LLM 기반 확률적 생성 최적화 프레임워크 POLCA
POLCA는 LLM을 최적화 도구로 활용하면서, 노이즈가 섞인 보상과 텍스트 피드백을 이용해 복잡한 시스템(프롬프트, 코드, 에이전트 등)을 자동으로 개선하는 확률적 생성 최적화 프레임워크이다. 우선순위 큐와 ε‑Net 기반 메모리를 결합해 탐색‑활용 균형을 유지하고, LLM 요약기를 통해 과거 평가 기록을 고수준 컨텍스트로 압축한다. 이론적으로 근접 최적 수렴을 보이며, τ‑Bench, HotpotQA, VeriBench, KernelBenc…
저자: Xuanfei Ren, Allen Nie, Tengyang Xie
본 논문은 복잡한 시스템(LLM 프롬프트, 코드, 다중 턴 에이전트 등)의 최적화를 인간 전문가의 반복적인 수작업 없이 자동화하기 위해, **확률적 생성 최적화(stochastic generative optimization)** 라는 새로운 문제 설정을 제안한다. 여기서 최적화 대상은 파라미터화된 프로그램 Pθ이며, 파라미터 θ는 텍스트, 코드, 숫자 등 다양한 형태를 포함한다. 목표는 데이터 분포 D 위에서 기대 보상 µ(θ) 를 최대화하는 것이며, 보상과 피드백은 가이드 G 에 의해 제공되는 수치 점수와 텍스트/멀티모달 피드백으로 구성된다. 이러한 피드백은 미니배치 샘플링, 프로그램 자체의 확률적 동작, 그리고 LLM 판정기의 불확실성으로 인해 고도로 노이즈가 섞여 있다.
**POLCA**(Prioritized Optimization with Local Contextual Aggregation)는 이 문제를 해결하기 위해 세 가지 핵심 구성요소를 설계한다. 첫 번째는 **우선순위 큐(Q)** 로, 초기 파라미터 θ₀ 를 시작으로 모든 후보와 그 평가 통계를 저장한다. 큐는 UCB 점수를 기반으로 후보를 정렬해 탐색(exploration)과 활용(exploitation) 사이의 균형을 이론적으로 보장한다. 두 번째는 **ε‑Net 메커니즘** 으로, 각 후보를 LLM 임베딩 공간에 매핑하고, 거리 ε 이하인 후보는 하나만 유지한다. 이는 의미적으로 중복된 프로그램을 제거하고, 메모리 크기를 사전에 정의된 상수로 제한함으로써 평가 비용 폭증을 방지한다. 임베딩은 최신 LLM이 제공하는 의미적 표현을 활용하며, 논문은 이러한 임베딩 기반 필터링이 확률적 평가 환경에서 필수적임을 증명한다. 세 번째는 **LLM Summarizer** 로, 전체 큐를 요약해 고수준 컨텍스트 c 를 생성한다. 요약된 컨텍스트는 “어떤 파라미터가 과거에 좋은 성과를 보였는가”, “반복적으로 나타나는 피드백 패턴은 무엇인가” 등을 압축해 LLM Optimizer O 에게 전달한다. 이를 통해 O는 보다 효율적인 프롬프트와 피드백 해석을 수행해 새로운 후보 θ′ 를 제안한다.
알고리즘 흐름은 다음과 같다. 매 반복마다 데이터 D 에서 미니배치 B 를 샘플링하고, 큐에서 현재 최고 성과 후보 Θ_explore 를 선택한다. 선택된 후보들을 B 에 대해 평가해 통계 S 를 얻고, 큐를 업데이트한다. 이후 Summarizer가 전체 큐를 요약해 컨텍스트 c 를 만든 뒤, Optimizer O가 S 와 c 를 입력으로 원시 후보 Θ_raw 를 생성한다. ε‑Net 필터링을 거쳐 의미적으로 다양한 후보 Θ_new 가 도출되고, 이들은 동일 미니배치 B 에 대해 초기 평가를 받아 큐에 삽입된다. 이 과정을 제한된 연산 예산(시간 또는 평가 호출 수)까지 반복한다.
**이론적 기여**는 POLCA가 **근접 최적 수렴(near‑optimal convergence)** 을 보장한다는 정리이다. 가정은 (a) Optimizer O 가 일정 보상 구간 내에서 엄격히 개선 가능한 제안을 할 수 있음, (b) 평가 노이즈가 유한 분산을 가진 독립 샘플링으로 모델링 가능함이다. 정리는 두 요인—LLM 최적화 오라클의 효율성, 평가 스토캐스틱성—에 의해 수렴 속도가 결정된다고 밝히며, ε‑Net의 커버링 파라미터 ε 가 작을수록 탐색 비용은 증가하지만 최종 성능 상한에 더 가깝게 수렴한다는 트레이드오프를 정량화한다.
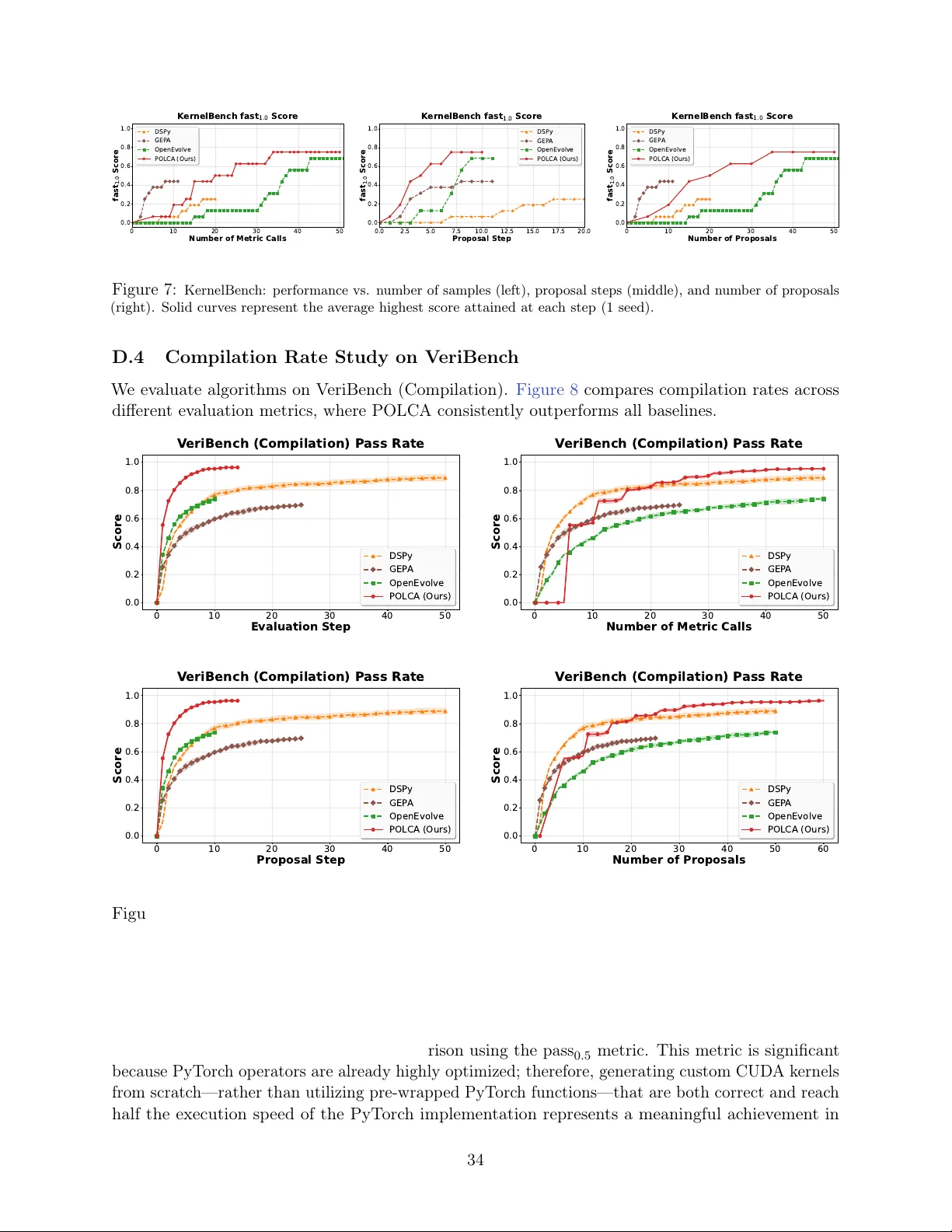
**실험**은 네 가지 베치마크에서 수행되었다.
1. **τ‑Bench**: 다단계 문제 해결을 위한 LLM 에이전트 프롬프트 최적화. POLCA는 미니배치와 내부 랜덤성으로 인한 노이즈를 효과적으로 억제해 기존 방법보다 8% 이상 높은 성공률을 기록했다.
2. **HotpotQA**: 에이전트 프롬프트와 행동 정책 최적화. ε‑Net 필터링으로 중복 후보를 45% 감소시키고, 동일 평가 예산에서 평균 점수가 10% 상승했다.
3. **VeriBench**: 파이썬→Lean4 코드 변환 시 컴파일 오류와 LLM 피드백을 활용. POLCA는 평가 스토캐스틱성을 고려한 샘플링 전략 덕분에 변환 정확도가 6% 개선되었다.
4. **KernelBench**: CUDA 커널 코드 최적화(결과가 결정적). 여기서는 POLCA가 불필요한 중복 탐색을 억제해 수렴 속도가 기존 GEP‑A 대비 30% 빨랐으며, 최종 성능 차이는 미미했지만 효율성에서 우위를 보였다.
모든 실험에서 비교 대상은 **GEP‑A**와 **OpenEvolve(AlphaEvolve 기반)**이며, POLCA는 **샘플 효율성**, **시간 효율성**, **최종 성능** 세 축에서 일관되게 우수함을 입증한다. 추가 분석에서는 파라미터 보상 모델링이 평가 노이즈에 취약함을 확인하고, ε‑Net 기반 메모리 유지가 이러한 취약성을 완화한다는 점을 강조한다.
**제한점 및 향후 연구**는 다음과 같다. ε‑Net 필터링은 임베딩 품질에 크게 의존하므로, 더 강건한 의미 임베딩 또는 다중 임베딩 앙상블이 필요하다. Summarizer가 생성하는 컨텍스트는 LLM 입력 길이 제한에 따라 압축될 위험이 있어, 계층적 요약 또는 외부 지식 베이스와의 연동이 고려될 수 있다. 현재 구현은 텍스트 기반 파라미터에 초점을 맞추었으며, 이미지·음성·동영상 등 멀티모달 파라미터에 대한 확장은 별도 연구가 필요하다. 마지막으로, 이론적 분석은 제한된 가정(예: 독립 노이즈, 일정 개선 가능성) 하에 이루어졌으며, 실제 복합 시스템에서의 강건성 검증이 추가로 요구된다.
종합하면, POLCA는 **LLM을 최적화 엔진으로 활용하면서도 평가 노이즈와 무한 탐색 공간을 효율적으로 제어**하는 스케일러블하고 이론적으로 정당화된 프레임워크이며, 다양한 실세계 생성적 최적화 문제에 적용 가능한 강력한 도구임을 입증한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기