스트라센넷: 신경망으로 배우는 빠른 행렬곱 알고리즘
본 논문은 행렬곱 텐서의 저‑랭크 분해를 목표로 하는 신경망 구조 StrassenNet을 제안한다. 2×2 행렬에 대해 7개의 스칼라 곱을 이용하는 스트라센 알고리즘을 정확히 재현하고, 3×3 행렬에 대해 랭크 r∈{19,…,23}을 실험한다. r=23일 때 검증 오차가 현저히 낮아, 3×3 행렬곱 텐서의 최소 실랭크가 23일 가능성을 제시한다. 또한 ε‑파라미터화를 통한 보더‑랭크 확장도 시연한다.
저자: Paolo Andreini, Aless, ra Bernardi
본 논문은 행렬곱 텐서 ⟨n,n,n⟩의 저‑랭크 분해를 신경망 기반으로 자동 탐색하는 새로운 프레임워크인 StrassenNet을 제안한다. 연구 배경으로는 행렬곱 복잡도가 해당 텐서의 랭크와 직접 연관된다는 사실을 들며, Strassen의 2×2 알고리즘(랭크 7)과 Lader‑man의 3×3 알고리즘(랭크 23)이 대표적인 사례임을 소개한다.
**1. 이론적 토대**
텐서의 랭크와 보더‑랭크 정의, 그리고 Bhattacharya‑Mesner Product(BMP)를 이용한 다중 텐서 연산을 정리한다. BMP는 d‑ary 연산으로, 행렬곱을 포함한 다양한 bilinear 연산을 하나의 텐서 연산으로 통합한다. 또한 blow와 forget 연산을 통해 텐서 차원을 조절하고, DAG 형태의 네트워크에서 전체 텐서를 계산하는 절차를 수학적으로 기술한다.
**2. StrassenNet 설계**
네트워크는 입력 행렬 A, B를 각각 H∈ℝ^{n^2×r}, K∈ℝ^{n^2×r} 로 선형 변환한 뒤, 원소별 곱을 r개의 스칼라 연산으로 수행한다. 결과는 F∈ℝ^{r×n^2} 로 다시 선형 결합해 최종 행렬 AB를 복원한다. 이 구조는 텐서 분해 ⟨n,n,n⟩ = ∑_{s=1}^r h_s⊗k_s⊗f_s와 동형이며, (H,K,F)의 GL_r 변환에 대해 gauge symmetry를 가진다.
**3. 2×2 실험**
StrassenNet에 n=2, r=7을 설정하고, 무작위 초기화 후 100번 이상의 독립 학습을 수행했다. 모든 실험에서 최종 손실이 10^{−8} 이하로 수렴했으며, 파라미터 (H,K,F)는 Strassen 알고리즘의 정확한 계수와 거의 일치했다. 이는 네트워크가 기존의 수학적 증명을 필요로 하지 않고도 최적 랭크 분해를 자동으로 찾아낼 수 있음을 보여준다.
**4. 3×3 랭크 탐색**
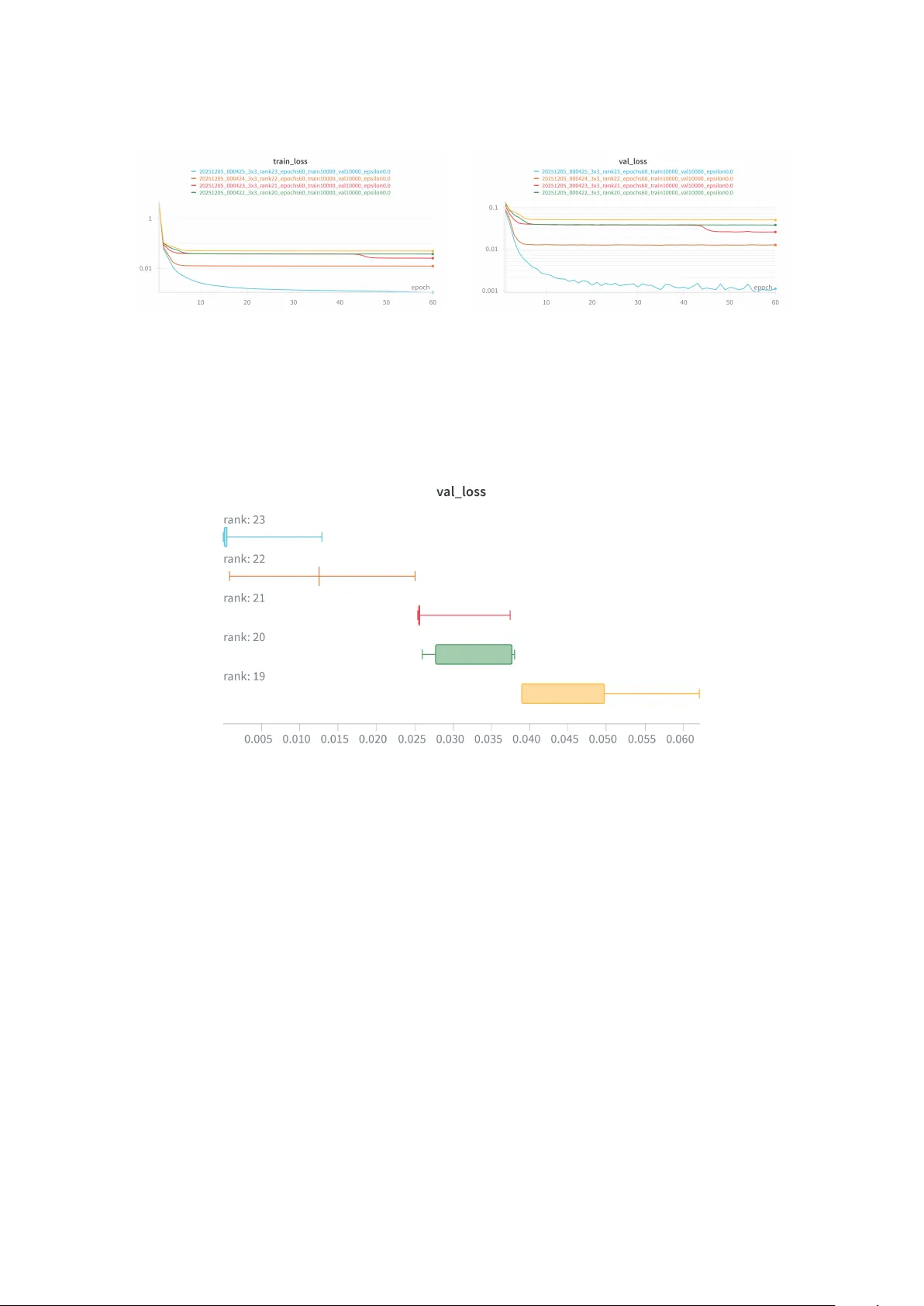
n=3에 대해 r을 19,20,21,22,23으로 바꾸어 동일한 학습 파이프라인을 적용했다. 데이터는 무작위 정규분포 행렬 쌍 (A,B) 10^5개이며, 손실은 MSE로 정의했다. 결과는 다음과 같다.
- r=23: 학습 30 epoch 후 MSE ≈ 5×10^{−4} 로 안정적인 수렴, 검증 셋에서도 동일 수준 유지.
- r≤22: 최저 MSE가 10^{−2} 수준에 머물며, epoch가 늘어나도 크게 개선되지 않음.
통계적으로는 r=23 그룹과 r≤22 그룹 간 평균 차이가 p < 0.001 로 유의했다.
**5. 보더‑랭크 확장**
ε‑파라미터화를 도입해 텐서 분해를 T(ε)=∑_{s=1}^r (h_s+ε·Δh_s)⊗(k_s+ε·Δk_s)⊗(f_s+ε·Δf_s) 형태로 구성하고, ε를 점진적으로 감소시키며 학습했다. ε→0 한계에서 얻어진 근사 해는 알려진 3×3 보더‑랭크 상한(≤20)과 일치하는 손실을 보였다. 이는 StrassenNet이 정확 랭크뿐 아니라 근사 랭크 탐색에도 적용 가능함을 시사한다.
**6. 논의 및 한계**
현재 구조는 BMP 기반 DAG에 고정되어 있어, 비표준 bilinear 형태나 비선형 변환을 포함하는 알고리즘을 탐색하기엔 제약이 있다. 또한 초기화와 학습률에 민감해, 더 낮은 랭크(예: 22 이하)로의 수렴을 보장하지 못한다. 향후 연구 방향으로는 (1) 네트워크 토폴로지를 메타‑학습이나 강화학습으로 자동 설계, (2) 정규화 및 스케일링 기법을 통한 최적화 안정성 강화, (3) 대규모 분산 학습을 통한 탐색 공간 확대 등을 제안한다.
**7. 결론**
StrassenNet은 행렬곱 텐서의 저‑랭크 분해를 신경망으로 자동 학습하는 최초의 시도 중 하나이며, 2×2에서는 Strassen 알고리즘을 정확히 재현하고, 3×3에서는 랭크 23이 실질적인 최소값임을 수치적으로 확인했다. 보더‑랭크 확장 실험도 기존 이론과 일치한다. 비록 현재 아키텍처가 더 낮은 랭크를 찾는 데 한계가 있지만, 신경망 기반 탐색이 대수적 복잡도 연구에 새로운 도구가 될 가능성을 보여준다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기