p-Hacking Inflates Type I Error Rates in the Error Statistical Approach but not in the Formal Inference Approach
p-hacking occurs when researchers conduct multiple significance tests (e.g., p1;H0,1 and p2;H0,2) and then selectively report tests that yield desirable (usually significant) results (e.g., p2 < 0.05;H0,2) without correcting for multiple testing (e.g…
Authors: Mark Rubin
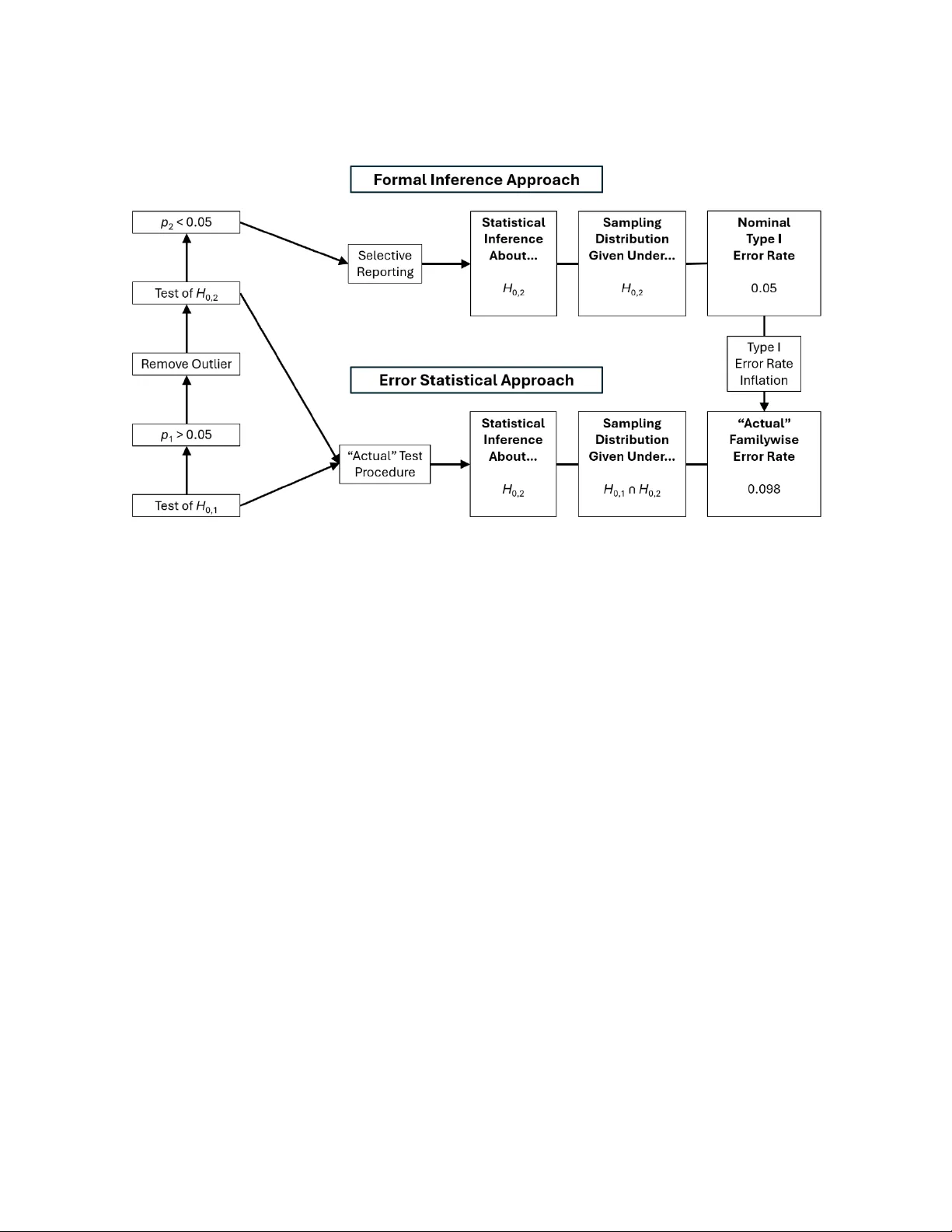
p -Hacking in the Formal Inference Approach 1 p -Hacking Infla tes Type I Error Rate s in the Error Statistical Appro ach But Not in the Formal Inference App roach Mark Rubin Durham University, UK February 23 , 20 26 Citation : Rubin , M. (2026 , Februar y 23 ). p -hacking inflates T ype I erro r rates in the error statistical ap proach but n ot in the formal in ference approach . PsyArXiv . https://doi.o rg/10.31234/osf. io/qr685_v2 Abstract p -hacking occurs when researchers conduct multiple significance tests (e.g., p 1 ; H 0,1 and p 2 ; H 0, 2 ) a nd then selectively report tests that yield desirable (usually significant) results (e.g., p 2 ≤ 0.05; H 0, 2 ) without correcting for multiple testing (e.g., 0.05 /2 = 0.025). In the present article, I consider p -hacking in the context of two philosophies of significa nce testing — the error statistical a pproach and the formal inference a pproach. I argue that a lthough p -hacking inflates Type I e rror rates in the error statistical approach, it does not in flate them in the formal inference approach. Specifically, in the err or statistical approach, the “actual” familywise error rate (e.g., 1 − [ 1 − 0.05] 2 = 0.098 for two tests) is re levant because it covers both the selectively reported and unreported tests in the “actual” test proced ure (i.e., p 1 ; H 0,1 and p 2 ; H 0, 2 ). In this approach, Type I error rate i nflation occurs b ecause the “actual” error rate (0.098) is higher tha n the nomi nal error rate (0.05). In contrast , in the formal inference approach, the “ actual” familywise error ra te is irrelevant because (a) the researcher does not report a st atistical infere nce about the corresponding intersection null hypothesis (i.e., H 0,1 ∩ H 0, 2 ), and (b) the “actual” f amilywise error rate does not license inferences about th e reported individual hypo these s (i.e., H 0, 2 ). Instead, in the formal inference approach , only the nominal error rate is relevant, and a comparison with the “actual” error rate is inappropriate. Implications for conceptualizing, demonstrating, and reducing p -hacking are discussed. Keywords : erro r statistics; familywise er ror rate; null results; p -hac king ; questionable r esearch practices; T exas sharpshooter fallacy p -Hacking in the Formal Inference Approach 2 p -hacking occ urs when researchers condu ct multiple significance tests and then selective ly report tests that yield desired, usually significant, results without correcting for multiple testing. Hence, p -hacking represents a type of undisclosed cherry-picking or fishing for specific (significant) results. Although p -hacking is often described as a “questionable research practice ” (John et al., 2012; e.g., Nagy et al., 2025; Reis & Friese, 2022), it is widely regarded as being statistically and ethically problematic (e.g., Miller et al., 2025 ; Pickett & Roche, 2018 ; Simmons et al., 2011 ; Stefan & Schönbrodt, 2023). It is also believed to be a major contributor to the replication crisis (e.g., Bishop, 2019 ; Nagy et al., 2025). In pa rticular, p - hacking is thought to inflate Type I error rates above their nominal conventional level, resulting in a larger proportion of false positive results in the literature than would otherwise be expected (e.g., Lake ns, 2019, p. 221; Na gy et al., 2025; R eis & Friese, 2022 ; Simmons et al., 2011; Stefan & Schönbrodt, 2023; Wicherts et al., 2016, p. 1 ). This disproportionate number of false positives is then thought to cause unexpectedly low replication rates. In the present article, I aim to add some nuance to this view by distingu ishing be tween two philosophies of significance testing — the error statisti cal approach (Mayo, 1996, 2018) and the formal inference approach (Rubin, 2021b, 2024a, 2024b). I argue that, although p -hacking inflat es Type I error rates in the error statistical approach, it does not inflate them in the formal inference approach. The article proceeds as follows : Section 1 explai ns how p -hacking inflates Type I error rates in the error statistical approach. S ections 2 and 3 introduce the formal inference app roach and explain why p -hacking does not inflate Type I err or ra tes in th is approach. Section 4 considers some key areas of agreement and disagr eement between the two approaches. Section 5 considers the error statistical appro ach ’ s minimal severity requirement and argu es that it is not necessary to obtain valid Type I error rates in the formal inference approach. Section 6 considers the nondisclosure of null results during p -hacking and argues that, although this practice does not inflate Type I error rates in the formal inference approach, it may bias substantive infere nces under certain conditions. Finally, Section 7 summarizes the conclusions a nd discusses the ir implications for conceptualizing, de monstrating, and re ducing p -hacking a nd for understanding and addre ssing the replication crisis. 1. p -Hacking Inflate s Type I Error Rate s in the Error S tatistical Approach Type I Error Rate s in the Error Statist ical Appr oach A Type I e rror rate represents the maximum fre quency with whi ch a significance tester would incorrectly reject a null hypothesis based o n random s ampling error (Neyman & Pearson, 1928, pp. 176 – 177, 231 – 232). Specifically, a Type I error occurs when r andom sampling error leads the significance teste r to dec ide that an observed sample was not drawn from a null population when, in fact, it was. In the Neyman -Pearson approach, a Type I error “ rate ” refers to this decision-making performance across a hypothetical long run of repeated random sampling from a specified null population (Neyman & Pearson, 1928, p. 177). Without denying th is Neyman-Pearson long-run “performance” ra tionale, error statisticians adopt a “probativ e ” approach in which they consider the error-probing cap acity of a test procedure in the case at hand (Mayo, 2018, pp. 13 – 14, 162; Mayo & Spanos, 2006, p. 351; Mayo & Spanos, 2011, pp. 162 – 163). Here, a Type I error rate is used to “ license ” specific inferences bas ed on the application of a particular test. As Mayo and Spa nos (2006) explained, p -Hacking in the Formal Inference Approach 3 “pre -data, the choices for the type I and II errors reflect the goal of ensuring the test is capable of licensing given inferences severe ly” (p. 350; see also Mayo & Spanos, 2011, p. 167). For ex ample, a test with a nominal Type I error rate of 0.05 ( α ) is capable of licensing specific statistical inferences with a minimum “worst case” severity of 0.95 (i.e., 1 – α ), assuming adequa te statistical assumptions (Mayo, 1996, pp. 124, 304, 399, 407; Mayo, 2008, pp. 863 – 864; Mayo, 2018, p. 94 ; Spanos & Mayo, 2015, p. 3535 ). The Problem w ith p -Hacking As Mayo and Spanos (2 011, p. 166) explained, a key requirement in the error statistical approach is that the probability of observing a significant p -value should be ≤ α when all null hypotheses are true (i.e., Pr [observing a p - value ≤ α ] ≤ α ). The problem with p -hacking is that th is probability becomes greater than α when multiple undisclosed significance tests are performed in the experimental testing context. Hence , when p -hacking occurs, th e probability of making at least one Type I error becomes greater than α . Consequently, a test procedure that includes p -hacking will have an “actual” Type I error rate that is highe r than t he nominal “computed” error rate of α ( Mayo, 1996, pp. 303 – 304, 348 ; Mayo, 2008, pp. 874 – 875; Mayo, 2018, pp. 274 – 275; Mayo & Cox, 2010, pp. 267 – 270). I t is this discrepancy betw een “a ctual” and nominal error rates that is con ceptualized as Type I error r ate “inflation” (Mayo, 2025, p. 1 ). To illustrate, imagine that a researcher conducts significance tests on 20 hypotheses H 0, 1 , H 0,2 , H 0,3 , … H 20 , yielding 20 corresponding p -values p 1 , p 2 , p 3 , … p 20 . They then search for results that are significant at the conventional level of 0.05. They find that only p 13 ; H 0,13 is significant, and so they selectively report th at particular result. 1 In this situation, the “ actual ” test pro cedure inclu des searching for significance among 20 tests and then selectively reporting significant r esults (Mayo, 1996, p. 304). Consequently, t he “ actual ” Type I error rate is the familywise error rate for those 20 tests (Mayo, 2018, p. 275). Th e upper bound of the familywise err or rate can be computed using the formula 1 − (1 − α) k , where k is the number of significance tests. Henc e, the “actual” error rate is 0.642 (i.e., 1 – [1 − 0.05] 20 ) . In contrast, the nominal error rate fo r the reported inference about H 0,13 is 0.05. Hence, the “actual” error rate is inflated above the nomi nal error rate, and the nominal error rate is “invalidated” or “vitiated” because it do es not match the “actual” error rate (i.e., Pr [observing a p - value ≤ α ] > α ; Mayo, 2008, p. 876; Mayo, 2018, pp. 234, 285, 438; Mayo & Spanos, 2011, p. 190). To address th is potential problem, error statisti cians recommend that we check or “audit” the experimental testing context for any “ bi asing selection effects, ” such as p -hacking (e.g., by cross-referencing with a preregistered analysis plan ; Mayo, 2018, pp . 92, 1 06 – 107, 275, 439). The “ minimal severity requirement ” is that we attempt to rule out ways in which a claim may be false (Mayo, 2018, p. 5 ). Biasing selection effects occur when hypoth eses and data are generated and selected in ways that violate, secretly alter, or p revent an ass essment of this requirement (Mayo, 2018, pp. 92, 269). Hence, p -hacking represents a biasing selection effe ct because its hidden multiple testing secretly inflates the “actual” Typ e I error rate and preven ts us from effectively ruling out ra ndom sampling e rror. Consequently, we are le ft with “ ba d evidence, no test (BENT) ” (Mayo, 2018, p. 5). p -Hacking in the Formal Inference Approach 4 2. The Formal Inference A pproach Th e error statistical approach can be contrasted w ith what I call here the formal inference approach (Rubin, 2021a , 2021b, 2024a, 2024b, 2025). I n this approa ch, re levant Type I error rates as based on formally reported (publicly specified ) statis tical inferences rather than “ actual ” test procedures, which may be only partially reported. 2 In particular, the contents of a formally reported inference a re used to determine (a) the category of statistical inference, (b) the number of significance tests associated with the inference, a nd (c) the specified alpha level for each test (or the conventional alpha level if none is specified). This information is then used to compute the relevant Type I error rate for the inference (e.g., Rubin, 2024b, p. 52). Categories of St atistical I nferences In the formal inf erence approach, a statis tical inference consists of (a) a provisional decision to either reject or fail to reject a formally specified statistical null hypothesis and (b) the result of one or more significance tests that indicate conditional uncertainty about this de cision (Fisher, 1956, pp. 57, 108 – 110; Rubin, 2024b, p. 49). Three categories of statisti cal inference are distinguished : individual , union-intersection , and intersection-union (Berger, 1982; García-Pérez, 2023 ; Hochberg & Tamhane, 1987; Parker & Weir, 2020; Roy, 1953 ; Rubin, 2021b, 2024a , 2024b). (1) Individual Inference If a researcher makes a decision about an individual alternative hypothesis (e.g., H 1,1 ) and corresponding individual null hypothesis (e.g., H 0,1 ) using a nominal alpha level of α, then the Type I error rate for that decision is α , even if the researcher makes multiple such decisions (reported or unrepo rted) within the same stud y. I n this case, the individual null hypothesis ca n only be rej ected following a significant result on one particular test (i.e., p 1 ≤ α ; H 0,1 ). Hence, there is only a single opportunity to make a Type I e rror with regard to that p articular individual null hypothesis (see also García-Pérez, 2023, p. 15; Par ker & Weir, 2020, pp. 563 – 564; Rubin, 2017a, pp. 271 – 272; Rubin, 2020, p. 380; Rubin, 2021a; Rubin, 2021b, pp. 10978 – 10983; Rubin, 2024a , p. 3; Rubin, 2024b, p. 51 ). (2) Union-Intersection Inference If a researcher makes a decision about a union alternative hypothesis (e.g., H 1,1 ∪ H 1,2 ∪ H 1,3 ∪ … H 1, k ) and corresponding intersection null hypothesis ( H 0,1 ∩ H 0,2 ∩ H 0,3 ∩ … H 0, k ), then the Type I error rate for that decision is the familywise error rate o f 1 − (1 − α) k . In thi s c ase, the intersection null hypothesis can be rejected following at least one significant result (i.e., p min ≤ α) among any of the k tests ( p 1 ; H 0,1 , p 2 ; H 0,2 , p 3 ; H 0,3 , … p k ; H 0, k ; e.g., García -Pérez, 2023, p. 15; Hochberg & Tamhane, 1987, p. 28; Parker & Weir, 2020, p. 563; Roy, 1953 ; Rubin, 2021b, pp. 10973 – 10975; Rubin, 2024b, pp. 51 – 52 ). Hence, there are multiple ( k ) opportunities to make a Type I error with regard to the intersection null hypothesis . Consequently, the familywise error rate for a decision about the intersection null hypothesis ( α Intersection ) is higher than th e nominal error rate for tests of each of its constituent null hypotheses ( α Constituent ). To control α Intersection at a conventional level (e.g., 0.05), α Constituent must be adjusted below the conven tional level (e.g., using a Dunn –Šidák c orrection, α Constituent = 1 – [1 – α Intersectio n ] 1/ k , or a Bonferroni c orrection , α Constituent = α Intersection / k ). 3 p -Hacking in the Formal Inference Approach 5 (3) Intersection-Union Inference If a r esearcher makes a decision about an intersection alternative hypothesis (e.g., H 1,1 ∩ H 1,2 ∩ H 1,3 ∩ … H 1, k ) and corresponding union null hypothesis ( H 0,1 ∪ H 0,2 ∪ H 0,3 ∪ … H 0, k ), then the Type I e rror rate for that decision is the nominal α level. Here, the union null hypothesis can only be rejected following all significant results (i.e., p max ≤ α) on all k tests ( p 1 ; H 0,1 , p 2 ; H 0,2 , p 3 ; H 0,3 , … p k ; H 0, k ). As with individual inferences, no alpha adjustment is required in this case because the re searcher only has a singl e opportunity to erroneously reject the union null hypothesis (Berger, 1982, p. 295; Rubin, 2021b, p. 10976 ). Guiding Princ iples for Determinin g Type I Err or Rates The formal inference approach applies the following four guiding principles when determining relevant Type I error rates. (1) Type I Error Rates Refer to Random Sampling Error, not S ystematic Error A Type I error rate is represented by one or more critical regions in the tail areas of the specified sampling distribution of a test statistic given under a statistical null hypothesis (Neyman, 1950, p. 265). In particular, it represents a hypothetical, mathem atical, subjunctive conditional probability that assumes that all test assumptions have been met, there is n o systematic error, and the only remaining source of decision-making error is random sampling error, as represented in the sampling distribution (Cortina & Dunla p, 1997, pp. 166 – 167; Fisher, 1956, pp. 40, 44; F isher, 1959, pp. 21 – 22; Kass, 2 011, pp. 5 – 6, 7; Meehl, 1990, p. 111; Neyman, 1952, pp. 23, 57; Ne yman, 1955, p. 17; Neyman & Pearson, 1928, pp. 176 – 177, 232; Rubin, 2024b, pp. 47 – 48). A Type I error rate is onl y supposed to represent the probability of inco rrectly rejecting a null hypothesis due to random sampling error given a specified sampling distribution. It is not supposed to quantify the probability of incorrectly rejecting a null hypothesis due to systematic error (Meehl, 1997, pp. 397, 401 ; Neyman & Pearson, 1928, p. 176; P ollard & Richardson, 1987, p. 162; Rubin, 2024a, p. 3, Confusion IV ; Rubin, 2024b, p. 49 ). Systematic error can include ( a) theoretical error ( e.g., errors in theories, hypothes es, predi ctions, background knowledge , causal relations, constructs, etc .); (b) methodological error (e.g., errors in research design, sampling procedures, testing conditions, stimuli, manipulations, measures, controls, et c.); (c) data error (e.g., errors in data colle ction, entry, coding, cleani ng, aggregation, transformation, etc.); or (d) analytical error (e.g., errors in statisti cal assumptions such as normality, linearity, or independence). Of course, systematic error can ca use the subst antive misinterpretation of a significant true positive re sult. F or example, a theoretically uninteresting “crud” effect may be misinterpreted a s a theoretically-predicted effect (Meehl, 1997, p. 402). However, it is important not to conflate substantive interpretational error with statistical Type I error (Meehl, 1990, p. 125; Rubin, 2017a, p. 274; Rubin, 2024b , pp. 50 – 51 ). The former is a substantive misinterpretation of a true positive result caused by systemat ic error. The latter is a stat istical mi sclassification of a true negative (null) result caused by random error. (2) Type I Error Rates for Different Tests are Incommensurate with One Another A Type I error rate is a hypothetical probability that is contingent on a specified sampling distribution under a statistical null hypothesi s. It cannot be detached from its sampling distribution and treated as a standalone, unconditional probability that may become “ inflated, ” “altered,” p -Hacking in the Formal Inference Approach 6 “invalidated,” or “vitiated” when moving f rom one test to another (Cortin a & Dunlap, 1997 , pp. 166 – 167 ; Pollard & Richardson, 1987). For example, th e Type I error rate for one brand of pregnancy test may be lower than that for another brand, but it would be in appropriate to claim that the second test’s error rate is an “inflated” v ersion of the first test ’s error rate or th at the first test’s error rate is “ in validated ” in this context. Each error rate licenses a separ ate decision about a different statistical null hypothesis based on a different statistical model. In this res pect, Type I error rates for different t ests are independent and incommensurate with one anoth er (García-Pérez, 2023, p. 15; R ubin, 2024a, p. 3). (3) Familywise Error Rates do not License Individual Inferences The familywise error rate for the intersection null hypothesis H 0,1 ∩ H 0,2 only licenses a union-intersection inference about H 0,1 ∩ H 0,2 as a whole. Here, the constit uent null hypotheses H 0,1 and H 0,2 are treated as being logically exchangeable with one another rather than as dist inct individual hypotheses (García-Pérez, 2023, p. 2; Rubin, 2021b, pp. 10978 – 10982; Rubin, 2024a , p. 2). Consequently, during union-intersection testing, a significant result in relation to the constituent null hypothesis H 0,1 doe s not allow us to reject H 0,1 a s a n individual hypothesis. It only allows us to reject H 0,1 ∩ H 0,2 and conclude that either H 0,1 or H 0,2 or both are false. 4 The same prin ciple appli es in the case of a one-way ANOVA (G arcía-Pérez, 2023, p. 6). A significant omnibus result allows us to claim that there is a signi ficant difference b etween at least one pair of means, but it does not allow us to identify which pair (Rubin, 2024a, p. 2). Consequently, in the formal inference approach, a familywise error rate is not the probability of making “ at least one Type I error ” because this phrasing implies that the researcher is making multiple individual inferences (de cisions) about multiple indi vidual hypotheses, each licensed by its own nominal Type I error r ate (Ru bin, 2021 b, pp. 10978 – 10983 ; Rubin, 2024a, p. 3, Confusion III; Rubin, 2024b, p. 59 ). Instead, as it s name implies, the familywise error rate re presents the probability of making an err or about an entire family of hypot heses, not any spe cific individual hypothesis within that family. Hence, during union-intersection testing, the researcher only makes a singl e decision to either reject or fail to reject an intersection null hypothesis (e.g., H 0,1 ∩ H 0,2 ) on the basis of “ at least one ” signi ficant resul t among their constituent tests (e.g., p 1 ; H 0,1 and p 2 ; H 0, 2 ; see also García-Pérez, 2023, p. 5; Rubin, 2021b, p. 1 0982). The familywise error rate is then the probability of making a Type I error about this intersection null hypothesis rather than the probability of making at least one Type I error about m ultiple individual null hypotheses. (4) Type I Error Rates are Based on Formally Reported Inferences, n ot “Actual” Test Procedures If a researcher ’ s “ actual ” test procedure includes tests of H 0,1 and H 0, 2 , then it is possible for them to report statistical inferences a bout H 0,1 , H 0, 2 , H 0,1 ∩ H 0,2 , and/or H 0,1 ∪ H 0,2 . Nothing in the description of the test procedure (i.e., “ test s of H 0,1 and H 0, 2 ” ) indicates whi ch of these inferences will be reporte d. Of course , a researcher can privately intend and publicly plan to report one or more of these inf erences. However, intentions and plans can change and, when they do, inferences and their associated e rror rates may change with them. For ex ample, a res earcher may plan to make an inference about H 0,1 ∩ H 0,2 , whic h would re quire a n alpha adjustment to α Constituent in order to control α Intersec tion . However, they may then change their mind and decide to make two individual inferences instead, one a bout H 0,1 and one about H 0, 2 , neither of which require an alpha p -Hacking in the Formal Inference Approach 7 adjustment. Hence, f rom a fo rmal inference perspec tive, it is forma lly reported statistical inferences, rather than planned or “actual” test procedures, that determine relevant error rates. This formal inference approach is consistent with the view that Type I error rates are contingent on hypothetical sampling distributions based on formally specified hypotheses, rather than “actual” sampling d istributions based on “actual” test procedure s (e.g., Cortina & Dunlap, 1997, pp. 166 – 167; see also Fisher, 1956, p. 44 ). It is also consistent with Popper’s methodological rule that scientific hypotheses must be objective and “intersubjectively testable” so that, in principle, they can b e t ested by anyone (Popper, 1966, p. 218; Poppe r, 2002, p. 22). Unlike formally reported inferences, “ a ctual” test procedures fail Popper’s requirement be cause they may be only partially reported and, consequently, not intersubjectively knowable by others. 3. p -Hacking Do es No t Inflate Type I Error Rate s in the Forma l Inference Approa ch The Basic Argumen t To recap, the main claim is that p -hacking inflates Type I e rror rates in the error statistical approach but not in the fo rmal inference approach. Th e basic argument for this claim is as follows. In the error statistical approach, the “ actual ” f amilywise error rate is relevant during p - hacking because it covers both reported and unreported tests in the “actual” test procedure . I n this approach, Type I error r ate inflation occurs because the “actual” familywise error rate is higher than the nominal rate for the reported inference. In contrast, in the formal inference approach, the “ actual ” familywise error rate is ir releva nt because it only li censes an inference about an intersection null hypothesis (e.g., H 0,1 ∩ H 0, 2 ), and , in pra ctice, researchers who p -hack can not re port this infe rence because they do not disclose some of their tests ( e.g., p 1 > 0.05; H 0, 1 ). Instead, they usually report separa te individual infere nces a bout selectively repo rted individual null hypotheses ( e.g., p 2 ≤ 0.05; H 0, 2 ). 5 Logically, t he “actual” familywise error rate do es not license these individual inferences. R ather, they are lic ensed by the ir own separate nominal error rates. p -hacking does not inflate these nominal error rates becaus e inflation only occurs relative to the “actual” familywise error rate, an d a compar ison with th e “actual” error rate is in appropriate be cause it is incommensurate and inconsistent with the reporte d individual inferences. A n Illustration To illustrate, imagine the following ex ample of p -hacking: A researcher conducts a two - sided independent samples t test using a conventional alpha level of 0.05. They fail to find a significant result with regard to their first null hypothesis H 0,1 : t (326) = 1.88, p = 0.061. For that reason , they remove an outlier fr om their sample and conduct a second test. The sec ond test has a smaller degrees of freedom (325) than the first, and it is formally specified by a different test procedure (i.e., outl iers removed). H ence, it tests a different statistical null hypothesis, H 0, 2 . This time, the researcher finds a significant result, t (3 25) = 2.16 , p = 0.032, which they then report without disclosing the nonsignificant result from their first test. From an error statisti cal perspective, the r esearch er has conduct ed two significance tests ( p 1 ; H 0,1 and p 2 ; H 0, 2 ) and then selectively report ed whichever test(s) yield ed a signific ant result (Mayo, 1996, pp. 303 – 3 04, 348; Mayo, 2008, pp. 874 – 875; Mayo, 2018, pp. 274 – 275; Mayo & Cox, 2010, pp. 267 – 270). In this ca se, the “actual” sampling distribution is given under the “a ctual” test procedure’s “global” or “universal” intersection null hypothesis , H 0,1 ∩ H 0,2 (Mayo, 2008, p. p -Hacking in the Formal Inference Approach 8 875; Mayo, 2018, p. 276; Ma yo & Cox, 2010, p. 2 69). Consequently, the “actual” e rror rate is the familywise err or rate 0.098 (i.e., 1 − [1 − 0.05] 2 ), which is inflated above the nominal error rate of 0.05. In contrast , from a formal inference perspective, the relevant s ampling distribution is given under H 0, 2 , not H 0,1 ∩ H 0,2 , because the r esearcher only re port ed an individual inference about H 0, 2 , not a union-intersection i nference about H 0,1 ∩ H 0,2 . Consequently, the relevant test procedure is the formally reported procedure for H 0, 2 , in which any outl iers are removed, and the relevant Type I error rate is the nominal error rate (Rubin, 2020, p. 381; Rubin, 2021b, p. 10991; Rubin, 2025, p. 10). Importantly, from a formal inference perspective, it is not appropriate to compare the “actual” familywise error rate fo r a decision about H 0,1 ∩ H 0,2 with the nomi nal error rate for a decision about H 0, 2 and argue that the form er represents an “inflated” version of the latter. As discussed previously, th ese two error rates are i ncommensurate with one another because they refer to two separate decisions about two different statisti cal null hypotheses based on two different statistical models. Arguing that a test’s Type I error rate has been infla ted because another test has a larger error rate is like arguing that a person ’s height has been inflated because their friend is taller than them! I t is also logically inconsistent to use a familywise error rate to license an individual inference. Specifically, we would be making a fallacy of division or e cological fallacy in this case because we would be misapplying an aggregate-level union probability to an individual member of the aggregate (Selvin, 1958; Waller, 2018). In particular, the union probability of obtaining at least one significant result given H 0,1 ∩ H 0,2 (i.e., the fa milywise error rate) does not repre sent the individual probability of obtaining a significant result given H 0,2 alone (García-Pérez, 2023; Rubin, 2017a, pp. 271 – 272; Rubin, 2020, p. 380; Rubin, 2021a; Rubin, 2021b, pp. 10978 – 10983; Rubin, 2024a, p. 3; Rubin, 2024b, p. 51). The fa milywise error rate would only be relevant if H 0, 2 was treated a s a logically exchangeable constituent of H 0,1 ∩ H 0,2 , rather than as a distinct individual hypothesis. I n this case, the researcher would ma ke a union-intersection inference about H 0,1 ∩ H 0,2 as a whole, rather than an individual infere nce about H 0,2 alone, and thi s inference would be based on at least one significant result among p 1 ; H 0,1 and p 2 ; H 0, 2 (García-Pérez, 2023, p. 2; Rubin, 2021b, p. 10981; Rubin, 2024a, p. 2). In summary, from an err or s tatist ical perspective, (a) the “actual” test procedure includes two signific ance tests : p 1 ; H 0,1 a nd p 2 ; H 0, 2 ; (b) the “ actual” sampling distribution is given under the intersection null hypothesis H 0,1 ∩ H 0,2 ; and so (c) the “actual” Type I error rate is the familywise error rate of 0.098 (i.e., 1 − [1 − 0.05] 2 ), which is “inflated” relative to the nominal error rate of 0.05. In cont rast, from a formal inference perspective, (a) the formally reported inference is an individual inference about the individual null hypothesis H 0, 2 ; (b) the relevant sampling distribution for thi s inference is given under H 0, 2 ; and so (c) the relevant Type I err or r ate is p 2 ; H 0, 2 ’s nominal error rate of 0.05, which is incommensurate with the familywise error rate for a decision about H 0,1 ∩ H 0,2 . Figure 1 illustrates these diffe rences. 6 p -Hacking in the Formal Inference Approach 9 Figure 1 p-Hacking in the Formal Inference and Error Statistical Approaches A Closer Look It is worth taking a closer look at the situation in Figure 1 in order to unpack some of its complexities. Contrary to the formal inference approach, the error statistical approach argues that the “actual” familywise error rate is relevant because we need to consider all of the hypotheses that could have b een outputt ed by the “a ctual” test procedure (i.e., H 0,1 and H 0,2 ) “ in order to assess the well-testedne ss of the one hypothesis [that it ] … ha ppened to have outputted” ( i.e., H 0,2 ; Mayo, 2008, p. 876). As Mayo (2008) explained: The hypothetical e rror rates teach us about the test ’ s capacities in the case at hand. Because at least one such impressive departure is common even if all are due to chance, the ‘ hunting expedition ’ has scarcely r eassured us that it has done a good job of a voiding such a mi stake in this case. The .05 ‘ computed ’ p -va lue is invalidated when it comes to the ‘a ctual’ va lue . (p. 876, italics in original here and in all subsequent quotes) Again, howev er, from a formal inference perspective, this reasoning commits the fallacy of division because it confounds union and individual probabilities. I n the situation shown in Figure 1, the “actual” familywise err or rate (a union probability) only informs us about the capacity of the “ hunting expedition ” to avoid an er ror in re lation to the intersection null hypothesis H 0,1 ∩ H 0,2 . It does not inform us about an indi vidual test’s capacity to avoid an error in relation to the individual null hypothesis H 0,2 (a n individual probability), and it is H 0,2 that represents “the case at hand” in Figure 1, not H 0,1 ∩ H 0,2 . F rom this pe rspective, it is the individual test’s nominal e rror rate that indicates its error-probing capacity with respect to H 0,2 , and that capacity is not invalidated by the hunting expedition that was used to identify and selectively report the test. By analogy, i f 20 athletes are test ed for illicit drugs, then hunting for, finding, and selectively reporting a test that yields a positive result does not alte r th at test’s capacity to avoid an error in relation to the athlete who took the test (see also Rubin, 2024b, p. 55). 7 p -Hacking in the Formal Inference Approach 10 In theory, the researcher in Figure 1’s p -hacking example could report a union-intersection inference based on th e “actual” intersection null hypothesis H 0,1 ∩ H 0,2 . For example, given different results, they c ould report that “there wa s a signi ficant result whe n either in cluding outliers, ex cluding outliers, or in both cases, p min ≤ 0.025. ” In th is case, th e formal infe rence and error statistical approaches would agree that the familywise error rate is relevant because, logically, the relevant sampling distribution for th is formally reported union-intersection inference is giv en under H 0,1 ∩ H 0,2 (Rubin, 2017b, p. 323 ; Rubin, 2021b, pp. 10973 – 10975; Rubin, 2024b, pp. 51 – 52 ). However, in practice, the researcher can not report this inference because the ir p -hacking conceals the null result for H 0, 1 . Instead, they report an individual inference about H 0,2 , and that inference is licensed by its own nominal Type I error rate. Error statisticians might argue that we “ ought ” to audit the experime ntal testing context to try to detec t any p - hacking and make this hidden part of the “actual” test procedure objective (e.g., Mayo, 2018, p. 49). However, from a formal in ference perspective, publicly reporting previously undisclosed tests does not necessarily change the specified category o f s tatistical inference. For example, the researcher might report both p 1 ; H 0, 1 and p 2 ; H 0, 2 but spec ify two indi vidual infe rences as follows: One outlier was identified at ±3.00 SD s from the sample mean. There was no significant result when this outlier was included in the analysis, t (326) = 1.88, p = 0.061. However, there was a significant result when the outlier was excluded, t (325) = 2.16, p = 0.032. In thi s case, the Type I error rate for each individual statistical inference remains at its nominal level even if the sec ond test wa s “ac tually” conducted because the fir st test yielde d a null result (see also García-Pérez, 2023; Parker & W eir, 2020, pp. 563 – 564; R ubin, 2017a, pp. 271 – 272; Rubin, 2020, p. 380; Rubin, 2021a; R ubin, 2021b, pp. 10978 – 10979; Rubin, 2024a, p. 3 , Confusion I ; Rubin, 2024b, p. 51). Aga in, logically, the re searcher would only need to refer to the familywise error rate if they formally reported a union-intersection infe rence about H 0,1 ∩ H 0,2 . It would be a category mistake for them to use the familywise error rate to license individual inferences about H 0,1 and H 0,2 , even if the re sult for H 0,1 inspired the researcher to test H 0,2 (Rubin & Donkin, 2024, pp. 2023 – 2024). Mayo (1996) argued that the nominal error rate misrepresents “ what should be expected to happen … in subsequent experiments” (p. 349 , see also p. 310). This “error un reliability” argument assumes that the original expe riment “actually” undertook a union-intersec tion test of H 0,1 ∩ H 0,2 , rather than an individual test of H 0,2 , and then evaluated the test result using the wrong (nominal) sampling distribution (Spanos & Mayo, 2015, p. 3546). However, in the formal inference approach, a significance test of H 0, 2 can be treated as either (a) part of a union-intersection test of H 0,1 ∩ H 0,2 or (b) an individual test of the individual null hypothesis H 0, 2 , and it is the formally reported inference that determines which is the case. Hence, if an original experiment r eports an individual inference about H 0,2 , then, objectively, the significance test is treated as an individual test of H 0,2 , and “what should be expected to happen” in hypothetical exact replications of this individual test is licensed by the nominal Type I error rate for that test (see also Rubin, 2024b, p. 58). Finally, it is important to appreciate that the error statistical scenario shown in the bottom half of Figure 1 represents a simplistic conceptualization of the “actual” test procedure because it ignores the indeterminate nature of p -hacking in a hypothetical long run of repeated random sampling. By definition, a researcher who p -hacks will continue testing until they obtain a de sired p -Hacking in the Formal Inference Approach 11 result. Consequently, although the researcher in Figure 1 managed to obtain a signi ficant result on their second attempt in the current sample, they may need many more attempts in other samples (e.g., by conduc ting additional tests that add covariates, use different outcome measures, etc. ; Stefan & Sc hönbrodt, 2023 ; Wiche rts e t al., 2016 ). I n this case, the number of tests ( k ) in hypothetical repetitions of the “actual” test procedure is unknown, and so we cannot compute the “actual” familywise error rate a s 1 − (1 − α) k (Hochberg & Tamhane, 1987, p. 6; Mayo, 1996, pp. 313 – 314; Rubin, 2017b, p. 325; Rubin, 2021b, p. 10992; Rubin, 2024b, p. 56; see also Simmons et al., 2011, p. 1365). From an error statistical perspective, th is indeterminate testing problem invalidates significance testing duri ng not only secretive p -hacking but also transparently re ported re sult- dependent exploratory analyses (Rubin, 2017a; Rubin, 2021b, p. 10992; Rubin, 2024b, p. 56). Even so-c alled “honest hunting” for significa nce, which includ es a correc tion for multiple testing , is untenable in an open-ended exploratory sit uation because transparency about the number of tests conducted in relation to one sample does not inform us about the number of tests that would be conducted in other samples ( Mayo, 1996, pp. 311−314; Mayo, 2018, p. 275). The for mal inference approach avoids this problem by defining k relative to a closed, formally specified inference rather than an op en-ended and indeterminate “actual” test pro cedure (Rubin, 2024b, p. 64). For example, k = 1 for an individual inference about H 0,1 , and k = 2 fo r a union-intersection inference about H 0,1 ∩ H 0, 2 , even if these two inferences have been sele ctively reported from a larger s et of unreported inferences . Hence, from a formal inference perspective, significance testing re tains its value in unplann ed exploratory analyses (Rubin, 2017a, 2020, 2022, 2024b; Rubin & Donkin, 2024). 4. Areas of Agreeme nt and Disagreement Areas of Ag reement Despite their contrasting views on p -hacking, t here are several area s of agreement be tween the error statisti cal and formal inference approaches that are worth highli ghting. First, they both acknowledge th at their diverging views reflect different philosophi es of science (e.g., Mayo, 1996 , p. 255; Mayo & Cox , 2010, p. 267; R ubin, 2024b, pp. 46 – 47; Rubin, 2025). As Mayo and Cox (2010) explained: The general issue is whether the evidential bearing of data y on a n inference or hypothesis H 0 is altered when H 0 has been either constructed or selected for testing in such a w ay as to result in a specific observed r elation between H 0 and y , whether th at is agreement or disagreement. Thos e who favor logical approache s to confirmation say no (e.g., Mill 1888, Keynes, 1921), whereas those closer to an error-statistical conception say yes (Whewell (1847), Pierce (1931 – 5)). (p. 267) Error statisticians also ac knowledge the logical and mathematical argum ents that support the formal inference approach, although they find these arguments wanting. For example, Mayo and Cox (2010) explained that , “t o the extent that p is viewed as an aspect of th e logi cal o r mathematical relation between the data and the probability model , … preliminary choices [based on an inspe ction of the data] are irr elevant ” (p. 266). Simil arly, Mayo (1996) explained that , “i f confirmation is strictly a logica l function b etween evidence (o r statements of evidence) and hypotheses, when or how hypotheses are constructed will be irrelevant ” (p. 255). p -Hacking in the Formal Inference Approach 12 Finally, the two approa ches agree that a researcher’s personal biases may affect the specification of a significance test without invalidating its Type I error rate. As Mayo (1996) explained: It does not matter that te st specifications mi ght re flect the b eliefs, biases, or hopes of the researcher. P erhaps the r eason for sele cting an insensitive test is your personal desire to find no increa sed risk, or perha ps it is due to economic or ethical factors. Those factors are entirely irrelevant to scrutinizing what the data do and do not say. They pose no obstacle to my scrutinizing any claims you might make based on the tests, nor to my criticizing your choice of test as inappropriate for given learning goals. (p. 409; see also pp. 148, 263) The latit ude that exists in the choice of test does not prevent the determination of what a given result does a nd does not say. The error prob abilistic properties of a test procedure — however that test was chosen — allows for an objective interpretation of the results. (p. 406) Areas of Di sagreement Despite agreeing that personal ly biased test specification do es not prevent an objective interpretation of test results, the two approaches disagree about the impact of undisclosed result- dependent selective reporting (i.e., p -hacking). According to the error statistical approach , p - hacking invalidates significance testing because it represents an unrecogniz ed part of the relevant ( “actual” ) test procedure. I n c ontrast, in the formal infere nce approac h, p -hacking is not part of the relevant ( formally reported) test procedure. Consequently, and consist ent with its view on personally biased test specification, the formal inference approach assumes that p -hacking does not prevent e ither (a) public scrutiny of the formally re ported rationale for a specifie d test (Rubin, 2022, pp. 539 – 542; Rubin & Donkin, 2024, pp. 2024, 2036 – 2037) or (b) an objective interpretation of the test ’s results relative to its nominal Type I error rate. From a broader perspective, the two approaches disagree about where to draw the line between the context of discov ery and the context of justification (Reichenbach, 1938, pp. 6 – 7). The error statistical approach argu es that the construction and selection of hypotheses and data occur in the context of justification. In contrast, the formal inference approach follows P opper’s (1983) view that “the f actual, psychological, and historical question, ‘How do we come by our theories?’ [or statistical hypothes es ], though it may be fascinating, is irrelevant to the logical, methodological, and epistemological question of validity” (p. 36 ; see also Popper, 2002, pp. 7 – 8, 22 ). From this perspective, it does not matter that statistical hypotheses are secretly chosen because their test results are psychologicall y “desired” by researchers (e.g., Nagy et al., 2025, p. 2; Simmons et al., 2011, p. 1359 ; Stefan & S chönbrodt, 2023, p. 2). What matters is a public critical evaluation of the objective, formally reported, test procedures and inferences. Relatedly, th e e rror statistical and formal inference approach es have different responses to the conc ern that the specification of a n “actual” test procedure may dep end on psychological “ intentions locked up inside the scientist’s head ” (Mayo & Spanos, 2011, p. 186; see also Mayo, 1996, pp. 346 – 350; Mayo, 2008, pp. 860 – 861). To address this c oncern, the error statistical approach argues that we should audit the scientist’s experimental testing context in order to “pick up on” relevant informati on regarding “the construction and selection of both hypotheses and data” that can then be use to s pecify the “ actual” t est procedure (Mayo, 2018, p . 49). In contrast, the p -Hacking in the Formal Inference Approach 13 formal inference approac h argues that the “actual” test procedure is irreleva nt and that we should only refer to the scientist’s objective, formally reported test procedure (Rubin, 2025, p. 10). Mayo (1996) recognized th ese diverging views when defining th e “ actual” test procedure in the context of an exam ple in which a researcher conducted multiple tests and then searched for a significant result to report: It may be objected that … I am taking sides in favor of one description of the “ actual ” test procedure — one that takes into account th e fact that searching has occurred. I am, but maintain that this aspect of the proce dure cannot be ignored given the aim of the statistical significance test chosen. Remember, I am distinguishing the appropriateness of the test chosen (for a given inquiry) from the error prob abilities, given that that test is chosen. (p. 304) Mayo ’s (1996) position makes sense from an err or statisti cal perspective because ignoring the undisclosed searching for significance misspecifies the “actual” t est procedure. Ho wever, in th e formal infe rence approach, “the aim of the statistical test chosen” is to tentatively rule out ra ndom sampling error “ given that that test is chosen ” and “ however that test was chosen ” (Mayo, 1996, pp. 304, 406). From this perspective, it is legitimate to de fine the test procedure solely in terms of its formal, publicly reported specification and independent f rom any personally biased, result- dependent se lection process that influe nced th at specification (see also Mayo, 1996, p. 255; Mayo & Cox, 2010, p. 266). Mayo and Cox (2010) disagree, arguing that, “b y allowing the result to influence the choice of specification, one is altering the procedure giving rise to the p - value” (p. 271). Again, they are correct fr om an error statistical perspective because an error statistical test i ncludes the process by which its hypothesis and data were construct ed and select ed (Mayo, 1996, pp. 206 – 207, 298) . Consequently, allowing a test’s result to influence th is process will alter the “actual” test procedure. However, from a formal inference perspective, a significance test and its p -value are only conditioned on the formally reported test procedure and not on th e “ factual, psychological, and historical ” proce ss that led up to that procedure (Popper, 1983, p. 36). C onsequently, cha nging the process by which a test procedure is specified does not alter the procedure itself. Mayo (2018 ) claimed t hat “s election effects alter the outcomes in the sample space, showing up in altered error prob abilities” (p. 286). Again, this claim is correct if we follow the error statistical approach and extend the sample space to include outcomes that would arise during hypothetical repetitions of the selection process. However, it does not apply in the formal inference approach, which limi ts the relevant sample space to outcomes under the s elected statistical null hypothesis. For example, a biasing selection effect will not alter the Type I error rate for a n inference about H 0,13 when that infere nce is limited to potential outcomes in H 0,13 ’s sample space, even if p 13 ; H 0,13 has been p -ha cked from a set of unreported t ests p 1 ; H 0,1 , … p k ; H 0, k (Rubin, 2024b , p. 55 ). Spanos and Mayo (2015) argued that “t he discre pancy between actual an d nomi nal error probabilities stems from evaluating the nominal error probabilities using the wrong sampling distribution ” (p. 3546 ; see also Figure 1). Certainly, from an error statistical perspective, the sampling distribution under H 0,13 does not reflect the “actual” test pro cedure when p 13 ; H 0,13 has been p -hacked from p 1 ; H 0,1 , p 2 ; H 0,2 , p 3 ; H 0,3 , … p k ; H 0, k . However, from a formal inference perspective, the sampling distribution under the intersection null hypothesis H 0,1 ∩ H 0,2 ∩ H 0,3 … ∩ H 0, k is the “wrong” distributi on because it is in commensurate and inconsistent with the p -Hacking in the Formal Inference Approach 14 researcher’s formal ly reported inference, which is only about the individual hypothesis H 0,13 (Rubin, 2024a, p. 3; Rubin, 2025, pp. 13 – 14). Finally, Mayo (2018) returns to the issue of well-testedness or severity: For the severe tester, o utputting H 13 , ignoring the non-significant others, re nders H 13 poorly tested. You might say, but look ther e’s the hypothesis H 13 , a nd data x — shouldn’t it speak for itself? No. That’s just the evidential -re lationship or logicist in you comin g out. (p. 275) Again, however, in the formal infere nce approach, the well-testedness of H 0,13 depends on the individual test of H 0,13 , not the union-intersection test of H 0,1 ∩ H 0,2 ∩ H 0,3 … ∩ H 0, k . In this respect, formal inferentialists are not a fraid to let t heir inner logicist come out! Indeed, they would view it a s il logical to use the “actual” familywise error r ate to license an indi vidual infere nce about H 0,13 because this approach commits the fallacy of division (Selvin, 1958; Waller, 2018; for examples of this fallacy in real research studies, see Rubin, 2024a, pp. 5 – 6 ). In summary, disagreements between the error statistical and formal inference approaches stem fr om their diff erent c onceptualizations of test procedures, the context of justification, sa mple spaces, and sampling distributions. The error statistical a pproach assumes that p -hacking (a) constitutes part of the “actual” test procedure, (b ) occurs in the context of justification, and (c) alters the relevant sample space and sampling distribution. I n contrast, the formal inference approach assumes that p - hacking (a) is not part of the selected, formally reported test procedure, (b ) occurs in the context of discovery and, consequently, (c) does not alter the relevant hypothetical sample space or sampling distribution (Rubin, 2025, pp. 4 – 5, 9 – 10). 5. The Minimal Sev erity Requirement According to the error statistical approach’s minimal severity requirement , it is important to adequately check a test’s assumptions in order to provisionally rule out systematic error , b ecause systematic error can cause a significant discrepancy between “actual” and nominal error probabilities that invalidates nominal error probabilities (Mayo & Spanos, 2011, p. 190; Spanos, 2010, p. 219; Spanos & Mayo, 2015, pp. 3541, 3543). In the for mal inference approach, however, nominal Type I error rates are not invalidated by systematic error because they refer to a hypothetical situation in which there is no systematic error, all test assumptions are met, and the only source of decision-making error is random sampling error ( Fisher, 1956, pp. 40, 44, 77 – 78, 82; Fisher, 1959, pp. 21 – 22; Kass, 2011, pp. 5 – 6, 7; Meehl, 1990, p. 111; Neyman, 1955, p. 17; Neyman & Pearson, 1928, p p. 177, 232; Rubin, 2024b, p. 49; see also Popper, 1983, p. 313). Hence, it is not necessary to meet the minimal severity requirement in order to obtain valid Type I error rates. This point can be illustrate d with res pect to (a) implicatory assumptions and (b) the Texas sharpshooter fallacy. Implicatory Assump tions In the formal inference a pproach, a Type I error rate refers to a hypothetical situation in which random sampling error is the only sourc e of decision -making error. This hypothetic al situation can be described as an “ implicationary or i-assumption ” that is made during testing in order to draw out certain logical implications (Mayo, 2018, pp. 109, 167). According to Mayo (2018), “the howle r [mistake] o ccurs whe n a test hypothesis that se rves merely as an i -assumption is purported to be an actual assumption, needed fo r the inference to go through” (p. 167; see also Cortina & Dunlap, 1997 , pp. 166−167 ). The formal inference approach agrees and applies th e p -Hacking in the Formal Inference Approach 15 same reasoning to not only the test hypothesis but also the test assumptions (see also Hennig, 2010, p. 47; Hennig, 2023, pp . 24, 38). Hence, the formal inference approach does not require a test’s “actual” assumptions to be checked and a ffirmed as “approximately true” i n order for a statisti cal inference to go through (Mayo, 2011, p. 96; Mayo & Spanos, 2011, p. 189 ; cf. Hennig, 2023, p. 38). Instead, during testing, all test assumptions are provisionally accepted as i-assumptions. In this case , failure to probe for systematic error in a test’s “actual” assumptions does not invalidate that test’s nomi nal error rate because the associated inferential argument is based on unproblematic i-assumptions. The relation between “actual” and implicatory assumptions is similar to that between the soundness and validity of a logical argument. For example, c onsider the argument that “all cats are gray, and x is a cat; therefore, x is gra y.” This argument is logically valid, even though it is unsound because its major premise is not “approximately true” — not all cats are gray ; not even most cats are gray (Fisher, 1959 , pp. 22 −23; Mayo, 2018, p. 60). F urthermore, the argument remains valid even though other major premises are available that ar e approximately true (e.g., “all cats have whiskers”). Similarly, in the formal inference approach, it remains valid to use a nominal Type I error ra te to license a statistical inference even when th e a ssociated test ’s “ac tual” assumptions are not a pproximately true. In other words, it remains valid to make the suppositional, subjunctive conditional argument that, if a test ’s assumptions were true and ra ndom sampling error was the only source of d ecision-making error, then the nominal Type I error rate would represent the maximum frequency with which the null hypo thesis would be incorrectly rejected (Neyman, 1950, p. 289; Neyman, 1955, p. 17; see also Corti na & Dunlap, 1997, pp. 1 66 – 167; Fisher, 1959, pp. 21 – 22; Hennig, 2023, pp. 21, 23 – 24; Kass, 2011, pp. 5 – 6, 7; Mayo, 2018, pp. 426 – 427). In this case, the nomi nal Type I error rate represents a hypothetical error rate r ather than an “actual” error rate, and “w e speak of what would be inferred if our assumptions were to hold ” (Kass, 2011, p. 7; see also Fisher, 1956, pp. 44, 77 ). 8 The use of i -assumptions during hypothesis testing is also consistent with Popper, who argued that a test’s background assumptions (initial conditions and auxiliary hypotheses) must be accepted as “unproblematic” during the test in order to force the test hypothesis int o logical isolation (Popper, 1983, pp. 186, 244; Popper, 1994, p. 160; P opper, 2002, p p. 197, 260; see also Lakatos, 1978, pp. 32, 42; Rubin, 2025, p. 12, F ootnote 7). Of course, a test’s “actual” assumpti ons may be challenged before or after the test takes place (Lakatos, 1978, p. 158; Popper, 1994, p. 160), and if they are judged to be in adequate, then an alternative test may b e considered (Popp er, 2002, p. 86). However, in the formal infere nce approach, the identification of a more ade quate test does not invalidate a st atistical inference bas ed on the original (inad equate) test because the inferential argument for th at test is bas ed on hyp othetical i -assumptions, not real-world “actual” assumptions. “2 + 2 = 4 , ” and this mathematical equation remains valid even if there has b een a data entry error and one of the “2s” is later revealed to be a “3.” The Texas Sharpsh ooter Fallacy Mayo also used the Texas sharpshooter fallacy to il lustrate the error statistical concern about violating the minimal severity requirement (Mayo, 1996, pp. 201 – 203; Mayo, 2018, pp. 5, 19, 276 – 277; Ma yo & Cox, 2010, p. 271). In th is scenario, a n individual with poor shooting skill s fires several shots at a barn wall and then paints a target around a random cluster of their bull et holes. Later on, they show the se “bull s eyes” to their friend as evidence of their “ e xcellent shooting skills. ” The minimal severity requirement is not met in this scenario because there has been no attempt to rule out the sharpshooter’s fr audulent behind -the-scenes behavior as one of the ways in p -Hacking in the Formal Inference Approach 16 which the ir claim may be fa lse (Mayo, 2018, p. 19 ). Consequently, we are left with “bad evidence, no test (BENT)” (Mayo, 2018, p. 5). Again, however, from a formal inference p ersp ec tive, it is not necessary to meet the minimal severity requirement in order to report valid hypothetical probability statemen ts . For example, it remains valid for the sha rpshooter to compute the prob ability that their shot s would hit the painted targ et in repeti tions of the ir formally reported test pro cedure (i. e., the proc edure that they report ed to their friend ; see also Mayo, 2018, p. 19). In this case , the relevant probability is a formal mathematical probability about the occurrence of a hypothetical event based on chance alone, and so it is not invalidated by the p resence of fraud in the real world (Fisher, 1956, pp. 40, 44, 77; Fisher, 1959; Neyman, 1955, p. 17; Neyman & Pearson, 1928, p p. 176, 232; cf. Mayo, 2018, p. 19 ). To be clear, I am not arguing that the sharpshooter’s fraudulent behavior is unproblematic. It certainly invalidates the substantive (nonstatisti cal) inference about th eir “excellent shooting skills. ” I am only arguing that, during significance testing, Type I error rates license hypothetical, test-specific, stat istical inferences giv en random sampling error alone, not real-world, general, substantive inferences gi ven systematic error (Meehl, 1990, p. 111; Meehl, 1997, p. 401 ; Neyman, 1950, p. 290) . Consequen tly, we shoul d not expect Type I error rates to be “ altered, ” “invalidated , ” or “vitiated” by the presence of syst ematic e rror in the rea l world, including error caused by fr aud. By analogy, we would not expect a weighing s cale ’s random measurement error to be altered o r invalidated when a person l ie s about their weight or when the sca le systematically underestimates weight. These systematic errors will certainly invalidate substantive inferences about the person’s weight , but they will not invalidate statis tical inferences based on the scale’s random measurement error. 6. The Nondisclosur e of Null Results p -hacking results in the nondisclosure of null (nonsignificant) results. Again, thi s nondisclosure only inflates Type I error rates in the error statistical appr oach. Nonetheless, it may also be problematic in the formal inference approach, depending on how we conceptualize null results an d their impact on substantive inferences. To illustrate, consider a r esearcher who reports th e subst antive inference that “eating jelly beans causes acne” (Mun roe, 2011). Imagine that they base thi s substantive inference on a single statistical inference : “ Participants who ate green jelly beans had significantly more acne than those in a control group, t (326) = 2.63 , p = 0.009. ” Ho wever, unbeknownst to readers, the researcher do es not r eport th e results of 19 other tests that found no significant results using 19 other colo r s of jelly beans ( p s > 0.05). From an error statisti cal perspective, the “actual” familywise error r ate for th e statisti cal inference (0.64 2) is infla ted above the c onventional nominal error rate (0.05) because the “ac tual” test procedure includes 20 tests, not 1 test. In contrast, from a formal inference p erspective, the nominal Type I error rate of 0.05 is valid because the reported statistical inference is an individual inference about green jelly beans, not a union-int ersection inference about green, red, blue, and other colors of jelly b eans (for a discussion, s ee Rubin, 2021b, pp. 10978 – 10983). But does the researcher’s failure to report the 19 null results bias their substantive inference that “ eating jelly beans causes ac ne”? Th e answer depends on ho w we con ceptualize null results and how they re late to the substantive inference. First, null re sults may be rega rded as providing evi dence of absenc e because we tentatively “accept” null hypothes e s following severe, high-powered tests (Neyman, 1950, pp. 259 – 260; e .g., p -Hacking in the Formal Inference Approach 17 Mayo, 2018, p. 150; Mayo & Cox, 2010, p. 256 ; Mayo & Spanos, 2006, p. 339 ; Mayo & Spanos, 2011, p. 177). In this case, nondisclosed null results may bias substantive inferences. F or example, in the current scenario, 19 results indi cate that jell y beans do not cause acne, and only one result indicates that they do ! Hence, failing to report th e 19 null results is problematic because it hides relevant evidence and biases the evidential support for the substantive inference. Second, null results may be reg arded as the absence of evidence (Aczel et al. , 2018; Altman & Bland, 1995; Murphy et al., 2025; Rubin & Donkin, 2024, p. 2036) because we merely “ fail to reject ” null hypotheses following nonsevere, low-powered, or F isherian tests (Fisher, 1956, p. 45 ; Mayo & Spanos, 2006, pp. 338 – 339; Mayo & Spanos, 2011, p. 176). Hence, in the absence of a meta-analysis, null results do not impact substanti ve inferences because they do not provide a ny evidence one way or the other. For example, in the current scenario, the si ngle significant result for green jelly beans supports the substantive claim that “ eating jelly beans ca uses acne, ” whereas the 19 null results do not count as e vidence either for or aga inst this claim and so can be ignored. 9 From this perspective, it is more problematic for researchers to omi t tests that yi eld significant results that contradict their substantive inference. For example, it would be problematic i f the research er failed to report a result showing that eating red jelly beans significantly reduced acne relative to a control group. In th is case, they would be omitting relevant evi dence that contradict ed the substantive claim that “ eating jelly beans causes acne ” (Rubin, 2020, p. 384). Finally, even if null results are regarded as providing evidence of absence, their nondisclosure will only bias a substantive inference when they are theoretically relevant to that inference (Rubin, 2020, p. 378; Rubin, 2022, p. 548). Fo r example, failing to report the severe , high-powered, statistical inferenc e that “there was no significant difference in acne betw een participants who ate M&Ms and those in a control group , t (326) = 0.33, p = 0.742 ” will not bias the substantive claim that “e ating jelly beans causes acne” because M& Ms are not j elly beans (Rubin, 2021b, p. 10988) . Hence, it is important to distinguish between biased selective reporting, which is problematic, and unbiased selective reporting, which is an essential part of effective scientific communication (Rubin, 2020, p. 383) . A theory-c entric critical rational discussi on among researchers is re quired to make this distinction (Popper, 1966, p p. 218 – 219, 229 – 231; Popper, 1994, pp. 93, 159 – 16; Rubin, 2025, p. 11 ). In summary, nondisclosed null results only bias substantive inferences when they are regarded as b eing both (a ) evidence of absence and (b) theoretically releva nt. How can we id entify these evidentially and the oretically important null results? Preregistration represents one app roach. However, preregistra tion cannot identify nondisclosed null results in the case of either exploratory analyses or unreported d eviations from preregistered an alyses. For example, a researcher may try out two deviations from a preregistered analysis protocol and then only report the deviation that yields a significant result. In this case, cross-referencing between the final research report and the preregistered protocol will not help to identify th e undisclosed null result. A more comprehensive approac h to identifying theoretically important unreporte d null results is to consider relevant theory, evidence, an d background knowledge. As K err (1998) asked, if an original hypothesi s is not re ported, but it “ had a sufficient rationale (theoretical, empirical, or even intuitive) to recommend itself to one researcher, why would it not also occur to others? ” (p. 208; see also Rubin, 2020, p. 378; Rubin, 2022, p . 548 ). For example, in the current s cenario, w e might reasonably expect reviewers and other readers to ask why the researcher only used green jelly beans to test the substantive hypothesis that “eating jelly beans causes acne” and whether they tested any other colors of jelly beans (Wells & Windschitl, 1999). I n the formal inference approach, researchers’ anticipation of this critical rational di scussion of their work helps to constrain th eir p -Hacking in the Formal Inference Approach 18 “researcher degrees of f reedom” (Simmons et al., 2011, p. 1359) and pr event an “anything goes” approach (Hennig, 2023, pp. 17, 19). 10 7. Conclusions and I mplications Conclusions I have argued that p -hacking inflates Type I error rates in the err or statistical approach but not in the formal inference approach. In the error statistical approach, t he “ actual ” test procedure determines the releva n t error rate. In contrast, in the formal inference approach, the formally reported statistical inference determines the relevant error rate. p -hacking is part of the “actual” test proce dure, but it is not part of the procedure implied by the formally reported inference . Consequently, p -hacking inflates the relevant erro r rate in the error statistical appro ach but not in the formal inference approach. Importantly, from a formal inference perspective, i t is in appropriate to use the “ actual ” familywise error rate to license inferences about selectively reported hypotheses following p - hacking. Logically, the “ actual ” familywise e rror rate only licens es an in ference about the entire family of reported and unreported hypotheses that a re tested in the “a ctual” test procedure . I t does not license inferences about selectively reported hypotheses, which are licensed by their own nominal error rates. Certainly, p -hacking influences the sele ction of reported significance tests. However, this selection p rocess is not part of th ose tests, and so p -h acking does not influence the associated nominal Typ e I error rates . Hence, i n the formal inference approach, “computed” nominal Type I error rates can be taken at f ace value, barring any logical or mathematical errors (Neyman, 1950, p. 289; Rubin, 2024b, p. 53; Rubin, 2025, p. 14 ). In the err or statistical approach, fa iling to meet the minimal severity requirement lea ves us with “bad evidenc e, no test (BENT)” (Mayo, 2018, p. 5) . In contrast, in the formal infere nce approach, failing to rule out ways in which a substantive inference could be false may result in a “ bad ” substantive inference without invalidating a corresponding statist ical inference, which is based on tentatively accepted i-assumptions. Of course, a researcher’s “actual” test assumptions may be judged to be inadequate. In thi s case, they should use a different test with more adequate assumptions. Howeve r, doing so only has the potential to reduce systematic error. It does not result in a more valid Type I error r ate because Type I error rates do not represent systematic error in a test ’s selection, sp ecification, or assumptions . They only r epresent random error given a test ’s selection, specification, and assumptions. Finally, nondisclosed null results inflate Type I error rates in the error stati stical approach but not in the formal inference approach. Nonetheless, nondisclosed null results may be problematic in the formal inference approach if they are regarded as being both (a) evidence of absence and (b) theoretically relevant. In this case , although unreported nul l results do not inflate Type I error rates, they may bias substantive inferences. Ho wever, this substantive bias can b e identified and address ed through a theory- centric critical rational discussion among peers (Popper, 1966, pp. 218 – 219, 229 – 231; Popper, 1994, pp. 93, 159 – 160; Rubin, 2025, pp. 5, 11). Implication s The contra st between the err or statistical and fo rmal inference appro aches ha s implications for the way in which we conceptualize p -hacking. p -hacking is often described a s a “questionable research practice” (John et al., 2012). The current analysis supports thi s equivocal description as opposed to stricter characterizations that equa te p -hacking with fraud and unethical resea rch behavior (e.g., Mil ler et al., 2025; Pickett & Roche , 2018). In particular, p -h acking may b e viewed p -Hacking in the Formal Inference Approach 19 as being more or less problematic depending on one’s philosophy of s ignificance testing. Accordingly, it would be helpful for discussions about the potential dangers of p -hacking to be more clearly situated withi n relevant philosophies of significance testi ng in order to a rticulate otherwise hidden assumptions. A simil ar recommendation applies to demonstrations and simulations showing that p - hacking inflates Typ e I error rates. This wo rk tends to adopt an error statistical perspective by contrasting nomi nal and “actual” error rates (e.g., Simmons et al ., 2011 , p. 1359 ). How ever, it should be acknowledged that , during p -hacking, (a) researchers cannot report union-intersection inferences about “actual” intersection null hypotheses , (b) “actual” familywise error rates c annot be computed due to the i ndetermina te number of tests in a hypothetical lon g run of sampling, a nd , even if they could be computed, (c) “actual” familywise error rates do not licens e researchers’ selectively reported individual inferences (Rubin, 2024b, pp. 58, 63). The contrast between the error statisti cal and formal inference approaches also has implications for int erventions that are int ended to reduce p -h acking. In pa rticular, f rom an error statistical perspective, prere gistration provides a useful method of limiting p -hacking, Typ e I error ra te inflation, and the nondisclosure of null results (Lakens, 2019, 2024; Lakens et al., 2024; Mayo, 2018, pp. 106 – 107, 439). However, from a formal inference perspective, p - hacking does not alter relevant (nominal) Type I error rates (Rubin, 2024b, 2025). In addition, nondisclosed null results may (a) represent the absence of evidence, (b) be theoretically ir relevant, and (c) be identified following a critical rational discussion of relevant theory and background knowledge (Rubin, 2020, p. 378; Rubin, 2022, p. 548 ; Rubin & Donkin, 2024, p. 2036 ). Hence, the formal inference approach does not provide a rationale for preregistration ba sed on either Type I error rate inflation or the nondisclosure of null results. Turning to the replication crisis, error statistic ians have argued that “ inflated error rat es [are] at the heart of obstacles to replication” (Mayo, 2025, p. 1) and that “much of the handwringing about irreproducibility is the result of wearing blinders as to the construction and selection of both hypotheses and data” ( Mayo, 2018, p. 49). I n contrast, fr om a formal inference perspective, researchers wh o p -hack do not report statisti cal inferences that have infla ted Type I error rates because they do not report union-intersection inferenc es about “actual” inters ection null hypotheses (Rubin, 2024b). Instead, they selectively report individual inferences that have v alid nominal error rates. To be clear, the formal inference approach attributes replication failures to both statistical Type I errors and substantive interpre tational errors. Howeve r, it a rgues that Type I e rror rates are fixed at their nominal levels. In contrast, unrecognised interpretational errors may occur more frequent ly than expe cted, whic h may help to explain lower than e xpected rep lication rates (i.e., the replication crisis; Rubin, 2024b, pp. 63 – 64). Of course, it is important to unde rtake rigorous auditing in origina l studies to try to identify interpretational errors (Mayo, 2018, pp. 100, 441 – 442). However, auditing can only examine known unknowns — th e potential interpretational errors that researchers have thought to investigate. By definition, even the most rigorous auditing can not identify unknown unknow ns — the potential interpretational errors that researchers have not yet considered. Unlike known unknowns, unknown unknowns cannot be tentatively ruled out in original studi es, and they may go on to represent hidden moderators that cause replication fa ilures (Rubin, 2024b, pp. 63 – 64; for examples, see Firestein, 2016 ). Hence, from a formal inference perspective, th e replication c risis is not t he r esult of p - hacking inflating Type I error rates. Certainly, Type I errors will result in some replication failure s, p -Hacking in the Formal Inference Approach 20 but no more than expected based on the nominal conventional alpha level. The replication crisis is also not the result of poorly audited test assumptions. More rigorous auditing will help to tentatively rule out some interpretational errors in original studies. However, by definition, it will be unable to identify unrecognized interpretation al errors (unknown unknow ns) that go on to cause replication failures via hidden moderators. Instead, the replication crisis is a result of our underestimation of the extent and impact of unrecognized interpretational errors . We end up being surprised by the extent of our own unanticipated ignorance ! From this perspective, the solut ion to th e replication crisis will not be found in new statistical or methodological appro aches. Instead, it requires a more fundamental epistemological shift in our research culture th at produces a better acknowledgment “of the finitude and fallibility of our knowledge, and of the infinity of our ignorance” (Popper, 1994, p. 123). Endnotes 1. Following the error statisti cal approach, a semicolon “;” is used to indicate that a p -value is computed assuming that a specific null hypothesis is true (e.g., “ p 1 ; H 0,1 ” ; Mayo & Spanos, 2006, p. 331; Mayo & Spanos, 2011, p. 169). 2. The word actual is placed in scare quotes throughout because, from a formal infere nce perspective, the “actual , ” inferentially relevant, test procedure and Type I error rate are both hypothetical and formally specified (Rubin, 2025, pp. 13 – 14). 3. Another method of correcting for multiple testing is based on the false discovery rate (FDR ; Benjamini & Hochbe rg, 1995, p. 290). The fa milywise error rate is the probability of re jecting at least one constituent null hypothesis (e.g., H 0,1 ) in an intersection null hypothesis (e.g., H 0,1 ∩ H 0,2 ) when all are true. In contrast, the FDR is the expec ted propo rtion of incorrectly rejected null hypotheses among all (true and false) rejected null hypotheses. Hence, unlike the familywise error rate, the F DR assumes th at some of the constituent null hypotheses in an intersection null hypothe sis (e.g., H 0,1 ) may be correctly rejected because th ey are false (Rubin, 2021b, p. 10975). Cons equently, from a fo rmal inference perspective, the FDR does not represent a Type I error rate because Type I err or rates are computed under the assumption that the associated null hypothesis is true (Neyman, 1952, p. 57), and the FDR assumes that the intersection null hypoth esis (e.g., H 0,1 ∩ H 0,2 ) may be false be cause one or more of it s constituent hypotheses may be false (e.g., H 0,1 ). 4. I n r esponse to Rubin (2021b), Goeman (2022) argued that strong control over the familywise error rate (e.g., via a Bon ferroni correction ) allows us to make inferences about not only (a) a superordinate intersection null hypothesis (e.g., H 0,1 ∩ H 0,2 ∩ H 0,3 ), but also (b) subordinate intersection null hypotheses (i.e., H 0,1 ∩ H 0,2 , H 0,2 ∩ H 0,3 , and H 0,1 ∩ H 0,3 ) and (c) indi vidual null hypotheses (e.g., H 0,1 , H 0,2 , and H 0,3 ). However, Goeman ’s argument confuses (a) constituent null hypotheses that are treated as being logical ly exchangeable parts of the same superordinate intersection null hypothesis with (b) subordinate intersection and individual null hypotheses that are treated as being logically distinct and nonex changeable with one another (García-Pérez, 2023, p. 2; Rubin, 2021b, pp. 1097 8 – 10982; Rubin, 2024a, p. 2 ). For example, the familywise error rate for a union -intersection inference about H 0,1 ∩ H 0,2 ∩ H 0,3 only licenses a de cision about H 0,1 ∩ H 0,2 ∩ H 0,3 . It would be a fallacy of division (Waller, 2018) to argue that it also licenses decisions about subordinate intersection null hypotheses, such as H 0,1 ∩ H 0,2 , and individual null hypotheses, such as H 0,1 . Furthermore, in the formal inference approach, researchers should not be interested in the error rate for H 0,1 ∩ H 0,2 ∩ H 0,3 unless p -Hacking in the Formal Inference Approach 21 they report a union-inte rsection inference about this hypothesis. Customized, inference- specific error control at the level of formally reported int ersection and/or individual hypotheses provides a more logically consistent and statis tically powerful approach , and it makes strong error control over sup erordinate intersection null hypothese s irrelevant (see also Rubin, 2021b, pp. 10990 – 10992). 5. Throughout thi s article, I assume that researchers tend to report individual inferences rather than union-intersection or intersection-union inferences be cause individual inferences are the most common type of statistical inference (García-Pérez, 2023, p. 4). However, the same formal inference principl es apply to subordinate in tersection null hypotheses (e.g., H 0,1 ∩ H 0,2 ) that ha ve been selectively re ported from an “actual” superordinate intersection null hypothesis (e.g., H 0,1 ∩ H 0,2 ∩ H 0,3 ). For a discussion and illustration, see Rubin (2024b , pp. 59 – 60). 6. Figure 1 is based on R ubin ’s (2025) Figure 1. Also note that a similar formal inference argument can be made to demonstrate that Type I e rror rates are not infl ated in the case of optional stopping (Rubin, 2024b, pp. 61 – 62; cf. Mayo, 2018, pp. 43 – 44 ). 7. Mayo (2018, p. 14) proposed an “argument from coincidence” as a “positive counterpart” to the minimal severity requirement . As Mayo (201 0) explained, “ th e most familiar canonical exemplar of an argument from coincidence is statistical null hypothesis testin g … [Here,] the null hypothesis, H 0 , asserts that the effect or observed agreement is ‘due t o coincidence’ ” (p. 85; see also Fisher, 1956, p. 35 ). When testing an intersection null hypothesis, the “ coincidence ” is that at least one test would yield a significant result when all constituent null hypotheses are true. If the fa milywise error rate is suitably low, then there is a low probability of encountering this coincidenc e. In this case, we ca n say that the union-intersec tion test has a high “ capacity ” to detect an error, and we are licensed to argue against this “ coincidence ” to the absence of error in the case at hand. Crucially, however, when testing an intersection null hypothesis, the case at hand is an intersection null hypothesis, not an individual hypothesis. 8. Mayo uses the term “inference” to refer to a claim that has been detached from an inferential argument (e.g., “ x is gray” in the case of “all cats are gray, and x is a cat; therefore, x is gray” ; Mayo, 2011, pp. 84 – 85; Mayo, 2018, p. 65). To b e warranted in the error statistical approach, a statistical inference m ust be detached after the argument’s premises have been adequately checked and affirmed as being “approximately true” (Mayo, 2011, p. 96; Mayo & S panos, 2011, pp. 189, 193 ; see also Mayo, 1996, p. 435; Mayo, 2018, pp . 84, 441 – 442). In contrast, in the formal inference approach, a statistical inference cannot be detached fr om its infere ntial argument because it is su bjunctively conditioned on a test’s suppo sitional i-assumptions (Ka ss, 2011, pp. 5 – 6, 7; see also Fisher, 1956, p. 44; Hennig, 2023, p. 24 ). Only a nonst atistical substantive inference can be d etached as a more g eneral standalone conclusion. Nonetheless, following F isher (1959, p. 21), a statistical inference can be regarded as a suppositional “ as if” inductive inference. Specifically, i t can be argued that if a test’s i-assumptions were true, then a significant result would license the provisional inference that the study’s current sample does not belong to a specified hypothetical infinite null population that contains no known re levant subsets (Fisher, 1956, pp. 32 – 33, 57, 109; Fisher, 1959, pp. 21 – 24). Despite its name, this “inductive reasoning” is consistent with Popper’s deductive approach because it is conceptualized as a “ statement of uncerta inty ” about the observed re sult (Fisher , 1956, pp. 57, 108 – 110; Fisher, 1959, p. 22; see also Gre enland, 1998, pp. 545 – 546) rather than an inductive prediction about future results during “repeated s ampling from the same population” (Fisher, 1956, p. 77; cf. Mayo, 2018, p. 83 ). p -Hacking in the Formal Inference Approach 22 9. The difference between a significant result and a nonsignificant result may not itself b e significant (Gelman & Stern, 2006). Hence, at this stage, we cannot draw any conclusions about the potential moderating effect of jelly bean color. 10. In order to avoid question s about why th ey only tested green jelly beans, a researcher may deliberately omit jelly bea n color from the specification of their statistical inference. In the formal inference approach , this personally biased respecification does not impact the validity of the associated Type I error rate, which is sub junctively conditioned on the researcher’s formally r eported in ference. Like all statistical inferences, the researcher’s respecified inference may include irrelevant variables and/o r exclude relevant variables (Rubin, 2025, p. 7, Footnote 5). Hence, when interpreting statistical infe rences, it is important to appreciate “that the population in question is hypothetical, that it could be defined in m any ways, and that the first to come to mi nd may be quit e misleading” (Fisher, 1956, p. 78). In the pr esent case, future tests may either co nfi rm that color is irr elevant or rev eal it to be a previously hidden moderator that has caused a systematic error in the substantive inference that “eating jelly beans c auses acne” (i.e., only green jelly beans ca use acne). However, th is revelation would not invalidate the researcher’s original statis tical inference, which requires us to accept a “postulate of ignorance” (i -a ssumption) about the presence of relevant subsets (e .g., green jelly beans) withi n a hypothetical infinite population (i.e., “jelly beans” ; Fisher, 1959, p. 23). This postulate allows us to construe the current sample as a random sample and to attribute uncertainty about the statistical inference to r andom sampling error independent from systematic error (Fisher, 1956, pp. 32 – 33, 57, 109; Fisher, 1959, pp. 21 – 24 ). Note that if the discovery of p reviously hidden modera tors and releva nt subsets were to invalidate prior statistical inferences, then most of our prior statistical inferences would be invalid. References Aczel, B., Palfi, B., Szollosi, A., Kovacs, M., S zaszi, B., Szecsi, P ., Zrubka, M., Gronau, Q. F., van den Bergh, D., & Wa genmakers, E. J. (2018). Quantifying support for the null hypothesis in psychology: An empirical investigation. Advanc es in Methods and Practices in Psychological Science, 1 (3), 357 – 366. https://doi.org/10.1177/2515245918773742 Altman, D. G., & Bland, J. M. (1995). Absence of evidence is not evidence of absence. Brit ish Medical Journal, 311 (7003), 485 – 485. https://doi.org/10.1136/bmj.311.7003.485 Benjamini, Y., & Hochberg, Y. (1995). Controll ing the false dis covery rate: A practical and powerful approach to mult iple testing. Journal of the Royal Statistical Society: Series B (methodological), 57 (1), 289 – 300. https://doi.org/10.1111/j.2517-6161.1995.tb02031.x Berger, R. L. (1982). Multiparameter hypothesis testing a nd a cceptance sampling. Technometrics, 24 , 295 – 300. https://doi.org/10.2307/1267823 Bishop, D. V. (2019). R ein in the four ho rsemen of irreproduc ibility. Nature, 568 (7753), 435 – 436. https://www.nature.com/articles/d41586-019-01307-2 Cortina, J. M., & Dunlap, W. P. (1997). On the logic a nd purpose of significanc e testing. Psychological Methods, 2 (2), 161 – 172. https://doi.org/10.1037/1082-989X.2.2.161 Firestein, S. (2016, February 14). Why failure to replicate findings can actually be good for science. L A Times. https://www.latimes.com/opinion/op -ed/la-oe- 0214-firestein-science- replication-failure-20160214-story.html Fisher, R. A. (1956). Statistical methods and scientific inference . Oliver & Boyd. Fisher, R. A. (1959 ). Ma thematical prob ability in the natur al sci ences. Technometrics, 1 (1), 21 – 29. https://doi.org/10.1080/00401706.1959.10489846 p -Hacking in the Formal Inference Approach 23 García-Pérez, M. A. (2023). Use and misuse of corr ections for multiple testing. Methods in Psychology , 8 , 100120. https://doi.org/10.1016/j.metip.2023.100120 Gelman, A., & Stern, H. (2006). The difference between “significant” and “not significant” is not itself statistically significant. The American Statistician, 60 (4), 328 – 331. https://doi.org/10.1198/000313006X152649 Goeman, J. (2022, May 12). Review of: When to adjust alpha during mul tiple testing. Qeios . https://doi.org/10.32388/48X0KD Greenland, S. (1998). I nduction versus Popper: Substance versus semantics. International Journal of Epidemiology, 27 (4), 543 – 548. https://doi.org/10.1093/ije/27.4.543 Hennig, C. (2010 ). Mathematical models and reality: A construc tivist perspective. Foundations of Science, 15, 29 – 48. https://doi.org/10.1007/s10699-009-9167-x Hennig, C . (2023). P robability models in statistical data analysis: Uses, interpretations, frequentism- as -model. In B. Sriraman (Ed.), Handbook of the History and Philosophy of Mathematical Practice (pp. 1 – 49) . Springer. https://doi.org/10.1007/978-3-030-19071- 2_105-1 [Accessed as preprint version: https://arxiv.org/abs/2007.05748 ] Hochberg, Y., & Tamhane, A. C . (1987). Multiple comparison procedure s. Wiley. http://doi.org/10.1002/9780470316672 John, L. K., Loewenstein, G., & Prelec, D. (2012). Measuring the prev alence of questionable research practices with incentives for truth telling. Psychological Science, 23 (5), 524 – 532. https://doi.org/10.1177/0956797611430953 Kass, R. E. (2011). Statistical inference: The big picture. Statistical Science, 26 (1), 1. https://doi.org/10.1214/10-STS337 Kerr, N. L. (1998). HARKing: Hypothesizing after the results are known. Personality and Social Psychology Review, 2 (3) , 196 – 217. http://doi.org/10.1207/s15327957pspr0203_4 Lakatos, I. (1978). T he methodology of scientific research programmes (Philosophical Papers, Volume I). Cambridge University Press. Lakens, D. (2019). The value of pr eregistration for psychological science: A conceptual analysis. Japanese Psychological Review, 62 (3), 221 – 230. https://doi.org/10.24602/sjpr.62.3_221 Lakens, D. (2024). When and how to de viate fr om a prere gistration. Collabra: Psychology , 10 (1), 117094. https://doi.org/10.1525/collabra.117094 Lakens, D., Mesquida, C., Rasti, S., & Ditroilo, M. (2024). The benefits of preregistration and Registered Reports. Evidence-Based Toxicology, 2: 1, 2376046, https://doi.org/10.1080/2833373X.2024.2376046 Mayo, D. G. (1996). Error and the growth of experimental knowledge . University of Chicago Press. Mayo, D. G. (2008). How to discount double -counting when it counts: Some clarifications. The British Journal for the Philosophy of Science, 59 (4), 857 – 879. https://doi.org/10.1093/bjps/axn034 Mayo, D. G. (2010). Can scientific th eories be warranted with s everity? Exchanges with Alan Chalmers. In D. G. M ayo & A. Spanos (Eds.), Error and inference: Recen t exchanges on experimental reasoning, reliability, and the objectivity and rationality of science (pp. 7 3 – 112). Cambridge University Press. Mayo, D. G. (2011). Statist ical science and philos ophy of science: Where do/should they meet in 2011 (and beyond)? RMM, 2, 79 – 102. http://hdl.handle.net/10919/80466 Mayo, D. G. (2018). Statistical inference as sev ere testing: How to get bey ond the statistics wars . Cambridge University Press. p -Hacking in the Formal Inference Approach 24 Mayo, D. G. (2025 ). Severe testing: Error statistics versus Bay es factor tests. British Journal for the Philosophy of Science. https://doi.org/10.1086/736950 Mayo, D. G., & C ox, D. (2010). Frequentist statistics as a theory of inductive inference. In D. G. Mayo & A. Spanos (Eds.), Error and inference: Recent exchanges on expe rimental reasoning, reliability, and the objectivity and rationality of science (pp. 247 – 275). Cambridge University Press. Mayo, D. G., & Spanos, A. (2006). Severe t esting as a basic concept in a Neyman – Pearson philosophy of induction. The British Journal for the Philosophy of Science, 57 (2 ), 323 – 357. https://doi.org/10.1093/bjps/axl003 Mayo, D. G., & Spanos, A. (2011). Error statistics. I n S. Bandyopadhyay, & M. R. Forster (Eds.), Handbook of philosophy of science: Philosophy of statistics (Vol. 7, pp. 152 – 198). Elsevier. Meehl, P . E. (1990). Appraising and amending theories: The strategy of Lakatosian defense and two principles that warrant it. Ps ychological Inquiry, 1 (2), 108 – 141. https://doi.org/10.1207/s15327965p li0102_1 Meehl, P . E. (1997 ). Th e problem is epistemology, not statistics: Replace significance tests by confidence intervals and quantify accuracy of risky numerical predictions. In L. L. Harlow, S. A. Mulaik, & J. H. Steiger (E ds.), What if there were no significance tests? (pp. 393 – 425). Lawrence Erlbaum. Miller, J. D., Phillips, N. L., & Lynam, D. R. (2025). Questionable research practices violate the American Psychological Association’s Code of Ethics. Journal of Psychopathology and Clinical Science, 134 (2), 113 – 114. https://doi.org/10.1037/abn0000974 Munroe, R. (2011). Significant . https://xkcd.com/882/ Murphy, S. L., Merz, R., Reimann, L. E., & Fernández, A. (2025). Nonsignificance misint erpreted as an effect’s absence in psychology: P revalenc e and temporal analyses. Royal Society Open Science, 12242167. http://doi.org/10.1098/rsos.242167 Nagy, T., He rgert, J., E lsherif, M. M., W allrich, L., Schmidt, K., Walt zer, T., Payn e, J. W., Gjoneska, B., Seetahul, Y., Wang, Y. A., Scharfenberg, D., Tyson, G., Yang, Y.- F., Stvortsova, A., Alarie, S., Graves, K., Sotola, L. K., Moreau, D., & R ubínová, E. (2025). Bestiary of questionable rese arch practices in psychology. Advance s in Methods and Practices in Psychological Science, 8 (3). https://doi.org/10.1177/25152459251348431 Neyman, J. (1950). First course in probability and statistics. Henry Holt. Neyman, J. (1952) . Lectures and c onferences on mathematical statistics and probability (2 nd ed.). Graduate School, US Department of Agriculture. https://doi.org/10.22004/ag.econ.327287 Neyman, J. (1955). The problem of inductive inference. Communications on Pure and Applied Mathematics, 8, 13 – 46. https://doi.org/10.1002/cpa.3160080103 Neyman, J., & P earson, E. S. (1928). On the use and interpretation of c ertain test criteria for purposes of statistical inference: Part I. Biometrika 20A (1/2) , 175 – 240. http:// doi.org/10.2307/2331945 Parker, R. A., & Weir, C. J. (2020). Non-adjustment for multiple testing in mul ti-arm trials of distinct treatme nts: Ra tionale and justification. Clinical Tria ls, 17 (5), 562 – 566. https://doi.org/10.1177/1740774520941419 Pickett, J. T., & Roch e, S. P. (2018). Questionable, objectionable or crimi nal? Public opinion on data fraud and selective reporting in science. Sci ence and Engineering Ethics , 24 , 151 – 171. https://doi.org/10.1007/s11948-017-9886-2 p -Hacking in the Formal Inference Approach 25 Pollard, P., & Richardson, J. T. (1987). On the probability of making Type I err ors. Psychological Bulletin , 102 (1), 159 – 163. https://doi.org/10.1037/0033-2909.102.1.159 Popper, K. R. (1966). The open society and its enemies (5 th ed.). Routledge. Popper, K. R. (1983 ). Re alism and the aim of scienc e: From the postscript to the logic of scientific discovery. Routledge. Popper, K. R. (1994). The myth of the framework: In defence of science and rationality. Psychology Press. Popper, K. R. (2002). The logic of scientific discovery. Routledge. Reichenbach, H. (1938 ). Experience and prediction: An analysis of the foundations and the structure of knowledge. Phoenix Books. Reis, D., & Friese, M. (2022). The myriad forms of p -hacking. In W. O'Donohue, A. Masuda, & S. Lilienfeld (Eds.), Avoi ding questionable research practices in appli ed psychology (pp. 101 – 121) . Springer. https://doi.org/10.1007/978-3-031-04968-2_5 Roy, S. N. (1953). On a heuristic method of test construction and its use in multivariate analysis. The Annals of Mathematical Statistics, 24 (2), 220 – 238. https://doi.org/10.1214/aoms/1177729029 Rubin, M. (2017a). Do p values lose their meaning in exploratory analyses? It dep ends how you define the familywise error rate. Review of General Psychology, 21 (3), 269 – 275. https://doi.org/10.1037/gpr0000123 Rubin, M. (2017b). An evaluation of four solution s to the forking paths problem: Adjusted alpha, preregistration, sensitivity analyses, and abandoning the Neyman-Pearson approach. Review of General Psychology, 21 (4) , 321 – 329. https://doi.org/10.1037/gpr0000135 Rubin, M. (2020). Doe s preregistration improve the credibility of research findings? The Quantitative Methods for Psychology, 16 (4), 376 – 390. https://doi.org/10.20982/tqmp.16.4.p376 Rubin, M. (2021a ). There’s no need to lower the significance threshold w hen conducting single tests of multiple individual hypothe ses. Academia Letters, 610. https://doi.org/10.20935/AL610 Rubin, M. (2021b). When to adjust alpha during multiple testing: A consideration of disjunction, conjunction, and individual testing. Synthese, 199 , 10969 – 11000. https://doi.org/10.1007/s11229-021-03276-4 Rubin, M. (2022). The costs of HARKing. British Journal for the Philosophy of Science, 73 (2), 535 – 560. https://doi.org/10.1093/bjps/axz050 Rubin, M. (2024a). Inconsistent mul tiple testing corrections: The fallacy of using family -based error rates to make inferences about individual hypotheses. Methods in Psychology, 10, 100140 . https://doi.org/10.1016/j.metip.2024.100140 Rubin, M. (2024b). Type I error rates are not us ually inflated. Journal of Trial and Error, 4 (2), 46 – 71 . https://doi.org/10.36850/4d35-44bd Rubin, M. (2025). Pre registration does not improve the transparent evaluation of severity in Popper’s philosophy of science or when deviations are allowed. Sy nthese, 206, 111. https://doi.org/10.1007/s11229-025-05191-4 Rubin, M., & Donkin, C. (2024). Exploratory hypothesis tests can be more compelling than confirmatory hypothesis tests. Philosophical Psychology, 37 (8), 2019 – 2047. https://doi.org/10.1080/09515089.2022.2113771 Selvin, H. C. (1958). Durkheim ’ s suicide and problems of empirical research. American Journal of Sociology, 63( 6), 607 – 619. https://doi.org/10.1086/222356 p -Hacking in the Formal Inference Approach 26 Simmons, J. P., Nelson, L. D., & Simonsohn, U. (2011). False-positive ps ychology: Undisclosed flexibility in data collection and analysis allows presenting anything as significant. Psychological Science, 22 (11), 1359 – 1366. https://doi.org/10.1177/0956797611417632 Spanos, A. (2010). Theory testing in economics and the error-statistical pers pective. In D. G. Mayo & A. Spanos (Eds.), Error and inf erence: Re cent exchanges on experimental reasoning, reliability, and the objectivity and rationality of science (pp. 202− 2 46 ). C ambridge University Press. Spanos, A., & Mayo, D. G. (2015). Error statisti cal modeling and inference: Where methodology meets ontology. Synthese, 192 (11), 3533 – 3555. https://doi.org/10.1007/s11229-015-0744- y Stefan, A. M., & Schönbrodt, F. D. (2023). Big litt le lies: A compendium and simulation of p - hacking stra tegies. Royal Society Open Science, 10 (2), 220346. https://doi.org/10.1098/rsos.220346 Waller, J. (2018 ). Division. In R. A rp, S. Barbone & M. Bruce (Eds. ), Bad arguments (pp. 259 – 260). Wiley. https://doi.org/10.1002/9781119165811.ch56 Wells, G. L., & Windschitl, P . D. (1999). Stimulus sampling and social psychological experimentation. Perso nality and Social Psychology Bulletin, 25 (9), 1115 – 1125. https://doi.org/10.1177/01461672992512005 Wicherts, J. M., Veldkamp, C. L., Augusteijn, H. E., Bakker, M., Van Aert, R. C., & Van Assen, M. A. (2016). Degrees of freedom in planning, running, analyzing, and reporting psychological studies: A checklist to avoid p -hacking. Frontiers in Psych ology, 7 , 1832. https://doi.org/10.3389/fpsyg.2016.01832 CRediT Statement: Mark Rubin: Conceptualization, Visualization, Writing — original draft, Writing — reviewing & editing. Acknowledgmen ts : N/A Generative AI : ChatGPT, Ge mini, an d Grammarly were used to chec k for typos, grammatical issues, argu ment inconsistencies, and potential mischaracterisations. The final text an d arguments are the author’s , and the y take full responsibility fo r all content. Funding: The author declare s no funding sources. Conflict of interest: T he author d eclares no conflict of interest. Peer review : This article has n ot yet undergone formal peer review. Biography : Mark Rubin is a professor of psychology at Durham University, UK. For further information about his work in this area, please visit h ttps://sites.google.co m/site/markrubinsocialpsy chresearch/replication -crisis Corresponden ce: Correspondence should be addressed to Mark Rub in at the Department of Psychology, Durham University, Sou th Road, Durham, DH1 3 LE, UK. E -mail: Mark-Ru bin@outlook.com Copyright © The Author(s). OPEN ACCESS: This material i s pu blished u nder the terms of the Creative Commons BY Attribution 4.0 International licen se (CC BY 4 .0 https://creativecomm ons.org/licenses/by/4.0 / ) . This license allows reu sers to distribute, remix, adapt, and build upon the m aterial in any med ium o r format, so long as attribution is given to th e creator. The license allows for co mmercial use.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment