Neural Learning of Fast Matrix Multiplication Algorithms: A StrassenNet Approach
Fast matrix multiplication can be described as searching for low-rank decompositions of the matrix--multiplication tensor. We design a neural architecture, \textsc{StrassenNet}, which reproduces the Strassen algorithm for $2\times 2$ multiplication. …
Authors: Paolo Andreini, Aless, ra Bernardi
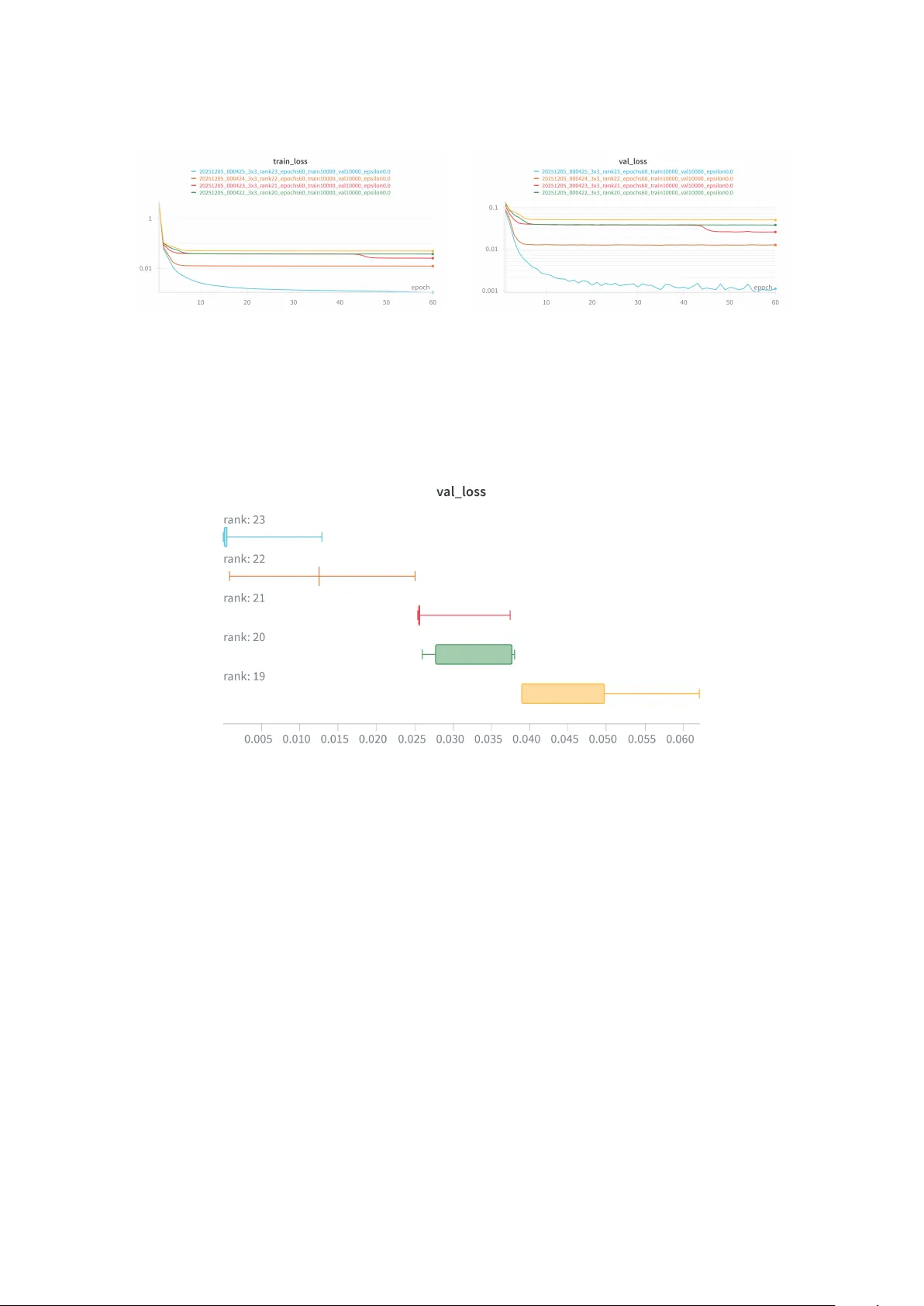
NEURAL LEARNING OF F AST MA TRIX MUL TIPLICA TION ALGORITHMS: A STRASSENNET APPR O A CH P A OLO ANDREINI, ALESSANDRA BERNARDI, MONIC A BIANCHINI, BARBARA TONIELLA CORRADINI, SARA MARZIALI, GIA COMO NUNZIA TI, FRANCO SCARSELLI Abstract. F ast matrix m ultiplication can b e describ ed as searc hing for lo w-rank de- comp ositions of the matrix–multiplication tensor. W e design a neural arc hitecture, StrassenNet , which repro duces the Strassen algorithm for 2 × 2 m ultiplication. Across man y indep enden t runs the netw ork alwa ys con verges to a rank-7 tensor, thus numeri- cally recov ering Strassen’s optimal algorithm. W e then train the same architecture on 3 × 3 m ultiplication with rank r ∈ { 19 , . . . , 23 } . Our exp eriments rev eal a clear n umerical threshold: mo dels with r = 23 attain significantly low er v alidation error than those with r ≤ 22, suggesting that r = 23 could actually b e the smallest effectiv e rank of the matrix m ultiplication tensor 3 × 3. W e also sketc h an extension of the method to b order-rank decomp ositions via an ε – parametrisation and rep ort preliminary results consisten t with the kno wn b ounds for the b order rank of the 3 × 3 matrix–multiplication tensor. 1. Introduction Matrix m ultiplication is a central ob ject in numerical Linear Algebra, Complexity Theory , and Mac hine Learning. The classical algorithm uses O ( n 3 ) operations, but Strassen’s 1969 breakthrough sho w ed that asymptotically few er multiplications suffice b y giving a 2 × 2 sc heme with 7 m ultiplications [ 1 ]. Since then, the searc h for fast algorithms has b een tigh tly link ed to the r ank (and b order rank) of the matrix–m ultiplication tensor ⟨ n, n, n ⟩ : an y bilinear algorithm with r scalar m ultiplications corresponds to a rank- r decomp osition of this tensor, and conv ersely [ 2 , 3 ]. Let T ( N ) denote the arithmetic complexit y of the algorithm when multiplying t wo N × N matrices. Via blo ck recursion, a base- k sc heme with r multiplications yields the recurrence T ( N ) = r T ( N /k ) + O ( N 2 ) and hence the exp onen t ω = log k r ; minimising rank (or b order rank) directly improv es the asymptotic complexit y [ 4 , 5 ]. Historical con text. After Strassen, the 1970s–80s clarified the role of bilinear and ap- pr oximate bilinear algorithms. Building on Bini’s theory of appro ximate bilinear al- gorithms and Sch¨ onhage’s asymptotic sum inequality , the b or der r ank R of the ma- trix–m ultiplication tensor is the quantit y that determines the asymptotic exp onent : in- deed, ω = inf k ≥ 2 log k R ( ⟨ k , k , k ⟩ ) [ 4 , 5 , 2 ] (see also the mo dern asymptotic-sp ectrum p ersp ectiv e and quantum function- als [ 6 , 7 , 8 ]). The Copp ersmith–Winograd framework [ 9 ] and its refinements via the laser metho d fueled steady progress on upp er b ounds for ω : notable milestones include Stothers [ 10 ], V assilevsk a Williams [ 11 ], Le Gall [ 12 ], and a refined laser metho d by Al- man and V assilevsk a Williams [ 13 ]. F ollo wing Strassen’s laser method and the Copp er- smith–Winograd framework, subsequen t refinements culminated in mo dern barrier results clarifying limitations of these approaches [ 14 ]. 2020 Mathematics Subje ct Classific ation. 15A69, 68Q17, 14N07. Key wor ds and phr ases. Algebraic Complexity Theory , Matrix Multiplication, Netw ork, Neural Arc hitecture. 1 2 A t fixe d smal l sizes , the classical case of 3 × 3 matrices o ccupies a special place: Lader- man (1976) found an exact algorithm with 23 m ultiplications [ 15 ]; whether 22 is p ossible remains op en. Related ge ometric and structural phenomena such as strict subm ultiplica- tivit y and (non-)additivit y of b order rank hav e b een analysed in [ 16 , 17 , 18 ]. On the lo w er-b ound side, the b est exact bilinear low er b ound is 19 [ 19 ], while the b est b order- rank low er b ound is 17 [ 20 , 21 ]. Recently , learning-guided search (e.g., AlphaT ensor [ 22 ]) redisco v ered and expanded compact sc hemes for man y small formats, complemen ting alge- braic and com binatorial techniques (the searc h space organisation used in learning-guided disco v ery is closely related to de c omp osition lo ci tec hniques from Algebraic Geometry whic h identifies the rank-1 tenors that ma y arise in a decomp osition of a given tensor cf. [ 23 ]). This pap er. W e ask whether gradien t-based learning can r e c over fast m ultiplication sc hemes when the computation graph mirrors the algebraic structure of bilinear algo- rithms. W e in tro duce StrassenNet , a tensor-netw ork arc hitecture whose forward pass implemen ts the Bhattac harya–Mesner pro duct (BMP) on activ ation tensors arranged on a small directed acyclic graph. Within this netw ork, three learnable tensors H , K , and F enco de a rank- r bilinear structure [ 24 ]: linear pre-com binations of the inputs, r scalar m ul- tiplications (as element wise pro ducts), and a linear p ost-com bination. Thus, the internal dimension r is an upp er b ound on the bilinear rank of ⟨ n, n, n ⟩ , and the gauge symmetry ( H , K , F ) 7→ ( H S, K S, S − 1 F ) for S ∈ GL r captures the intrinsic non-iden tifiability of factorised schemes. Concretely , w e: • give an algebraic construction (via BMP together with blow and for get op erators) that realises the classical 2 × 2 row-b y-column m ultiplication as a parametrised ten- sor net work; we then reuse the same template to rebuild Strassen’s 7-m ultiplication metho d [ 1 ], sho wing clearly ho w the netw ork’s graph connects to the underlying tensor op erations; • prop ose a differentiable parameterisation { H , K, F } for general n × n m ultiplication and train it end-to-end to minimise the MSE b etw een the matrix pro duct ( AB ) of t w o matrices A and B and the mo del prediction; • test r ∈ { 19 , 20 , 21 , 22 , 23 } for 3 × 3: r = 23 is a known achiev able baseline cf. [ 15 ], while r ≤ 22 explores the region ab o ve the b est exact low er b ound r ≥ 19 cf. [ 19 ]; • see a clear gap of about one order of magnitude in the v alidation error: for r = 23 the MSE stays b elow 10 − 3 , while for r ≤ 22 it stays around 10 − 2 . This suggests that our setup can reliably fit a 23-multiplication scheme, but not smaller r un- der the same training procedure. W e also p erform a one-tailed W elc h’s t -test to statistically assess whether the difference b etw een the losses is significant. Although we do not prov e new low er bounds, our exp erimen ts indicate that when the computation graph mirrors the algebraic structure of bilinear algorithms, gradient-based training can reliably recov er known fast algorithms. The sharp error gap b etw een r = 22 and r = 23 on 3 × 3 suggests a practical barrier in this architecture and training regime. Metho dologically , the BMP-based tensor-net w ork (with blow / for get ) provides a compact w a y to enco de, train, and insp ect bilinear algorithms within standard gradient pip elines. T aken together, these exp erimen ts offer a stable numerical indication, alb eit not a pro of, that r = 23 is the smallest rank our architecture can realise for 3 × 3. This aligns with the b est kno wn 23-multiplication constructions and suggests that learning-based approac hes can “sense” the gap b etw een r = 22 and r = 23 under standard training regimes. 3 Organisation. Section 2 reviews tensors, rank, and the BMP formalism. Section 3 de- fines the total tensor of a net w ork and the blo w/forget op erators. Section 4 builds tensor net w orks for classical and Strassen 2 × 2 m ultiplication. Section 5 presents StrassenNet and the H / K / F parameterisation with training and ev aluation proto cols. Section 5.3 rep orts the 3 × 3 rank sweep and the statistical analysis. Section 6 discusses implications and limitations. 2. Theoretical Back gr ound 2.1. Basic notation and concepts. W e w ork ov er a field K , typically Q , or C . Definition 1. A tensor T is a multi-linear map: T : K a 1 × · · · × K a d → K where the standard basis for eac h of the K a i are usually considered. The integer d is usually called the or der of T and the sequence of natural num b ers ( a 1 , . . . , a d ) indicates the dimensions of T . Definition 2. A (order- d ) tensor T ∈ V 1 ⊗ · · · ⊗ V d has r ank R ( T ) equal to the smallest r suc h that T = P r s =1 u (1) s ⊗ · · · ⊗ u ( d ) s , where u ( i ) s ∈ V i , i = 1 , . . . , d . The b or der r ank R ( T ) is the smallest r suc h that T lies in the Zariski closure of tensors of rank ≤ r . Inspired by Strassen’s algorithm for matrix m ultiplication and tensor decomp osition theory based on the Bhattachary a-Mesner pro duct, in this work w e present StrassenNet, a neural net w ork arc hitecture designed to learn efficient matrix m ultiplication algorithms through gradien t-based optimisation. First in tro duced in 1990 by Bhattac hary a and Mesner to generalise classical pair asso cia- tion sc hemes to a higher dimension, the BMP is an n -ary op eration in the space of n -order tensors that generalises matrix multiplication. Definition 3. Let T 1 , T 2 , . . . , T d b e order- d tensors of sizes l × n 2 × · · · × n d , n 1 × l × n 3 × · · · × n d , · · · , n 1 × · · · × l , resp ectiv ely . The gener alise d Bhattacharya-Mesner Pr o duct ( BMP ), denoted as ◦ ( T 1 , T 2 , . . . , T d ), is a d -ary op eration whose result is a tensor T of size n 1 × n 2 × · · · × n d suc h that: ( T ) i 1 ...i d = l X h =1 ( T 1 ) hi 2 ...i d · · · ( T d ) i 1 i 2 ...h . 2.2. Matrix Multiplication. The matrix multiplication of an a × b matrix with a b × c matrix is a bilinear map F a × b × F b × c → F a × c whic h corresp onds to the tensor ⟨ a, b, c ⟩ = a X i =1 b X j =1 c X k =1 e i,j ⊗ e j,k ⊗ e k,i ∈ F a × b ⊗ F b × c ⊗ F c × a . The complexit y of matrix multiplication is determined by the tensor rank of these ten- sors. Indeed matrix multiplication is a bilinear map, so any algorithm that ev aluates it with r scalar m ultiplications and linear pre/post-pro cessing corresp onds to a length- r decomp osition of the matrix multiplication tensor ⟨ n, n, n ⟩ : ⟨ n, n, n ⟩ = r X s =1 h s ⊗ k s ⊗ f s ⇐ ⇒ v ec( AB ) = F T ( H T v ec( A )) ⋆ ( K T v ec( B )) , with H , K ∈ K n 2 × r , F ∈ K r × n 2 , and ⋆ the elemen t wise pro duct. The smallest feasible r is the r ank R ( ⟨ n, n, n ⟩ ) and coincides with the c omplexity of the problem. In fact, a base- k 4 algorithm with r scalar multiplications can b e r e curse d on blo cks: multiplying t w o N × N matrices using k × k blo cks yields the recurrence T ( N ) = r T ( N /k ) + O ( N 2 ) , b ecause the linear pre/p ost-pro cessing costs O ( N 2 ). No w T ( N ) = O N log k r , hence the optimal exp onent ω of matrix multiplication satisfies ω = inf k ≥ 2 log k R ( ⟨ k , k , k ⟩ ) . Strassen’s result from 1969 [ 1 ], whic h prov es that the rank R ( ⟨ 2 , 2 , 2 ⟩ ) ≤ 7, and Landsb erg’s 2006 result [ 25 ], which sho ws that the b order rank R ( ⟨ 2 , 2 , 2 ⟩ ) = 7, put a definitiv e end to the fact that t w o 2 × 2 matrices can be multiplied using only 7 bilinear multiplications instead of the usual 8. By recursiv ely applying this algorithm to blo ck matrices, Strassen generalised that t wo n × n matrices can b e m ultiplied with arithmetic op erations, impro ving on the standard algorithm. It was later [ 26 , 27 ] shown that his result on the rank of the ⟨ 2 , 2 , 2 ⟩ tensor is optimal and that all implemen tations of algorithms that implemen t 2 × 2 matrix multiplication are equiv alent, up to isotopies and co ordinate changes [ 28 ]. 3. Tot al tensor of a network In [ 29 ], an algebraic approach has b een presen ted that enables the computation of the total tensor of a net w ork based on the top ology of the underlying graph and the activ ation tensors. Let G b e a Directed Acyclic Graph (D A G) with vertex set, or no de set, V ( G ) and edge set E ( G ). A no de b ∈ V ( G ) is called a p ar ent of another no de a ∈ V ( G ) if there exists a directed edge ( b, a ) ∈ E ( G ); we write paren ts( a ) = { b ∈ V ( G ) : ( b, a ) ∈ E ( G ) } . The in-degree of a , denoted by in-deg( a ), is | parents( a ) | . The c a r dinality of G is | V ( G ) | . Definition 4. In our setting, a network N = N ( G, A ) is defined by the following series of data: ( i ) a directed graph G = ( V ( G ) , E ( G )) without (oriented) cycles, whose no des repre- sen t the discrete v ariables of the netw ork; ( ii ) a set A of activ ation tensors A i , one for eac h no de a i ∈ V ( G ), whic h determines the output given by the no de, based on the inputs it receiv es; ( iii ) an ordering of the no des which is compatible with the partial ordering given by the graph (top ological sort). The absence of cycles (as in Definition 4 ( i )) in the graph implies, with an inductive ar- gumen t, that there exists some total ordering of the no des compatible with the partial ordering defined by the graph (see Definition 4 ( iii )). W e assume that the v ariable asso ciated with the vertex v i ∈ V ( G ) assumes v alues in an n i -elemen t state set, identified with { 0 , 1 , . . . , n i − 1 } . If the v ariables of all the no des are asso ciated to the same state set { 0 , 1 , . . . , n − 1 } , we talk ab out n -ary net w ork. According to Definition 4 , a net w ork N is fully sp ecified b y its underlying D A G and the tensors assigned to its vertices. These tensors, called activation tensors , describ e the function which determines whether a no de (neuron) is to b e activ ated or not dep ending on its inputs. 5 Definition 5. Let a i b e a no de of G and d its in-de gr e e , i.e. d = in-de g ( a i ). An activation tensor A i ∈ A is any tensor of order d + 1 such that A i ∈ ( C n ) ⊗ · · · ⊗ ( C n ) | {z } d +1 times . The entry A i 1 ,...,i d ,i d +1 of the activ ation tensor represen ts the fr e quency with which the no de a assumes the state i d +1 after receiving the signal i 1 from b 1 , the signal i 2 from b 2 , . . . , and the signal i d from b d . In particular, if d = 0, then an activ ation tensor at a i is simply a vector of C n . If d = 1, then an activ ation tensor at a i is a n × n matrix of complex n um b ers. In the binary case, w e assume that no de a i is inactiv e when its output is 0 and a i is activ ated if its output is 1. The final state of the net w ork is a string indexed b y the no des in the net w ork and can b e describ ed by in tro ducing the concept of total tensor . Definition 6. In a netw ork N ( G, A ) with q no des a 1 , . . . , a q , and states n 1 , . . . , n q , re- sp ectiv ely , the total tensor is the order- d tensor N of size n 1 × · · · × n q suc h that N i 1 ,...,i q = frequency with which no de a j is in state n j k , ∀ j = 1 , . . . , q , ∀ n j = 1 , . . . , n j . The standard argumen t for the computation of the total tensor follo ws. F or ev ery node a j , j = 1 , . . . , q , in-de g ( a j ) = d j < q , let A j b e the activ ation tensor and P j b e the d j -uple of indices in { i 1 , . . . , i q } corresp onding to the parents of a j , i.e. P j = ( i k : b k ∈ par ents ( a j )) (where the tuple is ordered according to the total ordering of the netw ork). Then N i 1 ,...,i q = Π q j =1 ( A j ) concat [ P j ,i j ] , where concat [ x, y ] is the concatenation of tuples x and y . An alternative approac h for computing the total tensor of a netw ork is prop osed in [ 29 ], where an algebraic algorithm based on the activ ation tensors of the graph no des shows ho w this tensor is closely dep enden t on the topology of the underlying graph. In fact, the total tensor is the BMP of the no de activ ation tensors, appropriately resized so that eac h of them has an order equal to the num ber of no des in the graph. The next section in tro duces the op erations necessary to set the order of the tensors and the alternativ e pro cedure for calculating the total tensor. 3.0.1. T ensor Op er ations. The algebraic algorithm for calculating the total tensor of the net w ork requires the in tro duction of some operations on tensors that allow their order to b e c hanged. The first tw o op erations, blow and for get , increase the order by one by em b edding the giv en tensor in a higher-dimensional space. Definition 7. Let T ∈ V ⊗ d . The blow , or inflation , of T is the tensor b ( T ) of order d + 1 defined by ( b ( T )) i 1 ,...,i d +1 = T i 1 ,...,i d if i 1 = i d +1 ; 0 else. Definition 8. Let T ∈ V ⊗ d . F or d ′ > d let J ⊂ { 1 , . . . , d ′ } , | J | = d ′ − d . The J -th for get , or J -th c opy of T is the tensor f J ( T ) of order d ′ defined by ( f J ( T )) i 1 ,...,i d ′ = T j 1 ,...,j d where ( j 1 , . . . , j d ) is the list obtained from ( i 1 , . . . , i d ′ ) by erasing the elemen t i k for all k ∈ J . 6 When analysing the total tensor of the netw ork, it is necessary to tak e in to account the presence of so-called hidden no des, i.e. vertices that merely enco de intermediate represen- tations of the input and are unobserv able, as they correspond neither to input nor output no des. Hidden no des apply a transformation to the input signals through a parametrised activ ation function, and their in teractions determine the in ternal representation calculated b y the netw ork [ 30 ]. The main ob jective of inference is to estimate the v alues of the hidden no des, given the v alues of the observ ed ones. In our model, we pro ceed with the follo wing approac h: once the total tensor of the net work has b een constructed, we pro ceed with a c ontr action op eration with resp ect to the indices of the hidden no des. Definition 9. F or a tensor T ∈ V ⊗ d of t ype a 1 × · · · × a d and for any subset J of the set [ d ] = { 1 , . . . , d } of cardinalit y n − q , define the J -c ontr action T J , also referred to as con traction J ( T ), as follows. Set { 1 , . . . , n } \ J = { j 1 , . . . , j q } . F or an y choice of k 1 , . . . , k q with 1 ≤ k s ≤ a j s , put T J k 1 ,...,k q = X T i 1 ,...,i n , where the sum ranges on all entries T i 1 ,...,i n in which i j s = k s , for s = 1 , . . . , q . The order in whic h operations are p erformed dep ends on the total order of the nodes in the graph, making the construction precise and repro ducible. Assume we are given a net w ork N ( G, A ) with | V ( G ) | = q no des and total ordering ( a = a 1 , a 2 , . . . , a q = b ). W e call a the sour c e and b the sink of the netw ork. F or any no de a i ∈ V ( G ), we define P i as the set of indexes of the parents of a i (see Definition 6 ), so that P i ⊂ { 1 , . . . , i − 1 } . Let p i b e the cardinalit y of P i and T i b e the activ ation tensor of the node a i . According to Definition 5 , tensor T i has order p i + 1. Definition 10. F or any no de a i ∈ V ( G ), we define the asso ciated order- q tensor T i with the following proc edure. Step 1. Start with the activ ation tensor A i . Step 2. If i > 1, consider the i -dimensional forget tensor A ′ i = f J ( A i ), where J = { 1 , . . . , i − 1 } \ P i . Step 3. If i = q , consider A ′′ i = b ( A ′ i ). Step 4. Define T i as the order- q forget tensor T i = f H ( A ′′ i ), where H = { i + 2 , . . . , q } . Finally , the total tensor of the netw ork N can b e computed as N = ◦ ( T q , T 1 . . . , T q − 1 ) , where T 1 , . . . , T q are the tensors obtained b y applying pro cedure in Definition 10 to the activ ation tensors A 1 , . . . , A q ∈ A [ 29 ]. F rom an algebraic p oint of view, the BMP op eration, in Definition 3 , can b e realised as the tensor pro duct of the input tensors follow ed b y a contraction o v er a prescrib ed set of cyclically arranged paired indices. 4. Networks of ma trix mul tiplica tion The aim of this work is to analyse differen t t yp es of algorithms for the computation of matrix multiplication, in order to pro vide information on the rank and b order rank of the matrix m ultiplication tensor. In a n utshell, we first describ e the matrix m ultiplication with a tensor net w ork, then w e translate it into a parametric mo del that describes the op- erations required to compute the matrix pro duct. Suc h a mo del is a tensor neur al network that can b e learned from examples using Machine Learning techniques. In particular, in Section 4.1 , we describ e the tensor neural net w ork that, using the approach prop osed 7 N 1 N 2 N 3 Figure 1. T ensor neural netw ork which computes the row by product matrix m ultiplication with the classical algorithm. in Section 3 , allows to compute the m ultiplication of t w o 2 × 2 matrices with the standard algorithm and with Strassen’s algorithm. The in tuition that emerges is that Strassen’s algorithm reduces the n um b er of multiplications required for the calculation, and there- fore the complexit y , at the exp ense of an increase in the complexit y of the top ology of the graph underlying the netw ork. The construction is then parametrised and generalised to the case of 3 × 3 matrices: in Section 5.3 we report the exp erimen tal results of the tensor neural net w ork trained to predict the matrices that characterise the type of algorithm for matrix multiplication. The size of these matrices determine an upp er b ound for the rank of the m ultiplication tensor. 4.1. T ensor net w ork for the 2 × 2 matrix multiplication. Let A = a 11 a 12 a 21 a 22 , B = b 11 b 12 b 21 b 22 ∈ C 2 ⊗ C 2 . The matrix multiplication A · B is a matrix C = c 11 c 12 c 21 c 22 ∈ C 2 ⊗ C 2 suc h that (1) C = a 11 b 11 + a 12 b 21 a 11 b 12 + a 12 b 22 a 21 b 11 + a 22 b 21 a 21 b 12 + a 22 b 22 . This pro duct can b e calculated by constructing the total tensor of the netw ork with three no des N 1 , N 2 , N 3 as in Figure 1 , where the only total order consistent with the partial order is ( N 1 , N 2 , N 3 ), and no de N 2 is hidden. Assuming that the signal is b o olean, i.e. that only 0 and 1 c an b e transmitted, let D 1 = (1 , 1) b e the initial distribution of the source node N 1 . The activ ation functions of the no des N 2 and N 3 are the tw o matrices A and B to b e multiplied, i.e. D 2 = A = a 11 a 12 a 21 a 22 , D 3 = B = b 11 b 12 b 21 b 22 . According to Section 3 , the order of the activ ation tensors is increased. No de N 1 transmits the signal to no de N 2 , which then receives it and sends it to N 2 . Therefore, the activ ation tensor of N 1 b ecomes T (1) = f 3 ( b ( D 1 )) . No de N 2 transmits the signal and its activ ation order D 2 is increased with a blow op eration; no de N 3 , on the other hand, receiv es a signal already sen t from N 1 to N 2 , so the activ ation tensor D 3 undergo es a forget op eration of the first index. Hence, T (2) = b ( D 2 ) , T (3) = f 1 ( D 3 ) . The total net w ork tensor N is determined by the BMP of the tensors asso ciated with the no des, N = ◦ ( T (3) , T (1) , T (2) ). 8 Since no de N 2 is hidden, the resulting total tensor N must b e contracted with resp ect to the second index. Then, N ′ = con traction { 2 } ( N ) = a 11 b 11 + a 12 b 21 a 11 b 12 + a 12 b 22 a 21 b 11 + a 22 b 21 a 21 b 12 + a 22 b 21 . 4.1.1. F r om the Str assen ’s algorithm to the Str assen ’s tensor neur al network. Strassen’s algorithm computes matrix C by p erforming only 7 m ultiplications. In fact, the entries c ij , with i, j = 1 , 2, dep end on 7 new terms: p 1 = ( a 11 + a 22 ) · ( b 11 + b 22 ) p 2 = ( a 21 + a 22 ) · ( b 11 ) p 3 = a 11 · ( b 12 − b 22 ) p 4 = a 22 · ( b 21 − b 11 ) p 5 = ( a 11 + a 12 ) · b 22 p 6 = ( a 21 − a 11 ) · ( b 11 + b 12 ) p 7 = ( a 12 − a 22 ) · ( b 21 + b 22 ) , suc h that c 11 c 12 c 21 c 22 = p 1 + p 4 − p 5 + p 7 p 3 + p 5 p 2 + p 4 p 1 − p 2 + p 3 + p 6 . W e no w give a description of StrassenNet , the tensor neural netw ork deriv ed from the Strassen’s algorithm. Let A and B b e the tw o matrices ab ov e. Consider a tensor neural net w ork with fiv e no des, N A , N B , N H , N K , and N F , suc h that the sources N A and N B ha v e initial distributions D A = ( a 11 , a 12 , a 21 , a 22 , 0 , 0 , 0) and D B = ( b 11 , b 12 , b 21 , b 22 , 0 , 0 , 0). The underlying graph is shown in Figure 2 . N A N H N B N K N F Figure 2. T ensor neural netw ork which computes the row by product matrix m ultiplication with the Strassen algorithm. The activ ation tensors of no des N H , N K and N F are constructed using the Strassen’s algorithm. The activ ation matrices of H and K are used to determine the linear combi- nations on matrix N A and matrix N B , resp ectively , future factors of the multiplications in p 1 , . . . , p 7 . Subsequen tly , the activ ation tensor of N F determines ho w to multiply these factors and ho w the new terms p 1 , . . . , p 7 con tribute to the en tries of the resulting matrix 9 N S 1 N S 2 N F Figure 3. Final sub-netw ork which computes the Strassen algorithm. C . Therefore, the activ ation tensors of N H and N K are 7 × 7 matrices suc h that H = 1 0 1 0 1 − 1 0 0 0 0 0 1 0 1 0 1 0 0 0 1 0 1 1 0 1 0 0 − 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 , K = 1 1 0 − 1 0 1 0 0 0 1 0 0 1 0 0 0 0 1 0 0 1 1 0 − 1 0 1 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 . The activ ation of N F is an order-3 tensor F suc h that F = f 2 ( F 0 ) , with F 0 = 1 0 0 1 − 1 0 1 0 0 1 0 1 0 0 0 1 0 1 0 0 0 1 − 1 1 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 . The outline of the arc hitecture follows. Consider the tw o sub-netw orks consisting of the pairs of no de N A , N H and N B , N K , in the only p ossible total order, which are resp onsible for the transmission of the signal from the input no des to the middle lay er. N A transmits the signal to no de N H , then the activ ation tensor A p erforms a blow op eration: A 1 = b ( A ) . By similar reasoning, B 1 = b ( B ) . The total tensors S (1) 0 and S (2) 0 of these t w o sub-netw orks w ere to b ecome inputs for the final sub-netw ork comp osed of the tw o new sources N S 0 and N S 1 and no de N F (see Fig- ure 3 ), and S (1) 0 = ( B M P ( A 1 , H )) , S (2) 0 = ( B M P ( B 1 , K )) . Therefore, the initial distributions b ecome the contraction ov er the first index of S (1) 0 and S (2) 0 . S (1) = con traction { 1 } ( S (1) 0 ) , S (2) = con traction { 1 } ( S (2) 0 ) . By construction, S (1) and S (2) are tw o v ectors of length 7. According to signal transmission, the activ ation tensors of no de N S 1 and N S 2 b ecome, resp ectiv ely , S (1) f = b ( f 2 ( S (1) )) , and S (2) f = b ( f 1 ( S (2) )) . 10 The no des N S 1 and N S 2 are not presen t in the original netw orks, but they represent in termediate states of the netw ork. Therefore, they are considered hidden and, once the total tensor of the net w ork has b een computed, it is necessary to con tract ov er the indices asso ciated with them. Hence, the final output is T = contraction { 2 } (con traction { 1 } ( B M P ( S (1) f , S (2) f , N F ))) , i.e. a v ector of length 7 such that whose first 4 co ordinates are the entries of the matrix m ultiplication in Equation ( 1 ): T = ( a 11 b 11 + a 12 b 21 , a 11 b 12 + a 12 b 22 , a 21 b 11 + a 22 b 21 , a 21 b 12 + a 22 b 21 , 0 , 0 , 0) . 5. Ma trix Mul tiplica tion via Neural Learning The aim of this w ork is to implemen t a neural arc hitecture that predicts the three matrices H , K , and F , characterising the matrix multiplication algorithm. The netw ork p erforms all the operations describ ed in Section 4.1.1 , while the matrices H , K , and F are initialised randomly and then up dated using a gradient descen t mec hanism. As in tro duced in Sec- tion 4 , the dimensions of these matrices are n 2 , in the case of n × n matrix multiplication, and r , which is an upp er b ound for the rank of the m ultiplication tensor. 5.1. Dataset. The training and v alidation sets consist of 10 , 000 triples each, comp osed of t w o random matrices A and B with inputs sampled uniformly from [ − 1 , 1], and their pro duct AB , which corresp onds to the target v alue. Thus, the inputs and the target can b e initialised as the triple ( A, B , AB ). 5.2. Net w ork Arc hitecture. The StrassenNet architecture exploits three learnable parameter matrices: H ∈ R n 2 × r , K ∈ R n 2 × r , and F ∈ R r × n 2 . These parameters are initialised with small random v alues ∼ N (0 , α 2 ), where α = 1 . 0. The input for the mo del are the flattened version a, b ∈ R n 2 of A, B ∈ R n × n , and learnable parameters H , K ∈ R n 2 × r and F ∈ R r × n 2 , where r is the upp er b ound of the rank. The reference v alue of matrix multiplication is v true = vec( AB ), while the predicted one v pred is computed b y the net w ork with the pro cedure sho wn in Section 4 . T o train the tensor neural net w ork, the error is estimated on the whole training set D using the the mean squared error (MSE) b etw een predicted and true flattened pro ducts as the loss function, i.e. (2) L = 1 | D | X ( A,B ) ∈ D ∥ v pred ( A, B ) − v true ( A, B ) ∥ 2 2 . F or the optimisation phase we use Adam with leaning rate η = 10 − 3 and, to preven t ex- plo ding gradients during the complex tensor op erations, w e incorp orate gradien t clipping, whic h rescales the gradien t whenev er its norm exceeds a prescribed threshold (set to 10 . 0). The pip eline of the exp erimentation pro cedure follows. 5.3. Exp erimen tation. The goal of these exp eriments is to pro vide a numerical under- standing of the rank of the 3 × 3 matrix–multiplication tensor b y v arying the mo del’s in ternal rank parameter r , whic h upp er-b ounds the num ber of scalar multiplications in the induced algorithm. A narrow target window is motiv ated by theory: by Laderman’s construction there exists a rank-23 scheme ( R ≤ 23) [ 15 ], while Bl¨ aser prov ed the low er b ound R ≥ 19 for the exact bilinear rank [ 19 ]; for comparison, the current b est low er b ound on the b or der rank is R ( M 3 ) ≥ 17 [ 20 , 21 ]. Consequently , v alues r < 19 cannot realise exact m ultiplication, and r = 23 is a known achiev able baseline. W e therefore sw eep r ∈ { 19 , 20 , 21 , 22 , 23 } to test feasibility near the b est-known low er b ound (19-22) 11 Algorithm 1 StrassenNet T raining 1: Input: Dataset D , rank r , matrix size n , ep o chs E , learning rate η 2: Initialize: H , K ∼ N (0 , 1) n 2 × r , F ∼ N (0 , 1) r × n 2 3: Initialize optimizer: Adam( { H , K, F } , lr= η ) 4: for ep o ch = 1 to E do 5: for batch ( A, B , V true ) in D do 6: V pred ← [ ] ▷ container for predictions in the batch 7: e A ← blo w( A ), e B ← blow( B ) ▷ prepro cess inputs according to the netw ork arc hitecture 8: for each sample ( a, b, v t ) in batc h do 9: C ( T ) ← BMP( a, H ); C ← P C ( T ) ▷ linear com binations defined b y H 10: C 1 ← forget( C , 1); C 2 ← blow( C 1 ) ▷ reshap e op erations required by the computational graph 11: D ( T ) ← BMP( b, K ); D ← P D ( T ) ▷ analogous transformation for B 12: D 1 ← forget( D , 1); D 2 ← blow( D 1 ) 13: F 1 ← forget( F , 2) ▷ prepare the p ost-combination tensor 14: T ← BMP( C 2 , D 2 , F 1 ) ▷ core bilinear step: r scalar multiplications 15: M ← P i T i 16: v pred ← P j M j ▷ assemble the output vector 17: App end v pred to V pred 18: end for 19: L ← MSE( V pred , V true ) ▷ batch loss 20: Bac kpropagate ∇ H,K,F L 21: Clip gradients: ∥∇∥ ≤ 10 ▷ stabilise training by prev en ting gradient explosion 22: Up date parameters with Adam ▷ apply adaptive up dates 23: end for 24: Ev aluate on v alidation set ▷ monitor generalisation p erformance 25: end for 26: Return: Optimised H , K, F and to include the p ositive con trol r = 23 corresponding to kno wn rank-23 algorithms. All remaining h yp erparameters are as in T able 1 . T able 1. Summary of training hyperparameters. Hyp erparameter V alue Matrix size n = 3 (i.e., 3 × 3 matrices) Rank r T raining samples p er ep o ch 10 , 000 V alidation samples 10 , 000 Batc h size 32 Ep o c hs 60 Learning rate 10 − 3 V alue range in matrices [ − 1 , 1] Device 12GB GPU GeF orce GTX 1080 Ti Figure 4 shows the training and v alidation losses of a batc h of exp eriments in whic h r = 19 , 20 , 21 , 22 , 23. F or eac h v alue r = 19 , 20 , 21 , 22 , 23, w e p erform sev en rep etitions, and the mean and standard deviation v alues are presented in Figure 5 . 12 (a) (b) Figure 4. Plot of the training (a) and v alidation (b) losses of a batch of exp eri- men ts for matrices with entries clamped in [ − 1 , 1] and v alues of rank r b etw een 19 and 23. In blue, orange, red, green and yello w the mean and standard deviation of the losses for r = 23 , 22 , 21 , 20 , 19, resp ectively . Figure 5. Histogram showing the mean µ and standard deviation σ of v alidation losses for matrices with en tries limited to [ − 1 , 1] and rank v alues r b etw een 19 and 23. The v alue µ for r = 23, in blue, is 0 , 0025802, while σ is 0 , 0050602; for r = 22, in orange, µ = 0 , 012773 and σ = 0 , 007641; for r = 21, in red, µ = 0 , 029102 and σ = 0 , 0056912; for r = 20, in green, µ = 0 , 034695 and σ = 0 , 0054031; for r = 19, in yello w, µ = 0 , 047196 and σ = 0 , 0085363. The mo del reac hes con v ergence in less than 60 ep o chs, with training and v alidation losses decreasing monotonically . During the training phase, a decrease can b e observ ed from initial v alues of ∼ 10 0 to final v alues of less than 10 − 2 . The v alidation loss follo ws the trend of the training loss. The results in Figure 4 and Figure 5 , evidence a clear separation b etw een the case r = 23 and all other tested v alues. In particular, for r = 23 the mean squared error stabilises at the order of 10 − 4 , whereas for all other ranks the error consistently remains around 10 − 2 . This one-order-of-magnitude impro v ement indicates that r = 23 is the smallest upp er b ound of the rank capable of accurately capturing the algebraic structure of the underlying tensor. Based on these observ ations, our model suggests that r = 23 is the effectiv e rank of the 3 × 3 matrix multiplication tensor. 13 6. Discussion T o statistically assess whether the difference b et ween the losses obtained b y imp osing r = 23 and r = 22 is significant, we p erform a one-tailed W elch’s t -test [ 31 ] on the loss v alues collected from the tw o indep endent sets of exp eriments. Let µ 1 and µ 2 denote the exp ected loss of the tw o mo dels with r = 23 , 22, resp ectively . The statistical hypotheses are formulated as follows: H 0 : µ 1 ≥ µ 2 , H 1 : µ 1 < µ 2 . Giv en the sample statistics x 1 = 0 . 0022168 , s 1 = 0 . 0047183 , n 1 = 7 , x 2 = 0 . 012782 , s 2 = 0 . 0069753 , n 2 = 7 , the W elc h t -statistic w as computed as t = x 1 − x 2 p s 2 1 /n 1 + s 2 2 /n 2 = − 3 . 318 , with ν ≈ 11 . 2 degrees of freedom as estimated via the W elc h–Satterth w aite approximation. The resulting one-tailed p -v alue is p = 0 . 0032 , indicating strong statistical evidence that the mo del trained with r = 23 ac hieves a lo w er loss than the one in which r = 22. In addition, the 95% confidence interv al for the difference in mean of µ 1 and µ 2 is C I 95% = [ − 0 . 0176 , − 0 . 0036] , whic h lies entirely b elo w zero. This confirms that the exp ected loss when r = 23 is significan tly smaller than that with r = 22. The resulting one-tailed p -v alue quan tifies the evidence against the null hypothesis. A sufficien tly small v alue of p supp orts the conclusion that the mo del trained with r = 23 ac hiev es a significan tly low er exp ected loss than mo del in which r = 22. T o justify that the result obtained by imp osing r = 23 is statistically b etter than all the others, the one-tailed W elch’s t -test based on sev en independent runs for eac h mo del is also computed to assess whether the difference in losses is significan t in each of the following cases: b etw een r = 22 and r = 21, r = 21 and r = 20, r = 20 and r = 19. • Differ enc e of the losses in the mo dels with r = 22 and r = 21 : the W elch test yields a test statistic of t = − 4 . 532 with approximately 11 . 6 degrees of freedom, corresp onding to a one-tailed p -v alue of 3 . 8 × 10 − 4 . This indicates that, under the assumption that the t w o mo dels ha v e equal or comparable p erformance, the decrease in losses statistically significant. • Differ enc e of the losses in the mo dels with r = 21 and r = 20 : although the difference in mean loss is relativ ely small compared to the within-group v ariability , the W elc h test yields a test statistic of t = − 1 . 884 with approximately 12 degrees of freedom, corresponding to a one-tailed p -v alue of 0 . 042. This provides w eak but non-negligible statistical evidence that the mo del trained with r = 21 outp erforms the one with r = 20. • Differ enc e of the losses in the mo dels with r = 20 and r = 19 : The W elc h test returned a test statistic of t = − 3 . 273 with approximately 10 . 7 degrees of freedom, yielding a one-tailed p -v alue of 0 . 0040. These results indicate strong statistical difference b etw een the mo dels with r = 20 and r = 19. 14 Therefore, since the differences b et w een the losses are statistically significant, our exp eri- men tal approac h seems to confirm that r = 23 is not just an upp er b ound of R ( ⟨ 3 , 3 , 3 ⟩ ). In fact, comparing the results of the mo del in whic h r = 23 with others that imp ose a lo w er rank b etw een 22 and 19 suggests, although it do es not prov e, that R ( ⟨ 3 , 3 , 3 ⟩ ) = 23. 7. Border rank T o explore appro ximate algorithms, we developed an ε –parametrised version of Strassen- Net , in whic h the factors ( H , K, F ) dep end p olynomially on a small parameter ε and reco v er, in the limit ε → 0, the b order-rank decomp ositions with 20 terms describ ed by Smirno v in [ 32 ]. Initial exp erimen ts for r ∈ 17 , . . . , 21 yield mean loss v alues consistent with the exp ected trend and with the theoretical bounds 17 ≤ R ( M 3 ) ≤ 20 ([ 20 , 21 ]). The loss systematically decreases as r increases, with a visible drop betw een r = 18 and r = 19. Ho w ever, all runs con v erge to v alues of order 10 − 2 , which limits the significance of these differences. This b eha viour is largely due to instability in the ε –parametrisation: the optimisation landscape b ecomes extremely flat, and the mo del cannot exploit finer structural differences among the candidate ranks. T o mitigate these issues, future directions include testing alternative optimisers instead of Adam and introducing nested sc heduling for ε , starting from a larger v alue (e.g. 0 . 02) and gradually reducing it via a multiplicativ e deca y ε ← 0 . 95 · ε . This homotopy-st yle approac h should impro v e conditioning and reduce premature conv ergence. A further refinement, which requires more substan tial developmen t, is the in tro duction of explicit cancellation mechanisms. Because the p olynomial parametrisation of ( H, K, F ) re- lies on delicate cancellations among monomials in H K —necessary to stabilise the division b y ε 2 in F —small p erturbations can lead to large n umerical errors. Adding regularisation terms enforcing these cancellations would stabilise the mo del and pro vide a more reliable appro ximation path to b order-rank decomp ositions. A cknowledgments A. Bernardi has b een partially supp orted b y GNSAGA of IND AM; the Europ ean Union’s HORIZON–MSCA-2023- DN-JD programme under the Horizon Europ e (HORIZON) Marie Sk lo do wsk a- Curie Actions, grant agreemen t 101120296 (TENORS); the Simons Institute. References [1] V olker Strassen. Gaussian elimination is not optimal. Numerische mathematik , 13(4):354–356, 1969. [2] Peter B ¨ urgisser, Michael Clausen, and M. Amin Shokrollahi. Algebr aic Complexity The ory , volume 315 of Grund lehren der mathematischen Wissenschaften . Springer, 1997. [3] Joseph M Landsb erg. T ensors: ge ometry and applic ations: ge ometry and applic ations , volume 128. American Mathematical So c., 2011. [4] Dario Bini. Relations b et ween exact and appro ximate bilinear algorithms. applications. Calc olo , 17(1):87–97, 1980. [5] Arnold Sch¨ onhage. Partial and total matrix multiplication. SIAM Journal on Computing , 10(3):434– 455, 1981. [6] Matthias Christandl, P´ eter V rana, and Jeroen Zuiddam. Asymptotic spectrum of tensors and quantum functionals. Communic ations in Mathematic al Physics , 367(2):705–747, 2019. [7] Matthias Christandl, Vladimir Lysiko v, and Jero en Zuiddam. W eighted slice rank and a minimax corresp ondence to strassen’s sp ectra. Journal de Math ´ ematiques Pur es et Appliqu´ ees , 172:299–329, 2023. [8] Jero en Zuiddam. Algebr aic c omplexity, asymptotic sp e ctr a and entanglement p olytop es . PhD thesis, Univ ersity of Amsterdam, 2019. [9] Don Copp ersmith and Shmuel Winograd. Matrix multiplication via arithmetic progressions. Journal of Symb olic Computation , 9(3):251–280, 1990. 15 [10] Andrew Stothers. On the Complexity of Matrix Multiplic ation . PhD thesis, Univ ersit y of Edin burgh, 2010. [11] Virginia V assilevsk a Williams. Multiplying matrices faster than coppersmith–winograd. In Pro c e edings of the 44th ACM Symp osium on The ory of Computing (STOC) , pages 887–898, 2012. [12] F ran¸ cois Le Gall. Po w ers of tensors and fast matrix multiplication. In Pro c e edings of the 39th Inter- national Symp osium on Symb olic and Algebr aic Computation (ISSAC) , pages 296–303, 2014. [13] Josh Alman and Virginia V assilevsk a Williams. A refined laser metho d and faster matrix multiplica- tion. In 62nd IEEE Symp osium on F oundations of Computer Scienc e (FOCS) , pages 524–535, 2021. [14] Matthias Christandl, P´ eter V rana, and Jero en Zuiddam. Barriers for fast matrix multiplication from irrev ersibility . The ory of Computing , 17(2):1–32, 2021. [15] Julian D. Laderman. A noncommutativ e algorithm for m ultiplying 3 × 3 matrices using 23 m ultipli- cations. Bul letin of the Americ an Mathematic al So ciety , 82(1):126–128, 1976. [16] Edoardo Ballico, Alessandra Bernardi, F ulvio Gesmundo, Alessandro Oneto, and Emanuele V entura. Geometric conditions for strict submultiplicativit y of rank and b order rank. Annali di Matematica Pur a e d Applic ata , 199:1099–1118, 2020. [17] Edoardo Ballico, Alessandra Bernardi, Matthias Christandl, and F ulvio Gesm undo. On the par- tially symmetric rank of tensor pro ducts of W-states and other symmetric tensors. R endic onti Lincei. Matematic a e Applic azioni , 30(1):93–124, 2019. [18] Matthias Christandl, F ulvio Gesmundo, Mateusz Micha lek, and Jero en Zuiddam. Border rank non- additivit y for higher order tensors. SIAM Journal on Matrix Analysis and Applic ations , 42(2):503–527, 2021. [19] Markus Bl¨ aser. On the complexity of the m ultiplication of matrices of small formats. Journal of Complexity , 19(1):43–60, 2003. [20] Austin Conner, Alicia Harp er, and J. M. Landsb erg. New low er b ounds for matrix multiplication and the 3 × 3 determinant. arXiv:1911.07981, 2019. [21] Austin Conner, Alicia Harp er, and J. M. Landsb erg. New low er b ounds for matrix multiplication and the 3 × 3 determinant. F orum of Mathematics, Pi , 11:e17, 2023. [22] Alhussein F awzi, Priyam Chhabra, Matej Balog, and et al. Disco vering faster matrix multiplication algorithms with reinforcement learning. Natur e , 610:47–53, 2022. [23] Alessandra Bernardi, Alessandro Oneto, and Pierpaola Santarsiero. Decomp osition lo ci of tensors. Journal of Symb olic Computation , 131:102451, 2025. [24] Dario Bini, Milvio Cap ov ani, F rancesco Romani, and Grazia Lotti. O (n2. 7799) complexity for n × n appro ximate matrix multiplication. Information pro c essing letters , 8(5):234–235, 1979. [25] J Landsb erg. The border rank of the multiplication of 2 × 2 matrices is sev en. Journal of the Americ an Mathematic al So ciety , 19(2):447–459, 2006. [26] Shmuel Winograd. On multiplication of 2 × 2 matrices. Line ar algebr a and its applic ations , 1971. [27] John E Hopcroft and Leslie R Kerr. On minimizing the n umber of m ultiplications necessary for matrix m ultiplication. SIAM Journal on Applie d Mathematics , 20(1):30–36, 1971. [28] Hans F de Gro ote. On v arieties of optimal algorithms for the computation of bilinear mappings i. the isotrop y group of a bilinear mapping. The or etic al Computer Scienc e , 7(1):1–24, 1978. [29] Luca Chiantini, Giusepp e Alessio D’Inv erno, and Sara Marziali. Pro duct of tensors and description of net works, 2025. [30] Ian Go o dfello w. Deep learning, 2016. [31] Bernard L W elch. The generalization of ‘student’s’problem when sev eral differen t population v arlances are inv olv ed. Bi ometrika , 34(1-2):28–35, 1947. [32] A. V. Smirnov. The bilinear complexity and practical algorithms for matrix multiplication. Compu- tational Mathematics and Mathematic al Physics , 53(12):1781–1795, 2013. (P . Andreini, M. Bianchini, S. Marziali, G. Nunziati, F. Scarselli) Dip ar timento di Ingegneria dell ’Inf ormazione e Scienze Ma tema tiche, Universit ` a di Siena, It al y (A. Bernardi) Dip ar timento di Ma tema tica, Universit ` a di Trento, It al y 16 (B. T. Corradini) It alian Institute of Technology, Genoa, It al y Email addr ess , (Andreini): paolo.andreini@unisi.it Email addr ess , (Bianchini): monica.bianchini@unisi.it Email addr ess , (Bernardi): alessandra.bernardi@unitn.it Email addr ess , (Corradini): barbaracorradini5@gmail.com Email addr ess , (Marziali): sara.marziali@student.unisi.it Email addr ess , (Nunziati): giacomo.nunziati@student.unisi.it Email addr ess , (Scarselli): franco.scarselli@unisi.it
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment