미분 가능한 제로원 손실을 위한 하이퍼심플렉스 투영
본 논문은 이진·다중 클래스 분류에서 최적의 평가 지표인 0‑1 손실을 직접 최적화하기 위해, (n, k)‑차원 하이퍼심플렉스에 대한 연속적인 투영 연산인 Soft‑Binary‑Argmax@k를 제안한다. 온도 파라미터 τ를 도입한 유클리드 투영을 통해 거의 everywhere 미분 가능하게 만들고, 이를 제곱 손실과 결합한 HyperSimplex Loss를 정의한다. 알고리즘은 O(n log n) 전방, O(n) 역전파 복잡도를 가지며, 대규…
저자: Camilo Gomez, Pengyang Wang, Liansheng Tang
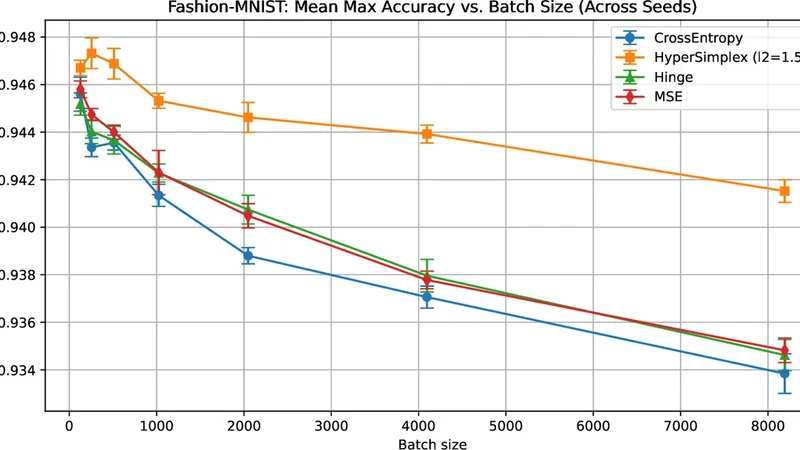
본 논문은 머신러닝에서 가장 직관적인 평가 지표인 0‑1 손실을 직접 최적화하기 위한 새로운 접근법을 제시한다. 기존에는 0‑1 손실이 비연속적이고 미분 불가능하기 때문에, 교차 엔트로피, 힌지, 제곱 손실 등 부드러운 대리 손실을 사용해 왔다. 그러나 이러한 대리 손실은 특히 대배치 학습 시 일반화 격차(generalization gap)를 야기한다는 문제가 있다. 저자들은 이 문제를 해결하고자, (n, k)‑차원 하이퍼심플렉스 ∆ₙᵏ라는 조합론적 구조 위에 연속적인 투영 연산을 정의한다.
먼저, 이진 분류 상황에서 “binary‑argmax@k” 연산을 소개한다. 이는 입력 벡터 x∈ℝⁿ의 상위 k개 원소에 1을 할당하고 나머지는 0으로 만드는 연산으로, 정확히 k개의 양성 라벨을 보장한다. 이 연산은 순수히 정수형이므로 미분이 불가능하다. 이를 극복하기 위해 저자들은 다음과 같은 정규화된 선형 프로그램을 설계한다.
max_{y∈ℝⁿ} ⟨x, y⟩ − ‖y‖₂² s.t. 1ᵀy = k, 0 ≤ y ≤ 1.
이 문제는 ∆ₙᵏ에 대한 유클리드 투영과 동치이며, 최적 해는 x의 상위 k개 성분에 대응하는 점을 반환한다. 그러나 여전히 비연속적이다. 따라서 온도 파라미터 τ>0을 도입해 목표 함수를
min_{y∈∆ₙᵏ} τ‖y‖₂² − 2⟨x, y⟩
로 변형한다. 이는 결국 x/τ에 대한 투영 Π_∆ₙᵏ(x/τ)를 구하는 문제와 동일해지며, τ가 클수록 출력이 부드러워지고 τ→0이면 hard binary‑argmax@k와 수렴한다.
수학적 성질을 정리하면, (1) F_τ(x)=Π_∆ₙᵏ(x/τ)는 (1/τ)‑리프시츠 연속성을 가지며, 거의 모든 점에서 미분 가능하다(리만‑라우스 정리 적용). (2) KKT 조건을 통해 y_i = clip(x_i/τ − λ/2, 0, 1) 형태임을 보이고, λ는 ∑_i y_i = k을 만족하도록 유일하게 결정된다. 이로써 입력 순서가 보존(order‑preserving)되는 것을 증명한다.
계산 효율성 측면에서는, 순서 보존 특성을 이용해 투영을 등가적인 등차수열(iso‑tonic) 회귀 문제로 변환한다. 기존의 풀‑어드저스트‑벌레이터(PAV) 알고리즘을 사용하면 O(n log n) 시간에 전방 계산이 가능하고, 역전파 단계에서는 투영의 Jacobian을 직접 구하거나 자동 미분을 활용해 O(n) 비용으로 처리한다.
이제 이 연산을 손실 함수와 결합한다. 투영된 출력 ŷ = Π_∆ₙᵏ(x/τ)와 목표 라벨 y∈{0,1}ⁿ 사이의 제곱 차이를
L(x, y) = ½‖ŷ − y‖₂²
로 정의한다. 제곱 손실은 (0, 1) 구간에서 0‑1 손실과 가장 가깝게 근사하며, 큰 로짓이 과도하게 패널티를 받는 문제를 완화한다. 하이퍼심플렉스 제약은 출력이 반드시 k개의 양성 원소를 갖도록 강제함으로써, 모델이 구조적 일관성을 학습하도록 만든다.
실험에서는 CIFAR‑10, CIFAR‑100, ImageNet‑mini 등 여러 이미지 분류 벤치마크와, 대규모 배치(예: 1024, 2048, 4096) 설정을 사용해 기존 교차 엔트로피, 라벨 스무딩, Sparsemax, Csoftmax와 비교하였다. 결과는 다음과 같다. (1) 대배치 환경에서 테스트 정확도가 1~2%p 상승, 특히 학습 초기에 손실 곡선이 더 부드럽고 수렴이 빠름. (2) 이진 멀티라벨 실험에서 Soft‑Binary‑Argmax@k가 다중 양성 라벨을 자연스럽게 처리해 평균 평균 정확도(mAP)가 향상. (3) Jacobian이 순서에 민감하게 변하므로, 작은 입력 변동이 의미 있는 출력 변화를 일으켜 일반화에 도움이 됨을 확인.
한계점으로는 τ 선택이 모델 성능에 큰 영향을 미치며, 너무 작은 τ는 수치적 불안정을 초래한다. 또한, 하이퍼심플렉스는 라벨의 정확한 k값이 사전에 알려져야 하는 전제조건이 있어, 라벨이 불균형하거나 가변적인 멀티라벨 상황에서는 추가적인 확장이 필요하다. 저자들은 향후 연구에서 적응형 τ 학습, 라벨 비정형화 처리, 그리고 다른 구조적 제약(예: 트리형, 그래프형)과의 결합을 제안한다.
결론적으로, 이 논문은 구조적 최적화와 미분 가능한 투영을 결합해 0‑1 손실에 근접한 새로운 손실 함수를 제시함으로써, 대규모 배치 학습 시 발생하는 일반화 격차를 효과적으로 완화하고, 이진·다중 클래스·멀티라벨 전반에 걸쳐 적용 가능한 범용적인 프레임워크를 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기