NoLan: Mitigating Object Hallucinations in Large Vision-Language Models via Dynamic Suppression of Language Priors
Object hallucination is a critical issue in Large Vision-Language Models (LVLMs), where outputs include objects that do not appear in the input image. A natural question arises from this phenomenon: Which component of the LVLM pipeline primarily cont…
Authors: Lingfeng Ren, Weihao Yu, Runpeng Yu
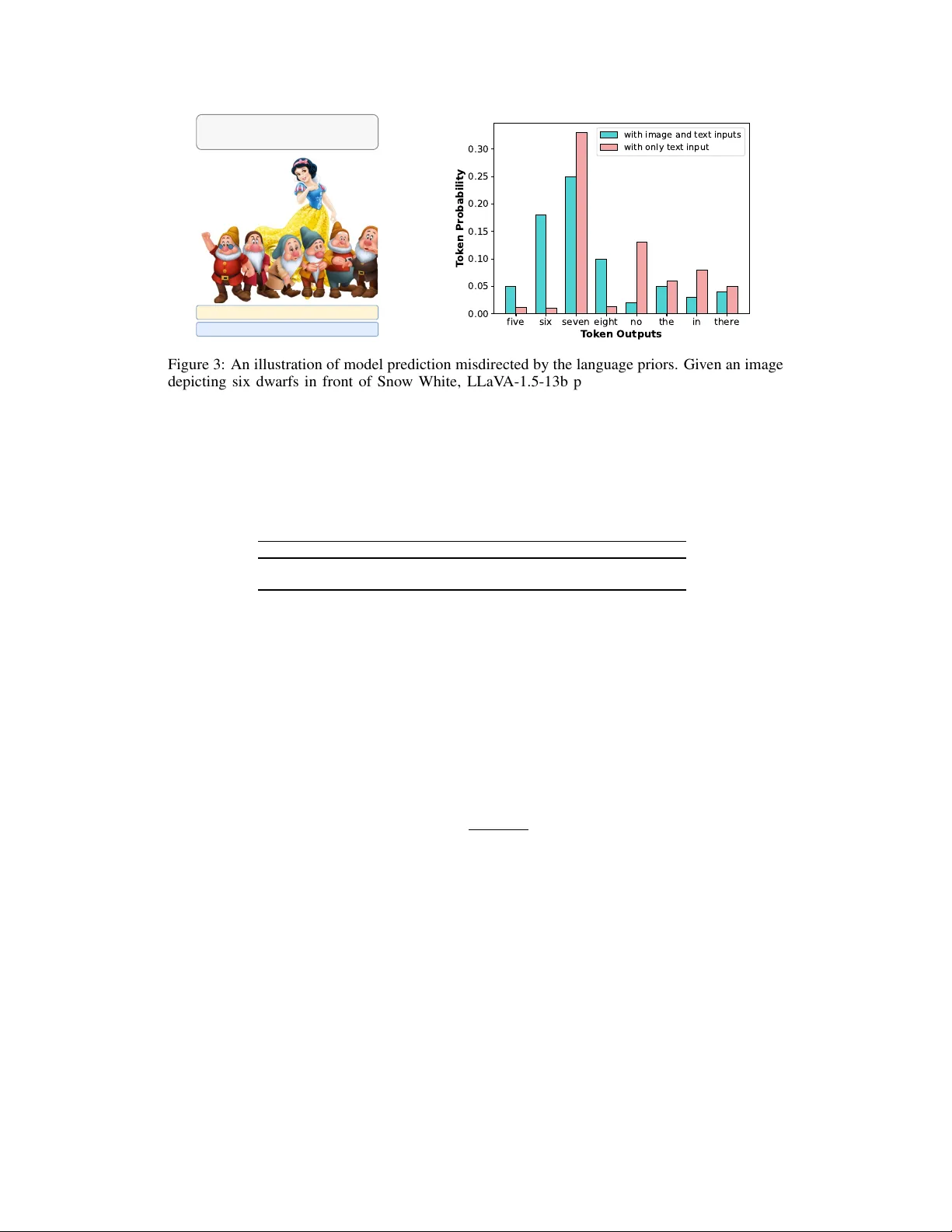
NoLan: Mitigating Object Hallucinations in Large V ision-Language Models via Dynamic Suppr ession of Language Priors Lingfeng Ren 1 W eihao Y u 2 ∗ Runpeng Y u 1 Xinchao W ang 1 ∗ 1 National Univ ersity of Singapore, Singapore 2 Peking Univ ersity Shenzhen Graduate School, China {lingfengren, r.yu}@u.nus.edu weihao@pku.edu.cn xinchao@nus.edu.sg https://github.com/lingfengren/NoLan Abstract Object hallucination is a critical issue in Large V ision-Language Models (L VLMs), where outputs include objects that do not appear in the input image. A natural question arises from this phenomenon: Which component of the L VLM pipeline primarily contributes to object hallucinations? The vision encoder to perceiv e visual information, or the language decoder to generate text responses? In this work, we stri ve to answer this question through designing a systematic experiment to analyze the roles of the vision encoder and the language decoder in hallucination generation. Our observ ations rev eal that object hallucinations are predominantly associated with the strong priors from the language decoder . Based on this finding, we propose a simple and training-free framew ork, No-Language-Hallucination Decoding, NoLan , which refines the output distribution by dynamically suppressing language priors, modulated based on the output distribution difference between multimodal and text-only inputs. Experimental results demonstrate that NoLan effecti vely reduces object hallucinations across various L VLMs on different tasks. For instance, NoLan achie ves substantial improvements on POPE, enhancing the accuracy of LLaV A-1.5 7B and Qwen-VL 7B by up to 6.45 and 7.21, respectively . The code will be made publicly av ailable. 1 Introduction In recent years, Lar ge Language Models (LLMs) [ 68 , 12 , 10 , 90 , 41 , 79 , 81 ] hav e rev olutionized the field of machine learning with the ability of language understanding and content generation, offering unprecedented capabilities and potentials across a multitude of applications. The inte gration of LLMs with computer vision systems has giv en rise to Large V ision-Language Models (L VLMs) [ 9 , 68 , 87 , 2 , 82 , 51 , 92 , 83 , 47 , 36 , 69 , 42 ], facilitating various applications through their capacity to produce contextually accurate te xtual outputs from visual data. These models e xcel in identifying and con verting intricate visual patterns into seamless linguistic expressions [ 51 , 93 , 84 , 34 , 15 , 21 , 57 , 88 , 4 ]. L VLMs with these adv anced capabilities ha ve demonstrated their v alue across multiple domains, such as content generation, image and video annotation, and interacti ve platforms that require comprehensi ve visual content interpretation. The de velopment of L VLMs is characterized by continuous enhancements in model structures, training strategies, and data v ariety , resulting in improv ed performance and broader application adaptability . Nev ertheless, a significant challenge persists: object hallucinations [ 40 , 23 , 46 , 56 ], where the te xt generated by L VLMs does not accurately ∗ Corresponding author . Language Question L VLM L VLM Language Question Multimodal logits bear whale deer dinosaur Language Question: Which animal is the largest? Unimodal logits bear whale deer dinosaur Ste p 1 Ste p 3 Our NoLan logits bear whale deer dinosaur Kullback-Leibler Divergence-based function Ste p 2 Multimodal logits bear whale deer dinosaur Unimodal logits bear whale deer dinosaur Figure 1: No-Language-Hallucination Decoding (NoLan). Giv en an L VLM, an image v , and a language question x , NoLan mitigates hallucinations in responses by comparing outputs generated from multimodal and unimodal (text-only) inputs. Step 2 can also be simplified by setting α to a fixed v alue of 1 . In this e xample, the hallucinated object “ whale ” is suppressed by reducing the influence of language priors during token generation, while the ground truth object “ bear ” is ef fectively enhanced. reflect the objects in the provided image. Object hallucinations can lead to misinformation and misinterpretation, posing significant risks for decision-making—particularly in high-stakes areas such as robotics [58, 48], autonomous systems [11, 80], and healthcare [76, 25]. In light of this, various strategies have been in vestig ated to mitigate object hallucinations in L VLMs. Initial ef forts focused on small-scale VLMs, employing techniques like fine-grained modality alignment [ 7 ] and data augmentation to reduce statistical biases related to object co- occurrence [ 61 , 30 ]. Howe ver , the distinct behaviors of L VLMs render these methods difficult to generalize and scale [ 29 , 78 ]. Recent research has tackled this challenge by developing hallucination- specific datasets for fine-tuning [ 45 , 23 ], training post-hoc revisors to produce outputs with fewer hallucinations [ 91 ], and employing factually enhanced Reinforcement Learning from Human Feed- back (RLHF) [ 65 ]. Despite their ef fectiveness, these interv entions demand significant human ef fort and computational resources, underscoring the urgent need for a simpler yet ef ficient solution. L VLMs generally comprise two main components: a vision encoder that percei ves visual information and a language decoder that generates text responses. This model composition motiv ates us to analyze the contributions of the vision and language components within L VLMs to the occurrence of object hallucinations. Through a series of analytical experiments, we find that object hallucinations primarily stem from the language decoder’ s priors rather than the vision encoder . Based on this insight, we focus on overcoming language priors and introduce No - Lan guage-Hallucination Decoding ( NoLan ), a simple, ef fectiv e, and training-free frame work designed to mitig ate hallucinations in L VLMs. As illustrated in Figure 1, NoLan works by contrasting the output distributions of multimodal inputs with those of text-only inputs, acting as a correcti ve mechanism to address the model’ s over -reliance on linguistic priors embedded in the LLM. The modulation of the output distribution increases when the similarity between the token distrib utions of multimodal and text-only inputs is higher , as measured by a Kullback-Leibler div ergence-based function. Compared to previous methods [ 45 , 23 , 91 , 65 ], NoLan eliminates the need for additional training or external tools, such as other pre-trained models. Our e xperimental results v alidate the effecti veness of NoLan, demonstrating consistent impro vements across v arious object hallucination benchmarks and L VLM families, including LLaV A-1.5 [ 51 , 49 ], InstructBLIP [ 15 ], and Qwen-VL [ 4 ]. Specifically , on the POPE benchmark [ 40 ], NoLan achie ves significant performance gains, with accuracy improv ements of up to 8 . 38 and F1 score enhancements of up to 8 . 78 , highlighting its rob ustness and scalability in addressing object hallucinations across div erse L VLM architectures. 2 Overall, our main contrib utions are as follo ws: 1. W e conduct a series of analytical experiments to in vestigate the contrib utions of each component in L VLMs to object hallucinations, finding that hallucinations mainly stem from the language model’ s priors rather than the vision model. 2. Building on this insight, we introduce NoLan, a plug-and-play approach designed to mitigate object hallucinations by dynamically suppressing language priors. NoLan achiev es this by lev eraging the differences in output distributions between multimodal and te xt-only inputs, ensuring more consistent and contextually accurate content generation. 3. Extensiv e e xperiments demonstrate the effecti veness of NoLan in significantly reducing object hallucinations. Notably , our methods do not require additional training or external tools. 2 Related work 2.1 V isual-Language Models The e volution of V ision-Language Models (VLMs) has advanced significantly , shifting from language models that incorporate BER T -like language encoder [ 16 , 54 , 31 ] for the fusion of visual and textual information [ 38 , 64 , 71 , 37 ] to being driven by the integration of LLMs [ 20 , 68 , 67 , 60 , 8 , 14 , 66 , 13 , 3 ]. By inte grating a general vision encoder with a large language model, L VLMs demonstrate a range of emergent capabilities, enabling them to process and interpret complex visual and textual information more effecti vely . Howe ver , while grafted VLMs inherit strong linguistic capabilities from their base LLM, they also carry over the propensity to generate ungrounded or fabricated information [27, 6]. 2.2 Hallucination in VLMs Hallucination typically refers to instances in which the generated responses include information that is not present in the visual content [ 61 , 7 , 40 ]. Recent initiati ves hav e aimed to tackle these intricacies, with research focusing on detecting and e valuating object hallucinations in the realm of L VLMs [ 73 , 45 , 40 , 56 , 85 ], and methods to reduce them [ 45 , 85 , 70 ]. For instance, POPE [ 40 ] transforms hallucination into a binary classification task to assess the model’ s ability to recognize whether a particular object is present in the image. Unlike approaches that simply integrate po werful LLMs with in-context or few-shot learning capabilities [ 1 , 35 ], efforts to address hallucinations hav e primarily focused on incorporating external tools for post-processing. For instance, W oodpecker [ 85 ] utilizes a fiv e-stage process, but many of these stages rely heavily on auxiliary models, such as multiple LLMs and vision foundation models, making the approach resource-intensive. Additionally , adapting factually augmented reinforcement learning from human feedback (RLHF) [ 65 ] has emerged as an effecti ve strategy to align model outputs with f actual accuracy . Ho we ver , current strategies [ 52 , 50 ] that in volv e acquiring additional datasets, performing detailed tuning on initial or new models, or utilizing other pretrained models can be time-intensiv e, laborious, and computationally demanding. T o address these limitations, sev eral training-free methods have been de veloped. For instance, V isual Contrastiv e Decoding (VCD) [ 33 ] calibrates visual uncertainty by contrasting output distributions generated from original and distorted visual inputs. Similarly , Multi-Modal Mutual Information Decoding (M3ID) [ 17 ] and V isual Debias Decoding (VDD) [ 89 ] enhance the influence of the reference image by comparing probability distributions produced from conditioned and unconditioned inputs. These approaches aim to refine model predictions without requiring additional training. Compared to these methods, our NoLan introduces a fundamentally different, finer-grained assumption. While methods like VCD [ 33 ] and VDD [ 89 ] simplify the problem by assuming a uniform language prior for all tokens, and M3ID assumes that the prior de gree is conditioned only on sequence length [ 17 ], our approach makes a more nuanced and realistic assumption. Specifically , our NoLan posits that each token possesses a distinct language prior . W e further propose a simple yet ef fective KL-based method to measure the prior degree of each tok en. This tok en-specific and dynamic prior modeling allows our method to more accurately suppress each token’ s language prior, leading to performance improv ements. Thus, our work’ s novelty lies in this novel assumption and the dev elopment of an effecti ve mechanism to model it, which fundamentally distinguishes it from prior work. 3 BERT ViT A photo of an elephant Q: Is there a elephant in the image? LLaV A's vision encoder cosine similarity Y es No Figure 2: Experimental pipeline to test whether LLaV A ’ s vision encoder can detect the presence of an object in an image. T able 1: The V ision encoder can rob ustly detect object pr esence in samples. On the MSCOCO dataset of POPE- random [ 40 ], for samples where LLaV A-1.5 experiences hallucinations, its vision encoder can indeed predict object presence with high accuracy . Samples on COCO of POPE- Random where LLaV A experiences hallucinations Metric Accuracy Precision Recall F1 Score Score 83.01 83.71 98.33 90.43 3 Method 3.1 Preliminary experiments L VLMs generally comprise two core components: a vision encoder to gain visual information and a language decoder to generate textual responses. This design raises an important question: are these two components responsible for object hallucinations? In this section, we present a comprehensi ve analysis to in vestigate the contrib utions of both the vision encoder and the language decoder to these hallucinations. V ision Encoder . W e aim to in vestig ate whether the vision encoder accurately detects object presence in the failing cases of object hallucinations. T o this end, we design a pipeline as sho wn in Figure 2. Specifically , LLaV A comprises a CLIP vision encoder and a LLaMA (V icuna) language model, but in this experiment, we use only the CLIP vision encoder . W e extract image representation using the CLIP encoder and e v aluate whether the representation includes information about a specific object. For this, we transform the te xt query into “ A photo of a [object]” and pass it through CLIP’ s BER T encoder to obtain a text representation. W e then calculate the cosine similarity between CLIP’ s image and text representations to assess object presence. As shown in T able 1, for samples where LLaV A-1.5 experiences hallucinations on the MSCOCO dataset of POPE (random) [ 40 ], its vision encoder can predict object presence with high accuracy of 83%. These results lead to our Finding 1 : the vision encoder can indeed detect object presence in samples exhibiting object hallucinations. Language Decoder . While vision encoders can accurately detect objects, L VLMs - which combine vision encoders with LLaMA-like language decoders - still experience hallucinations. W e h ypothesize that these hallucinations occur when the output distribution is dominated by language priors embedded in LLMs, as illustrated in Figure 3. T o test this hypothesis, we compare output distributions between an L VLM processing image-text inputs and its used LLM processing text-only inputs. Specifically , for LLaV A-1.5-7B [50], we denote: • p m : Output distrib ution from LLaV A with image-text inputs. • p u : Output distrib ution from LLaV A ’ s language decoder LLaMA with text-only inputs. W e measure the dif ference between these distrib utions using KL Di vergence and JS Div ergence metrics. Using the MSCOCO dataset from POPE- random [ 40 ], we create two subsets based on 4 Language Question: How many dwarfs are there near Snow White in the image? LLaV A with only text input: seven LLaV A with image and text inputs: seven five six seven eight no the in ther e T ok en Outputs 0.00 0.05 0.10 0.15 0.20 0.25 0.30 T ok en Probability with image and te xt inputs with only te xt input Figure 3: An illustration of model prediction misdirected by the language priors. Given an image depicting six dwarfs in front of Snow White, LLaV A-1.5-13b provides the same token “ seven ” regardless of whether the image is pro vided as input or not. T able 2: T oken probability distrib ution differ ence between multimodal and unimodal inputs. W e split MSCOCO with POPE- random [ 40 ] into two subsets according to whether the answers from LLaV A-1.5-7B [ 50 ] contain hallucinations or not. Here, p m and p u represent the token probability distributions conditioned on multimodal and unimodal (text-only) inputs, respectiv ely . The lo wer KL Div ergence and JS Div ergence v alues in the hallucination subset indicate greater similarity between the two distrib utions, suggesting that language priors heavily influence the outputs. Dataset D KL ( p m ∥ p u ) D KL ( p u ∥ p m ) D JS ( p m , p u ) POPE no − hallucination 1.20 0.58 0.28 POPE hallucination 0.46 0.28 0.11 whether LLaV A-1.5-7B produces hallucinations in its answers. As sho wn in T able 2, the hallucination subset e xhibits significantly smaller div ergence between P m and P u compared to the no-hallucination subset. This suggests that when hallucinations occur , the model’ s outputs are more hea vily influenced by language priors embedded in LLMs. As shown in T able 2, the distribution difference is promi- nent in the successful subset, whereas it is minimal in the subset of hallucinated responses. This result confirms that the linguistic priors inherent in the language decoder play a significant role in contributing to hallucinations. Indeed, this model’ s behavior is not entirely unexpected, as LLMs are fundamentally designed to predict the next word’ s probability based on extensi ve textual corpora. When confronted with ambiguous dominant language question stimuli, L VLMs may default to these text-based predictions as a “safety net”. While language priors are generally beneficial for contextual understanding and efficient inference, they can introduce biases or assumptions that conflict with the actual visual content. These results lead to our Finding 2 : The output distribution of an L VLM is more dominated by its underlying LLM’ s priors when object hallucinations occur . 3.2 No-Language-Hallucination Decoding While it is commonly believed that hallucinations arise from weak visual signals in the vision module [ 22 , 61 , 72 ], our above findings indicate that object hallucinations are primarily driv en by language priors. Therefore, in this section, we propose a very simple frame work named No- Language-Hallucination Decoding (NoLan), to overcome the influence of language priors on object hallucinations. Specifically , consider an L VLM parameterized by θ , with visual inputs v and textual inputs x . The output y is generated auto-regressi vely from a probability distribution conditioned on both v and x , expressed as: l m = logit θ ( y t | v , x, y
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment