Invariant Transformation and Resampling based Epistemic-Uncertainty Reduction
An artificial intelligence (AI) model can be viewed as a function that maps inputs to outputs in high-dimensional spaces. Once designed and well trained, the AI model is applied for inference. However, even optimized AI models can produce inference e…
Authors: Sha Hu
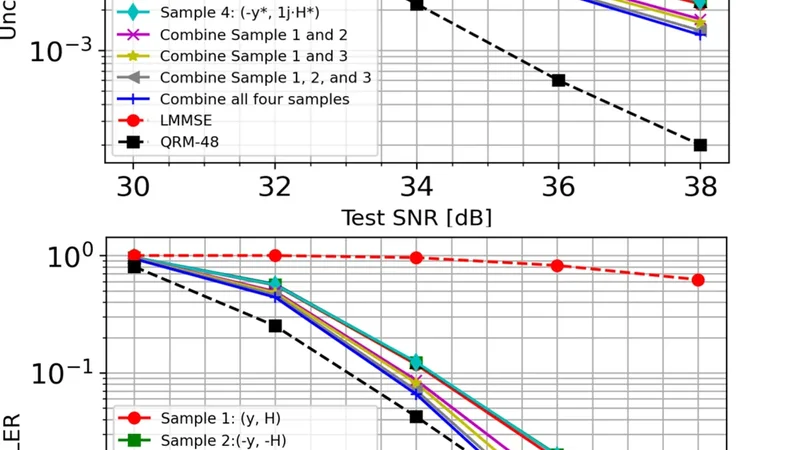
In v ariant T ransformation and Resampling based Epistemic-Uncer tainty Redu ction Sha Hu Lund Research Center , Huawei T ech nologies Sweden AB, Sweden. Email: hu.sha @huawei.com Abstract —An artificial intelligence (AI) model can be v iewed as a fun ction that maps inp uts to outputs in high-dimensional spaces. Once designed and well trained, the AI model is applied fo r inf erence. Howev er , even optimized AI models can produce inference errors due to aleatoric and epistemic un certainties. Interestingly , we observ ed that when inferring mult i ple samples based on in variant transf ormations of an input, infere nce er rors can show partial i ndependen ces du e to epistemic uncertainty . Lev eraging this insight, we propose a “resampling“ b ased in - ferencing that applies to a trained AI model with multiple transfo rmed versions of an in put, and aggrega tes i nference outputs to a more accurate result. This approach has the potential to improv e inference a ccuracy and offers a strategy fo r balancin g model size and perform ance. I . I N T RO D U C T I O N Artificial intelligen ce (AI) and mach ine learning (ML) are emerging as key enab lers [1 ]–[7] in sixth -gener ation (6G) system. Recent p roposals aim to e n hance conventional signal processing modules, inducing channel estimation (CE) [8]– [11] and multi-inpu t multi-outpu t ( M IMO) dete c tion [12]– [14]. While supervised learning allo ws AI models to be trained with labels, there are two uncertain ties in ML, kn own as aleatoric u ncertainty an d epistemic uncertain ty [24], [2 5 ], respectively . Aleatoric un certainty reflects the inheren t ran - domness from the n oisy data a nd is reducible, while epistemic uncertainty m easures the imp erfectness o f learning and can be red uced by means of scaling training dataset a n d mo del size, optimizin g model architecture, and adju sting lea r ning methods. Due to uncertain ties, even a well-trained AI model with large network size can still prod uce inference e r rors. In the context MIMO dete c tion, conventional quasi maximum -likelihood (ML) detector s [15] – [18] perf orm near- optimally . AI b a sed designs have also demonstrate d compara- ble p e r forman ce [1]. Howev er , as system grows more co mplex when signal-to-no ise ratio (SNR) increases, such as with large MIMO sizes (e.g., 8 × 8 ) and high -order quad r ature am plitude modulatio n (QAM) like 6 4QAM and 256QAM, subop timal detectors can suf fer f rom perform ance losses relati ve to the ML d etector . T h ese lo sses b ecome pronounced with a hig h code-ra te wh en op erational unc oded bit error rate (BER) is below 1%. T his p resents a challeng e for AI ba sed M IMO detector th at relies o n learn ing fr om statistical pa tter ns in training data. Ach ieving such a high p recision requir es very large n e twork s an d extensive amou n t of tra in ing d ata, leading to increased com plexity and cost. Instead o f optimizing AI model in training process, we consider an in teresting question: Can inference ac curacy be impr oved witho ut a trained AI model? Our find ings su g gest T rained AI Model ( , ) f (-y, -H ) s f (y, H) P -1 f ( Qy, QHP ) Fig. 1. Resamplin g a traine d MIMO detector with multiple inference samples generat ed from conjugates, flips, and permutations for an input ( y , H ) . the answer is yes. The idea is to le verag e properties of th e considered problem that are difficult for AI to fully capture from learning , such as inv ariant tra n sformatio n s of MIMO de- tection m odel. Specifically , wh en p e rformin g in ferences with multiple samp les, inferen ce errors exhibit partial statistical indepen d ence that arises from the ep istem ic u ncertainty . This can be exploited to enhance a trained AI model throu g h a “re- sampling”, wh e re multip le infere n ces are treated as d ifferent samples for the trained AI mo del. A combin a tio n of resamp led inference outp u ts c an yield a better results with less epistemic uncertainty . Fig. 1 illustrates this concept, and we provid e analytical insights and numerical results to demonstrate th e enhancem ents with resamplin g for AI b ased MIMO detection . Note that a similar fr amework has been kn own as test time augmen ta tio n ( T T A) [2 6]–[2 8] in image classifications, which makes pr edictions o n a set of in puts at test time with data augmen ta tio ns a n d aggregates those prediction s for a final prediction . Ho we ver , data au gmentatio ns employed in TT A predom inantly rely on heu r istic techn iques such as im age rota- tions, flips, and addin g extra noise, which lack solid theor etical justifications. Fu rthermo re, the optimal strategy for combin in g multiple outpu ts rem ains ambiguo u s. By compar ison, our “resampling ” proposal is ground ed in inv ar iant transfor m a- tions and en dowed with clear math ematical me a nings, a n d the optimal co m bining can be derived fro m err o r correlatio n s. Moreover , we also elucidate th e co nnection s b etween r esam- pling a trained AI mode l and epistemic unc e rtainty r eduction. I I . R E S A M P L I N G A T R A I N E D A I M O D E L A. Mathematical F ormulatio ns Consider a g eneral inp u t-outpu t system y = f ( s ) + n , (1) where the hyper-dimension al parame ter s is the inp ut an d y is the outpu t co rrupted by a noise n . W itho ut loss o f genera lity , the noise is assumed zero -mean and the variance is norm alized to o ne and excluded f rom th e m odel inputs. The system is governed by a map ping function f , which can b e lin e a r or non-lin e ar , known o r unkn own before h and. Char( f ) y Lables s Loss( , ) T raining AI Model (a) Supervised T raining: (b) Normal Inferencing: (c) Resampling based Inferencing: Char( f ) y T rained AI Model Char( f ) y 0 , 1 , ... , M-1 T rained AI Model Generate multiple samples for inferencing Combine multiple estimates ( y 0 , Char( f 0 )) ( y M-1 , Char( f M-1 )) ... ( y 1 , Char( f 1 )) s est Fig. 2. Con ventio nal supervised-le arning based traini ng (a) and inferenci ng (b), and the proposed resampling based inferenc ing with multipl e samples generat ed from an input observ ation. In case f is unkno wn, Char ( f ) is exc luded from the inputs to the model. A co mmon task is to estimate s from a noisy observation y as in (1). In this c ase, the optim al Bay esian estimator th a t maximizes a p osteriori (MAP) is ˆ s = argma x p ( y | s ) p ( s ) , (2) where p ( y | s ) is th e likelihood and p ( s ) is the pr iors o f s . In the absence of p ( s ) , it redu ces to the ML estimato r ˆ s = argma x p ( y | s ) . (3) In g eneral, the n oise n is also modele d as additive w h ite Gaussian noise (A WGN). Und er this assump tion, maximizing the likelihood p ( y | s ) is eq uiv alen t to min im ize the error ˆ s = argmin k y − f ( s ) k 2 . (4) In high dim ensional sp a c es, an exhaustive sear ch o ver s is computatio nally infea sible. For in stan ce, in an 8 × 8 MI MO system with 256QAM modu lation, th e search size for s is 8 256 , which is pro hibitively large. Suboptimal a lg orithms h ave been developed over the past h alf cen tury un der the umb r ella of MIMO d e te c tion, o ffering near-optimal performa nce with significantly reduced com plexity . W ith the rise of AI, it is also p o ssible to ap ply super vised- learning to solve (1). Essentially , the AI m odel is trained to learn an inverse map ping ˆ s = ϕ ( y , Char ( f )) , (5) where Ch ar ( f ) represents the mappin g cha racteristic of f . Definition 1 (Mapping Characteristic): Th e ch aracteristic Char ( f ) is defined as a representation o f m apping f that serves as an inp ut to the AI mod el associated with th e observation y in tra in ing and infere ncing fo r solving (1). The form of Char ( f ) is desig n -depen dent. For example, in a lin ear MI MO system y = H s + n (6) where f ( s ) = H s , the c haracteristic c a n be defined as Char ( f ) = H or ( Re { H } , Im { H } ) if H is co mplex-valued. An AI based MIM O de te c tor operates in two stag es: a training stage an d an in ference stag e, as illu strated in Fig. 2(a) and Fig. 2(b) , r espectively . Dur in g training stag e, a sufficiently large d a ta set co mprises of input-o utput pairs ( y , s ) is u sed to train the model, toge th er with the charac te r istic Char ( f ) . Th e inputs s serve as labels to m in imize a predefine d loss f u nction. After the mod el is well-trained , it is applied in inferen ce, where it estimates ˆ s for any observation y , most of which are p reviously un seen in training . The AI mo del is expected to exploit the statistics fr om the training d ata an d lear n a reverse- mapping ϕ ( · ) that reco nstructs s from y and Char ( f ) . B. In variant T ransformations Although AI b ased de signs can be effecti ve, one limitatio n is that they of ten fail to fully lea r n the inher e nt prop e rties of the s ystem. Consider a general transformation T ( y ) on (1 ) with two functions g and q (and an in verse fu nction q − 1 ) to form a new mapp ing T f = g ◦ f ◦ q − 1 such th a t T ( y ) = ( g ◦ f ◦ q − 1 )( q ( s )) + g ( n ) = T f ( q ( s )) + g ( n ) . (7) Definition 2 (I n variant T ransformation): For a tran sforma- tion T in (7) to be inv arian t, it sha ll meet the condition that the distributions of Char ( T f ) , q ( s ) , an d g ( n ) are all identical to Char ( f ) , s , and n , r e sp ectiv ely . For instan ce, if the ch annel H in (6) follows a Rayleigh distribution [1 ], and the en tries in s drawn from a QAM con- stellation are indepen dent and ide ntically distributed ( i.i.d.), then th e following tran sfo rmation s are inv arian t: • Line a r transform ation with a u nitary matr ix Q : T ( y ) = Qy = QH s + Qn . (8) • Permu ting ch annel and data entries via a permutation matrix P : T ( y ) = y = H P T ) P s ) + n . (9) • Comp lex co njugate: T ( y ) = y ∗ = H ∗ s ∗ + n ∗ . (10) Specifically , inv a r iant transfor m ations in cluding u n itary rota- tions, conjug ate, and perm utations arise from the statistical proper ties of H , s , and n . These o perations preserve the statistical structur e of system, and lead to eq uiv alen t detec tio n perfor mance in ML sense. Hence, the b elow Prope r ty 1 holds. Pr operty 1: For an AI mode l tr ained on inpu t sam p les y , Char ( f ) and labels s , it also works fo r tran sformed samples T ( y ) , Char ( T f ) under an in variant transfo rmations T , an d with equal in ference accur acy . C. Resampling Theor em Next we present the m a in result. In gener al, an inference output fr om th e traine d AI model can be modeled as ˆ s = s + z , (11) where z repr e sents an estimation erro r and can b e reaso n ably modeled as Gaussian due to the Central Limit Theorem. If there are multiple estimates of s , the accura cy can b e refined. Theor em 1: Assume there are M estimates of a scalar variable s , denoted as s m = s + z m , and z m represents a zero-mea n estimation err or with identical variance var ( z m ) = σ 2 . Further, the correlatio n between any two e rrors satisfies cov ( z m , z n ) = ρ mn σ 2 for m 6 = n . Con stru ct an estimate ¯ s with a lin ear co mbination ¯ s = M − 1 X m =0 β m s m (12) subject to P M − 1 m =0 β m = 1 . The minimum variance of estima- tion er ror in ¯ s is var (¯ s ) = 1 1 T R − 1 1 , (13) attained w ith we ig hts β = R − 1 1 1 T R − 1 1 . (14) Here R deno tes the covariance ma trix amon g th e M estimates and 1 is the vector with all entries equ al to 1. T h e vector β comprises of co mbination weigh ts in (12 ) . Theorem 1 ca n be dire ctly verified. As a n example, con - sidering the case ρ mn = ρ f or m 6 = n , th e optima l weight β m = 1 / M and the minim u m variance is ρ + 1 − ρ M . W ith Prop erty 1, M infere n ce samples can be generated from tra n sformatio n s with an in p ut ( y , f ) . This can be v iewed as “resamp ling” of the fu nction ϕ ( y , f ) , as shown in Fig. 2(c), and it turns out to be an effective technique when ρ < 1 . No te that as M → ∞ , the minimu m variance o f estimation error conv erges to ρ . An illu stration o f variance decrement with refined estimate is shown in Fig. 3. D. Epistemic Uncertainty Redu ction with Resamplin g The inference erro r in (11) contains two p arts: a leatoric uncertainty inh erited from the rando mness in p ( s | y ) , an d epistemic uncertainty d ue to imperfect lear ning. Fro m [25], the epistemic u ncertainty can be measured by var T E s | y [ ˆ s |T ( y ) , T f ] = E T ϕ T ( T ( y ) , T f ) − ¯ ϕ T 2 . (1 5) Fig. 3. The varia nce decrements in relati on to ρ mn = ρ for m 6 = n . For simplicity , he re we assume that for a ny transfo r mation T ( y ) , the inference r e sult is s . T h e mapping fu nction ϕ T de- notes a trained n etwork with the tr aining data set transfor med with T . Its in f erence outpu t is d enoted as ϕ T ( T ( y ) , T f ) for the o b servation T ( y ) . Th e mean of inferenc e results from all transform ations th at r emoves epistemic unce rtainty equals ¯ ϕ T = E T [ ϕ T ( T ( y ) , T f )] . (16) On the o ther han d , with the proposed resampling techn ique, in essence it constru cts a new mappin g function ϕ T = E T [ ϕ ( T ( y ) , T f )] . (17) Pr operty 2: If the training dataset { y } contain s all inv arian t transform ations such that {T y } = { y } for any T , the n it holds that ϕ T = ϕ , and ¯ ϕ T = ϕ T . (18) Property 2 rev eals that a training dataset needs to be in- finitely large to mitiga te epistemic unce r tainty . Howev er , (1 7) provides a nother ap p roach to mitig a te epistemic unc e r tainty in inferen ce stage o th er th an in training [2 4], [25], especially when the difference b etween ϕ T and ¯ ϕ T is small. On the other hand, by increasing the numb er of samp les M , the “resampling b ased inferen ce” can ser ve as a perfo rmance bound for the AI m odel to be train ed, in the sense of minimizing e p istemic un certainty . E. Discussions When no ise level in the system is high in (1), alea toric uncertainty dominates the inference er ror in (11), a n d this often results in h igh correlation s across inferen ce errors from different tran sformation s, thereby limiting the benefits of resampling. In con trast, a s noise level go es down, epistemic uncertainty bec o mes domin ant in the inference e r ror, making resampling m ore effectiv e at high SNR. On the other hand , in case f or its pro perties are un k nown, since ge n erating multiple samples via in variant-transformatio n is not straightfo rward, h euristic resampling metho ds can be considered . One h euristic resampling can construct trans- formed or p erturbed versions based on y and infer ence th ese samples with the same AI model. The inferen c e results can be combin e d eithe r via a conventional method or with an other neural network . Th e heu ristic metho d som etimes can be effecti ve, but unlike resamp ling with in variant transfo r mations, an an a lytical un derstandin g can be intractable. Fig. 4. The distributi on of inference errors and example samples. I I I . S I M U L AT I O N R E S U LT S W I T H M I M O D E T E C T I O N Consider a MIMO tra n smission on two resource block s in 5G system. An AI based MIMO detector is c o nstructed with T r ansforme r Enc oder with inp uts ( y , H ) . Th e ou tput is a matrix comprises of either log-likelihoo d ratio (LLR) values L m,k for the k th bit on the n th lay er , or the marginal probab il- ities p ( s n,m = s m | y , H ) f o r each co nstellation symb ol s m on each layer . T he AI mo d el contains four Transformer Enc o ders and each with 4 heads. The mod el size a n d feed-for ward network (FFN) sizes are set to 25 6 and 1 024, respecti vely , for 4 × 4 MI M O. T his y ields a numb er of trainable param eters close to 3 M , and both sizes are do ubled for larger MIM O an d higher-order modulatio ns. A. Infer ence Err ors W e firstly evaluate a 4 × 4 MIMO with 64QAM modu- lation in (6), an d H is modeled as i.i.d . Rayleigh chann el. Since the AI m odel applies real-valued inputs, the complex- valued mo del is equiv alently con verted into an 8 × 8 real- valued m odel, and s con tains 8P AM symbols uniform ly drawn from {± 1 , ± 3 , ± 5 , ± 7 } . The AI d e tector is tr a ined at SNR=26dB and o utputs the marginal proba b ilities p ( s n,m = s m | y , H ) . The m easured SERs when inferencin g with ( y , H ) or ( − y , − H ) are both eq ual to 5.7%, which matche s with SER in training . Notably , if these two inf erence ou tputs are combined , SER is red uced to 5.1%. Fig. 4 illustrates the inferen ce errors z in r econstructed soft estimates E ( s m | y , H ) , wh ich is trun cated in to inter val (-1. 5 , 1,5), since an symbol error o c curs when an er ror fall ou tside this range. I nferenc e errors correspo nding to ( y , H ) an d (- y , - H ) b oth approx imately exhibit Gau ssian distributions, with a m ean-value 0 . 004 that is close to zero and a variance σ 2 = 0 . 385 . The correlation between these two errors is ρ = 0 . 71 . After averaging th e two infer ence o utputs, the error-variance is reduc e d to 0 .33, which perfec tly align s with th e pr e diction ( ρ + 1 − ρ M ) σ 2 based o n Theore m 1. Fig. 5. Uncoded BER and BLER for 8 × 8 MIMO and 256QAM modulat ion under ETU-70Hz channel. B. P erforman c e Enh ancements Next we co nsider an 8 × 8 MI M O with 256QAM m odulatio n in (6 ). In addition, a low-density parity - check (LDPC) c ode with a high co d e-rate 12 / 13 is ap p lied for measuring th e block-er ror-rate (BLER). Th e chan nel H is m odeled as ETU- 70Hz spec ified in 5 G. The AI model is trained at SNR=34dB, and in this case, dire c tly ou tput LLR values L m,k for decod er . W e resample the AI model with three inv ariant transfor ma- tions: (- y , - H ), ( y , H P ), and ( y ∗ , 1 j · H ∗ ) , wh ere P denotes a r andom colu m n p e rmutation on H . As can b e seen in Fig. 5, alth o ugh the AI model is trained at SNR=34dB, it works well fo r SNR values fro m 3 0dB to 38dB. By combin g the infe r ence outputs from multiple samp les, b o th the unco ded BER and BLER are consistently improved. W ith four inference o utputs, th ere is around 0.5dB gain s at 1% uncod e d BER, and 0 .7dB gains at 10% BLER. These gains become larger as SNR increases. In this case, the ML detector is infeasible and we compar e AI d etector to conventional LMMSE and QRM d etectors. While LMMSE h as the worst perfor mance, the AI detector approaches the QRM detector [16] that preserves 48 best n odes on each lay er after sorting 48 × 256 candidate node s. As shown in Fig. 3 and also from Theorem 1, the gains with com bining more samp les become smaller as M increa ses. I V . S U M M A RY W e hav e proposed a resampling techniqu e f or a trained AI m odel. Un der inv a r iant transfo rmations, the trained AI model p rodu ces inferen ce ou tputs with errors th at may have indepen d encies a m ong transfor med input samples . Comb ing multiple inferenc e outp uts can effecti vely improve th e infer- ence accura cy and redu ce the ep istemic uncertain ty . W e have demonstra te d the pr o posal with a n AI based MIMO detector design, and showed that und er 8 × 8 MIMO and 2 56QAM modulatio n, the SNR g ains with resampling the trained AI model can b e up to 1dB. R E F E R E N C E S [1] X. Qin, S. Hu, J. Zhang, J. Qian, and H. W ang, “ AI Recei ver Design with Deep Learning Based Channel Es timatio n and MIMO Detectio n”, Int. Symp. Personal , Indoor Mobile Radio Commun. (PIMRC) pp. 1-7, Sep. 2024. [2] M. Soltani, V . Pourahmadi , A. Mirzaei, and H. S heikhzadeh, “Deep learni ng-based channel estimation, ” IE EE Commun. Lett. , vol. 23, N o. 4, pp. 652-655, Apr . 2019. [3] P . Jiang, C. K. W en, S. Jin, and G. Y . L i, “Dual CNN-based channel estimati on for MIMO-OFDM systems, ” IEE E T rans. Commun. , vol. 69, no. 9, pp. 5859-5872, Sep. 2021. [4] J. Sun, Y . Zhang, J. Xue, and Z. Xu, “Learning to search for MIMO detec tion, ” IEEE T rans. W ireless Commun. , vol. 19, no. 11, pp. 7571- 7584, Nov . 2020. [5] S. Cammerer et al., “ A neural recei ver for 5G NR multi-user MIMO, ” IEEE Global Commun. Conf. (GLOBECOM) Wkshps, Kual a Lumpur, Malaysia , Dec. 2023, pp. 329-334. [6] T . Ravi v , S. Park, O. Simeone, and N. Shlezinger , “Modular m odel- based Bayesian learning for uncertaint y-a ware and reliable deep MIMO recei vers, ” https://d oi.org/ 10.48550/a rXiv .2302.0243 6, Mar . 2023. [7] Z. Z hou, L. Liu, S. Jere, J. Zhang, and Y . Y i, “RCNet: Incorporatin g structura l information into deep RNN for online MIMO-OFDM symbol detec tion with limited training, ” IEE E T rans. W irel ess Commun. , vol. 20, no. 6, pp. 3524-3537, Jun. 2021. [8] D. Maruyama, K. Kanai and J. Katto, “Performance Evaluat ions of Channel Es timation Using Deep-learning Based Super-re solutio n, ” IEEE Ann. Cons. Commun. Netw . Conf. (CCNC), Las V e gas, NV , USA, 2021, pp. 1-6. [9] B. Lim, S. Son, H. K im, S. Nah, and K. M. Lee, “Enhanced deep resid- ual networks for single image super-resoluti on, ” IE E E Conf. Comput. V ision Patt. Recogniti on W orkshops (CVPR W ), Honolulu, 2017, pp. 1132-1140. [10] M. Soltani, V . Pourahmadi, A. Mirzaei and H. Sheikhza deh, “Deep learni ng-based channel estimatio n, ” IEEE Commun. Lett. , vol. 23, no. 4, pp. 652-655, Apr . 2019. [11] D. Luan and J. Thompson, “Channelforme r: Atte ntion based neural solution for wirele ss channel estimation and effec tive online training , ” IEEE T rans. W irele ss Commun. , pp. 6562-6577, vol. 22, no. 10, 2023. [12] L. Sc hmid and L. Schmalen, “Lo w-complexit y near-opti mum sym- bol detectio n based on neural enhance ment of factor graphs, ” IEE E T rans. Commun. , vol . 70, no. 11, pp. 7562-7575, Nov . 2022. [13] M. Honkala, D. Korpi , J. M. J. Huttune n, “DeepRx: Fully con voluti onal deep learning recei ver , ” IEEE T rans. W ire less Commun. , vol. 20, no. 6, pp. 3925-3940, Jun. 2021. [14] F . A. Aoudia and J. Hoydi s, “End-to-end learning for OFDM: from neural recei vers to pilotl ess communication, ” IEEE T rans. W ir eless Commun. , vol. 21, no. 2, pp. 1049-1063, Feb. 2022. [15] S. Hu and F . Rusek, “ A soft-output MIMO detec tor with achie vable informati on rate based partial margi naliz ation, ” IEE E T rans. Signal Pr ocess. , vol. 65, no. 6, pp. 1622-1637, Mar . 2017. [16] T -H. Im, J. Kim, and Y . S Cho, “ A lo w comple xity QRM-MLD for MIMO systems, ” IE EE 65th V eh. T echnol . Conf. (VTC), Dublin, Ireland , Apr . 2007, pp. 1550–2252. [17] J. Zhang, H. W ang, J. Qian, and Z. Gao, “Soft MIMO detection using marginal posterior probability stati stics, ” IEEE Global Com- mun. Conf. (GL OBECOM), Brazil, Dec. 2022, pp. 3198-3204. [18] D. W ¨ ubben, R. Bohnke, V . Kuhn, and K. D. Kammeyer , “MMSE-based latti ce-red uction for near-ML detectio n of MIMO systems, ” Proc. ITG Wkshps Smart Ant. , Munich, Germany , Mar . 2004, pp. 106-113. [19] 3GPP TS 36. 101,“Evolve d unive rs al terrestrial radio access (E-UTRA); user equipment (UE) radio transmission and recepti on, ”. [20] A. Kosasih , V . Onasis, W . Hardjaw ana, V . Miloslavska ya, V . Andrean, J-S. Leu, and B. V ucetic , “Graph neural network aided expec tati on propagat ion detect or for MU-MIMO systems, ” IEEE Wire less Commun. Netw . Conf. (WCNC), New Y ork, NY , USA, Apr . 2022, pp. 1212-1217. [21] X. Zhou, J. Zhang, C. K. W en, S. Jin, S. Han, “Graph neural networks- enhanc ed expe ctat ion propagati on algorithm for MIMO turbo recei ver , ” IEEE T rans. Signal Pr ocess. , vol. 71, pp. 3458-3473. Oct. 2023. [22] N. T . Nguyen and K. Lee, “ Applica tion of deep learni ng to sphere decodin g for large MIMO systems, ” IEEE T rans. W irele ss. Commun. , vol. 20, no. 10, pp. 6787–6803, Oct. 2021. [23] B. Zhou, X. Y ang, S. Ma, F . Gao, and G. Y ang, “Pay less but get more: a dual attent ion-base d channel estimation network for massiv e MIMO systems with low density pilots, ” IEEE Tr ans. W ireless. Commun., Early Access, 2023. [24] Z. Huang, H. Lam, and H. Zhang, “Effici ent uncert ainty quantific ation and reduct ion for ove r-par ameteri zed neural networks, ” Pro c. NeurIPS , 36th Adv . in Neural Inf. Process. Syst., pp. 64428-64467, 2023. [25] S Ji m ´ enez, M. J urgen s, and W . W aegeman, “Why machine learni ng models fail to fully capture epistemic uncertai nty , ” https:// arxiv .org/abs/250 5.23506 , May 2025. [26] D. S hanmugam, D. Blalock , G. Balakri shnan, and J. Guttag, “Better aggre gatio n for test-time augmentation, ” IEEE Int. Con. Comput. V ision (ICCV), pp.1194-1203, 2021. [27] P . Conde and C.Premebida, “ Adapti ve-TT A: Accuracy- consisten t weighte d test-time augmentation method for the uncertai nty calibra- tion of deep learning classifiers, ” Pr oc. British Machine V ision Conf. (BMVC), pp. 1-12, 2022. [28] M. Kimura and H. Bondell, “T est-ti me augmenta tion meets vari ationa l bayes”, https://arxiv .org/ab s/2409.12587 , Sept. 2024.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment