BrainBench: Exposing the Commonsense Reasoning Gap in Large Language Models
Large language models (LLMs) achieve impressive scores on standard benchmarks yet routinely fail questions that any human would answer correctly in seconds. We introduce BrainBench, a benchmark of 100 brainteaser questions spanning 20 carefully desig…
Authors: Yuzhe Tang
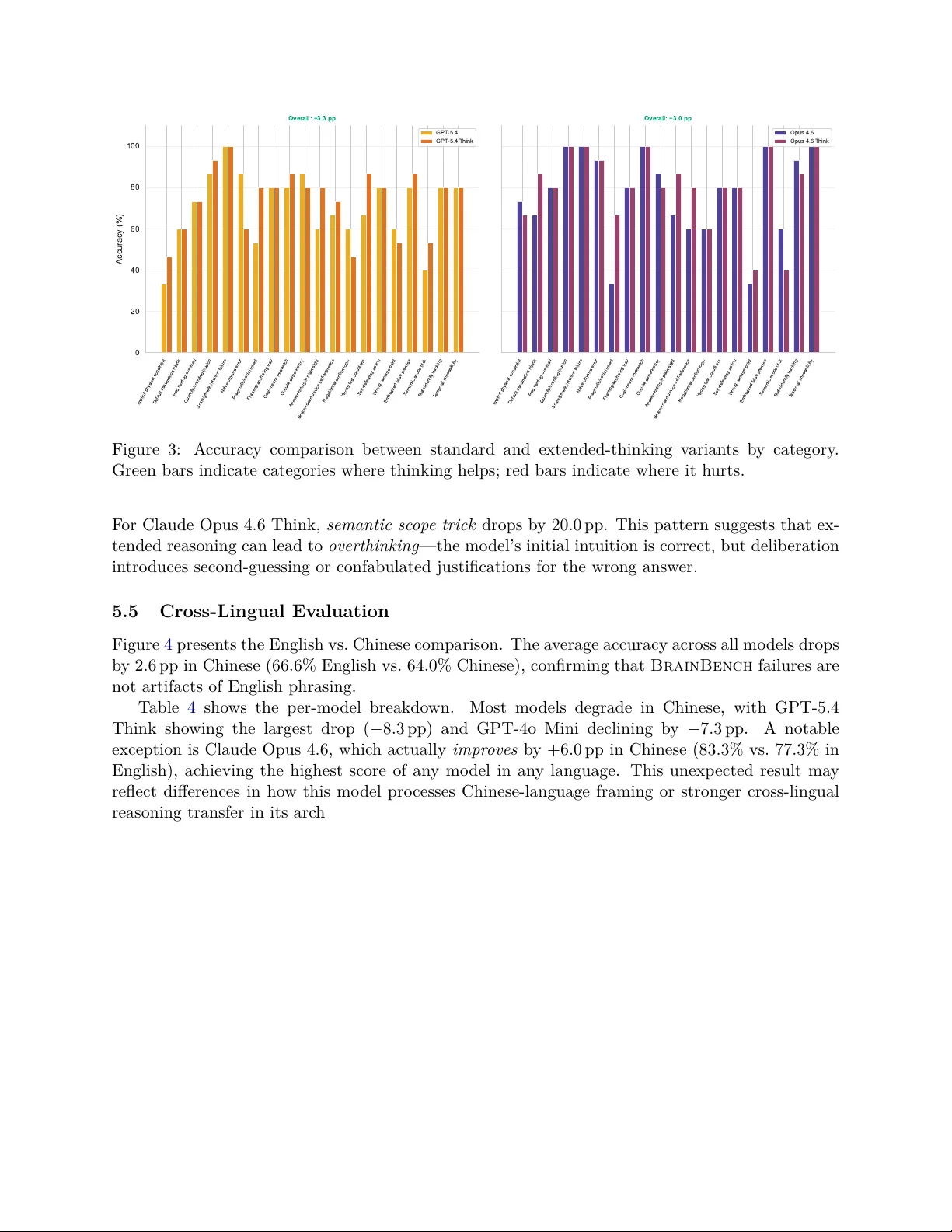
BrainBenc h: Exp osing the Commonsense Reasoning Gap in Large Language Mo dels Y uzhe T ang Georgia Institute of T ec hnology ytang352@gatech.edu Abstract Large language mo dels (LLMs) ac hiev e impressiv e scores on standard benchmarks y et rou- tinely fail questions that an y human w ould answ er correctly in seconds. W e in tro duce Brain- Bench , a benchmark of 100 brainteaser questions spanning 20 carefully designed categories, eac h targeting a sp ecific commonsense reasoning failure mo de in LLMs. Categories range from implicit physic al c onstr aints (“Should I walk or drive my rental car to the return lot?”) to semantic sc op e tricks and default assumption hijacks . W e ev aluate eight frontier mo dels—four from the Claude family and four from the GPT family—using a zero-shot proto col with 10 inde- p enden t runs p er question. The b est mo del, Claude Opus 4.6 with extended thinking, achiev es only 80.3% accuracy; the worst, GPT-4o, scores 39.7%. Ev en top-p erforming mo dels exhibit a 6–16 p ercentage-point gap b etw een accuracy and consistency , rev ealing sto chastic reasoning. Cross-lingual ev aluation in Chinese shows most mo dels degrade by 2–8 pp, confirming that these failures reflect reasoning deficits rather than language-sp ecific artifacts. BrainBench provides a fine-grained diagnostic to ol for identifying where and why LLMs substitute surface heuristics for genuine commonsense reasoning. 1 In tro duction Consider the following question: “I ne e d to r eturn my r ental c ar. The r ental agency is just acr oss the str e et. Should I walk over or drive?” Ev ery h uman immediately recognizes that y ou m ust drive —the car itself needs to b e returned. Y et when this class of question was p osed to leading AI mo dels in the Opp er.ai Car W ash T est [ Opp er AI , 2025 ], the ma jorit y recommended walking, treating the problem as a simple distance-optimization task while ignoring the implicit ph ysical constrain t that the ob ject m ust tra vel with y ou. This is not an isolated failure. A growing bo dy of evidence suggests that large language mo dels (LLMs), despite their remarkable p erformance on standard NLP b enchmarks [ W ang et al. , 2019 , Sriv asta v a et al. , 2023 ], systematically fail on questions requiring basic commonsense reasoning [ Da vis an d Marcus , 2015 , Marcus , 2020 ]. These are not tric k questions in the adversarial sense— they are questions that an y adult human answ ers effortlessly , often without conscious delib eration. The difficulty lies not in the complexity of the reasoning but in the need to ov erride a surface-level heuristic with a deep er understanding of ho w the ph ysical or so cial world w orks. Existing benchmarks capture fragments of this problem. The BRAINTEASER shared task at SemEv al-2024 [ Jiang et al. , 2024 ] fo cused on lateral thinking puzzles requiring creative rein ter- pretation. SimpleBench [ SimpleBench T eam , 2024 ] tested spatial, temp oral, and so cial reasoning. 1 HellaSw ag [ Zellers et al. , 2019 ] and PIQA [ Bisk et al. , 2020 ] ev aluate commonsense through sen- tence completion and physical in tuition. Ho wev er, none of these b enchmarks pro vides a systematic taxonomy of failur e mo des —a categorization of the sp ecific types of reasoning traps that LLMs fall in to, organized by the underlying cognitiv e mec hanism. W e introduce BrainBench , a b enchmark designed to fill this gap. Our contributions are: 1. A taxonomy of 20 commonsense reasoning failure categories , each defined by a sp e- cific cognitiv e trap (e.g., broken-device self-reference, wrong v an tage p oint, default assumption hijac k), the surface heuristic that LLMs follow, and wh y that heuristic fails. 2. A b enc hmark of 100 questions (5 p er category), designed so that eac h question is trivially easy for humans but exploits a kno wn LLM reasoning gap. 3. A comprehensive ev aluation of 8 fron tier mo dels across t wo mo del families (Claude and GPT), including extended-thinking v arian ts, using a zero-shot proto col with 10 indep enden t runs p er question to measure b oth accuracy and consistency . 4. A cross-lingual ev aluation in Chinese, revealing that reasoning failures p ersist across lan- guages and are not artifacts of English-specific phrasing. Our k ey findings rev eal a clear three-tier structure in commonsense reasoning ability: Claude- family mo dels cluster at 74–80% accuracy , GPT-5.4 mo dels at 70–74%, and GPT-4o mo dels at ap- pro ximately 40%. The hardest categories— implicit physic al c onstr aint and wr ong vantage p oint — a verage only 40% accuracy across all mo dels, meaning that even frontier LLMs p erform near chance on questions an y c hild could answ er. Extended thinking provides a mo dest b enefit of approximately 3 pp ov erall but actually hurts p erformance on certain category t yp es, suggesting that more com- putation do es not uniformly translate to better commonsense reasoning. 2 Related W ork Commonsense reasoning b enc hmarks. Ev aluating commonsense in AI systems has a long history [ Davis and Marcus , 2015 ]. Mo dern b enchmarks approach th e problem from different an- gles. CommonsenseQA [ T almor et al. , 2019 ] tests kno wledge-intensiv e commonsense via m ultiple- c hoice questions grounded in ConceptNet. PIQA [ Bisk et al. , 2020 ] fo cuses on physical intuition (“Whic h is a b etter w ay to cut a piece of glass?”). HellaSw ag [ Zellers et al. , 2019 ] uses adversar- ially filtered sen tence completions to test situational commonsense. RiddleSense [ Lin et al. , 2021 ] prob es creative commonsense through riddles. The RAINBOW b enchmark [ Lourie et al. , 2021 ] uni- fies several commonsense tasks into a m ultitask framew ork. While these b enchmarks ha ve driv en progress, state-of-the-art LLMs now achiev e near-h uman p erformance on most of them [ Op enAI , 2023 ], raising the question of whether they measure genuine reasoning or pattern-matching abil- it y . BrainBench is designed to remain c hallenging precisely b ecause it targets the gap b et w een surface-lev el pattern matching and gen uine understanding. The Car W ash T est. Opper AI [ 2025 ] in tro duced a viral ev aluation in which 53 AI mo dels w ere asked whether to walk or drive to a nearby car wash. The question exploits the same implicit ph ysical constraint as our Category 1: the car itself must be present at the car w ash. The ma jority of tested mo dels recommended walking, revealing that they optimized for distance rather than reasoning about the task’s physical requirements. The Car W ash T est demonstrated that a single w ell-designed question can exp ose fundamental reasoning gaps, but as a single-question ev aluation 2 it cannot c haracterize the breadth of failure mo des. BrainBench extends this insigh t in to a systematic taxonomy . BRAINTEASER and lateral thinking. The SemEv al-2024 BRAINTEASER task [ Jiang et al. , 2024 ] ev aluated LLMs on sentence puzzles and word puzzles that require defying default common- sense asso ciations. Their work demonstrated that LLMs struggle with questions requiring lateral thinking—breaking aw ay from the most ob vious interpretation. BrainBench complements this b y pro viding a finer-grained categorization: rather than grouping all lateral thinking failures together, w e decomp ose them in to 20 distinct mec hanisms (e.g., seman tic scop e tric ks vs. default assumption hijac ks vs. answer hiding in plain sight). SimpleBenc h. SimpleBenc h [ SimpleBench T eam , 2024 ] ev aluates LLMs on questions requiring spatial reasoning, temp oral reasoning, and so cial in telligence. It shares our motiv ation of testing supp osedly “simple” tasks, but fo cuses on a coarser categorization (spatial, temporal, so cial) rather than the sp ecific cognitiv e traps that cause failures. LLM reasoning and c hain-of-though t. Chain-of-though t prompting [ W ei et al. , 2022 ] and extended thinking mo des hav e b een shown to impro v e p erformance on complex reasoning tasks. Recen t work [ Maho wald et al. , 2024 ] argues that language comp etence and reasoning ability are disso ciable in LLMs—mo dels can exhibit fluent language pro duction while lacking robust reasoning. Our thinking-mo de analysis (Section 5 ) pro vides empirical evidence for this disso ciation: extended thinking yields only mo dest improv emen ts on commonsense brain teasers and actually degrades p erformance on certain categories. 3 The BrainBenc h Dataset BrainBench consists of 100 questions organized into 20 categories, with 5 questions p er category . Eac h category targets a sp ecific commonsense reasoning failure mo de, defined by (a) the c or e tr ap : the surface-level heuristic that LLMs follo w; (b) the why : the reason this heuristic leads to the wrong answ er; and (c) the c orr e ct r e asoning : the commonsense knowledge needed to o verride the heuristic. T able 1 presen ts the full taxonom y . 3.1 Category Design The 20 categories w ere identified through a systematic analysis of LLM failure patterns on com- monsense questions rep orted in prior work [ Opper AI , 2025 , Jiang et al. , 2024 , SimpleBenc h T eam , 2024 ], online AI failure compilations, and our o wn exploratory testing. W e organized these failures b y the typ e of c o gnitive shortcut that pro duces the error, yielding a taxonomy that spans ph ysical reasoning (Categories 1–5), linguistic/seman tic reasoning (Categories 6–7, 15, 16, 19–20), logical reasoning (Categories 8–9, 12–13, 18), and so cial/pragmatic reasoning (Categories 10–11, 14, 17). T able 1 pro vides the complete taxonomy . 3.2 Question Design Eac h question in BrainBench is designed to satisfy three criteria: (1) trivially easy for hu- mans —an a v erage adult should answer correctly within seconds; (2) trap-sp ecific —the question activ ates the sp ecific surface heuristic defined by its category; and (3) unam biguous —the correct answ er is ob jectively determinable, not a matter of opinion. 3 Questions v ary in surface complexity . Some are delib erately short (“My car battery is dead. Should I drive to the auto parts store or ha v e someone bring me a battery?”), while others embed the trap within a longer, more naturalistic scenario featuring exp ert-sounding but fla wed advice. The longer format tests whether mo dels can identify the critical flaw amid plausible-sounding detail—a skill that requires gen uine comprehension rather than pattern matc hing. 3.3 Illustrativ e Examples W e highlight three examples that illustrate differen t failure mechanisms: Example 1: Implicit physical constrain t. “I ne e d to get my b o at r ep air e d. The r ep air do ck is 100 meters along the shor e. Should I walk or sail?” The correct answ er is sail —the boat must b e at the do ck. Mo dels that recommend walking optimize for the easier mode of transp ort without reasoning ab out the ph ysical constrain t that the repair target m ust be presen t. Example 2: Broken/dead device self-reference. “My internet c onne ction is down. Should I go o gle the tr oublesho oting steps or c al l my ISP?” The correct answer is c al l —go ogling requires the very internet connection that is down. This exploits the mo del’s asso ciation b etw een “trou- blesho oting” and “search online. ” Example 3: Default assumption hijack. Questions in this category exploit cultural stereo- t yp es or default scripts (e.g., assuming a surgeon is male, or that a dark scene implies nighttime). The mo del fills in unstated details with statistically dominan t patterns rather than considering alternativ es consisten t with the stated facts. 4 Exp erimen tal Setup 4.1 Mo dels W e ev aluate eight fron tier LLMs spanning tw o ma jor mo del families, as shown in T able 2 . This selection cov ers a range of mo del sizes within each family and includes extended-thinking v ariants for b oth the Claude and GPT families. 4.2 Ev aluation Proto col W e adopt a strict zero-shot proto col: eac h question is sen t to the mo del as a standalone prompt with no system prompt, no few-s hot examples, and no c hain-of-thought instructions. This isolates the mo del’s default reasoning b ehavior, following the metho dology of the Car W ash T est [ Opp er AI , 2025 ]. Eac h question is ev aluated 10 indep enden t times per mo del (300 total resp onses p er model across 100 questions). Multiple runs allow us to distinguish betw een reliable reasoning and sto c has- tic correctness—a model that answ ers correctly 3 out of 10 times is meaningfully differen t from one that answers correctly 10 out of 10 times. 4.3 A utomated Judging Resp onses are ev aluated b y an LLM judge that compares eac h resp onse against the ground-truth answ er. The judge makes a binary determination (correct/incorrect) based on whether the re- 4 sp onse’s conclusion matches the ground-truth reasoning, regardless of phrasing or verbosity . W e use a strong mo del as the judge and v alidated its agreemen t with h uman annotators. 4.4 Metrics W e rep ort t wo primary metrics: • A ccuracy : the f raction of runs in which the mo del pro duces the correct answ er, aggregated across all 10 runs p er question. • Consistency (Reliabilit y): the fraction of questions for whic h the mo del pro duces the correct answ er in al l 10 runs. A mo del with 80% accuracy but 50% consistency gets many questions righ t sometimes but wrong other times, indicating sto chastic reasoning rather than robust un- derstanding. The gap b etw een accuracy and consistency captures r e asoning r eliability : ho w m uch a mo del’s correctness dep ends on the particular sample from its output distribution. 4.5 Cross-Lingual Ev aluation T o test whether BrainBench failures are English-sp ecific or reflect deep er reasoning deficits, w e translate the full b enc hmark into Chinese and ev aluate all eight mo dels under the same proto col. T ranslation preserv es the semantic conten t and trap structure of eac h question while adapting cultural references where necessary . 5 Results 5.1 Ov erall Performance Figure 1 presents the ov erall accuracy ranking. A clear three-tier structure emerges: • Tier 1 (74–80%): All four Claude mo dels, led by Claude Opus 4.6 Think at 80.3%. • Tier 2 (70–74%): GPT-5.4 and GPT-5.4 Think, at 70.7% and 74.0% resp ectiv ely . • Tier 3 ( ∼ 40%): GPT-4o and GPT-4o Mini, both at 39.7%. The 40.7 pp spread b et w een the b est and worst mo dels demonstrates that BrainBench discrim- inates effectively b etw een mo del capabilities. Notably , even the smallest Claude mo del (Haiku 4.5, 74.3%) outp erforms the largest non-thinking GPT mo del (GPT-5.4, 70.7%) by 3.6 pp, suggesting fundamen tal differences in commonsense reasoning b et w een mo del families. T able 3 pro vides the complete leaderb oard with b oth accuracy and consistency scores. 5.2 Category-Lev el Analysis Figure 2 shows the category-level heatmap, revealing striking v ariation in difficult y across categories. 5 0 20 40 60 80 100 Overall Accuracy (%) GPT -4o Mini GPT -4o GPT -5.4 GPT -5.4 Think Claude Haiku 4.5 Claude Sonnet 4.6 Claude Opus 4.6 Claude Opus 4.6 Think 39.7% 39.7% 70.7% 74.0% 74.3% 76.7% 77.3% 80.3% chance (25%) Figure 1: Ov erall accuracy (%) on BrainBench (English). Mo dels are ranked b y accuracy . Error bars indicate the range b etw een accuracy and consistency , capturing reasoning reliabilit y . Hardest categories. T wo categories stand out as exceptionally difficult, a v eraging only 40% accuracy across all mo dels: 1. Implicit ph ysical constraint (40.0%): Questions where a surface cue (short distance, conv e- nience) triggers a default resp onse that ignores the requirement for an ob ject to b e physically presen t. GPT-4o and GPT-4o Mini score 0% on this category . 2. W rong v an tage p oint (40.0%): Questions ab out observ ation or p erception where the target is not visible from the assumed position. GPT-4o scores 0%. Three additional categories av erage b elo w 55%: semantic sc op e trick (50.0%), default assump- tion hijack (51.7%), and pr agmatic/so cial intent (56.7%). Easiest categories. Sc ale/gr owth intuition failur e is the easiest category at 95.0% av erage ac- curacy , with even GPT-4o Mini achieving 80%. This suggests that fron tier mo dels hav e largely in ternalized exponential growth reasoning, perhaps through extensiv e exp osure to classic exam- ples (e.g., lily pad doubling problems) in training data. Quantity/c ounting il lusion (81.7%) and state/identity tr acking (80.0%) are also relativ ely easy . Category-mo del interactions. The heatmap rev eals that no mo del is uniformly strong or weak across all categories. Claude Opus 4.6 Think ac hieves 100% on five categories (embedded false premise, goal–means mismatch, temp oral imp ossibility , quantit y/coun ting illusion, scale/gro wth in tuition failure) but scores only 40% on wrong v antage p oint and 40% on semantic scop e trick. 6 Implicit physical constraint W rong vantage point Semantic scope trick Default assumption hijack Pragmatic/social intent Answer hiding in plain sight Negation/exception logic Broken/dead device self-reference W rong test conditions Red herring overload Framing/anchoring trap Self-defeating action Circular dependency Naive physics error Embedded false premise Goal-means mismatch T emporal impossibility State/identity tracking Quantity/counting illusion Scale/growth intuition failure Claude Opus 4.6 Think Claude Opus 4.6 Claude Sonnet 4.6 Claude Haiku 4.5 GPT -5.4 Think GPT -5.4 GPT -4o Mini GPT -4o 67 40 40 87 67 87 60 80 80 80 80 80 80 93 100 100 100 87 100 100 73 33 60 67 33 67 60 60 80 80 80 80 87 93 100 100 100 93 100 100 40 47 53 67 67 60 67 80 93 80 47 80 100 87 100 100 100 80 87 100 60 67 53 47 67 53 47 80 73 93 73 80 80 60 100 100 100 93 67 93 47 53 53 60 80 80 47 73 87 73 80 80 80 60 87 87 80 80 93 100 33 60 40 60 53 60 60 67 67 73 80 80 87 87 80 80 80 80 87 100 0 20 40 7 53 33 73 20 27 40 47 47 40 67 7 33 53 60 47 80 0 0 60 20 33 33 73 27 0 40 80 53 33 40 33 27 13 67 73 87 0 20 40 60 80 100 Accuracy (%) Figure 2: A ccuracy heatmap across mo dels and categories. Categories are sorted by av erage diffi- cult y (hardest at left). Dark er cells indicate low er accuracy . Similarly , GPT-4o scores 87% on scale/growth in tuition failure and 80% on framing/anchoring trap, but 0% on implicit physical constrain t, wrong v an tage p oint, and wrong test conditions. These asymmetric strengths and w eaknesses make BrainBench a useful diagnostic to ol for iden tifying sp ecific reasoning gaps in individual mo dels. 5.3 Consistency Analysis The gap b etw een accuracy and consistency reveals the reliabilit y of eac h mo del’s reasoning. The a verage gap across all mo dels is 10.3 pp. The most consistent mo del is Claude Opus 4.6 Think, with a reliabilit y-to-accuracy ratio of 0.92 (74.0% consistency vs. 80.3% accuracy). The least consisten t is GPT-4o Mini, with a ratio of 0.61 (24.0% consistency vs. 39.7% accuracy). Claude Haiku 4.5 presents an in teresting case: despite ranking 4th in accuracy (74.3%), it has the second-largest consistency gap (16.3 pp), suggesting that many of its correct answers are sto c hastic rather than reflecting robust reasoning. By contrast, GPT-5.4 has a relativ ely small gap (7.7 pp) despite lo w er accuracy (70.7%), indicating that when it gets a question right, it do es so reliably . 5.4 Effect of Extended Thinking Figure 3 compares standard and thinking-mo de v arian ts for b oth mo del families. Extended thinking pro vides a modest o verall b enefit: + 3.3 pp for GPT-5.4 and + 3.0 pp for Claude Opus 4.6. Ho w ever, the effect is highly uneve n across categories. Where thinking helps. F or GPT-5.4, the largest gains from thinking mode app ear in categories requiring multi-step delib eration: pr agmatic/so cial intent ( + 26.7 pp), answer hiding in plain sight ( + 20.0 pp), and wr ong test c onditions ( + 20.0 pp). F or Claude Opus 4.6, thinking helps most on pr agmatic/so cial intent ( + 33.3 pp) and default assumption hijack ( + 20.0 pp). Where thinking hurts. Strikingly , thinking mo de de gr ades p erformance on sev eral categories. F or GPT-5.4 Think, naive physics err or drops by 26.7 pp and ne gation/exc eption lo gic b y 13.3 pp. 7 Implicit physical constraint Default assumption hijack Red herring overload Quantity/counting illusion Scale/growth intuition failure Naive physics error Pragmatic/social intent Framing/anchoring trap Goal-means mismatch Circular dependency Answer hiding in plain sight Broken/dead device self-reference Negation/exception logic W rong test conditions Self-defeating action W rong vantage point Embedded false premise Semantic scope trick State/identity tracking T emporal impossibility 0 20 40 60 80 100 Accuracy (%) Overall: +3.3 pp GPT -5.4 GPT -5.4 Think Implicit physical constraint Default assumption hijack Red herring overload Quantity/counting illusion Scale/growth intuition failure Naive physics error Pragmatic/social intent Framing/anchoring trap Goal-means mismatch Circular dependency Answer hiding in plain sight Broken/dead device self-reference Negation/exception logic W rong test conditions Self-defeating action W rong vantage point Embedded false premise Semantic scope trick State/identity tracking T emporal impossibility Overall: +3.0 pp Opus 4.6 Opus 4.6 Think Figure 3: A ccuracy comparison b etw een standard and extended-thinking v arian ts b y category . Green bars indicate categories where thinking helps; red bars indicate where it hurts. F or Claude Opus 4.6 Think, semantic sc op e trick drops b y 20.0 pp. This pattern suggests that ex- tended reasoning can lead to overthinking —the mo del’s initial intuition is correct, but delib eration in tro duces second-guessing or confabulated justifications for the wrong answer. 5.5 Cross-Lingual Ev aluation Figure 4 presents the English vs. Chinese comparison. The av erage accuracy across all mo dels drops b y 2.6 pp in Chinese (66.6% English vs. 64.0% Chinese), confirming that BrainBench failures are not artifacts of English phrasing. T able 4 shows the p er-mo del breakdo wn. Most models degrade in Chinese, with GPT-5.4 Think sho wing the largest drop ( − 8.3 pp) and GPT-4o Mini declining b y − 7.3 pp. A notable exception is Claude Opus 4.6, whic h actually impr oves b y + 6.0 pp in Chinese (83.3% vs. 77.3% in English), achieving the highest score of any mo del in any language. This unexp ected result ma y reflect differences in how this mo del pro cesses Chinese-language framing or stronger cross-lingual reasoning transfer in its architecture . 5.6 Mo del F amily Comparison Within the GPT family , the most striking finding is the 31.0 pp jump from GPT-4o (39.7%) to GPT-5.4 (70.7%), suggesting substan tial reasoning improv ements in the newer generation. By con trast, GPT-4o and GPT-4o Mini p erform identically (39.7%), and extended thinking adds only 3.3 pp to GPT-5.4. The Claude family sho ws a flatter progression: all four mo dels fall within a 6.0 pp range (74.3% to 80.3%). Ev en the smallest Claude mo del (Haiku 4.5) outp erforms GPT-5.4 by 3.6 pp. In head- to-head comparisons at matched tiers, Claude mo dels outp erform their GPT coun terparts at ev ery lev el, with adv an tages ranging from 6.3 pp (Opus Think vs. GPT-5.4 Think) to 37.0 pp (Sonnet vs. GPT-4o). 8 GPT -4o Mini GPT -4o GPT -5.4 GPT -5.4 Think Claude Haiku 4.5 Claude Sonnet 4.6 Claude Opus 4.6 Claude Opus 4.6 Think 0 20 40 60 80 100 Overall Accuracy (%) -7.3 -2.7 +0.0 -8.3 -4.7 -3.7 +6.0 -0.3 English (v3) Chinese (v3) Figure 4: Accuracy comparison b etw een English and Chinese versions of BrainBench . 6 Discussion 6.1 Wh y Do Mo dels F ail? The category-level results suggest a unifying explanation: LLMs default to surface heuristics when the correct answ er requires o verriding a statistically dominan t pattern . The hardest categories are precisely those where the most “obvious” resp onse—the one that would b e correct in the ma jorit y of similar-sounding scenarios—is wrong in the sp ecific case presented. Consider implicit ph ysical constrain t (40% a verage accuracy). In most real-world con texts, when a destination is nearb y , walking is the sensible c hoice. The mo del has learned this pattern from millions of examples. The brain teaser sub verts this pattern b y adding a constrain t (the object m ust trav el with you) that requires o verriding the default. The mo del’s failure is not a lac k of kno wledge—it “knows” that cars need to b e present for car washes and repairs—but a failure to activ ate that knowledge in context. This aligns with the disso ciation betw een language comp etence and reasoning proposed b y Maho wald et al. [ 2024 ]: mo dels can pro duce fluent, kno wledgeable text while failing to apply that kno wledge to nov el situations that conflict with learned patterns. 6.2 The Ov erthinking Parado x Our finding that extended thinking helps on some categories but hurts on others reveals what we term the overthinking p ar adox . On categories lik e pr agmatic/so cial intent , where the correct answer requires stepping back from literal interpretation to consider so cial context, additional reasoning time helps the mo del reconsider its initial literal parse. But on categories like semantic sc op e trick and naive physics err or , the mo del’s first intuition is sometimes correct, and extended delib eration 9 in tro duces opp ortunities to talk itself into the wrong answer. This pattern has practical implications: deploying thinking mo des for commonsense tasks may not yield uniform improv ement, and the optimal strategy dep ends on the type of reasoning required. 6.3 Cross-Lingual Robustness The mo dest a verage degradation in Chinese ( − 2.6 pp) confi rms that BrainBench measures rea- soning deficits that transcend language-sp ecific surface features. The remarkable p erformance of Claude Opus 4.6 in Chinese ( + 6.0 pp ov er English) warran ts fu rther inv estigation. One h yp othesis is that Chinese phrasing, b eing structurally different from English, disrupts some of the English- cen tric surface heuristics that mo dels ha ve ov er-learned, inadv erten tly improving p erformance by forcing the mo del in to a less “autopilot” mode. 6.4 Univ ersally Hard and Easy Questions Three questions achiev e 0% mean accuracy across all 8 mo dels, meaning no mo del answer e d c or- r e ctly in any run . These represen t reasoning blind sp ots shared across architectures. Conv ersely , 10 questions ac hieve 100% accuracy across all mo dels. The co existence of universally-solv ed and univ ersally-failed questions within the same category (e.g., self-defe ating action con tains b oth) sug- gests that difficulty dep ends not just on the category but on the sp ecific w ay the trap is instantiated. 6.5 Limitations Sev eral limitations should b e noted. First, our b enchmark contains 100 questions—sufficient for category-lev el analysis but limited for fine-grained statistical tests within categories (5 questions eac h). Expanding the dataset w ould strengthen per-category conclusions. Second, we lack a formal h uman baseline; while these questions are designed to b e trivially easy for humans, a con trolled study with h uman participants would quantify the human–AI gap precisely . Third, our ev aluation co vers t wo model families (Claude and GPT); including additional families (Gemini, Llama, etc.) w ould broaden the findings. F ourth, the LLM judge, while v alidated, may in tro duce systematic bi- ases in edge cases. Finally , our cross-lingual ev aluation cov ers only Chinese; extending to additional languages would further test the language-indep endence of the findings. 7 Conclusion W e introduced BrainBench , a b enchmark of 100 commonsense brainteaser questions organized in to 20 categories, each targeting a sp ecific reasoning failure mo de in large language models. Our ev aluation of eight frontier mo dels rev eals that even the b est mo del achiev es only 80.3% accuracy on questions that are trivially easy for humans, with the hardest categories av eraging 40% accuracy— near chance. The BrainBench taxonomy pro vides a diagnostic to ol for identifying wher e and why LLMs fail at commonsense reasoning: not from a lack of w orld kno wledge, but from an o ver-reliance on surface heuristics that are correct in most contexts but fail in precisely the situations where commonsense matters most. As LLMs are increasingly deploy ed in real-world settings that require gen uine understanding of physical constrain ts, so cial norms, and logical dep endencies, b enchmarks lik e BrainBench serv e as a necessary complement to standard ev aluations—measuring not what mo dels know, but whether they can apply what they know when it coun ts. 10 The dataset and ev aluation co de are publicly a v ailable. 1 References Y onatan Bisk, Row an Zellers, Ronan Le Bras, Jianfeng Gao, and Y ejin Choi. PIQA: Reasoning ab out ph ysical in tuition b y question answ ering. In Pr o c e e dings of the AAAI Confer enc e on A rtificial Intel ligenc e , v olume 34, pages 7432–7439, 2020. Ernest Davis and Gary Marcus. Commonsense reasoning and commonsense knowledge in artificial in telligence. Communic ations of the A CM , 58(9):92–103, 2015. Yifan Jiang, Filip Ilievski, Kaixin Ma, and Zhiv ar Sourati. SemEv al-2024 task 9: BRAINTEASER: A nov el task defying common sense. In Pr o c e e dings of the 18th International W orkshop on Se- mantic Evaluation (SemEval-2024) , pages 1855–1867. Asso ciation for Computational Linguistics, 2024. Bill Y uchen Lin, Ziyi W u, Yichi Y ang, Dong-Ho Lee, and Xiang Ren. RiddleSense: Reasoning ab out riddle questions featuring linguistic creativity and commonsense knowledge. In Findings of the A sso ciation for Computational Linguistics: A CL-IJCNLP 2021 , pages 1504–1515, 2021. Nic holas Lourie, Ronan Le Bras, Chandra Bhagav atula, and Y ejin Choi. UNICORN on RAINBO W: A universal commonsense reasoning mo del on a new multitask benchmark. In Pr o c e e dings of the AAAI Confer enc e on A rtificial Intel ligenc e , v olume 35, pages 13480–13488, 2021. Kyle Mahow ald, Anna A Iv ano v a, Idan A Blank, Nancy Kan wisher, Josh ua B T enenbaum, and Ev elina F edorenk o. Disso ciating language and though t in large language mo dels. T r ends in Co gnitive Scienc es , 28(6):517–540, 2024. Gary Marcus. The next decade in AI: F our steps tow ards robust artificial in telligence. arXiv pr eprint arXiv:2002.06177 , 2020. Op enAI. GPT-4 technical rep ort. arXiv pr eprint arXiv:2303.08774 , 2023. Opp er AI. Car wash test on 53 leading AI mo dels, 2025. URL https://opper.ai/blog/ car- wash- test . A ccessed: 2026-03-01. SimpleBenc h T eam. SimpleBench: Ev aluating the simplification of m ulti-step reasoning b ench- marks, 2024. URL https://simple- bench.com/ . A ccessed: 2026-03-01. Aarohi Sriv astav a et al. Bey ond the imitation game: Quantifying and extrapolating the capabilities of language mo dels. T r ansactions on Machine L e arning R ese ar ch , 2023. Alon T almor, Jonathan Herzig, Nic holas Lourie, and Jonathan Beran t. CommonsenseQA: A ques- tion answering challenge targeting world knowledge. In Pr o c e e dings of the 2019 Confer enc e of the North A meric an Chapter of the A sso ciation for Computational Linguistics: Human L anguage T e chnolo gies , pages 4149–4158, 2019. Alex W ang, Y ada Pruksachatkun, Nikita Nangia, Amanpreet Singh, Julian Michael, F elix Hill, Omer Levy , and Samuel R Bowman. Sup erGLUE: A stickier b enc hmark for general-purp ose language understanding systems. A dvanc es in Neur al Information Pr o c essing Systems , 32, 2019. 1 URL redacted for review. 11 Jason W ei, Xuezhi W ang, Dale Sc h uurmans, Maarten Bosma, Brian Ic hter, F ei Xia, Ed Chi, Quoc V Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language mo dels. A dvanc es in Neur al Information Pr o c essing Systems , 35:24824–24837, 2022. Ro wan Zellers, Ari Holtzman, Y onatan Bisk, Ali F arhadi, and Y ejin Choi. HellaSwag: Can a mac hine really finish your sentence? In Pr o c e e dings of the 57th A nnual Me eting of the A sso ciation for Computational Linguistics , pages 4791–4800, 2019. A Category Difficult y Rankings T able 5 presents the full category difficulty ranking, sorted b y av erage accuracy across all eigh t mo dels. B Thinking Mo de: P er-Category Deltas T able 6 shows the p er-category accuracy change when enabling extended thinking mo de for b oth mo del pairs. 12 T able 1: The 20 BrainBench categories. Eac h category targets a sp ecific reasoning trap. A vg. A cc. is the mean accuracy across all 8 mo dels. # Category Core T rap A vg. A cc. 1 Implicit physical constrain t Surface cue (short distance) ov errides need for ob ject to b e present 40.0% 2 Brok en/dead device self-ref. Recommends broken device for the task it cannot p erform 60.8% 3 W rong test conditions F av ors immediate action; ignores that conditions inv alidate the test 63.3% 4 Self-defeating action Direct action sounds efficien t but physi- cally undermines the goal 72.5% 5 W rong v antage p oint Uses nearest observ ation to ol; ignores spatial geometry 40.0% 6 Em b edded false premise Answ ers within a premise that should be rejected outright 75.8% 7 Seman tic scop e trick In terprets a key w ord with wrong scope (e.g., “exactly” vs. “at least”) 50.0% 8 State/iden tit y tracking Applies the even t lab el rather than track- ing resulting state 80.0% 9 T emp oral imp ossibility Endorses action whose window has al- ready closed 78.3% 10 Default assumption hijack Fills in unstated details with stereot ypi- cal defaults 51.7% 11 Red herring ov erload Ov er-pro cesses irrelev ant detail; misses trivially simple answer 70.0% 12 Quan tit y/counting illusion P erforms the obvious arithmetic, whic h is wrong 81.7% 13 Scale/gro wth intuition fail. Linear intuition underestimates exp o- nen tial growth 95.0% 14 Naiv e physics error Repro duces folk-ph ysics misconceptions from training data 73.3% 15 Pragmatic/so cial inten t Answ ers literally; misses that the utter- ance is a request or sarcasm 56.7% 16 F raming/anchoring trap F ollo ws the pattern the question’s fram- ing establishes 70.8% 17 Goal–means mismatch Endorses action asso ciated with goal that do es not causally achiev e it 78.3% 18 Circular dep endency Recommends to ol whose use requires the thing it would pro vide 73.3% 19 Answ er hiding in plain sight Searc hes for complex solution; ov erlo oks answ er stated in the question 59.2% 20 Negation/exception logic Miscoun ts nested negations; gets p olar- it y backw ards 60.8% 13 T able 2: Models ev aluated. “Think” denotes extended thinking (reasoning) mo de. Mo del Pro vider V ariant Claude Haiku 4.5 An thropic Standard Claude Sonnet 4.6 An thropic Standard Claude Opus 4.6 An thropic Standard Claude Opus 4.6 Think An thropic Extended thinking GPT-4o Mini Op enAI Standard GPT-4o Op enAI Standard GPT-5.4 Op enAI Standard GPT-5.4 Think Op enAI Extended thinking T able 3: Overall leaderb oard on BrainBench (English). Consistency measures the fraction of questions answered correctly in all 10 runs. Gap = Accuracy − Consistency . Rank Mo del Accuracy Consistency Gap Correct/T otal 1 Claude Opus 4.6 Think 80.3% 74.0% 6.3 pp 241/300 2 Claude Opus 4.6 77.3% 71.0% 6.3 pp 232/300 3 Claude Sonnet 4.6 76.7% 69.0% 7.7 pp 230/300 4 Claude Haiku 4.5 74.3% 58.0% 16.3 pp 223/300 5 GPT-5.4 Think 74.0% 64.0% 10.0 pp 222/300 6 GPT-5.4 70.7% 63.0% 7.7 pp 212/300 7 GPT-4o Mini 39.7% 24.0% 15.7 pp 119/300 8 GPT-4o 39.7% 27.0% 12.7 pp 119/300 T able 4: Cross-lingual comparison: English vs. Chinese accuracy . ∆ is Chinese min us English. Mo del English Chinese ∆ Direction Claude Opus 4.6 Think 80.3% 80.0% − 0.3 pp EN > CN Claude Opus 4.6 77.3% 83.3% + 6.0 pp CN > EN Claude Sonnet 4.6 76.7% 73.0% − 3.7 pp EN > CN Claude Haiku 4.5 74.3% 69.7% − 4.7 pp EN > CN GPT-5.4 Think 74.0% 65.7% − 8.3 pp EN > CN GPT-5.4 70.7% 70.7% ± 0.0 pp Equal GPT-4o Mini 39.7% 32.3% − 7.3 pp EN > CN GPT-4o 39.7% 37.0% − 2.7 pp EN > CN A verage 66.6% 64.0% − 2.6 pp 14 T able 5: Categories ranked by a verage accuracy (hardest first). Rank Category A vg Acc. Hardest F or Easiest F or 1 Implicit physical constrain t 40.0% GPT-4o Mini (0%) Claude Opus 4.6 (73%) 2 W rong v antage p oint 40.0% GPT-4o (0%) Claude Haiku 4.5 (67%) 3 Seman tic scop e trick 50.0% GPT-4o Mini (40%) GPT-4o (60%) 4 Default assumption hijack 51.7% GPT-4o Mini (7%) Claude Opus Think (87%) 5 Pragmatic/so cial inten t 56.7% GPT-4o (33%) GPT-5.4 Think (80%) 6 Answ er hiding in plain sight 59.2% GPT-4o Mini (33%) Claude Opus Think (87%) 7 Negation/exception logic 60.8% GPT-5.4 Think (47%) GPT-4o Mini (73%) 8 Brok en/dead device self-ref. 60.8% GPT-4o Mini (20%) Haiku/Sonnet (80%) 9 W rong test conditions 63.3% GPT-4o (0%) Claude Sonnet 4.6 (93%) 10 Red herring ov erload 70.0% GPT-4o Mini (40%) Claude Haiku 4.5 (93%) 11 F raming/anchoring trap 70.8% GPT-4o Mini (47%) GPT-4o (80%) 12 Self-defeating action 72.5% GPT-4o Mini (47%) Multiple (80%) 13 Circular dep endency 73.3% GPT-4o (33%) Claude Sonnet (100%) 14 Naiv e physics error 73.3% GPT-4o (40%) Claude Opus 4.6 (93%) 15 Em b edded false premise 75.8% GPT-4o Mini (7%) Haiku/Opus (100%) 16 Goal–means mismatch 78.3% GPT-4o (27%) Haiku 4.5 (100%) 17 T emp oral imp ossibility 78.3% GPT-4o (13%) Haiku 4.5 (100%) 18 State/iden tit y tracking 80.0% GPT-4o Mini (60%) Haiku/Opus (93%) 19 Quan tit y/counting illusion 81.7% GPT-4o Mini (47%) Claude Opus 4.6 (100%) 20 Scale/gro wth intuition fail. 95.0% GPT-4o Mini (80%) Multiple (100%) T able 6: Accuracy c hange (in pp) from enabling extended thinking mo de. Bold indicates changes ≥ 10 pp in magnitude. Category GPT-5.4 ∆ Claude Opus ∆ Pragmatic/so cial inten t + 26.7 + 33.3 Answ er hiding in plain sight + 20.0 + 20.0 W rong test conditions + 20.0 0.0 Implicit physical constrain t + 13.3 − 6.7 Seman tic scop e trick + 13.3 − 20.0 Default assumption hijack 0.0 + 20.0 Brok en/dead device self-ref. + 6.7 + 20.0 W rong v antage p oint − 6.7 + 6.7 Naiv e physics error − 26.7 0.0 Negation/exception logic − 13.3 0.0 Circular dep endency − 6.7 − 6.7 State/iden tit y tracking 0.0 − 6.7 15
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment