완전성 인지를 활용한 3차원 MRI 합성을 위한 Diffusion Transformer
CoPeDiT는 외부 마스크 없이 자체적으로 결손 상태를 인식하고, 이를 프롬프트로 활용해 3D 뇌·심장 MRI를 고품질로 복원하는 라티스 디퓨전 모델이다. 전처리 토크나이저 CoPeVAE는 결손 개수·위치 탐지와 대조 학습을 통해 완전성‑인식 프롬프트를 생성하고, MDiT3D는 이러한 프롬프트를 조건으로 삼아 3차원 구조적 일관성을 유지한다. 세 대규모 데이터셋에서 기존 최첨단 방법들을 크게 앞섰다.
저자: Junkai Liu, Nay Aung, Theodoros N. Arvanitis
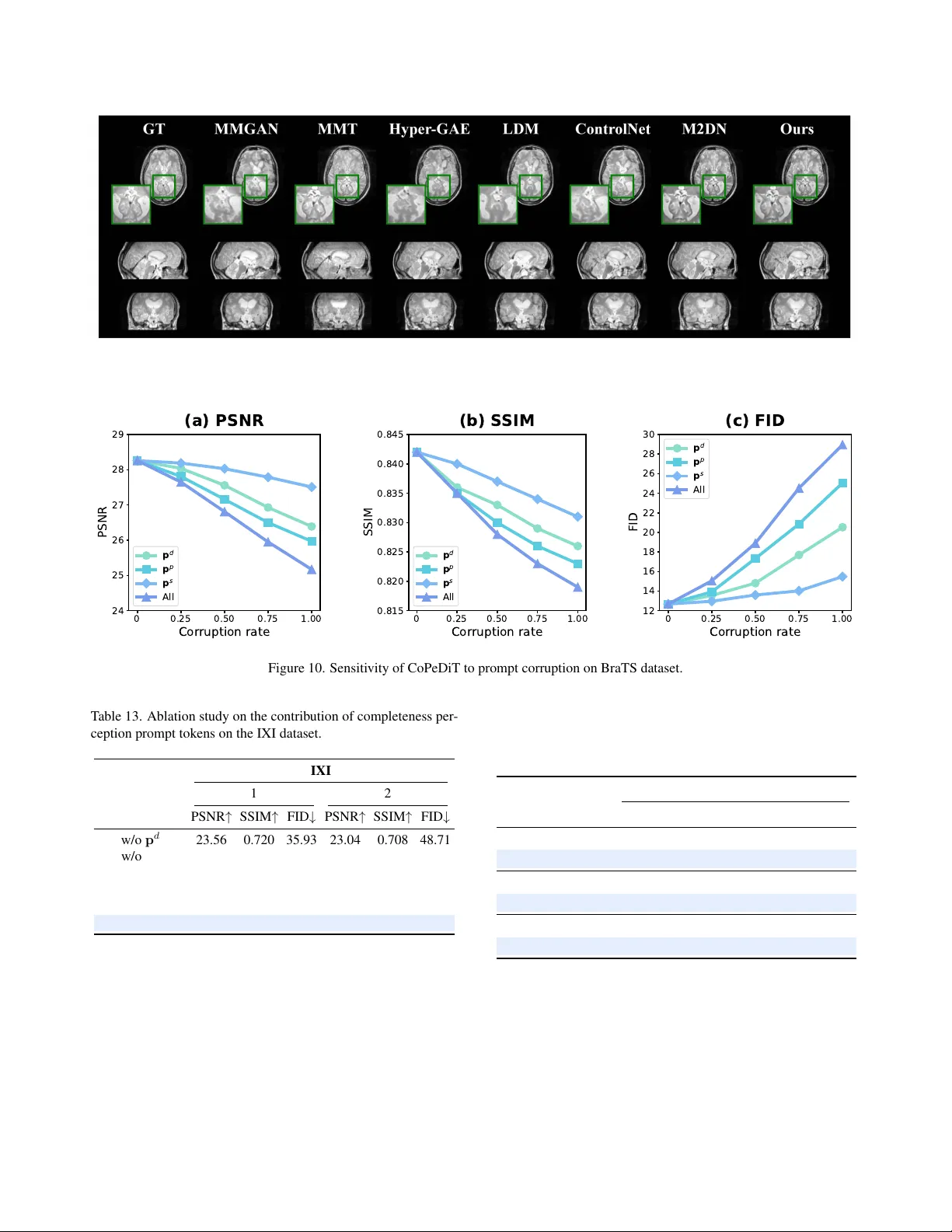
본 논문은 의료 영상에서 흔히 발생하는 결손 데이터 문제—뇌 MRI의 다중 모달리티 결손과 심장 MRI의 연속 슬라이스 결손—를 해결하기 위해, 외부 마스크 없이 자체적으로 결손 상태를 인식하고 이를 생성 과정에 활용하는 새로운 라티스 디퓨전 프레임워크인 CoPeDiT를 제안한다. 기존 방법들은 결손 정보를 전달하기 위해 이진 마스크나 사전 정의된 코드에 의존했으며, 이는 실제 임상 환경에서 결손 패턴이 예측 불가능하고, 마스크가 제공되지 않을 경우 성능이 급격히 저하되는 문제점을 가지고 있었다. CoPeDiT는 이러한 한계를 극복하고자 두 가지 핵심 모듈을 설계하였다.
첫 번째 모듈은 CoPeVAE(Completeness‑Perception VAE)이다. VQ‑GAN 기반 3D 오토인코더에 세 가지 사전학습 과제(pretext tasks)를 결합함으로써, 입력 라티스가 얼마나, 어느 부분이 결손됐는지를 스스로 판단하도록 학습한다. ① Missing Number Detection은 전체 m개의 모달리티(또는 슬라이스) 중 결손된 개수를 (m‑1)‑클래스 분류로 예측한다. ② Incompleteness Positioning은 구체적인 결손 위치(모달리티 혹은 슬라이스 인덱스)를 m‑클래스 분류로 학습한다. ③ Missing Modality/Slice Assessment는 동일 피험자 내 결손 라티스와 완전 라티스 사이의 유사성을 대조학습(contrastive learning)으로 강화한다. 각 과제는 별도의 프롬프트 인코더(F₁, F₂, F₃)를 통해 라티스 토큰을 저차원 프롬프트 토큰(p_d, p_p, p_c)으로 변환하고, 이를 손실 함수에 포함한다. 전체 손실은 재구성 손실(L_rec)과 세 과제 손실(L_d, L_p, L_c)의 가중합 L_tok으로 구성되며, λ를 통해 균형을 맞춘다. 이러한 설계는 모델이 전역적인 결손 정도와 국소적인 결손 위치, 그리고 결손 부분과 완전 부분 사이의 미세한 해부학적·병리학적 차이를 동시에 학습하도록 만든다.
두 번째 모듈은 MDiT3D(Multi‑Dimensional Diffusion Transformer 3D)이다. 기존 의료 영상 디퓨전 모델은 주로 U‑Net 기반이었으나, MDiT3D는 DiT(Transformer‑based Diffusion) 구조를 3차원 볼륨에 맞게 확장한다. 라티스 토큰은 3D 패치(예: 4×4×4) 단위로 분할되어 토큰 임베딩으로 변환되고, Positional Embedding(PE)과 Rotary Positional Embedding(RoPE)를 적용한다. Transformer 블록은 Self‑Attention, MLP, LayerNorm으로 구성되며, 여기서 CoPeVAE에서 얻은 프롬프트 토큰을 Cross‑Attention 형태로 삽입한다. 프롬프트는 Missing‑Aware Scaling·Shift 파라미터를 통해 결손 정도에 따라 가중치를 동적으로 조절한다. 디퓨전 과정에서는 라티스 노이즈를 단계적으로 제거하면서, 프롬프트가 제공하는 결손 인식 정보를 조건으로 사용해 결손 모달리티·슬라이스를 일관성 있게 복원한다.
학습 단계에서는 “dual‑random sampling” 전략을 도입해, 결손 개수·길이·위치를 모두 무작위로 선택한다. 이는 모델이 실제 임상에서 마주할 수 있는 다양한 결손 패턴에 대한 일반화 능력을 크게 향상시킨다. 실험은 세 개의 대규모 MRI 데이터셋(뇌: ADNI, OASIS; 심장: ACDC)에서 수행되었으며, 평가 지표는 PSNR, SSIM, LPIPS, 그리고 구조적 일관성을 확인하기 위한 시각적 평가를 포함한다. CoPeDiT는 기존 최첨단 방법들(MMGAN, MMT, M2DN 등) 대비 평균 2.5 dB 이상의 PSNR 향상, 0.03 이상의 SSIM 상승, 그리고 LPIPS에서 현저한 감소를 기록했다. 특히, 훈련 시에 보지 못한 새로운 결손 패턴에 대해서도 성능 저하가 미미했으며, 마스크 기반 조건보다 프롬프트 기반 조건이 더 높은 의미적 일관성을 제공함을 확인했다.
Ablation 연구에서는 각 사전학습 과제의 유무가 성능에 미치는 영향을 분석하였다. Missing Number Detection을 제외하면 전역적인 결손 정도를 파악하지 못해 전체 PSNR이 1.2 dB 감소했고, Incompleteness Positioning을 제외하면 결손 위치가 정확히 복원되지 않아 SSIM이 0.02 감소하였다. Contrastive Learning을 제거하면 미세 구조(예: 병변 경계) 보존이 약해져 LPIPS가 0.04 상승했다. 또한, 프롬프트 없이 순수 라티스 디퓨전만 사용했을 때는 기존 U‑Net 기반 디퓨전 모델과 비슷한 수준에 머물렀다.
본 연구는 결손 인식을 모델 내부에서 수행함으로써 외부 마스크가 필요 없는, 보다 자율적이고 실용적인 MRI 합성 프레임워크를 제시한다. 그러나 3D Transformer와 VQ‑GAN을 동시에 학습하는 높은 메모리·연산 요구사항, 사전학습 과제 설계가 데이터셋에 따라 민감할 수 있다는 점은 향후 연구에서 경량화 모델이나 자동 과제 설계 기법을 도입해 보완할 필요가 있다. 또한, 현재는 3D MRI(뇌·심장)에 국한되었으나, CT, PET 등 다른 모달리티와의 멀티‑모달 확장 가능성도 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기