quir es B / ( γ δ 0 ) exp e cte d steps to r e ach the same thr eshold. The pro of of Theorem 2 is provided in Section A.4 . By using the historical maxim um, POLCA main tains a monotonically non-decreasing reward baseline. This ensures the algorithm is robust to the sto c hasticit y of the optimizer, as p o or prop osals cannot reset its progress. 5 Exp erimen ts W e implemen t POLCA within the T race workflo w optimization pip eline ( Cheng et al. , 2024 ), utilizing OptoPrime as the optimizer to conduct generative optimization guided by rich feedback and execution traces. W e compare POLCA against established baselines (DSPy ( Khattab et al. , 2023 ), GEP A ( Agraw al et al. , 2025 ), and Op enEv olv e ( Sharma , 2025 )); see Section D.1 for a detailed discussion on baselines. W e select representativ e domains where sto c hasticity arises from minibatch sampling, program execution ( Section 5.1 ), and ev aluation metho ds ( Section 5.2 ). Finally , w e demonstrate the sup eriorit y of POLCA in deterministic domains in Section 5.3 . Comparison criterion Ev aluating prop osed programs in the search pro cess is computationally exp ensiv e and time-consuming. While the total n umber of metric calls represen ts the actual computation used, we define an evaluation step as a unit where all constituent metric calls are parallelized, effectively measuring the num b er of sequential op erations required as a surrogate of wall clo c k time. T o ensure a fair comparison, w e set a maximum budget of metric calls for all algorithms and rep ort the scores ac hieved at each step. In Section D.3 , w e discuss criteria to ev aluate and compare algorithms across m ultiple dimensions of wall-clock time and computational cost. 5.1 Sto c hasticit y from program execution and minibatch sampling One p opular application of generative optimization in v olves training LLM-based agen ts. Since LLM-based agents are inheren tly sto c hastic, m ultiple trials on the same task may yield div erse outcomes. F urthermore, giv en the large n umber of p oten tial tasks, ev aluating agents on the entire training set is often inefficient. A widely used alternative is to sample a minibatch from the dataset to estimate agent p erformance. Consequently , the observed scores during the training pro cess are inheren tly sto c hastic. τ -b enc h W e first demonstrate such sto c hasticity using τ -b enc h ( Y ao et al. , 2024 ), a b enc hmark designed to ev aluate agents in interacting with h uman users and executing to ols to solve complex 9 0 50 100 150 200 250 300 Evaluation Step 0.35 0.40 0.45 0.50 0.55 0.60 0.65 T est Score - b e n c h T e s t S c o r e GEP A (Most F r equent) GEP A (Sample by F r eq) OpenEvolve POLCA (Ours) (a) τ -b enc h 0 50 100 150 200 250 Evaluation Step 0.70 0.75 0.80 0.85 0.90 0.95 1.00 T est Score HotpotQA T est Score GEP A OpenEvolve POLCA (Ours) (b) Hotp otQA 0 10 20 30 40 50 Evaluation Step 0.0 0.2 0.4 0.6 0.8 1.0 Score V eriBench (3-step evaluation) Score DSPy GEP A OpenEvolve POLCA (Ours) (c) V eriBench 0.0 2.5 5.0 7.5 10.0 12.5 15.0 17.5 20.0 Evaluation Step 0.0 0.2 0.4 0.6 0.8 1.0 f a s t 1 . 0 S c o r e K e r n e l B e n c h f a s t 1 . 0 S c o r e DSPy GEP A OpenEvolve POLCA (Ours) (d) KernelBench Figure 2: Searc h efficiency across four b enc hmarks. Solid curv es represent the av erage highest score attained at each step, while the shaded regions denote the standard error across multiple indep enden t runs (6 seeds for τ -b enc h, 3 for Hotp otQA and V eriBenc h (3-step ev aluation), and 1 for KernelBench). Higher curves indicate sup erior efficiency . queries. Here we use gemini-2.0-flash 5 as the bac kb one mo del, gemini/text-embedding-004 6 as the em b edding mo del for POLCA. The en vironment provides a sparse, binary rew ard r ∈ { 0 , 1 } p er execution, indicating whether the user’s request was resolved. W e utilize the first 10 tasks from the retail domain of τ -b enc h for optimization, with the remaining 145 tasks held out to test for generalization. The base agent provided by the b enc hmark is parameterized via a string v ariable, additional_instructions , whic h is app ended to the system prompt. Details can be found in Section D.2 . Figure 2(a) demonstrate the effectiveness of POLCA. While Op enEv olve and GEP A demonstrate impro vemen ts o ver the base agent, they are significan tly outp erformed by POLCA in this sto c hastic en vironment. This discrepancy arises b ecause these metho ds ev aluate each prop osed program on 10 tasks once without con tinuously up dating the statistics, making them heavily sensitiv e to the sto c hastic ev aluation. W e also ev aluate the b est generated prompt on the complete τ -b enc h retail domain dataset, consisting of 115 tasks. T able 1 shows that the prompt generated b y POLCA is not only the most effective on the 10 -task training set but also achiev es the b est p erformance on the en tire dataset. 5 https://docs.cloud.google.com/vertex- ai/generative- ai/docs/models/gemini/2- 0- flash 6 https://ai.google.dev/gemini- api/docs/embeddings 10 T able 1: P ass@1 of τ -b enc h retail domain (115 tasks). Prompts are trained on only the first 10 tasks. Here our POLCA achiev es a 13% impro vemen t compared with the base prompt. Metho d First 10 tasks Last 105 tasks All 115 tasks Base Prompt 0.348 0.392 0.389 GEP A 0.557 0.417 0.429 OpenEvolve 0.373 0.422 0.418 POLCA (Ours) 0.575 0.425 0.439 T able 2: V eriBenc h compilation pass rates. Each algorithm is allo cated a bud- get of 50 metric calls p er task. Algorithm P ass Rate DSPy 0.888 ± .023 GEP A 0.695 ± .010 OpenEvolve 0.738 ± .010 POLCA (Ours) 0.952 ± .005 Hotp otQA HotpotQA ( Y ang et al. , 2018 ) is a multi-hop question answering dataset where eac h task requires reasoning across m ultiple context paragraphs to pro duce a short answer. Each task consists of a question, 10 con text paragraphs (of which 2–3 are relev ant and the rest are distractors), and a ground-truth answer. W e use gemini-2.5-flash-lite as the backbone mo del, and gemini-embedding-001 6 as the embedding mo del for POLCA. Correctness is determined b y exact matc h or substring con tainment, yielding a binary reward of 0 or 1 p er task. W e use different algorithms to optimize the prompt for question answering. Details can b e found in Section D.2 . The result in Figure 2(b) sho ws the sup eriorit y of POLCA. 5.2 Sto c hasticit y from the ev aluator In the previous subsection, we discussed the sto chasticit y arising from program execution and the minibatc h sampling tasks. Here w e study the case of sto c hastic ev aluator for optimizing deterministic programs on a single task. V eriBenc h (3-step ev aluation) W e consider the formal verific ation domain using V eriBench ( Miranda et al. , 2025 ), whic h ev aluates the capability of LLMs to translate Python programs into v erifiable Lean 4 co de, with claude-3.5-sonnet 7 as the bac kb one and gemini/text-embedding-004 as the embedding mo del. LLMs are prompted to translate the Python program into a compilable and seman tically correct Lean 4 program. W e formalize this problem by treating the en tire translated Lean 4 program as the parameter, i.e., P θ ( x ) ≡ θ , resulting in a fully deterministic program execution. The provided 3-step ev aluation pro cess of V eriBench, which contains compilation, unit tests, and an LLM judge, has sto c hasticity and provides a [0 , 1] reward for each prop osed Lean 4 program. See Section D.2 for details. Figure 2(c) sho ws that our algorithm outp erforms all baselines, suggesting sup erior p erformance within the same time budget. In suc h cases, the ev aluator is the only source of sto c hasticit y . POLCA addresses this by contin uously up dating empirical mean scores, ensuring scalabilit y compared to approac hes using static p erformance v alues. Algorithms such as DSPy and Op enEv olv e typically collect reward and feedbac k for a program only once, even if that data is used multiple times to generate new programs. In contrast, POLCA rep eatedly selects current high-p erforming programs to collect data; this not only helps for accurate estimation but also gathers diverse, sto c hastic feedbac k for these programs. Due to this sto c hasticit y , obtaining feedback multiple times on the same parameter can increases the probability of receiving useful information to prop ose b etter programs. While GEP A also collects data m ultiple times for promising programs, it remains limited b ecause it: (1) dep ends highly on the initial v alidation and do es not up date program scores when new data is 7 https://www.anthropic.com/news/claude- 3- 5- sonnet 11 collected; (2) cannot explore m ultiple programs in parallel; and (3) degenerates into alwa ys selecting the single b est p erformer for exploration in single-task optimization problems, as the Pareto fron tier collapses. 5.3 Deterministic Domains Man y generative optimization problems are nearly deterministic. Examples include co de generation with a deterministic verifier and v arious scientific discov ery problems. This class of problems is of equal significance in the field of generative optimization. W e show that POLCA can b e directly applied to fully deterministic domains without mo dification. V eriBench (Compilation) W e utilize V eriBench again and the same LLMs but fo cusing on the deterministic compilation stage only . This remains a challenging domain giv en the limited Lean 4 programming kno wledge inherent in current LLMs. F or this analysis, the reward is a binary indicator of compilation success; all other exp erimen tal settings remain unc hanged. W e pro vide comprehensiv e experimental details in Section D.2 . The results for V eriBench compilation are presen ted in T able 2 , with extended results av ailable in Section D.4 . The results show that DSPy , Op enEv olv e, and GEP A are effectiv e but remain less efficient than our metho ds. Our parallelized POLCA consisten tly outp erforms these baselines, ev en when compared with the fully sequential DSPy and GEP A algorithm. Our b est algorithm reaches a 95.2% compilation pass rate (133/140) using a budget of 50 metric calls p er task, significantly exceeding the baseline results. Our work represents the first thorough study applying agentic search algorithms to V eriBench; previous metho ds relied on simple iterativ e refinement and achiev ed considerably low er success rates. Sp ecifically , Miranda et al. ( 2025 ) employ ed the same mo del and a sequential search with 5 retries on a subset of our tasks (113 tasks), ac hieving a maximum pass rate of 0.593 (67/113). KernelBenc h CUDA kernel optimization is also a p opular problem suitable for generative opti- mization. W e pick 16 matrix multiplication tasks from KernelBench (level 1) ( Ouyang et al. , 2025 ), whic h app ear simple but remain challenging. As men tioned in Y an et al. ( 2026 ), these tasks are already highly optimized in PyT orch, making it difficult to ac hieve further sp eedups. W e utilize the fast p score ( Ouyang et al. , 2025 ) defined as: fast p = 1 N P N i =1 1 ( correct i ∧ { speedup i > p } ) , where p is the sp eedup threshold relative to the PyT orc h baseline. This metric measures the prop ortion of tasks for whic h the algorithm prop oses a correct CUD A program with a sp eedup exceeding p . W e utilize the claude-3.7-sonnet 8 mo del for generation and gemini-embedding-001 as the em b edding mo del. Figure 2(d) illustrates pass 1 . 0 p erformance comparisons 9 where POLCA distinctly outp erforms the baselines. Implemen tation details are provided in Section D.2 . The success of POLCA in deterministic domains can b e attributed to tw o factors. First, the use of parallel starting p oin ts exploits the sto chasticit y of the optimizer more effectively than sequential baselines. Second, the global history context c history is summarized from all failed programs of differen t paths. In con trast, DSPy , GEP A, and Op enEvolv e are limited to lo cal knowledge, fo cusing on a single or small sets of optimization paths. 5.4 Ablation study Ablation on ε -Net and Summarizer In POLCA, we emplo y an ε -Net to filter programs and a Summarizer to pro vide a global context summary . W e conduct an ablation study on these 8 https://www.anthropic.com/news/claude- 3- 7- sonnet 9 W e provide a pass 0 . 5 analysis in Section D.5 . 12 0 250 500 750 1000 1250 1500 1750 2000 Number of Metric Calls 0.35 0.40 0.45 0.50 0.55 0.60 0.65 Score - b e n c h T e s t S c o r e vanilla POLCA vanilla POLCA+ -Net vanilla POLCA+Summarizer vanilla POLCA+ -Net+Summarizer (a) Ablation of ε -Net and Summarizer 0 100 200 300 400 500 Number of Metric Calls 0.30 0.35 0.40 0.45 0.50 0.55 Score - b e n c h T e s t S c o r e = 0.0 = 0.05 = 0.1 = 0.15 = 0.2 = 0.25 = 0.3 (b) Ablation on ε sensitivity 0 20 40 60 80 100 Number of Metric Calls 0.0 0.2 0.4 0.6 0.8 1.0 Score V eriBench (3-step evaluation) Score = 0.0 = 0.02 = 0.05 = 0.07 = 0.1 (c) Ablation on ε sensitivity 30% 60% 100% Data Usage 0.2 0.3 0.4 0.5 0.6 0.7 0.8 T est Score - b e n c h T e s t S c o r e C o m p a r i s o n Empirical Mean L owest P r ediction Mean P r ediction Highest pr ediction (d) Why not use regression? Figure 3: In (a–c), solid curves show the mean highest score achiev ed at eac h step, with shaded areas representing the standard error ov er indep enden t runs (6 seeds for (a); 3 seeds for (b, c)). In (d), bar heights denote test scores for programs selected via different criteria across v arying training data p ercentages. Results are av eraged ov er 3 runs, with error bars indicating the standard error. See Section D.7 for details. comp onen ts; see Figure 3(a) (further comparisons across different metrics can b e found in Figure 10 ), where v anilla POLCA refers to the version without the ε -Net or Summarizer. Comparing these v ariants highlights the adv an tages of our prop osed comp onen ts. Both the ε -Net and the Summarizer significantly improv e p erformance o ver v anilla POLCA. In this domain, the ε -Net lev erages embedding information to filter new candidates that are semantically similar to programs already in memory , thereby conserving a substantial p ortion of the sampling budget. Consequen tly , it achiev es higher scores with few er samples. The Summarizer enhances the optimizer by pro viding a broader con text, utilizing the entire memory rather than just lo cal observ ations to identify success and failure patterns across diverse programs, leading to the discov ery of sup erior candidates. Ablation on ε sensitivit y W e p erform an ablation on the ε v alue to provide intuition on how it affects p erformance on τ -b enc h and V eriBench. The results are presented in Figures 3(b) and 3(c) (more ablation ov er different domains/metrics can b e found in Figure 11 ). By construction, the ε v alue controls the coarseness of the discretization: parameters with a distance less than ε are iden tified as the same b y the algorithm. The ablation results show that POLCA’s p erformance is not v ery sensitiv e to the exact ε v alue within a certain range. W e consistently find that ε = 0 (no discretization) yields the worst learning p erformance. F or large ε , we observe a degradation in asymptotic p erformance due to approximation error of coarser discretization, although it improv es the initial learning sp eed as exp ected. As ε increases, POLCA accepts more diverse programs into memory , thereby encouraging exploration across distinct program structures. When a reasonable ε 13 v alue is selected, it improv es sp eed while incurring only negligible appro ximation error. Wh y not use regression? In large-scale exp eriments, a substantial amount of programs can b e generated. If they are treated as indep endent, ev aluating them all (multiple times) to iden tify optimal candidates w ould require an impractical sampling budget. W e use ε -Net filter with empirical mean to address this issue. W e ev aluate the feasibility of an alternate approach of training a surrogate rew ard function that maps program embeddings to predicted scores. W e train an ensem ble of fiv e logistic regressors with semantic embedding vectors to predict scores of candidates generated by an optimization pro cess in τ -b enc h. W e then select the b est candidates based on the ensemble’s highest , me an , and lowest predicted scores. As shown in Figure 3(d) , these function approximators failed to outp erform the simple selection based on the empiric al me an used in POLCA. A likely reason for this failure is that predicting a program’s score accurately is difficult without explicit problem-instance information. F or further details on this study , refer to Section D.7 . 6 Related W ork Existing algorithms are primarily distinguished b y their optimizer design , se ar ch str ate gy , and c andidate cur ation . The optimizer design p ertains to the sp ecific metho d of inv oking an LLM to generate a program parameter; the searc h strategy refers to the orchestration of the comprehensive optimization system, which may inv olve diverse and multiple LLM calls; whereas c andidate cur ation addresses the principled filtering and selection mec hanisms required to scale the pro cess when the p ool of generated programs exceeds computational or context limits. Optimizer Design Regarding optimizer design, some w orks utilize few-shot prompting, while others fo cus on sequential revision based on lo cal observ ations such as rewards, textual feedback, and execution traces ( Khattab et al. , 2023 ; Cheng et al. , 2024 ; Y uksekgon ul et al. , 2024 ). A more robust approac h inv olves leveraging global knowledge b y summarizing history to enhance p erformance ( Cui et al. , 2024 ). In large-scale search, context summarization is b ecoming increasingly p opular ( Zhang et al. , 2025b ). F or example, in kernel optimization tasks, Lange et al. ( 2025b ); Liao et al. ( 2025 ); Zhang et al. ( 2025a ) emplo y an external LLM as a con text summarizer to facilitate learning. POLCA similarly in tegrates numerical and textual feedback and leverages historical context summarization. Searc h Strategies Our work fo cuses on search strategies that balance exploration and exploitation. W e maintain a program memory , where the exploration-exploitation trade-off in volv es b oth prop osing impro ved programs via the optimizer and reducing uncertaint y regarding our curren tly accessible programs. While basic metho ds rely on rep eated generation and N -b est selection, more sophisticated framew orks utilize in-context learning from rewards, iterative refinement, or task-merging ( Khattab et al. , 2023 ; Cheng et al. , 2024 ). Sp ecialized approaches include Beam Searc h ( Sun et al. , 2023 ; Pryzan t et al. , 2023 ; Chen et al. , 2024 ), Monte-Carlo T ree Search ( W ang et al. , 2023 ), and Gibbs Sampling ( Xu et al. , 2023 ). Among these, Chen et al. ( 2024 ) prop oses learning a rew ard mo del from collected data; while effective in certain domains, this ma y fail in the presence of highly sto c hastic reward observ ations. Some prompt optimization works ( Pryzant et al. , 2023 ; Cui et al. , 2024 ) prop ose a finite-arm b andit sele ction phase, which is effectiv e for small-scale searc h. How ever, this remains an exploitation-heavy metho d that may prematurely cease generating new programs. Con versely , difficult problems require contin uous exploration. GEP A ( Agraw al et al. , 2025 ), designed for prompt tuning, maintains a P areto fron tier of undominated programs to preserv e diversit y . Ho wev er, it is susceptible to sto c hastic observ ations, as it falsely rejects candidates. F urthermore, 14 for single-task optimization with a verifier, GEP A may not b e suitable, as Pareto-fron tier-based searc h tends to degenerate, where the frontier merely represents the curren t b est program. In suc h domains, AlphaEv olve ( Novik o v et al. , 2025 ) utilizes MAP-Elites and island-based mo dels to guide ev olution. Subsequent framew orks like ThetaEvolv e ( W ang et al. , 2025b ) integrate evolutionary searc h with test-time reinforcemen t learning, while Shink aEvolv e ( Lange et al. , 2025a ) employs rejection sampling and bandit-based ensemble selection. While these evolution-based metho ds excel at generating complex programs, they primarily address tasks with nearly deterministic v erifiers and lac k sp ecific mec hanisms to handle environmen ts where the ev aluation pro cess is sto c hastic. Unlike prior metho ds that p erform simple v alidation to reject non-improving candidates ( Khattab et al. , 2023 ; Novik ov et al. , 2025 ; Agraw al et al. , 2025 ), POLCA manages sto c hasticity by contin uously up dating its memory buffer, including the re-ev aluation of older candidates, as new information emerges. This allo ws the algorithm to p erpetually learn and revisit candidates that demonstrate p oten tial, mitigating the risk of false rejection due to noise. Candidate Curation One of the primary challenges in generative optimization is the tendency of LLMs to prop ose semantically redundant candidates during long-horizon search pro cesses. Often, clustering and filtering me chanisms are used to maintain memory diversit y and nov elty . F or example, AlphaCo de ( Li et al. , 2022 ) utilizes test-based metho ds to reject underp erforming candidates and clusters programs based on execution b eha vior to assess nov elty and reduce ev aluation need. Recent framew orks such as Kim et al. ( 2025 ) and W ang et al. ( 2025a ) lev erage embedding-based clustering to iden tify and collapse redundant reasoning states, thereby significantly pruning the search space while maintaining high optimization accuracy . Similarly , Shink aEv olve ( Lange et al. , 2025a ) employs em b edding-based similarity detection coupled with an LLM-based co de-no v elty judge to accept or reject candidates. POLCA prop oses the semantic ε -Net filtering me chanism , where under mild assumptions on the quality of the em b edding (i.e., it contains useful information ab out the reward), w e can control ε to trade off b etw een final prop osed candidate’s p erformance and search budget in a principled manner, while all previous w orks rely on m ultiple heuristic hyper-parameters without clear implications. 7 Conclusion W e formalize the problem of sto chastic gener ative optimization , addressing the challenges of sto chas- ticit y in optimization and the unconstrained growth of the program space. W e design POLCA, which in tro duces tw o primary con tributions to address these challenges: (1) a contin uously up dated memory buffer that employs mean-based priorities to a verage out ev aluation v ariance, and (2) a semantic ε -Net filtering mechanism that prunes redundant candidates to maintain a diverse and efficient searc h space. Theoretical analysis shows POLCA with such design could con verge to near-optimal candidates efficiently . Empirical ev aluations on τ -b enc h, Hotp otQA, V eriBench and KernelBenc h, co vering b oth sto c hastic and deterministic domains, demonstrate that our approach significantly outp erforms existing baselines, effectiv ely handling sto c hasticit y from minibatc h sampling, program execution and ev aluation. Limitations Despite these adv ancements, POLCA has limitations. First, while the empirical mean is an efficien t priorit y metric, more sophisticated selection strategies ma y exist. Although our analysis of POLCA with the UCB score has a go o d guarantee, it relies on the knowledge of the degree of sto c hasticity in the reward, and the assumption on the optimizer may not alwa ys b e realistic. In addition, more adv anced function approximation metho ds than semantic embedding 15 distance for filtering is p ossible, e.g., by predicting p erformance across analogous tasks. Lastly , the observ ations made in the exp erimen tal results may b e limited to the b enc hmarks and mo dels tested here, despite our b est efforts to make them representativ e. A c kno wledgemen ts W e ackno wledge supp ort of the D ARP A AIQ A ward and the Gemini A cademic Program A ward. References Laksh ya A Agraw al, Shangyin T an, Dilara So ylu, Noah Ziems, Rishi Khare, Krista Opsahl-Ong, Arna v Singhvi, Herumb Shandilya, Michael J Ryan, Meng Jiang, et al. Gepa: Reflective prompt ev olution can outp erform reinforcemen t learning. arXiv pr eprint arXiv:2507.19457 , 2025. Leni Aniv a, Chuyue Sun, Brando Miranda, Clark Barrett, and Sanmi Ko yejo. Pan tograph: A mac hine-to-machine interaction interface for adv anced theorem proving, high level reasoning, and data extraction in lean 4. In International Confer enc e on T o ols and A lgorithms for the Construction and Analysis of Systems , pages 104–123. Springer, 2025. Y ongchao Chen, Jacob Arkin, Yilun Hao, Y ang Zhang, Nic holas Roy , and Ch uch u F an. Prompt optimization in m ulti-step tasks (promst): In tegrating human feedback and preference alignment. CoRR , 2024. Ching-An Cheng, Allen Nie, and Adith Swaminathan. T race is the next auto diff: Generative optimization with rich feedback, execution traces, and llms. arXiv pr eprint arXiv:2406.16218 , 2024. An thony Cui, Pranav Nandyalam, Andrew Rufail, Ethan Cheung, Aiden Lei, Kevin Zhu, and Sean O’Brien. In tro ducing map o: Momentum-aided gradient descent prompt optimization. arXiv pr eprint arXiv:2410.19499 , 2024. Jia wei Gu, Xuh ui Jiang, Zhic hao Shi, Hexiang T an, Xuehao Zhai, Cheng jin Xu, W ei Li, Yinghan Shen, Sheng jie Ma, Honghao Liu, et al. A survey on llm-as-a-judge. arXiv pr eprint arXiv:2411.15594 , 2024. Jie Huang, Xinyun Chen, Sw aro op Mishra, Huaixiu Steven Zheng, Adams W ei Y u, Xin ying Song, and Denn y Zhou. Large language mo dels cannot self-correct reasoning yet, 2024. arXiv pr eprint arXiv:2310.01798 , 2023. Omar Khattab, Arna v Singhvi, Paridhi Maheshw ari, Zhiyuan Zhang, Keshav Santhanam, Sri V ard- hamanan, Saiful Haq, Ashutosh Sharma, Thomas T Joshi, Hanna Moazam, et al. Dspy: Compiling declarativ e language mo del calls into self-improving pip elines. arXiv pr eprint arXiv:2310.03714 , 2023. Jo ongho Kim, Xirui Huang, Zarreen Reza, and Gabriel Grand. Chopping trees: Seman tic similarity based dynamic pruning for tree-of-thought reasoning. arXiv pr eprint arXiv:2511.08595 , 2025. A viral Kumar, Vincen t Zh uang, Rishabh Agarwal, Yi Su, John D Co-Reyes, A vi Singh, Kate Baumli, Shariq Iqbal, Colton Bishop, Reb ecca Ro elofs, et al. T raining language mo dels to self-correct via reinforcemen t learning. arXiv pr eprint arXiv:2409.12917 , 2024. 16 Rob ert Tjarko Lange, Y uki Ima juku, and Edoardo Cetin. Shink aevolv e: T o wards op en-ended and sample-efficien t program evolution. arXiv pr eprint arXiv:2509.19349 , 2025a. Rob ert Tjarko Lange, Qi Sun, Aadity a Prasad, Maxence F aldor, Y ujin T ang, and Da vid Ha. T ow ards robust agen tic cuda kernel b enchmarking, verification, and optimization. arXiv pr eprint arXiv:2509.14279 , 2025b. Ch ungpa Lee, Thomas Zeng, Jongwon Jeong, Jy-y ong Sohn, and Kangwook Lee. Ho w to correctly rep ort llm-as-a-judge ev aluations. arXiv pr eprint arXiv:2511.21140 , 2025a. Jinh yuk Lee, F eiy ang Chen, Sahil Dua, Daniel Cer, Madhuri Shanbhogue, Iftekhar Naim, Gus- ta vo Hernández Ábrego, Zhe Li, Kaifeng Chen, Henrique Schec hter V era, et al. Gemini em b edding: Generalizable em b eddings from gemini. arXiv pr eprint arXiv:2503.07891 , 2025b. Y ujia Li, Da vid Choi, Juny oung Chung, Nate Kushman, Julian Schritt wieser, Rémi Leblond, T om Eccles, James Keeling, F elix Gimeno, Agustin Dal Lago, et al. Comp etition-lev el co de generation with alphaco de. Scienc e , 378(6624):1092–1097, 2022. Gang Liao, Hongsen Qin, Ying W ang, Alicia Golden, Michael Kuchnik, Y avuz Y etim, Jia Jiunn Ang, Ch unli F u, Yihan He, Samuel Hsia, et al. Kernelevolv e: Scaling agentic kernel co ding for heterogeneous ai accelerators at meta. arXiv pr eprint arXiv:2512.23236 , 2025. Jessy Lin, Nic holas T omlin, Jacob Andreas, and Jason Eisner. Decision-oriented dialogue for human-ai collab oration. T r ansactions of the Asso ciation for Computational Linguistics , 12:892–911, 2024. Brando Miranda, Zhanke Zhou, Allen Nie, Elyas Obbad, Leni Aniv a, Kai F ronsdal, W eston Kirk, Dilara Soylu, Andrea Y u, Ying Li, et al. V erib enc h: End-to-end formal v erification b enchmark for ai co de generation in lean 4. In 2nd AI for Math W orkshop@ ICML 2025 , 2025. Allen Nie, Ching-An Cheng, Andrey K olob o v, and A dith Swaminathan. The imp ortance of directional feedbac k for llm-based optimizers. arXiv pr eprint arXiv:2405.16434 , 2024. Alexander Novik o v, Ngân V u, Marvin Eisenberger, Emilien Dup on t, Po-Sen Huang, Adam Zsolt W agner, Sergey Shirob ok ov, Borisla v K ozlovskii, F rancisco JR Ruiz, Abbas Mehrabian, et al. Alphaev olve: A co ding agent for scientific and algorithmic disco very , 2025. URL: https://arxiv. or g/abs/2506.13131 , 2025. Anne Ouy ang, Simon Guo, Simran Arora, Alex L Zhang, William Hu, Christopher Ré, and Azalia Mirhoseini. Kernelb enc h: Can llms write efficient gpu kernels? arXiv pr eprint arXiv:2502.10517 , 2025. Reid Pryzant, Dan Iter, Jerry Li, Yin T at Lee, Chenguang Zhu, and Michael Zeng. Automatic prompt optimization with" gradient descent" and b eam searc h. arXiv pr eprint arXiv:2305.03495 , 2023. Asankha ya Sharma. Op enev olve: an op en-source evolutionary co ding agent, 2025. URL ht tps : //github.com/algorithmicsuperintelligence/openevolve . F reda Shi, Daniel F ried, Marjan Ghazvininejad, Luke Zettlemoy er, and Sida I W ang. Natural language to co de translation with execution. In Pr o c e e dings of the 2022 Confer enc e on Empiric al Metho ds in Natur al L anguage Pr o c essing , pages 3533–3546, 2022. 17 Hao Sun, Xiao Liu, Y eyun Gong, Y an Zhang, Daxin Jiang, Linjun Y ang, and Nan Duan. Allies: Prompting large language mo del with b eam search. arXiv pr eprint arXiv:2305.14766 , 2023. An te W ang, Linfeng Song, Y e Tian, Dian Y u, Haitao Mi, Xiangyu Duan, Zhaop eng T u, Jinsong Su, and Dong Y u. Don’t get lost in the trees: Streamlining llm reasoning by ov ercoming tree searc h exploration pitfalls. In Pr o c e e dings of the 63r d Annual Me eting of the Asso ciation for Computational Linguistics (V olume 1: L ong Pap ers) , pages 23946–23959, 2025a. Xin yuan W ang, Chenxi Li, Zhen W ang, F an Bai, Haotian Luo, Jiay ou Zhang, Neb o jsa Jo jic, Eric P Xing, and Zhiting Hu. Promptagen t: Strategic planning with language mo dels enables exp ert-lev el prompt optimization. arXiv pr eprint arXiv:2310.16427 , 2023. Yiping W ang, Shao-Rong Su, Zhiyuan Zeng, Ev a Xu, Liliang Ren, Xinyu Y ang, Zeyi Huang, Xuehai He, Luyao Ma, Baolin Peng, et al. Thetaev olve: T est-time learning on op en problems. arXiv pr eprint arXiv:2511.23473 , 2025b. Anjiang W ei, Allen Nie, Thiago SFX T eixeira, Rohan Y adav, W onchan Lee, Ke W ang, and Alex Aik en. Improving parallel program p erformance with llm optimizers via agen t-system interfaces. arXiv pr eprint arXiv:2410.15625 , 2024. Shirley W u, Mic hel Galley , Baolin P eng, Hao Cheng, Ga vin Li, Y ao Dou, W eixin Cai, James Zou, Jure Lesk ov ec, and Jianfeng Gao. Collabllm: F rom passiv e resp onders to active collab orators. arXiv pr eprint arXiv:2502.00640 , 2025. W anqiao Xu, Allen Nie, Ruijie Zheng, Adit ya Mo di, Adith Swaminathan, and Ching-An Cheng. Pro v ably learning from language feedback. arXiv pr eprint arXiv:2506.10341 , 2025. W eijia Xu, Andrzej Banburski-F ahey , and Neb o jsa Jo jic. Reprompting: Automated chain-of-though t prompt inference through gibbs sampling. arXiv pr eprint arXiv:2305.09993 , 2023. Minghao Y an, Bo P eng, Benjamin Coleman, Ziqi Chen, Zhouhang Xie, Zhankui He, Nov een Sachdev a, Isab ella Y e, W eili W ang, Chi W ang, et al. Pacev olve: Enabling long-horizon progress-aw are consisten t evolution. arXiv pr eprint arXiv:2601.10657 , 2026. Chengrun Y ang, Xuezhi W ang, Yifeng Lu, Hanxiao Liu, Quo c V Le, Denn y Zhou, and Xin yun Chen. Large language mo dels as optimizers. In The Twelfth International Confer enc e on L e arning R epr esentations , 2023. Zhilin Y ang, P eng Qi, Saizheng Zhang, Y oshua Bengio, William Cohen, Ruslan Salakh utdinov, and Christopher D Manning. Hotpotqa: A dataset for div erse, explainable m ulti-hop question answ ering. In Pr o c e e dings of the 2018 c onfer enc e on empiric al metho ds in natur al language pr o c essing , pages 2369–2380, 2018. Sh unyu Y ao, Noah Shinn, Pedram Raza vi, and Karthik Narasimhan. τ -b enc h: A b enc hmark for to ol-agen t-user in teraction in real-world domains. arXiv pr eprint arXiv:2406.12045 , 2024. Mert Y uksekgonul, F ederico Bianchi, Joseph Bo en, Sheng Liu, Zhi Huang, Carlos Guestrin, and James Zou. T extgrad: Automatic" differen tiation" via text. arXiv pr eprint arXiv:2406.07496 , 2024. Genghan Zhang, Shaow ei Zhu, A njiang W ei, Zhenyu Song, Allen Nie, Zhen Jia, Nandita Vijaykumar, Yida W ang, and Kunle Olukotun. A ccelopt: A self-improving llm agen tic system for ai accelerator k ernel optimization. arXiv pr eprint arXiv:2511.15915 , 2025a. 18 Qizheng Zhang, Changran Hu, Sh ubhangi Upasani, Boyuan Ma, F englu Hong, V amsidhar Kamanuru, Ja y Rainton, Chen W u, Mengmeng Ji, Hanchen Li, et al. Agentic context engineering: Evolving con texts for self-improving language mo dels. arXiv pr eprint arXiv:2510.04618 , 2025b. Lianmin Zheng, W ei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao W u, Y onghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and c hatb ot arena. A dvanc es in neur al information pr o c essing systems , 36:46595–46623, 2023. 19 A F ull Pro of of Section 4 A.1 Notations and the T ec hnical Lemma W e run POLCA for n steps. Without loss of generality , we assume that B is divisible b y γ / 2 . T o b egin our analysis, we partition the reward range into small interv als of width γ / 2 : [0 , B ] = S 2 B /γ k =1 [( k − 1) γ / 2 , k γ / 2] = [0 , γ / 2] ∪ [ γ / 2 , γ ] ∪ · · · ∪ [ B − γ , B ] . Define I k = { θ ∈ Θ : µ ( θ ) ∈ [( k − 1) γ / 2 , k γ / 2] } for any 1 ≤ k ≤ 2 B /γ − 2 . W e define τ k to b e the stopping time when the total num b er of selections in I k reac hes u interv al : = 2 log( n ) /δ 0 , i.e., τ k : = min ( t : X ˜ θ ∈ I k T ˜ θ ( t ) = u interv al ) . (5) Later we will show that this level of interv al-level exploration is sufficien t to prop ose a b etter program. F or a single program θ ∈ I k , w e fo cus on the additional selections o ccurring after this time ( t ≥ τ k ), defined as: T add θ ( t ) : = T θ ( t ) − T θ ( τ k ) , whic h represents the n umber of selections of an individual program after the in terv al itself has b een sampled u interv al times. Define u single : = 64 σ 2 γ 2 log ( n ) . Our Theorem 3 shows that this additional num b er of selections can b e b ounded. Lemma 3 (Bounded selection num b er for each in terv al) . L et Θ n denote the set of pr o gr ams pr op ose d and ac c epte d in the first n steps. Consider the c ase wher e θ ∈ Θ n and τ k ≤ n , such that T add θ ( n ) is wel l-define d. F or any θ ∈ I k , the exp e cte d numb er of additional sele ctions is b ounde d by: E [ T add θ ( n ) | θ ∈ Θ n , τ k ≤ n ] ≤ u single + 3 = 64 σ 2 γ 2 log( n ) + 3 . W e pro vide the pro of of Theorem 3 in Section A.2 . Theorem 3 serves as the most critical comp onen t of the entire pro of. Intuitiv ely , it demonstrates that POLCA with a UCB priorit y function will successfully distinguish b et w een t wo programs with a reward gap of γ after O σ 2 γ 2 log ( n ) observ ations. A.2 Pro of of Theorem 3 This lemma analyzes the additional selection num b er for any fixed θ ∈ I k . Define τ θ to b e the time step at which the additional selections of program θ reac h u single , i.e., τ θ = min t { T add θ ( t ) = u single } . Let ˜ θ b e the first prop osed program satisfying µ ( ˜ θ ) > ( k + 1) γ / 2 . Define the "go od even t" G = G 1 ∩ G 2 ∩ G 3 as: • Concen tration of program θ : G 1 = n ˆ µ θ,T θ ( τ θ ) + 2 σ q log( n ) T θ ( τ θ ) < ( k + 1) γ / 2 o • Prop osal of ˜ θ : G 2 = { the strictly b etter program ˜ θ is prop osed b efore iteration τ k } • Concen tration for program ˜ θ : G 3 = { U C B ˜ θ ( t ) ≥ µ ( ˜ θ ) for all t ∈ [ n ] } W e first claim that when G o ccurs, T add θ ( n ) ≤ u single holds. Otherwise , if T add θ ( n ) > u single , there m ust exist τ θ < n suc h that T add θ ( τ θ ) = u single . A t iteration τ θ , T add θ > 0 implies τ k ≤ τ θ . By G 2 , a 20 program ˜ θ with µ ( ˜ θ ) > ( k + 1) γ / 2 has already b een prop osed. By G 1 and G 3 , it follows that for all τ θ ≤ t ≤ n : U C B ˜ θ ( t ) ≥ µ ( ˜ θ ) > ( k + 1) γ / 2 > ˆ µ θ,T θ ( τ θ ) + 2 σ s log( n ) T θ ( τ θ ) = U C B θ ( t ) . Since the algorithm selects the program with the highest UCB score at each iteration, the fact that U C B ˜ θ ( t ) > U C B θ ( t ) for all t ≥ τ θ implies that θ will no longer b e selected after time step τ θ . This yields a con tradiction to the assumption T add θ ( n ) > u single . Bounding P ( G c 1 ) Consider any fixed s ≥ u single . Since u single = 64 σ 2 γ 2 log ( n ) , w e hav e 2 σ q log( n ) s ≤ γ / 4 . W e first b ound P ( G c 1 | T θ ( τ θ ) = s ) : P ( G c 1 | T θ ( τ θ ) = s ) = P ˆ µ θ,T θ ( τ θ ) + 2 σ s log( n ) T θ ( τ θ ) ≥ ( k + 1) γ / 2 | T θ ( τ θ ) = s (Definition of G 1 ) = P ˆ µ θ,s + 2 σ r log( n ) s ≥ ( k + 1) γ / 2 = P ˆ µ θ,s − µ ( θ ) ≥ ( k + 1) γ / 2 − 2 σ r log( n ) s − µ ( θ ) ≤ P ˆ µ θ,s − µ ( θ ) ≥ γ 4 ( µ ( θ ) ≤ k γ / 2 ) ≤ exp − sγ 2 32 σ 2 (Ho effding’s inequality) ≤ exp − u single γ 2 32 σ 2 ( s ≥ u single ) ≤ 1 n 2 . This probabilit y b ound has no relationship with the sp ecific v alue of T θ ( τ θ ) , so generally w e hav e P ( G c 1 ) ≤ 1 n 2 . Bounding P ( G c 2 ) By the definition of τ k in ( 5 ) , at iteration τ k the interv al I k has b een selected u interv al times. The even t G c 2 implies that no γ -strictly b etter program ˜ θ has b een generated after u interv al selections on I k . By Assumption 1 , when we select a program θ ∈ I k with reward µ ( θ ) ∈ [( k − 1) γ / 2 , k γ / 2] , the optimization oracle pro duces a θ ′ with µ ( θ ′ ) > ( k + 1) γ / 2 with probabilit y at least δ 0 . Therefore, P ( G c 2 ) is the probabilit y of failing to prop ose such a program for u interv al consecutiv e trials: P ( G c 2 ) ≤ (1 − δ 0 ) u interv al ≤ e − δ 0 u interv al ≤ e − δ 0 1 δ 0 log( n 2 ) ≤ 1 n 2 . Bounding P ( G c 3 ) G 3 describ es n concentration b ounds hold simultaneously . G c 3 = n [ t =1 { U C B ˜ θ ( t ) < µ ( ˜ θ ) } . 21 F or a fixed θ 1 ∈ Θ , P ( G c 3 | ˜ θ = θ 1 ) = P n [ t =1 { U C B ˜ θ ( t ) < µ ( ˜ θ ) } | ˜ θ = θ 1 ) = P n [ t =1 { U C B θ 1 ( t ) < µ ( θ 1 ) } ≤ n X t =1 P ( U C B θ 1 ( t ) < µ ( θ 1 )) = n X t =1 P b µ θ,T θ 1 ( t ) + 2 σ s log( n ) T θ 1 ( t ) < µ ( θ 1 ) = n X t =1 P b µ θ,T θ 1 ( t ) − µ ( θ 1 ) < − 2 σ s log( n ) T θ 1 ( t ) ≤ n X t =1 1 n 2 = 1 n . (Ho effding’s inequality) Since the final b ound has no relationship with the v alue of θ 1 , w e hav e P ( G c 3 ) ≤ 1 n . Com bining the b ound for P ( G c 1 ) , P ( G c 2 ) , P ( G c 3 ) , w e hav e P ( G c ) ≤ 1 n 2 + 1 n 2 + 1 n = n + 2 n 2 . Strictly sp eaking, to obtain our final result, w e should b ound the probability given the even t { θ ∈ Θ n , τ k ≤ n } . Ho w ever, w e can calculate the probability P ( G c i | Θ = ˜ Θ , τ k = s ) for fixed ˜ Θ , s and i ∈ { 1 , 2 , 3 } using iden tical steps. Because the resulting b ounds are indep endent of the v alue of s , our b ound also holds in the conditional version: P ( G c | θ ∈ Θ n , τ k ≤ n ) ≤ n + 2 n 2 . Bounding the exp ected additional selection num b er Since we alwa ys ha ve T add θ ( n ) ≤ n , E [ T add θ ( n ) | θ ∈ Θ n , τ k ≤ n ] = E [ T add θ ( n ) 1 G | θ ∈ Θ n , τ k ≤ n ] + E [ T add θ ( n ) 1 G c | θ ∈ Θ n , τ k ≤ n ] ≤ u single + n P ( G c | θ ∈ Θ n , τ k ≤ n ) ≤ u single + n ( n + 2) /n 2 ≤ 64 σ 2 γ 2 log( n ) + 3 . So w e finish the pro of of Theorem 3 . 22 A.3 Pro of of Theorem 1 By definition, E X θ ∈ Θ n : µ ( θ ) ≤ B − γ T θ ( n ) = 2 B /γ − 2 X k =1 E X θ ∈ I k ∩ Θ n T θ ( n ) . F or each in terv al, b y definition of τ k in ( 5 ), E X θ ∈ I k ∩ Θ n T θ ( n ) = E X θ ∈ I k ∩ Θ n T θ ( n ) | τ k ≤ n P [ τ k ≤ n ] + E X θ ∈ I k ∩ Θ n T θ ( n ) | τ k > n P [ τ k > n ] ≤ E u interv al + X θ ∈ I k ∩ Θ n T add θ ( n ) | τ k ≤ n P [ τ k ≤ n ] + u interv al · P [ τ k > n ] ≤ u interv al + E X θ ∈ I k ∩ Θ n T add θ ( n ) | τ k ≤ n . (6) Since θ / ∈ Θ n ⇒ T add θ ( n ) = 0 , w e hav e E [ T add θ ( n ) | τ k ≤ n ] = E [ T add θ ( n ) | θ ∈ Θ n , τ k ≤ n ] · P [ θ ∈ Θ n ] + E [ T add θ ( n ) | θ / ∈ Θ n , τ k ≤ n ] · P [ θ / ∈ Θ n ] ≤ E [ T add θ ( n ) | θ ∈ Θ n , τ k ≤ n ] . (7) Therefore, E X θ ∈ Θ n : µ ( θ ) ≤ B − γ T θ ( n ) = 2 B /γ − 2 X k =1 E X θ ∈ I k ∩ Θ n T θ ( n ) ( 6 ) ≤ 2 B /γ − 2 X k =1 u interv al + E X θ ∈ I k ∩ Θ n T add θ ( n ) | τ k ≤ n ! ≤ 2 B /γ · u interv al + E X θ ∈ Θ n : µ ( θ ) ≤ B − γ T add θ ( n ) | τ k ≤ n ( 7 ) ≤ 2 B /γ · u interv al + E X θ ∈ Θ n : µ ( θ ) ≤ B − γ T add θ ( n ) | θ ∈ Θ n , τ k ≤ n = 2 B /γ · u interv al + E " X θ ∈ Θ n : µ ( θ ) ≤ B − γ E T add θ ( n ) | θ ∈ Θ n , τ k ≤ n | Θ n # ≤ 2 B /γ · u interv al + N ε · ( u single + 3) , where the last step is from Theorem 3 and the fact that the cardinality of Θ n is b ounded by N ε . A.4 Pro of of Theorem 2 F or simplicity , we assume that B is divisible by γ . Let R t denote the reward of the program prop osed at step t . This induces a probability measure on the sequence R = ( R 1 , R 2 , . . . , R t , . . . ) . Sequen tial Up dates. Supp ose the sequence R = ( R 1 , R 2 , . . . , R t , . . . ) is generated by a sequential up dating algorithm following ( 3 ). Then, by Assumption 1 , we hav e P [ R t +1 > R t + γ ] ≥ δ 0 . 23 In tuitively , in the worst case, a sequential up dating algorithm m ust mak e N : = B /γ consecutiv e impro vemen ts to reach a near-optimal program. W e define the stopping time τ as the first step ac hieving a reward in ( B − γ , B ] , and τ 1 as the first step where an improv emen t larger than γ has o ccurred for N consecutive steps: τ : = min { t : R t > B − γ } , τ 1 : = min { t : R t − R t − 1 > γ , . . . , R t − N +1 − R t − N > γ } . F or any given reward sequence R , the set of indices satisfying the condition for τ 1 is a subset of those satisfying the condition for τ ; therefore, τ ≤ τ 1 . In the worst case, we assume P [ R s − R s − 1 > γ ] = δ 0 for all s . Define τ ( n ) 1 = min { t : R t − R t − 1 > γ , . . . , R t − n +1 − R t − n > γ } as the first time n consecutiv e improv emen ts o ccur, where τ 1 = τ ( N ) 1 . By conditioning on the outcome after achieving n − 1 consecutive improv ements, we hav e: E [ τ ( n ) 1 ] = δ 0 ( E [ τ ( n − 1) 1 ] + 1) + (1 − δ 0 )( E [ τ ( n − 1) 1 ] + 1 + E [ τ ( n ) 1 ]) , where the second term accoun ts for the streak b eing broken, requiring a full restart. Simplifying this expression yields: E [ τ ( n ) 1 ] = E [ τ ( n − 1) 1 ] + 1 δ 0 . Using the base case E [ τ (0) 1 ] = 0 , the closed-form solution for this recurrence is: E [ τ 1 ] = δ − N 0 − 1 1 − δ 0 . This result establishes the O ( δ − N 0 ) = O ( δ − B /γ 0 ) complexit y for the sequential up dating algorithm. POLCA. Supp ose the sequence R = ( R 1 , R 2 , . . . , R t , . . . ) is generated b y POLCA using the up dating rule ( 4 ) . Let τ b e the first step reaching a reward in ( B − γ , B ] . W e define τ 2 as the first step where N total (not necessarily consecutive) improv emen ts of size at least γ hav e b een observed: τ = min { t : R t > B − γ } , τ 2 = min t : t X s =1 I ( R s > max j τ } and failures H − θ = { ( θ , ω , x, y , r, f ) ∈ H θ : r ≤ τ } based on a reward threshold τ . By identifying systematic patterns across these partitions—such as instruction formats unique to high-scoring programs— the Summarizer compresses these insights into natural language meta-gr adients . T o maintain a represen tative view while adhering to context limits, w e employ a Contr astive Sampling strategy , pro viding the LLM with program parameters alongside paired represen tative tra jectories (one r > τ and one r ≤ τ ). This enables the LLM to p erform cross-program error correction, providing a stable historical direction analogous to Gr adient Desc ent with Momentum ( Cui et al. , 2024 ). The pro cess is gov erned by a structured prompt template utilizing XML-style tags to separate in ternal reasoning from actionable guidance, as detailed b elow. Summarizer Prompt T emplate System: Y ou are an exp ert at analyzing program b ehavior patterns and providing actionable guidance for parameter optimization. User: Analyze the following program rollout tra jectories and extract insights for optimization. F or eac h program, a successful and a failed tra jectory are provided for contrastiv e analysis. T ra jectories: { histor y _ tr aj ector ies } Pro vide your analysis in XML format: • Analyze the k ey patterns and strategies that led to success or failure in these tra jectories. • Concrete recommendations for improving output quality based on successful or failed patterns observed. Then we combine lo cal rollouts with c history summarized from Q to construct the context for O . F or each θ ∈ Θ explore , w e construct the context as C θ = { ( θ , x i , y i , r i , f i , c history ) } B i =1 and in vok e the optimizer O to get θ ′ ∼ Π · |{ ( θ , x i , y i , r i , f i , c history ) } B i =1 . W e collect the prop osed program in Θ raw . The async hronous ProposePr ograms subroutine is detailed in Algorithm 3 . Seman tic Filter based on ε -Net Design T o enhance optimization efficiency , the Semantic- Fil ter subroutine leverages semantic similarit y among programs to prune redundant prop osals and main tain diversit y . Giv en a set of raw candidates Θ raw , w e construct a filtered set Θ new using a farthest-first tra versal strategy to form an ε -net. Starting with Θ new ← ∅ and a program p ool Θ remaining ← Θ raw , we iteratively: (1) for each θ ∈ Θ remaining , compute its distance to the current p opulation of v alidated and newly selected agents, d ( θ ) = min θ ′ ∈Q∪ Θ new ˜ d ( θ , θ ′ ) ; (2) identify the candidate θ ∗ = arg max θ ∈ Θ remaining d ( θ ) with the maximum distance d max = d ( θ ∗ ) ; and (3) if d max > ε , transfer θ ∗ from Θ remaining to Θ new , otherwise the pro cess terminates. This greedy selection strategy ensures the expanded agent set maintains a diversit y threshold: for any distinct pair θ , θ ′ ∈ Q ∪ Θ new , the seman tic distance satisfies ˜ d ( θ , θ ′ ) > ε . Implementation details are provided in Algorithm 4 . 10 W e also refer to ev aluation data of the form ( θ, ω , x, y , r, f ) as an ev aluation tra jectory . 26 Algorithm 3 Pr oposePrograms – F ully asynchronous program generation Require: Inputs: Aggregate rollouts S = S θ S θ , priorit y queue Q , optimizer O Ensure: Set of new program parameters Θ raw 1: Θ raw ← ∅ 2: U ← ∅ ▷ Global task queue for parallel execution 3: Summarize Q to get global history con text c history 4: for eac h θ ∈ Θ explore do 5: Extract the rollouts S θ = { ( θ , ω i , x i , y i , r i , f i ) } |B| i =1 to Construct the con text C θ = { ( θ , x i , y i , r i , f i , c history ) } |B| i =1 6: U ← U ∪ {C θ } ▷ Queue task for parallel dispatch 7: end for 8: for eac h C θ ∈ U in parallel do ▷ Massiv ely parallel asynchronous calls 9: θ ′ ∼ Π( · | C θ ) 10: lo c k Θ raw ← Θ raw ∪ { θ ′ } 11: end for 12: w ait for all threads in U to return 13: return Θ raw Algorithm 4 SemanticFil ter – Seman tic-based pruning for candidate diversit y Require: Inputs: Ra w candidate set Θ raw , priorit y queue Q Hyp erparameters: Div ersit y threshold ε , semantic distance metric ˜ d ( · , · ) Ensure: Filtered set Θ new s.t. ∀ θ i , θ j ∈ (Θ new ∪ Q ) , i = j = ⇒ ˜ d ( θ i , θ j ) ≥ ε 1: 2: Θ new ← ∅ 3: Θ remaining ← Θ raw ▷ Initialize p ool of remaining candidates 4: 5: while Θ remaining = ∅ do 6: ▷ Find candidate with maximum distance to the existing p opulation 7: θ ∗ ← arg max θ ∈ Θ rem n min θ ′ ∈Q∪ Θ new ˜ d ( θ , θ ′ ) o 8: δ max ← min θ ′ ∈Q∪ Θ new ˜ d ( θ ∗ , θ ′ ) 9: 10: if δ max ≥ ε then 11: Θ new ← Θ new ∪ { θ ∗ } 12: Θ remaining ← Θ remaining \ { θ ∗ } 13: else 14: break ▷ T ermination: all remaining candidates are seman tically redundant 15: end if 16: end while 17: 18: return Θ new 27 C Instan tiating Classical Search Algorithms POLCA is univ ersal b ecause mo difying the priority function p explore : Θ → R is sufficien t to mimic man y classical search paradigms. Changing p explore ( · ) lea ves the rest of the algorithm untouc hed, making it easy to implemen t different designs on the same problem instance. Sequen tial searc h (Iterative refinemen t). The simplest strategy follows a depth-first tra jectory through the search space. At eac h iteration, only the most recently prop osed program is selected for further ev aluation and refinement. This b eha vior is enforced by setting p explore ( θ ) = t θ , where t θ is the creation timestamp of agen t θ . By using this L ast-In, First-Out (LIF O) ordering and restricting the exploration budget to k = 1 , the algorithm collapses into a sequen tial refinement pro cess that ignores the broader p opulation in fav or of lo cal, iterative impro vemen ts. Beam search. Sequen tial search is prone to lo cal traps. Beam searc h impro ves robustness b y main taining a p opulation of k activ e b e ams ; at eac h iteration, these b eams pro duce new programs that are v alidated, with only the top- k candidates surviving based on their initial scores. In our framework, this is realized by allowing O to prop ose m ultiple new programs θ ′ , and assigning p explore ( θ ′ ) = ¯ r ( θ ′ ) for newly prop osed programs—where the av erage is calculated using only the v alidation data from the current iteration—and setting p explore ( θ ) = −∞ for all old programs in memory . This ensures the priority queue retains only the most recent high-p erforming generation while pruning older branches, effectiv ely emulating the breadth-first expansion of classical b eam searc h. This approac h might b e efficien t in deterministic settings; how ev er, in the presence of sto c hasticit y , discarding historical ev aluations and ev aluating eac h program only once may lead to sub optimal results. Upp er Confidence Bound (UCB) In finite-action b est-arm-iden tification bandit theory , greedy exploration is not pro v ably optimal. T o address this, more refined strategies suc h as the Upp er Confidence Bound (UCB) approac h can b e emplo yed to provide an explicit incen tive for collecting data on uncertain candidates. UCB incorp orates an uncertaint y b on us in to the priority calculation, sp ecifically , at iteration t we can calculate the priority score for each program as: p explore ( θ ) = b µ θ,T θ ( t ) + β s log( n ) T θ ( t ) , where T θ ( t ) is the num b er of rew ard observ ations of program θ , b µ θ,s is the empirical mean of program θ with the first s rew ard observ ations, n = P θ ′ ∈Q T θ ′ ( t ) is the total rollout budget, and β > 0 con trols the exploration-exploitation tradeoff. The b on us increases for programs with small T θ ( t ) , guiding exploration to ward under-sampled regions and preven ting premature conv ergence. In Section 4 , w e pro ve if β is selected as a certain n umber related to the randomness of the system, under some assumptions, a simplified version of POLCA could con verges to programs that can not b e further impro ved by the optimizer. While our current framework utilizes the empirical mean as a robust starting p oin t for sto c hastic generativ e optimization, in tegrating such carefully designed priorit y functions represen ts a promising direction for future work to further enhance search p erformance and accelerate the identification of the global optim um. 28 D Detailed Exp erimen ts D.1 Baselines DSPy DSPy ( Khattab et al. , 2023 ) is a declarativ e framework designed for mo dularizing and optimizing Large Language Mo del (LLM) pip elines. It provides a structured approach to prompt engineering by treating prompts as learnable parameters within a programmatic workflo w. It can also b e adapted to optimize general-purp ose string-based programs with well-defined rew ards and feedbac k. In our exp erimen ts, we use a dspy.ChainOfThought mo dule to implement a sequential revision search algorithm, which alwa ys takes the current parameter with its score and feedbac k to prop ose a new parameter at each step. In the following we use DSPy to denote such a search algorithm. GEP A GEP A (Genetic-Pareto Prompt Optimizer) is a reflective prompt optimization algorithm recen tly integrated into the DSPy ecosystem ( Agraw al et al. , 2025 ). W e apply it here to more div erse generative optimization problems b ey ond prompt tuning by simply treating the optimizable parameter as a string. It maintains a Par eto fr ontier of parameters to track non-dominated solutions across different training instances, lev eraging natural language reflection to iteratively impro ve parameters through trial and error. Op enEv olv e Op enEv olv e ( Sharma , 2025 ) is an op en-source implemen tation of AlphaEvolv e ( No viko v et al. , 2025 ), an autonomous evolutionary pip eline for algorithmic discov ery . W e could also utilize it to handle div erse generative optimization problems b ey ond co de evolution. It utilizes the MAP-Elites algorithm and island-based search to manage a p opulation of diverse, high-p erforming parameters through iterativ e ev aluation and selection. D.2 T ask F orm ulation and Implemen tation Details In this section, we describ e the formulation of generative optimization tasks across v arious domains and sp ecify the configuration for all ev aluated search algorithms. τ -b enc h τ -b enc h is a b enc hmark designed to ev aluate multi-turn agents on their ability to interact with h uman users, adhere strictly to domain-sp ecific p olicies, and execute to ols to resolve complex queries. The environmen t pro vides a sparse, binary reward r ∈ { 0 , 1 } for eac h program-task execution, indicating whether the user’s request was successfully resolved. W e utilize the first 10 tasks from the retail domain of τ -b enc h for optimization and the rest 145 tasks held out to test 11 the generalization of the optimized agent. The base agent (program) provided b y the b enchmark is parameterized via a string v ariable, additional_instructions , whic h is app ended to the original system prompt. Searc h algorithms learn optimized versions of additional_instructions through trial and error by reflecting on the accum ulated conv ersation history . F or our exp eriments w e use gemini-2.0-flash as the backbone mo del of agents, simulated users in τ -b enc h and optimizers in search algorithms, gemini/text-embedding-004 as the em b edding mo del for POLCA. W e do external tests to measure the p erformance of trained agen t instances from differen t searc h algorithms. The test score for a sp ecific agen t instance is computed by running 11 These tasks are exclusively used for the final ev aluation presented in T able 1 . Other external tests inv olve ev aluating the first 10 tasks multiple times to obtain a nearly deterministic score for the trained agents. 29 10 trials p er task and calculating the av erage pass rate across all tasks and trials 12 . F or all the searc h algorithms, we set the maxim um num b er of parallel ev aluation in one ev aluation step to b e 10 , meaning that when running the algorithm, at most 10 ev aluation could b e done in parallel at the same time. F or POLCA, we set num_candidates = 5 , batch_size = 2 , and num_batches = 1 . W e select the candidates with the highest mean scores for external tests. F or Op enEv olv e, we construct an ev aluator that runs the prop osed agent instance on all 10 tasks once and use the pass rate as the score. W e set the parallel_evaluations = 10 and max_workers = 1 , whic h means Op enEvolv e could ev aluate a agen t instance on 10 tasks in parallel but cannot ev aluate multiple agent instances in parallel. W e choose num_islands = 3 , migration_interval = 20 , and migration_rate = 0 . 1 to p erform island-based evolution. W e set num_top_programs = 3 and num_diverse_programs = 2 as the programs to include in the prompt. W e pick the candidate with the highest pass rate for external tests. F or GEP A, w e also c ho ose batch_size = 2 , and use all 10 tasks as the v alidation dataset. In the training pro cess it will maintain a pareto-frontier of non-dominated agen t instances for 10 tasks. F or external test, w e implemen t t wo wa ys to pic k the b est agent instances from the training of GEP A. Sp ecifically , we ev aluate t wo selection metho ds: 1) GEP A (most fr e q) , which selects the candidate app earing most frequen tly in the P areto frontier—this corresp onds to the agent achieving the highest pass rate ov er 10 tasks —and 2) GEP A (sample fr e q) 13 , which p erforms w eighted selection based on candidate app earance frequency in the pareto-fron tier. Results are av eraged o ver 6 random seeds, sho wing the mean and standard error for indep enden t runs in Figure 2 . Hotp otQA Hotp otQA ( Y ang et al. , 2018 ) is a multi-hop question answering dataset where each task requires reasoning across multiple context paragraphs to pro duce a short answer. W e use the distractor setting of Hotp otQA, taking the first 100 examples from the v alidation split as our b enc hmark. Eac h example consists of a question, 10 context paragraphs (of which 2–3 are relev ant and the rest are distractors), and a ground-truth answer. W e use gemini-2.5-flash-lite as the backbone mo del for task execution, and gemini-embedding-001 7 as the embedding mo del for POLCA. Correctness is determined by case-insensitive exact match or substring con tainment after stripping trailing punctuation, yielding a binary rew ard of 0 or 1 p er task. T est scores are computed b y ev aluating eac h candidate prompt on all 100 tasks with 5 indep enden t rep etitions p er task, and w e rep ort the a verage accuracy across rep etitions. F or GEP A, we use a reflection minibatch size of 10 with a budget of 2,000 metric calls p er run. F or Op enEv olv e, w e run 50 iterations with cascade ev aluation (a 20-sample first stage with a ≥ 50% threshold gating a full 100-sample second stage). F or POLCA, we set ε = 0 . 1 , num_candidates = 5 , batch_size = 2 , and num_batches = 1 . All algorithms use gemini-2.5-flash-lite for meta- optimization (reflection/prop osal generation). W e conduct 3 indep enden t runs p er algorithm and rep ort the mean and standard error. V eriBenc h (3-step ev aluation) V eriBench ( Miranda et al. , 2025 ) is a challenging domain for curren t LLMs due to their limited domain knowledge of Lean 4 programming. It ev aluates the capabilit y of LLMs to translate Python programs in to verifiable Lean 4 co de. Eac h task con tains one Python program and a golden Lean 4 program. LLMs are prompted to translate the Python program in to a compilable and semantically correct Lean 4 program. W e formalize this problem by treating the en tire translated Lean 4 program as the parameter, i.e., P θ ( x ) ≡ θ , resulting in a fully deterministic program execution. 12 Here test score of each agent instances is an av erage of 100 trials, which serves as an accurate measure of p erformance. 13 This metric is utilized to select the programs for exploration within GEP A. 30 W e select the easy_set (41 tasks) from V eriBench and optimize for each individual task, utilizing a sequen tial three-step ev aluation pro cess for eac h Lean 4 program. F or each candidate, the program is first pro cessed b y a Lean 4 compiler within a Lean 4 RL environmen t accessed via PyPan tograph ( Aniv a et al. , 2025 ). The compiler returns a binary score; if compilation fails, the compiler error is captured as textual feedback. A candidate only pro ceeds to the subsequen t stage if it successfully passes the current chec k. If compilation succeeds, the program is ev aluated against sev eral unit tests to determine if the Lean 4 translation is semantically correct and functionally equiv alen t to the original Python program. Finally , only programs that pass b oth the compiler and the unit tests are assessed by an LLM judge. The judge compares the translated Lean 4 program with the ground-truth implementation, assigning a score from 0 to 30. Consequen tly , programs that fail at earlier stages receive a score of zero. This LLM-based score is subsequently normalized to [0 , 1] for use in the optimization pro cess. Since this three-step ev aluation is progressive, we design a n umerical reward signal to determine the final p erformance of the prop osed agent instances. The rew ard r ∈ [0 , 1] is defined as: r = 0 . 3 · 1 Compilation + 0 . 3 · 1 Unit tests + 0 . 4 · r LLM . While the first t wo phases are fully deterministic, the final comp onen t in tro duces sto chasticit y through the score and feedbac k provided by the LLM judge. W e use claude-3.5-sonnet as the backbone for searc h algorithms and LLM judge, and gemini/text-embedding-004 as the embedding mo del, ev aluating DSPy , GEP A, Op enEv olve, and POLCA. F or all the search algorithms, we set the maximum num b er of parallel ev aluation in one ev aluation step to b e 5 , meaning that when running the algorithm, at most 5 ev aluation could b e done in parallel at the same time. F or GEP A, we set batch_size = 1 and use the single task under optimization as the v alidation dataset. F or Op enEv olve, w e set num_islands = 1 and num_workers = 5 for simplicity . F or our POLCA v arian ts, we set the exploration budget k = 5 and the div ersity threshold ε = 0 . 02 . W e compare algorithms by measuring the pass rate achiev ed ov er the tasks within a fixed budget. F or each algorithm, w e p erform the searc h across all 41 tasks indep enden tly , with a maxim um budget of 50 compiler calls p er task. W e calculate the av erage score ov er all tasks at each step and for eac h n umber of metric calls. T o ensure statistical reliability , we rep eat the exp erimen ts three times and rep ort the mean and standard error across these runs. V eriBench (Compilation) W e utilize the complete V erib enc h dataset, consisting of all 140 tasks, fo cusing sp ecifically on the compilation stage. This remains a c hallenging domain given the limited Lean 4 programming knowledge inherent in curren t LLMs. F or this analysis, w e define the reward as a binary indicator of compilation success, r = 1 Compilation ∈ { 0 , 1 } , while all other exp erimen tal settings remain unchanged. W e run each search algorithm on the 140 tasks indep enden tly and rep eat the exp erimen ts three times. KernelBenc h CUD A kernel optimization is also a p opular domain in generativ e optimization problems. In this part, we pick 16 matrix multiplication tasks from KernelBench (level 1) ( Ouyang et al. , 2025 ), which app ear simple but remain challenging. As mentioned in Y an et al. ( 2026 ), these tasks are already highly optimized in PyT orch, making it difficult to ac hieve further sp eedups. W e use the claude-3.7-sonnet mo del and the gemini-embedding-001 em b edding mo del. F or GEP A, we set batch_size = 1 and use the single task under optimization as the v alidation dataset. F or Op enEv olve, we set num_islands = 1 and num_workers = 5 for simplicit y . F or our POLCA 31 v ariants, we set the exploration budget k = 5 and the div ersity threshold ε = 0 . 02 . The kernel ev aluation is executed on an L40S GPU, with each ev aluation result b eing an a verage of five rep eated executions. W e contin ue to p erform p er-task optimization; as the programs b eing optimized are the k ernel programs themselves, there is no sto c hasticit y in execution or minibatc h sampling. Although minor noise in co de execution sp eed exists, we hav e confirmed that this v ariance is negligible for the optimization pro cess. W e utilize the fast p score ( Ouy ang et al. , 2025 ) defined as: fast p = 1 N N X i =1 1 ( correct i ∧ { speedup i > p } ) , where p is the sp eedup threshold relativ e to the PyT orc h baseline. This metric measures the prop ortion of tasks for which the algorithm prop oses a correct CUD A program with a sp eedup exceeding p . Here, N = 16 for our selected tasks. D.3 Ev aluation Metrics The primary b ottlenec k in generativ e optimization v aries significantly across domains. F or most sto c hastic problems addressed in this pap er, ev aluating a single program is exp ensive due to inheren t noise and the computational cost of the ev aluation function. While the main pap er fo cuses on ev aluation steps, we pro vide a more comprehensive analysis here by considering additional dimensions of complexit y . Num b er of metric calls (Computational complexit y) Ev aluating proposed programs is resource-in tensive. By fixing the total n umber of metric calls, we compare the efficiency of different searc h algorithms within a strict computational budget. Num b er of ev aluation steps (Time complexity) W e define an evaluation step as a unit where all constituen t metric are executed in parallel. This metric measures the num b er of sequential op erations required, serving as a proxy for wall-clock time. Ho wev er, in domains where ev aluation is relativ ely inexp ensiv e, the b ottleneck shifts to the prop osal pro cess. T o provide a m ultidimensional comparison, we introduce: Num b er of prop osals (Computational complexity) Generating new candidates requires substan tial compute. By fixing the num b er of prop osals, we ev aluate how effectively each algorithm utilizes its generativ e budget. Num b er of prop osal steps (Time complexity) In each pr op osal step , LLM API calls for program generation are parallelized. This metric coun ts the sequen tial op erations required for generation. T o ensure fairness, we imp ose a maxim um num b er of parallel prop osals p er step across all algorithms. F or all exp erimen ts, we complement the ev aluation step analysis with plots based on these additional metrics to pro vide deep er insights into search efficiency . Results are presented in Figures 4 to 7 . Discussion Due to its parallelized batch up date design, POLCA consistently outp erforms baselines in terms of prop osal and ev aluation steps. When considering the total computational budget, suc h as the num b er of metric calls and prop osals, POLCA maintains strong final p erformance but may lag b ehind sequential metho ds in the early stages of search. 32 On V eriBenc h, for instance, POLCA outp erforms all parallelized baselines in total metric calls, though it remains slightly b elo w sequential DSPy initially . This o ccurs b ecause batc h-oriented algorithms are designed for low latency and utilize less cum ulative information p er step compared to sequen tial up dates. F or example, with a budget of 10 metric calls, DSPy can p erform 10 sequential revisions, reaching a searc h tree depth of 10. Con versely , POLCA may ev aluate 5 candidates in parallel ov er 2 steps. While the computational cost is identical, POLCA significantly reduces the required sequen tial time. Similarly , on KernelBench, while POLCA consisten tly surpasses baselines in terms of time budget, it do es not consistently outp erform sequential GEP A when measured by total metric calls. This underscores the inherent trade-off in batch design; sequential metho ds can ac hieve greater search depth for the same computation budget, whereas POLCA prioritizes minimizing wall-clock time through parallel execution and batch-informed optimization. 0 200 400 600 800 1000 1200 Number of Metric Calls 0.35 0.40 0.45 0.50 0.55 0.60 0.65 T est Score - b e n c h T e s t S c o r e GEP A (Most F r equent) GEP A (Sample by F r eq) OpenEvolve POLCA (Ours) 0 25 50 75 100 125 150 175 200 Proposal Step 0.35 0.40 0.45 0.50 0.55 0.60 0.65 T est Score - b e n c h T e s t S c o r e GEP A (Most F r equent) GEP A (Sample by F r eq) OpenEvolve POLCA (Ours) 0 25 50 75 100 125 150 175 200 Number of Proposals 0.35 0.40 0.45 0.50 0.55 0.60 0.65 T est Score - b e n c h T e s t S c o r e GEP A (Most F r equent) GEP A (Sample by F r eq) OpenEvolve POLCA (Ours) Figure 4: τ -b enc h: p erformance vs. n umber of samples (left), prop osal steps (middle), and num ber of prop osals (righ t). Solid curves represent the av erage highest score attained at each step, while the shaded regions denote the standard error across multiple indep endent runs (6 seeds). 0 500 1000 1500 2000 2500 Number of Metric Calls 0.70 0.75 0.80 0.85 0.90 0.95 1.00 T est Score HotpotQA T est Score GEP A OpenEvolve POLCA (Ours) 0 20 40 60 80 Proposal Step 0.70 0.75 0.80 0.85 0.90 0.95 1.00 T est Score HotpotQA T est Score GEP A OpenEvolve POLCA (Ours) 0 100 200 300 400 Number of Proposals 0.70 0.75 0.80 0.85 0.90 0.95 1.00 T est Score HotpotQA T est Score GEP A OpenEvolve POLCA (Ours) Figure 5: HotpotQA: p erformance vs. num b er of samples (left), prop osal steps (middle), and num b er of prop osals (righ t). Solid curves represent the av erage highest score attained at each step, while the shaded regions denote the standard error across multiple indep endent runs (3 seeds). 0 20 40 60 80 Number of Metric Calls 0.0 0.2 0.4 0.6 0.8 1.0 Score V eriBench (3-step evaluation) Score DSPy GEP A OpenEvolve POLCA (Ours) 0 10 20 30 40 50 Proposal Step 0.0 0.2 0.4 0.6 0.8 1.0 Score V eriBench (3-step evaluation) Score DSPy GEP A OpenEvolve POLCA (Ours) 0 20 40 60 80 100 Number of Proposals 0.0 0.2 0.4 0.6 0.8 1.0 Score V eriBench (3-step evaluation) Score DSPy GEP A OpenEvolve POLCA (Ours) Figure 6: V eriBench: p erformance vs. num b er of samples (left), prop osal steps (middle), and num b er of prop osals (righ t). Solid curves represent the av erage highest score attained at each step, while the shaded regions denote the standard error across multiple indep endent runs (3 seeds). 33 0 10 20 30 40 50 Number of Metric Calls 0.0 0.2 0.4 0.6 0.8 1.0 f a s t 1 . 0 S c o r e K e r n e l B e n c h f a s t 1 . 0 S c o r e DSPy GEP A OpenEvolve POLCA (Ours) 0.0 2.5 5.0 7.5 10.0 12.5 15.0 17.5 20.0 Proposal Step 0.0 0.2 0.4 0.6 0.8 1.0 f a s t 1 . 0 S c o r e K e r n e l B e n c h f a s t 1 . 0 S c o r e DSPy GEP A OpenEvolve POLCA (Ours) 0 10 20 30 40 50 Number of Proposals 0.0 0.2 0.4 0.6 0.8 1.0 f a s t 1 . 0 S c o r e K e r n e l B e n c h f a s t 1 . 0 S c o r e DSPy GEP A OpenEvolve POLCA (Ours) Figure 7: KernelBenc h: p erformance vs. num b er of samples (left), prop osal steps (middle), and num b er of proposals (righ t). Solid curves represent the av erage highest score attained at each step (1 seed). D.4 Compilation Rate Study on V eriBenc h W e ev aluate algorithms on V eriBench (Compilation). Figure 8 compares compilation rates across differen t ev aluation metrics, where POLCA consistently outp erforms all baselines. 0 10 20 30 40 50 Evaluation Step 0.0 0.2 0.4 0.6 0.8 1.0 Score V eriBench (Compilation) P ass Rate DSPy GEP A OpenEvolve POLCA (Ours) 0 10 20 30 40 50 Number of Metric Calls 0.0 0.2 0.4 0.6 0.8 1.0 Score V eriBench (Compilation) P ass Rate DSPy GEP A OpenEvolve POLCA (Ours) 0 10 20 30 40 50 Proposal Step 0.0 0.2 0.4 0.6 0.8 1.0 Score V eriBench (Compilation) P ass Rate DSPy GEP A OpenEvolve POLCA (Ours) 0 10 20 30 40 50 60 Number of Proposals 0.0 0.2 0.4 0.6 0.8 1.0 Score V eriBench (Compilation) P ass Rate DSPy GEP A OpenEvolve POLCA (Ours) Figure 8: V eriBench (Compilation) results: Plots show the compilation rate ov er 140 tasks relative to num b er of ev aluation steps, metric calls, proposal steps and prop osals, resp ectiv ely . Solid curves represent the av erage highest score attained at each step, while the shaded regions denote the standard error across multiple indep enden t runs (3 seeds). D.5 F ast 0 . 5 study on KernelBenc h F or KernelBenc h, we also provide a comparison using the pass 0 . 5 metric. This metric is significant b ecause PyT orch op erators are already highly optimized; therefore, generating custom CUDA k ernels from scratc h—rather than utilizing pre-wrapp ed PyT orch functions—that are b oth correct and reach half the execution sp eed of the PyT orch implemen tation represen ts a meaningful ac hievemen t in 34 automated k ernel synthesis. Figure 9 sho ws POLCA consisten tly outp erforms all baselines in terms of ev aluation and prop osal steps, as well as final p erformance. While POLCA demonstrates sup erior efficiency within a fixed time budget, it may not b e the most efficient at early stages when compared against computational budgets, such as the total n umber of metric calls and prop osals, particularly against sequen tial algorithms, for the same reasons discussed in Section D.3 . 0.0 2.5 5.0 7.5 10.0 12.5 15.0 17.5 20.0 Evaluation Step 0.0 0.2 0.4 0.6 0.8 1.0 f a s t 0 . 5 S c o r e K e r n e l B e n c h f a s t 0 . 5 S c o r e DSPy GEP A OpenEvolve POLCA (Ours) 0 10 20 30 40 50 Number of Metric Calls 0.0 0.2 0.4 0.6 0.8 1.0 f a s t 0 . 5 S c o r e K e r n e l B e n c h f a s t 0 . 5 S c o r e DSPy GEP A OpenEvolve POLCA (Ours) 0.0 2.5 5.0 7.5 10.0 12.5 15.0 17.5 20.0 Proposal Step 0.0 0.2 0.4 0.6 0.8 1.0 f a s t 0 . 5 S c o r e K e r n e l B e n c h f a s t 0 . 5 S c o r e DSPy GEP A OpenEvolve POLCA (Ours) 0 10 20 30 40 50 Number of Proposals 0.0 0.2 0.4 0.6 0.8 1.0 f a s t 0 . 5 S c o r e K e r n e l B e n c h f a s t 0 . 5 S c o r e DSPy GEP A OpenEvolve POLCA (Ours) Figure 9: Performance comparison across 16 kernel optimization tasks. Plots show the fast 0 . 5 score relative to n umber of ev aluation steps, metric calls, prop osal steps, and proposals, resp ectiv ely . Solid curves represent the av erage highest score attained at each step (1 seed). D.6 More Ablation Results In this section, we provide additional results from our ablation study . Figure 10 sho ws the ablation on the ε -Net and Summarizer features of POLCA, while Figure 11 presents the ablation study on ε v alues. 0 25 50 75 100 125 150 175 200 Evaluation Step 0.35 0.40 0.45 0.50 0.55 0.60 0.65 Score - b e n c h T e s t S c o r e vanilla POLCA vanilla POLCA+ -Net vanilla POLCA+Summarizer vanilla POLCA+ -Net+Summarizer 0 20 40 60 80 100 Proposal Step 0.35 0.40 0.45 0.50 0.55 0.60 0.65 Score - b e n c h T e s t S c o r e vanilla POLCA vanilla POLCA+ -Net vanilla POLCA+Summarizer vanilla POLCA+ -Net+Summarizer 0 100 200 300 400 500 Number of Proposals 0.35 0.40 0.45 0.50 0.55 0.60 0.65 Score - b e n c h T e s t S c o r e vanilla POLCA vanilla POLCA+ -Net vanilla POLCA+Summarizer vanilla POLCA+ -Net+Summarizer Figure 10: Ablation on ε -Net and Summarizer. Solid curves represent the av erage highest score attained at each step, while the shaded regions denote the standard error across multiple indep enden t runs (6 seeds). 35 0 5 10 15 20 25 30 Evaluation Step 0.30 0.35 0.40 0.45 0.50 0.55 Score - b e n c h T e s t S c o r e = 0.0 = 0.05 = 0.1 = 0.15 = 0.2 = 0.25 = 0.3 0.0 2.5 5.0 7.5 10.0 12.5 15.0 17.5 20.0 Evaluation Step 0.0 0.2 0.4 0.6 0.8 1.0 Score V eriBench (3-step evaluation) Score = 0.0 = 0.02 = 0.05 = 0.07 = 0.1 Figure 11: Ablation study on ε -v alues (first tw o panels for τ -b enc h; last panel for V eriBench). Solid curves represent the av erage highest score attained at each step, while shaded regions denote the standard error across 3 indep endent seeds. D.7 Wh y Not Use Regression? In large-scale generative optimization, the search pro cess often yields reward observ ations for a wide v ariety of programs. A naive approach is to ev aluate each program separately and estimate its rew ard indep endently . How ev er, due to the inheren t sto c hasticity of these observ ations, such an approac h can require a prohibitively large ev aluation budget to achiev e precision. A natural alternative is to use function approximation by training a reward mo del that maps a program’s em b edding to its exp ected reward: ψ ◦ ϕ : Θ → R , where ϕ maps a program to an embedding vector, and ψ predicts a reward in [0 , 1] . The goal is for such a mo del to generalize across the program space, leveraging the entire dataset to estimate the reward of any given program. This is particularly app ealing b ecause similar programs likely yield similar rewards; thus, a learned predictor might provide more robust estimates than a noisy empirical mean, esp ecially for programs with few observ ations. T o train this mo del, we collect a dataset of embedding–reward pairs { ( ϕ ( θ j ) , r j ) } N j =1 , where eac h reward observ ation r j ∈ { 0 , 1 } is binary . W e instantiate ψ as a logistic regression mo del parameterized b y ( w , b ) : ψ ( z ) = σ ( w ⊤ z + b ) , z ∈ R d , where σ ( z ) = 1 / (1 + e − z ) is the sigmoid function. The predicted reward for a program θ is then: ( ψ ◦ ϕ )( θ ) = σ ( w ⊤ ϕ ( θ ) + b ) . W e optimize the parameters ( w , b ) by minimizing the regularized empirical risk: L ( w , b ) = − 1 N N X j =1 h r j log σ ( w ⊤ ϕ ( θ j ) + b ) + (1 − r j ) log 1 − σ ( w ⊤ ϕ ( θ j ) + b ) i + λ 2 ∥ w ∥ 2 2 , where λ > 0 is the regularization parameter. 36 T o further reduce v ariance and enhance diversit y , we emplo y an ensem ble of five regressors, each trained on a randomly sampled subset of the data. These mo dels predict scores for all programs stored in the priority memory Q . F or each program θ ∈ Q , let b p k ( θ ) b e the prediction of the k -th regressor and b µ ( θ ) b e the empirical mean reward based on its existing samples. W e then compute four candidate scores: S emp ( θ ) = b µ ( θ ) , S max ( θ ) = max 1 ≤ k ≤ 5 b p k ( θ ) , S mean ( θ ) = 1 5 5 X k =1 b p k ( θ ) , S min ( θ ) = min 1 ≤ k ≤ 5 b p k ( θ ) . A cross v arious training set sizes N , we select the program with the highest score for each metric and sub ject it to additional external testing for a more precise reward estimate. How ev er, our results ( Figure 3(d) ) show that the naive strategy—selecting programs based solely on the empirical mean—consisten tly outp erforms all regressor-based criteria. This suggests that, in this sp ecific optimization setting, the regression mo del fails to provide sufficien tly reliable generalization to surpass simple empirical estimation. D.8 T oken Usage Estimation W e ev aluate the token consumption of the generative optimization pro cess by monitoring a single run of POLCA, using the configuration detailed in Section D.2 , across the τ -b enc h, Hotp otQA, V eriBench, and KernelBench b enc hmarks. This estimation is limited to the tokens utilized by the searc h pip eline and excludes LLM calls inv oked within the optimizing programs themselv es. F or τ -b enc h, a single run (100 iterations) requires 30,822,470 input tokens and 380,240 output tokens, totaling 31,202,710 tokens. F or Hotp otQA, a single run (100 iterations) requires 4,739,242 input tok ens and 1,801,051 output tokens, totaling 6,540,293 tokens. F or V eriBenc h, a single run (10 iterations) on a single task requires 554,900 input tokens and 79,145 output tokens, totaling 634,045 tok ens. F or KernelBenc h, a single run (10 iterations) on a single task requires 477,186 input tokens and 93,432 output tok ens, totaling 570,618 tokens. E Optimized Program Case Studies In this section, we provide representativ e examples of programs optimized using POLCA on the τ -b enc h, V eriBenc h, and KernelBench b enc hmarks. These cases illustrate the ability of our generative optimization framew ork to disco ver high-p erforming solutions across diverse domains, from multi-turn agen tic reasoning to formal verification and hardware-lev el p erformance tuning. E.1 τ -b enc h In τ -b enc h, w e formalize the search problem by app ending a trainable string to the original system prompt of the agent as p ar ameters ; this string is initialized as the original instruction pr ompt and trained using generativ e optimization algorithms. 37 Original Instruction Prompt Here are the additional instructions to help the agent solve the task: T rained Prompt from POLCA Here are the additional instructions to help the agent solve the task: • IMPOR T ANT: Only ONE order can b e mo dified or exc hanged p er con versa- tion. Inform the user of this limit at the b eginning of the interaction. If the user men tions mo difying items in multiple orders, inform them that only ONE order can b e mo dified. Ask them to choose the order they w ant to mo dify . Then pro ceed with mo difying only that order. Remind the user of this limitation b efore presen ting an y pro duct options or pro ceeding with any mo difications. Begin the conv ersation b y stating this limitation. • Prioritize verifying user identit y at the b eginning of the conv ersation, with email as the primary metho d. If email verification fails, double-che ck the email addr ess pr ovide d with the user , and if it’s incorrect, offer alternative authentication metho ds (first name, last name, zip co de) only after email verific ation definitively fails . Implement a more robust retry mec hanism if the initial attempt fails, re trying up to three times. If email verific ation p ersistently fails after multiple attempts, pr o c e e d with name/zip c o de verific ation but inform the user that email verific ation is pr eferr e d for se curity purp oses. Con tinue verifying identit y throughout the conv ersation. Do not pro ceed with any order-related actions un til the user’s identit y is confirmed. If the user is suc c essful ly identifie d by name and zip c o de, offer to up date their user pr ofile with the c orr e ct email addr ess, if available, to str e amline futur e inter actions. Explicitly offer to save the email addr ess to the user pr ofile to str e amline futur e inter actions. If the user pr ovides a new email addr ess, use update_user_email to ol to up date the user’s pr ofile. AL W A YS up date the user pr ofile with the email addr ess if they ar e authentic ate d via name/zip. Only attempt user identification by name/zip after email verification has failed. Explicitly state the imp ortanc e of pr oviding ac cur ate information for suc c essful identific ation. If the user has priv acy concerns, explain that identit y v erification is for their protection and to preven t unauthorized access to their account. If the email is incorrect or not found, pr ovide a sp e cific err or message to the user, such as: “I’m sorry, but I c ouldn ’t find a user with that email addr ess. Could you ple ase double-che ck the email addr ess you pr ovide d? It’s imp ortant to pr ovide ac cur ate information for suc c essful identific ation. Ple ase c onfirm your email or pr ovide your first name, last name and zip c o de.” • Immediately after user identification, b efore pro ceeding with any requests, offer the user a summary of av ailable actions: “Ok ay , Y usuf, now that I’ve v erified y our identit y , I can help you with the following: modify a p ending order, cancel a p ending order, return a delivered order, or exchange a deliv ered order. Whic h action w ould you like to take?” • When the user asks to mo dify or exc hange an order, esp ecially regarding item character- istics (color, size, material, st yle, brightness, compatibility), pr o actively ask for the order ID and the item IDs of the items they want to mo dify or exchange . Remind the user that only a single exchange or mo dification call is av ailable p er order, so it’s imp ortan t to include ALL desired c hanges in one request. Gather ALL the necessary details ab out the desired options BEFORE attempting to find matching items. Remind the user that 38 exc hange or mo dify order to ols can only b e called once p er order. Sp e cific al ly, c onfirm the item ID, the attributes of the old items, and the attributes of the new items. If the user is unsure which order contains the items, offer to search their order history using their user ID and present the conten ts of each order to the user to help them identify the correct one. • Immediately after the user provides an order ID, call get_order_details to proactively v alidate the order’s existence, conten ts, and status. Flag any discr ep ancies b et ween the user’s request and the actual order details and ask them to verify . Clarify any discrepancies with the user b efore pro ceeding. Sp e cific al ly, c onfirm that ALL items the user wants to mo dify, exchange, or r eturn ar e actual ly in the identifie d or der. Before confirming the items, AL W A YS c hec k the order status to ensure the requested action (mo dification, exc hange, return) is p ossible given the current order status. Pr esent the or der details (c ontents, status, shipping addr ess) to the user and ask them to c onfirm everything is ac cur ate b efor e pr o c e e ding. Che ck if the or der status even supp orts the r e quest (e.g. p ending for mo dific ations, deliver e d for exchanges or r eturns). If the order has already b een delivered or cancelled, inform the user that y ou cannot mo dify it. If the user do esn’t kno w the order ID or item IDs, pr o actively offer to retriev e order details using their user ID. If the user pr ovides an or der ID but the items they mention ar e not in that or der, ask the user to double-che ck the or der ID and c onfirm if the liste d items ar e inde e d in that or der. V alidate the or der details and explicitly ask the user to c onfirm the c orr e ctness of item names, quantities, and attributes. Before listing pro duct t yp es for returns or exchanges, confirm the order ID and item IDs related to the return or exc hange. • If a to ol, such as search_items , fails or returns an error, inform the user that the to ol is unav ailable and offer an alternative approach. DO NOT use search_items as it is curr ently unr eliable. Prioritize using get_product_details to obtain sp e cific item details b efor e r esorting to list_all_product_types . If the search_items to ol fails, y ou can try offering an alternative solution, such as connecting the user with a human agen t or using differen t search parameters. How ever, transfer only after exhausting all av ailable strategies and to ol calls. If a to ol fails, inform the user that the to ol is una v ailable and offer an alternativ e approach. F or example, offer to list av ailable options for each attribute (color, size, material, st yle) individually using get_product_details and ask the user to c ho ose from the av ailable options. If get_product_details also fails, suggest that the user browse our online catalog and provide the item ID. Do NOT guess or pro ceed without confirming the correct item ID. If list_all_product_types r eturns an empty dictionary, inform the user that ther e ar e curr ently no pr o ducts of that typ e available and ap olo gize for the inc onvenienc e. • When presenting pro duct options for an exc hange or mo dification, alw a ys use the information from get_product_details and include the item ID, features, price, and a v ailabilit y . If an item is una v ailable, clearly state that and offer alternatives. Do not men tion that the pro duct options are unav ailable until all pro duct options are displa yed. When presenting options, display a maximum of 5 options at a time for b etter user exp erience. • Alw ays clarify with the user BEF ORE using exchange_items or modify_pending_order_items . Explicitly state and c onfirm al l identifie d items and their attributes, and the desir e d changes, b efor e using the to ol. Before calling the 39 to ol, rep eat the action b eing taken: “Y ou are exc hanging item A for item B, and your card C will b e charged $X. Is this correct?”. Alwa ys confirm the exchange/modification details with the user b efore executing the final to ol call. This confirmation should include the items being exc hanged/mo dified, the new items (with all their c haracteristics), and the paymen t metho d for any price difference. R emind the user that exchange and mo dify or der to ols c an only b e c al le d onc e, so al l desir e d changes must b e include d in a single r e quest. After the to ol c al l, r ep e at the c onfirmation with the user b efor e finalizing. Ensur e the agent gathers al l ne c essary information b efor e attempting to c al l the exchange_items or modify_pending_order_items to ol. • Be sure to c heck the order status before taking actions like cancelling, modifying, returning, or exchanging. Actions are generally only p ossible on p ending or deliv ered orders. Clarify which actions ar e available for e ach or der status. Implemen t robust order v erification steps to ensure the identified order matches the user’s intended items. Sp e cific al ly, for r eturns, ensur e the or der status is ‘deliver e d’ b efor e attempting to pr o c ess the r eturn. • Before asking for a pa yment metho d, pro cess all pro duct options and confirm the user’s selection. A p ayment metho d is only r e quir e d if ther e is a pric e differ enc e or if r e quir e d by the to ol itself. Do not ask for a p ayment metho d if ther e is no pric e differ enc e and the to ol do esn ’t explicitly r e quir e it. • A lways validate with the user: V alidate al l details of the identifie d or der b efor e making changes, clarify any ambiguities b efor e acting. • When dealing with returns, imme diately ask for the or der ID and item IDs . Then, confirm all of the information, like order id and items to b e returned, b efore listing all of the pro duct types. • Handle m ultiple requests or orders within a single conv ersation step-b y-step. Complete one action fully b efore mo ving on to the next. If the user is indecisive, summarize the curren t state, options, and consequences to guide them. If the user changes sc op e often, r emind the user of the single-exchange/mo dific ation limit to guide them. If the user is inde cisive or changes their mind fr e quently, summarize the c onfirme d details (or der ID, items, r e queste d actions) and r e quir e explicit c onfirmation b efor e pr o c e e ding. • If the user provides an incorrect order ID, p olitely inform them of the p oten tial mistak e and offer to lo ok up their orders using their user ID to confirm the correct order ID. If the user provides the wrong item IDs, offer the user to find the item IDs on the website and suggest finding them no w b efore moving on. • Implement a lo op to help the user sele ct and identify the c orr e ct item by cr oss-che cking the details pr ovide d by the user or other items in the or der. • When the user asks for the numb er of available options for a pr o duct (e.g., t-shirts), use get_product_details to r etrieve the pr o duct’s variants. Count the numb er of variants wher e “available”: true, and then inform the user of the total c ount of available options. Prioritize answ ering this request b efore handling other requests from the user. Count the num b er of v ariants where “a v ailable”: true, and then inform the user of the total count of a v ailable options. In the example, there are 10 t-shirt options currently av ailable. There are 12 v arian ts listed, and 2 of them are una v ailable. After c ol le cting item and or der details, cr e ate a summary of al l c onfirme d items, attributes, desir e d changes, and the p ayment metho d. R e quir e explicit user c onfirmation (e.g., “So, 40 to c onfirm, you want to exchange item A (size M, blue) for item B (size L, r e d), and the pric e differ enc e of $X wil l b e char ge d to your c ar d ending in 1234. Is that c orr e ct?”) b efor e pr o c e e ding. • If the user men tions mo difying items in multiple orders, inform them that only ONE order can b e mo dified. Ask them to c ho ose the order they w ant to mo dify . Then pro ceed with m odifying only that order. • Before pro ceeding with mo difications, AL W A YS chec k the order status. If the order status is not ‘p ending’, inform the user that the order cannot b e mo dified. Befor e c al ling any to ol, the agent should say, “Just to c onfirm, I have the fol lowing information: ... Is this c orr e ct?” If any information is missing, ask the user to pro vide it b efore pro ceeding. E.2 Hotp otQA In Hotp otQA, we optimize the prompt for the question-answering task. Belo w, we present the original pr ompt alongside a tr aine d pr ompt generated b y POLCA. Original Prompt Answ er the question based on the context. T rained Prompt from POLCA Carefully read the provided con text and the question. Systematically break down the question in to its constituent parts and identify all required information. F or m ulti-hop reasoning questions, meticulously do cumen t the entire reasoning path b efore providing the final answ er. This path must: 1. Deconstruct the question into a series of sub-questions or iden tify k ey in termediate facts/en tities required. 2. Detail the retriev al of relev ant information for each sub-question or intermediate comp o- nen t. 3. Explicitly demonstrate the logical connections and dep endencies b et ween the retriev ed pieces of information, forming a coheren t reasoning c hain. F or example, explain how F act A leads to F act B, which is then used with F act C to infer a conclusion. 4. Syn thesize these interconnected facts and intermediate conclusions to directly address and answ er the main question. Answ er F ormatting Rules: 1. Direct Retriev al Questions: If a question solely asks for a sp ecific entit y name, n umerical v alue, or factual item, provide only that exact, complete identifier or fact as presented in the context. Do not include any pream ble, explanation, or supp orting details. 2. En tit y Identification: F or questions asking to identify an entit y , the primary answer m ust b e the exact, complete identifier as presented in the context. This primary answ er m ust b e stated first and without preamble. If the question implies a need for elab oration b ey ond the direct iden tification, supp orting details from the context should follow. 3. Concept/Practice/Metho d Identification: F or questions asking to identify a prac- 41 tice, metho d, or concept, the primary answer must b e the most appropriate conceptual term or category from the context, stated first and without preamble. Supp orting details from the context that elab orate on this concept should follow. A void answ ering with only descriptiv e details if a sp ecific term exists. 4. Comparativ e Questions (Lo cations): Explicitly analyze and differentiate b et ween geographical lev els (e.g., city , district, neighborho o d). Do not infer ’same’ based solely on a broader shared con text. 5. Numerical Data: • Prioritize sp ecific, qualified figures. • If the question directly asks for a n umerical v alue, present the most sp ecific, qualified figure av ailable in the con text upfront as the primary answ er, without pream ble. • If the requested scop e (e.g., country p opulation) is not directly a v ailable but a relev ant sub-unit’s data is (e.g., count y p opulation), first state that the requested broad-scop e information is not a v ailable. Then, provide the qualified sub-unit figure, clearly qualifying it as b elonging to that sub-unit. • Clearly qualify all n umerical data presented. 6. Binary Answers (Y es/No): Provide the direct binary answ er clearly and upfront, follo wed by supp orting details that justify the conclusion. 7. Handling Questions with Fla w ed Premises: If the question’s premise con tains a factual inaccuracy (e.g., refers to a song as an album), the agen t must address this directly . The resp onse should: • State that the requested entit y type (e.g., “album”) is not found as describ ed in the con text. • Iden tify the correct entit y t yp e (e.g., “song”) and pro vide its relev an t details from the con text. • If applicable, pro vide information ab out the containing album (name and release date), clearly distinguishing it from the song. • This structured explanation takes precedence ov er Rule 1 when a flaw ed premise is detected. 8. Handling Am biguity and Undersp ecified Questions: • If a question can hav e multiple v alid answ ers based on the con text, first attempt to resolv e the ambiguit y using the following prioritized strategies: 1. Prioritize Explicit/Unique Links: Select t he option most directly or uniquely link ed to the question’s criteria. 2. Prioritize Prominence/Emphasis: If the context highligh ts a sp ecific en tity , use this as a tie-break er. 3. Prioritize Order of App earance: If no other criteria apply , select the first v alid option encountered in the text. • If a definitive single choice cannot b e made after applying these strategies, state that multiple answers exist and list them clearly , qualifying that the question w as undersp ecified. F or example: “There are m ultiple v alid answers fitting this description. One is [Answer A]. Another is [Answer B].” Pro vide a complete, fully qualified, and verifiable answer that directly addresses all parts of the question, synthesized from the context. Ensure answers are comprehensiv e and include all necessary qualifiers, esp ecially for lo cation-based queries. 42 E.3 V erib enc h In V eriBench, the goal is to translate Python programs into verifiable Lean 4 programs. W e utilize generativ e optimization algorithms to optimize for these Lean 4 programs directly , iteratively refining the formal co de to satisfy verification requirements. Below, we provide a concrete example (square function) of this pro cess. Input Python Program """Return the square of a natural number (non-negative integer). Edge cases: - square(0) = 0 - square(1) = 1 - The function raises ValueError if input is not a natural number. """ def pre(n: int) -> bool: """True iff the input is a non-negative integer.""" return isinstance(n, int) and n >= 0 def prog(n: int) -> int: """ Return n ² for non-negative integer n. Raises ValueError if the precondition is violated. """ if not pre(n): raise ValueError(f"Input must be a non-negative integer (got n={n})") return n * n # -- Tests -- from typing import Callable def check(candidate: Callable[[int], int]) -> bool: # Basic unit test assert candidate(3) == 9 # Edge unit test assert candidate(0) == 0 # Negative (pre-violations must raise ValueError) bad_inputs = [-1, 3.14] for n in bad_inputs: try: candidate(n) raise AssertionError("expected pre-violation did not raise") except ValueError: pass return True if __name__ == "__main__": assert check(prog), f"Failed: {__file__}" print("All tests passed.") 43 Initial Lean 4 Program -- Lean 4 translation of the Python program T rained Lean 4 Program /-! # Square Function This module implements a square function for natural numbers. ## Features: - Returns square of non-negative integers - Edge cases: square(0) = 0, square(1) = 1 - Input validation for natural numbers -/ namespace Square /-- **Implementation of ‘square‘.** ‘square n‘ returns the natural number n ² . ## Examples #eval square 3 -- expected: 9 #eval square 0 -- expected: 0 -/ def square (n : Nat) : Nat := n * n /-! # Tests -/ /-- Basic test: 3^2 = 9 -/ example : square 3 = 9 := by native_decide #eval square 3 -- expected: 9 /-! # Tests: Edge Cases -/ /-- Edge case: 0^2 = 0 -/ example : square 0 = 0 := by native_decide #eval square 0 -- expected: 0 /-- Edge case: 1^2 = 1 -/ example : square 1 = 1 := by native_decide #eval square 1 -- expected: 1 /-! # Positive / Negative Test-Suite -/ /-- positive: 4^2 = 16 -/ example : square 4 = 16 := by native_decide #eval square 4 -- expected: 16 44 /-- positive: 5^2 = 25 -/ example : square 5 = 25 := by native_decide #eval square 5 -- expected: 25 /-- negative: 2^2 != 5 -/ example : ¬ (square 2 = 5) := by native_decide #eval (decide (square 2 = 5)) -- expected: false /-- negative: 3^2 != 8 -/ example : ¬ (square 3 = 8) := by native_decide #eval (decide (square 3 = 8)) -- expected: false /-! # Pre-Condition -/ /-- **Pre-condition.** Input is non-negative (always true for Nat). -/ def Pre (n : Nat) : Prop := 0 <= n /-! # Property Theorems -/ /-- **Non-negativity property**: square of any natural number is non-negative. -/ def non_negative_prop (n : Nat) : Prop := 0 <= square n /-- **Non-negativity theorem** -/ theorem non_negative_thm (n : Nat) : non_negative_prop n := sorry /-- **Zero property**: square of zero is zero. -/ def zero_prop : Prop := square 0 = 0 /-- **Zero theorem** -/ theorem zero_thm : zero_prop := sorry /-- **One property**: square of one is one. -/ def one_prop : Prop := square 1 = 1 /-- **One theorem** -/ theorem one_thm : one_prop := sorry /-- **Multiplication property**: square equals number multiplied by itself. -/ def mult_prop (n : Nat) : Prop := square n = n * n /-- **Multiplication theorem** -/ theorem mult_thm (n : Nat) : mult_prop n := sorry /-! # Post-Condition -/ /-- **Post-condition**: conjunction of all desired properties for square. -/ def Post_prop (n : Nat) : Prop := (non_negative_prop n) /\ (mult_prop n) /\ zero_prop /\ one_prop 45 /-! # Correctness Theorem -/ /-- **Correctness theorem**: the pre-condition implies the post-condition. -/ theorem correctness_thm (n : Nat) (hPre : Pre n) : Post_prop n := sorry /-! # Imperative Implementation -/ /-- ‘squareImp n‘ computes the same square using accumulation. -/ def squareImp (n : Nat) : Nat := Id.run do let mut acc : Nat := 0 for _ in [:n] do acc := acc + n return acc /-! # Imperative Tests -/ /-- Basic test: imp 3^2 = 9 -/ example : squareImp 3 = 9 := by native_decide #eval squareImp 3 -- expected: 9 /-- Edge case: imp 0^2 = 0 -/ example : squareImp 0 = 0 := by native_decide #eval squareImp 0 -- expected: 0 /-- Edge case: imp 1^2 = 1 -/ example : squareImp 1 = 1 := by native_decide #eval squareImp 1 -- expected: 1 /-! # Implementation Equivalence -/ /-- **Equivalence theorem**: functional and imperative implementations coincide. -/ theorem square_equivalence_thm (n : Nat) : square n = squareImp n := sorry end Square E.4 KernelBenc h In KernelBench, the goal is to optimize custom CUD A kernels to outp erform baseline PyT orch implemen tations in terms of execution sp eed. Here, we provide a concrete example (batched matrix m ultiplication) of this optimization pro cess. 46 T ask Prompt You write custom CUDA kernels to replace the pytorch operators in the given architecture to get speedups. You have complete freedom to choose the set of operators you want to replace. You may make the decision to replace some operators with custom CUDA kernels and leave others unchanged. You may replace multiple operators with custom implementations, consider operator fusion opportunities (combining multiple operators into a single kernel, for example, combining matmul+relu), or algorithmic changes (such as online softmax). You are only limited by your imagination. Here’s an example to show you the syntax of inline embedding custom CUDA operators in torch: The example given architecture is: ‘‘‘ import torch import torch.nn as nn import torch.nn.functional as F class Model(nn.Module): def __init__(self) -> None: super().__init__() def forward(self, a, b): return a + b def get_inputs(): # randomly generate input tensors based on the model architecture a = torch.randn(1, 128).cuda() b = torch.randn(1, 128).cuda() return [a, b] def get_init_inputs(): # randomly generate tensors required for initialization based on the model architecture return [] ‘‘‘ The example new arch with custom CUDA kernels looks like this: ‘‘‘ import torch import torch.nn as nn import torch.nn.functional as F from torch.utils.cpp_extension import load_inline # Define the custom CUDA kernel for element-wise addition elementwise_add_source = """ #include #include 47 __global__ void elementwise_add_kernel(const float* a, const float* b, float* out, int size) { int idx = blockIdx.x * blockDim.x + threadIdx.x; if (idx < size) { out[idx] = a[idx] + b[idx]; } } torch::Tensor elementwise_add_cuda(torch::Tensor a, torch::Tensor b) { auto size = a.numel(); auto out = torch::zeros_like(a); const int block_size = 256; const int num_blocks = (size + block_size - 1) / block_size; elementwise_add_kernel<<>> (a.data_ptr(), b.data_ptr(), out.data_ptr(), size); return out; } """ elementwise_add_cpp_source = ( "torch::Tensor elementwise_add_cuda(torch::Tensor a, torch::Tensor b);" ) # Compile the inline CUDA code for element-wise addition elementwise_add = load_inline( name="elementwise_add", cpp_sources=elementwise_add_cpp_source, cuda_sources=elementwise_add_source, functions=["elementwise_add_cuda"], verbose=True, extra_cflags=[""], extra_ldflags=[""], ) class ModelNew(nn.Module): def __init__(self) -> None: super().__init__() self.elementwise_add = elementwise_add def forward(self, a, b): return self.elementwise_add.elementwise_add_cuda(a, b) ‘‘‘ You are given the following architecture: ‘‘‘ import torch import torch.nn as nn class Model(nn.Module): """ 48 Performs batched matrix multiplication (C = A * B) where A, B, and C have the same batch dimension. """ def __init__(self): super(Model, self).__init__() def forward(self, A: torch.Tensor, B: torch.Tensor) -> torch.Tensor: """ Performs batched matrix multiplication. Args: A: Input tensor of shape (batch_size, m, k). B: Input tensor of shape (batch_size, k, n). Returns: C: Output tensor of shape (batch_size, m, n). """ return torch.bmm(A, B) batch_size = 128 m = 128 * 4 k = 256 * 4 n = 512 * 4 def get_inputs(): A = torch.rand(batch_size, m, k) B = torch.rand(batch_size, k, n) return [A, B] def get_init_inputs(): return [] # No special initialization inputs needed ‘‘‘ Optimize the architecture named Model with custom CUDA operators! Name your optimized output architecture ModelNew. Output the new code in codeblocks. Please generate real code, NOT pseudocode, make sure the code compiles and is fully functional. Just output the new model code, no other text, and NO testing code! Initial CUD A Kernel # This is a dummy kernel code. You should replace it with your own kernel code based on the task prompt and optimization objectives. T rained CUDA Kernel import torch import torch.nn as nn from torch.utils.cpp_extension import load_inline # Define the custom CUDA kernel for batched matrix multiplication batched_matmul_source = """ #include #include #include 49 #define CHECK_CUDA(x) TORCH_CHECK(x.is_cuda(), #x " must be a CUDA tensor") #define CHECK_CONTIGUOUS(x) TORCH_CHECK(x.is_contiguous(), #x " must be contiguous") #define CHECK_CUBLAS(err) { cublasStatus_t status = (err); if (status != CUBLAS_STATUS_SUCCESS) { throw std::runtime_error("cuBLAS error: " + std::to_string(status)); } } // Singleton class to manage cuBLAS handle with TENSOR_OP math mode for automatic Tensor Core usage class CuBLASHandleManager { public: static cublasHandle_t& getHandle() { static CuBLASHandleManager instance; return instance.handle; } private: cublasHandle_t handle; CuBLASHandleManager() { CHECK_CUBLAS(cublasCreate(&handle)); // Enable Tensor Cores if available CHECK_CUBLAS(cublasSetMathMode(handle, CUBLAS_TENSOR_OP_MATH)); // Set stream for better asynchronous execution cudaStream_t stream; cudaStreamCreateWithFlags(&stream, cudaStreamNonBlocking); CHECK_CUBLAS(cublasSetStream(handle, stream)); } ~CuBLASHandleManager() { cudaStream_t stream; cublasGetStream(handle, &stream); cublasDestroy(handle); if (stream) cudaStreamDestroy(stream); } }; // Optimized batched matrix multiplication with specialized handling for common shapes torch::Tensor batched_matmul_cuda(torch::Tensor A, torch::Tensor B) { // Quick checks before proceeding CHECK_CUDA(A); CHECK_CUDA(B); const int batch_size = A.size(0); const int m = A.size(1); const int k = A.size(2); const int n = B.size(2); // Create output tensor auto C = torch::empty({batch_size, m, n}, A.options()); // Ensure input tensors are contiguous for best performance auto A_cont = A.contiguous(); auto B_cont = B.contiguous(); // Get data pointers float* A_data = A_cont.data_ptr(); float* B_data = B_cont.data_ptr(); 50 float* C_data = C.data_ptr(); // Get cuBLAS handle cublasHandle_t handle = CuBLASHandleManager::getHandle(); // Constants for cuBLAS call const float alpha = 1.0f; const float beta = 0.0f; // Use strided batch GEMM for maximum performance // cuBLAS uses column-major order while PyTorch uses row-major // To compute C = A * B in row-major, we compute C^T = B^T * A^T in column-major // Use cublasGemmStridedBatchedEx for better performance (supports mixed precision) CHECK_CUBLAS(cublasGemmStridedBatchedEx( handle, CUBLAS_OP_N, CUBLAS_OP_N, n, m, k, // Dimensions for column-major (swapped) &alpha, B_data, CUDA_R_32F, n, k * n, // B, data type, leading dimension, stride A_data, CUDA_R_32F, k, m * k, // A, data type, leading dimension, stride &beta, C_data, CUDA_R_32F, n, m * n, // C, data type, leading dimension, stride batch_size, // Number of matrices CUDA_R_32F, // Computation type CUBLAS_GEMM_DEFAULT_TENSOR_OP // Algorithm selection )); return C; } // Half-precision version for tensor cores torch::Tensor batched_matmul_half_cuda(torch::Tensor A, torch::Tensor B) { CHECK_CUDA(A); CHECK_CUDA(B); const int batch_size = A.size(0); const int m = A.size(1); const int k = A.size(2); const int n = B.size(2); // Convert to half precision if needed auto A_half = A.type().scalarType() == torch::ScalarType::Half ? A.contiguous() : A.contiguous().to(torch::ScalarType::Half); auto B_half = B.type().scalarType() == torch::ScalarType::Half ? B.contiguous() : B.contiguous().to(torch::ScalarType::Half); // Create output tensor in half precision auto C_half = torch::empty({batch_size, m, n}, A_half.options()); // Get data pointers __half* A_data = reinterpret_cast<__half*>(A_half.data_ptr()); __half* B_data = reinterpret_cast<__half*>(B_half.data_ptr()); __half* C_data = reinterpret_cast<__half*>(C_half.data_ptr()); // Get cuBLAS handle 51 cublasHandle_t handle = CuBLASHandleManager::getHandle(); // Constants for cuBLAS call const __half alpha = __float2half(1.0f); const __half beta = __float2half(0.0f); // Use cublasGemmStridedBatchedEx for better performance and more flexibility with half precision CHECK_CUBLAS(cublasGemmStridedBatchedEx( handle, CUBLAS_OP_N, CUBLAS_OP_N, n, m, k, &alpha, B_data, CUDA_R_16F, n, k * n, A_data, CUDA_R_16F, k, m * k, &beta, C_data, CUDA_R_16F, n, m * n, batch_size, CUDA_R_16F, CUBLAS_GEMM_DEFAULT_TENSOR_OP )); // Convert back to original precision if needed return A.type().scalarType() == torch::ScalarType::Half ? C_half : C_half.to(A.type().scalarType()); } // INT8 quantized version for maximum throughput on compatible hardware torch::Tensor batched_matmul_int8_cuda(torch::Tensor A, torch::Tensor B) { CHECK_CUDA(A); CHECK_CUDA(B); // Original shapes const int batch_size = A.size(0); const int m = A.size(1); const int k = A.size(2); const int n = B.size(2); // Quantize to INT8 (this is a simplified quantization) auto A_float = A.contiguous(); auto B_float = B.contiguous(); // Scale factors for quantization/dequantization float scale_A = 127.0f / A_float.abs().max().item(); float scale_B = 127.0f / B_float.abs().max().item(); float scale_C = 1.0f / (scale_A * scale_B); // Create quantized tensors auto A_int8 = (A_float * scale_A).to(torch::kChar).contiguous(); auto B_int8 = (B_float * scale_B).to(torch::kChar).contiguous(); // Output will be in int32 auto C_int32 = torch::empty({batch_size, m, n}, torch::TensorOptions().dtype(torch::kInt).device(A.device())); // Get data pointers int8_t* A_data = A_int8.data_ptr(); 52 int8_t* B_data = B_int8.data_ptr(); int* C_data = C_int32.data_ptr(); // Get cuBLAS handle cublasHandle_t handle = CuBLASHandleManager::getHandle(); // Constants for INT8 GEMM const int32_t alpha = 1; const int32_t beta = 0; // Use INT8 GEMM with tensor cores if available // Note: This is a simplified implementation; real-world would need more careful quantization CHECK_CUBLAS(cublasGemmStridedBatchedEx( handle, CUBLAS_OP_N, CUBLAS_OP_N, n, m, k, &alpha, B_data, CUDA_R_8I, n, k * n, A_data, CUDA_R_8I, k, m * k, &beta, C_data, CUDA_R_32I, n, m * n, batch_size, CUDA_R_32I, CUBLAS_GEMM_DEFAULT_TENSOR_OP )); // Dequantize and return auto C_float = C_int32.to(torch::kFloat) * scale_C; return C_float; } """ batched_matmul_cpp_source = """ torch::Tensor batched_matmul_cuda(torch::Tensor A, torch::Tensor B); torch::Tensor batched_matmul_half_cuda(torch::Tensor A, torch::Tensor B); torch::Tensor batched_matmul_int8_cuda(torch::Tensor A, torch::Tensor B); """ # Compile the inline CUDA code for batched matrix multiplication custom_ops = load_inline( name="batched_matmul_ops", cpp_sources=batched_matmul_cpp_source, cuda_sources=batched_matmul_source, functions=[ "batched_matmul_cuda", "batched_matmul_half_cuda", "batched_matmul_int8_cuda", ], verbose=True, extra_ldflags=["-lcublas"], extra_cuda_cflags=[ "--expt-relaxed-constexpr", "-O3", "--use_fast_math", "-Xptxas=-v", ], 53 ) class ModelNew(nn.Module): """ Optimized version of the model that performs batched matrix multiplication using custom CUDA kernels with cuBLAS. The implementation includes options for half-precision and INT8 computation to leverage tensor cores when available. """ def __init__(self): super(ModelNew, self).__init__() self.custom_ops = custom_ops self.use_half_precision = False # Can be toggled based on hardware support self.use_int8_precision = ( False # Can be toggled for hardware with INT8 tensor core support ) # Optimized for the given matrix sizes (128, 512, 1024, 2048) # Higher threshold as the custom kernel performs better for larger matrices self.size_threshold = 32768 # Empirical threshold def forward(self, A: torch.Tensor, B: torch.Tensor) -> torch.Tensor: """ Performs batched matrix multiplication with optimized CUDA implementation. Args: A: Input tensor of shape (batch_size, m, k). B: Input tensor of shape (batch_size, k, n). Returns: C: Output tensor of shape (batch_size, m, n). """ # Fall back to PyTorch’s native implementation for CPU tensors if not A.is_cuda or not B.is_cuda: return torch.bmm(A, B) # For small matrices, PyTorch’s native BMM might be more efficient matrix_size = A.size(1) * A.size(2) * B.size(2) if matrix_size < self.size_threshold: return torch.bmm(A, B) try: # Use INT8 precision for maximum throughput on compatible hardware if ( self.use_int8_precision and torch.cuda.get_device_capability(A.device)[0] >= 7 ): return self.custom_ops.batched_matmul_int8_cuda(A, B) # Use half precision for tensor cores if enabled and supported if ( self.use_half_precision and torch.cuda.get_device_capability(A.device)[0] >= 7 ): return self.custom_ops.batched_matmul_half_cuda(A, B) # Use our custom CUDA kernel for standard precision 54 return self.custom_ops.batched_matmul_cuda(A, B) except Exception as e: # Graceful fallback to PyTorch implementation if custom kernel fails print(f"Custom kernel error: {e}, falling back to PyTorch bmm") return torch.bmm(A, B) 55
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment