Prompt Sensitivity and Answer Consistency of Small Open-Source Language Models for Clinical Question Answering in Low-Resource Healthcare
Small open-source language models are gaining attention for healthcare applications in low-resource settings where cloud infrastructure and GPU hardware may be unavailable. However, the reliability of these models under different phrasings of the sam…
Authors: Shravani Hariprasad
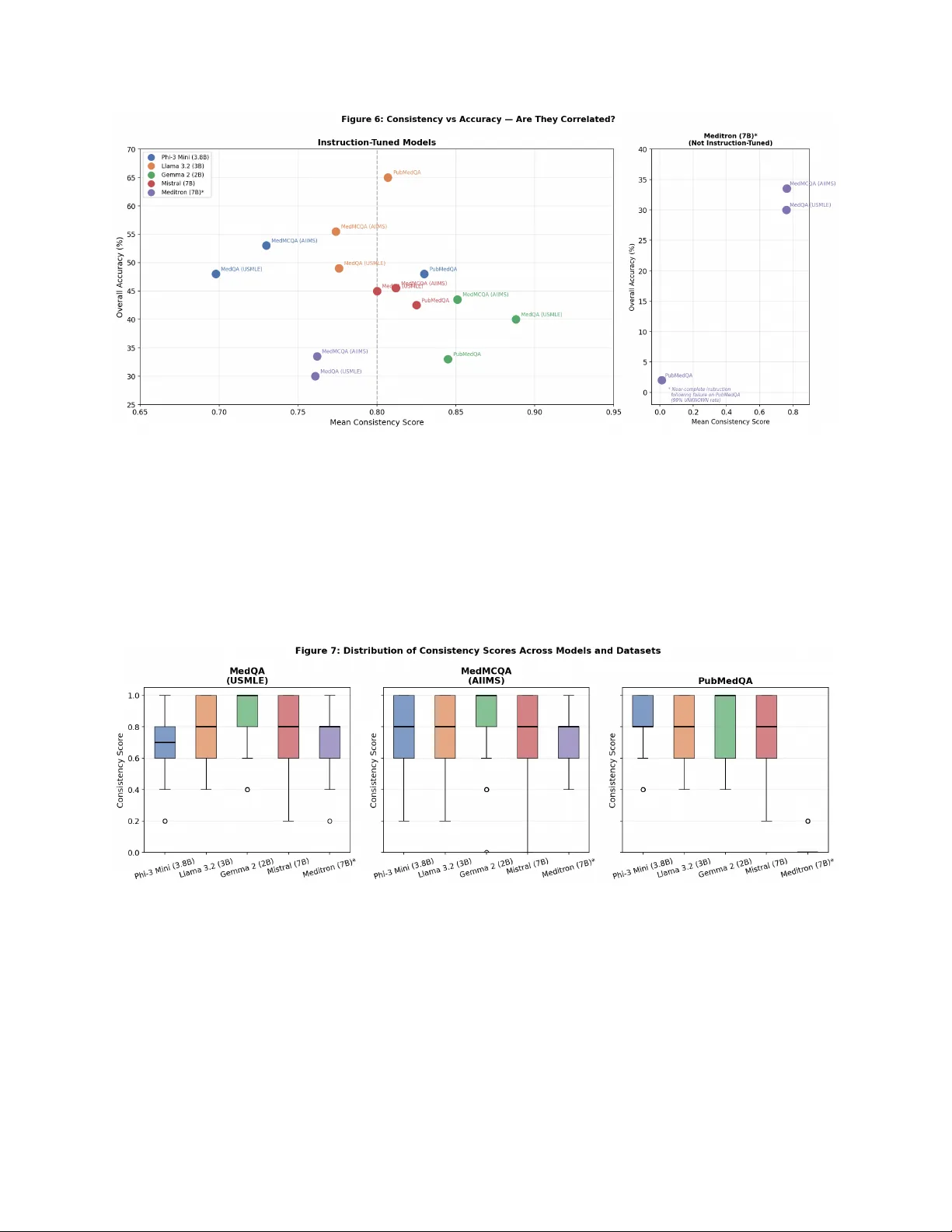
Prompt Sensitivit y and Answ er Consistency in Small Op en-Source Language Mo dels for Clinical Question Answ ering: An Empirical Ev aluation for Lo w-Resource Healthcare Deplo ymen t Shra v ani Hariprasad Indep endent R ese ar cher Abstract Bac kground: Artificial intelligence is increasingly deplo y ed in healthcare w ork- flo ws, and small open-source language mo dels are gaining atten tion as viable to ols for lo w-resource settings where cloud infrastructure is unav ailable. Despite their growing accessibilit y , the reliability of these mo dels, particularly the stabilit y of their outputs under different phrasings of the same clinical question, remains p o orly understo o d. Ob jectiv e: This study systematically ev aluates prompt sensitivit y and answer con- sistency in small op en-source language mo dels on clinical question answering b ench- marks, with implications for lo w-resource healthcare deplo yment. Metho ds: Fiv e op en-source language mo dels spanning distinct arc hitectural and training paradigms w ere ev aluated across three clinical question answ ering datasets (MedQA, MedMCQA, PubMedQA) using fiv e con trolled prompt style v ariations, yield- ing 15,000 total inference calls conducted lo cally on consumer CPU hardware without 1 fine-tuning. Consistency scores, accuracy , and instruction-following failure rates were measured and interpreted in the context of each mo del’s architectural design. Results: Consistency and accuracy were largely indep enden t across mo dels and datasets. Gemma 2 achiev ed the highest consistency scores (0.845–0.888) but the lo w- est accuracy (33.0–43.5%), pro ducing p erfectly consisten t yet incorrect answ ers on 77 of 200 MedQA questions (38.5%), a failure mo de termed r eliable inc orr e ctness . Llama 3.2 demonstrated mo derate consistency (0.774–0.807) alongside the highest accuracy (49.0–65.0%). Rolepla y prompts consisten tly reduced accuracy across all mo dels and datasets, with Phi-3 Mini sho wing the largest decline of 21.5 p ercentage points on MedQA. Instruction-follo wing failure rates v aried by mo del and were not determined b y parameter count, with Phi-3 Mini exhibiting the highest UNKNOWN rate at 10.5% on MedQA. Meditron-7B, a domain-pretrained mo del without instruction tuning, ex- hibited near-complete instruction-following failure on PubMedQA (99.0% UNKNO WN rate), demonstrating that domain knowledge alone is insufficient for structured clinical question answering. Conclusions: High consistency do es not imply correctness in small clinical lan- guage mo dels; mo dels can b e reliably incorrect, represen ting a p oten tially dangerous failure mo de in clinical decision supp ort. Rolepla y prompt styles should b e av oided in healthcare AI applications. Among the mo dels ev aluated, Llama 3.2 demonstrated the strongest balance of accuracy and reliabilit y for lo w-resource deplo yment. These findings highlight the necessity of multidimensional ev aluation frameworks that assess consistency , accuracy , and instruction adherence jointly for safe clinical AI deplo yment. Keyw ords: prompt sensitivit y , answer consistency , small language mo dels, clinical question answ ering, large language mo dels, lo w-resource healthcare, instruction following, medical AI 2 Con ten ts 1 In tro duction 4 2 Related W ork 6 3 Metho ds 7 3.1 Datasets . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7 3.2 Mo dels . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8 3.3 Prompt V ariation Design . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10 3.4 Inference Setup . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11 3.5 Ev aluation Metrics . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11 4 Results 13 4.1 Ov erall Consistency and Accuracy . . . . . . . . . . . . . . . . . . . . . . . . 13 4.2 Effect of Prompt Sty le on Accuracy . . . . . . . . . . . . . . . . . . . . . . . 18 4.3 Instruction-F ollo wing F ailure Rate . . . . . . . . . . . . . . . . . . . . . . . . 20 4.4 Consistency V ersus Accuracy Relationship . . . . . . . . . . . . . . . . . . . 22 5 Discussion 24 5.1 Consistency and Accuracy are Indep endent Metrics . . . . . . . . . . . . . . 24 5.2 Rolepla y Prompts Consistently Underp erform . . . . . . . . . . . . . . . . . 26 5.3 Implications for Low-Resource Healthcare Deploymen t . . . . . . . . . . . . 27 5.4 Domain Knowledge V ersus Instruction F ollowing . . . . . . . . . . . . . . . . 28 5.5 Limitations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29 5.6 F uture W ork . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30 6 Conclusion 32 A Represen tativ e Prompt V ariation Example 35 3 1 In tro duction Artificial intelligence is increasingly b eing in tegrated in to healthcare w orkflo ws, including clinical decision supp ort, medical do cumen tation, and exam-style clinical question answering. While muc h atten tion has focused on large cloud-based mo dels, smaller op en-source language mo dels are gaining imp ortance because they can run lo cally on standard CPUs, making them viable for rural clinics, comm unity hospitals, and low-resource health systems with limited infrastructure [Garg et al., 2024]. As these smaller mo dels b ecome more accessible for real- w orld deploymen t, questions ab out their reliability b ecome critical. In clinical settings, ev en small inaccuracies can hav e significan t consequences, and the safety of AI systems dep ends not only on their o verall p erformance but also on how stable and predictable their outputs are under different conditions. Despite increasing adoption, the reliability of small, lo cally deplo y able mo dels in healthcare remains insufficiently studied. Most existing ev aluations of clinical language mo dels fo cus primarily on accuracy , that is, whether a mo del selects the correct answ er on a giv en b enc hmark [Bedi et al., 2025]. Ho w ever, accuracy alone do es not capture how stable a mo del’s outputs are when the same clinical question is phrased differently . In safet y-critical domains such as healthcare, this distinction is imp ortant. A mo del that giv es different answers dep ending on ho w a question is worded cannot b e considered reliable, regardless of its aggregate accuracy score. Prior work has not systematically ev aluated whether small, CPU-runnable language mo d- els pro vide consistent answers under con trolled prompt v ariation in clinical contexts. The CLEVER framew ork [Ko caman et al., 2025] ev aluates clinical LLM outputs through ph ysi- cian preference but do es not assess resp onse stabilit y across prompt reformulations. Ngw eta et al. [Ngw eta et al., 2024] quantify prompt brittleness in general NLP tasks but do not examine clinical datasets or safety implications. Kim et al. [Kim et al., 2025] demonstrate that foundation mo dels frequen tly pro duce confiden t but incorrect medical outputs, yet do not empirically measure v ariabilit y under prompt c hanges. Surv eys on small language mo d- els in healthcare [Garg et al., 2024] discuss efficiency and deploymen t tradeoffs but do not 4 analyze answer consistency as a reliability dimension. The present study addresses this gap. This study addresses three researc h questions: R Q1: Do small op en-source language mo dels pro duce consistent answers when semanti- cally equiv alent clinical questions are phrased differently? R Q2: Is answ er consistency correlated with clinical question answ ering accuracy? R Q3: Ho w do differen t prompt st yles influence the reliability of mo del outputs? T o inv estigate these questions, this w ork ev aluates fiv e op en-source language mo dels—Phi- 3 Mini (3.8B), Llama 3.2 (3B), Gemma 2 (2B), Mistral 7B, and Meditron-7B (domain- pretrained)— across three established clinical question answering b enchmarks (MedQA, MedMCQA, and PubMedQA). Eac h question is ev aluated under five controlled prompt styles designed to sim ulate realistic query reform ulation. A quantitativ e consistency score is intro- duced to measure how often a mo del pro duces the same answ er across prompt v ariations for the same question, and this metric is analyzed alongside ov erall accuracy , p er-st yle accuracy , and instruction-follo wing failure rates. All exp eriments were conducted lo cally on consumer CPU hardw are using unmo dified base mo dels without medical fine-tuning, reflecting realistic deplo ymen t conditions in low-resource healthcare en vironments. The analysis yields sev eral k ey findings. First, consistency and accuracy emerge as inde- p enden t p erformance dimensions: mo dels that pro duce highly stable answers across prompt v ariations are not necessarily more accurate. Second, roleplay prompt st yles consistently re- duce p erformance across mo dels and datasets, indicating that p ersona-based prompting may degrade reliabilit y in clinical question answ ering tasks. Third, instruction-follo wing failures v ary indep enden tly of mo del size, suggesting that larger parameter coun ts do not guar- an tee more dep endable outputs. Finally , Meditron-7B, a domain-pretrained mo del without instruction tuning, exhibits near-complete instruction-following failure despite enco ding sub- stan tial medical kno wledge, demonstrating that domain kno wledge and instruction-follo wing capabilit y are distinct requirements for clinical AI deploymen t. The remainder of this paper is structured as follows. Section 2 reviews related w ork 5 on clinical LLM ev aluation, prompt sensitivit y , and small language mo dels in healthcare. Section 3 describ es the datasets, mo dels, prompt v ariation design, inference setup, and ev aluation metrics. Section 4 presents exp erimen tal results. Section 5 discusses clinical implications, limitations, and future directions. Section 6 concludes the pap er. 2 Related W ork Most prior w ork ev aluating large language mo dels in healthcare has fo cused on accuracy , rea- soning qualit y , and output safet y . The CLEVER framew ork [Ko caman et al., 2025] ev aluates clinical LLM outputs through blinded ph ysician preference on tasks including summarization and question answering, demonstrating that smaller domain-sp ecific mo dels can outp erform larger general-purp ose systems on clinically relev ant criteria. Kim et al. [Kim et al., 2025] systematically examine medical hallucinations in foundation mo dels, highligh ting the dangers of confident but incorrect outputs and their p otential to mislead clinical decision-making. While these studies provide critical insights into output quality and safety , neither inv esti- gates whether mo dels pro duce consistent answ ers when the same clinical question is phrased differen tly , leaving prompt sensitivit y largely unexplored in healthcare AI. Gro wing interest in small, CPU-runnable language mo dels has emerged in resp onse to the practical constrain ts of healthcare deploymen t in low-resource settings. Garg et al. [Garg et al., 2024] surv ey small language mo dels in healthcare, do cumenting their efficiency adv an tages and suitabilit y for lo cal deplo yment under limited infrastructure. The MedQA [Jin et al., 2021], MedMCQA [P al et al., 2022], and PubMedQA [Jin et al., 2019] b enc hmarks pro vide standardized ev aluation tasks across diverse clinical question formats and hav e b een widely adopted for assessing compact mo dels. These works collectively adv ance the case for small model deploymen t in accessible healthcare AI but fo cus primarily on task accuracy and computational efficiency rather than answer stability under prompt v ariation. Prompt sensitivit y , defined as the tendency of mo del outputs to change in resp onse to 6 seman tically equiv alent but stylistically differen t inputs, has b een studied in general NLP researc h. Ngweta et al. [Ngw eta et al., 2024] demonstrate that minor changes in prompt for- matting cause measurable p erformance fluctuations across multiple mo dels and b enc hmarks and propose mitigation strategies to reduce this brittleness. Ho w ev er, suc h in v estigations ha v e not b een extended to clinical question answ ering, and the safety implications of prompt sensitivit y for healthcare AI deploymen t remain largely unexplored. T ak en together, these lines of research motiv ate the presen t study , which systematically ev aluates prompt sensitivity and answer consistency in small op en-source clinical language mo dels. This work complements prior studies on accuracy , hallucination, and general prompt robustness by fo cusing on reliabilit y under realistic deploymen t constraints. 3 Metho ds This study follo ws a controlled empirical ev aluation design to assess the reliability of small language mo dels under prompt v ariation in clinical question answering tasks. 3.1 Datasets Mo del consistency and accuracy w ere ev aluated using three established clinical question answ ering b enc hmarks. MedQA [Jin et al., 2021] con tains m ultiple-choice questions de- riv ed from the United States Medical Licensing Examination (USMLE), represen ting clinical kno wledge required for medical licensure. MedMCQA [P al et al., 2022] consists of multiple- c hoice questions from Indian medical entrance examinations (AI IMS/NEET), co vering di- v erse medical sp ecialties including pharmacology , anatom y , and pathology . Although the dataset includes sub ject lab els, the ev aluation was conducted on a randomly sampled subset of 200 questions without stratification by sp ecialty . PubMedQA [Jin et al., 2019] presen ts biomedical research questions paired with PubMed abstracts, requiring y es, no, or ma yb e answ ers based on provided evidence rather than memorized kno wledge. 7 F rom eac h dataset, 200 questions w ere randomly sampled using a fixed random seed (seed = 42) to ensure repro ducibility . This sample size was selected to balance statistical co v erage with the computational constrain ts of lo cal CPU inference across m ultiple mo dels and prompt v ariations, resulting in 15,000 total inference calls. 3.2 Mo dels Fiv e open-source language models spanning 2B–7B parameters w ere ev aluated, including one domain-adapted medical pretraining mo del. T able 1 summarises the architectural and training c haracteristics of each model. The four instruction-tuned mo dels differ in their fine-tuning metho dology , pretraining scale, and prompt template conv entions in wa ys that plausibly influence prompt sensitivit y b ehaviour. Phi-3 Mini [Ab din et al., 2024] (3.8B, Microsoft) is a dense deco der-only transformer fine- tuned using Sup ervised Fine-T uning (SFT), Direct Preference Optimisation (DPO), and Re- inforcemen t Learning from Human F eedbac k (RLHF). Its pretraining relies heavily on high- qualit y synthetic data and filtered educational conten t, an approach motiv ated by the “text- b o oks are all y ou need” philosoph y . This regime prioritises structured reasoning and instruc- tion adherence; how ever, the mo del’s strict chat template format ( <|user|>...<|end|> ) ma y create sensitivity to prompts that deviate from this exp ected structure, contributing to the elev ated UNKNOWN rate observed on MedQA. Llama 3.2 [Grattafiori et al., 2024] (3B, Meta) is deriv ed from Llama 3.1 via pruning and kno wledge distillation from larger Llama 3.1 mo dels (8B and 70B), follow ed by multi- ple rounds of p ost-training alignmen t using SFT, Rejection Sampling (RS), and DPO. This m ulti-round alignmen t pro cess, explicitly optimising dialogue helpfulness across v aried in- struction formats, lik ely contributes to the mo del’s strong instruction-follo wing p erformance and its low UNKNO WN rates across all datasets. Gemma 2 [Gemma T eam et al., 2024] (2B, Go ogle DeepMind) is trained via knowledge distillation from a substantially larger teac her mo del rather than standard next-token pre- 8 diction, using on-p olicy distillation to mitigate train-inference distribution mismatc h. P ost- training applies SFT, RLHF with a con v ersational reward mo del, and mo del merging across h yp erparameter configurations. Kno wledge distillation at this scale may instil stable but p oten tially miscalibrated resp onse tendencies inherited from the teac her mo del, providing a mec hanistic accoun t of Gemma 2’s high consistency scores alongside its low accuracy: the mo del may b e replicating confident resp onse patterns from its teacher that do not generalise correctly to clinical reasoning tasks. Mistral [Jiang et al., 2023] (7B, Mistral AI) uses sliding window attention and group ed- query attention for efficient inference, and is instruction-tuned using SFT on publicly av ail- able conv ersation datasets. Compared to Llama 3.2 and Phi-3, Mistral’s instruct fine-tuning used a more limited set of public instruction data and requires strict [INST]...[/INST] delimiters. Prompts that do not conform to this format ma y partially escap e instruction alignmen t, potentially contributing to higher UNKNO WN rates relativ e to Llama 3.2 and Gemma 2. Meditron-7B [Chen et al., 2023] (EPFL) is built on Llama-2 and further pretrained on a curated medical corpus comprising PubMed abstracts and in ternational clinical practice guidelines. Critically , Meditron-7B is a con tinued-pretraining mo del without instruction tuning; it has not b een trained to follow structured task instructions or pro duce constrained single-tok en outputs. Its inclusion serves as an arc hitectural con trol condition: by contrasting a domain-kno wledgeable but non-instruction-tuned mo del against instruction-tuned general mo dels, this study isolates instruction-follo wing capabilit y as a distinct and necessary ar- c hitectural requiremen t for structured clinical question answering, indep enden t of domain kno wledge. All mo dels w ere selected b ecause they are fully op en-source, capable of running on consumer CPU hardware without GPU acceleration, and represen t distinct mo del families with meaningfully different training metho dologies, enabling cross-architecture comparison of consistency b ehaviour. All inference w as conducted lo cally using Ollama without domain- 9 sp ecific fine-tuning, ensuring that observed consistency patterns reflect inheren t mo del b e- ha viour rather than task-sp ecific adaptation. T able 1: Architectural and training characteristics of ev aluated mo dels. SFT = Sup ervised Fine-T uning; DPO = Direct Preference Optimisation; RLHF = Reinforcement Learning from Human F eedback; RS = Rejection Sampling; KD = Kno wledge Distillation. † Meditron-7B is a contin ued pretraining mo del without instruction tuning; its chat template is effectiv ely undefined. Model Params Base Model Inst. T uned Fine-T uning Method Medical Domain Chat T emplate Phi-3 Mini 3.8B Phi-3 (Microsoft) Y es SFT + DPO + RLHF No <|user|>..<|end|> Llama 3.2 3B Llama 3.1 (Meta) Y es SFT + RS + DPO (multi-round) No <|start header id|>..<|eot id|> Gemma 2 2B Gemma 2 (Google) Y es KD + SFT + RLHF + Model Merging No .. Mistral 7B 7B Mistral (Mistral AI) Y es SFT (public datasets) No [INST]..[/INST] Meditron-7B † 7B Llama-2 (Meta) No Continued pretraining only (PubMed + guidelines) Y es None 3.3 Prompt V ariation Design T o systematically ev aluate how small language mo dels resp ond to differently worded clinical prompts, a prompt v ariation engine w as designed to generate fiv e seman tically equiv alent but stylistically distinct prompt formulations for eac h question. • Original: The question exactly as it app ears in the dataset, serving as the baseline condition. • F ormal: Rephrased in clinical academic language to sim ulate ho w a healthcare pro- fessional might query a mo del in a structured setting. • Simplified: W ritten in plain everyda y language, sim ulating how a non-exp ert or pa- tien t migh t p ose the same question. • Rolepla y: The mo del is instructed to resp ond as a practicing ph ysician, testing whether p ersona-based prompting affects answer consistency . • Direct: Presents only the bare question and answ er options with minimal framing, assessing mo del b ehavior without explicit instruction. 10 Eac h question across all three datasets w as transformed in to these fiv e prompt st yles, yielding 3,000 total prompts (600 questions × 5 st yles). By k eeping seman tic conten t identical across v ariations, an y differences in mo del output can b e attributed to prompt sensitivit y rather than differences in question conten t. 3.4 Inference Setup All mo dels were serv ed lo cally via Ollama and queried through its REST API. Inference was conducted with temp erature set to 0 and a maximum token limit of 10 tokens p er resp onse. Setting temp erature to 0 ensures deterministic outputs, meaning that identical prompts pro duce identical resp onses across runs. This configuration isolates prompt v ariation as the primary source of output differences rather than sto chastic sampling effects. Limiting output to 10 tokens preven ts v erb ose responses and constrains the mo del to pro duce the single-letter (A, B, C, or D) or keyw ord (yes, no, or maybe) answ er required by each dataset format. Mo del responses w ere parsed using regular expression extraction. F or multiple-c hoice datasets (MedQA and MedMCQA), the extractor iden tified the first standalone letter A, B, C, or D in the response. F or PubMedQA, the extractor iden tified the first o ccurrence of yes , no , or maybe . Responses that did not contain a v alid answer w ere categorized as UNKNOWN , represen ting instruction-following failures where the mo del do es not pro duce a v alid answ er option. All resp onses, including UNKNOWN outputs, were retained for consistency scoring and subsequen t analysis. All inference parameters were held constant across mo dels and prompt st yles to ensure fair comparison. 3.5 Ev aluation Metrics F our complementary metrics w ere defined to quan tify mo del b eha vior under prompt v aria- tion. Consistency Score. F or each question, the ma jorit y answ er was identified, defined as the resp onse selected most frequently across the five prompt st yles, and the prop ortion of 11 prompt styles that agreed with it was computed. F ormally , giv en resp onses r 1 , r 2 , r 3 , r 4 , r 5 for a question, the consistency score was defined as: C = P 5 i =1 1 [ r i = ˆ r ] 5 (1) where ˆ r denotes the ma jorit y answer and 1 [ · ] is the indicator function. A score of 1.0 indicates perfect consistency across all prompt st yles, while a score of 0.2 indicates maxim um inconsistency . F or example, resp onses [A, B, B, B, A] yield a ma jority answ er of B and a consistency score of 3 / 5 = 0 . 60. Ov erall Accuracy . The ma jority answer for eac h question is compared with the dataset ground-truth lab el, reflecting task-lev el correctness while accoun ting for v ariability across prompt styles. P er-St yle Accuracy . Accuracy is computed separately for each prompt st yle (original, formal, simplified, roleplay , direct), enabling identification of whic h prompt formulations the mo del handles most and least reliably . UNKNO WN Rate. The prop ortion of resp onses that do not contain a v alid answer option (A–D or yes/no/ma yb e), represen ting instruction-follo wing failures that undermine clinical reliability . Statistical significance was assessed using the Wilcoxon signed-rank test for comparisons of consistency scores and McNemar’s test for paired accuracy comparisons. All p-v alues are rep orted without adjustmen t for m ultiple comparisons. Because the analysis is exploratory and h yp othesis-generating, no correction for multiple testing was applied, consisten t with prior exploratory clinical AI b enc hmarking studies [Bedi et al., 2025]. Individual p-v alues should therefore b e interpreted cautiously rather than as confirmatory statistical evidence. T ogether, these metrics provide a holistic assessment of mo del b eha vior. A mo del may b e highly consistent y et systematically incorrect, accurate only under sp ecific prompt styles, or prone to instruction-follo wing failures. Ev aluating any single metric in isolation w ould obscure these clinically relev an t failure mo des. 12 4 Results 4.1 Ov erall Consistency and Accuracy T able 2: Summary of consistency scores, ov erall accuracy , and instruction-follo wing failure rates across all mo dels and datasets. The best v alue among instruction-tuned mo dels is sho wn in b old . † Meditron-7B is a pretraining mo del without instruction tuning; high UN- KNO WN rates reflect instruction-following failure rather than lack of domain knowledge. Dataset Mo del Mean F ully Overall UNKNO WN Acc. Acc. Acc. Acc. Acc. Cons. Cons. Acc. Rate Orig. F orm. Simp. Role. Dir. (%) (%) (%) (%) (%) (%) (%) (%) MedQA Phi-3 Mini 0.698 19.5 48.0 10.5 44.5 44.5 42.5 26.5 48.0 Llama 3.2 0.776 35.0 49.0 0.8 47.5 44.5 46.0 47.0 43.5 Gemma 2 0.888 63.5 40.0 2.1 39.0 39.0 37.0 35.0 35.0 Mistral 7B 0.800 41.0 45.0 4.7 45.5 41.5 43.0 34.0 50.5 Meditron † 0.761 10.0 30.0 22.8 4.0 26.5 28.0 29.5 30.5 MedMCQA Phi-3 Mini 0.730 27.0 53.0 4.6 52.0 49.5 48.5 37.5 52.0 Llama 3.2 0.774 38.5 55.5 1.5 56.5 50.5 51.5 48.0 53.0 Gemma 2 0.851 56.5 43.5 0.9 42.5 39.0 38.0 40.5 44.0 Mistral 7B 0.812 45.5 45.5 4.7 44.5 43.0 42.5 41.5 44.0 Meditron † 0.762 8.0 33.5 22.4 4.0 33.0 30.0 33.5 29.5 PubMedQA Phi-3 Mini 0.830 41.0 48.0 0.0 42.5 53.5 52.5 47.5 31.0 Llama 3.2 0.807 45.5 65.0 2.8 59.5 51.0 64.5 65.0 56.5 Gemma 2 0.845 50.5 33.0 1.3 28.0 41.5 47.5 27.0 30.5 Mistral 7B 0.825 49.5 42.5 7.2 39.5 39.5 45.5 34.5 45.5 Meditron † 0.010 0.0 2.0 99.0 0.0 0.0 1.5 0.0 0.5 Statistical significance of observed differences was assessed using the Wilcoxon signed-rank test for consistency scores and McNemar’s test for accuracy comparisons. Consistency differ- ences b etw een mo dels were statistically significant on MedQA and MedMCQA (p < 0.001 for most pairwise comparisons) but not on PubMedQA, suggesting that dataset characteristics 13 influence the degree of prompt sensitivity . Accuracy differences w ere generally non-significan t on MedQA, whereas on PubMedQA, Llama 3.2 significan tly outp erformed b oth Phi-3 Mini and Gemma 2 (p < 0.001), indicating stronger p erformance on biomedical evidence-based questions. F ull significance test results are provided in T able 3. T able 3: P airwise statistical significance tests. Wilco xon signed-rank test for consistency; McNemar test for ac- curacy . *** p < 0.001, ** p < 0.01, * p < 0.05, ns = not significan t. † Meditron PubMedQA comparisons reflect instruction-follo wing failure (99% UNKNOWN rate). Dataset M1 M2 Metric p Sig. MedQA Llama 3.2 Phi-3 Mini Cons. 0.0005 *** Gemma 2 Phi-3 Mini Cons. < .0001 *** Mistral Phi-3 Mini Cons. < .0001 *** Llama 3.2 Gemma 2 Cons. < .0001 *** Meditron Phi-3 Mini Cons. < .0001 *** Meditron Llama 3.2 Cons. 0.3342 ns Llama 3.2 Phi-3 Mini Acc. 0.9020 ns Gemma 2 Phi-3 Mini Acc. 0.0689 ns Mistral Phi-3 Mini Acc. 0.5383 ns Llama 3.2 Gemma 2 Acc. 0.0512 ns Meditron Phi-3 Mini Acc. 0.0004 *** Meditron Llama 3.2 Acc. 0.0001 *** MedMCQA Llama 3.2 Phi-3 Mini Cons. 0.0437 * Gemma 2 Phi-3 Mini Cons. < .0001 *** Continue d on next p age 14 Dataset M1 M2 Metric p Sig. Mistral Phi-3 Mini Cons. 0.0001 *** Llama 3.2 Gemma 2 Cons. 0.0001 *** Meditron Phi-3 Mini Cons. 0.0007 *** Meditron Llama 3.2 Cons. 0.2052 ns Llama 3.2 Phi-3 Mini Acc. 0.5962 ns Gemma 2 Phi-3 Mini Acc. 0.0327 * Mistral Phi-3 Mini Acc. 0.1060 ns Llama 3.2 Gemma 2 Acc. 0.0075 ** Meditron Phi-3 Mini Acc. 0.0002 *** Meditron Llama 3.2 Acc. < .0001 *** PubMedQA Llama 3.2 Phi-3 Mini Cons. 0.1055 ns Gemma 2 Phi-3 Mini Cons. 0.8497 ns Mistral Phi-3 Mini Cons. 0.6172 ns Llama 3.2 Gemma 2 Cons. 0.1055 ns Meditron † Phi-3 Mini Cons. < .0001 *** Meditron † Llama 3.2 Cons. < .0001 *** Llama 3.2 Phi-3 Mini Acc. < .0001 *** Gemma 2 Phi-3 Mini Acc. 0.0002 *** Mistral Phi-3 Mini Acc. 0.1930 ns Llama 3.2 Gemma 2 Acc. < .0001 *** Meditron Phi-3 Mini Acc. < .0001 *** Meditron Llama 3.2 Acc. < .0001 *** Across all three datasets, consistency scores v aried across mo dels without a clear corre- lation with mo del size (Figure 1). Phi-3 Mini (3.8B) exhibited the low est mean consistency 15 scores (0.698–0.830), while Gemma 2 (2B) ac hiev ed the highest (0.845–0.888) despite b eing the smallest mo del tested. Mistral 7B demonstrated strong but slightly v ariable consistency (0.800–0.825), and Llama 3.2 sho wed intermediate consistency (0.774–0.807). Accuracy patterns diverged substan tially from consistency rankings (Figure 2). Llama 3.2 achiev ed the highest o v erall accuracy across datasets (49.0–65.0%), follo w ed by Phi-3 Mini (48.0–53.0%) and Mistral 7B (42.5–45.5%). Gemma 2, despite exhibiting the highest consistency scores, ac hieved the low est accuracy (33.0–43.5%). This in v erse relationship b et ween consistency and accuracy in Gemma 2 highlights a critical finding: high consistency do es not imply high accuracy . Mo dels can b e r eliably wr ong , pro ducing the same incorrect answ er across all prompt v ariations, which represents a particularly dangerous failure mo de in clinical decision supp ort contexts. Meditron-7B, included as a domain-adapted pretraining mo del without instruction tun- ing, exhibited markedly different b eha vior from all instruction-tuned mo dels. While it ac hiev ed mo derate consistency on MedQA and MedMCQA (0.761 and 0.762, resp ectively), its UNKNO WN rates w ere substan tially higher (22.8% and 22.4%), indicating frequen t instruction-follo wing failures. On PubMedQA, Meditron-7B pro duced near-complete fail- ure, with a consistency score of 0.010, 2.0% accuracy , and a 99.0% UNKNO WN rate. This suggests that the mo del is unable to pro duce structured y es/no/ma yb e responses without instruction tuning. These results indicate that domain-sp ecific pretraining alone is insuffi- cien t for structured clinical question answering and that instruction-following capability is a prerequisite for clinical deplo yment. Due to the extremely high UNKNOWN rate observed for Meditron-7B on PubMedQA (99.0%), statistical comparisons in v olving this mo del on that dataset should b e interpreted cautiously , as the near-absence of v alid resp onses renders consistency metrics unreliable. 16 Figure 1: Mean consistency scores across mo dels and datasets. Higher scores indicate greater agreemen t across prompt styles. 17 Figure 2: Ov erall accuracy across mo dels and datasets, calculated using ma jority answ er against ground truth lab els. 4.2 Effect of Prompt St yle on Accuracy Prompt style demonstrated a consisten t and measurable effect on mo del accuracy across all fiv e mo dels and three datasets (Figure 3). The Roleplay prompt style, in which mo dels were instructed to resp ond as a practicing ph ysician, consistently underp erformed relative to all other styles. The most pronounced decline w as observed in Phi-3 Mini, whic h ac hieved 48.0% accuracy under the Direct st yle but only 26.5% under the Rolepla y st yle on MedQA, repre- 18 sen ting a drop of 21.5 p ercen tage p oin ts. Similar reductions were observ ed across Llama 3.2, Gemma 2, and Mistral 7B, suggesting that roleplay prompting is systematically detrimental rather than mo del-sp ecific (Figure 4). In contrast, the Direct and Original prompt styles pro duced the highest and most stable accuracy across mo dels and datasets, suggesting that minimal framing is preferable for reli- able clinical question answering. These findings carry direct implications for healthcare AI deplo ymen t: prompt form ulations in tended to simulate clinical exp ertise, such as p ersona- based instructions, may parado xically reduce the reliability of small language mo del outputs in patient-facing applications. Figure 3: Accuracy by prompt st yle across mo dels and datasets. Roleplay consistently underp erforms relativ e to other styles. 19 Figure 4: Roleplay prompt accuracy v ersus b est p erforming non-rolepla y st yle across all mo dels and datasets, with annotated p erformance gaps. 4.3 Instruction-F ollo wing F ailure Rate The UNKNO WN rate, defined as the proportion of responses that did not con tain a v alid an- sw er option, v aried substan tially across mo dels and datasets (Figure 5). Phi-3 Mini exhibited the highest UNKNOWN rate on MedQA at 10.5%, indicating that approximately one in ten queries failed to pro duce a usable resp onse. Mistral 7B, despite b eing the largest mo del ev al- uated, also demonstrated non-negligible UNKNO WN rates across all three datasets (4.7%– 7.2%), suggesting that mo del size alone do es not guaran tee reliable instruction following. In con trast, Llama 3.2 and Gemma 2 ac hiev ed the lo west UNKNOWN rates across datasets (0.8%–2.8% and 0.9%–2.1%, resp ectiv ely), consistently pro ducing resp onses in the exp ected format. These results suggest that instruction adherence is a mo del-sp ecific c har- acteristic indep enden t of parameter coun t. Meditron-7B exhibited the most severe instruction-follo wing failures of all mo dels ev al- uated, with UNKNOWN rates of 22.8% on MedQA, 22.4% on MedMCQA, and 99.0% on PubMedQA. The near-complete failure on PubMedQA, where 99 of 100 resp onses w ere in v alid, is consistent with Meditron’s architecture as a base pretraining mo del without in- 20 struction tuning. Unlik e the instruction-follo wing failures observ ed in Phi-3 Mini, whic h app ear to b e prompt-st yle dep enden t, Meditron’s failures reflect a fundamental absence of structured resp onse capability rather than prompt sensitivit y . F rom a clinical deplo yment p ersp ectiv e, high UNKNOWN rates represen t a critical reli- abilit y concern. A mo del that frequen tly fails to pro duce a v alid resp onse cannot serve as a dep endable decision supp ort to ol, as such failures interrupt clinical workflo ws, introduce uncertain t y , and ero de clinician trust in AI-assisted systems. The v ariation in UNKNO WN rates across instruction-tuned mo dels also reflects dif- ferences in the scop e and metho dology of their p ost-training alignment. Llama 3.2 and Gemma 2, which pro duced the low est UNKNO WN rates, underwen t multi-round alignment pro cesses optimising across diverse instruction formats. Mistral 7B and Phi-3 Mini, whic h sho w ed higher UNKNOWN rates on certain datasets, relied on more constrained instruction fine-tuning that ma y b e more sensitive to prompt phrasings that div erge from their exp ected template structures. These patterns suggest that the breadth of instruction format cov erage during fine-tuning, not merely parameter coun t, is the primary architectural determinant of instruction-follo wing reliabilit y in structured clinical tasks. Figure 5: Instruction-follo wing failure rates (UNKNOWN resp onses) across mo dels and datasets. Phi-3 Mini shows the highest failure rate on MedQA at 10.5%. 21 4.4 Consistency V ersus Accuracy Relationship Analysis of the relationship b etw een mean consistency scores and ov erall accuracy rev ealed no clear p ositive correlation across mo dels and datasets (Figure 6). Gemma 2 exemplifies this disconnect most clearly: it achiev ed the highest consistency scores across all datasets (0.845–0.888) while sim ultaneously recording the low est accuracy (33.0–43.5%), indicating that it consisten tly pro duces incorrect answers with high confidence. Con versely , Llama 3.2 demonstrated mo derate consistency (0.774–0.807) y et ac hiev ed the highest accuracy across most datasets (49.0–65.0%), sho wing that a mo del can b e more frequently correct ev en when its answers v ary across prompt styles. The distribution of consistency scores further illustrates mo del-level differences in relia- bilit y (Figure 7). Phi-3 Mini exhibited the widest spread of consistency scores on MedQA, indicating substantial v ariability in prompt sensitivity across questions. Gemma 2 sho wed a tigh ter, higher distribution, remaining consisten tly stable but systematically inaccurate. These findings demonstrate that consistency and accuracy are indep endent dimensions of mo del p erformance. Ev aluating either metric in isolation is insufficient for clinical AI assessmen t. A mo del that is highly consisten t but consisten tly wrong ma y b e more danger- ous than one that o ccasionally contradicts itself, as the former provides false confidence in systematically incorrect outputs. Safe clinical deploymen t therefore requires joint ev aluation of b oth consistency and accuracy . 22 Figure 6: Scatter plot of mean consistency score v ersus o verall accuracy across all mo dels and datasets. No clear p ositive correlation is observed, indicating that consistency and accuracy are indep enden t metrics. Figure 7: Distribution of consistency scores across mo dels and datasets. Phi-3 Mini sho ws the widest spread on MedQA; Gemma 2 shows a tight but high distribution reflecting systematic consistency without accuracy . 23 5 Discussion F rom a clinical informatics persp ective, these findings highligh t the imp ortance of ev aluating AI systems not only for accuracy but also for resp onse stability . Clinical decision supp ort to ols are often queried in multiple w a ys by clinicians, and inconsisten t resp onses to seman ti- cally equiv alent queries ma y undermine trust in AI-assisted systems. Conv ersely , consisten tly incorrect outputs ma y create a false sense of reliabilit y if rep eated answ ers are interpreted as evidence of mo del confidence. Ev aluation frameworks that jointly assess accuracy and re- sp onse stabilit y therefore pro vide a more comprehensiv e basis for assessing whether language mo dels are sufficiently reliable for integration into clinical workflo ws. 5.1 Consistency and Accuracy are Indep enden t Metrics A central empirical finding of this study is that consistency and accuracy represen t indep en- den t dimensions of small language mo del p erformance in clinical question answering. While prior ev aluations of clinical AI hav e predominan tly fo cused on accuracy as the primary met- ric [Bedi et al., 2025], the results presen ted here demonstrate that a mo del can exhibit high consistency while still pro ducing systematically incorrect answers, a failure mo de referred to in this work as r eliable inc orr e ctness . Gemma 2 illustrates this most clearly , ac hieving the highest mean consistency scores across all datasets (0.845–0.888) while recording the low est ov erall accuracy (33.0–43.5%). This pattern suggests that the mo del has learned stable resp onse tendencies that are nonethe- less clinically incorrect. Across 200 MedQA questions, Gemma 2 pro duced p erfectly consis- ten t yet incorrect answers on 77 questions (38.5%), selecting the same wrong option across all five prompt st yles with a consistency score of 1.0. The danger of reliable incorrectness is b oth psyc hological and tec hnical. Consider a primary care ph ysician using an AI assistan t to supp ort diagnostic reasoning. If the mo del returns the same answer regardless of ho w a question is phrased, this rep etition creates an 24 illusion of reliability . A clinician might reason, “it k eeps suggesting pulmonary embolism; it must b e confiden t.” That apparent stability can feel reassuring. How ever, if the correct diagnosis is pneumonia, the mo del’s consistency activ ely reinforces a false conclusion. Over time, clinicians ma y develop misplaced trust in systems that app ear stable and decisive without recognising that the stabilit y reflects systematic error rather than clinical knowledge. In practice, this could translate into rep eated misdiagnoses, inappropriate inv estigations, or dela y ed treatmen t, not b ecause the mo del b eha ves randomly , but b ecause it is confidently and predictably incorrect. This finding aligns with Kim et al. [Kim et al., 2025], who demonstrate that foundation mo dels frequen tly pro duce hallucinations with high apparent confidence and that clinicians consider suc h outputs particularly dangerous b ecause they are difficult to detect. The present results extend this concern to the domain of prompt sensitivit y . A mo del that pro duces consisten t but incorrect answers across v aried prompt form ulations comp ounds this risk b y app earing robust to rephrasing. These observ ations underscore that accuracy and consistency m ust b e ev aluated join tly in an y clinical AI assessment framework. Neither metric alone is sufficient to characterize the safety profile of a mo del in tended for healthcare deploymen t. The arc hitectural c haracteristics of Gemma 2 offer a plausible mechanistic accoun t of this pattern. The 2B Gemma 2 mo del is trained via kno wledge distillation from a substantially larger teacher mo del, inheriting the teacher’s resp onse tendencies rather than learning inde- p enden tly from ground-truth lab els. If the teacher mo del has developed systematic biases in clinical question answering — for instance, preferring certain option p ositions or applying heuristics that generalise p oorly to medical reasoning — these biases may b e faithfully repli- cated in the distilled student mo del, pro ducing high cross-prompt consistency that reflects the teac her’s error patterns rather than gen uine clinical knowledge. This distillation-induced miscalibration represen ts a distinct arc hitectural risk factor for clinical AI deploymen t that accuracy-only ev aluation frameworks w ould not detect. 25 5.2 Rolepla y Prompts Consisten tly Underp erform Across all fiv e mo dels and three datasets, roleplay-st yle prompts consisten tly pro duced lo w er accuracy than direct or original question formats. The most pronounced decline was observed in Phi-3 Mini on MedQA, where rolepla y accuracy dropp ed 21.5 p ercentage p oints b elow the b est-performing st yle. Critically , this pattern w as consisten t across all mo del families tested, suggesting a systematic rather than mo del-sp ecific phenomenon. Rolepla y prompts app ear to introduce a form of task in terference that is particularly detrimen tal for small language mo dels. When a prompt b egins with p ersona framing suc h as “Y ou are a senior physician taking a licensing examination,” the mo del m ust sim ultane- ously interpret and simulate a clinical identit y while reasoning through a structured medical question. F or smaller mo dels with limited representational capacity , this dual requiremen t ma y dilute attention from the core reasoning task. F urthermore, p ersona-based prompts ma y activ ate patterns learned from conv ersational or narrativ e training data rather than the structured exam-style reasoning required for clinical QA b enc hmarks, effectiv ely shifting the task from question answering to p erformance-oriented text generation. This finding has direct practical implications. Prompt engineering guidelines for clinical AI systems often recommend p ersona framing to make outputs sound more authoritativ e or clinically appropriate [White et al., 2023]. These results suggest that, for small op en- source mo dels, suc h framing may paradoxically reduce factual reliabilit y . Dev elop ers building clinical decision support to ols on small language mo dels should fa vor minimal, direct prompt form ulations o v er p ersona-based instructions. This observ ation also extends findings from Ngweta et al. [Ngw eta et al., 2024], who demonstrated that prompt format changes cause measurable p erformance v ariation in gen- eral NLP tasks. The present results sho w that, in clinical settings, one sp ecific prompt format, roleplay , is systematically and substantially more harmful than others, representing a concrete and actionable finding for healthcare AI deplo yment. 26 This phenomenon is lik ely amplified by the prompt template con ven tions enforced during instruction fine-tuning. Eac h mo del ev aluated uses a distinct chat template: Phi-3 Mini em- plo ys <|user|>...<|end|> delimiters, Llama 3.2 uses <|start header id|>...<|eot id|> mark ers, and Mistral 7B requires [INST]...[/INST] framing. Roleplay prompts, which b e- gin with p ersona instructions suc h as “Y ou are a senior ph ysician,” may partially misalign with the exp ected input structure of these templates, shifting the mo del’s pro cessing tow ard narrativ e or con v ersational generation rather than constrained structured reasoning. This suggests that rolepla y sensitivit y reflects not merely task framing but an in teraction b etw een prompt st yle and the learned template exp ectations embedded during instruction tuning — an architectural rather than purely b ehavioural phenomenon. 5.3 Implications for Lo w-Resource Healthcare Deplo ymen t A primary motiv ation for this study was the practical challenge of deploying AI in resource- constrained healthcare environmen ts. Man y rural clinics, communit y hospitals, and health systems in low-income settings lac k access to GPU infrastructure, reliable high-sp eed inter- net, or cloud-based AI services. In these con texts, lo cally deploy able op en-source mo dels in the 2B–7B parameter range represent a more realistic and equitable alternative to large proprietary systems. The exp erimen tal design inten tionally reflected these constrain ts: all mo dels w ere ev aluated on consumer CPU hardw are without domain-sp ecific fine-tuning, sim ulating realistic deploymen t conditions rather than idealized research en vironments. These findings provide concrete guidance for mo del selection in such settings. Although Gemma 2 demonstrated the highest consistency scores, its substantially low er accuracy sug- gests that it ma y systematically mislead clinicians, particularly in lo w-o v ersight environ- men ts where AI outputs ma y not b e routinely verified. Mistral 7B, despite b eing the largest mo del ev aluated, did not clearly outp erform smaller alternatives and exhibited unexp ected instruction-follo wing failures, suggesting that larger parameter counts do not automatically justify greater hardware demands. 27 Llama 3.2 (3B) emerged as the most balanced candidate under the ev aluation criteria used in this study , ac hieving the highest o verall accuracy (49.0–65.0%), mo derate consistency , and among the lo west instruction-following failure rates. F or low-resource healthcare deploymen t scenarios where clinician ov ersight ma y b e limited, a model offering strong accuracy and reliable instruction adherence is preferable to one that maximizes consistency at the exp ense of correctness. More broadly , these results suggest that deplo yment decisions for clinical AI systems should be guided b y join t ev aluation of accuracy , consistency , and instruction compliance rather than an y single metric. In settings where errors carry direct patien t safet y impli- cations, the cost of systematic incorrectness, ev en when deliv ered consisten tly , out weighs the b enefit of apparent stability . This study pro vides a practical ev aluation framework for lo w-resource healthcare AI deploymen t that can b e reproduced without sp ecialized infras- tructure, making it accessible to researchers and practitioners in the settings it is in tended to serve. 5.4 Domain Kno wledge V ersus Instruction F ollo wing The inclusion of Meditron-7B reveals an imp ortant distinction b etw een tw o capabilities re- quired for clinical AI deploymen t: domain knowledge and instruction adherence. Meditron- 7B w as pretrained on a curated medical corpus comprising PubMed articles and clinical guidelines [Chen et al., 2023], enco ding substan tial medical domain kno wledge. How ever, without instruction tuning, it failed to pro duce structured resp onses in the required format across all three datasets, with UNKNOWN rates reac hing 99.0% on PubMedQA. This finding suggests that domain kno wledge and task usabilit y are orthogonal capabili- ties. A mo del can enco de ric h medical knowledge through con tin ued pretraining yet remain clinically un usable for structured question answering if it lac ks the ability to follo w task- sp ecific instructions. F or practitioners deploying AI in clinical settings, this distinction has direct practical implications. Selecting a mo del based solely on its training data, without 28 v erifying instruction-following capabilit y , ma y result in a system that is knowledgeable but functionally unusable in structured workflo ws. These observ ations also motiv ate a clear direction for future work: instruction-tuning Meditron or similar domain-pretrained mo dels on structured clinical QA datasets and ev al- uating whether the com bination of domain knowledge and instruction following pro duces mo dels that are b oth more accurate and more consistent than general instruction-tuned alternativ es. F rom an architectural standp oin t, this finding reflects a fundamental distinction b etw een t w o training ob jectives that are often conflated in clinical AI discourse. Con tinued pretrain- ing on medical corp ora, as applied to Meditron-7B, optimises the mo del’s internal represen- tations of medical kno wledge but does not instil the structured output behaviour required for task-constrained deplo yment. Instruction tuning, by contrast, explicitly trains the mo del to pro duce constrained resp onses in sp ecific formats in resp onse to sp ecific prompt structures. These are orthogonal capabilities: a mo del can enco de rich biomedical knowledge through pretraining y et remain clinically un usable b ecause it lac ks the architectural conditioning to translate that kno wledge in to a structured, deploy able output. F or practitioners selecting mo dels for lo w-resource clinical deplo yment, this distinction implies that medical domain pretraining alone is an insufficient selection criterion; instruction-following capabilit y must b e v erified indep enden tly . 5.5 Limitations Sev eral limitations should b e considered when interpreting these findings. These limitations define the scop e of the curren t study and collectiv ely motiv ate the future directions describ ed in Section 5.6. First, 200 questions p er dataset were sampled, whic h provides a computationally feasi- ble and repro ducible ev aluation but ma y not fully capture the diversit y of each b enc hmark. Second, the three datasets used, MedQA, MedMCQA, and PubMedQA, fo cus primarily on 29 structured examination-style and research-based questions and may not reflect the complex- it y of real-world clinical dialogue or unstructured patient interactions. Third, human clinical ev aluation w as not conducted to assess whether consisten t but incorrect mo del outputs would meaningfully influence ph ysician decision-making in practice. Suc h ev aluation would strengthen the clinical v alidity of these findings but was b eyond the scop e of this study . F ourth, all mo dels were ev aluated without domain-sp ecific fine-tuning, whic h may underestimate the p erformance ac hiev able through medical adaptation techniques suc h as instruction tuning or retriev al-augmen ted generation [Lewis et al., 2020]. Fifth, the ev aluation w as restricted to m ultiple-c hoice and yes/no/ma yb e answ er formats, whereas real clinical en vironmen ts frequen tly in v olve op en-ended reasoning, differen tial di- agnosis, and con textual patien t data. Sixth, hardware constraints limited the ev aluation to mo dels in the 2B–7B parameter range running on consumer CPU hardw are, precluding direct comparison with larger proprietary systems such as GPT-4 or Claude. Seven th, while the fiv e prompt styles were designed to simulate realistic v ariation in clinical query formu- lation, they do not exhaust the full range of phrasings a clinician migh t use in practice. Finally , Meditron-7B was ev aluated in its base pretraining form without instruction tuning, whic h limits direct comparison with instruction-tuned mo dels and ma y underrepresent the p oten tial of domain-adapted mo dels when prop erly instruction-tuned for structured clinical tasks. T ogether, these limitations define the scop e of this study as an initial systematic analysis of prompt sensitivit y under constrained deploymen t conditions. The ev aluation framework in tro duced here is designed to b e repro ducible and extensible, supp orting future clinical v alidation studies without requiring sp ecialised infrastructure. 5.6 F uture W ork Sev eral directions emerge naturally from this study . First, future researc h should ev aluate whether domain-sp ecific fine-tuning of small mo dels on medical corp ora reduces prompt 30 sensitivit y and improv es consistency . If fine-tuned models demonstrate stronger stabilit y under prompt v ariation, this would suggest that training data alignmen t, rather than mo del arc hitecture, is the primary driver of inconsistency . In particular, instruction-tuning Meditron-7B or similar domain-pretrained mo dels on structured clinical QA datasets represents a direct next step. This would test whether com bining domain kno wledge with instruction-following capability pro duces mo dels that are b oth more accurate and more consistent than the general instruction-tuned alternativ es ev aluated in this study . Second, in tegrating retriev al-augmented generation (RAG) pip elines with small clini- cal mo dels represents a promising direction. RA G-augmented systems ground resp onses in retriev ed evidence, whic h may reduce b oth factual hallucinations and prompt-induced answ er v ariation. Ev aluating whether external knowledge retriev al mitigates the consis- tency–accuracy tradeoff observed in this study would b e a natural extension [Lewis et al., 2020]. Third, ev aluating larger op en-source and proprietary mo dels, when hardw are resources p ermit, w ould clarify whether the indep endence b et ween consistency and accuracy observ ed here p ersists at greater parameter scales or whether it is sp ecific to sub-7B mo dels. Bey ond tec hnical extensions, human-cen tered v alidation is essen tial. A con trolled clinical study in volving practicing physicians could assess how consistent but incorrect mo del outputs influence clinical reasoning, trust calibration, and decision-making in realistic workflo ws. Suc h a study would strengthen the ecological v alidity of the consistency metric introduced here. T ranslationally , these findings supp ort the developmen t of a ligh tw eight clinical decision supp ort prototype for general practitioners in lo w-resource settings, built around the mo del demonstrating the strongest balance of accuracy and instruction adherence, with prompt engineering guardrails informed b y the sensitivit y analysis. Extending this ev aluation frame- w ork to m ultilingual datasets and non-English clinical b enchmarks is also critical, as man y 31 lo w-resource healthcare environmen ts op erate outside English-dominan t settings. T ogether, these directions would adv ance this work from con trolled b enc hmarking tow ard s afe, deploy- able clinical AI systems grounded in b oth technical rigor and real-world constraints. 6 Conclusion This study systematically ev aluates prompt sensitivity in five open-source language mo d- els (2B–7B parameters), including four general instruction-tuned mo dels and one domain- adapted pretraining mo del, across three clinical question answering datasets using fiv e con- trolled prompt style v ariations, yielding 3,000 total ev aluation instances. F our principal findings emerge from this analysis. First, consistency and accuracy are in- dep enden t metrics: mo dels that achiev e high consistency are not necessarily more accurate, with Gemma 2 demonstrating the most pronounced case of reliable incorrectness, ac hiev- ing the highest consistency scores while recording the lo west accuracy across all datasets. Second, roleplay-st yle prompts consisten tly reduce accuracy across all mo dels and datasets, suggesting that p ersona-based framing introduces systematic instability in clinical reasoning tasks and should b e a v oided in healthcare AI prompt design. Third, instruction-following failures v ary substantially across mo dels and are not determined b y parameter count alone, indicating that mo del size is an insufficient proxy for deploymen t reliability under hardware constrain ts. F ourth, Meditron-7B, a domain-adapted mo del without instruction tuning, ex- hibited near-complete failure on structured clinical QA tasks despite enco ding substantial medical domain kno wledge, demonstrating that domain knowledge and instruction-follo wing capabilit y are orthogonal requirements for clinical AI deploymen t. T ak en together, these results demonstrate that consistency alone cannot serve as a proxy for clinical reliabilit y . Mo dels that app ear stable under prompt v ariation ma y still p ose significan t patient safety risks if their answers are systematically incorrect. Safe deploymen t of AI in clinical settings, particularly in lo w-resource en vironments where human ov ersight 32 ma y b e limited, requires join t ev aluation of accuracy , consistency , and instruction adherence. More broadly , this work highlights the need for the research communit y to mov e b ey ond accuracy-only ev aluation framew orks for clinical AI and adopt m ultidimensional assessment approac hes that reflect the reliability requiremen ts of real-w orld healthcare deplo ymen t. The ev aluation framework, datasets, and co de in tro duced in this study are publicly av ailable at [Hariprasad, 2026] to supp ort repro ducibility and future research in this direction. Ac kno wledgmen ts This study receiv ed no funding. All exp eriments were conducted on p ersonal hardw are by an indep endent researc her. The author thanks the op en-source communities b ehind Ollama, HuggingF ace Datasets, and the mo del developers whose publicly released tec hnical rep orts informed the architectural analysis in this work. Conflicts of In terest The author declares no conflicts of interest. No funding was received for this study . Data Av ailabilit y The ev aluation framew ork, scored datasets, and all co de used in this study are publicly av ail- able at https://github.com/shravani- 01/clinical- llm- eval [Hariprasad, 2026]. The three clinical b enc hmarks used (MedQA, MedMCQA, PubMedQA) are publicly a v ailable via HuggingF ace Datasets. 33 Ethics Statemen t This study used publicly av ailable, de-identified b enchmark datasets (MedQA, MedMCQA, PubMedQA) and did not inv olve h uman sub jects, patien t data, or any form of primary data collection. No ethics b oard review w as required. References Marah Ab din et al. Phi-3 T ec hnical Rep ort: A Highly Capable Language Mo del Lo cally on Y our Phone. arXiv pr eprint arXiv:2404.14219 , 2024. Sehej Bedi et al. A Systematic Review of Large Language Mo del Ev aluations in Clinical Medicine. BMC Me dic al Informatics and De cision Making , 2025. Zeming Chen et al. MEDITR ON-70B: Scaling Medical Pretraining for Large Language Mo dels. arXiv pr eprint arXiv:2311.16079 , 2023. Sehej Garg et al. A Surv ey of Small Language Mo dels in Healthcare. arXiv pr eprint , 2024. Gemma T eam et al. Gemma 2: Impro ving Op en Language Mo dels at a Practical Size. arXiv pr eprint arXiv:2408.00118 , 2024. Aaron Grattafiori et al. The Llama 3 Herd of Models. arXiv pr eprint arXiv:2407.21783 , 2024. Shra v ani Hariprasad. Clinical LLM consistency study – co de and data. https://github. com/shravani- 01/clinical- llm- eval , 2026. Alb ert Q Jiang et al. Mistral 7B. arXiv pr eprint arXiv:2310.06825 , 2023. Di Jin, Eileen P an, Nassim Oufattole, W ei-Hung W eng, Han yi F ang, and Peter Szolo vits. What Disease Do es This Patien t Hav e? A Large-Scale Op en Domain Question Answering Dataset from Medical Exams. Applie d Scienc es , 2021. 34 Qiao Jin, Bh uw an Dhingra, Zhiyong Liu, William Cohen, and Xinghua Lu. PubMedQA: A Dataset for Biomedical Research Question Answering. In EMNLP , 2019. Y ubin Kim et al. Medical Hallucinations in F oundation Models and Their Impact on Health- care. arXiv pr eprint , 2025. V eysel Kocaman et al. Clinical Large Language Model Ev aluation b y Exp ert Review (CLEVER): F ramework Dev elopment and V alidation. JMIR AI , 2025. P atric k Lewis et al. Retriev al-Augmen ted Generation for Kno wledge-In tensive NLP T asks. NeurIPS , 2020. Lilian Ngweta et al. T o w ards LLMs Robustness to Changes in Prompt F ormat Styles. arXiv pr eprint , 2024. Ankit Pal, Logesh Kumar Umapathi, and Malaik annan Sank arasubbu. MedMCQA: A Large- Scale Multi-Sub ject Multi-Choice Dataset for Medical Exam Comprehension. In Confer- enc e on He alth, Infer enc e, and L e arning , 2022. Jules White et al. A Prompt Pattern Catalog to Enhance Prompt Engineering with Chat- GPT. arXiv pr eprint arXiv:2302.11382 , 2023. A Represen tativ e Prompt V ariation Example This app endix presen ts a single represen tativ e example illustrating how the five prompt st yles w ere applied to an iden tical clinical question, along with the ra w mo del resp onses and extracted answers from Phi-3 Mini. This example was selected b ecause it demonstrates prompt sensitivit y in practice: the mo del pro duces the correct answer under three prompt st yles (F ormal, Simplified, Direct) but selects an incorrect answ er under b oth the Original and Roleplay styles, despite identical question con ten t across all five v ariations. 35 Question A health y 23-year-old male is undergoing an exercise stress test as part of his physiology class. If blo o d w ere to be sampled at differen t lo cations before and after the stress test, whic h area of the b o dy would con tain the low est oxygen con tent at b oth time p oints? Options: A: Inferior v ena ca v a B: Coronary sin us (c orr e ct answer) C: Pulmonary artery D: Pulmonary v ein Prompt T exts and Mo del Resp onses (Phi-3 Mini) T able 4: Prompt texts, raw mo del output, and extracted answ ers for Phi-3 Mini on a rep- resen tativ e MedQA question. The correct answer is B (Coronary sinus). The Rolepla y style pro duces an incorrect answer (A) despite iden tical question conten t across all five v ariations. St yle Prompt T ext (abbreviated) Ra w Resp onse Extracted Correct? Original “A nswer the fol lowing me dic al question by cho osing the c orr e ct option. . . . A nswer with only the option letter (A, B, C, or D).” Option A: Inferior vena c... A No F ormal “Y ou ar e a me dic al exp ert. Base d on your clinic al know le dge, sele ct the most appr opri- ate answer . . . R esp ond with only the letter of the c orr e ct choic e (A, B, C, or D).” B: Coronary sinus B Y es Simplified “R e ad this me dic al question c ar eful ly and pick the b est answer. . . . Which letter is c orr e ct? R eply with just A, B, C, or D.” B: Coronary sinus The... B Y es Rolepla y “Y ou ar e a physician taking a me dic al lic ens- ing exam. Answer this question as you would on the exam. . . . Y our answer (A, B, C, or D):” The correct answer is A: Inferior v... A No Direct “Me dic al question: . . . What is the c orr e ct op- tion? State only the letter.” B B Y es 36 The ma jority answer across five styles is B (3 of 5 resp onses), yielding a consistency score of 3 / 5 = 0 . 60 and a correct ma jorit y answ er. How ever, the Rolepla y prompt pro duces answ er A in both instances it app ears, illustrating ho w persona-based framing systematically shifts the mo del to ward an incorrect resp onse. The Original prompt also returns A, despite minimal structural difference from the Direct prompt — a further illustration of prompt sensitivit y ev en b et ween sup erficially similar formulations. The ra w resp onses also reflect a secondary finding: the 10-tok en output limit causes truncation ( Option A: Inferior vena c... ), con tributing to the UNKNO WN rate observ ed in cases where truncation prev ents a v alid letter from b eing extracted. F ull prompt texts for all fiv e styles across all three datasets are av ailable in the pro ject rep ository [Hariprasad, 2026]. Example 2: Reliable Incorrectness (Gemma 2, Consistency = 1.0, Accuracy = 0) This example illustrates the r eliable inc orr e ctness failure mo de describ ed in Section 5.1. Gemma 2 selects the same incorrect answ er (D) across all fiv e prompt styles, yielding a p erfect consistency score of 1.0 while being en tirely wrong. The correct answ er is B (Isosorbide dinitrate), consistent with the presentation of Prinzmetal angina, which is treated with nitrates and calcium channel blo c kers rather than beta-blo c kers such as propranolol (D). This case demonstrates that a model app earing maximally stable under prompt v ariation can simultaneously b e maximally unreliable from a clinical standp oint. Question A 38-year-old woman presents to her physician’s clinic for recurrent episo des of chest pain that w ak es her from her sleep. While usually occurring late at nigh t, she has also had similar pains during the da y at random times, most recen tly while sitting at her desk in her office 37 and at other times while doing the dishes at home. The pain lasts 10–15 minutes and resolv es sp on taneously . She is unable to identify any common preceding even t to pain onset. The remainder of her history is unremark able and she takes no regular medications. Examination rev eals: pulse 70/min, respirations 16/min, and blo od pressure 120/70 mmHg. A ph ysical examination is unremark able. Whic h of the following would b e effectiv e in reducing her symptoms? Options: A: Aspirin B: Isosorbide dinitrate (c orr e ct answer) C: Heparin D: Propranolol 38 Mo del Resp onses (Gemma 2) T able 5: Gemma 2 resp onses across all five prompt st yles for a represen tative MedQA question demonstrating reliable incorrectness. The correct answer is B (Isosorbide dinitrate). Gemma 2 selects D (Propranolol) under every prompt st yle, yielding a consistency score of 1.0 and 0% accuracy on this question. St yle Prompt T ext (abbreviated) Ra w Resp onse Extracted Correct? Original “A nswer the fol lowing me dic al question by cho osing the c orr e ct option. . . . Answer with only the option letter (A, B, C, or D).” D D No F ormal “Y ou ar e a me dic al exp ert. Base d on your clinic al know le dge, sele ct the most appr opriate answer . . . R esp ond with only the letter of the c orr e ct choic e (A, B, C, or D).” D D No Simplified “R e ad this me dic al question c ar eful ly and pick the b est answer. . . . Which letter is c orr e ct? R eply with just A, B, C, or D.” D D No Rolepla y “Y ou are a physician taking a me dic al lic ensing exam. Answer this question as you would on the exam. . . . Y our answer (A, B, C, or D):” The correct answer is **(D) Propran... D No Direct “Me dic al question: . . . What is the c orr e ct option? State only the letter.” D D No Consistency score = 5 / 5 = 1 . 0; ma jorit y answ er = D (incorrect). This pattern — p erfect stabilit y , zero correctness — exemplifies why consistency alone is insufficien t as a clinical safet y metric. A clinician or automated system relying on answ er stabilit y as a proxy for confidence w ould receive maximally misleading signals from this model on this question. Gemma 2 pro duced 77 suc h cases on MedQA alone (out of 200 questions), representing 38.5% of its ev aluation set. F ull prompt texts for all fiv e styles across all three datasets are av ailable in the pro ject rep ository [Hariprasad, 2026]. 39
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment