불변 변환과 재샘플링 기반 에피스테믹 불확실성 감소
본 논문은 훈련된 AI 모델에 입력을 불변 변환으로 다중 생성하고, 각 변환에 대한 추론 결과를 최적 가중합으로 결합함으로써 에피스테믹 불확실성을 감소시키는 “재샘플링” 기법을 제안한다. MIMO 검출 실험을 통해 SNR 1 dB 수준의 성능 향상을 입증한다.
저자: Sha Hu
본 논문은 인공지능(AI) 모델을 고차원 입력‑출력 함수로 보고, 훈련 후 추론 단계에서 발생하는 두 종류의 불확실성—aleatoric(데이터 자체의 잡음)과 epistemic(모델 학습·표현 한계)—을 명확히 구분한다. 특히, epistemic 불확실성은 동일 입력에 대해 서로 다른 추정 오차를 야기하며, 이를 감소시키는 것이 고성능 AI 시스템 설계의 핵심 과제로 제시된다.
저자들은 “불변 변환(invariant transformation)”이라는 개념을 도입한다. 일반적인 시스템 y = f(s) + n 에 대해, 변환 T는 두 함수 g와 q(및 그 역함수 q⁻¹)를 이용해 T(y) = g∘f∘q⁻¹(q(s)) + g(n) 형태로 정의된다. 여기서 Char(f)·(시스템 매핑 특성), 입력 신호 s, 잡음 n의 통계적 분포가 변환 전후에 동일해야 한다는 조건을 만족한다면, T는 불변 변환이라 부른다. 구체적인 예로는 유니터리 행렬 Q에 의한 회전, 행·열 순열 행렬 P, 복소수 켤레 연산 등이 있다. 이러한 변환은 MIMO 시스템에서 채널 행렬 H와 전송 심볼 s가 i.i.d. 라는 가정 하에 통계적 동등성을 유지한다.
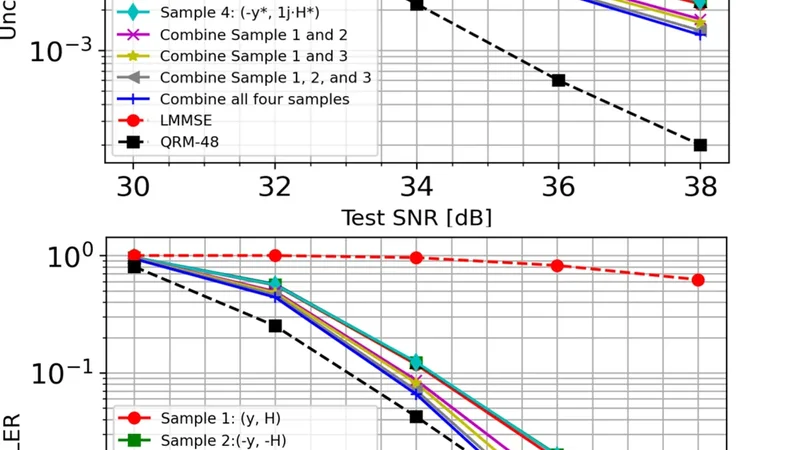
논문은 Property 1을 통해, 훈련 데이터에 포함된 (y,Char(f),s) 쌍에 대해 불변 변환을 적용한 (T(y),Char(Tf),q(s)) 역시 동일한 추론 정확도를 보인다고 증명한다. 이를 기반으로 “재샘플링(resampling)” 기법을 제안한다. 구체적으로, 훈련된 AI 모델 ϕ에 대해 동일 입력 y를 여러 불변 변환 T₁,…,T_M 로 변환하고, 각 변환에 대해 모델을 실행해 sₘ = s + zₘ (zₘ은 평균 0, 분산 σ², 상호 공분산 ρσ²) 를 얻는다.
Theorem 1은 이러한 M개의 추정값을 선형 가중합 ¯s = Σβₘ sₘ 로 결합했을 때 최소 분산이 var(¯s)=1ᵀR⁻¹1⁻¹ 로 주어지며, 최적 가중치는 β = R⁻¹1 / (1ᵀR⁻¹1) 임을 제시한다. 여기서 R은 공분산 행렬이며, 동일 분산·동일 상관(ρ) 가정 시 βₘ=1/M 이 되고, 최소 분산은 (ρ+1−ρM)σ² 로 감소한다. ρ가 0에 가까울수록 변환 간 오류가 독립적이며, M을 늘릴수록 분산 감소 효과가 커진다. 반대로 ρ가 1에 가까우면 변환 간 오류가 완전히 상관되어 재샘플링 효과가 사라진다.
Epistemic uncertainty와의 연관성을 Property 2에서 논한다. 훈련 데이터가 모든 불변 변환을 포함한다면 ϕ_T = ϕ 가 되며, 평균 추정 ¯ϕ_T 역시 동일해진다. 하지만 현실적으로 무한히 큰 데이터는 불가능하므로, inference 단계에서 변환을 적용해 얻은 평균 ϕ_T = E_T
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기