p해킹은 오류통계 접근에서는 유형 I 오류를 증가시키지만 형식추론 접근에서는 그렇지 않다
본 논문은 p‑해킹이 오류통계(에러스태티스틱스) 접근에서는 실제 가족 전체 오류율을 상승시켜 명목적 0.05 수준을 초과하게 만들지만, 형식추론(포멀 인퍼런스) 접근에서는 보고된 개별 가설에 대해서는 명목적 오류율만이 적용되므로 오류율이 인위적으로 부풀려지지 않는다고 주장한다.
저자: Mark Rubin
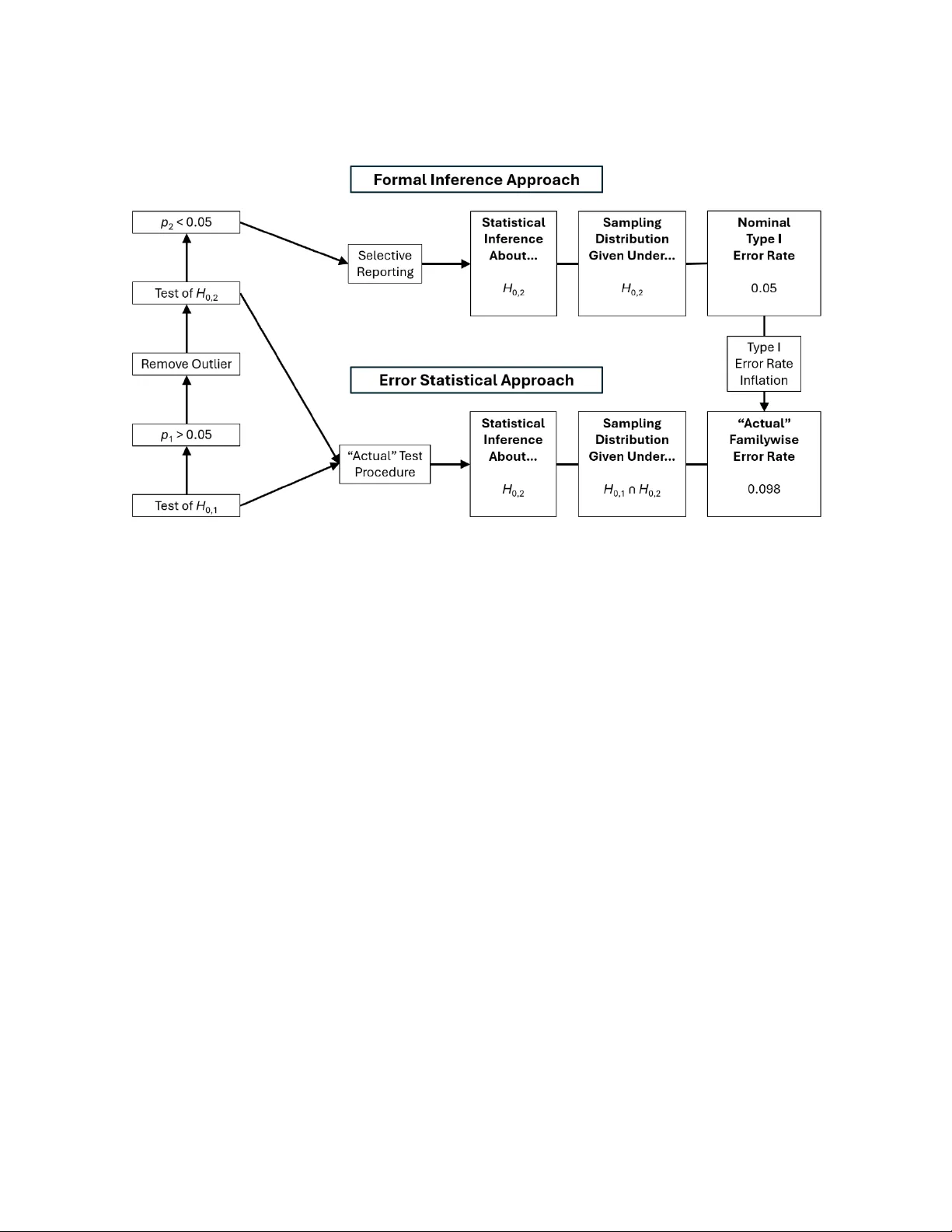
본 논문은 최근 학계에서 크게 우려되는 p‑해킹 현상을 두 가지 통계 철학적 관점에서 재검토한다. 첫 번째는 오류통계 접근(error statistical approach)이며, 두 번째는 형식추론 접근(formal inference approach)이다. 오류통계 접근은 마요(Mayo)와 스파노스(Mayo & Spanos)의 전통을 계승하여, 검정 절차 전체를 ‘실제(test procedure)’로 간주하고, 이 절차가 명시된 α 수준 이하의 오류율을 유지하는지를 평가한다. 여기서 p‑해킹은 연구자가 사전 계획 없이 다수의 가설을 검정하고, 유의한 결과만 선택적으로 보고함으로써 실제 가족 전체 오류율(FWER)이 명목 α보다 커지는 현상으로 정의된다. 예를 들어, 20개의 독립 검정을 수행하고 하나만 보고한다면 실제 FWER은 1‑(1‑0.05)²⁰≈0.64가 되며, 이는 명목 0.05를 크게 초과한다. 오류통계 학자들은 이러한 상황을 ‘biasing selection effect’라 부르며, 검정 절차가 ‘심각도(severity)’ 기준을 충족하지 못해 ‘나쁜 증거, 무검정(BENT)’ 상태에 빠진다고 경고한다. 따라서 오류통계 관점에서는 p‑해킹이 직접적으로 유형 I 오류를 부풀리는 문제로 간주된다.
반면 형식추론 접근은 저자(루빈)의 최근 연구를 토대로, 연구자가 공개적으로 보고한 통계적 추론 자체에 초점을 맞춘다. 여기서는 보고된 추론이 어떤 형태인지에 따라 적용되는 오류율이 달라진다. 세 가지 추론 유형이 정의된다. 첫째, ‘개별(inidividual) 추론’에서는 각 영가설에 대해 α만 적용되며, 다중 검정이 있더라도 개별 영가설에 대한 오류 기회는 하나뿐이다. 둘째, ‘합집합‑교집합(union‑intersection) 추론’에서는 여러 영가설의 교집합에 대한 검정이며, 이 경우 전체 가족에 대한 FWER가 적용된다. 하지만 이 오류율은 교집합 영가설 전체에 대한 하나의 결정만을 의미하고, 개별 영가설을 개별적으로 기각할 권한을 주지는 않는다. 셋째, ‘교집합‑합집합(intersection‑union) 추론’에서는 영가설의 합집합에 대한 검정이며, 여기서도 명목 α만 사용된다.
형식추론 접근은 네 가지 원칙을 제시한다. 첫째, 오류율은 무작위 표본오차만을 반영하고 체계적 오류(이론적, 방법론적, 데이터적, 분석적 오류)와는 구별된다. 둘째, 서로 다른 검정의 오류율은 독립적이며 직접 비교하거나 ‘inflated’라는 표현을 쓰는 것이 부적절하다. 셋째, 가족 전체 오류율은 개별 영가설에 대한 오류를 의미하지 않으며, 따라서 개별 추론에 적용해서는 안 된다. 넷째, 보고된 추론의 형태와 수에 따라 적절한 오류율을 선택해야 한다.
이러한 논리 전개를 통해 저자는 p‑해킹이 오류통계 접근에서는 실제 오류율을 부풀려 유형 I 오류를 증가시키지만, 형식추론 접근에서는 보고된 개별 가설에 대해서는 명목 α만 적용되므로 오류율이 인위적으로 상승하지 않는다고 주장한다. 또한, 비공개 영가설 결과를 누락하는 행위가 실질적인(내용적) 추론에 편향을 초래할 수는 있지만, 이는 통계적 유형 I 오류와는 별개의 문제이며, 형식추론에서는 이를 별도 논의 대상으로 남긴다. 마지막으로, 두 접근법 사이의 공통점과 차이점을 정리하고, p‑해킹을 감소시키기 위한 실천적 방안(사전등록, 투명한 보고, 검정 절차 감사 등)을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기