Provably Safe Generative Sampling with Constricting Barrier Functions
Flow-based generative models, such as diffusion models and flow matching models, have achieved remarkable success in learning complex data distributions. However, a critical gap remains for their deployment in safety-critical domains: the lack of for…
Authors: Darshan Gadginmath, Ahmed Allibhoy, Fabio Pasqualetti
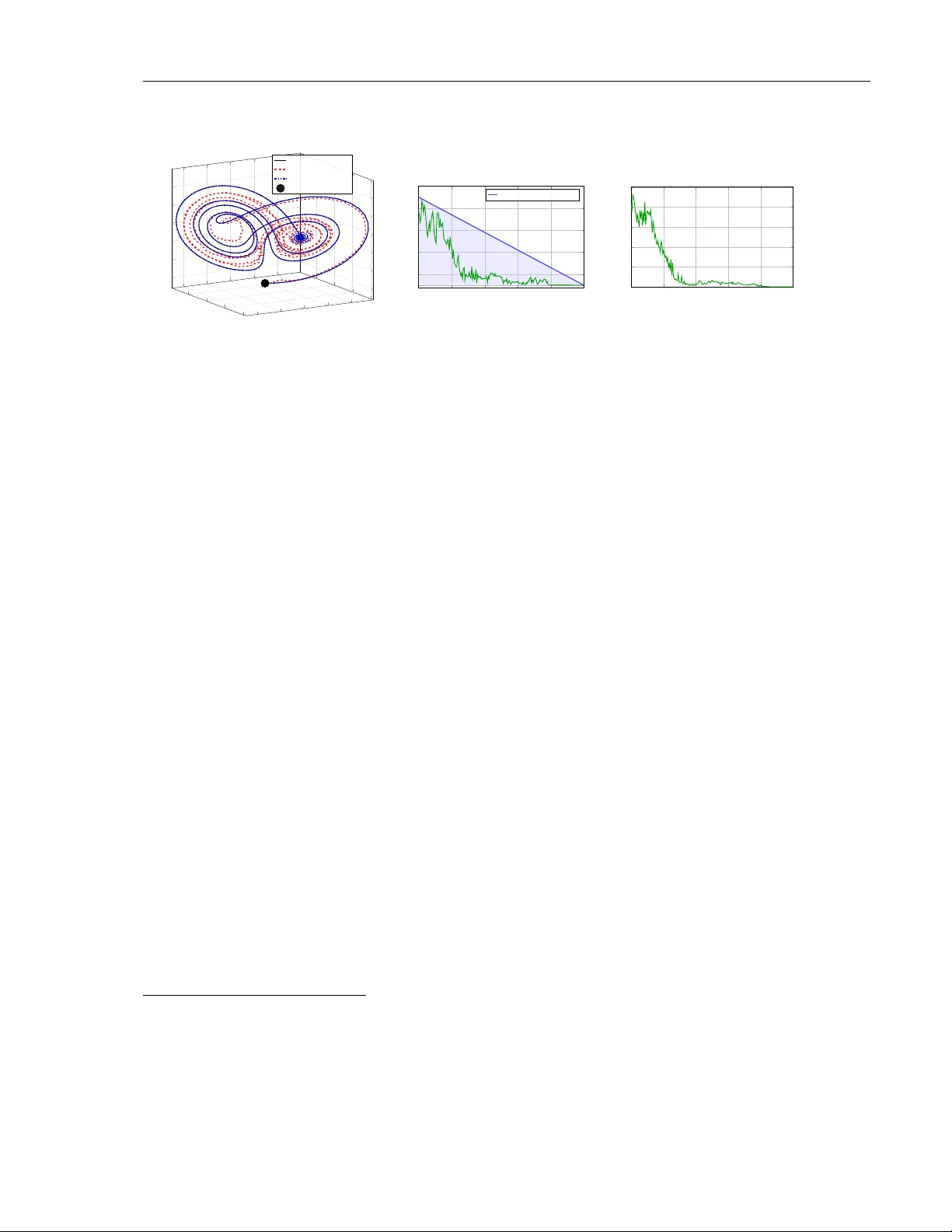
Provably Safe Generative Sampling with Constricting Ba rrier F unctions Darshan Gadginmath dgadg001@ucr.e du Me chanic al Engine ering University of California, Riverside Ahmed Allibho y aal libho@uci.e du Ele ctric al Engine ering and Computer Scienc e University of California, Irvine F abio P asqualetti fabiop as@uci.e du Ele ctric al Engine ering and Computer Scienc e University of California, Irvine Abstract Flo w-based generativ e models, such as diffusion mo dels and flo w matching mo dels, ha v e ac hiev ed remarkable success in learning complex data distributions. Ho w ev er, a critical gap remains for their deploymen t in safet y-critical domains: the lac k of formal guarantees that generated samples will satisfy hard constraints. W e address this by prop osing a safety filtering framew ork that acts as an online shield for any pre-trained generativ e mo del. Our k ey insigh t is to co op erate with the generativ e pro cess rather than ov erride it. W e define a constricting safet y tube that is relaxed at the initial noise distribution and progressively tightens to the target safe set at the final data distribution, mirroring the coarse-to-fine structure of the generative pro cess itself. By c haracterizing this tub e via Con trol Barrier F unctions (CBF s), w e syn thesize a feedback control input through a conv ex Quadratic Program (QP) at each sampling step. As the tub e is lo osest when noise is high and interv ention is cheapest in terms of con trol energy , most constraint enforcemen t occurs when it least disrupts the mo del’s learned structure. W e pro ve that this mec hanism guaran- tees safe sampling while minimizing the distributional shift from the original mo del at eac h sampling step, as quantified by the KL div ergence. Our framework applies to any pre-trained flow-based generativ e scheme requiring no retraining or architec- tural mo difications. W e v alidate the approac h across constrained image generation, ph ysically-consisten t tra jectory sampling, and safe rob otic manipulation policies, ac hieving 100% constraint satisfaction while preserving semantic fidelity . 1 Intro duction Flo w-based generativ e mo dels suc h as diffusion models (Ho et al., 2020; Song et al., 2021), flow matc hing (Lipman et al., 2023), and contin uous normalizing flows (Papamakarios et al., 2021) hav e 1 redefined the state-of-the-art in learning complex, high-dimensional distributions. By transforming a simple prior noise distribution into a structured data distribution through a sequence of infinites- imal steps, these mo dels excel in tasks suc h as molecular design (W eiss et al., 2023), high-fidelit y image synthesis (Ho et al., 2022), and con trol policies for robots (Chi et al., 2025). The deplo y- men t of these mo dels increasingly requires constrain t satisfaction across diverse applications. In con ten t generation, constraints ensure human alignmen t, whic h requires filtering harmful conten t in images (Schramo wski et al., 2023) or preven ting toxic text generation (Li et al., 2025). In safety- critical physical systems suc h as rob otics (Janner et al., 2022; Chi et al., 2025) or autonomous na vigation (Liao et al., 2025), constrain ts encode in violable ph ysical la ws or safety sp ecifications suc h as dynamical feasibility , joint limits, collision a v oidance, smoothness, etc. T raditional soft guidance techniques, suc h as classifier-based, classifier-free (Dhariwal & Nichol, 2021; Ho & Salimans, 2021) or rew ard-w eigh ted guidance (Y uan et al., 2023), merely act as proba- bilistic incentiv es. While they bias the mo del tow ard desired regions, they cannot provide prov able guaran tees of feasibility . Con v ersely , pro jection-based methods can guaran tee safet y by formally pro jecting completed samples onto a safe manifold (Fishman et al., 2023; Utkarsh et al., 2025), y et they often suffer from significant computational ov erhead and in tro duce large distributional shifts. x ( T ) ∼ p T Unsafe sample x ( t ) Safety tub e ˜ C ( t ) Safe set C Unguided sampling pro cess: d x = f θ ( x, t )d t + g ( t )d w Safe sampling pro cess: d x = [ f θ ( x, t ) + u ]d t + g ( t )d w , s.t. x ( t ) ∈ ˜ C ( t ) for all t Figure 1: Constr aine d gener ative sampling with a c onstricting safety tub e. The flow-based sampling pro cess transforms noise sample x ( T ) into data x (0) . Unc onstr aine d sampling pr o c ess can pro duce unsafe samples that violate constrain ts, landing outside the required safe set. Our control barrier function-guided sampling augmen ts the generativ e dynamics with feedback con trol inputs u that main tain the sample within the constricting safety tub e ˜ C ( t ) (green region) throughout the sampling pro cess, guaran teeing safe samples and minimal p erturbation of the learned sampling process. T o address this gap, we prop ose a guidance sc heme motiv ated by safety filtering in con trol theory . By leveraging Control Barrier F unctions (CBF s), we syn thesize a feedback con trol input through a Quadratic Program (QP) that aims to retain the fidelity of the original mo del. Our k ey insigh t is the use of a constricting safety tube ˜ C ( t ) that is relaxed at the high-noise regime ( t = T ) and progressiv ely constricts to the target safe set C at the data distribution ( t = 0 ). As illustrated in 2 Figure 1, this ensures that the final sample belongs to the safe set while formally bounding the distributional shift b et w een the original mo del and the safe distribution. W e frame the guidance problem as a problem of control syn thesis. The goal is to inject a feedbac k control input u in to the sampling pro cess to render the safet y tub e ˜ C ( t ) inv ariant, ensuring that tra jectories prov ably remain within the safety tub e for the entire duration. CBF s pro vide the mathematical framew ork needed to synthesize suc h con trol inputs with formal safety certificates regarding the membership of x ( t ) in ˜ C ( t ) . Our framework ensures that the sample at the final sampling step x (0) lies within the safe set C which satisfies the required constraints. A t each sampling step, we solve a constrained optimal con trol problem that minimizes control effort to preserv e distributional fidelity while enforcing a CBF constrain t that guaran tees x ( t ) ∈ ˜ C ( t ) for all t ∈ [0 , T ] . Unlik e prior CBF-based approaches (Xiao et al., 2023; Y ang et al., 2025; Dai et al., 2025) that emplo y prescrib ed-time con v ergence or p ost-ho c tra jectory correction, our metho d enforces strict in v ariance of a constricting safety tub e that tigh tens during the sampling pro cess, providing safety guaran tees on sampling. Our main contributions are: 1. Pr ovably safe sampling: F or an y closed and b ounded set C , w e pro ve that our guidance mec hanism based on CBF s ensures that the final sample x (0) ∈ C . Importantly , we mak e no assumptions ab out the con vexit y of the safe set. 2. Co op er ation with the gener ative pr o c ess: Our constricting safety tube mirrors the coarse- to-fine structure of flow-based sampling, concentrating constrain t enforcemen t in the high- noise regime where in terven tions are distributionally c heap. This ensures that the mo del retains full authorit y o v er the seman tic structure and fine details. W e pro ve that our minim um-norm control minimizes the p er-step contribution to the KL divergence b et w een the safe and original distributions. 3. Mo dular guidanc e : Our guidance sc heme can be applied to an y pre-trained flo w-based generativ e model at sampling time, requiring no retraining or architectural mo difications. W e v alidate our approac h on three differen t experiments: sim ulation of nonlinear ph ysics, con- strained image generation, safety-critical planning in rob otics. 2 Related W o rk The literature on enforcing constraints in generativ e mo dels is rapidly gro wing, typically bifurcated in to metho ds that provide probabilistic incentiv es and those that formally enforce hard constrain ts. Soft guidance and probabilistic steering. Soft guidance metho ds generally mo dify the sam- pling pro cess by adding a p enalty or a steering term that biases the model to ward desired regions of the data distribution. Classifier guidance (Dhariw al & Nic hol, 2021) utilize the probabilistic confi- dence from a classifier, or implicitly compute confidence in classifier-free guidance Ho & Salimans (2021) to steer the score function to wards sp ecific attributes or labels. Similarly , rew ard-guided metho ds Y uan et al. (2023) prioritize trajectories that maximize rew ards, while gradien t-based approac hes (Guo et al., 2024) steer sampling via optimization objectives. While these metho ds effectiv ely increase the lik eliho o d of constrain t satisfaction, they do not provide formal guarantees of admissibility . They lack a mechanism to explicitly ensure safe sampling. They are fundamentally 3 probabilistic and ma y still pro duce samples that violate safet y guidelines, making them unsuitable for safet y-critical hardware where failure is imp ermissible. Strict guidance with pro jection. T o address the need for deterministic certificates, several hard enforcement framew orks hav e recently emerged, largely focused on projection. Pro jection- based approac hes (Fishman et al., 2023; Utkarsh et al., 2025; Römer et al., 2024; Gadginmath & P asqualetti, 2025; Zampini et al., 2025) pro ject unconstrained samples on to a v alid manifold of samples at each sampling step. Classically , constraining a sto chastic pro cess to a domain is framed as a Skorokhod problem, whic h utilizes reflected SDEs (Lou & Ermon, 2023) to push the pro cess bac k in to the set whenever it reaches the b oundary of the domain. While mathematically elegant, these approaches can b e computationally intensiv e for complex, non-con vex sets and ma y introduce distributional shifts when the reflection direction is not w ell-aligned with the learned drift. CBF-based guidance in sampled rob otic planning and con trol. A recen t line of literature in sampling based rob otic planning and control hav e increasingly turned to CBF s (Mizuta & Leung, 2024; Dai et al., 2025; Xiao et al., 2023; Y ang et al., 2025) to transform soft heuristics in to formal safet y certificates. Mizuta & Leung (2024) use a CBF-CLF framew ork to define a reward function, whic h is in turn used for rew ard-based guidance. Both Dai et al. (2025) and Xiao et al. (2023) emplo y prescrib ed-time CBF mechanisms with singular class- K functions that enforce conv ergence to the safe set by a deadline, requiring high-gain feedback that can lead to aggressive steering. Y ang et al. (2025) adopts a prediction-correction architecture that generates a candidate path in laten t space and then corrects it in a separate, post-ho c phase. In contrast, our metho d enforces strict inv ariance throughout the entire sampling pro cess by utilizing a constricting safety tub e. This ensures the particle remains safe at every integration step, rather than only at the final time. By using a minimum-norm control synthesis ob jective, we maintain maximal mo del fidelity without the need for high-gain steering. Our approach integrates the safet y barrier directly in to the sampling dynamics as a control interv ention. W e pro v e that our metho d minimizes the per-step contribution to the KL divergence b etw een the safe and learned distributions. 3 Prelimina ries: Flo w-based sampling and CBF s Here we introduce essential mathematical preliminaries. W e introduce generativ e sampling from the persp ective of dynamical systems and the use of CBF s for safe con trol. 3.1 Flo w-based sampling as a dynamical system W e formalize generative sampling as the trajectory of an autonomous system that transforms a prior noise distribution into a target data distribution. W e define t ∈ [0 , T ] as the sampling time, where p ( T ) is the initial noise distribution at t = T , and p (0) is the final data distribution at t = 0 . The sampling pro cess is go verned by a Sto chastic Differential Equation (SDE): d x = f θ ( x, t )d t + g ( t )d w , (1) where the sample is x ( t ) ∈ R n , and f θ ( x, t ) is the drift v ector field. The noise sc hedule g ( t ) is time-dependent, and d w is a reverse-time Wiener process (Song et al., 2021), reflecting that t decreases from T to 0 during sampling. W e are able to capture a large family of flo w-based 4 generativ e models using this notation. F or example, in score-based diffusion mo dels (Song et al., 2021), f θ ( x, t ) = − 1 2 x − g 2 ( t ) ∇ x log p ( x, t ) where the score ∇ x log p ( x, t ) is approximated by a neural net w ork. In flow matching (Lipman et al., 2023), f θ = NN θ ( x, t ) directly learns the v elo city field that generates optimal transp ort paths betw een noise and data distributions. F or deterministic framew orks lik e flow matching, the noise term v anishes, i.e. g ( t ) = 0 , reducing the dynamics to an Ordinary Differen tial Equation (ODE). While the SDE (1) describes individual sample paths, it induces a corresponding evolution of the population’s probability densit y p ( x, t ) as t decreases from T to 0 . This progression has an imp ortan t structural prop erty: in the high-noise regime ( t ≈ T ), the broad support of p ( x, t ) means the model establishes only global, coarse structure. As t → 0 and the distribution concentrates to w ard the data distribution p (0) , the mo del progressively resolves finer details. W e refer to this as the c o arse-to-fine structure of flo w-based sampling, and our constricting safety tub e in section 4 is designed to mirror this progression. This coarse-to-fine progression has a direct consequence for constrained sampling: in terven tions applied during the high-noise regime, where the mo del has not y et committed to fine-grained structure, are less disruptive than those applied near t = 0 when the sample has nearly conv erged. 3.2 Control Barrier Functions for Set Inva riance Consider a system whose state x ( t ) ∈ R n ev olv es as t decreases from T to 0 , gov erned b y: d x = f ( x, u ) d t, (2) where u ∈ R m is the control input. Since t decreases during sampling, d t < 0 throughout, and f ( x, u ) represents the drift of the reverse-time dynamics, consisten t with the sampling process (1). Assume that we are given a set C ⊂ R n of “safe” states, giv en by the sup erlevel set of a contin uously differen tiable function h : R n → R : C = { x ∈ R n | h ( x ) ≥ 0 } . (3) W e seek to design a feedback controller that ensures the state remains in C throughout the sampling pro cess. This is accomplished using a feedback con troller design based on control barrier functions Ames et al. (2016; 2019). F ormally , we sa y C is r everse invariant 1 if, for an y terminal condition x ( T ) ∈ C , the resulting trajectory satisfies x ( t ) ∈ C for all t ∈ [0 , T ] as t decreases from T to 0 . Equiv alen tly , if h ( x ( T )) ≥ 0 , we need that h ( x ( t )) ≥ 0 for all t ∈ [0 , T ] . W e say that h is a r everse-time c ontr ol b arrier function 2 if for all x ∈ C , there exists a u ∈ R m ∇ h ( x ) · f ( x, u ) ≤ γ ( h ( x )) . (4) where γ is a class- K function, i.e. γ is contin uous, strictly increasing, and γ (0) = 0 . If h is a rev erse-time CBF, then any feedback controller u ( x, t ) that satisfies (4) renders C reverse inv arian t. 1 Note that standard literature in safety-critical control deals with con trol systems that evolv e forward in time, hence the results deriv e conditions for forward inv ariance. Since we are controlling generative sampling dynamics that evolv e bac kward in time, we instead consider the problem of enforcing reverse in variance. Our presentation closely follows Ames et al. (2019), ho wev er the CBF condition (4) is mo dified to b e consisten t with the change in direction of time. 2 F or brevity , we henceforth refer to reverse-time control barrier functions simply as CBF s since we only deal with systems evolving backw ard in time. 5 The condition, (4) ma y b e understo o d in tuitiv ely as follo ws: to maintain reverse in v ariance of C we require that for any trajectory x ( t ) that reac hes the boundary ∂ C , i.e. h ( x ( t )) = 0 , there exists an input u ∈ R m suc h that dh dt ≤ 0 . Since t is decreasing, dh dt ≤ 0 implies that h is increasing. This ensures that, in reverse time, h increases, and the tra jectory remains on the b oundary or returns to the in terior of C . The CBF condition (4) enforces this condition gradually throughout the entire safe set: if x ( t ) is instead in the in terior of C , γ ( h ( x ( t ))) > 0 , p ermitting inputs suc h that dh dt > 0 , while con tinuit y of γ still guaran tees that dh dt → 0 and x → ∂ C . 4 Guidance of flow-based mo dels via constricting CBF s Ha ving established the sampling dynamics (1) and the CBF framework for safe con trol, we now address the central question: ho w can w e enforce hard constraints on the output of a pre-trained generativ e model without mo difying the model itself ? The k ey observ ation is that by introducing a con trol input to the sampling SDE (1), we arrive at a control-affine structure for the control systems in Section 3.2. This additive control input u can be designed to steer sampling trajectories tow ard the safe set while preserving the learned distribution. W e frame this as a con trol syn thesis problem where the guided sampling pro cess is gov erned b y: d x = [ f θ ( x, t ) + u ( x, ξ , t )]d t + g ( t )d w , t ∈ [ 0 , T ] , (5) where f θ is the unconstrained drift learned by the generative mo del, g ( t ) is the noise schedule, d w is a Wiener process, and u ( x, ξ , t ) is the feedback con trol that dep ends on the curren t state x and the realized noise 3 ξ = d w / d t . The challenge is to design u so that it provides formal safety guarantees while remaining minimally inv asive, interv ening only when necessary and as little as p ossible. Note that our prop osed feedbac k controller dep ends b oth on the state of the system and the noise pro cess. Although this assumption may b e restrictive in settings where the feedbac k con troller regulates a physical system, and the noise cannot be directly measured, in our application w e ha v e full kno wledge of the noise pro cess since the system is b eing sim ulated on a computer. This assumption allo ws us to ensure that reverse inv ariance holds exactly for the sto chastic system, whereas other approac hes that consider feedback con trollers dep ending only the state do not hav e suc h guaran tees (c.f. Remark 1). 4.1 CBF s for flo w-based generative sampling A fundamental challenge in generative sampling is that the initial prior noise x ( T ) is dra wn from a distribution that is easy to sample from, typically the standard Gaussian. This means that x ( T ) almost certainly resides outside the target safe set C . T raditional CBF formulations for static sets w ould require an immediate, high-energy interv ention to push x ( t ) close to C , which would violate the model’s generativ e in tent and pro duce samples that no longer represent the learned distribution. Our framew ork is motiv ated by the need for minimal interv entions and a smooth approac h tow ards C . W e achiev e this by defining a constricting barrier ˜ h ( x, t ) = h ( x ) + ϵ ( x ( T ) , t ) . This is a time-v arying barrier that constricts with the sampling pro cess. W e characterize safety 3 W e say that ξ : [0 , T ] → R n is the r e alize d noise to a Wiener pro cess w if R t 0 ξ ( τ ) dτ = w ( t ) for all t ∈ [0 , T ] . Although w is not contin uously differen tiable, ξ may b e thought of as a formal deriv ative the Wiener pro cess. 6 through a constricting sup erlevel tub e ˜ C ( t ) with resp ect to the constricting barrier ˜ h as, ˜ C ( t ) = { x ∈ R n | ˜ h ( x, t ) ≥ 0 } . (6) W e design ˜ C ( t ) such that initially , the set ˜ C ( T ) is sufficien tly relaxed to contain the noise sample x ( T ) , and at the end of sampling, it recov ers the target set C , i.e., ˜ C (0) = C . Since the sampling pro cess ev olves in rev erse time from t = T to t = 0 , the safety tube ˜ C ( t ) must remain occupied b y x ( t ) as t decreases, a prop erty we term r everse invarianc e . As derived in Section 3.2, the reverse- time CBF condition requires b ounding ∇ ˜ h · f from ab ov e. The follo wing design of the constricting barrier function handles this through a time-v arying control barrier function. Definition 1 (Constricting barrier function) Given a CBF h : R n → R and a terminal c on- dition x ( T ) ∈ R n , a c onstricting b arrier function is ˜ h ( x, t ) = h ( x ) + ϵ ( x ( T ) , t ) , wher e ϵ is a C 1 function satisfying: 1. Initial fe asibility: ϵ ( x ( T ) , T ) ≥ max (0 , − h ( x ( T ))) . 2. R e c overy of tar get set: ϵ ( x ( T ) , 0) = 0 . 3. Monotone c onstriction: ∂ ϵ/∂ t ≥ 0 for al l t ∈ [0 , T ] . Sinc e t de cr e ases fr om T to 0 during sampling, this me ans ϵ de cr e ases as sampling pr o gr esses, c onstricting ˜ C ( t ) towar d C . The asso ciate d c onstricting safety tub e is ˜ C ( t ) = { x ∈ R n | ˜ h ( x, t ) ≥ 0 } . The following result sho ws ho w to ensure that the sampling process (5) can be made inv arian t to the safet y tub e ˜ C ( t ) using a constricting barrier function. Theorem 4.1 (Rev erse inv ariance) L et ˜ h b e a c onstricting b arrier function and γ a class- K function. F or e ach noise r e alization { ξ ( t ) } t ∈ [0 ,T ] as t de cr e ases fr om T to 0 , if ther e exists a c ontr ol u ( x, ξ , t ) such that ∇ x ˜ h ( x, t ) · ( f θ ( x, t ) + u ( x, ξ , t ) + g ( t ) ξ ( t )) + ∂ ˜ h ( x, t ) ∂ t ≤ γ ( ˜ h ( x, t )) , (7) then the guide d sampling pr o c ess ensur es x ( t ) ∈ ˜ C ( t ) for al l t ∈ [0 , T ] , and in p articular x (0) ∈ C . W e refer the reader to App endix A.1 for a formal pro of. Theorem 4.1 establishes that any control u satisfying the CBF condition (7) guaran tees x (0) ∈ C , regardless of the con vexit y of C , the arc hitecture of f θ , or the location of the initial noise sample x ( T ) . The k ey mec hanism is the in terpla y b et ween the constriction and the class- K function. At the onset of sampling ( t ≈ T ), ˜ h = h + ϵ is large due to the relaxation ϵ . As sampling progresses, ϵ → 0 and ˜ h → h , so γ ( ˜ h ) shrinks and the constraint tigh tens tow ard the standard CBF condition for C guided by the feedback control u ( x, ξ , t ) . By this point, the learned model f θ has already resolved the trajectory close to C , and the con trol u needs only to enforce the final constraint b oundary . Many fixed-time conv ergence schemes rely on singular class- K functions that blow up as t → 0 (Xiao et al., 2023; Dai et al., 2025). In con trast, our C 1 constriction mimics the coarse-to-fine generation sc heme of typical flo w-based mo dels, ensuring that any feasible con trol remains b ounded and minimally inv asive. 7 Remark 1 (Comparison to other approac hes to extending CBF s to sto c hastic systems) Unlike other works that c onsider the pr oblem of designing fe e db ack c ontr ol lers that enfor c e safety of sto chastic dynamic al systems Clark (2021), our appr o ach assumes that the fe e db ack c ontr ol ler has know le dge of the state as wel l as the noise. While this assumption is mor e r estrictive, it al lows us to obtain str onger guar ante es. In p articular, with our design appr o ach, we c an enfor c e invarianc e of the c onstricting safety tub e exactly, wher e as by So et al. (2023), invarianc e do es not exactly or almost sur ely for the CBFs c onsider e d in Clark (2021). Theorem 4.1 provides safet y given the noise realization ξ ( t ) . At eac h step, w e first observe the noise realization ξ ( t ) ∼ N (0 , I ) , then syn thesize u = u ( x, ξ , t ) to ensure safet y giv en the observ ed noise. This paradigm is conditioned on the observ ed noise at each step, pro viding deterministic safet y for each tra jectory realization rather than safety in expectation. While Gaussian noise has un b ounded supp ort and extreme realizations could theoretically require large con trol effort, our exp erimen ts (Section 5) demonstrate reliable feasibilit y across diverse applications. Alternative form ulations that use mo del predictiv e con trol require sto chastic CBF s (Pra jna et al., 2004) to predict the behavior of mo del and the noise. Here, c hance constrain ts can pro vide formal high- probabilit y b ounds b y incorp orating safet y margins proportional to the noising sc heme g ( t ) . W e defer suc h extensions to future work. W e now discuss candidates for the constriction scheme ϵ ( x ( T ) , t ) . Let ϵ 0 = max(0 , − h ( x ( T ))) denote the initial constrain t violation. A key practical adv antage of Definition 1 is that its conditions are mild enough to b e satisfied by a broad family of simple, closed-form functions. W e present three suc h candidates: (1) Line ar : ϵ ( x ( T ) , t ) = ϵ 0 · ( t/T ) with constant constriction rate; (2) Exp onential : ϵ ( x ( T ) , t ) = ϵ 0 · ( e λt/T − 1) / ( e λ − 1) for λ > 0 , which front-loads relaxation when λ > 1 , providing aggressiv e early in terven tion and gentler later refinement; (3) Polynomial : ϵ ( x ( T ) , t ) = ϵ 0 · ( t/T ) p for p ≥ 1 , whic h bac k-loads constriction when p > 1 , offering slow er initial relaxation and faster final con vergence. All sc hemes satisfy Definition 1 b y construction, and the shap e parameter ( λ or p ) giv es practitioners direct control ov er when along the sampling tra jectory the constriction pressure is concentrated. Minim um-norm con trol syn thesis. T o ensure lo w-energy in terven tions that preserv e model fidelit y , we synthesi ze the control as: min u 1 2 ∥ u ∥ 2 s.t. ∇ x ˜ h ( x, t ) · ( f θ ( x, t ) + u + g ( t ) ξ ( t )) + ∂ ϵ ( x ( T ) , t ) ∂ t ≤ γ ( ˜ h ( x, t )) , (8) where the optimization is p erformed for the current state-noise pair ( x, ξ ) at time t , yielding the con trol u ∗ ( x, ξ , t ) . Remark 2 (F easibilit y of the QP (8) ) The ab ove QP is a minimum-norm pr oblem with a sin- gle line ar c onstr aint of the form a ⊤ u ≤ b , wher e a = ∇ x ˜ h ( x, t ) and b = γ ( ˜ h ) − ∇ x ˜ h · ( f θ + g ξ ) − ∂ ϵ ∂ t . When b ≥ 0 , the unc ontr ol le d drift alr e ady satisfies the CBF c ondition and u ∗ = 0 . When b < 0 , the QP admits the close d-form solution u ∗ = ( b/ ∥ a ∥ 2 ) a whenever a = 0 , which p oints in the −∇ x ˜ h di- r e ction, ste ering the state to satisfy the b arrier c ondition. Equivalently, u ∗ = min(0 , b/ ∥ a ∥ 2 ) a . The r e gularity assumption ∇ h ( x ) = 0 for x ∈ ∂ C ensur es that a = 0 in a neighb orho o d of the c onstr aint b oundary wher e intervention is ne e de d. In the interior of ˜ C ( t ) wher e ˜ h ( x, t ) ≫ 0 , the c onstr aint is 8 slack and u ∗ = 0 . Conse quently, the QP is always fe asible for any finite noise r e alization ξ , and infe asible in the de gener ate c ase ∥ ξ ∥ → ∞ , which o c curs with pr ob ability zer o under Gaussian noise. The follo wing result c haracterizes the distributional shift induced by our guidance. Theorem 4.2 (Distribution shift for guided sampling) L et p (0) b e the pr ob ability distribu- tion gener ate d by the unc onstr aine d sampling pr o c ess (1) , and let p safe (0) b e the distribution r esult- ing fr om the guide d dynamics in (5) with additive c ontr ol u . The K ul lb ack-L eibler (KL) diver genc e b etwe en the safe and original distributions is given by: D KL ( p safe (0) ∥ p (0)) = 1 2 E p safe (0) " Z T 0 ∥ u ( x, t ) ∥ 2 g ( t ) 2 d t # . (9) W e refer the reader to App endix A.2 for the pro of. The minimum-norm con trol u ∗ = arg min ∥ u ∥ 2 sub ject to (7) is a greedy minimizer of the instantaneous contribution to KL divergence b etw een the safe and learned distributions at eac h sampling instance. While this strategy does not guarantee global optimality ov er the en tire sampling horizon, it provides the tightest instan taneous b ound on the distributional shift at each step. The factor 1 g ( t ) 2 in (9) rev eals that con trol interv entions are c heap est in distributional terms when the noise level g ( t ) is large. Our constricting safet y tub e is designed to exploit this structure. Flow-based models perform coarse-to-fine refinement: the high-noise phase ( t ≈ T ) establishes global structure, while the lo w-noise phase ( t ≈ 0) resolves fine details. The safety tub e mirrors this progression, maximally relaxed when noise is high and tigh tening only as the mo del refines local details. As the tub e is lo osest precisely when interv ention is c heap est, most constraint enforcemen t is absorb ed during the high-noise regime at minimal distributional cost. By the time the mo del enters the low-noise regime where fine details are resolved, and in terven tion is expensive, the tub e has already guided the tra jectory close to the safe set, and u ∗ ≈ 0 . The mo del thus retains full authorit y ov er the structure and details that determine sample qualit y . When the safe set C o v erlaps significan tly with supp ( p (0)) , the learned drift f θ already steers samples to ward safety , requiring minimal control effort throughout. When C is disjoint from supp ( p (0)) , the QP identifies the closest safe distribution under the greedy minimization. The QP in (8) minimizes ∥ u ∥ 2 at every state-time pair ( x, t ) independently . The resulting control u ∗ is a minimizer of the instantaneous KL divergence rate ∥ u ∥ 2 /g ( t ) 2 . In deterministic regimes g ( t ) = 0 , suc h as flow matc hing, our framework naturally transitions in to a minimal L 2 drift perturbation. Exact minimization of the distribution shift ov er the full horizon requires solving an optimal control problem o ver the whole horizon [0 , T ] . This in volv es the prediction of the b ehavior of the model, and taking into account future noise realizations. Since the state tra jectory under the con trolled pro cess dep ends on the full history of past con trols, point wise minimization do es not, in general, yield the global optimal policy o ver all feasible control sequences. How ever, u ∗ in (8) pro vides a principled strategy that minimizes the instantaneous contribution to the KL divergence b etw een the final distributions at each step, yielding a strong upp er b ound on the total distributional shift o v er the whole sampling pro cess. In the stochastic regime when g ( t ) > 0 , this greedy p olicy is the tigh test single-step b ound av ailable. Our metho d of refining the CBF o ver the sampling horizon stands in contrast to pro jection-based metho ds, which apply corrections indep endently of the noise sc hedule and therefore pay the same distributional cost at ev ery step, disrupting global structure when applied early and o verriding fine 9 details when applied late. The exp erimental consequence is visible in Figure 4: pro jection-based enforcemen t (b) satisfies the constraint but destro ys semantic coherence, whereas our CBF-guided sampling (a, c) preserv es realistic scene structure by deferring to the mo del during the critical structure-forming phase. Ha ving established the theoretical foundations for safe sampling, w e now turn to practical implementation. 4.2 Discrete-time implementation W e now discuss the discretization of our contin uous-time framew ork into a practical algorithm for guided sampling. W e discretize the sampling interv al [0 , T ] into K steps of size ∆ t = T /K , with time indices t k = T − k ∆ t for k = 0 , 1 , . . . , K , and write x k = x ( t k ) for brevit y . The discrete-time ev olution under the Euler-Maruyama scheme follows: x k − 1 = x k − [ f θ ( x k , t k ) + u k ( x k , ξ k , t k )]∆ t + g ( t k ) √ ∆ t ξ k , (10) where ξ k ∼ N (0 , I ) . T o enforce x k − 1 ∈ ˜ C ( t k − 1 ) , we require ˜ h ( x k − 1 , t k − 1 ) ≥ 0 . Applying a first-order T aylor expansion of ˜ h around ( x k , t k ) and substituting the up date (10) yields the linear constraint: ˜ h k + ∇ x ˜ h k · − [ f θ ( x k , t k ) + u k ]∆ t + g ( t k ) √ ∆ t ξ k − ∂ ϵ ∂ t ∆ t ≥ (1 − γ ∆ t ) ˜ h k , (11) whic h is linear in u k , making the minim um-norm con trol synthesis a con vex QP at eac h step. The complete procedure is giv en in Algorithm 1. W e note that the discrete-time constraint (11) is derived via a first-order T aylor series expansion of ˜ h around ( x k , t k ) , and is therefore only a sufficien t condition for ˜ h ( x k − 1 , t k − 1 ) ≥ 0 only up to linearization error. F or barrier functions with high curv ature or large step sizes ∆ t , the true nonlinear barrier v alue could deviate from the linear prediction. In practice, the margin provided b y the class- K term γ ( ˜ h k )∆ t and the conserv ativ e initialization ϵ 0 absorb this error. Across all exp erimen ts in Section 5, w e observ ed no constraint violations at the final sample, empirically v alidating the linearization for the step sizes used. The discrete-time constrain t (11) provides an appro ximate safety guaran tee: the first-order T aylor expansion introduces an O (∆ t 2 ) residual that is not formally bounded in our analysis. The additive margin c > 0 can b e introduced in the initialization ϵ 0 and the class- K damping γ to provide empirical robustness to this discretization error. A rigorous discrete-time CBF analysis that establishes explicit step-size-dep enden t b ounds on constrain t violation is an imp ortant direction for future work. Nonetheless, across all exp erimen ts with step sizes ranging from ∆ t = 0.01 (Section 5.1) to ∆ t = 0 . 005 (Section 5.3), w e observ ed zero constrain t violations at the final sample. 5 Exp eriments W e v alidate our framew ork across three domains that demonstrate its v ersatility and practical ef- fectiv eness. In eac h experiment, w e apply our CBF-guided sampling to pre-trained, off-the-shelf generativ e mo dels without an y retraining or architectural mo difications, demonstrating the mod- ularit y claimed in Con tribution 2. F or each experiment, our goal is to demonstrate that the safe sampling guarantees of Theorem 4.1 hold empirically across qualitatively distinct constraint t yp es. All exp eriments use the linear constriction ϵ ( x ( T ) , t ) = ϵ 0 · t T where ϵ 0 = max(0 , − h ( x ( T ))) + c , where c > 0 is a small p ositive margin. This margin serv es tw o purposes: it pro vides a buffer 10 Algorithm 1: CBF-guided safe sampling Input: Pre-trained mo del f θ , noise schedule g ( t ) , safe set C = { x | h ( x ) ≥ 0 } , num b er of steps K , class- K function γ Output: Safe sample x 0 ∈ C 1 Initialize: Sample x K ∼ p ( T ) (e.g., x K ∼ N (0 , I ) ), set t K = T , ∆ t = T /K 2 for k = K, K − 1 , . . . , 1 do 3 Sample noise: ξ k ∼ N (0 , I ) 4 Compute noise-induced drift: d noise = g ( t k ) √ ∆ t ξ k 5 Compute constricting barrier: ˜ h k = h ( x k ) + ϵ ( x K , t k ) 6 Solv e safet y-constrained QP: min u k 1 2 ∥ u k ∥ 2 s.t. ˜ h k + ∇ x ˜ h k · ( − [ f θ ( x k , t k ) + u k ]∆ t + d noise ) − ∂ ϵ ∂ t ( x K , t k )∆ t ≥ (1 − γ ( ˜ h k )∆ t ) ˜ h k 7 Apply con trol and update state: x k − 1 = x k − f θ ( x k , t k )∆ t − u ∗ k ∆ t + d noise 8 Up date time: t k − 1 = t k − ∆ t 9 return x 0 against the linearization error introduced by the discrete-time T aylor series expansion in (11), and it prev ents the barrier from op erating exactly on its zero level set at initialization, where numerical precision could cause spurious violations. In all experiments, w e set c = 0 . 1 . W e choose the class- K function γ ( h ) = αh with α = 0 . 5 . The QPs in Algorithm 1 are solved using CVXPY with the OSQP solver. Our implementation is av ailable at [anonymized for review]. Our experiments were conducted on an In tel i9-9900 mac hine with 128GB RAM and an Nvidia Quadro R TX 4000 GPU. 5.1 Physics-consistent trajectory generation fo r the Lo renz system In this exp eriment, we demonstrate the b ehavior of our guidance sc heme on a syn thetic testb ed. W e seek to generate tra jectories of the Lorenz system with dynamics, ˙ z 1 = σ ( z 2 − z 1 ) ˙ z 2 = z 1 ( ρ − z 3 ) − z 2 ˙ z 3 = z 1 z 2 − β z 3 (12) where we set σ = 10 , ρ = 28 , β = 8 3 . This system exhibits a characteristic b eha vior called the Lorenz attractor, famously known as the butterfly effect, where it is highly sensitiv e to the initial condition. Our goal is to ensure that sampled tra jectories satisfy the true physics enco ded in (12). Giv en an initial condition z (0) = [ z 1 (0) z 2 (0) z 3 (0)] ⊤ , we seek to sample an entire tra jectory up to 10 seconds of evolution. W e use a physical time discretization ∆ l = 0 . 01 , whic h results in L = 1000 sampling steps. F or the sake of brevity , w e denote the state sampled at time l ∆ l as z ( l ∆ l ) = z l . W e sample a full tra jectory x (0) = [ z 0 ⊤ z 1 ⊤ · · · z L ⊤ ] ⊤ . Note that l is the sampling step in physical time for the Lorenz system, whereas we reserve k for the sampling time for the diffusion mo del. 11 W e select the Lorenz oscillator b ecause its ground-truth solution is av ailable via n umerical integra- tion, providing an exact reference for v alidating our guidance sc heme. In practice, our framework targets settings where the gov erning equations are high-dimensional or computationally exp ensive to integrate, such as turbulent flo ws or m ulti-scale PDEs, and where a generative model serv es as an efficien t surrogate. Unlike traditional numerical methods that accumulate integration error o v er time, our approach generates the entire tra jectory as a single high-dimensional sample. The Lorenz system thus serv es as a con trolled testb ed to v erify that our CBF-guided sampling can re- co v er underlying ph ysical laws and main tain temp oral consistency across the en tire sequence b efore deplo ymen t in more complex domains. W e train a diffusion mo del with syn thetic data generated by numerically integrating (12) from initial conditions uniformly sampled from the region [ − 2 , 2] 3 . The model is implemented as a conditional DDPM with a U-Net arc hitecture featuring 4 do wnsampling blo cks, each with 64, 128, 256, and 512 c hannels resp ectively , trained for 1000 ep o chs with a cosine noise schedule. As we seek adherence to the true dynamics (12), w e define the barrier function as: h ( x ) = e − 1 L L − 1 X l =0 z l +1 − z l ∆ l − ˙ z l 2 (13) where ˙ z l is given b y the true v ector field (12), and e is an error tolerance in the av erage physics adherence. The safe set C = { x | h ( x ) ≥ 0 } enforces the physics up to a tolerance e = 0 . 001 . Figure 2 presents k ey results of our CBF-guided sampling for Lorenz system tra jectory generation. Figure 2(a) sho ws trajectories in the phase plane. The true ODE solution (dashed blac k) is closely trac k ed by our CBF-guided diffusion mo del (blue), while unconstrained sampling (red) pro duces tra jectories that deviate significantly from the true physics. The unconstrained sample still pro duces the characteristic butterfly effect, but it is not the true trajectory that is follow ed b y the system. This arises due to the fact that the diffusion mo del has learned to pro duce samples that exhibit the butterfly attractor by seeing ground truth data in training. This highligh ts a subtle but critical failure mo de: a generative mo del can pro duce samples that are statistically indistinguishable from real data y et physically incorrect, and an y do wnstream task that consumes suc h samples, whether a con troller, a sim ulator, or a decision-making system, would op erate on corrupted inputs without an y indication of the violation. Figure 2(b) reveals the ev olution of the safety tub e. A t t = 1 , the noise sample x ( T ) ∼ N (0 , I ) has large cumulativ e physics error, requiring relaxation ϵ 0 ≈ 16 —ov er four orders of magnitude larger than our target tolerance e = 0 . 001 . The blue line shows the linear constriction ϵ ( x ( T ) , t ) = ϵ 0 · ( t/T ) to zero at t = 0 . The constriction barrier ˜ h ( x, t ) (red) remains non-negative throughout, v erifying rev erse inv ariance (Theorem 4.1). Fluctuations during t ≈ 0 . 8 - 1 . 0 reflect the high-noise regime where g ( t ) is large. A t t = 0 , ˜ h ( x, 0) ≈ 0 with ϵ ( x ( T ) , 0) = 0 implies h ( x (0)) ≈ 0 , confirming that our minim um-norm control maximally exploits the constraint tolerance. Figure 2(c) shows control effort ∥ u ∥ 2 concen trated at sampling onset ( t ≈ 0 . 8 - 1 . 0 ), p eaking around 130-140, then rapidly decaying to near-zero by t ≈ 0 . 6 . This fron t-loaded interv ention exploits that con trol is c heap er when g ( t ) is large. The minimal effort for t < 0 . 6 indicates that the pre-trained mo del has implicitly learned the Lorenz system structure from training data, requiring only minor corrections to enforce hard guaran tees. 12 − 10 0 10 20 − 20 − 10 0 10 20 0 10 20 30 40 50 Ground truth Unconstrained sample CBF-guided sample Initial condition z 3 z 1 z 2 (a) 0 0 . 2 0 . 4 0 . 6 0 . 8 1 18 14 10 6 2 0 Safety tub e ˜ C ( t ) Constriction ( x ( T ) , t ) Barrier ˜ h ( x, t ) Sampling time t → (b) 0 0 . 2 0 . 4 0 . 6 0 . 8 1 0 30 60 90 120 150 Con trol ∥ u ∥ 2 Sampling time t → (c) Figure 2: Lorenz system tra jectory generation with CBF guidance. (a) Phase portrait showing the true ODE solution (dashed black). Our CBF-guided diffusion mo del (blue) closely tracks the true dynamics, while unconstrained sampling (red) pro duces physically inconsisten t tra jectories. (b) Ev olution of the constricting barrier ˜ h ( x, t ) (green) and relaxation ϵ ( x ( T ) , t ) (blue) during sampling. The constriction go es from ϵ 0 ≈ 16 to 0, accommo dating the large initial physics violation. The barrier remains non-negativ e throughout, verifying reverse in v ariance. (c) Control effort ∥ u ∥ 2 o v er sampling time, concen trated at the onset of sampling when the initial noise sample must be corrected, then rapidly diminishing as the tra jectory b ecomes ph ysics-consistent. 5.2 Constrained image generation W e demonstrate our framework on image synthesis tasks using the off-the-shelf DDPM-b edro om- 256 4 mo del from Hugging F ace Diffusers, trained on the LSUN bedro om dataset (Y u et al., 2015). Images are represented as x ∈ R 256 × 256 × 3 with R GB v alues normalized to [ − 1 , 1] . A key feature of our framework in this setting is that we define one barrier function p er constrained pixel, rather than a single aggregate barrier ov er all pixels. F or each pixel p in the constrained region, w e define an indep enden t barrier h p ( x ) and enforce h p ( x ) ≥ 0 separately . The resulting QP at eac h sampling step contains | R | linear constrain ts, where R is the set of constrained pixels. Crucially , since each p er-pixel barrier h p dep ends only on the three RGB v alues x p ∈ R 3 at pixel p . This sparsit y implies that the multi-constrain t QP ov er the full image space R 256 × 256 × 3 decomp oses in to |R| indep endent three-dimensional QPs, one p er pixel. Each sub-problem admits the closed- form solution from Remark 2, enabling efficien t parallel computation. In our exp eriments, w e solve the full QP using OSQP via CVXPY, which exploits this sparsity internally . 5.2.1 Lo cation and content constraints In this exp eriment, we enforce specific visual con tent at designated pixel lo cations, while retaining seman tic meaning with the rest of the image. Giv en any reference image, we constrain a rectangular region R ⊆ N 2 of dimension h × w in the generated image x ∈ R 256 × 256 × 3 to matc h the reference. T o ensure the reference image app ears in the prescrib ed lo cation, we enforce pixel-level constrain ts inside the region R . F urther, w e mo dulate the constrain t strength near boundary of R so that the diffusion mo del can smo othly fill the edges of the image with seman tic information. W e define a 4 https://huggingface.co/google/ddpm- bedroom- 256 13 spatially-v arying mask function v : N 2 → [0 , 1] for eac h pixel p ∈ R 256 × 256 × 3 : v ( p ) = 1 if p ∈ interior ( R ) smo oth deca y to 0 if p ∈ boundary ( R ) 0 if p / ∈ R where the boundary region is defined as pixels within 5% of the edge of R , and the deca y is implemen ted via a linear ramp. Let x ∗ p ∈ R 3 denote the RGB v alues of the reference image P at the corresponding p osition within R . F or each pixel p ∈ R , we define the barrier function: h p ( x ) = e − v ( p ) · ∥ x p − x ∗ p ∥ 2 , (14) where e = 0 . 005 is the error tolerance and x p ∈ R 3 denotes the R GB pixel v alues of x at lo cation p . The safe set is the intersection C = T p ∈ R { x | h p ( x ) ≥ 0 } , which enforces pixel-lev el fidelity in the in terior of R where v ( p ) = 1 , while allowing deviations near b oundaries where v ( p ) < 1 . The smo oth deca y v ( p ) → 0 allo ws the diffusion mo del to alter the edges of the reference image P as required for natural blending. Each pixel has its own constricting barrier ˜ h p ( x, t ) = h p ( x ) + ϵ p ( x ( T ) , t ) with a linear relaxation ϵ p ( x ( T ) , t ) = ϵ 0 , p · t/T , where ϵ 0 , p = max(0 , − h p ( x ( T ))) + c , where c = 0 . 01 is a small p ositive margin. Figure 3 demonstrates constrained image generation with a 50 × 70 pixel window region placed at p osition (40 , 150) . Both generated images (b-c) preserv e the reference window (a) exactly , v ali- dating Theorem 4.1. With 200 sampling steps (c), the mo del generates a coheren t b edro om scene with seman tically appropriate con text—b ed, lamps, and furniture prop erly scaled and lit relative to the window. The spatially-v arying mask enables smo oth blending at boundaries without visi- ble artifacts. With only 50 sampling steps (b), visual qualit y degrades in unconstrained regions, y et the window remains perfectly preserv ed. This demonstrates that the CBF shield guaran tees constrain t satisfaction regardless of sampling duration, while unconstrained regions follow standard diffusion mo del b ehavior. This arises due to ho w the constriction ϵ is constructed with conditions in Definition 1. (a) (b) (c) Figure 3: Spatially constrained image generation with DDPM-b edro om-256. (a) Reference windo w patc h ( 50 × 70 pixels). (b) Generated image with 50 sampling steps. (c) Generated image with 200 sampling steps. Both (b) and (c) preserve the reference window exactly at the specified lo cation while generating bedro om context. Higher sampling steps improv e generation quality in uncon- strained regions, but constraint satisfaction is guaranteed in b oth cases. 14 This exp eriment demonstrates the modularity of our framew ork. W e apply our metho d to an off- the-shelf pre-trained mo del without any architectural mo difications or retraining, enforcing hard spatial constrain ts that would b e imp ossible to guarantee with soft guidance metho ds. A dditional results with different reference images and placements are provided in App endix B.1. 5.2.2 Regional color intensity constraints W e demonstrate enforcement of regional color constraints by constraining the low er one-third of the image to maintain sp ecified color intensities. Define the constrained region as: R low er = { ( i, j ) ∈ N 2 : 171 ≤ i ≤ 256 , 1 ≤ j ≤ 256 } , whic h corresp onds to the low er one-third of the image. The target color in tensity is x ∗ p ∈ [ − 1 , 1] 3 for all p ∈ R low er . T o allow natural blending near the b oundary , w e emplo y a spatially v arying mask function v : N 2 → [0 , 1] that modulates constraint strength: v ( p ) = ( i − i min i max − i min · v max + 1 − i − i min i max − i min · v min , if p = ( i, j ) ∈ R low er , 0 , otherwise , (15) where i min = 171 , i max = 256 denote the ro w b oundaries of R low er , and ( v min , v max ) ∈ [0 , 1] 2 the constrain t strength, resp ectively . F or each pixel p ∈ R low er , the barrier function is: h p ( x ) = e − v ( p ) · ∥ x p − x ∗ p ∥ 2 , (16) where e = 0 . 05 is the error tolerance, and x p ∈ R 3 denotes the RGB pixel v alues of x at pixel p . The safe set C = { x ∈ R 256 × 256 × 3 | h ( x ) ≥ 0 } represen ts images with pixel-level color fidelit y weigh ted b y the mask function v ( p ) , where higher mask v alues enforce stricter adherence to the target inten- sit y . W e use the linear constriction scheme ϵ ( x ( T ) , t ) = ϵ 0 · t/T + c where ϵ 0 = max(0 , − h ( x ( T ))) . In this exp eriment, w e use different mask configurations and color intensities and compare our constricting CBF guidance sc heme with pro jection-based constrain t enforcement in Zampini et al. (2025). This exp eriment illustrates ho w our coarse-to-fine constrain t enforcement retains seman tic meaning with the rest of the image whereas projection schemes can lose seman tic meaning: 1. Mo der ate c onstr aint in Figure 4(a): The target pixel color is blac k, x ∗ p = ( − 0 . 9 , − 0 . 9 , − 0 . 9) , and the spatial mask v ( p ) v aries from v max = 0 . 5 at the b ottom to v min = 0 at the upp er b oundary of R low er . This allo ws the diffusion mo del freedom to generate detailed, realistic textures while satisfying the p er-pixel color constraints. 2. Pr oje ction in Figure 4(b): W e implemen t the pro jection-based constrain t enforcemen t sc heme in Zampini et al. (2025) and compare the visual qualit y . The constraint is the same as in the earlier case where the b ottom-third of the image needs to b e blac k x ∗ p = ( − 0 . 9 , − 0 . 9 , − 0 . 9) , and the spatial mask v ( p ) v aries from v max = 0 . 5 at the bottom to v min = 0 at the upper b oundary of R low er . Due to pro jection at each step, w e get a blac k-tap e effect, which achiev es constraint enforcemen t but semantic meaning is lost. 3. W e ak c onstr aint in Figure 4(c): The target pixel in tensit y is x p = ( − 0 . 4 , − 0 . 3 , − 0 . 3) , corresp onding to a ligh t bro wn color. The mask v alues range from ( v min , v max ) = (0 , 0 . 2) , applying w eak constrain ts. This allo ws the diffusion mo del to almost freely generate an image, relying on the guidance to only nudge individual pixels tow ard the target color. 15 All images successfully satisfy the color constrain t in the low er region while maintaining semantic coherence with realistic bedro om lay outs. How ever, the c hoice of mask strength directly affects the balance betw een strict constrain t adherence and natural visual app earance, with lo w er mask v alues allo wing greater mo del freedom to generate detailed, realistic textures within the constrained color range. Figure 4 illustrates how our CBF-guided sampling framew ork enables precise control ov er the strength and exten t of constrain t enforcemen t. The spatially-v arying mask function v ( p ) pro vides a smo oth con trol b etw een strict enforcement and model freedom, allo wing practitioners to balance safet y enforcement with perceptual qualit y based on application requiremen ts. Imp ortantly , all three configurations achiev e 100% constraint satisfaction. No generated image violates h ( x ) ≥ 0 , demonstrating the formal safety guarantees of Theorem 4.1 even under weak constraint settings. (a) (b) (c) Figure 4: Regional color in tensit y constrain ts. All images enforce different RGB v alues in the lo wer third. (a) Mo der ate intensity: The target pixel color is blac k, and the spatial mask v ( p ) go es from 0 . 5 → 0 , allo wing the diffusion mo del to pro duce clean furniture. (b) Pr oje ction: Pro jection- based constrain t enforcement (Zampini et al., 2025), constraint are same as in (a) with target pixel color black in the b ottom one-third of the image. Projection at every sampling step causes in tense constrain t enforcement, which leads to loss of seman tic information. (c) L ow intensity: The target color is bro wn, and the spatial mask v ( p ) goes from 0 . 2 at the b ottom to 0 at the lo w er-third b oundary , pro ducing a semantically meaningful image of a ro om with a brown carp et. 5.3 Smo oth rob ot p olicy generation W e demonstrate our framew ork on rob otic manipulation using the pre-trained Diffusion P olicy mo del (Chi et al., 2025) for the Push-T task. The Push-T task requires a planar rob otic arm to push a T-shap ed blo ck to a target p ose, as depicted in Figure 5(a). The diffusion p olicy generates a sequence of actions x (0) = { a 0 , a 1 , . . . , a S } , where S = 15 is the action horizon and eac h action a s ∈ R 2 represen ts an end-effector v elo cit y command. W e seek safe samples of action ch unks x (0) b y applying Algorithm 1 during the diffusion sampling pro cess, without any retraining or mo dification to the mo del architecture. On physical rob otic hardware, abrupt changes in velocity commands p ose concrete safety risks. Large accelerations violate actuator rate limits, inducing torque spikes that can damage motors and gearb oxes. In contact-ric h tasks such as Push-T, jerky motions destabilize the grasp or push con tact, leading to task failure or uncon trolled ob ject motion. Smo othness 16 of the commanded action sequence is therefore not merely a qualit y metric but an op erational safet y requiremen t for real-world deplo yment. W e enco de this requiremen t as a hard constrain t b y bounding the a verage control v ariation, or the jerk, across the action horizon. Sp ecifically , we define the barrier function as: h ( x ) = e smooth − 1 S S − 1 X s =0 ∥ a s +1 − a s ∥ 2 ∆ s , (17) where e smooth = 1 . 5 is the tolerance that b ounds the maxim um allo wed jerk magnitude, and ∆ s is the time discretization of the en vironment. The safe set C = { x | h ( x ) ≥ 0 } enco des the set of all action sequences whose av erage control v ariation magnitude remains b elow the prescrib ed threshold e smooth . W e apply our CBF shield during the sampling pro cess using Algorithm 1 with the same linear constriction scheme as in the previous exp eriments. (a) (b) DP (Chi et al., 2025) DP-DDIM Ours Figure 5: Smo oth action generation for Push-T rob otic manipulation. (a) The Push-T environmen t: a planar rob ot arm must push the T-shap ed blo ck (gray) to the target p ose (green). (b) End-effector tra jectories for a represen tative episo de. Unconstrained Diffusion Policy (DP , dotted red) exhibits sharp directional changes during pushing. DP-DDIM (dashed blue) pro duces more erratic motion due to few er sampling steps. Our CBF-guided sampling (solid blac k) generates a smo oth tra jectory that satisfies the acceleration constrain t at every step while achieving the same task rew ard. T able 1 presen ts quan titative results av eraged ov er 100 episodes. W e compare our CBF-guided sampling against the original Diffusion P olicy with DDPM sampling (DP) and DDIM sampling (DP-DDIM), using the pre-trained c heckpoints from the authors’ rep ository 5 . Our CBF-guided sampling achiev es a mean reward of 0.92, matc hing the original Diffusion Policy , while guaran teeing zero smo othness violations across all episo des. In contrast, unconstrained DP and DP-DDIM exceed the smo othness threshold ϵ smooth an a v erage of 12 and 16 times p er episo de, resp ectively . This demonstrates that the learned p olicy do es not inherently satisfy smo othness requiremen ts despite b eing trained on smo oth demonstrations. The diffusion sampling process itself introduces high- frequency artifacts that violate the constrain t. Figure 5(b) visualizes the end-effector tra jectory for 5 https://github.com/real- stanford/diffusion_policy 17 Metric DP DP-DDIM CBF-guided Mean rew ard 0 . 92 0 . 90 0 . 92 Smo othness violation 12 16 0 Sampling steps K 100 10 100 Mean inference time (ms) 47 . 05 4 . 57 62 . 92 T able 1: Quantitativ e comparison on Push-T with smo othness constraints ov er 100 episo des. Diffu- sion Policy with DDPM (DP) and DDIM (DP-DDIM) violate the smo othness constraint an av erage of 12 and 16 times per episo de, respectively , whereas our CBF-guided framework achiev es zero vio- lations while main taining identical task reward. The computational ov erhead of solving the QP (8) at eac h sampling step is mo dest relativ e to the environmen t con trol rate. a represen tative episode. The unconstrained DP trajectory (dotted red) exhibits sharp directional c hanges, particularly during the pushing phase. DP-DDIM (dashed blue), which uses fewer sampling steps, pro duces even more erratic motion. Our CBF-guided trajectory (blac k) follows a visibly smo other path w hile achieving the same task ob jective. The smo othness is enforced throughout the diffusion sampling process rather than applied as p ost-ho c filtering, ensuring that ev ery generated action ch unk satisfies the constraint b y construction. The additional computational cost of solving the QP at each sampling step is mo dest. Inference time increases from 47 ms to 63 ms p er sample, a 34% ov erhead that remains well within real-time requiremen ts for the 10 Hz con trol loop of the Push-T en vironment. DP-DDIM ac hiev es significan tly faster inference (4.6 ms) by using only 10 sampling steps, but at the cost of higher smoothness violations and sligh tly low er task rew ard. This exp eriment v alidates our framework in a rob otic planning setting where the generativ e model op erates o ver structured action sequences rather than images or physical trajectories. The con- strain t is enforced purely in action space, requiring no forward dynamics mo del or state prediction. Extending to state-space safet y constrain ts, suc h as collision av oidance, w ould require access to a dynamics mo del (analytical or learned) to propagate the effect of actions to states. W e discuss this as a natural extension in Section 6. 6 Limitations and future w o rk Our framework assumes access to a contin uously differen tiable barrier function h ( x ) that precisely enco des the safet y specification. When the notion of safet y is well-defined and analytically ex- pressible, suc h as physics residuals (Section 5.1), pixel-lev el constrain ts (Section 5.2), or action smo othness b ounds (Section 5.3), our method pro vides deterministic guaran tees. How ev er, in do- mains where safet y is ambiguous or difficult to formalize, suc h as filtering semantically inappropriate con ten t in images, constructing a suitable barrier is non trivial. In our preliminary exp erimen ts, w e attempted to use CLIP-based confidence scores and neural netw ork classifiers as barrier functions for seman tic constrain ts. These attempts were unsuccessful on sev eral occasions. The classifiers o ccasionally assigned high confidence to unsafe samples, causing the CBF condition to b e trivially satisfied and the safet y filter to remain inactive. This failure mo de is well-documented in the adv er- sarial robustness literature and stems from the fact that learned classifiers extract features that do not reliably align with the safet y boundary . When the barrier function itself is unreliable, obtaining formal guaran tees on safet y with resp ect to the intended safety semantics is unac hiev able. 18 Sev eral extensions follo w naturally from our framework. First, extending the approac h to latent diffusion mo dels w ould enable scalability to higher-resolution generation. W e inv estigated extending our framework to latent diffusion mo dels (Rombac h et al., 2022) where the diffusion pro cess op erates in a compressed laten t space z = E ( x ) and the constraint is defined in image space. While the QP structure is preserved, the laten t gradient is computed via a single bac kward pass through the deco der. Our preliminary experiments with Stable Diffusion v1.5 revealed that exact constraint satisfaction does not transfer from latent to image space (see App endix B.2). The V AE decoder is not a diffeomorphism: it is lo cally non-inv ertible and introduces reconstruction artifacts that distort the constraint b oundary . As a result, the CBF shield successfully biases the latent tra jectory tow ard the constrained region but cannot guaran tee pixel-level fidelity in the deco ded image. A chieving exact constrain ts in laten t diffusion mo dels lik ely requires either (i) a constraint-a ware fine-tuning of the deco der to impro ve lo cal in v ertibilit y near the constrain t boundary , or (ii) a h ybrid approac h that applies coarse guidance in laten t space and a final correction step in pixel space after deco ding. Second, enforcing state-space safet y constrain ts in robotic p olicies, such as collision a voidance, requires a dynamics model to map actions to states. Com bining our framew ork with learned dynamics mo dels or neural ODEs is a promising direction. Third, our current implemen tation solves one QP p er sampling step using a general-purp ose solv er. Exploiting the closed-form solution of the single-constraint QP or using an MPC framework across man y steps could significan tly reduce computational o verhead and obtain bounds on the KL div ergence o v er the entire sampling horizon. 7 Conclusion W e introduced a framew ork for enforcing hard constraints on flow-based generativ e mo dels by fram- ing guided sampling as an optimal con trol problem. Our approach leverages constricting Control Barrier F unctions (CBF s) to define a safet y tube that is relaxed at the initial noise distribution and progressively constricts to the target safe set. The resulting minimum-norm QP synthesizes a feedbac k control input that pro v ably maintains samples within the safet y tub e while minimizing the instan taneous contribution to the distributional shift from the learned mo del, as quan tified by the KL divergence (Theorem 4.2). W e v alidated the mo dularit y and effectiv eness of this framework across ph ysically-consistent tra jectory generation, constrained image syn thesis, and smooth action generation for rob otic manipulation, using off-the-shelf pre-trained mo dels. As generativ e models are increasingly deploy ed in safety-critical systems, this framew ork provides a deterministic safet y la y er that complements the expressiveness of generativ e sampling mo dels. References A. D. Ames, X. Xu, J. W. Grizzle, and P . T abuada. Con trol barrier function based quadratic programs for safety critical systems. IEEE T r ansactions on A utomatic Contr ol , 62(8):3861–3876, 2016. A. D. Ames, S. Co ogan, M. Egerstedt, G. Notomista, K. Sreenath, and P . T abuada. Con trol barrier functions: Theory and applications. In 2019 18th Eur op e an Contr ol Confer enc e (ECC) , pp. 3420–3431, 2019. F. Blanc hini and S. Miani. Set-the or etic metho ds in c ontr ol , v olume 78. Springer, 2008. 19 C. Chi, Z. Xu, S. F eng, E. Cousineau, Y. Du, B. Burchfiel, R. T edrak e, and S. Song. Diffusion p olicy: Visuomotor policy learning via action diffusion. The International Journal of R ob otics R ese ar ch , 44(10-11):1684–1704, 2025. A. Clark. Control barrier functions for sto chastic systems. A utomatic a , 130:109688, 2021. X. Dai, Z. Y ang, D. Y u, S. Zhang, H. Sadeghian, S. Haddadin, and S. Hirche. Safe flow matching: Rob ot motion planning with con trol barrier functions. arXiv pr eprint arXiv:2504.08661 , 2025. P . Dhariw al and A. Nichol. Diffusion models b eat gans on image synthesis. A dvanc es in neur al information pr o c essing systems , 34:8780–8794, 2021. N. Fishman, L. Klarner, V. De Bortoli, E. Mathieu, and M. J. Hutc hinson. Diffusion models for constrained domains. T r ansactions on Machine L e arning R ese ar ch , 2023. ISSN 2835-8856. URL https://openreview.net/forum?id=xuWTFQ4VGO . D. Gadginmath and F. P asqualetti. Dynamics-a ware diffusion mo dels for planning and con trol. In 64th IEEE Confer enc e on De cision and Contr ol (CDC) , 2025. Y. Guo, H. Y uan, Y. Y ang, M. Chen, and M. W ang. Gradient guidance for diffusion models: An optimization p ersp ectiv e. A dvanc es in Neur al Information Pr o c essing Systems , 37:90736–90770, 2024. J. Ho and T. Salimans. Classifier-free diffusion guidance. In NeurIPS 2021 W orkshop on De ep Gener ative Mo dels and Downstr e am Applic ations , 2021. URL https://openreview.net/forum? id=qw8AKxfYbI . J. Ho, A. Jain, and P . Abbeel. Denoising diffusion probabilistic mo dels. In A dvanc es in Neur al Information Pr o c essing Systems , volume 33, 2020. J. Ho, C. Saharia, W. Chan, D. J. Fleet, M. Norouzi, and T. Salimans. Cascaded diffusion mo dels for high fidelity image generation. Journal of Machine L e arning R ese ar ch , 23(47):1–33, 2022. M. Janner, Y. Du, J. T enenbaum, and S. Levine. Planning with diffusion for flexible b eha vior syn thesis. In Pr o c e e dings of the 39th International Confer enc e on Machine L e arning , volume 162 of Pr o c e e dings of Machine L e arning R ese ar ch , pp. 9902–9915. PMLR, 17–23 Jul 2022. Z. Li, D. Chen, M. F an, C. Chen, Y. Li, Y. W ang, and W. Zhou. Responsible diffusion mo dels via constraining text em b eddings within safe regions. In Pr o c e e dings of the A CM on W eb Confer enc e 2025 , pp. 1588–1601. Asso ciation for Computing Machinery , 2025. B. Liao, S. Chen, H. Yin, B. Jiang, C. W ang, S. Y an, X. Zhang, X. Li, Y. Zhang, Q. Zhang, et al. Diffusiondriv e: T runcated diffusion mo del for end-to-end autonomous driving. In Pr o c e e dings of the Computer V ision and Pattern R e c o gnition Confer enc e , pp. 12037–12047, 2025. Y. Lipman, R. T. Chen, H. Ben-Hamu, M. Nic kel, and B. Poole. Flo w matc hing for generativ e mo deling. In The Eleventh International Confer enc e on L e arning R epr esentations , 2023. URL https://openreview.net/forum?id=PqvMRDCJT9t . A. Lou and S. Ermon. Reflected diffusion mo dels. In International Confer enc e on Machine L e arning , pp. 22675–22701. PMLR, 2023. 20 K. Mizuta and K. Leung. Cobl-diffusion: Diffusion-based conditional rob ot planning in dynamic en vironmen ts using control barrier and ly apunov functions. In 2024 IEEE/RSJ International Confer enc e on Intel ligent R ob ots and Systems (IROS) , pp. 13801–13808. IEEE, 2024. B. Øksendal. Stochastic differen tial equations. In Sto chastic differ ential e quations: an intr o duction with applic ations , pp. 38–50. Springer, 2003. G. Papamakarios, E. Nalisnick, D. J. Rezende, S. Mohamed, and B. Lakshminara yanan. Normal- izing flo ws for probabilistic mo deling and inference. Journal of Machine L e arning R ese ar ch , 22 (57):1–64, 2021. S. Pra jna, A. Jadbabaie, and G. J. Pappas. Stochastic safet y verification using barrier certificates. In 2004 43r d IEEE c onfer enc e on de cision and c ontr ol (CDC) , volume 1, pp. 929–934. IEEE, 2004. R. Rom bach, A. Blattmann, D. Lorenz, P . Esser, and B. Ommer. High-resolution image synthesis with laten t diffusion mo dels. In Pr o c e e dings of the IEEE/CVF c onfer enc e on c omputer vision and p attern r e c o gnition , pp. 10684–10695, 2022. R. Römer, L. Brunk e, M. Sch uck, and A. P . Sc ho ellig. Safe offline reinforcemen t learning using tra jectory-lev el diffusion mo dels. In ICRA 2024 W orkshop - Back to the F utur e: R ob ot L e arning Going Pr ob abilistic , 2024. P . Schramo wski, M. Brack, B. Deiseroth, and K. Kersting. Safe latent diffusion: Mitigating in- appropriate degeneration in diffusion mo dels. In Pr o c e e dings of the IEEE/CVF Confer enc e on Computer Vision and Pattern R e c o gnition , pp. 22522–22531, 2023. O. So, A. Clark, and C. F an. Almost-sure safet y guaran tees of sto c hastic zero-control barrier functions do not hold. arXiv pr eprint arXiv:2312.02430 , 2023. Y. Song, J. Sohl-Dickstein, D. P . Kingma, A. Kumar, S. Ermon, and B. Poole. Score-based genera- tiv e mo deling through sto chastic differential equations. In International Confer enc e on L e arning R epr esentations , 2021. U. Utkarsh, P . Cai, A. Edelman, R. Gomez-Bombarelli, and C. V. Rackauc kas. Ph ysics- constrained flow matching: Sampling generativ e models with hard constrain ts. arXiv pr eprint arXiv:2506.04171 , 2025. T. W eiss, E. Ma yo Y anes, S. Chakraborty , L. Cosmo, A. M. Bronstein, and R. Gershoni-Poranne. Guided diffusion for in verse molecular design. Natur e Computational Scienc e , 3(10):873–882, 2023. W. Xiao, T.-H. W ang, C. Gan, R. Hasani, M. Lechner, and D. R us. Safediffuser: Safe planning with diffusion probabilistic models. In The Thirte enth International Confer enc e on L e arning R epr esentations , 2023. J. Y ang, S. Jang, and S. Han. Safeflowmatc her: Safe and fast planning using flo w matc hing with con trol barrier functions. arXiv pr eprint arXiv:2509.24243 , 2025. F. Y u, Y. Zhang, S. Song, A. Seff, and J. Xiao. Lsun: Construction of a large-scale image dataset using deep learning with h umans in the loop. arXiv pr eprint arXiv:1506.03365 , 2015. 21 H. Y uan, K. Huang, C. Ni, M. Chen, and M. W ang. Reward-directed conditional diffusion: Pro v able distribution estimation and reward impro vemen t. A dvanc es in Neur al Information Pr o c essing Systems , 36:60599–60635, 2023. S. Zampini, J. K. Christopher, L. Oneto, D. Anguita, and F. Fioretto. T raining-free constrained generation with stable diffusion mo dels. arXiv pr eprint arXiv:2502.05625 , 2025. A App endix: Pro ofs fo r Theo rem 4.1 and Theo rem 4.2 A.1 Pro of of Theorem 4.1 (Reverse invariance of guided sampling p ro cess) W e first establish initial feasibilit y at the onset of the sampling pro cess at t = T . Given x ( T ) , an arbitrary sample drawn from the noise distribution p ( T ) , the constricting barrier function is: ˜ h ( x ( T ) , T ) = h ( x ( T )) + ϵ ( x ( T ) , T ) . By the condition ϵ ( x ( T ) , T ) ≥ − h ( x ( T )) , it follows immediately that ˜ h ( x ( T ) , T ) ≥ 0 , which implies x ( T ) ∈ ˜ C ( T ) . Next, w e consider the evolution of the state x ( t ) under the controlled dynamics (5). The k ey observ ation is that in our setting, w e ha ve full kno wledge of the noise process: at eac h instan t t , the noise realization ξ ( t ) is observed b efor e the con trol u ( x, ξ , t ) is synthesized. Conse- quen tly , the result follows if w e can pro v e reverse inv ariance for each realization of the noise path { ξ ( t ) } t ∈ [0 ,T ] , where the controlled dynamics reduce to the following deterministic time-v arying or- dinary differen tial equation ˙ x ( t ) = ˜ f ( x, t ) := f θ ( x, t ) + u ( x, ξ ( t ) , t ) + g ( t ) ξ ( t ) , (18) F or each such realization, we verify the conditions of the generalization of Nagumo’s theorem (Blan- c hini & Miani, 2008, Section 4.2.2) for the time-v arying set ˜ C ( t ) = { x | ˜ h ( x, t ) ≥ 0 } . Existence and uniqueness of solutions to (18) for eac h realization of the noise process ξ hold b y (Øksendal, 2003, Theorem 5.2.1) By condition (7), for any ( x, t ) with ˜ h ( x, t ) = 0 , the control u ( x, ξ ( t ) , t ) ensures ∇ ˜ h ( x, t ) · ˜ f ( x, t ) + ∂ ˜ h ( x, t ) ∂ t ≤ γ ( ˜ h ( x, t )) = 0 , (19) where the equality γ ( ˜ h ( x, t )) = 0 follows from γ b eing a class- K function ev aluated at zero. Since (18) is a deterministic ODE for eac h fixed noise path, the generalization of Nagumo’s theorem applies directly , yielding reverse inv ariance of ˜ C ( t ) : if x ( T ) ∈ ˜ C ( T ) , then x ( t ) ∈ ˜ C ( t ) for all t ∈ [0 , T ] . Since this argument holds for every noise realization { ξ ( t ) } t ∈ [0 ,T ] , w e conclude that ˜ h ( x ( t ) , t ) ≥ 0 for all t ∈ [0 , T ] . At t = 0 , we hav e ˜ h ( x (0) , 0) = h ( x (0)) + ϵ ( x ( T ) , 0) = h ( x (0)) ≥ 0 , so x (0) ∈ C . □ A.2 Pro of of Theorem 4.2 (Distributional shift wrt to guidance) Let P denote the probabilit y measure associated with the unconstrained pro cess gov erned by the drift f θ , and Q denote the measure asso ciated with the controlled pro cess gov erned by f θ + u . W e assume g ( t ) > 0 for all t ∈ [0 , T ] . Recall that the sampling pro cess runs in reverse time from T to 0 . T o apply standard results, we reparametrize the process in forward time via τ = T − t , so that 22 τ increases from 0 to T as sampling progresses. Under this substitution, the unconstrained and con trolled SDEs b ecome d x = ¯ f θ ( x, τ ) d τ + ¯ g ( τ ) d W τ , d x = [ ¯ f θ ( x, τ ) + ¯ u ( x, τ )] d τ + ¯ g ( τ ) d W τ , (20) where ¯ f θ ( x, τ ) = − f θ ( x, T − τ ) , ¯ g ( τ ) = g ( T − τ ) , ¯ u ( x, τ ) = − u ( x, T − τ ) , and W τ is a stan- dard forw ard-time Wiener pro cess. By Girsanov’s Theorem, the Radon-Nikodym deriv ative of the con trolled measure Q with resp ect to the unconstrained measure P ov er [0 , T ] is d Q d P = exp Z T 0 ¯ u ( x τ , τ ) ¯ g ( τ ) · d W τ − 1 2 Z T 0 ∥ ¯ u ( x τ , τ ) ∥ 2 ¯ g ( τ ) 2 d τ ! . (21) The KL divergence is the exp ected log-likelihoo d ratio under Q : D KL ( Q ∥ P ) = E Q ln d Q d P = E Q " Z T 0 ¯ u ¯ g · d W τ − 1 2 Z T 0 ∥ ¯ u ∥ 2 ¯ g 2 d τ # . (22) By Girsanov’s Theorem, the pro cess W Q τ = W τ − R τ 0 ¯ u ¯ g d s is a Wiener pro cess under Q . Substituting d W τ = d W Q τ + ¯ u ¯ g d τ into (22) yields D KL ( Q ∥ P ) = E Q " Z T 0 ¯ u ¯ g · d W Q τ + ¯ u ¯ g d τ − 1 2 Z T 0 ∥ ¯ u ∥ 2 ¯ g 2 d τ # = E Q " Z T 0 ¯ u ¯ g · d W Q τ # + 1 2 E Q " Z T 0 ∥ ¯ u ∥ 2 ¯ g 2 d τ # . (23) Since W Q τ is a Wiener pro cess under Q , the sto chastic in tegral R T 0 ¯ u ¯ g · d W Q τ is a martingale under Q with zero exp ectation. Substituting bac k the original v ariables via ∥ ¯ u ( x, τ ) ∥ 2 = ∥ u ( x, T − τ ) ∥ 2 and ¯ g ( τ ) 2 = g ( T − τ ) 2 , and changing the integration v ariable bac k to t = T − τ , w e obtain D KL ( p safe (0) ∥ p (0)) = 1 2 E p safe (0) " Z T 0 ∥ u ( x, t ) ∥ 2 g ( t ) 2 d t # . (24) This concludes the pro of. □ B App endix: A dditional exp eriments B.1 Spatial content constraints with alternate reference images Figure 6 demonstrates spatial and conten t-constrained image generation using red decorative pillo ws as the reference patc h. Both constrained generations (b-c) preserv e the pillo ws exactly at the sp ecified location. Notably , the generated scenes exhibit predominan tly light tones. This o ccurs because the refer- ence patch (a) includes white pixels near its b oundaries, which the diffusion mo del in terprets as lo cal context. The spatially-v arying mask v ( p ) constrains boundary pixels to remain close to ref- erence v alues, causing the model to generate am bien t colors that transition naturally from the white boundary . This demonstrates that our CBF shield enforces constraints precisely as sp ecified, including boundary characteristics. In practice, reference patches with neutral b oundaries allo w greater freedom in surrounding generation. 23 (a) (b) (c) Figure 6: Spatial and con tent constrained generation with red pillow reference. (a) Reference patc h ( 50 × 50 pixels) con taining tw o red pillows with white bac kground. (b) Generated image with 50 sampling steps. (c) Generated image with 200 sampling steps. Both preserv e the pillo ws exactly while generating b edro om context. The white boundary pixels in the reference influence the surrounding color palette, resulting in light-toned ambien t environmen ts. B.2 Constrained image generation with latent diffusion mo dels W e in vestigate extending our CBF framew ork to laten t diffusion mo dels (Rombac h et al., 2022), where the diffusion pro cess op erates in a compressed latent space rather than directly in pixel space. This extension is motiv ated by the scalability requiremen ts of mo dern text-to-image models such as Stable Diffusion, whic h p erform sampling in a low-dimensional laten t space R 4 × 64 × 64 that is deco ded to images in R 3 × 512 × 512 via a v ariational auto enco der (V AE). Let E : R n → R d and D : R d → R n denote the V AE encoder and deco der, resp ectively , where d ≪ n . Giv en a constrain t defined in image space via a barrier function h : R n → R , w e define the latent b arrier function as the comp osition ¯ h ( z ) := h ( D ( z )) , (25) whic h lifts the image-space constrain t in to the laten t space via the decoder. The constricting barrier b ecomes ˜ h ( z , t ) = ¯ h ( z ) + ϵ ( z ( T ) , t ) , and the CBF condition for the latent dynamics d z = [ f θ ( z , t ) + u ]d t + g ( t )d w requires the gradient ∇ z ¯ h ( z ) = ∂ D ∂ z ⊤ ∇ x h ( x ) x = D ( z ) , (26) whic h is computed via a single backw ard pass through the deco der using automatic differ- en tiation. The QP structure of Algorithm 1 is preserved, with the state space replaced by R d . W e apply the spatial lo calization constraint from Section 5.2.1 to Stable Diffusion v1.5 ( sd-legacy/stable-diffusion-v1-5 ) from Hugging F ace Diffusers. The prompt to the mo del is “high qualit y image of a rustic bedro om” . W e constrain a rectangular region in the generated image to match a reference windo w patc h, using the same p er-pixel barrier function (14) ev aluated on the decoded image ˆ x = D ( z ) . The laten t gradient (26) is backpropagated through the V AE deco der at each sampling step. Figure 7 presen ts the results. The CBF-guided latent diffusion mo del resp onds to the spatial con- strain t: a visually distinct region app ears at the sp ecified location, indicating that the latent-space 24 con trol input successfully biases the sampling trajectory to ward the constrained region. Ho wev er, the reference window patch is not preserved with pixel-level fidelit y . The constraint region app ears blurred, color-shifted, and blended into the surrounding scene, in contrast to the exact preserv ation ac hiev ed in pixel-space exp erimen ts (Figure 3 and 6). This degradation stems from a fundamental limitation that the V AE deco der D is not a diffeomorphism. The mapping from laten t to image space is locally non-inv ertible and many-to-one, meaning that m ultiple laten t codes can decode to similar but non-identical images. Consequently , enforcing ¯ h ( z ) = h ( D ( z )) ≥ 0 in laten t space do es not guaran tee that the deco ded image ˆ x = D ( z ) satisfies h ( ˆ x ) ≥ 0 with the same precision. The decoder introduces reconstruction artifacts that distort the constrain t b oundary , causing the gradien t ∇ z ¯ h to p oint in directions that are appro ximately but not exactly aligned with the true image-space constrain t. (a) (b) Figure 7: Constrained image generation with laten t diffusion mo dels with prompt “high-quality image of a rustic bedro om” . The constraint is to pro duce the reference window in Figure 3(a) in the top righ t corner, same as in Section 5.2.1. W e see that the model resp onds to the constraint by pro ducing a visually distinct region at the target location, but the reference patc h is not preserved with pixel-lev el fidelity due to the V AE decoder’s non-inv ertibility . F ormally , the safety guarantee of Theorem 4.1 holds with respect to the comp osed barrier ¯ h ( z ) = h ( D ( z )) : if ˜ h ( z (0) , 0) ≥ 0 , then h ( D ( z (0))) ≥ 0 . The issue is that the safe set ¯ C = { z | h ( D ( z )) ≥ 0 } in latent space do es not corresp ond exactly to the in tended safe set in image space when the deco der has non-trivial reconstruction error. This is not a failure of the CBF framew ork itself, but rather a limitation of the representation space in which the diffusion pro cess operates. 25
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment