소형 오픈소스 LLM의 임상 질문 응답 안정성: 저자원 의료 현장의 실험적 고찰
본 연구는 5개의 소형 오픈소스 언어모델(Gemma 2 2B, Phi‑3 Mini 3.8B, Llama 3.2 3B, Mistral 7B, Meditron‑7B)을 세 가지 임상 QA 데이터셋(MedQA, MedMCQA, PubMedQA)과 다섯 가지 프롬프트 변형(원본, 공식, 단순, 역할극, 직접)으로 평가하였다. 일관성 점수와 정확도는 대부분 독립적이며, Gemma 2는 가장 높은 일관성(0.845‑0.888)·낮은 정확도(33‑43 %)…
저자: Shravani Hariprasad
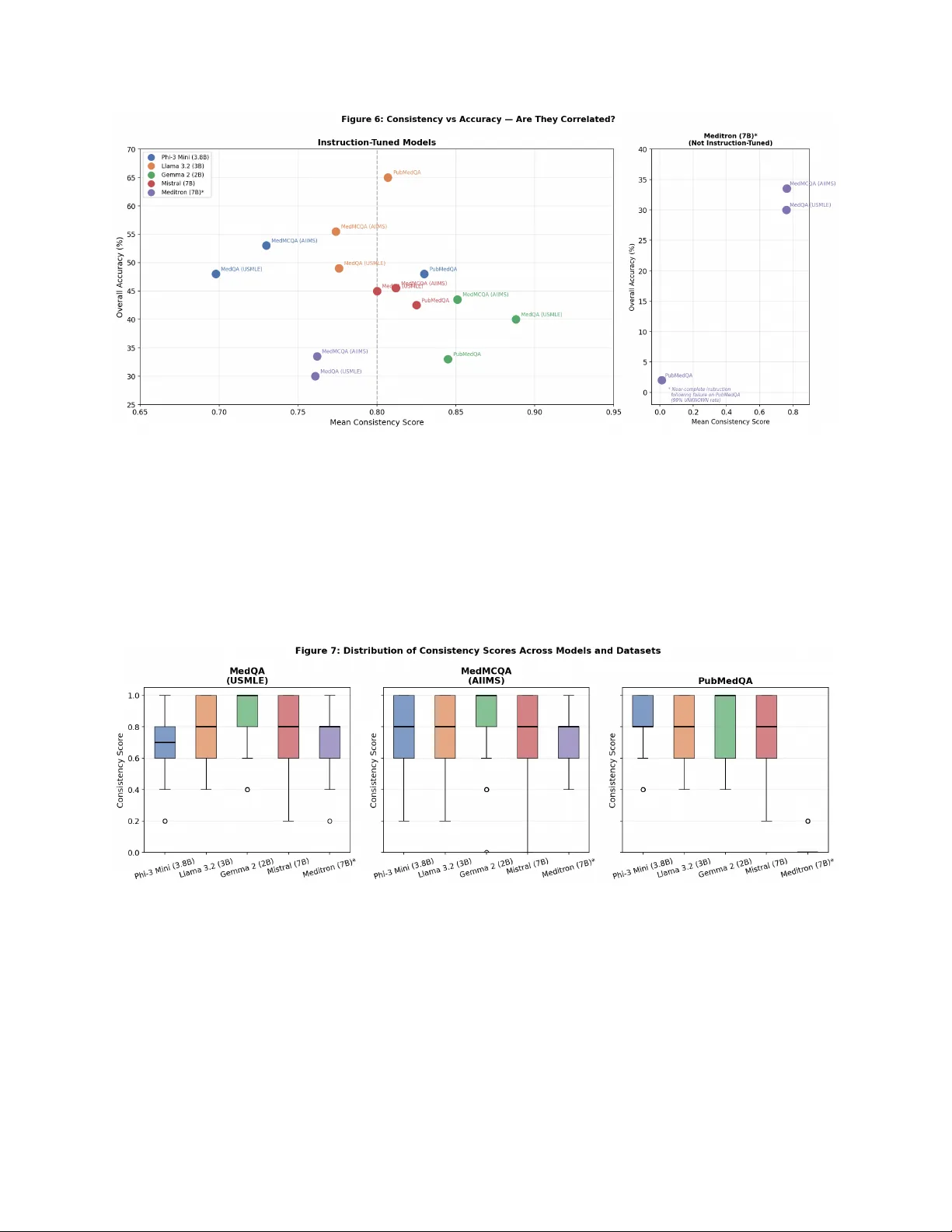
본 논문은 저자원 의료 환경에서 클라우드·GPU 의존도가 낮은 소형 오픈소스 대형언어모델(LLM)의 신뢰성을 평가하기 위해 설계·실험·분석 과정을 체계적으로 제시한다. 연구 목적은 세 가지 질문(RQ1‑RQ3)에 답하는 것으로, (1) 동일한 임상 질문을 다양한 표현으로 바꿨을 때 모델이 일관된 답을 내는가, (2) 일관성 점수가 정확도와 상관관계가 있는가, (3) 프롬프트 스타일이 모델의 신뢰도에 미치는 영향은 무엇인가이다.
**데이터셋 및 실험 설계**
- MedQA, MedMCQA, PubMedQA 세 가지 공개 임상 QA 벤치마크를 각각 200문제씩 무작위 추출(시드 42)하여 총 600문제, 5가지 프롬프트 변형(원본, 공식, 단순, 역할극, 직접)으로 15,000번의 추론을 수행하였다.
- 모델은 Gemma 2 2B, Phi‑3 Mini 3.8B, Llama 3.2 3B, Mistral 7B, Meditron‑7B(도메인 사전학습만) 총 5종이며, 모두 오픈소스이며 CPU‑only 환경(Ollama)에서 실행되었다. 파인튜닝 없이 원본 가중치를 그대로 사용해 실제 배포 상황을 모사하였다.
**평가 지표**
- **일관성 점수**: 동일 질문에 대해 5가지 프롬프트 중 동일한 답을 선택한 비율.
- **정확도**: 정답과 일치하는 비율(전체 정확도, 프롬프트 별 정확도).
- **Instruction‑following 실패율(UNKNOWN)**: 모델이 “UNKNOWN”, “I don’t know” 등으로 응답해 정답을 제공하지 못한 비율.
**핵심 결과**
1. **일관성 vs 정확도 독립성**
- Gemma 2는 0.845‑0.888의 높은 일관성을 보였지만 정확도는 33‑43 %에 불과했다. 반면 Llama 3.2는 0.774‑0.807의 중간 일관성에 49‑65 %의 최고 정확도를 기록했다. 두 지표는 상관관계가 낮아 ‘신뢰성 높은 틀린 답변’이 실제 위험 요인임을 강조한다.
2. **프롬프트 스타일 영향**
- 역할극 프롬프트는 모든 모델에서 정확도를 크게 감소시켰다. 특히 Phi‑3 Mini는 MedQA에서 21.5 %p 포인트 하락했으며, 이는 모델이 특정 대화 템플릿에 과도하게 의존함을 의미한다. 공식·단순·직접 프롬프트는 비교적 안정적인 성능을 유지했다.
3. **Instruction‑following 실패**
- Meditron‑7B는 PubMedQA에서 99 % UNKNOWN을 기록, 도메인 사전학습만으로는 구조화된 질문‑응답 흐름을 따르기 어렵다는 점을 입증한다. Phi‑3 Mini는 MedQA에서 10.5 % UNKNOWN, Mistral은 약간 높은 실패율을 보였다. Llama 3.2와 Gemma 2는 전반적으로 낮은 UNKNOWN 비율을 유지했다.
4. **모델 아키텍처·학습 방식 차이**
- 지식 증류 기반 Gemma 2는 일관적인 응답 패턴을 재현하지만 정확도는 낮다. 다중 라운드 정렬과 RLHF·DPO가 결합된 Llama 3.2는 일관성과 정확도 사이의 균형을 가장 잘 맞췄다. Phi‑3 Mini는 엄격한 채팅 템플릿에 민감해 프롬프트 변형에 취약했다. Mistral은 제한된 공개 데이터로 학습돼 UNKNOWN 비율이 다소 높았다.
5. **실제 배포 가능성**
- 모든 실험이 CPU‑only 환경에서 수행됐으며, 파인튜닝 없이도 15,000번의 추론을 성공적으로 마쳤다. 이는 저자원 의료기관에서도 동일한 파이프라인을 그대로 적용할 수 있음을 시사한다.
**논의 및 한계**
- 일관성 높은 모델이 반드시 정확한 것은 아니므로, 임상 AI 시스템 설계 시 일관성·정확도·지시 수행 능력을 동시에 평가해야 한다.
- 역할극 프롬프트는 실제 의료 현장에서 ‘전문가 역할’ 시뮬레이션에 사용될 수 있지만, 현재 모델들은 이 스타일에 취약하므로 신중히 적용해야 한다.
- 데이터셋 규모(각 200문제)와 다중 선택형 질문에 국한된 평가가 일반화에 제한을 둔다. 향후 실제 전자건강기록(EHR) 기반 질문·답변, 장문 요약 등 다양한 태스크로 확장할 필요가 있다.
- Meditron‑7B와 같은 도메인 사전학습 모델은 의료 지식 보유는 충분하지만, 지시 정렬이 없으면 실용적인 임상 지원에 한계가 있음을 보여준다.
**결론**
- 일관성·정확도·Instruction‑following을 모두 고려한 다차원 평가 프레임워크가 필요하다.
- Llama 3.2가 가장 높은 정확도와 적절한 일관성을 동시에 달성해 저자원 의료 현장에 가장 적합한 후보임을 제시한다.
- 향후 연구는 더 큰 임상 데이터, 실제 의료 워크플로와의 통합, 그리고 프롬프트 강건성 향상을 위한 사전학습·정렬 기법 개선을 목표로 해야 한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기