Functional Continuous Decomposition
The analysis of non-stationary time-series data requires insight into its local and global patterns with physical interpretability. However, traditional smoothing algorithms, such as B-splines, Savitzky-Golay filtering, and Empirical Mode Decompositi…
Authors: Teymur Aghayev
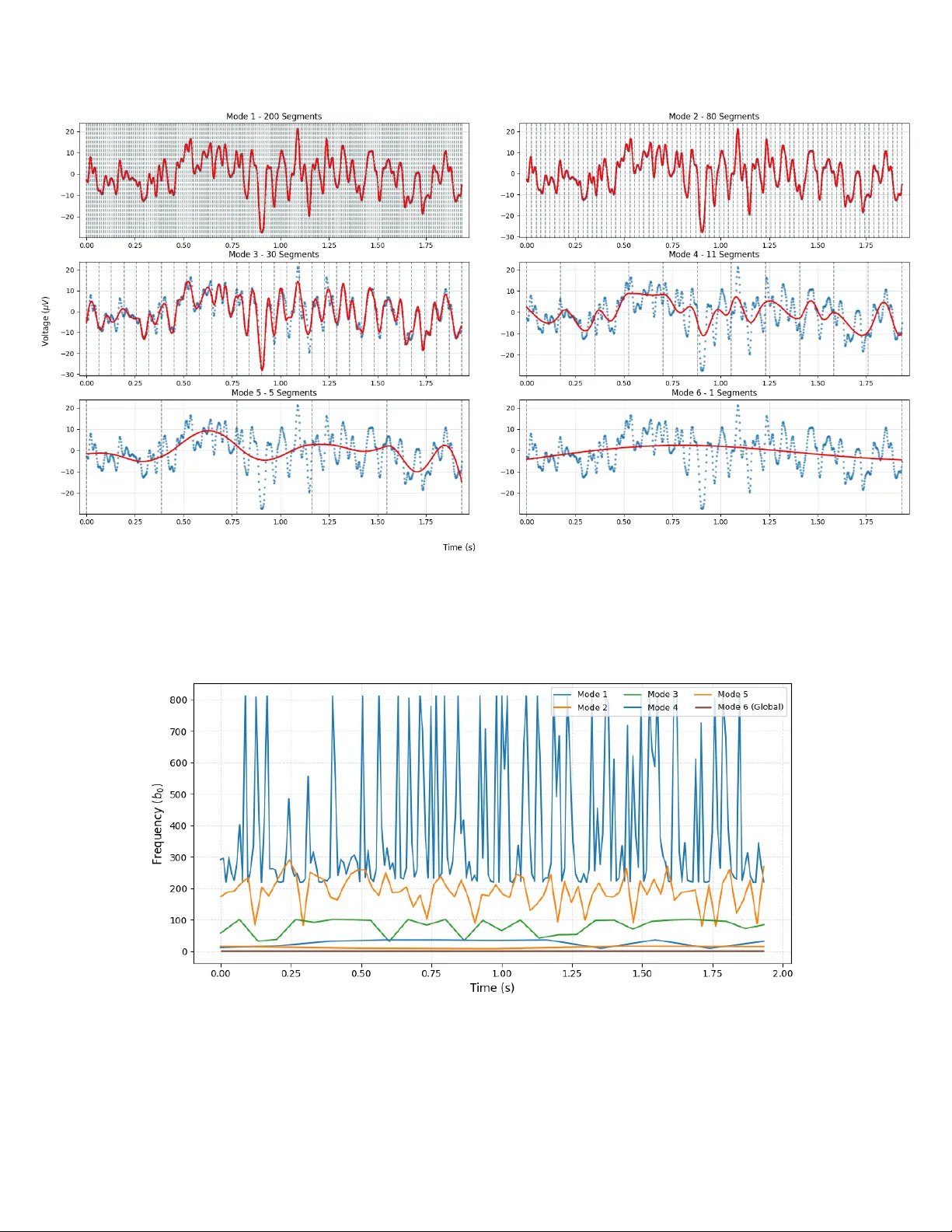
F unctional Con tin uous Decomp osition T eym ur Agha yev Vilnius Gediminas T ec hnical Univ ersity Vilnius, Lithuania teymur.aghayev@stud.vilniustech.lt Abstract The analysis of non-stationary time-series data requires insigh t into its local and global patterns with physical in terpretabilit y . Ho wev er, traditional smo othing algorithms, suc h as B-splines, Savitzky-Gola y filtering, and Empirical Mode Decomp osition (EMD), lac k the abil- it y to p erform parametric optimization with guaranteed contin uit y . In this pap er, we prop ose F unctional Con tinuous Decomp osition (FCD), a JAX-accelerated framework that p er- forms parametric, contin uous optimization on a wide range of mathematical functions. By us- ing Lev enberg-Marquardt optimization to achiev e up to C 1 con tinuous fitting, F CD transforms ra w time-series data in to M mo des that capture different temp oral patterns from short-term to long-term trends. Applications of F CD include physics, medicine, financial analysis, and ma- c hine learning, where it is commonly used for the analysis of signal temp oral patterns, optimized parameters, deriv atives, and integrals of decomp osition. F urthermore, FCD can b e applied for ph ysical analysis and feature extraction with an av erage SRMSE of 0.735 p er segment and a sp eed of 0.47s on full decomp osition of 1,000 p oin ts. Finally , w e demonstrate that a Con volu- tional Neural Net work (CNN) enhanced with FCD features, suc h as optimized function v alues, parameters, and deriv ativ es, achiev ed 16.8% faster conv ergence and 2.5% higher accuracy o ver a standard CNN. 1 In tro duction Real-w orld raw signals are highly non-stationary , and analyzing them requires more than just an optimized curv e. Standard signal pro cessing tec hniques, such as B-splines, Sa vitzky-Golay filtering, and Empirical Mo de Decomp osition (EMD), are widely used for smo othing and feature extraction but lack functional optimization and ph ysical plausibilit y . While traditional optimization algo- rithms, such as Lev enberg-Marquardt (LM), T rust Region Reflective (TRF), and LBF GS-B, can fit data with mathematical functions, they cannot b e used for contin uous C 1 fitting b et ween segmen ts for full decomp osition of the raw signal, which is essen tial for deep er analysis and div erse ph ysical applications. Th us, our F unctional Con tinuous Decomposition algorithm bridges the limitations of current signal processing algorithms by decomp osing raw time-series data in to M mo des with o verall C 1 con tinuit y . Sp ecifically , initial modes ha v e a higher num b er of segmen ts to sho w local patterns, whereas higher mo des reveal general patterns in the data. Each segmen t is fit with a sp ecified mathematical function used for decomp osition. Segmen ts maintain C 1 con tinuit y b y al- gebraically fixing tw o parameters of the function. Finally , FCD can b e used to express lo cal and global patterns of data, optimized v alues, deriv atives, and parameters of the fitted function. 1 1.1 Main Con tributions This framework introduces several key contributions to the field of time-series analysis, sp ecifically addressing the limitations of traditional signal pro cessing algorithms. 1. P arametric fitting : Segmen ts are fitted with a sp ecified mathematical function; the output con tains an optimized fit, a function deriv ative, an integral, and parameters. 2. Guaran teed Contin uit y : W e in tro duce a metho d to enforce C 0 and C 1 con tinuit y across segmen t b oundaries by algebraically deriving parameters, ensuring an ov erall contin uous fit. 3. F ull Configurability : Users can define custom mathematical functions (via SymPy integra- tion [8]), initial guesses, tune segmen tation, Leven b erg-Marquardt (LM) parameters, and set sp ecific C 0 , C 1 deriv ative con tinuit y settings. 4. High-Efficiency Decomp osition : W e demonstrate high-fidelit y reconstruction with an a verage segment-wise SRMSE of 0.735 and processing sp eed of 0.47s for 1,000 data points across 6 mo des, demonstrating linear computational complexity ( O ( n )) with resp ect to signal length. 5. Efficien t CNN training : Integrating F CD-derived features (parameters, optimized fit, and deriv atives) in to a CNN architecture results in 16.8% faster con vergence and a 2.5% increase in predictive accuracy . The full implementation and technical do cumen tation can b e accessed here. 2 Bac kground The developmen t of F unctional Con tinuous Decomp osition (FCD) is situated at the intersection of non-stationary signal decomp osition and smo othing algorithms. This sec tion sho ws the mechanical foundations of current traditional tec hniques and iden tifies the technical gaps that F CD aims to solv e. 2.1 Mo de Decomp osition The decomp osition of mo des from non-stationary signals is traditionally dominated by Empirical Mo de Decomp osition (EMD). EMD uses a recursiv e ”sifting” pro cess, whic h extracts In trinsic Mo de F unctions (IMFs) b y in terp olating lo cal extrema of the raw signal via cubic splines. Mechanically , the algorithm iden tifies all lo cal maxima and minima to construct upp er and lo wer env elop es via cubic spline in terp olation. The mean of these env elop es is then subtracted from the original signal to isolate IMFs; this is done recursively un til all mo des are extracted. With this approach, EMD efficien tly decomp oses the signal in to different temp oral patterns. Ho w ever, it lacks an analytical form ulation f ( t ), a contin uous deriv ative, and has error propagation due to its recursiv e nature. 2.2 Lo cal Smo othing Algorithms F CD shares some similarit y with lo cal digital filters and piecewise splines, y et it extends their application for a functional con tinuous analysis. Cubic and B-Splines are highly efficien t smo othing algorithms that p erform p olynomial interpolation of basis functions. B-Splines use a sequence of knots to define piecewise b oundaries, resulting in a smo oth fit across the data. How ever, B-splines lac k parametric interpretabilit y and can only show a smo othed signal fit. 2 Sa vitzky-Golay (SG) is a non-parametric filter that p erforms a lo cal least-squares polynomial fit on a sliding window of fixed length. SG fits a p olynomial and keeps only the cen ter p oin t of each fit. While effective for simple denoising, SG is limited by its static window arc hitecture, with whic h it is not p ossible to sho w contin uous decomp osition, optimized fit, deriv atives, and its parameters. 2.3 Summary of Researc h Gap While existing algorithms provide robust to ols for either signal smo othing (B-Splines, Savitzky- Gola y) or mo de decomp osition (EMD), there remains a critical gap in pro viding a functional de- comp osition of the raw signal with C 1 con tinuit y . F unctional Con tinuous Decomp osition addresses this gap by pro viding a JAX-accelerated framework [1] for contin uous and parametric signal anal- ysis. 3 Metho dology The F unctional Con tin uous Decomposition consists of four main stages: dataset normalization, uniform mo de segmentation, Leven b erg-Marquardt (LM) optimization, and algebraic contin uity enforcemen t. By using the JAX-accelerated LM optimization in batches while pro cessing mo des in parallel, FCD p erforms efficient m ode decomp osition across complex functions and signals. 3.1 Normalization Original x and y datasets are normalized with adaptive standard scaling using the mean ( µ ) and length-dep enden t standard deviation ( σ N ) of the datasets. z = x − µ σ N (1) Here, standard deviation σ N dep ends on the dataset length ( N ) to ensure constant density regard- less of dataset length, whic h results in m uch higher stabilit y of the Lev enberg-Marquardt algorithm. Scaling factor s f = 0 . 01 is used to control the sample densit y: σ N = σ N · s f (2) 3.2 Uniform Segmen tation and Mo de Calculation The FCD framework b egins b y decomp osing the original signal X = { x 1 , x 2 , x 3 , . . . , x N } into M hierarc hical mo des starting from the noisiest to the global trend mo de. Eac h mo de m , except the last, utilizes a uniform segmentation, where the num b er of segments decreases as the algorithm progresses tow ard long-term trends. The total num b er of modes, M , is determined adaptiv ely based on the signal length N . T o ensure eac h mo de captures a distinct temp oral pattern, the framew ork starts with ( N/α ) segments with a minim um n umber of segmen ts β . The n umber of mo des is calculated using a logarithmic function: M = log 2 N /α β + 1 (3) Where α represents the initial divisor for the n umber of segments (default α = 5) and β defines the minim um n umber of segmen ts (default β = 4); the addition of 1 accoun ts for the last trend 3 mo de. This logarithmic approach ensures that M scales efficien tly with the dataset length. F or instance, generating 4 mo des for N = 100, 7 mo des for N = 1 , 000, and 10 mo des for N = 10 , 000. T o generate segmen t b oundaries for eac h mo de, we calculate the num b er of segmen ts in each mo de starting from k 1 = ⌊ N /α ⌋ . Subsequent mo des follow a recursive reduction, where the num b er of segmen ts is halved, k m = max( ⌊ k m − 1 / 2 ⌋ , β ), un til the last trend mo de with ( k M = 1). Afterw ards, segmen t b oundary indices are calculated using linear in terp olation of the n umber of segmen ts in eac h mo de into the dataset range ([0 , N ]). 3.3 Lo cal T ranslation T o ensure high numerical stabilit y and b etter ph ysical interpretation of optimized parameters, eac h segmen t’s x -v alues are translated to lo cal co ordinates. x k represen ts the absolute x-v alue at the curren t segmen t b oundary k , lo cal x-v alues are calculated as: ˆ x = x − x k (4) Lo cal translation impro v es numerical stabilit y and physical applications of parameters. P olynomial co efficien ts and linear offsets directly represen t the signal’s state in the current segment, b eing indep enden t of the global x magnitude. 3.4 Lev en b erg-Marquardt Optimization T o represent the signal within each mo de m , a sp ecified general function y = f ( x, p ) is used, where p is a v ector of parameters. T o ensure con tinuit y betw een segments, t w o parameters are fixed and excluded from p during optimization; instead, they are algebraically deriv ed from the remain- ing parameters in vector p during the calculation of residuals. Unlik e traditional non-parametric metho ds, this approach allo ws for the definition of custom mo dels (p olynomial, sinusoidal, or exp o- nen tial) to reflect the underlying physics of the data with guaranteed contin uit y . Optimization is done with JAX-accelerated Lev enberg-Marquardt algorithm [5, 6] in batches of s segments; mo des are fitted in parallel. General formula of LM optimization: J T J + ( λ + α ) I ∆ p = − J T r , J ij = ∂ r i ∂ p j (5) The system is solved for ∆ p where J is the Jacobian matrix of the residuals r with resp ect to the parameters p , λ is the dynamic damping factor, α is a static ridge regularization, i ∈ { 1 , . . . , N } denotes the data p oin t index and j ∈ { 1 , . . . , d } denotes the parameter index. Residuals are calculated via the Sum of Squared Residuals loss function L : L ( p ) = n X i =1 ( y i − f ( x i , p )) 2 (6) The quality of the prop osed step is defined as the actual reduction ∆ r : the difference b et ween the loss function of past and prop osed error at iteration ( n ) of the optimization. ∆ r = L ( p n − 1 ) − L ( p n ) (7) Crucially , while the lo calized segments are fitted with the LM optimizer, the final trend mo de (not segmen ted) is optimized using a T rust Region Reflective (TRF) algorithm [2] to a void recompilation, as our prop osed LM optimizer is designed for segmen tal fitting. 4 3.5 Ensuring Con tin uity T o ensure each mo de is smooth across segmen t boundaries x k , w e enforce C 0 (v alue) and C 1 (deriv a- tiv e) contin uity by algebraically fixing tw o parameters. They are solv ed analytically based on the previous segment’s y-v alue and deriv ative at the segmen t b oundary . The fixed contin uity param- eters are calculated from the following equations for segmen t k > 1, and the previous segmen t’s lo cal x-v alue at the segment b oundary , denoted as x k − 1 ,l : f (0 , p k ) = f ( x k − 1 ,l , p k − 1 ) (8) f ′ (0 , p k ) = f ′ ( x k − 1 ,l , p k − 1 ) (9) The first equation is solv ed for a fixed v alue parameter, and the second equation for a fixed deriv ative parameter. In function with linear offset term ( ax + b ), b can b e used as a fixed v alue parameter and a as a fixed deriv ative parameter for contin uity b et ween segmen ts. This constrains the Leven b erg- Marquardt (LM) optimizer to only explore solutions that are ph ysically consistent, ensuring exact con tinuit y . Demonstration of the FCD algorithm with 6-parameter sin usoidal mo del (sin6) given as y = ( A 1 x + A 0 ) sin( B 0 x + D ) + C 1 x + C 0 . Blue p oints sho w the original dataset, red is the optimized contin uous fit, and gra y lines are segmen t b oundaries. Figure 1: F CD example on Bitcoin 1-min ute data Optimized functions for mo de 5 are presen ted as follows: f ( x ) = (0 . 263 x + 56 . 296) sin(0 . 064 x − 1 . 155) + (0 . 475 x + 29030) 0 ≤ x < 90 (1 . 198 x + 96 . 122) sin(0 . 044 x + 2 . 236) + (1 . 545 x + 28917) 90 ≤ x < 180 ( − 1 . 681 x + 220 . 586) sin(0 . 052 x − 0 . 823) + (1 . 396 x + 29200) 180 ≤ x < 270 (0 . 142 x + 29 . 495) sin(0 . 059 x + 1 . 922) + (0 . 163 x + 29254) 270 ≤ x < 360 ( − 1 . 974 x + 90 . 332) sin(0 . 063 x − 0 . 870) + ( − 3 . 441 x + 29372) 360 ≤ x ≤ 449 (10) 5 Absolute x-v alues are giv en here for clarit y; to reconstruct the fit, x has to b e lo cally adjusted for eac h segmen t. 3.6 F orward Fit Ho wev er, implementing such constrain ts introduces instabilit y and error propagation within each segmen t. F or example, if a batc h begins with unfa vorable fixed con tinuit y parameters, optimization can b ecome highly unstable, and the error propagates forw ard. W e prop ose an Overlapping F orw ard Fit mec hanism to mitigate this: s + 1 segments are optimized within each batc h, but the last segment is discarded from the fit; instead, it is assigned as an initial guess for the next batch’s first segmen t. The last segment is discarded sp ecifically to re-optimize it in the next batc h while ha ving fa vorable starting contin uity constraints. Th us, during the optimization of one batch, LM enforces contin uity from the past segment and ensures ov erall fit is fav orable to the future segment, whic h efficiently solves error propagation and frequent instability problems. Ov erall, segmen tal fitting in batches is p erformed to ensure high stabilit y , accuracy , and sp eed. 3.7 Unscaling P arameters After the decomp osition is complete, the optimized parameters m ust b e properly unscaled to retain ph ysical meaning and units. W e deriv e the unscaling form ulas b y substituting scaling equations for x and y back into the mo del function. F or brevity , let σ x and σ y denote the length-dep enden t scaling factors σ N ,x and σ N ,y , and let subscripts s and u denote scaled and unscaled parameters, resp ectiv ely . y s = y − µ y σ y (11) As x is translated lo cally for each segment, x k represen ts the absolute x-v alue at the b oundary of the current segment: x s = x − µ x σ x − x k − µ x σ x = x − x k σ x (12) F or example, on a 6-parameter sine wa ve: y s = ( A 1 x s + A 0 ) sin( B 0 x s + D ) + C 1 x s + C 0 (13) W e substitute the scaling equations for y s and x s : y − µ y σ y = ( A 1 x − x k σ x + A 0 ) sin( B 0 x − x k σ x + D ) + C 1 x − x k σ x + C 0 (14) The whole equation is simplified to find equations for unscaling optimized parameters: y = ( A 1 σ y σ x ( x − x k ) + A 0 σ y ) sin( B 0 σ x ( x − x k ) + D ) + C 1 σ y σ x ( x − x k ) + C 0 σ y + µ y (15) Th us, unscaling equations for eac h parameter are defined as: A 1 ,u = A 1 ,s σ y σ x A 0 ,u = A 0 ,s σ y B 0 ,u = B 0 ,s σ x C 1 ,u = C 1 ,s σ y σ x C 0 ,u = C 0 ,s σ y + µ y D u = D s (16) 6 3.8 Computational Optimization The F unctional Con tinuous Decomp osition is designed for high-sp eed fitting and massive datasets. This p erformance is ac hieved b y using JAX’s Just-In-Time (JIT) compilation and XLA (Acceler- ated Linear Algebra) to speed up mathematical operations. F urthermore, parallel mo de fitting with JAX-accelerated Leven b erg-Marquardt algorithm, Jacobian and residual functions, batched opti- mization, and buc keting were utilized to impro ve decomp osition sp eed. Buck eting w as implemen ted to find the b est speed b et ween compilation time and ov erall run time. 3.9 Configurabilit y and Presets F unctional Contin uous Decomp osition is highly configurable; a wide range of mathematical func- tions with initial guesses can b e used for decomp osition. Default presets include linear, quadratic, and cubic p olynomials, sin usoidal models (4,5,6,7 parameter v ariations), deca y , F ourier sine series, Gaussian, and logistic functions with relev ant initial guesses for them. F or mo dels lacking a linear offset term ( ax + b ), the decomp osition can b e configured to maintain only C 0 con tinuit y for stabil- it y . F urthermore, con tinuit y parameters to fix, the num b er of mo des, the order of contin uity , and segmen tation settings can b e configured. The framework allows for analytical output of deriv ative and integral parameters of decomp osition, using numerical or analytical methods, and sp ecifying the order of the deriv ative and in tegral. 4 Results In this section, the F CD framework is ev aluated for accuracy and computational sp eed. The prop osed FCD algorithm was implemen ted in Python 3.9 (64-bit Windows 10) using the JAX library . Benchmarks were p erformed on a computer equipp ed with an Intel i7-10700 CPU, 16GB of DDR4-3200 RAM, and an NVIDIA R TX 3050 GPU. 4.1 Accuracy T ests F unctional Con tin uous Decomposition w as tested on 30 datasets of different v olatility , structure, and scales on all default models. T est datasets include 6 crypto currency markets (BTC, ETH, SOL, AD A, DOGE, XRP) on a second, minute, hourly , and daily time in terv als [4] with non-uniform x-datasets on differen t scales. F urthermore, the remaining 6 datasets include 2 flat line data, linear, cubic function data, and 2 crypto currency datasets on 10 − 20 and 10 20 scales. The primary metric for the measurement of fit accuracy is segmen t-wise SRMSE calculated as follo ws: SRMSE k = q 1 N k P N k i =1 ( y i − ˆ y i ) 2 σ y (17) Where y i represen ts the observed data, ˆ y i is the mo del prediction, and N k is the num b er of data p oin ts in the segmen t k . T o ensure reliability of the error metrics on flat segments, segmen ts with deviation less than 1% of the y-dataset deviation are considered flat. F or such segmen ts, SRMSE w as capp ed at 1.0 to prev ent unstable SRMSE v alues on flat segments, marking it as a neutral fit. 7 Mo del T yp e Avg. SRMSE Cubic 0.774 6-parameter sine 0.568 All mo dels 0.735 T able 1: Accuracy Metrics of the FCD Algorithm. Global SRMSE is often an insensitive metric in time-series due to the total dataset deviation. By using Segment-Wise SRMSE, we ev aluate the mo del’s ability to capture lo cal dynamics, whic h is muc h more accurate for estimation of ov erall fit accuracy . 4.2 Sp eed T ests F CD was designed and optimized for high-sp eed decomp osition. The runtime sp eed of the FCD al- gorithm primarily dep ends on the n umber of p oin ts in the dataset ( N ), its structure, the complexit y of the utilized function, and the qualit y of initial guesses. Speed was tested on different num b ers of p oin ts ( N = 10 to 100,000) and tw o sp ecifically used cubic and 6-parameter sine functions. T able 2: Computational Performance on cubic mo del Num b er of P oints ( N ) First Run* Subsequen t Runs* 10 0.014 s 0.004 s 100 1.669 s 0.024 s 1,000 2.247 s 0.469 s 10,000 6.659 s 3.568 s 100,000 37.116 s 27.382 s The first run is muc h slow er due to initial JAX Just-In-Time compilation. The framew ork can b e compiled during initialization by using w armup; subsequen t runs show the real sp eed of the F CD algorithm without compilation time. T able 3: Computational Performance on 6-parameter sine function Num b er of P oints ( N ) First Run Subsequen t Runs 10 0.066 s 0.005 s 100 2.229 s 0.051 s 1,000 3.341 s 1.289 s 10,000 8.420 s 4.617 s 100,000 50.549 s 43.167 s F CD run time sp eed highly dep ends on the complexity of the function, as a 6-parameter sine w av e requires 2-3x more time than the cubic mo del. 5 Applications F unctional Con tinuous Decomp osition has v arious applications in man y fields, such as ph ysics, medicine, financial analysis, and mac hine learning. In the follo wing sections, we show p ossible examples of F CD in car v elo cit y , EEG signals, and efficien t training of Conv olutional Neural Net- w orks. 8 5.1 V elo city Applications Figure 2: Decomposition of UAH-DriveSet velocity dataset. Figure 3: Normalized deriv ative of decomp osition for UAH-DriveSet velocity dataset. 9 5.1.1 V elo cit y and Acceleration Analysis T o show p ossible applications of the FCD algorithm, we used the UAH-DriveSet dataset [9], whic h records the v elo cit y of the car throughout time. FCD with a cubic mo del is used to decomp ose the v elo cit y signal in to different temp oral patterns and calculate the analytical deriv ative of functions to analyze acceleration (Fig. 2 and 3). Using velocity decomp osition, we can analyze optimized parameters of functions and get insight in to the structure, lo cal, and global patterns of the dataset. In the cubic function used to decomp ose the v elo cit y dataset: v ( t ) = at 3 + bt 2 + ct + d (18) Where d represen ts initial velocity ( v 0 ), c sho ws initial acceleration ( a 0 ), 2 b sho ws initial jerk, 6 a shows rate of change of jerk. T able 4: Comparison of V elo cit y F unctions across FCD Mo des and Segments Mo de Segmen t Time Range (s) Fitted V elo cit y F unction f ( t ) Driving Beha vior 2 20 198.80 – 208.82 − 0 . 057 t 3 + 0 . 666 t 2 + 1 . 761 t + 90 . 31 Rapid spik e 4 12 464.87 – 506.82 − 0 . 0007 t 3 + 0 . 0539 t 2 − 0 . 564 t + 90 . 40 Gradual recov ery 5 7 541.81 – 630.83 1 . 09 · 10 − 5 t 3 − 0 . 003 t 2 − 0 . 052 t + 111 . 0 F ull decrease As observed, lo cal translation of t in each segmen t correctly highlights physical in terpretability , whic h otherwise w ould b e distorted with absolute t-scales. It is imp ortan t to note that the t -v alues pro vided are absolute for clarity . Offsets clearly sho w the initial velocity of eac h segmen t with p olynomial co efficients correctly highlighting driving b eha viour (0 . 666 t 2 , 1 . 761 t on rapid spik e, − 0 . 564 t , 0 . 0539 t 2 on recov ery , and − 0 . 052 on full decrease). While the absolute magnitude of p olynomial parameters decreases in long-term mo des due to the higher segment’s t -span and lo cal translation, their relative influence remains the same. W e demonstrate this most effectiv ely in the deriv ative plot (Fig. 3), where a relative colorbar is used to normalize deriv atives across eac h mo de, clearly sho wing that the relative influence of each mo de is the same, despite absolute scales b eing differen t. Analytic deriv atives can be used to analyze acceleration, for example, in mo de 4, segment 1 ( t = 7 . 850 to 48 . 830s, initial rise) deriv ativ e sho ws the follo wing function: a ( t ) = v ′ ( t ) = − 0 . 00426 t 2 + 0 . 185 t − 0 . 229 (19) Here, − 0 . 229 shows initial acceleration ( a 0 ), 0 . 185 shows initial jerk, whic h correctly represents the initial spike, and − 0 . 00852 (which is − 0 . 00426 · 2) sho ws the rate of change of jerk. The integral of optimized functions w as not shown as the velocity data is p ositiv e, and thus, the integral is monotonic and less useful for analysis. The b est example of integration is sho wn later in EEG applications, where integration shows net v oltage across different mo des. 5.2 Application in EEG signals Our algorithm was applied to EEG signals [10] with a 6-parameter sine mo del to sho w differen t patterns, ensuring ph ysical C 1 con tinuit y . Optimized frequency and amplitude parameters were used to estimate the EEG signal, and the in tegral of the EEG decomp osition was additionally presen ted. T o ensure physical plausibilit y , custom fitting was used to set strictly non-negativ e b ounds for amplitude and frequency , which cannot be physically negativ e. 10 Figure 4: Decomposition p erformed on EEG data with sine mo del. F rom the following decomp osition, w e extracted frequency ( b 0 ) and amplitude ( a 0 ) to analyze patterns in optimized parameters and EEG data: Figure 5: Optimized F requency for EEG dataset. 11 Figure 6: Optimized Amplitude for EEG dataset. The frequency plot (Fig. 5) illustrates that eac h mode successfully captures a distinct frequency . The initial mo des mostly capture signal noise and thus, show v ery high frequency bands; frequency decreases in higher mo des as they provide more general patterns. Amplitude plot (Fig. 6) on the other side, reveals a differen t structure: high-frequency mo des exhibit low er amplitudes due to the higher n umber of segments required to fit rapid fluctuations. In terestingly , Mo de 3 demonstrates the highest amplitude, represen ting a balance b et ween lo cal fitting and signal generalization. Higher mo des show a decrease in amplitude as they capture broader, global trends. Additionally , optimized functions were analytically integrated to sho w Net V oltage ( µ · V · s ): Figure 7: In tegral of decomp osition for EEG dataset. 12 As observ ed, the integral correctly reflects accumulated voltage and provides a deep er insight in to the underlying structure of EEG data. F rom the integral plot, we can see that initially , until ( t = 0 . 50), net EEG v oltage was trending negative, after which it started increasing and sta yed mostly p ositiv e un til (roughly t = 1 . 6), where net v oltage returned to negativ e. Initial modes clearly sho w high-frequency c hanges, whereas higher mo des generalize the accumulated voltage. T o ensure physical applicability of in tegrals, for each segment s , running in tegration logic is used to adjust and calculate integral v alues b y the Cumulativ e Constant C t represen ting the definite in tegral of previous segments. An integral formula for mo de 3, segment 8 ( t = 0.451 to 0.515, gradual recov ery) is given as: Z f ( t ) dt = 75 . 3 t 2 − 0 . 35 t + 1 . 74 t cos(100 t − 1 . 34) − 0 . 0174 sin(100 t − 1 . 34) − 0 . 0679 cos(100 t − 1 . 34) + C t (20) 5.3 Application for efficien t CNN training F unctional Contin uous Decomposition can be used to pro vide Conv olutional Neural Net w orks (CNN) with optimized curv es, parameters, and analytical deriv atives derived from decomp osi- tion. W e tried to in tegrate FCD features into a standard CNN to impro ve prediction accuracy by giving it differen t patterns. W e conducted a comparative test b etw een a standard CNN and the F CD-enhanced CNN architecture. Both mo dels used a lo okbac k window of 60 p oin ts to predict the next 30 v alues; a light complexit y netw ork was used for easier testing [7]. F or architectural fairness, the F CD-CNN was designed with tw o branc hes: one branch is iden tical to the architecture of a standard CNN with pro cessing raw signals, optimized decomp osition, and its deriv ative from F CD, while a secondary branc h pro cesses the optimized parameters from decomp osition. The mo dels w ere ev aluated across t wo datasets: UCI Household Po w er Demand [3] and EEG dataset [10]. A cubic mo del was used for Household P ow er tests, and 6 parameter sine wa v e for EEG tests. W e p erformed a study using training set s izes of 5,000, 10,000, and 20,000 samples. These datasets were pro cessed into 983, 1 , 981, and 3 , 983 training windo ws with a stride (step) of 5, resp ectiv ely . F urthermore, to accoun t for the sto c hastic nature of weigh t initialization and ensure statistical accuracy , each experiment w as rep eated across fiv e indep enden t iterations using differen t seeds. W e recorded the av erage Ro ot Mean Square Error (RMSE) to measure predictive accuracy and the n umber of training ep ochs required for conv ergence (via Early Stopping) to measure effi- ciency . This exp eriment allows us to demonstrate that the FCD-CNN consistently accelerates and impro ves the learning pro cess compared to standard feature extraction. T able 5: CNN Performance Comparison (UCI Household P ow er) Mo del T raining size ( N ) Avg. RMSE Avg. Ep o c hs Avg. Time Standard CNN 5,000 1.2058 43.2 10.6 s F CD-CNN (Cubic) 5,000 1.1343 53.8 35.2 s Standard CNN 10,000 1.0961 46.0 20.7 s F CD-CNN (Cubic) 10,000 1.0646 38.2 63.5 s Standard CNN 20,000 0.7433 37.2 26.9 s F CD-CNN (Cubic) 20,000 0.7450 30.8 108.4 s 13 T able 6: CNN Performance Comparison (EEG Dataset) Mo del T raining size ( N ) Avg. RMSE Avg. Ep o c hs Avg. Time Standard CNN 5,000 7.9772 81.8 17.5 s F CD-CNN (Sin6) 5,000 8.0280 53.0 45.5 s Standard CNN 10,000 7.8166 79.8 26.2 s F CD-CNN (Sin6) 10,000 7.4657 38.0 78.1 s Standard CNN 20,000 8.3649 28.8 18.7 s F CD-CNN (Sin6) 20,000 8.1831 27.8 146.7 s These results provide a comprehensiv e comparison of the performance and efficiency of the standard CNN versus the F CD-CNN. A t a training size of N = 5000, as the training dataset is smaller, the F CD-CNN architecture takes more ep ochs to conv erge, primarily due to higher complexit y and a low-data regime, but results in 6% low er RMSE for the household dataset, whereas for the EEG dataset, FCD-CNN required 35% few er ep ochs and only negligible (0.6%) higher RMSE. F urthermore, F CD-CNN shows the most efficient performance on N = 10000 training size. F or the household dataset test, the mo del achiev ed 17% faster con vergence, while the EEG test sho wed a dramatic 52% reduction in training ep o c hs; the FCD-CNN maintained an av erage 4% lo wer RMSE than the standard mo del. On a training set of 20,000 samples, b oth mo dels start to conv erge with nearly equal RMSE; ho wev er, F CD-CNN still sho wed 17% faster conv ergence for the household test and 3.5% for the EEG test. While the av erage runtime for the FCD-CNN is higher, this is caused by the o verhead of the FCD decomp osition. Sp ecifically , the decomp osition pro cess requires 22 s for 983 windo ws ( N = 5000), 39 s for 1981 windows ( N = 10 , 000), and 74 s for 3983 windows ( N = 20 , 000). F CD feature extraction can b e fully parallelized, and it pro vides a significant sp eed adv antage for more complex deep netw orks where training t ypically spans hours or days. Ov erall, the F CD-CNN consisten tly sho ws 16.8% faster con vergence and 2.5% higher accuracy . By utilizing a cubic mo del for household p o wer and 6-parameter sine w a ves for EEG datasets, F CD- CNN effectively uses robust physical parameters, an optimized curve, and deriv atives to conv erge faster and more accurately . Figure 8: Epo c h coun ts across all iterations and training set sizes for EEG comparison 14 Figure 9: Epo c h coun ts at all iterations and training set sizes for Household Po wer comparison 6 Limitations and Implemen tation Details While F unctional Contin uous Decomp osition offers high flexibility , its stability is highly influenced b y the quality of initial guesses, the complexit y of the model, and stable contin uity parameters. The framew ork provides default presets for commonly used mo dels and initial guesses. Using unstable fixed parameters, functions, or inaccurate initial guesses can lead to slowdo wns and numerical instabilit y . When using custom settings, please adhere to our technical do cumen tation for correct usage. It should b e noted that algebraically derived parameters required for exact contin uit y , by definition, cannot b e constrained b y b ounds. 7 Conclusion This paper presented the F unctional Con tinuous Decomp osition framew ork, a no vel approach to decomp osing non-stationary datasets with a specified mathematical function into C 1 con tinuous mo des. By using a JAX-accelerated Lev enberg-Marquardt optimization with algebraically deriv ed con tinuit y parameters, F CD addresses curren t limitations of mo de decomp osition and smo othing algorithms. This framew ork provides a completely new insight for the analysis of time-series data with differen t temporal patterns, optimized parameters, deriv atives, and integrals of decomposition. Exp erimen tal results demonstrate that the FCD algorithm achiev es an av erage segmen t-wise SRMSE of 0.735 . F urthermore, when integrated into a CNN architecture, F CD-derived features enabled 16.8% faster con vergence and a 2.5% improv ement in accuracy . F uture w ork will focus on the real-time implementation of the FCD b y improving its accuracy , sp eed, and extending the framew ork to provide C n con tinuit y and a wider range of default functions. References [1] James Bradbury et al. JAX: c omp osable tr ansformations of Python+NumPy pr o gr ams . V er- sion 0.3.13. 2018. url : http://github.com/jax- ml/jax . [2] Mary Ann Branch, Thomas F Coleman, and Y uying Li. “A subspace, interior, and conjugate gradien t metho d for masked nonlinear least squares problems”. In: SIAM Journal on Scientific Computing 21.1 (1999), pp. 1–23. 15 [3] Georges Hebrail and Alice Berard. Individual Household Ele ctric Power Consumption . UCI Mac hine Learning Rep ository. DOI: https://doi.org/10.24432/C58K54. 2006. [4] Igor Kroitor, Vitaly Gerasimov, and Artem Danilo v. CCXT – CryptoCurr ency eXchange T r ading Libr ary . https://github.com/ccxt/ccxt . 2023. [5] Kenneth Leven b erg. “A metho d for the solution of certain non-linear problems in least squares”. In: Quarterly of applie d mathematics 2.2 (1944), pp. 164–168. [6] Donald W Marquardt. “An algorithm for least-squares estimation of nonlinear parameters”. In: Journal of the so ciety for Industrial and Applie d Mathematics 11.2 (1963), pp. 431–441. [7] Mart ´ ın Abadi et al. T ensorFlow: L ar ge-Sc ale Machine L e arning on Heter o gene ous Systems . Soft ware a v ailable from tensorflow.org. 2015. url : https://www.tensorflow.org/ . [8] Aaron Meurer et al. “SymPy: symbolic computing in Python”. In: Pe erJ Computer Scienc e 3 (Jan. 2017), e103. issn : 2376-5992. doi : 10.7717/peerj- cs.103 . url : https://doi.org/ 10.7717/peerj- cs.103 . [9] Eduardo Romera, Luis M. Bergasa, and Roberto Arroy o. “Need Data for Driving Beha vior Analysis? Presenting the Public UAH-DriveSet”. In: IEEE International Confer enc e on In- tel ligent T r ansp ortation Systems (ITSC) . Rio de Janeiro, Brazil, No v. 2016, pp. 387–392. doi : 10.1109/ITSC.2016.7795583 . [10] Igor Zyma et al. “Electro encephalograms during Mental Arithmetic T ask Performance”. In: Data 4.1 (2019), p. 14. doi : 10 . 3390 / data4010014 . url : https : / / www . mdpi . com / 2306 - 5729/4/1/14 . 16
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment