언어 선입견 억제로 시각‑언어 모델의 객체 환각 방지
본 논문은 대형 시각‑언어 모델(LVLM)에서 발생하는 객체 환각이 주로 언어 디코더의 강한 사전 지식에 기인한다는 사실을 실험적으로 규명한다. 이를 토대로, 멀티모달 입력과 텍스트 전용 입력의 출력 분포 차이를 이용해 언어 사전 지식을 동적으로 억제하는 훈련‑프리 디코딩 기법 NoLan을 제안한다. NoLan은 다양한 LVLM에 적용했을 때 POPE, VQA 등 여러 벤치마크에서 환각을 현저히 감소시키며, 특히 LLaVA‑1.5 7B와 Qwe…
저자: Lingfeng Ren, Weihao Yu, Runpeng Yu
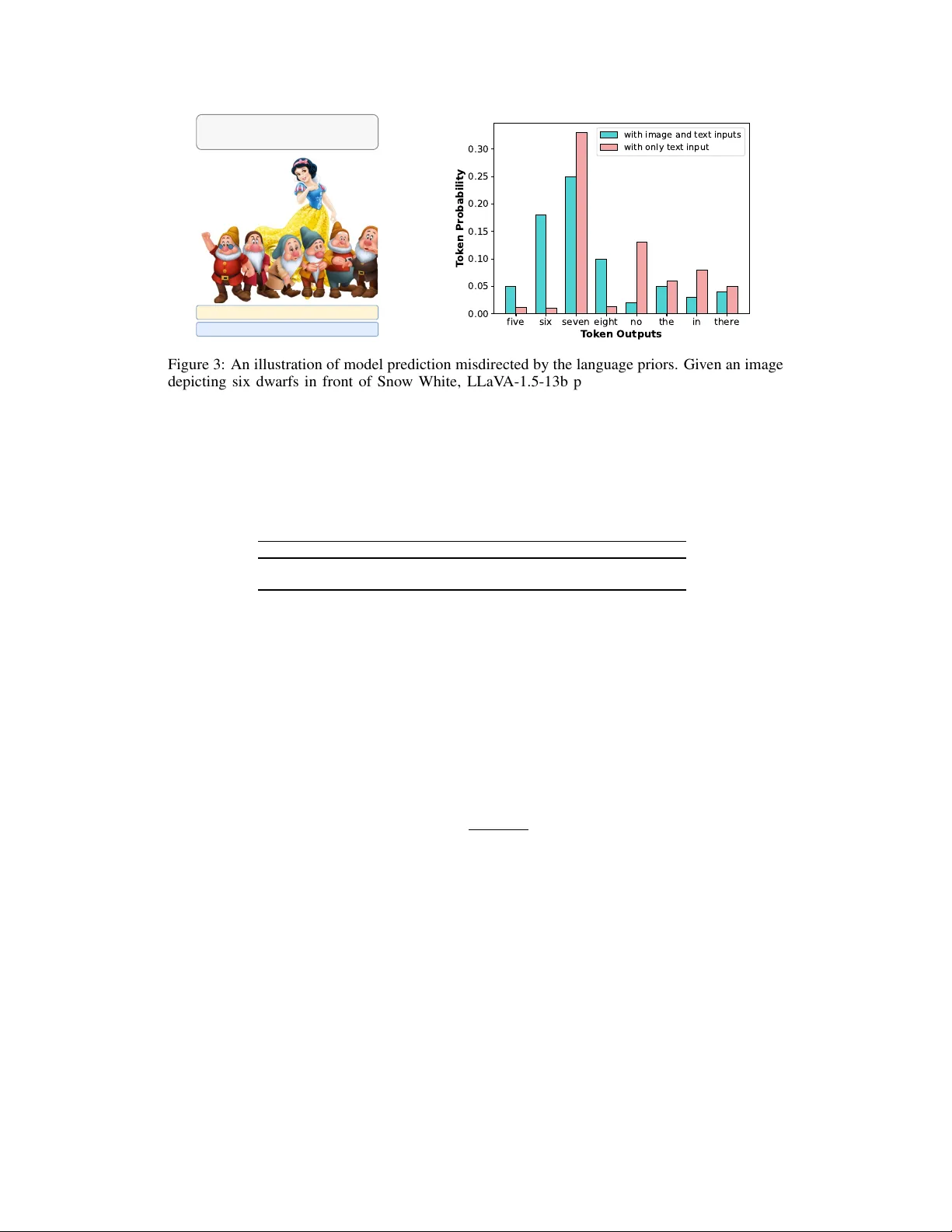
대형 시각‑언어 모델(LVLM)은 이미지와 텍스트를 동시에 처리해 자연스러운 대화형 응답을 생성하지만, 이미지에 존재하지 않는 객체를 언급하는 “객체 환각” 문제가 심각한 한계로 지적되어 왔다. 기존 연구는 주로 시각 인코더의 표현 부족이나 데이터 편향을 원인으로 보았으며, 이를 해결하기 위해 추가 데이터, 파인튜닝, 혹은 외부 검증 모델을 도입하는 복잡한 방법을 제안했다. 그러나 이러한 접근법은 높은 계산 비용과 인력 투입을 요구한다. 본 논문은 LVLM의 두 핵심 구성 요소인 시각 인코더와 언어 디코더가 환각에 각각 어떤 역할을 하는지 체계적인 실험을 통해 규명한다.
첫 번째 실험에서는 LLaVA‑1.5 모델에 사용된 CLIP 기반 시각 인코더만을 활용한다. 이미지와 “A photo of a
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기