BrainBench 대형 언어 모델 상식 추론 격차 분석
BrainBench는 20가지 인지 함정으로 구분된 100개의 뇌티저 질문을 제공해 LLM의 상식 추론 약점을 정밀 진단한다. 8개 최신 모델을 제로샷·10회 반복 평가한 결과, 최고 모델인 Claude Opus 4.6 Think이 80.3% 정확도에 그쳤으며, GPT‑4o는 39.7%에 머물렀다. 정확도와 일관성 사이에 6~16 pp 차이가 나타나며, 중국어 번역에서도 2~8 pp 감소해 언어와 무관한 추론 결함임을 확인한다.
저자: Yuzhe Tang
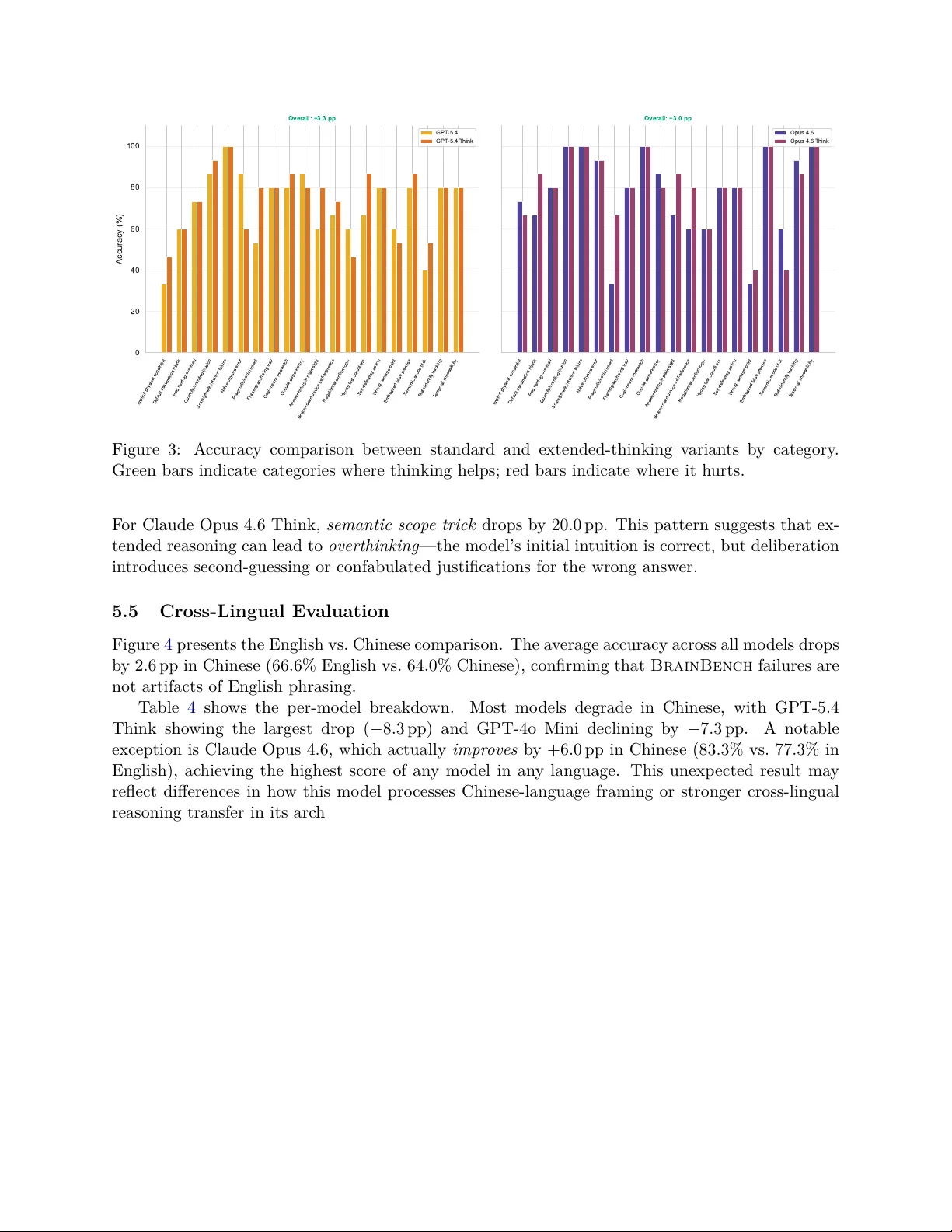
본 논문은 대형 언어 모델(LLM)이 표준 벤치마크에서는 높은 점수를 받지만, 인간이 몇 초 만에 풀 수 있는 상식 기반 질문에서는 일관되게 실패한다는 문제점을 지적한다. 이를 해결하기 위해 저자들은 “BrainBench”라는 새로운 벤치마크를 제안한다. BrainBench는 20개의 상식 추론 실패 유형을 정의하고, 각 유형당 5개의 질문, 총 100개의 뇌티저 문제를 포함한다. 각 질문은 (1) 인간에게는 즉각적으로 정답이 명확히 드러나는 수준, (2) 특정 표면 히스토리(예: 거리 최적화, 일반적 문화 스테레오타입 등)를 유도하도록 설계되었으며, (3) 정답이 명확히 결정될 수 있도록 구성된다.
20가지 카테고리는 물리적 추론(암묵적 물리적 제약, 나이브 물리 오류 등), 언어·의미 추론(의미 범위 트릭, 부정·예외 논리 등), 논리·추론(잘못된 전제, 목표‑수단 불일치 등), 사회·프래그마틱 추론(디폴트 가정 하이재킹, 사회적 의도 등) 등으로 구분된다. 이러한 분류는 기존 벤치마크가 제공하지 못한 “왜 LLM이 틀리는가”에 대한 인지적 메커니즘을 명시한다.
평가에서는 Claude와 GPT 두 패밀리에서 각각 4개씩, 총 8개의 최신 모델을 선정했다. 각 모델은 제로샷 설정으로 질문을 단일 프롬프트에 넣어 10번 독립 실행한다. 정답 여부는 강력한 LLM 판정자를 이용해 자동화했으며, 인간 검증을 통해 판정 정확성을 확보했다. 두 가지 핵심 지표를 사용한다: (1) 정확도 – 10번 실행 중 정답 비율, (2) 일관성 – 10번 모두 정답을 맞춘 비율. 정확도와 일관성 사이의 차이는 모델이 확률적 출력에 얼마나 의존하는지를 나타낸다.
실험 결과, Claude Opus 4.6 Think이 80.3 % 정확도로 최고 성능을 보였지만, 일관성은 74 %에 그쳐 약 6 pp 차이를 보였다. 반면 GPT‑4o는 전체 39.7 % 정확도에 머물렀으며, 일관성은 24 %로 큰 격차를 나타냈다. 전체 모델 평균 정확도 차이는 약 40 pp에 달해, BrainBench가 모델 간 실력을 명확히 구분함을 확인했다. 카테고리별 성능을 살펴보면, “암묵적 물리적 제약”과 “잘못된 시점”은 모든 모델에서 평균 40 % 이하, 특히 GPT‑4o는 0 %를 기록했다. 반면 “스케일·성장 직관”과 “수량·계산 착시”는 80~95 % 수준으로 비교적 쉬운 편이었다. 이는 모델이 특정 유형의 추론에서는 충분히 학습되었지만, 물리적 세계와 직접 연결된 상식에는 여전히 큰 결함이 있음을 보여준다.
확장 사고(Extended Thinking) 모드, 즉 체인‑오브‑쓰스팅을 적용한 변형을 실험했을 때, 전체 정확도는 평균 +3 pp 정도 상승했지만, 카테고리별로는 편차가 크다. 특히 “프래그마틱·사회적 의도”, “정답 숨기기”, “잘못된 테스트 조건” 등 다단계 논리와 상황 판단이 요구되는 영역에서 큰 이득을 보였지만, “암묵적 물리적 제약”과 같은 직관적 함정에서는 오히려 성능이 감소했다. 이는 추가 연산이 반드시 깊은 이해를 의미하지 않으며, 모델이 히스토리 기반 패턴을 과도하게 활용할 위험이 있음을 시사한다.
또한, 동일한 질문을 중국어로 번역해 8개 모델을 동일 프로토콜로 평가했다. 대부분의 모델이 2~8 pp 정확도 감소를 보였으며, 특히 GPT‑4o는 중국어에서도 0 %에 가까운 성능을 기록했다. 이는 오류가 영어 특유의 어휘·구문에 의존한 것이 아니라, 근본적인 추론 메커니즘의 결함임을 뒷받침한다.
결론적으로, BrainBench는 LLM의 상식 추론 능력을 세밀하게 진단할 수 있는 도구이며, 모델 개발 단계에서 특정 인지 함정을 목표로 한 데이터 보강·미세조정 전략을 설계하는 데 활용될 수 있다. 정확도와 일관성 간 격차를 통해 모델의 확률적 출력 안정성을 평가함으로써, 실제 서비스 환경에서의 신뢰성을 판단하는 기준도 제공한다. 향후 연구에서는 더 다양한 언어와 도메인에 대한 확장, 그리고 인간‑모델 협업을 통한 오류 교정 메커니즘 개발이 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기