Exploiting Completeness Perception with Diffusion Transformer for Unified 3D MRI Synthesis
Missing data problems, such as missing modalities in multi-modal brain MRI and missing slices in cardiac MRI, pose significant challenges in clinical practice. Existing methods rely on external guidance to supply detailed missing state for instructin…
Authors: Junkai Liu, Nay Aung, Theodoros N. Arvanitis
Exploiting Completeness P er ception with Diffusion T ransf ormer f or Unified 3D MRI Synthesis Junkai Liu 1 , Nay Aung 2 , 3 , Theodoros N. Arv anitis 1 , Joao A. C. Lima 4 , Stef fen E. Petersen 2 , 3 , Daniel C. Alexander 5 , Le Zhang 1 , 2 1 School of Engineering, Uni versity of Birmingham, UK 2 W illiam Harv e y Research Institute, Queen Mary Uni versity London, UK 3 Barts Heart Centre, St Bartholome w’ s Hospital, Barts Health NHS T rust, UK 4 Di vision of Cardiology , Johns Hopkins University School of Medicine, US 5 Department of Computer Science, Uni versity Colle ge London, UK jxl1920@student.bham.ac.uk; l.zhang.16@bham.ac.uk Abstract Missing data pr oblems, such as missing modalities in multi- modal brain MRI and missing slices in car diac MRI, pose significant challenges in clinical practice. Existing meth- ods r ely on e xternal guidance to supply detailed missing state for instructing generative models to synthesize missing MRIs. However , manual indicators ar e not always avail- able or r eliable in r eal-world scenarios due to the unpr e- dictable natur e of clinical en vironments. Mor eover , these explicit masks ar e not informative enough to pr ovide guid- ance for impr oving semantic consistency . In this work, we ar gue that generative models should infer and r ecognize missing states in a self-perceptive manner , enabling them to better captur e subtle anatomical and pathological varia- tions. T owards this goal, we pr opose CoP eDiT , a general- purpose latent diffusion model equipped with complete- ness perception for unified synthesis of 3D MRIs. Specif- ically , we incorporate dedicated pr etext tasks into our to- kenizer , CoP eV AE, empowering it to learn completeness- awar e discriminative pr ompts, and design MDiT3D, a spe- cialized diffusion tr ansformer ar chitectur e for 3D MRI syn- thesis, that ef fectively uses the learned pr ompts as guid- ance to enhance semantic consistency in 3D space. Com- pr ehensive evaluations on thr ee lar ge-scale MRI datasets demonstrate that CoP eDiT significantly outperforms state- of-the-art methods, achie ving superior r obustness, g eneral- izability , and flexibility . The code is available at https: //github.com/JK- Liu7/CoPeDiT . 1. Introduction Magnetic resonance imaging (MRI) is widely used in clin- ical medicine due to its non-in v asi ve nature and ability to visualize detailed tissue properties [ 8 ]. For instance, multi- modal brain MRIs provide complementary information re- garding brain anatomy and pathology [ 27 ], while volumet- ric cardiac MRIs rev eal detailed cardiac structure and tis- sue characteristics [ 7 ]. Howe ver , brain and cardiac MRIs often suffer from missing data in real-world clinical set- tings [ 50 ]. For brain MRIs, certain modalities may be un- av ailable, while for cardiac MRIs, some slices may be miss- ing, which are commonly caused by limited scanning time, image corruption, and variations in acquisition protocols [ 33 ]. T o address this, generative models have been dev eloped to infer missing data from observed inputs [ 11 , 19 ]. Exist- ing paradigms rely on auxiliary embeddings, e.g., binary mask codes, as prior knowledge to encode missing pat- terns (e.g., severity , type, and position) [ 6 , 14 , 21 , 24 , 29 ]. Nonetheless, this approach has sev eral inherent limitations that hinder its practical applicability . First, in real-world deployments, input images may originate from different hospitals, scanners, or time points. As missing patterns are intrinsically unpredictable, providing manually defined masks in advance is impractical [ 41 , 48 ]. Second, this ov er-reliance on predefined masks causes generati ve mod- els to be unaw are of the missing state and unable to dis- tinguish between dif ferent modalities or spatial character- istics, thereby reducing robustness to variable and unseen incomplete patterns [ 20 , 22 , 51 ]. Models conditioned on fixed mask representations often suffer from limited gen- eralizability , exhibiting noticeable drop in synthesis quality when encountering unfamiliar missing sites [ 2 , 13 , 32 ]. Fi- CoP e V AE w/ o Pr e t e xt T ask s T1 T1c e T2 FLA I R (a) Ho w m an y MR Is ar e mis si ng? Gener a tiv e Mod el Which MR Is ar e mis si ng? What MR Is ar e mis si ng? E xis ting Str a t egy Our Str a t egy 0 0 1 1 Ext ernal Gu i dan c e P r omp ts T1 T1c e T2 FLA I R 55 . 3% 54 . 2% 43 . 8% 45 . 4% w/ Pr omp t T ok en s T1 T1c e T2 FLA I R 42 . 7% 41 . 6% 39 . 5% 38 . 4% w/ Mask Code s T1 T1c e T2 FLA I R MMT G A E M 2 D N FID MMT G A E M 2 D N SSIM MMT G A E M 2 D N w / o M a s k C o d e w / M a s k C o d e w / P r o m p t s PSNR (b) (d) (c ) Glo b al U n d e r s t a n d i n g A n a t omi c al Stru ctu r es L e s i o n P a t t e r n s Figure 1. The motiv ation of CoPeDiT . (a) Comparison of com- pleteness perception between CoPeDiT and prior methods. (b) Prompt tokens of fer more ef fectiv e guidance than binary mask codes. (c) CoPeV AE enables more discriminativ e latent repre- sentations. (d) Prompt tokens yield more semantically consistent attention maps in MDiT3D blocks, highlighting stronger interac- tions between similar modalities (e.g., T1-T1ce, T2-FLAIR). nally , binary mask codes lack semantic richness and adapt- ability , leading to a rigid guidance that weakens spatial alignment and semantic coherence in the synthesized out- put [ 17 , 37 , 44 ]. Intuitiv ely , generative models should be capable of in- ferring and detecting the incomplete state spontaneously , rather than relying on externally manual guidance [ 12 , 17 ]. Motiv ated by this, we pose a central question: ‘Can we empower the model with the ability to per ceive missing states on its own?’ In light of this, we exploit a long ne- glected and underexplored property of generativ e models in medical imaging, i.e., ‘ completeness perception ’ , to en- hance flexibility and generalizability under arbitrary miss- ing MRI conditions, as illustrated in Fig. 1 (a). Our funda- mental insight is to enable the generati v e model to recog- nize the fine-grained incomplete state information in a self- perceptiv e manner, and to leverage this understanding as in- ternal prompts to guide the generation process. W e hypoth- esize that, for diffusion models, such self-guided prompts may serve as an effectiv e alternativ e to manually defined masks, and potentially offer even stronger guidance sig- nals (Fig. 1 (b)). The main reason lies in the fact that this self-perceptiv e strategy encourages the model to learn both global and local anatomical structures and lesion patterns at coarse and fine lev els, thus enabling more semantically co- herent generation of the missing MRI regions during syn- thesis (Fig. 1 (c)(d)) [ 18 , 23 ]. Driv en by our moti vation, we propose CoPeDiT , a 3D latent diffusion model (LDM) framew ork for unified 3D MRI synthesis. T echnically , our frame work builds on two core components: (i) Unlike prior approaches that require explicit missing indicators, a nov el tokenizer with a com- pleteness perception function, CoPeV AE, is proposed to au- tonomously assess the integrity of modalities or volumes through tailored self-supervised pretext tasks. By detect- ing anatomical structures and v ariations in lesion patterns, CoPeV AE dev elops a comprehensi ve understanding of 3D MRIs. This enables CoPeDiT to eliminate the need for manual intervention with flexible adaptability , enhancing the method’ s autonomy and impro ves its feasibility for real- world clinical deployment with div erse missing patterns. (ii) A novel diffusion transformer architecture, MDiT3D, is dev eloped to unlock the potential of Diffusion T rans- formers (DiT) [ 34 ] for medical image synthesis, offering a new paradigm for generating high-quality v olumetric data. MDiT3D lev erages tokenization and attention mechanisms to model long-range and irregular contextual dependencies in high-dimensional, structurally complex 3D MRIs. It sup- ports conditional generation guided by completeness-aware prompts, which provide semantic-meaningful guidance on the synthesis process. The learned prompt tokens compre- hensiv ely absorb information from available modalities or slices during the dif fusion process and guide the genera- tion of the missing ones. Incorporating the abov e two in- nov ations, our architecture not only enables adapti ve self- guidance synthesis in a mask-free manner which exhibits strong robustness and generalizability , but also demon- strates improved structural coherence and enhanced preser- vation of fine-grained anatomical details. Our main contributions are summarized as follo ws: • W e propose a unified framework, dubbed CoPeDiT , for both 3D brain and cardiac missing MRI synthesis under arbitrary incomplete scenarios, without the need for ex- plicit external indicators as guidance. • W e empower our tokenizer , CoPeV AE, with a strong ca- pacity to perceiv e completeness by seamlessly integrat- ing carefully designed prete xt tasks, enabling the model to recognize missing states and learn informativ e, self- guided prompts. • W e present MDiT3D, a no vel latent dif fusion transformer for 3D MRI synthesis, featuring a dedicated architecture for capturing modality/spatial relationships and lev erag- ing generated prompts as conditional guidance. • Extensive e xperiments on three datasets demonstrate that our model surpasses state-of-the-art (SO T A) methods, achieving generalizability , robustness, and real-world clinical applicability . 2. Related W ork MRI Synthesis. Recent efforts focus on unified MRI syn- thesis using generative models such as Generative Adver - sarial Networks (GAN) and dif fusion models [ 1 , 36 , 52 , 56 ]. For example, MMGAN [ 43 ] employs a single network to handle di verse missing configurations, while Hyper- A v ailab le M o d alit ie s ℳ s M is s in g M o d alit i e s ℳ c D a t a S a m p l i n g C o m p l e t e n e s s P e r c e p t i o n P r e t e xt T a s k s Co m pr e s s i o n N e t w o r k 3D B r a i n M RI 3 D C ar d i ac M R I A v ailab le S lic e s ℳ s M is s in g S lic e s ℳ c La t en t T o k en s Co P eV AE - B ℳ s ℳ c � ℳ s � ℳ c s c ℰ ℱ 1 P r o m pt En cod e r s ℱ 2 ℱ 3 s P r o m pt T o k e ns s c ℱ 1 ℱ 2 ℱ 3 H o w M a n y M o d a l i t i e s a r e M i s si n g W h ic h M o d a l i t i e s a r e M i ssi n g W h a t M o d a l i t i e s a r e M i s si n g Sc o r e Num be r I nde x Sc o r e M o da l i t y I nde x T a s k 1: Mi s s i ng N um be r D et ec t i o n T a s k 2 : I nc o m pl e t e ne s s P o s it io n in g ℳ s : A v ailab le M o d alit i e s / S lic e s ℳ c : M is s in g M o d alit i e s / S lic e s : T rain ab le I n t er - m od al C o n t r a s t i ve L e a r n i n g ℒ ℒ ℒ Co P eV AE - C s c ℱ 1 ℱ 2 ℱ 3 H o w M a n y Sl i ce s a r e M i s s i n g W h ic h Sl i ce s a r e M i s si n g W h a t Sl i ce s a r e M i s si n g Sc o r e L e ng t h I nde x T a s k 1: Mi s s i ng L e ng t h D et ec t i o n T a s k 2 : I nc o m pl e t e ne s s P o s it io n in g T a s k 3 : M is s in g S lic e Asse ssm e n t I n t er - s l i ce C o n t r a s t i ve L e a r n i n g ℒ ℒ ℒ Sc o r e Sl i ce I n d e x T a s k 3 : Mi s s i ng M o da l Asse ssm e n t ℋ 1 ℋ 2 ℋ 3 ℋ 1 ℋ 2 ℋ 3 Figure 2. The overvie w framework of CoPeV AE. W e implement two variants, CoPeV AE-B and CoPeV AE-C, with slight architectural modifications for brain and cardiac MRI synthesis tasks, respectiv ely . GAE [ 53 ] introduces a shared hyper-encoder and decoder architecture with a graph-based fusion module for recon- structing missing brain MRIs. MMT [ 24 ] proposes to le ver - age Swin Transformers [ 25 ] to capture inter-modal depen- dencies. M2DN [ 29 ] presents a dif fusion-based method that jointly models all modalities using a multi-input multi- output frame work. Despite these advances, most existing methods still rely on externally provided masks to encode missing patterns in randomly incomplete cases. In contrast, CoPeDiT e xplores self-percepti ve capability of generati ve models to autonomously recognize data completeness, en- abling more flexible and high-fidelity MRI synthesis. Diffusion Models. Diffusion models have shown strong generativ e capacities across various computer vision tasks [ 26 , 28 , 55 ]. Denoising Diffusion Probabilistic Mod- els [ 16 ] generate images by gradually adding Gaussian noise and learning to re v erse the process. LDM [ 39 ] im- prov e efficiency by operating in a compressed latent space using autoencoders. Recently , Diffusion transformers [ 34 ] hav e been effecti v e alternatives to U-Net [ 40 ] in LDMs, achieving competitiv e performance in natural image gen- eration. Howe ver , most prior medical image generation ap- proaches still rely on U-Net-based architectures as the dif- fusion backbone, leaving the potential of transformer -based diffusion models undere xplored in this domain [ 31 , 49 ]. In this paper , we devise MDiT3D, by replacing the U-Net backbone with a diffusion transformer and incorporating task-specific architectural modifications, MDiT3D is capa- ble of generalizing to 3D MRI data and capturing long- range dependencies of high-dimensional 3D MRIs. 3. Methodology 3.1. Notations W e consider two 3D MRI synthesis tasks: brain missing modality synthesis and cardiac missing slice synthesis. T o unify the formulation, let M = { x i } m i =1 denote a complete MRI sample, where m is the total number of modalities or slices. The av ailable and missing subsets are denoted as M S = { x s i } s i =1 and M C = { x c i } c i =1 , respecti vely , with m = s + c . (1) Brain missing modality synthesis: M represents all brain MRIs with m modalities, and the task is to infer M C from M S . (2) Cardiac missing slice synthe- sis: M corresponds to a volume with m slices, where miss- ing slices M C are consecutiv e, non-ov erlapping with M S , and are to be reconstructed from the av ailable ones. No- tably , our experimental setup considers randomly generated incomplete cases from all the possible combinations as in- put, with a v arying number and length of missing modalities or slices, aiming to mimic real-world clinical en vironments. 3.2. Stage I: Completeness Per ception T okenizer The core idea of CoPeV AE (Fig. 2 ) is that detecting the completeness of high-resolution MRI data enforces the model to perceive both global anatomy and local lesion pat- terns, thereby producing high-quality prompts as diffusion guidance. Building upon VQGAN [ 10 , 47 ], we deploy a 3D autoencoder jointly trained with self-supervised pretext tasks. Each task employs a prompt encoder , denoted as F 1 , F 2 and F 3 , to transform latent tokens (learned by the encoder E ) into low-dimensional prompt tokens. All prompt encoders contain 3D Con v layers followed by spatial av- erage pooling. Afterwards, task-specific projection heads are applied for multi-granular classification and contrastiv e learning. Sp a t ial B lo c k M o d al B lo c k M o d al B lo c k Sp a t ial B lo c k Sp a t ial B lo c k M o d al B lo c k P lan ar B lo c k Sp a t ial B lo c k Sp a t ial B lo c k P lan ar B lo c k P lan ar B lo c k Sp a t ial B lo c k L a t e nt La te n t N o i s e s P r om p t T ok e n s MDi T3 D B l o c k 3D P a t ch i f y + 3D P E R M S N o r m L in e ar & R e s h ap e Ti m es tep E m b e d = = N × Av a i l a b l e M o d a l i t i e s s P ro mp t T o k e n s L a t en t N o i s es L a t en t C M Di T 3D - B Av a i l a b l e M o d a l i t i e s s M i s s i n g M o d a l i t i e s c B r ai n Mi s s i n g Mo d al i t y S yn t h e s i s Av a i l a b l e Sl i ce s s P ro mp t T o k e n s L a t en t N o i s es L a t en t M Di T 3D - C Av a i l a b l e Sl i ce s s M i s s i n g Sl i ce s c C a r d ia c M is s in g S lic e S y n t h e s is : T r a i n a b l e : F r o z e n C (a) O v e r v ie w o f B r ain an d C ar d iac M is s in g M R I S y n t h e s is P ip e lin e s ( b ) De t aile d A r c h it e c t u r e o f M DiT 3 D (c ) M D i T 3 D - B an d M DiT 3 D - C B l o ck s R M S N o r m S c ale , S h ift M HA S c ale Q K V R o PE R M S N o r m S c ale , S h ift FF N S c ale C o n d i t i o n s MLP , , M DiT 3 D - B M DiT 3 D - C × × × × × × > × × × × > × × × × × × Figure 3. The o vervie w framework of MDiT3D. PE and RoPE denote positional embeddings and rotary position embeddings [ 45 , 54 ], respectiv ely . Data Sampling . T o impro ve CoPeV AE’ s adaptability to di- verse missing cases, we employ a dual-random sampling strategy , where both the number/length of missing elements and the modality types/slice positions are randomly sam- pled. Giv en a complete set M , we first randomly sample a missing count c ∈ { 1 , . . . , m − 1 } , then uniformly select c elements to form the missing subset M C , with the remain- der forming the incomplete subset M S . T ask 1. Missing Number/Length Detection. Equipped with global contextual awareness, the tokenizer is capable of answering the question that how many modalities/slices are missing in the incomplete input. This task aims to en- able the tokenizer to identify the se verity of incompleteness by perceiving the global context of MRIs, thereby learning modality/spatial attributes in a coarse-grained manner . W e formulate this task as an ( m − 1) -class classification task and define the loss using the cross-entropy as L d = L cls ( H 1 ( F 1 ( z s )) c ) . (1) where F 1 and H 1 represent the prompt encoder and the projection head for missing detection, respectiv ely . The learned prompt tokens p d = F 1 ( z s ) are rich in informa- tion about the sev erity of missing state. T ask 2. Incompleteness Positioning . By identifying which modalities or slices are missing, CoPeV AE yields prompt tokens p p = F 2 ( z s ) that capture semantically meaningful local properties. The motiv ation of this task is to driv e the model to dev elop a finer -grained contextual understanding of subtle anatomical structures and detailed pattern v aria- tions. Although the missing position implicitly encodes the count, T ask 1 learns a modality/slice-agnostic global mag- nitude prior that calibrates the conditioning strength, while this task pro vides discrete, spatially localized cues about the exact missing identity . The incorporation of the tw o tasks improv es robustness to errors from either signal. This task is formulated as an m -class classification problem and is also optimized using the cross-entropy loss, defined as fol- lows: L p = L cls ( H 2 ( F 2 ( z s )) I ) . (2) where I denotes the index of missing type/position. T ask 3. Missing Modality/Slice Assessment. Moti- vated by the observation that modalities or slices from the same scan share more similar anatomical and textural con- text than those from dif ferent scans, we adopt an inter - modal/inter-slice contrastiv e learning scheme [ 38 ] to serve as a missing data estimator . Specifically , we take the incom- plete latent tokens z s as anchor, the corresponding miss- ing latent z c from the same subject as positiv es, and latent tokens z c − from different subjects as neg ati ves. The con- trastiv e loss is defined as follo ws: L c = − log φ ( H 3 ( p s ) , H 3 ( p c )) φ ( H 3 ( p s ) , H 3 ( p c ))+ P φ ( H 3 ( p s ) , H 3 ( p c − ) ) . (3) where p s = F 3 ( z s ) , p c = F 3 ( z c ) , φ ( a, b ) = exp( a · b/τ ) , and τ is the temperature parameter . This contrastive learning scheme encourages the model to focus on inter - modal/slice conte xtual dif ferences, thus improving anatom- ical coherence and fine-grained detail preservation. The ov erall loss of CoPeV AE is formulated as L tok = L rec + λ ( L d + L p + L c ) . (4) where λ is the weighting coefficient, and L rec denotes the re- construction loss that consists of a pixel-wise L1 loss, vec- tor quantization loss, adversarial loss, and perceptual loss. 3.3. Stage II: 3D MRI Diffusion T ransformer W e propose MDiT3D (see Fig. 3 ), extending the model configuration of DiT [ 34 ] with se v eral key design inno- vations to enable MDiT3D to adapt to 3D modalities and T able 1. Quantitative results for multi-modal brain MRI synthesis on BraTS and IXI datasets. The numbers of the second row denote the number of missing modalities. The best performances are bolded . BraTS IXI 1 2 3 1 2 PSNR ↑ SSIM ↑ FID ↓ PSNR ↑ SSIM ↑ FID ↓ PSNR ↑ SSIM ↑ FID ↓ PSNR ↑ SSIM ↑ FID ↓ PSNR ↑ SSIM ↑ FID ↓ GAN-based Methods MMGAN [ 43 ] 24.71 ± 1.57 0.817 ± 0.027 27.94 ± 1.05 24.38 ± 1.74 0.806 ± 0.023 32.48 ± 1.66 24.06 ± 1.92 0.794 ± 0.031 39.37 ± 2.10 22.29 ± 1.35 0.684 ± 0.015 70.91 ± 3.64 21.13 ± 1.49 0.668 ± 0.019 93.57 ± 3.42 MMT [ 24 ] 25.19 ± 1.41 0.824 ± 0.017 24.53 ± 1.33 24.50 ± 1.55 0.811 ± 0.020 29.57 ± 1.82 23.92 ± 1.53 0.801 ± 0.021 39.66 ± 1.95 22.64 ± 1.49 0.698 ± 0.013 53.60 ± 3.14 21.82 ± 1.60 0.687 ± 0.019 72.24 ± 2.98 Hyper-GAE [ 53 ] 24.65 ± 1.62 0.813 ± 0.022 28.97 ± 1.57 24.42 ± 1.74 0.808 ± 0.024 33.52 ± 1.78 23.86 ± 1.88 0.788 ± 0.029 41.79 ± 2.21 22.12 ± 1.33 0.682 ± 0.017 72.62 ± 3.78 20.91 ± 1.45 0.662 ± 0.021 98.79 ± 4.05 Diffusion Model-based Methods LDM [ 39 ] 23.84 ± 1.52 0.805 ± 0.019 36.47 ± 1.54 23.12 ± 1.64 0.798 ± 0.021 45.93 ± 2.41 22.65 ± 1.77 0.791 ± 0.025 52.50 ± 2.07 21.36 ± 1.28 0.679 ± 0.016 86.62 ± 3.86 20.94 ± 1.53 0.654 ± 0.020 112.57 ± 5.02 ControlNet [ 58 ] 23.98 ± 1.49 0.808 ± 0.018 34.09 ± 1.93 23.34 ± 1.60 0.801 ± 0.020 41.28 ± 2.49 22.85 ± 1.68 0.795 ± 0.022 48.07 ± 1.99 21.83 ± 1.51 0.681 ± 0.015 81.26 ± 3.85 21.07 ± 1.50 0.661 ± 0.019 103.77 ± 5.17 M2DN [ 29 ] 26.45 ± 1.36 0.830 ± 0.016 21.29 ± 1.18 25.87 ± 1.48 0.820 ± 0.017 27.36 ± 1.62 25.21 ± 1.59 0.809 ± 0.024 32.40 ± 1.93 23.47 ± 1.43 0.715 ± 0.014 42.52 ± 3.08 22.81 ± 1.56 0.702 ± 0.018 55.64 ± 3.62 CoPeDiT 28.26 ± 1.24 0.842 ± 0.019 12.67 ± 0.98 28.13 ± 1.49 0.831 ± 0.021 13.25 ± 1.45 27.91 ± 1.41 0.822 ± 0.023 14.89 ± 1.61 24.34 ± 1.21 0.732 ± 0.016 25.84 ± 2.58 23.92 ± 1.53 0.721 ± 0.020 32.53 ± 3.16 volumetric MRI. It tak es the high-dimensional latent to- kens z s as input, along with the learned prompt tokens p = p d ∥ p p ∥ p s from our CoPeV AE tokenizer , which en- code comprehensiv e missing state information and serve as conditional guidance for synthesizing. Without loss of gen- erality , we use MDiT3D-B as a representative configuration to illustrate the architectural design. 3D Patchify & 3D Positional Embeddings. W e apply a 3D patchify operator with patch size p × p × p to obtain h ∈ R m × T × d [ 30 ], where m denotes the number of modal- ity , and d is the embedding dimension. Unlike the stan- dard 2D positional embeddings [ 9 ] used in DiT , we le verage 3D frequency-based sine-cosine positional embeddings (3D PE) to better encode spatial positional information within the 3D MRI data. Alternating Blocks & Prompt Injection. T wo distinct types of blocks are designed tailored for brain and cardiac tasks, respecti vely . F or the brain MRI synthesis task, we adopt spatial and modal blocks: the former focuses on cap- turing 3D spatial information, while the latter models inter - modal relationships. Before each modal block, the tokens h are reshaped into R T × m × d to facilitate inter -modal inter - action, then reshaped back for subsequent spatial process- ing. These two types of blocks are stacked in an alternat- ing fashion to form a total of N blocks. The moti v ation behind this design lies in the need for the model to cap- ture both inter- and intra-modal relationships to boost con- textual understanding and anatomical consistency . Addi- tionally , adaptiv e layer normalization is employed to inject prompts into the blocks. Notably , inspired by the intuition that conditioning signals should be subtle yet informative, prompt tokens are injected only into the modal blocks. Joint Reconstruction & Synthesis. W e concatenate the av ailable and the noisy latent (corresponding to missing sections) as the input to MDiT3D. Moreov er , a joint re- construction & synthesis scheme is introduced, where only the missing sections undergo noise injection and denoising during the dif fusion process, while the observ ed re gions re- main unchanged, serving as auxiliary context that provides rich semantic guidance for generation. Given that directly synthesizing the entire modality/volume is more informa- tiv e and efficient than simply predicting zero noise for the av ailable latent re gions [ 29 ], we adopt x-prediction loss as objectiv e function for MDiT3D, as belo w: L diff = E z 0 ,ϵ,t ∥ z 0 − f θ ( z t , t, p ) ∥ 2 2 . (5) where z 0 = z s ∥ z c denotes the concatenated clean latent tokens, z t = z s ∥ z c t is the noisy input at timestep t , p is the prompt tokens, and f θ represents our MDiT3D model. 4. Experiments and Results 4.1. Experimental Setup Datasets. (i) Brain MRI Datasets. W e ev aluate the ef- fectiv eness of CoPeDiT on two public brain MRI datasets: BraTS 2021 [ 3 ] and IXI [ 5 ]. The BraTS 2021 dataset in- cludes 1251 subjects with multi-modal MRI scans across four modalities: T1, T1ce, T2, and FLAIR. The IXI dataset contains 577 subjects with three MRI modalities: T1, T2, and PD. (ii) Cardiac MRI Datasets. Missing slice synthe- sis experiments are conducted on four cardiac MRI datasets: UK Biobank (UKBB) [ 35 ], MESA [ 57 ], A CDC [ 4 ], and MSCMR [ 59 ]. The model is trained on the combined dataset including all four sources with 32,248 MRI volumes in total, while performance comparisons are conducted on the UKBB dataset. W e randomly select 80% of the data for training and use the remaining 20% as the test set. Please refer to the supplementary material for more dataset details. Implementation Details. The compression rate of CoPe- V AE is set to (8 , 8 , 8) . For hyperparameters, the dimension of each prompt token is set to 512, τ and λ are set to 0.2 and 1e-2, respectiv ely . The model is trained with a global batch size of 8 for CoPeV AE-B and 64 for CoPeV AE-C, using a learning rate of 1e-4. Regarding MDiT3D, we set the num- ber of time steps to 500 with linearly scaled noise schedul- ing. The model is trained for 100k steps with a global batch size of 32 and learning rate of 5e-5. All training is con- ducted on four NVIDIA A100 GPUs. More details are pro- vided in the supplementary material. 4.2. Perf ormance Comparison Quantitative Results. W e compare our method against six recent SO T A models for 3D brain and cardiac MRI synthe- T able 2. Quantitative results for Cardiac MRI synthesis on UKBB dataset. The numbers of the second row denote the length of missing slices. The best performances are bolded . UKBB 8 16 24 PSNR ↑ SSIM ↑ FID ↓ PSNR ↑ SSIM ↑ FID ↓ PSNR ↑ SSIM ↑ FID ↓ GAN-based Methods MMGAN [ 43 ] 25.81 ± 0.86 0.815 ± 0.012 16.68 ± 0.93 24.35 ± 0.84 0.793 ± 0.009 27.52 ± 0.90 23.06 ± 1.08 0.776 ± 0.018 45.88 ± 1.32 MMT [ 24 ] 26.02 ± 0.82 0.824 ± 0.009 15.90 ± 0.88 24.73 ± 0.87 0.809 ± 0.010 23.75 ± 0.97 24.12 ± 1.06 0.794 ± 0.017 37.39 ± 1.27 Hyper-GAE [ 53 ] 25.23 ± 0.89 0.810 ± 0.012 19.02 ± 0.96 23.66 ± 0.94 0.789 ± 0.013 31.84 ± 1.15 22.70 ± 1.14 0.771 ± 0.019 48.27 ± 1.39 Diffusion Model-based Methods LDM [ 39 ] 24.17 ± 0.96 0.795 ± 0.012 24.61 ± 0.94 23.04 ± 1.03 0.778 ± 0.010 44.93 ± 1.49 22.19 ± 1.21 0.761 ± 0.018 60.02 ± 1.68 ControlNet [ 58 ] 24.62 ± 0.91 0.801 ± 0.012 22.47 ± 1.06 23.30 ± 0.98 0.784 ± 0.014 37.51 ± 1.55 22.46 ± 1.16 0.765 ± 0.020 54.93 ± 1.74 M2DN [ 29 ] 25.48 ± 0.79 0.814 ± 0.011 17.72 ± 0.85 24.62 ± 0.87 0.803 ± 0.011 24.15 ± 1.06 24.03 ± 0.99 0.780 ± 0.021 40.08 ± 1.59 CoPeDiT 26.42 ± 0.81 0.831 ± 0.013 15.53 ± 0.88 26.07 ± 0.74 0.826 ± 0.013 18.21 ± 0.90 25.39 ± 0.86 0.817 ± 0.016 25.84 ± 1.22 Figure 4. Qualitati ve results on BraTS dataset. The results are depicted in the axial (top), sagittal (middle) and coronal (bottom) views of the 3D MRI volume. The visual results on IXI dataset are provided in the supplementary material. T able 3. Ablation study on the contribution of each pretext task to CoPeV AE’ s reconstruction capacity . ‘Cardiac’ refers to the aggre- gated cardiac MRI dataset consisting of four sources, which are used for training our CoPeV AE model. BraTS IXI Cardiac PSNR ↑ SSIM ↑ PSNR ↑ SSIM ↑ PSNR ↑ SSIM ↑ w/o T ask 1 34.38 0.926 30.92 0.914 32.34 0.921 w/o T ask 2 33.62 0.918 30.35 0.908 31.59 0.914 w/o T ask 3 34.69 0.929 31.13 0.917 32.62 0.925 CoPeV AE 35.05 0.935 31.28 0.921 33.34 0.931 sis, including three GAN-based approaches [ 24 , 43 , 53 ] and three advanced diffusion model-based methods [ 29 , 39 , 58 ]. W e report results by reimplementing all baselines from scratch under identical experimental settings to ensure fair comparisons. Performance is ev aluated using three met- rics: Peak Signal-to-Noise Ratio (PSNR), Structural Sim- ilarity Inde x Measure (SSIM), and Fr ´ echet Inception Dis- tance (FID) [ 15 ] that uses Inception-V3 [ 46 ] as the feature extractor . Quantitativ e results on the three datasets are pre- sented in T ables 1 and 2 , where the second row indicates the number of missing modalities or slices c , respecti vely . The results show that CoPeDiT consistently outperforms all baselines across all missing configurations in both synthe- sis tasks, sho wcasing superior generalizability . Notably , the performance gains are more pronounced in scenarios with a larger number of missing modalities/slices, highlighting the robustness of our completeness-a ware prompts in handling complex missing cases. Besides, CoPeDiT achieves signif- icantly lo wer FID, indicating that the generated MRIs are more anatomically coherent and te xture-preserving, with feature distrib utions that are closer to real clinical data, thus enhancing perceptual realism and diagnostic plausibility . Qualitative Results. As depicted in Fig. 4 and 5 , our model generates synthetic MRIs that e xhibit the highest visual similarity to the ground truth images, particularly in accurately capturing tumor re gions. Our CoPeDiT ex- cels at preserving subtle te xtural details and modeling com- plex anatomical structures within brain tissues, justifying our motiv ation that incorporating completeness perception leads to improv ed anatomical consistency and realism. 4.3. Ablation Study Effect of Pretext T asks. As T able 3 displays, CoPe- V AE preserves strong reconstruction capability while ben- efiting from the incorporation of pretext tasks. Each task contributes positi v ely , and their combination leads to fur - ther improv ements. This improvement can be attributed to the fact that pretext tasks promote the tokenizer to cap- GT MMGAN MMT LDM Hyper -GAE Ours ControlNet M2DN Figure 5. Qualitativ e results of comparison on UKBB dataset. The top and bottom results correspond to the first and last missing slices within a giv en v olume, respectiv ely . T able 4. Ablation study on the contribution of completeness-a ware prompt tokens. BraTS UKBB 1 2 3 8 24 PSNR ↑ SSIM ↑ FID ↓ PSNR ↑ SSIM ↑ FID ↓ PSNR ↑ SSIM ↑ FID ↓ PSNR ↑ SSIM ↑ FID ↓ PSNR ↑ SSIM ↑ FID ↓ w/o p d 27.35 0.833 16.04 27.02 0.824 17.30 26.73 0.814 19.62 25.82 0.819 16.34 24.53 0.803 33.80 w/o p p 26.92 0.829 18.46 26.43 0.819 20.23 26.06 0.810 25.13 25.17 0.812 20.08 24.39 0.798 36.54 w/o p s 27.56 0.835 15.26 27.22 0.827 16.37 26.90 0.815 17.58 26.27 0.828 16.79 25.08 0.813 29.83 w/o Prompts 25.92 0.823 25.69 25.06 0.807 32.17 24.83 0.802 37.97 24.70 0.797 23.29 23.56 0.778 42.17 w/ Mask Codes 27.18 0.831 17.42 26.82 0.816 20.06 26.18 0.809 24.59 26.15 0.823 18.15 24.65 0.802 35.86 CoPeDiT 28.26 0.842 12.67 28.13 0.831 13.25 27.91 0.822 14.89 26.42 0.831 15.53 25.39 0.817 25.84 T able 5. Quantitativ e results by incorporating our learned prompt tokens into baselines instead of mask codes. BraTS PSNR ↑ SSIM ↑ FID ↓ MMT [ 24 ] 25.19 0.824 24.53 + Prompts (ours) 25.68 (+0.49) 0.826 (+0.002) 22.07 (–2.46) Hyper-GAE [ 53 ] 24.65 0.813 28.97 + Prompts (ours) 25.26 (+0.61) 0.822 (+0.009) 24.26 (–4.71) M2DN [ 29 ] 26.45 0.830 21.29 + Prompts (ours) 27.23 (+0.78) 0.837 (+0.007) 17.06 (–4.23) ture anatomical structure variances in both coarse and fine- grained manner , learning highly discriminati ve features. Effect of Prompt T okens. T able 4 presents the synthe- sis performance associated with each learned prompt to- ken and mask code. The mask codes are generated as one- hot vectors whose dimension corresponds to the number of modalities or slices, indicating the corresponding missing positions. Notably , we employ an identical injection strat- egy for all prompts and masks to ensure a fair comparison. As shown, all individual prompt tokens and their combi- nations improve model performance, surpassing guidance based on binary mask codes. These findings strongly high- light the effecti veness and rationale of our completeness perception scheme. The incompleteness positioning task yields the most effecti v e prompts, likely due to its explicit emphasis on positioning missing sections along the modal- ity/slice dimension, thus increasing the sensitivity to sub- tle structural v ariations. T o further explore the potential of our learned prompts, we incorporate them into prior base- lines as replacements for mask codes. As illustrated in T a- ble 13 , this substitution consistently improves their perfor- mance, demonstrating the utility and generalizability of our completeness-aware prompts, which can serve as a flexible paradigm for improving emer ging MRI synthesis methods. Choice of Prompt Injection Position. This e xperiment aims to justify our choice of injecting prompts exclusiv ely into the modal and spatial blocks for brain and cardiac tasks, respectiv ely . As illustrated in T able 14 , injecting prompts into the modal/spatial block yields the best overall perfor - mance, whereas injecting into spatial/planar blocks or both blocks results in inferior outcomes. This can be attributed to the fact that aligning the prompt with the block that explic- itly models the task’ s primary dependency , namely modality fusion for brain and through-plane continuity for cardiac, maximizes the efficac y of conditional signals. Impact of 3D MRI Diffusion T ransformer . The quan- titativ e e v aluation of MDiT3D and existing diffusion net- works [ 30 , 34 , 39 ] is presented in T able 7 . The results il- lustrate that MDiT3D consistently achie ves superior perfor - mance, confirming that the specialized architectural designs effecti vely enhance the quality of 3D MRI synthesis. 4.4. V isualization Analysis Salient Regions. T o better understand the learning proce- dure of pretext tasks, we visualize their activ ation maps us- ing GradCAM [ 42 ]. As sho wn in Fig. 6 , the four exam- ples re veal strong correlations between salient regions and T able 6. Ablation study on the choice of prompt injection positions within the MDiT3D blocks. ‘Spatial / Planar’ indicates that prompt tokens are injected into the spatial and planar blocks for brain and cardiac tasks, respectiv ely . ‘Both’ indicates that prompt tokens are injected into both the spatial and modal blocks for brain tasks, and into both the planar and spatial blocks for cardiac tasks. ‘Modal / Spatial’ indicates that prompt tokens are injected into the modal and spatial blocks, respecti vely . BraTS UKBB 1 2 3 8 24 PSNR ↑ SSIM ↑ FID ↓ PSNR ↑ SSIM ↑ FID ↓ PSNR ↑ SSIM ↑ FID ↓ PSNR ↑ SSIM ↑ FID ↓ PSNR ↑ SSIM ↑ FID ↓ Spatial / Planar 27.47 0.834 15.41 27.20 0.825 16.83 27.03 0.817 17.45 26.29 0.827 16.82 25.22 0.814 29.24 Both 27.76 0.836 13.94 27.54 0.827 15.48 27.29 0.818 16.77 26.33 0.827 16.39 25.28 0.815 28.45 Modal / Spatial 28.26 0.842 12.67 28.13 0.831 13.25 27.91 0.822 14.89 26.42 0.831 15.53 25.39 0.817 25.84 T able 7. Ablation study on the contribution of 3D MRI Dif fusion Transformer . BraTS UKBB 1 2 3 8 24 PSNR ↑ SSIM ↑ FID ↓ PSNR ↑ SSIM ↑ FID ↓ PSNR ↑ SSIM ↑ FID ↓ PSNR ↑ SSIM ↑ FID ↓ PSNR ↑ SSIM ↑ FID ↓ UNet [ 39 ] 25.61 0.825 23.56 25.20 0.816 28.37 24.78 0.805 36.70 24.46 0.800 22.34 23.01 0.778 41.59 DiT [ 34 ] 26.78 0.835 19.72 26.14 0.823 21.84 25.74 0.808 24.47 25.89 0.825 16.28 24.78 0.799 36.10 DiT -3D [ 30 ] 26.84 0.835 19.23 26.23 0.822 21.95 25.90 0.810 26.08 26.08 0.825 16.37 24.83 0.806 33.73 MDiT3D 28.26 0.842 12.67 28.13 0.831 13.25 27.91 0.822 14.89 26.42 0.831 15.53 25.39 0.817 25.84 T ask 1 T ask 2 T ask 3 S o u r c e Figure 6. V isualization of salient regions on BraTS dataset. ( a ) P r o m p t p d D i s t r i b u t i o n Missing Number : 1 Missing Number : 2 Missing Number : 3 ( b ) P r o m p t p p D i s t r i b u t i o n T1 T1ce T2 FL AIR Figure 7. t-SNE visualization on the BraTS dataset of (a) The count-focused prompt p d colored by missing-number classes; and (b) The identity-focused prompt p p colored by missing modality . modality-discriminativ e features. Specifically , these pat- terns mirror each task’ s objectiv e: T ask 1 and T ask 3 must w / Pr omp t To k e n s w/ M as k Co d e s L a y e r 1 L a y e r 2 L a y e r 4 L a y e r 6 L a y e r 8 Figure 8. V isualization of attention maps from individual modal blocks on BraTS dataset under a missing configuration of [1, 0, 0, 0], where the first modality is absent. assess global consistenc y , so they rely on coarse anatomi- cal layout (gray and white matter) that summarize the v ol- ume. In contrast, T ask 2 needs to pinpoint where/which is missing, so it ke ys on high-frequency , modality-specific cues (tumors, lesions, and white matter hyperintensities in FLAIR) to localize. The results emphasize that our pre- text tasks effecti vely capture modality-specific properties, understanding the MRI context and relationships. Prompt Distribution. W e implement the t-SNE visu- alization of learned prompts on BraTS and color them by ground-truth incompleteness labels. As depicted in Fig. 7 , the count-focused prompt p d forms compact, well-separated clusters aligned with the missing number classes corresponding to each missing state (1/2/3 absent modalities), while the identity-focused prompt p p produces modality-specific clusters (T1, T1ce, T2, FLAIR) with clear boundaries, highlighting that the two prompts capture com- plementary aspects of incompleteness. Attention Maps. W e in vestig ate the contribution of prompts by visualizing the attention maps of each modal block. As shown in Fig. 8 , our prompts guide the attention mechanism to progressively focus on the actual missing el- ements (the first ro w and column) with the increase of block layers. In comparison, mask codes lack sufficient informa- tiv eness and fail to provide nuanced guidance that aligns with the true missing state. 5. Conclusion This work presents CoPeDiT , a unified model for 3D brain and cardiac MRI synthesis that explores completeness perception. W e demonstrate that enabling the model to autonomously infer missing state, rather than relying on externally pre-defined masks, can provide more discrimi- nativ e and informative guidance. T o this end, we equip our tokenizer with completeness perception capability through elaborated pretext tasks. MDiT3D is then developed to utilize the learned prompt tokens as guidance for 3D MRI generation. Experimental ev aluation validates the superiority of CoPeDiT in terms of accuracy , generaliz- ability , robustness, and adaptability across diverse missing scenarios. Furthermore, CoPeDiT enables mask-free synthesis through percei ving completeness state, enhancing flexibility and applicability in practical clinical settings. References [1] Suhyun Ahn, W onjung Park, Jihoon Cho, and Jinah Park. V olumetric conditioning module to control pretrained diffu- sion models for 3d medical images. In W ACV , pages 85–95, 2025. 2 [2] Reza Azad, Mohammad Dehghanmanshadi, Nika Khosravi, Julien Cohen-Adad, and Dorit Merhof. Addressing missing modality challenges in mri images: A comprehensive revie w . Computational V isual Media , 11(2):241–268, 2025. 1 [3] Ujjwal Baid, Satyam Ghodasara, Suyash Mohan, Michel Bilello, Evan Calabrese, Errol Colak, Ke yv an Farahani, Jayashree Kalpathy-Cramer , Felipe C Kitamura, Sarthak Pati, et al. The rsna-asnr -miccai brats 2021 benchmark on brain tumor segmentation and radiogenomic classification. arXiv pr eprint arXiv:2107.02314 , 2021. 5 , 1 [4] Olivier Bernard, Alain Lalande, Clement Zotti, Freder- ick Cerv enansky , Xin Y ang, Pheng-Ann Heng, Irem Cetin, Karim Lekadir , Oscar Camara, Miguel Angel Gonza- lez Ballester , Gerard Sanroma, Sandy Napel, Stef fen Pe- tersen, Georgios Tziritas, Elias Grinias, Mahendra Khened, V arghese Ale x K ollerathu, Ganapathy Krishnamurthi, Marc- Michel Roh ´ e, Xavier Pennec, Maxime Sermesant, Fabian Isensee, Paul J ¨ ager , Klaus H. Maier-Hein, Peter M. Full, Ivo W olf, Sandy Engelhardt, Christian F . Baumgartner , Lisa M. K och, Jelmer M. W olterink, Ivana I ˇ sgum, Y eonggul Jang, Y oonmi Hong, Jay Patrav ali, Shubham Jain, Olivier Hum- bert, and Pierre-Marc Jodoin. Deep learning techniques for automatic mri cardiac multi-structures segmentation and di- agnosis: Is the problem solv ed? IEEE T ransactions on Med- ical Imaging , 37(11):2514–2525, 2018. 5 , 1 [5] Imperial College London Brain Development Project. Ixi dataset (information extraction from images), 2025. Ac- cessed 2025-07-28. 5 , 1 [6] Jihoon Cho, Jonghye W oo, and Jinah Park. A unified frame- work for synthesizing multisequence brain mri via hybrid fu- sion. arXiv pr eprint arXiv:2406.14954 , 2024. 1 [7] Sanuwani Dayarathna, Kh T ohidul Islam, Sergio Uribe, Guang Y ang, Munawar Hayat, and Zhaolin Chen. Deep learning based synthesis of mri, ct and pet: Revie w and anal- ysis. Medical Image Analysis , 92:103046, 2024. 1 [8] Louise Dickinson, Hashim U Ahmed, Clare Allen, Jelle O Barentsz, Brendan Carey , Jurgen J Futterer , Stijn W Hei- jmink, Peter Hoskin, Ale x P Kirkham, Anwar R Padhani, et al. Clinical applications of multiparametric mri within the prostate cancer diagnostic pathway . Ur ologic oncology , 31 (3):281, 2013. 1 [9] Alexey Dosovitskiy , Lucas Beyer , Alexander K olesnikov , Dirk W eissenborn, Xiaohua Zhai, Thomas Unterthiner , Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly , et al. An image is worth 16x16 words: Trans- formers for image recognition at scale. arXiv pr eprint arXiv:2010.11929 , 2020. 5 [10] Patrick Esser , Robin Rombach, and Bjorn Ommer . T aming transformers for high-resolution image synthesis. In CVPR , pages 12873–12883, 2021. 3 , 1 [11] Andr ´ e Ferreira, Jianning Li, Kelsey L. Pomykala, Jens Kleesiek, V ictor Alves, and Jan Egger . Gan-based genera- tion of realistic 3d v olumetric data: A systematic revie w and taxonomy . Medical Image Analysis , 93:103100, 2024. 1 [12] Alexandros Graikos, Srikar Y ellapragada, Minh-Quan Le, Saarthak Kapse, Prateek Prasanna, Joel Saltz, and Dimitris Samaras. Learned representation-guided diffusion models for lar ge-image generation. In CVPR , pages 8532–8542, 2024. 2 [13] Ibrahim Ethem Hamamci, Sezgin Er, Anjany Sekuboy- ina, Enis Simsar, Alperen T ezcan, A yse Gulnihan Sim- sek, Sevv al Nil Esirgun, Furkan Almas, Irem Do ˘ gan, Muhammed Furkan Dasdelen, et al. Generatect: T ext- conditional generation of 3d chest ct volumes. In ECCV , pages 126–143, 2024. 1 [14] Huaibo Hao, Jie Xue, Pu Huang, Liwen Ren, and Dengwang Li. Qgformer: Queries-guided transformer for flexible med- ical image synthesis with domain missing. Expert Systems with Applications , 247:123318, 2024. 1 [15] Martin Heusel, Hubert Ramsauer, Thomas Unterthiner , Bernhard Nessler, and Sepp Hochreiter . Gans trained by a two time-scale update rule con ver ge to a local nash equilib- rium. In NeurIPS , 2017. 6 [16] Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models. In NeurIPS , pages 6840–6851, 2020. 3 [17] V incent T ao Hu, David W . Zhang, Y uki M. Asano, Gertjan J. Burghouts, and Cees G. M. Snoek. Self-guided dif fusion models. In CVPR , pages 18413–18422, 2023. 2 [18] Wuliang Huang, Y iqiang Chen, Xinlong Jiang, Chenlong Gao, T eng Zhang, Qian Chen, and Y ifan W ang. Mitigating pervasi ve modality absence through multimodal generaliza- tion and refinement. In AAAI , pages 26796–26804, 2025. 2 [19] Mahmoud Ibrahim, Y asmina Al Khalil, Sina Amirrajab, Chang Sun, Marcel Breeuwer , Josien Pluim, Bart Elen, G ¨ okhan Ertaylan, and Michel Dumontier . Generative ai for synthetic data across multiple medical modalities: A system- atic re view of recent dev elopments and challenges. Comput- ers in Biology and Medicine , 189:109834, 2025. 1 [20] Guanzhou Ke, Shengfeng He, Xiaoli W ang, Bo W ang, Guo- qing Chao, Y uanyang Zhang, Y i Xie, and Hexing Su. Knowl- edge bridger: T owards training-free missing modality com- pletion. In CVPR , pages 25864–25873, 2025. 1 [21] Jonghun Kim and Hyunjin Park. Adaptive latent diffusion model for 3d medical image to image translation: Multi- modal magnetic resonance imaging study . In W ACV , pages 7604–7613, 2024. 1 [22] Y i-Lun Lee, Y i-Hsuan Tsai, W ei-Chen Chiu, and Chen-Y u Lee. Multimodal prompting with missing modalities for vi- sual recognition. In CVPR , pages 14943–14952, 2023. 1 [23] Hanwen Liang, Niamul Quader , Zhixiang Chi, Lizhe Chen, Peng Dai, Juwei Lu, and Y ang W ang. Self-supervised spa- tiotemporal representation learning by exploiting video con- tinuity . In AAAI , pages 1564–1573, 2022. 2 [24] Jiang Liu, Sriv athsa P asumarthi, Ben Duf fy , Enhao Gong, Kesha v Datta, and Greg Zaharchuk. One model to synthesize them all: Multi-contrast multi-scale transformer for missing data imputation. IEEE T ransactions on Medical Imaging , 42 (9):2577–2591, 2023. 1 , 3 , 5 , 6 , 7 , 2 [25] Ze Liu, Y utong Lin, Y ue Cao, Han Hu, Y ixuan W ei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windo ws. In ICCV , pages 10012–10022, 2021. 3 [26] Haoyu Lu, Guoxing Y ang, Nanyi Fei, Y uqi Huo, Zhiwu Lu, Ping Luo, and Mingyu Ding. VDT: General-purpose video diffusion transformers via mask modeling. In ICLR , 2024. 3 [27] Michael Lustig, David Donoho, and John M. Pauly . Sparse mri: The application of compressed sensing for rapid mr imaging. Magnetic Resonance in Medicine , 58(6):1182– 1195, 2007. 1 [28] Xin Ma, Y aohui W ang, Xinyuan Chen, Gengyun Jia, Ziwei Liu, Y uan-Fang Li, Cunjian Chen, and Y u Qiao. Latte: La- tent diffusion transformer for video generation. T ransactions on Machine Learning Resear ch , 2025. 3 [29] Xiangxi Meng, Kaicong Sun, Jun Xu, Xuming He, and Ding- gang Shen. Multi-modal modality-mask ed diffusion network for brain mri synthesis with random modality missing. IEEE T ransactions on Medical Imaging , 43(7):2587–2598, 2024. 1 , 3 , 5 , 6 , 7 , 2 [30] Shentong Mo, Enze Xie, Ruihang Chu, Lanqing Hong, Matthias Niessner , and Zhenguo Li. Dit-3d: Exploring plain diffusion transformers for 3d shape generation. In NeurIPS , pages 67960–67971, 2023. 5 , 7 , 8 [31] Maham Nazir , Muhammad Aqeel, and Francesco Setti. Diffusion-based data augmentation for medical image se g- mentation. In ICCV , pages 1330–1339, 2025. 3 [32] T an Pan, Zhaorui T an, Kaiyu Guo, Dongli Xu, W eidi Xu, Chen Jiang, Xin Guo, Y uan Qi, and Y uan Cheng. Structure- aware semantic discrepanc y and consistency for 3d medi- cal image self-supervised learning. In ICCV , pages 20257– 20267, 2025. 1 [33] Anthony P aproki, Olivier Salvado, and Clinton F ookes. Syn- thetic data for deep learning in computer vision & medical imaging: A means to reduce data bias. ACM Computing Surve ys , 56(11), 2024. 1 [34] William Peebles and Saining Xie. Scalable diffusion models with transformers. In ICCV , pages 4195–4205, 2023. 2 , 3 , 4 , 7 , 8 [35] Steffen E. Petersen, P aul M. Matthews, Jane M. Francis, Matthew D. Robson, Filip Zemrak, Redha Boubertakh, Alis- tair A. Y oung, Sarah Hudson, Peter W eale, Stev e Garratt, Rory Collins, Stefan Piechnik, and Stefan Neubauer . Uk biobank’ s cardio v ascular magnetic resonance protocol. Jour- nal of Car diovascular Magnetic Resonance , 18(1):8, 2016. 5 , 1 [36] Kunpeng Qiu, Zhiqiang Gao, Zhiying Zhou, Mingjie Sun, and Y ongxin Guo. Noise-consistent siamese-diffusion for medical image synthesis and segmentation. In CVPR , pages 15672–15681, 2025. 2 [37] Y ansheng Qiu, Ziyuan Zhao, Hongdou Y ao, Delin Chen, and Zheng W ang. Modal-aware visual prompting for incomplete multi-modal brain tumor segmentation. In ACMMM , page 3228–3239, 2023. 2 [38] Alec Radford, Jong W ook Kim, Chris Hallacy , Aditya Ramesh, Gabriel Goh, Sandhini Agarw al, Girish Sastry , Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger , and Ilya Sutske ver . Learning transferable visual models from natural language supervision. In ICML , pages 8748–8763, 2021. 4 [39] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser , and Bj ¨ orn Ommer . High-resolution image syn- thesis with latent diffusion models. In CVPR , pages 10684– 10695, 2022. 3 , 5 , 6 , 7 , 8 , 2 [40] Olaf Ronneber ger , Philipp Fischer , and Thomas Brox. U- net: Con v olutional networks for biomedical image segmen- tation. In International Confer ence on Medical image com- puting and computer-assisted intervention , pages 234–241. Springer , 2015. 3 , 2 [41] Shaohao Rui, Lingzhi Chen, Zhenyu T ang, Lilong W ang, Mianxin Liu, Shaoting Zhang, and Xiaosong W ang. Multi- modal vision pre-training for medical image analysis. In CVPR , pages 5164–5174, 2025. 1 [42] Ramprasaath R. Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna V edantam, Devi P arikh, and Dhruv Ba- tra. Grad-cam: V isual explanations from deep networks via gradient-based localization. In ICCV , 2017. 7 [43] Anmol Sharma and Ghassan Hamarneh. Missing mri pulse sequence synthesis using multi-modal generati ve adversar - ial network. IEEE T ransactions on Medical Imaging , 39(4): 1170–1183, 2020. 2 , 5 , 6 [44] Y ejee Shin, Y eeun Lee, Hanbyol Jang, Geonhui Son, Hyeongyu Kim, and Dosik Hwang. Anatomical consis- tency and adaptive prior-informed transformation for multi- contrast mr image synthesis via diffusion model. In CVPR , pages 30918–30927, 2025. 2 [45] Jianlin Su, Murtadha Ahmed, Y u Lu, Shengfeng P an, W en Bo, and Y unfeng Liu. Roformer: Enhanced transformer with rotary position embedding. Neur ocomputing , 568:127063, 2024. 4 [46] Christian Szegedy , V incent V anhoucke, Ser gey Ioffe, Jon Shlens, and Zbigniew W ojna. Rethinking the inception ar- chitecture for computer vision. In CVPR , 2016. 6 [47] Aaron van den Oord, Oriol V inyals, and koray ka vukcuoglu. Neural discrete representation learning. In NeurIPS , 2017. 3 , 1 [48] Hu W ang, Y uanhong Chen, Congbo Ma, Jodie A very , Louise Hull, and Gustavo Carneiro. Multi-modal learning with missing modality via shared-specific feature modelling. In CVPR , pages 15878–15887, 2023. 1 [49] Haoshen W ang, Zhentao Liu, Kaicong Sun, Xiaodong W ang, Dinggang Shen, and Zhiming Cui. 3d meddiffusion: A 3d medical latent diffusion model for controllable and high- quality medical image generation. IEEE T ransactions on Medical Imaging , 2025. 3 [50] Y ulin W ang, Honglin Xiong, Kaicong Sun, Shuwei Bai, Ling Dai, Zhongxiang Ding, Jiameng Liu, Qian W ang, Qian Liu, and Dinggang Shen. T ow ard general te xt-guided multimodal brain mri synthesis for diagnosis and medical image analysis. Cell Reports Medicine , 2025. 1 [51] Laura W enderoth, Konstantin Hemker, Nikola Simidjievski, and Mateja Jamnik. Measuring cross-modal interactions in multimodal models. In AAAI , pages 21501–21509, 2025. 1 [52] Y an Xia, Le Zhang, Nishant Ravikumar , Rahman Attar , Ste- fan K. Piechnik, Stefan Neubauer , Steffen E. Petersen, and Alejandro F . Frangi. Recovering from missing data in pop- ulation imaging – cardiac mr image imputation via condi- tional generativ e adversarial nets. Medical Image Analysis , 67:101812, 2021. 2 [53] Heran Y ang, Jian Sun, and Zongben Xu. Learning unified hyper-netw ork for multi-modal mr image synthesis and tu- mor segmentation with missing modalities. IEEE T ransac- tions on Medical Imaging , 42(12):3678–3689, 2023. 3 , 5 , 6 , 7 , 2 [54] Zhuoyi Y ang, Jiayan T eng, W endi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Y uanming Y ang, W enyi Hong, Xiao- han Zhang, Guanyu Feng, Da Y in, Y uxuan.Zhang, W eihan W ang, Y ean Cheng, Bin Xu, Xiaotao Gu, Y uxiao Dong, and Jie T ang. Cogvideox: T ext-to-video dif fusion models with an expert transformer . In ICLR , 2025. 4 [55] Jingfeng Y ao, Bin Y ang, and Xinggang W ang. Reconstruc- tion vs. generation: T aming optimization dilemma in latent diffusion models. In CVPR , pages 15703–15712, 2025. 3 [56] Y ousef Y eganeh, Azade Farshad, Ioannis Charisiadis, Marta Hasny , Martin Hartenberger , Bj ¨ orn Ommer, Nassir Na vab, and Ehsan Adeli. Latent drifting in dif fusion models for counterfactual medical image synthesis. In CVPR , pages 7685–7695, 2025. 2 [57] Guo-Qiang Zhang, Licong Cui, Remo Mueller, Shiqiang T ao, Matthew Kim, Michael Rueschman, Sara Mariani, Daniel Moble y , and Susan Redline. The national sleep re- search resource: towards a sleep data commons. Journal of the American Medical Informatics Association , 25(10): 1351–1358, 2018. 5 , 1 [58] Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. In ICCV , pages 3836–3847, 2023. 5 , 6 , 2 [59] Xiahai Zhuang, Jiahang Xu, Xinzhe Luo, Chen Chen, Cheng Ouyang, Daniel Rueckert, V ictor M. Campello, Karim Lekadir , Sulaiman V esal, Nishant RaviKumar , Y ashu Liu, Gongning Luo, Jingkun Chen, Hongwei Li, Buntheng L y , Maxime Sermesant, Holger Roth, W entao Zhu, Jiexiang W ang, Xinghao Ding, Xinyue W ang, Sen Y ang, and Lei Li. Cardiac segmentation on late gadolinium enhancement mri: A benchmark study from multi-sequence cardiac mr segmen- tation challenge. Medical Image Analysis , 81:102528, 2022. 5 , 1 Exploiting Completeness P er ception with Diffusion T ransf ormer f or Unified 3D MRI Synthesis Supplementary Material A. Datasets The details of the brain and cardiac MRI datasets used in our e xperiment are summarized in T able 8 . Notably , we train our CoPeV AE and MDiT3D models on the brain MRI synthesis task on BraTS and IXI datasets separately , due to differences in the number and types of modalities. The ev aluation and results are also reported for the two datasets separately . F or Cardiac MRI synthesis, we le verage a com- bination of all four datasets to train both two-stage models. T able 8. Details of brain and cardiac MRI datasets. Datasets Modality Cases T rain T est Brain MRI BraTS [ 3 ] T1, T1ce, T2, FLAIR 1251 1000 251 IXI [ 5 ] T1, T2, PD 577 462 115 Car diac MRI UKBB [ 35 ] - 31350 25080 6270 MESA [ 57 ] - 298 238 60 A CDC [ 4 ] - 300 240 60 MSCMR [ 59 ] - 300 240 60 Combined - 32248 25798 6450 B. More Implementation Details B.1. Data Prepr ocessing Brain MRI data. Following [ 24 , 29 ], we use 90 and 80 middle axial slices for BraTS and IXI datasets, respecti vely . These slices are further cropped to a size of 192 × 192 from the central region. Ultimately , all volumes are resized to a fixed size of 192 × 192 × 64 to serve as model input. Cardiac MRI data. All slices within each cardiac MRI volume are used and cropped to 192 × 192 from the central region. Each volume is then resized to a fixed size of 192 × 192 × 32 for training and inference. For all datasets, we apply intensity normalization by lin- early scaling voxel intensities between the 0.5th and 99.5th percentiles to the range [0 , 1] . The data augmentations we employ include random spatial cropping, rotation, flipping, scaling, and shifting. B.2. Ar chitecture of Prompt Encoders and Projec- tion Heads W e de vise three light weight prompt encoders to generate completeness-aware prompt tokens in our CoPeV AE, fol- lowed by three projection heads for each pretext task. The T able 9. Detailed architecture of each prompt encoder and projec- tion head in the pretext task. Prompt Encoder F 1 F 2 F 3 Architecture 3D Con v (in 8, out 256) 3D BatchNorm ReLU 3D Con v (in 256, out 512) 3D BatchNorm ReLU 3D Adaptiv e A vg Pool Linear (512, 1024) ReLU Linear (1024, 512) 3D Con v (in 8, out 256) 3D BatchNorm ReLU 3D Con v (in 256, out 512) 3D BatchNorm ReLU 3D Adaptiv e A vg Pool Linear (512, 1024) ReLU Linear (1024, 512) 3D Con v (in 8, out 256) 3D BatchNorm ReLU 3D Con v (in 256, out 512) 3D BatchNorm ReLU 3D Adaptiv e A vg Pool Linear (512, 1024) ReLU Linear (1024, 512) Projection Head H 1 H 2 H 3 Architecture SiLU Linear (512, m − 1 ) SiLU Linear (512, m ) SiLU Linear (512, 128) detailed architecture of each prompt encoder and projection head is illustrated in T able 9 . Notably , in our framework, binary mask codes are only used in the pretraining of CoPeV AE, where we synthetically remov e modalities/slices and supervise the pretext tasks with kno wn missing patterns. Once CoPeV AE is trained, we freeze its parameters and use it as a completeness-aw are tokenizer: given any incomplete MRI with an arbitrary missing pattern, CoPeV AE directly infers the correspond- ing completeness prompts p = p d ∥ p p ∥ p s from the ob- served data, without requiring explicit mask codes as input. During both diffusion model training and inference, the dif- fusion backbone receiv es only the latent representations and these learned prompts. The original binary masks that were used to generate synthetic missingness are not provided to the diffusion model. In this sense, our synthesis process is mask-free: CoPeDiT no longer depends on hand-crafted or externally supplied mask codes at the generation stage, but instead relies entirely on the learned completeness prompts produced by the frozen CoPeV AE. B.3. Hyperparameter Setups CoPeV AE. The detailed hyperparameter setup of CoPeV AE is provided in T able 10 . Built upon VQV AE [ 47 ] and VQ- GAN [ 10 ], our model employs a codebook containing 8192 codes with the latent dimensionality of 8. The values of τ and λ are empirically set, as they hav e only a slight im- pact on model performance. The Adam optimizer is applied with a warmup cosine learning rate schedule. The training steps of CoPeV AE-B and CoPeV AE-C are 400k and 100k, T able 10. Hyperparameter setup of CoPeV AE. CoPeV AE-B CoPeV AE-C Architectur e Input dim. m × 192 × 192 × 64 192 × 192 × 32 Num. codebook 8192 8192 Latent dim. 8 8 Channels (256, 384, 512) (32, 64, 128) Compression ratio (8, 8, 8) (8, 8, 8) Prompt dim. 512 512 τ 0.2 0.2 λ 0.01 0.01 Optimization Batch size 8 64 Learning rate 1e-4 1e-4 Optimizer Adam Adam ( β 1 , β 2 ) (0.9, 0.999) (0.9, 0.999) LR schedule W armup cosine W armup cosine T raining steps 400k 200k T able 11. Hyperparameter setup of MDiT3D. MDiT3D-B MDiT3D-C Architectur e Input dim. m × 8 × 24 × 24 × 8 4 × 8 × 24 × 24 Hidden dim. 768 576 Num. blocks 16 12 Num. heads 12 12 Patch size 2 1 Params (M) 173.3 33.0 Flops (G) 555.1 (BraTS) 424.5 (IXI) 104.0 Optimization Batch size 32 64 Learning rate 5e-5 5e-5 Optimizer AdamW AdamW ( β 1 , β 2 ) (0.9, 0.999) (0.9, 0.999) LR schedule W armup cosine W armup cosine T raining steps 100k 100k EMA decay 0.9999 0.9999 Interpolants T raining objectiv e x-prediction x-prediction Noise schedule scaled-linear scaled-linear T imesteps 500 500 Sampler DDIM DDIM Sampling steps 200 250 respectiv ely . MDiT3D. For MDiT3D, we carefully design the hyperpa- rameters to balance dataset size and model capacity , as sum- marized in T able 11 . Following DiT [ 34 ], we report the experimental results using the exponential moving average (EMA) with a decay rate of 0.9999. During training, we set the timestep to 500 with linearly scaled noise levels rang- ing from 0.0015 to 0.0195. MDiT3D is trained for 100k T able 12. Experimental results of tumor segmentation experiments on BraTS dataset. Dice Score (%) ↑ WT TC ET A VG Missing 86.08 84.67 81.59 84.11 GAN-based Methods MMGAN [ 43 ] 89.35 88.14 87.73 88.41 MMT [ 24 ] 90.43 88.37 86.92 88.57 Hyper-GAE [ 53 ] 88.72 86.54 85.37 86.88 Diffusion Model-based Methods LDM [ 39 ] 87.86 85.91 84.19 85.99 ControlNet [ 58 ] 88.27 87.05 85.23 86.85 M2DN [ 29 ] 91.28 90.09 88.20 89.86 CoPeDiT 91.35 90.41 88.94 90.23 iterations using the AdamW optimizer and a warmup co- sine learning rate schedule. During inference, the DDIM sampler is applied with sample steps of 200 and 250 for MDiT3D-B and MDiT3D-C, respectiv ely . In addition, we use mixed-precision training with a gra- dient clipping to accelerate training and sav e computational resources throughout all two-stage experiments. C. Additional Experimental Results C.1. Qualitative Results Fig. 9 provides the qualitativ e e v aluation results of brain MRI synthesis on the IXI dataset. As shown, we can also observe that our CoPeDiT outperforms other baselines in preserving the intricate structures and texture information in the synthesized MRIs. C.2. T umor Segmentation In this section, we e v aluate the clinical utility of our syn- thesized MRIs through downstream tumor segmentation experiments on the BraTS dataset. Specifically , follow- ing [ 24 , 29 ], we train a multi-modal U-Net [ 40 ] on the four MRI modalities, where one modality is withheld and re- placed by the synthesized image generated by our CoPeDiT or competing baselines. Additionally , we implement a U- Net that takes only the three av ailable modalities as input for comparison. W e report the a verage Dice scores for whole tumor (WT), tumor core (TC), and enhancing tumor (ET), as summarized in T able 12 . As shown, all methods impro ve the segmentation accuracy over the ’Missing’ baseline that only uses the three av ailable modalities, confirming the ben- efit of reco v ering the missing contrast. Among them, CoPe- DiT achie ves the best performance on all three tumor subre- gions, leading to the highest average Dice of 90.23%. These results demonstrate that our synthesized MRIs are not only Figure 9. Qualitativ e results of comparison on IXI dataset. The results are depicted in the axial (top), sagittal (middle) and coronal (bottom) views of the 3D MRI v olume. 0 0.25 0.50 0.75 1.00 Cor ruption rate 24 25 26 27 28 29 PSNR (a) PSNR p d p p p s All 0 0.25 0.50 0.75 1.00 Cor ruption rate 0.815 0.820 0.825 0.830 0.835 0.840 0.845 SSIM (b) S SIM p d p p p s All 0 0.25 0.50 0.75 1.00 Cor ruption rate 12 14 16 18 20 22 24 26 28 30 FID (c) FID p d p p p s All Figure 10. Sensitivity of CoPeDiT to prompt corruption on BraTS dataset. T able 13. Ablation study on the contribution of completeness per- ception prompt tokens on the IXI dataset. IXI 1 2 PSNR ↑ SSIM ↑ FID ↓ PSNR ↑ SSIM ↑ FID ↓ w/o p d 23.56 0.720 35.93 23.04 0.708 48.71 w/o p p 22.81 0.697 50.70 21.99 0.692 63.16 w/o p s 24.17 0.724 31.89 23.56 0.710 39.87 w/o Prompts 22.48 0.696 57.64 21.67 0.683 81.49 w/ Mask Codes 23.35 0.711 44.03 22.84 0.702 56.72 CoPeDiT 24.34 0.732 25.84 23.92 0.721 32.53 visually plausible but also provide more informativ e inputs for downstream clinical tasks such as tumor se gmentation. C.3. Prompt Accuracy Sensiti vity T o assess ho w sensitiv e CoPeDiT is to the correctness of completeness prompts, we conduct a controlled prompt cor- ruption study on the BraTS dataset under the number of T able 14. Quantitativ e results on the IXI dataset by incorporating our completeness perception prompt tokens into baseline methods instead of mask codes. IXI PSNR ↑ SSIM ↑ FID ↓ MMT [ 24 ] 22.64 0.698 53.60 + Prompts (ours) 23.19 (+0.55) 0.707 (+0.009) 46.13 (–7.47) Hyper-GAE [ 53 ] 22.12 0.682 72.62 + Prompts (ours) 22.46 (+0.34) 0.694 (+0.012) 59.43 (–13.19) M2DN [ 29 ] 23.47 0.715 42.52 + Prompts (ours) 23.84 (+0.37) 0.726 (+0.011) 33.79 (–8.73) missing modalities of 1. Starting from a trained CoPe- DiT and CoPeV AE, we consider the degree prompt p d (number/length of missing content), the position prompt p p (location of missing regions), and the semantic prompt p s . For each prompt type, we define a corruption rate r ∈ { 0 , 0 . 25 , 0 . 5 , 0 . 75 , 1 . 0 } . Gi ven a rate r , we randomly select an r -fraction of validation samples and replace the corresponding prompt with an incorrect one (sampled from other cases), while keeping all netw ork weights and the other prompts unchanged. W e also include an ’All’ setting where all three prompts are corrupted simultaneously . As illustrated in Fig. 10 , increasing the corruption rate con- sistently degrades synthesis quality in terms of all three metrics. This demonstrates that CoPeDiT relies on the ac- curacy of completeness prompts. Among the three types, corrupting the position prompt p p causes the largest syn- thesis performance drop, emphasizing that precise localiza- tion of missing regions is particularly critical. Corrupting the degree prompt p d also noticeably harms performance, whereas the semantic prompt p s is some what more robust but still sho ws a clear degradation trend. When all prompts are corrupted, performance deteriorates the most across all metrics, confirming that the three prompts provide comple- mentary and influential guidance for high-fidelity synthesis. C.4. Ablation Study W e further e v aluate the effecti veness of our prompt tok en design on the IXI dataset. As shown in T able 13 , the com- plete set of prompt tok ens yields the best performance, out- performing both con ventional mask codes and all individ- ual prompt tok ens. Furthermore, we apply our learned prompt tokens to other baseline models originally using mask codes. As illustrated in T able 14 , our prompts also lead to consistent performance gains across all baselines. In summary , the effecti veness of our prompt learning scheme is v alidated on the IXI dataset through the additional e v alu- ations presented abov e.
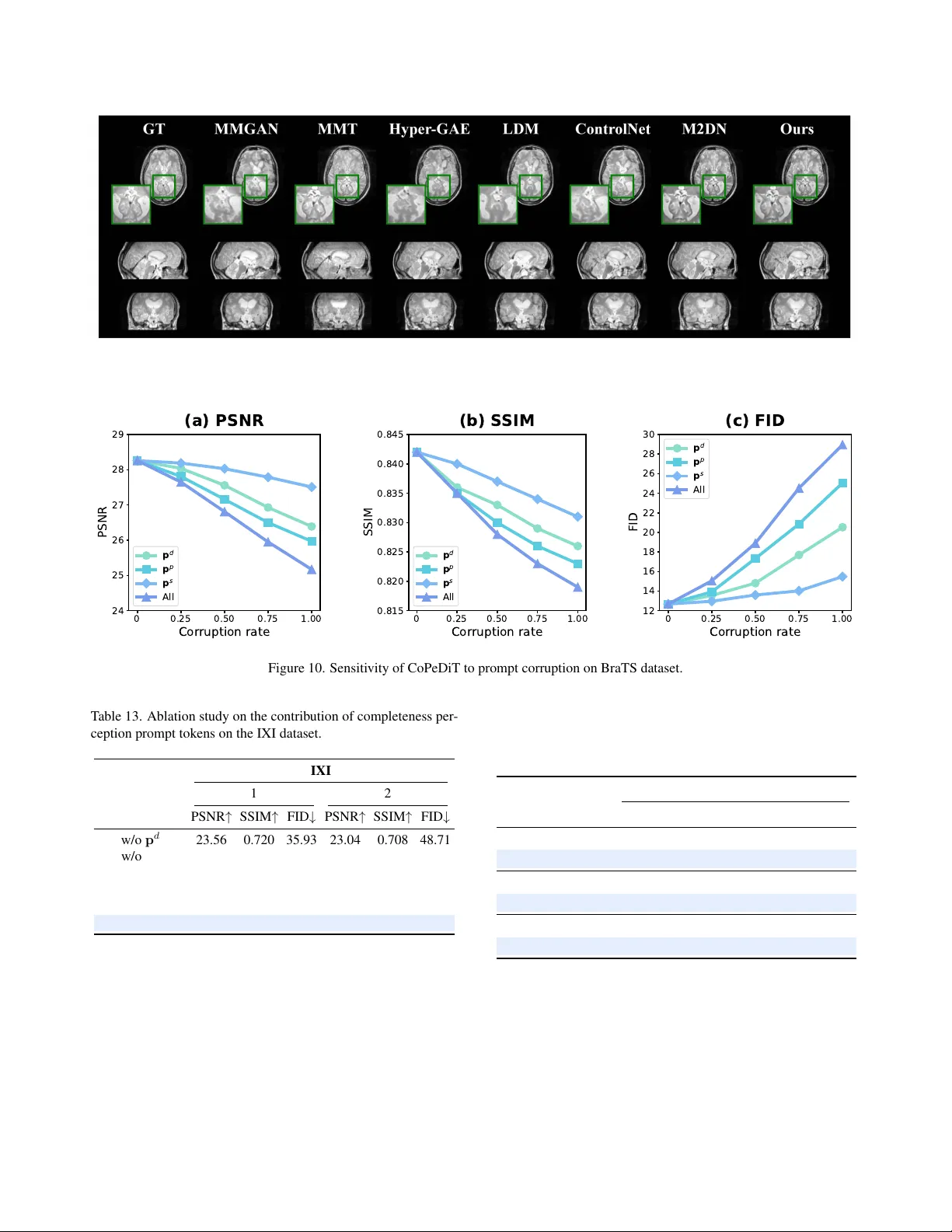
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment