Differentiable Zero-One Loss via Hypersimplex Projections
Recent advances in machine learning have emphasized the integration of structured optimization components into end-to-end differentiable models, enabling richer inductive biases and tighter alignment with task-specific objectives. In this work, we in…
Authors: Camilo Gomez, Pengyang Wang, Liansheng Tang
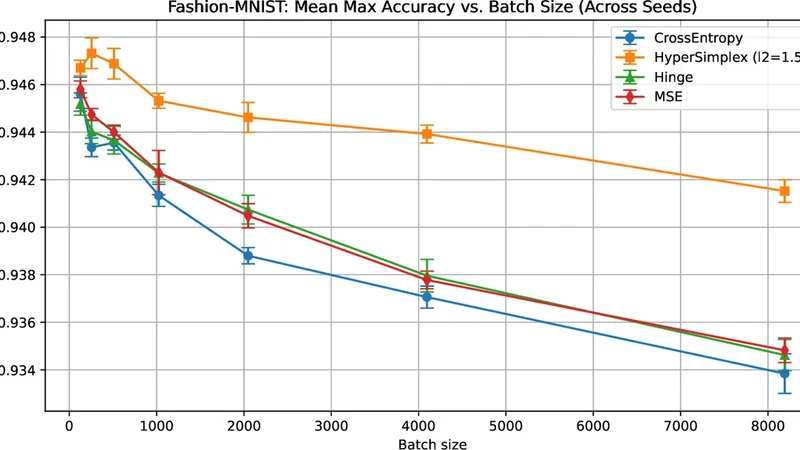
Differen tiable Zero-One Loss via Hyp ersimplex Pro jections Camilo Gomez 1 ⋆ , P engyang W ang 2 , and Liansheng T ang 1 1 Sc ho ol of Data, Mathematical, and Statistical Sciences, Universit y of Central Florida, Orlando, USA camilo.gomez@ucf.edu, liansheng.tang@ucf.edu 2 Departmen t of CIS, Universit y of Macau, Macao, China pywang@um.edu.mo Abstract. Recen t adv ances in machine learning ha ve emphasized the in tegration of structured optimization comp onen ts into end-to-end dif- feren tiable mo dels, enabling richer inductive biases and tighter alignment with task-specific ob jectiv es. In this w ork, w e in tro duce a no vel differen- tiable approximation to the zero–one loss—long considered the gold stan- dard for classification performance, yet incompatible with gradient-based optimization due to its non-differentiabilit y . Our metho d constructs a smo oth, order-preserving pro jection onto the ( n, k ) -dimensional hyper- simplex through a constrained optimization framework, leading to a new op erator we term Soft-Binary-Argmax. After deriving its mathematical prop erties, w e show how its Jacobian can b e efficiently computed and in- tegrated into binary and multiclass learning systems. Empirically , our ap- proac h achiev es significant improv ements in generalization under large- batc h training by imposing geometric consistency constrain ts on the out- put logits, thereb y narrowing the p erformance gap traditionally observed in large-batch training. Our co de is av ailable here h ttps://github.com/ camilog04/Differen tiable- Zero- One- Loss- via- Hypersimplex- Pro jections . Keyw ords: Differentiable Optimization in Deep Learning · Differen- tiable programming · Large-batch generalization. 1 In tro duction Recen t developmen ts in machine learning hav e demonstrated that optimization pro cedures can b e used as fundamen tal comp onen ts within end-to-end differ- en tiable systems [ 1 , 6 , 10 , 11 ]. Rather than relying solely on traditional neural net work la yers, these approac hes incorporate more structured, often nontriv- ial computations—such as constrained optimization—directly into the learning pip eline. These comp onen ts usually hav e structural or computational prop erties that hav e been pro v en useful in do wnstream tasks. F or instance, Sparsemax, a differen tiable pro jection onto the simplex, pro duces sparse p osterior distri- butions that are effectiv e as atten tion mec hanisms [ 17 ]. Similarly , Csoftmax, ⋆ Corresp onding author 2 C. Gomez et al. a pro jection on to the budget p olytop e, has demonstrated utilit y in sequence tagging [ 18 ]. This reflects a growing shift tow ard viewing learning systems as differen tiable computational frameworks that blend elements of traditional sta- tistical mo deling with algorithmic computation [ 5 ]. In this pap er, we fo cus on crafting a differen tiable, order-preserving pro jection into the n, k -dimensional h yp ersimplex [ 7 ]–a w ell-studied combinatorics p olytop e–in comp osition with a squared loss to generate a close approximation to the zero-one, misclassification loss compatible with mo dern large-scale differentiable systems. F rom a theoretical p erspective in machine learning, the goal is to minimize the exp ected v alue of a task-sp ecific loss function ov er a data distribution. F or classification, the most natural choice is the zero-one loss, which directly mea- sures misclassification error. Ho wev er, zero-one loss is non-differen tiable and dis- con tinuous, as it depends on a hard threshold decision—yielding gradients of zero almost ev erywhere and rendering it incompatible with gradient-based op- timization. T o enable tractable training, mo dern approaches rely on surrogate losses (e.g., cross-en trop y , hinge loss) that are smooth and differen tiable [ 3 ]. These surrogates serve as proxies that approximate the zero-one loss while fa- cilitating efficien t optimization. Despite their practicality , such surrogates often exhibit a mismatc h with the true ev aluation metric, esp ecially under large-batch regimes. This degradation in p erformance with large batch sizes is the so-called generalization gap [ 19 ], leading to gro wing interest in tighter, more faithful ap- pro ximations to the zero-one loss, under the hypothesis that closer surrogates yield b etter generalization. This work introduces a fully differentiable approximation to the zero–one loss, featuring an efficient forward pass with complexity O ( n log n ) and a backw ard pass with O ( n ) complexity . This is achiev ed through our no vel differen tiable pro- jection lay er, Soft-Binary-Argmax@k . Rather than treating the output scores as indep enden t, our lay er explicitly enforces that the largest k logits corresp ond to the predicted p ositiv e classes. This design ensures that small p erturbations in the input pro duce coherent, structurally consisten t adjustments in the out- put, making the Jacobian of the transformation inherently p ositional ly awar e with resp ect to the most confident predictions. The b enefits of this approach are t wofold: it allows binary classifiers to express multiple p ositiv e outcomes within a single forward pass, and it extends naturally to the multiclass setting by ap- plying the same pro jection principle across one-hot enco ded class dimensions. Imp ortan tly , the geometric constraints imp osed on the output logits act as a form of regularization that mitigates the generalization degradation typically observ ed under large-batch training, enabling stable optimization and improv ed predictiv e p erformance. More precisely , our contributions and nov elty can b e summarized as follows: 1. W e introduce a differentiable pro jection lay er—a smo oth thresholding op- erator realized via pro jection onto the interior of the n, k -dimensional hy- p ersimplex—termed Soft-Binary-Argmax@k . It provides a differentiable relaxation of the binary ar gmax , reduces to isotonic regression, and enables efficien t forward and backw ard computation on b oth CPU and GPU. Differen tiable Zero-One Loss via Hyp ersimplex Pro jections 3 2. W e prop ose a smo oth, almost-everywhere differentiable loss function for bi- nary classification, the Hyp erSimplex Loss , and derive its mathematical prop erties. The loss couples the mean squared error with our pro jection la yer and extends naturally to m ulticlass. 3. Through rigorous exp erimentation, we pro vide empirical evidence that the prop osed loss mitigates the generalization gap and impro ves p erformance across m ultiple classification b enc hmark datasets. 2 Related work 2.1 Differen tiable optimization-based ML Optimization-based mo deling integrates structure and constrain ts into machine learning architectures by embedding parameterized ar gmin / ar gmax op erations as differentiable lay ers. Such lay ers are often formulated as conv ex, constrained programs, with differentiabilit y ac hieved via the implicit function theorem ap- plied to the KKT conditions [ 11 ]. Parallel work has explored differentiable op- timization for order-constrained or monotonic outputs, including differentiable isotonic regression op erators for smo oth, order-aw are learning [ 6 ]. T o the b est of our knowledge, no prior work has in tro duced a differentiable Euclidean pro- jection on to the ( n, k ) -dimensional h yp ersimplex—computed via the P o ol Ad- jacen t Violators (P A V) algorithm—as a learnable lay er. Our approach fills this gap, providing an efficien t and theoretically grounded form ulation for in tegrating h yp ersimplex pro jections into mo dern differen tiable systems. 2.2 Generalization gap A w ell-known challenge in mo dern deep learning is the gener alization gap , where mo dels trained with large batch sizes achiev e low training loss but exhibit de- graded test p erformance. This phenomenon has b een widely observed in neural net works, as large batches tend to con verge to sharp minima that generalize p oorly compared to the flatter solutions found by small-batc h training [ 15 ]. Sub- sequen t work has explored remedies such as adaptiv e learning rate schedules and w armup strategies, noise injection and regularization [ 12 ], and sto c hastic weigh t a veraging [ 14 ] to mitigate this effect. How ever, to the b est of our kno wledge, our w ork is the first to address the generalization gap thr ough loss function design , in tro ducing a principled framework that directly links the geometry of the loss landscap e to generalization b eha vior. 3 Preliminaries In sup ervised multiclass classification, we are given a dataset D = { ( x i , y i ) } n i =1 , where eac h input x i ∈ X ⊂ R d is asso ciated with a categorical label y i ∈ { 1 , . . . , C } among C p ossible classes. Let f : X → R C denote a prediction 4 C. Gomez et al. function producing a score v ector f ( x i ) = ( f 1 ( x i ) , . . . , f C ( x i )) ⊤ , where eac h comp onen t f c ( x i ) reflects the mo del’s confidence for class c . The learning ob jectiv e is to minimize the multiclass zer o–one loss , which measures the fraction of misclassified samples: L 0 / 1 ( f ) = 1 n n X i =1 I [ ˆ y i = y i ] , ˆ y i = arg max c ∈{ 1 ,...,C } f c ( x i ) . (1) While L 0 / 1 directly quan tifies classification accuracy , it is discon tinuous and non-differen tiable, making it unsuitable for gradient-based optimization. T o obtain a differentiable surrogate, con vex losses are commonly employ ed. Common loss functions in mac hine learning—such as squared loss, hinge loss, and logistic loss—are conv ex approximations of the true 0–1 misclassification loss [ 3 ]. Among these, the squared loss provides the closest approximation to the 0–1 loss on the interv al (0 , 1) , making it a natural foundation for our formulation. The multiclass squar e d loss p enalizes deviations b et w een predicted scores and the corresp onding one-hot target enco dings, summing ov er all classes: L sq ( f ) = 1 n n X i =1 C X c =1 f c ( x i ) − I [ y i = c ] 2 . (2) Equiv alently , in matrix form, L sq ( f ) = 1 n ∥ F ( X ) − Y ∥ 2 F , where F ( X ) ∈ R n × C collects the mo del outputs and Y is the one-hot lab el matrix. While this smo oth, con vex loss provides analytic gradients and serves as a tractable approximation to L 0 / 1 , it also suffers from a ma jor drawbac k: it imp oses a quadratic p enalt y on extreme predicted v alues, leading to sensitivity to outliers [ 8 , 13 ]. This limitation motiv ates our pro jection-based formulation in tro duced next, whic h preserv es smo othness while constraining outputs within a geometrically consistent region. 4 Metho dology 4.1 Ov erview This work b egins by formulating the problem in the binary classification set- ting, where the ob jectiv e is to distinguish b et w een p ositiv e and negative out- comes. The same geometric principles, how ever, extend naturally to the m ulti- class setting, as shown in later sections. Common loss functions in mac hine learn- ing—suc h as squared loss, hinge loss, and logistic loss—are conv ex surrogates of the true 0–1 misclassification loss [ 3 ]. How ever, the true 0–1 loss minimizer lies at one of the v ertices of the ( n, k ) -dimensional hypersimplex, as it satisfies tw o k ey prop erties: 1. Its en tries are binary , i.e., each comp onen t of f ( X ) takes a v alue in { 0 , 1 } . 2. F or any given sample y drawn from the distribution of Y , a p erfect prediction v ector should con tain exactly k p ositive entries, matc hing the num b er of p ositiv es in y ; that is, ∥ f ( X ) ∥ 1 = ∥ y ∥ 1 = k . Differen tiable Zero-One Loss via Hyp ersimplex Pro jections 5 Motiv ated by the geometry of the optimal solution, we now in tro duce a se- ries of relaxations that make the learning problem tractable. First, w e relax the binary constrain t and allow f ( X ) to tak e real v alues in R n , while encour- aging sparsity—pushing predictions as close as p ossible to 0 or 1 . T o balance smo othness with structural fidelity , we comp ose our differentiable pro jection op- erator, the soft-binary-argmax@k , which pro duces sparse and nearly binary outputs, with the squared loss, which ensures smooth optimization and stability . This comp osition yields a surrogate ob jective that remains differentiable while closely aligning with the discrete geometry of the hypersimplex. The remainder of this section is organized as follows. W e b egin by establish- ing the connection betw een binary-argmax@k and thresholding. Next, we formu- late binary-argmax@k as a pro jection onto the n, k hypersimplex, from whic h w e derive its contin uous relaxation, soft-binary-argmax@k, and analyze its key prop erties. Finally , we combine the soft-binary-argmax@k with a squared loss to define the HyperSimplex loss, and demonstrate its effectiv eness in generalization for large batc h sizes. 4.2 Thresholding and the Binary-Argmax@k This section establishes an in tuitive connection betw een a real-v alued v ector x ∈ R n and its binary counterpart in { 0 , 1 } n . A common discretization metho d is thr esholding , where entries exceeding a fixed b oundary (typically 0 . 5 ) are set to 1 , and the rest to 0 . Although simple, this approach ignores relativ e ordering and offers no con trol ov er the num b er of p ositiv e comp onents. A more structured alternative is the binary-argmax@k op erator, denoted r k , whic h assigns 1 to the k largest entries of x and 0 to the remaining n − k . Here, the threshold is adaptiv ely defined b y the k -th largest v alue of x , reducing to standard thresholding when k = ⌈ n/ 2 ⌉ , where the threshold equals the empirical median of the logits. F ormally , let x ∈ R n b e a vector of scores and k ∈ { 1 , . . . , n } . W e define the binary-argmax@k op erator as r k ( x ) = I ( x i ≥ T k ( x )) , T k ( x ) = k -th largest v alue of x . (3) This rule ensures exactly k comp onen ts of x are set to 1 , enforcing the con- strain t ∥ r k ( x ) ∥ 1 = k , r k ( x ) ∈ { 0 , 1 } n . (4) The binary-argmax@k mapping do es not pro vide useful deriv atives, hindering gradien t-based optimization. T o address this, we formulate it as a linear opti- mization problem ov er the ( n, k ) -dimensional hypersimplex ∆ n k and introduce a Euclidean regularization term with a temp erature parameter, yielding a smo oth relaxation—the soft-binary-argmax@k. This differentiable form ulation preserves the hypersimplex geometry while providing informative gradien ts for end-to-end learning. 6 C. Gomez et al. 4.3 Binary-Argmax@k: Euclidean Pro jections onto the Hyp ersimplex The Euclidean pro jection onto the ( n, k ) -dimensional h yp ersimplex can b e ex- pressed as the solution of a simple regularized linear program: argmax y ∈ R n ⟨ x , y ⟩ − ∥ y ∥ 2 2 s.t. 1 ⊤ y = k , 0 ≤ y ≤ 1 . (5) The first term encourages alignmen t with the input vector x , while the quadratic regularization term enforces proximit y to the origin, thereb y inducing a balance b et ween sparsit y and fidelity . The affine constraint 1 ⊤ y = k fixes the ℓ 1 mass of y , ensuring exactly k active comp onen ts, while the b o x constraint 0 ≤ y ≤ 1 confines the solution to the h yp ercub e [0 , 1] n . The feasible region defined by these tw o constraints is precisely the ( n, k ) - dimensional h yp ersimplex: ∆ n k = ( y ∈ [0 , 1] n n X i =1 y i = k ) . (6) Hence, the optimization problem in ( 5 ) is equiv alent to the Euclidean pro jection o ver the hypersimplex: Π ∆ n k ( x ) = argmin y ∈ ∆ n k ∥ x − y ∥ 2 2 . (7) Since ∆ n k is conv ex and compact, this problem admits a unique solution. Geo- metrically , Π ∆ n k ( x ) corresp onds to the p oint within ∆ n k that lies closest to x in Euclidean dis tance, and algebraically , it coincides with the binary vector that activ ates the k largest comp onen ts of x , the binary-argmax@k. 100 010 001 001 010 100 Fig. 1. Binary-argmax@k of a p oin t x = (0 . 1 , 1 . 6 , 1) into the exterior of the Hyp ersim- plex (left). At k = 1 , the solution is (0 , 1 , 0) . Introducing temp erature to the program yields an in terior solution (righ t), i.e., the soft-binary-argmax@1. In R 3 differen t k v al- ues yield p oin ts on a standard simplex, but in higher dimensions yields a p oin t on the h yp ersimplex. In R 4 with k = 2 , the solution l ies on an o ctahedron [ 2 ]. Differen tiable Zero-One Loss via Hyp ersimplex Pro jections 7 4.4 Soft-Binary-Argmax@k: A Differentiable Approximation The pro jection Π ∆ n k ( x ) pro vides a geometric mapping from a contin uous vec- tor x to its structured binary coun terpart, but it remains piecewise constant and thus non-differentiable. Small p erturbations in x can abruptly change the iden tity of the top- k elemen ts, yielding discontin uities and zero gradients almost ev erywhere. Consequently , the hard binary-argmax@k op erator is incompatible with gradien t-based optimization. T emp er atur e-Sc ale d R elaxation. T o obtain a smo oth approximation, we intro- duce a temp erature parameter τ > 0 that scales the regularization strength in the pro jection ob jective: argmin y ∈ ∆ n k τ ∥ y ∥ 2 2 − 2 ⟨ x , y ⟩ = argmin y ∈ ∆ n k ∥ y ∥ 2 2 − 2 D x τ , y E (8) leading to the compact expression Π τ ( x ) = argmin y ∈ ∆ n k y − x τ 2 2 = Π ∆ n k x τ (9) As τ → 0 , the op erator recov ers the discon tinuous hard pro jection, while larger τ v alues yield smo other outputs closer to the h yp ersimplex—defining the soft- Binary-Argmax@k op erator. Prop osition 1 (Differentiabilit y a.e). Fix k ∈ { 1 , . . . , n } and τ > 0 . The mapping F τ : R n → ∆ n k , F τ ( x ) := Π ∆ n k x τ is (1 /τ ) -Lipschitz, henc e differ entiable almost everywher e (a.e.) in R n . Pr o of. The Euclidean pro jection on to a closed conv ex set in a Hilb ert space is nonexpansiv e: ∥ Π C ( u ) − Π C ( v ) ∥ 2 ≤ ∥ u − v ∥ 2 for all u , v . With C = ∆ n k and u = x /τ , v = z /τ , F τ ( x ) − F τ ( z ) = Π ∆ n k x τ − Π ∆ n k z τ ≤ x τ − z τ = 1 τ ∥ x − z ∥ . Th us F τ is (1 /τ ) -Lipschitz. By Rademac her’s theorem, ev ery Lipschitz map on R n is differen tiable a.e., proving the claim. Prop osition 2 (Order preserv ation). The pr oje ction solution y i = Π ∆ n k x i τ is or der pr eserving; that is, if x 1 /τ ≥ x 2 /τ ≥ · · · ≥ x n /τ , then the pr oje cte d c o or dinates satisfy y 1 ≥ y 2 ≥ · · · ≥ y n . Pr o of. F rom the KKT conditions of the Lagrangian asso ciated with ( 9 ), station- arit y and complementarit y yield, for each i , y i = clip x i /τ − λ 2 , 0 , 1 , where the multiplier λ is uniquely determined to satisfy the equality constraint P i y i = k . Since the mapping t 7→ clip t − λ 2 , 0 , 1 is monotone nondecreasing in t , it follo ws that x 1 /τ ≥ · · · ≥ x n /τ ⇒ y 1 ≥ · · · ≥ y n . See [ 9 ] for details. 8 C. Gomez et al. Corollary 1 (Computation). Sinc e the pr oje ction is or der pr eserving (Pr op o- sition 2 ), adding a monotonicity c onstr aint do es not change the solution. Henc e, for any sorte d input x /τ , the pr oje ction c an b e c ompute d via a r e duction to iso- tonic r e gr ession: Π ( x /τ ) = arg min y ∈ [0 , 1] n , 1 ⊤ y = k , y 1 ≥···≥ y n x τ − y 2 . The fe asible set is close d and c onvex, ensuring a unique and differ entiable solu- tion. This r e duc es to a standar d isotonic pr oje ction pr oblem, solvable efficiently via the p o ol-adjac ent-violators (P A V) algorithm [ 4 ] in O ( n log n ) time. 4.5 The Hyp erSimplex loss W e no w comp ose our pro jection op erator with the squared loss to define a smo oth surrogate for b inary classification. The squared loss pro vides high fidelit y to the zero–one ob jective within (0 , 1) but can b e dominated by large-magnitude predictions. By comp osing it with the pro jection op erator Π ∆ k n , we constrain predictions to the hypersimplex, preven ting any co ordinate from ov ertaking the loss while preserving the discrete geometry of the solution. F ormally , for x , y ∈ R n , define ˆ y = Π ∆ k n x τ , L ( x , y ) = 1 2 ∥ ˆ y − y ∥ 2 2 , where τ > 0 controls the smo othness of the relaxation. The gradient with resp ect to x follo ws from the chain rule: ∇ x L ( x , y ) = 1 τ J Π x τ ( ˆ y − y ) , where J Π denotes the Jacobian of the pro jection op erator Π ∆ k n . Let A = { i : 0 < ˆ y i < 1 } denote the activ e co ordinates. On this set, the Jacobian acts as J Π = I | A | − 1 | A | 11 ⊤ , yielding the comp onen t-wise gradient ( ∇ x L ) i = 1 τ ( ˆ y i − y i ) − 1 | A | P j ∈ A ( ˆ y j − y j ) , i ∈ A, 0 , i / ∈ A. A t b oundary p oin ts where some ˆ y i ∈ { 0 , 1 } , the mapping is only directionally differen tiable, and any subgradient consistent with this Jacobian form is v alid. 4.6 Extension to Multiclass Classification The formulation extends naturally to the m ulticlass setting. F or each class c ∈ { 1 , . . . , C } with logits x ( c ) ∈ R n , one-hot target y ( c ) , and temp erature τ c > 0 , w e pro ject onto the ( n, k c ) -h yp ersimplex: p ( c ) = Π ∆ n k c x ( c ) τ c . Differen tiable Zero-One Loss via Hyp ersimplex Pro jections 9 The total loss is L ( X, Y ) = 1 2 C X c =1 p ( c ) − y ( c ) 2 2 , ∇ x ( c ) L = 1 τ c J Π x ( c ) τ c ( p ( c ) − y ( c ) ) . This provides a smo oth, per-class pro jection framework that preserves h yp ersim- plex structure while remaining fully differentiable. During the learning pro cess eac h k c is set to matc h the exp ected n umber of p ositiv e resp onses for class c . 5 Exp erimen ts F or our exp eriments, we ev aluate the effectiveness of the prop osed Hyp erSim- plex loss in reducing the generalization gap compared to standard classification losses, including Cross-Entrop y , Hinge, and Mean Squared Error (MSE, without pro jection). This setup also serves as an ablation study to isolate the contribu- tion of our pro jection lay er, verifying that incorp orating geometric constrain ts on the output logits yields more consistent p erformance across batch sizes than the MSE ob jective alone. 5.1 Datasets W e conduct exp erimen ts on t wo standard image classification b enc hmarks: CIF AR- 10 [ 16 ] and F ashion-MNIST [ 21 ]. CIF AR-10 consists of 60,000 color images of size 32 × 32 pixels, split into 50,000 training and 10,000 test samples across 10 ob jec t categories. F ashion-MNIST contains 70,000 grayscale images of size 28 × 28 pixels, divided in to 60,000 training and 10,000 test images from 10 cloth- ing categories, serving as a more c hallenging replacemen t for the original MNIST dataset. 5.2 Exp erimen tal Setup W e emplo yed a standard conv olutional neural netw ork (CNN) for multiclass im- age classification, consisting of four conv olutional lay ers, each follo wed by batch normalization, max p o oling, and ReLU activ ation. The final feature map is flat- tened and passed through tw o fully connected lay ers, with the last lay er pro duc- ing class logits. The datasets w ere preprocessed using random cropping, horizon- tal flipping, and p er-channel normalization, and randomly split into training and test sets. All exp eriments w ere implemen ted in PyT orch [ 20 ] and executed on 32- core AMD Ryzen Threadripp er PRO 5975WX CPU with 503 GB of RAM and three NVIDIA R TX 6000 Ada Generation GPUs, each with 48 GB of VRAM. T o ensure statistical robustness, each configuration was trained using five indep enden t random seeds, v arying b oth mo del initialization and data splits. W e ev aluated four loss functions—our prop osed Hyp erSimplex loss and three widely used baselines: Cross-Entrop y , Hinge, and Mean Squared Error (MSE)– across sev en batc h sizes (128, 256, 512, 1024, 2048, 4096 and 8192) on b oth 10 C. Gomez et al. CIF AR-10 and F ashion-MNIST. In total, this resulted in 280 training runs. F or eac h configuration, we recorded the maximum test accuracy achiev ed p er loss function and batc h size, and assessed differences against the Cross-En tropy base- line using paired t -tests at the 10% significance lev el. This exp erimental design pro vides a rigorous and statistically grounded comparison, isolating the con tri- bution of the Hyp erSimplex form ulation to generalization stability under v arying batc h regimes. 5.3 Results 0 1000 2000 3000 4000 5000 6000 7000 8000 Batch size 0.85 0.86 0.87 0.88 0.89 Max A ccuracy CIF AR -10: Mean Max A ccuracy vs. Batch Size (A cr oss Seeds) Cr ossEntr opy HyperSimple x (l2=1.5) Hinge MSE 0 1000 2000 3000 4000 5000 6000 7000 8000 Batch size 0.934 0.936 0.938 0.940 0.942 0.944 0.946 0.948 Max A ccuracy F ashion-MNIST : Mean Max A ccuracy vs. Batch Size (A cr oss Seeds) Cr ossEntr opy HyperSimple x (l2=1.5) Hinge MSE F or CIF AR-10, all seven configurations rep ort p ositive mean accuracy dif- ferences, and all ( 100% ) show statistically significant improv ements at the 10% lev el ( p < 0 . 1 ). F or F ashion-MNIST, six of seven configurations ( ≈ 86% ) also ac hieve significance, with only the smallest batch size ( 128 ) falling abov e the 10% threshold. A cross b oth datasets, therefore, 13 of 14 total comparisons ( ≈ 93% ) demonstrate statistically significant gains, indicating that the prop osed loss sys- tematically outp erforms cross-entrop y across a wide range of training conditions. These findings confirm that the Hyp erSimplex loss maintains accuracy sta- bilit y at smaller batch sizes while mitigating the degradation observed in cross- en tropy as batc h size increases. This supp orts its effectiv eness as a smo oth, geometry-consisten t surrogate that enhances generalization and robustness in large-batc h training regimes. T able 1. Batc h-wise Comparison of Cross-Entrop y (CE) vs. Hyp erSimplex (HS) Losses on CIF AR-10 and F ashion-MNIST. The highlighted scores are statistically significant at a 10% level of significance. CIF AR-10 F ashionMNIST Batc h CE HS (ours) ∆ t-stat p-v al CE HS (ours) ∆ t-stat p-v al 128 0.8885 0.8917 0.0032 2.29 0.084 0.9456 0.9467 0.0011 1.31 0.262 256 0.8843 0.8874 0.0030 3.47 0.026 0.9434 0.9473 0.0040 4.34 0.012 512 0.8807 0.8857 0.0050 6.08 <0.01 0.9436 0.9469 0.0033 5.51 <0.01 1024 0.8776 0.8821 0.0045 9.78 <0.01 0.9413 0.9453 0.0040 6.67 <0.01 2048 0.8725 0.8791 0.0066 7.81 <0.01 0.9388 0.9446 0.0058 12.97 <0.01 4096 0.8659 0.8750 0.0090 13.14 <0.01 0.9371 0.9439 0.0069 9.68 <0.01 8192 0.8541 0.8648 0.0108 8.52 <0.01 0.9338 0.9415 0.0077 14.99 <0.01 Differen tiable Zero-One Loss via Hyp ersimplex Pro jections 11 5.4 Other Exp eriments: Cross-domain V alidation A dditional GBR T results on tabular datasets for classification are rep orted in App endix A , showing that the Hyp erSimplex loss also improv es out-of-sample generalization b ey ond the neural settings studied in the main text. 6 Conclusion W e introduced the soft-binary-argmax@k, a differentiable pro jection onto the in terior of the ( n, k ) -dimensional h yp ersimplex, and established its key prop er- ties—differen tiability , order preserv ation, and efficien t GPU computation. W e sho wed how this op erator integrates naturally into end-to-end learning systems, and used it to construct a surrogate to the zero–one loss for binary and m ulticlass settings, with statistically significan t reductions in the generalization gap. Owing to its close alignmen t with the true zero–one ob jectiv e, the prop osed Hyp erSimplex loss impro ves generalization under large-batc h training. Addi- tional cross-domain ev aluations on tabular data further suggest that the benefits of the pro jection extend b ey ond neural mo dels. F uture work will explore appli- cations to con trastive learning ob jectiv es and structured prediction. A App endix: Cross-Domain T abular Results Dataset Higgs Flight KDD10 KDD12 Criteo A v azu KKBox MovieLens Cross Entropy 0.823 0.773 0.826 0.724 0.774 0.738 0.777 0.827 HyperSimplex 0.846 0.778 0.849 0.729 0.796 0.741 0.797 0.828 References 1. Agra wal, A., Amos, B., Barratt, S.T., Boyd, S.P ., Diamond, S., Kolter, J.Z.: Differen tiable conv ex optimization la yers. CoRR abs/1910.12430 (2019), http: 2. Amos, B., Koltun, V., Kolter, J.Z.: The limited m ulti-lab el pro jection lay er (2019), h 3. Bartlett, P .L., Jordan, M.I., McAuliffe, J.D.: Con vexit y , classification, and risk b ounds. Journal of the American Statistical Association 101 (473), 138–156 (2006) 4. Best, M.J., Chakra v arti, N.: Activ e set algorithms for isotonic regression: a unifying framew ork. Mathematical Programming 47 (1-3), 425–439 (1990). https://doi.org/ 10.1007/BF01580880 5. Blondel, M., Roulet, V.: The elemen ts of differen tiable programming (2024), https: 6. Blondel, M., T eb oul, O., Berthet, Q., Djolonga, J.: F ast differentiable sorting and ranking. In: International Conference on Machine Learning. pp. 950–959. PMLR (2020) 12 C. Gomez et al. 7. De Lo era, J.A., Sturmfels, B., Thomas, R.R.: Gröbner bases and triangulations of the second hypersimplex. Com binatorica 15 (3), 409–424 (1995). https://doi.org/ 10.1007/BF01299745 8. Gneiting, T., Raftery , A.E.: Strictly prop er scoring rules, prediction, and estima- tion. Journal of the American Statistical Asso ciation 102 (477), 359–378 (2007) 9. Gomez, C.: F ast Differen tiable Pro jection Lay ers on to High-Dimensional Polytopes for Large-Scale Predictive Mo deling. Ph.D. thesis, Universit y of Central Florida (2025), https://stars.library .ucf.edu/etd2024/450 10. Gomez, C., W ang, P ., F u, Y.: Metric-agnostic learning-to-rank via b oosting and rank approximation. In: 2023 IEEE International Conference on Data Mining (ICDM). pp. 1043–1048 (2023). https://doi.org/10.1109/ICDM58522.2023.00121 11. Gould, S., F ernando, B., Cherian, A., Anderson, P ., Cruz, R.S., Guo, E.: On differ- en tiating parameterized argmin and argmax problems with application to bi-level optimization. CoRR abs/1607.05447 (2016), 12. Hoffer, E., Hubara, I., Soudry , D.: T rain longer, generalize better: Closing the generalization gap in large batch training of neural netw orks. In: Pro ceedings of the 31st Conference on Neural Information Pro cessing Systems (NeurIPS). pp. 1731–1741 (2017) 13. Hub er, P .J.: Robust estimation of a lo cation parameter. The Annals of Mathemat- ical Statistics 35 (1), 73–101 (1964) 14. Izmailo v, P ., Podoprikhin, D., Garip o v, T., V etrov, D., Wilson, A.G.: A veraging w eights leads to wider optima and better generalization. In: Pro ceedings of the 34th Conference on Uncertain ty in Artificial Intelligence (UAI). pp. 876–885 (2018), h 15. Kesk ar, N.S., Mudigere, D., No cedal, J., Smelyanskiy , M., T ang, P .T.P .: On large- batc h training for deep learning: Generalization gap and sharp minima. In: Pro- ceedings of the 5th International Conference on Learning Representations (ICLR) (2017), https://openreview.net/forum?id=H1oyRlY gg 16. Krizhevsky , A.: Learning m ultiple la yers of features from tin y images. T ech. Rep. TR-2009, Universit y of T oronto (2009), https://www.cs.toron to.edu/~kriz/ learning- features- 2009- TR.p df 17. Martins, A.F.T., Astudillo, R.F.: F rom softmax to sparsemax: A sparse mo del of attention and multi-label classification. CoRR abs/1602.02068 (2016), http: 18. Martins, A.F.T., Kreutzer, J.: Learning what‘s easy: F ully differentiable neural easy-first taggers. In: Palmer, M., Hwa, R., Riedel, S. (eds.) Pro ceedings of the 2017 Conference on Empirical Metho ds in Natural Language Pro cessing. pp. 349– 362. Asso ciation for Computational Linguistics, Copenhagen, Denmark (Sep 2017). h ttps://doi.org/10.18653/v1/D17- 1036 , https://aclan thology .org/D17- 1036/ 19. Oy edotun, O.K., Papadopoulos, K., A ouada, D.: A new persp ectiv e for under- standing generalization gap of deep neural netw orks trained with large batch sizes (2022), 20. P aszke, A., Gross, S., Massa, F., Lerer, A., Bradbury , J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., An tiga, L., Desmaison, A., Köpf, A., Y ang, E., De Vito, Z., Raison, M., T ejani, A., Chilamkurthy , S., Steiner, B., F ang, L., Bai, J., Chintala, S.: Pytorc h: An imp erative style, high-performance deep learning library . In: Adv ances in Neural Information Pro cessing Systems. pp. 8024–8035 (2019) 21. Xiao, H., Rasul, K., V ollgraf, R.: F ashion-mnist: A nov el image dataset for b enc h- marking machine learning algorithms. arXiv preprint arXiv:1708.07747 (2017), h
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment