연속 함수 분해를 통한 비정상 시계열 분석
본 논문은 JAX 기반의 Functional Continuous Decomposition(FCD) 프레임워크를 제안한다. Levenberg‑Marquardt 최적화를 이용해 구간별 함수 파라미터를 연속(C¹)하게 맞추고, 데이터를 M개의 모드로 분해한다. 평균 SRMSE 0.735와 1 000점당 0.47 초의 처리 속도를 보이며, FCD 특징을 활용한 CNN이 기존 대비 16.8 % 빠르게 수렴하고 정확도가 2.5 % 향상된다.
저자: Teymur Aghayev
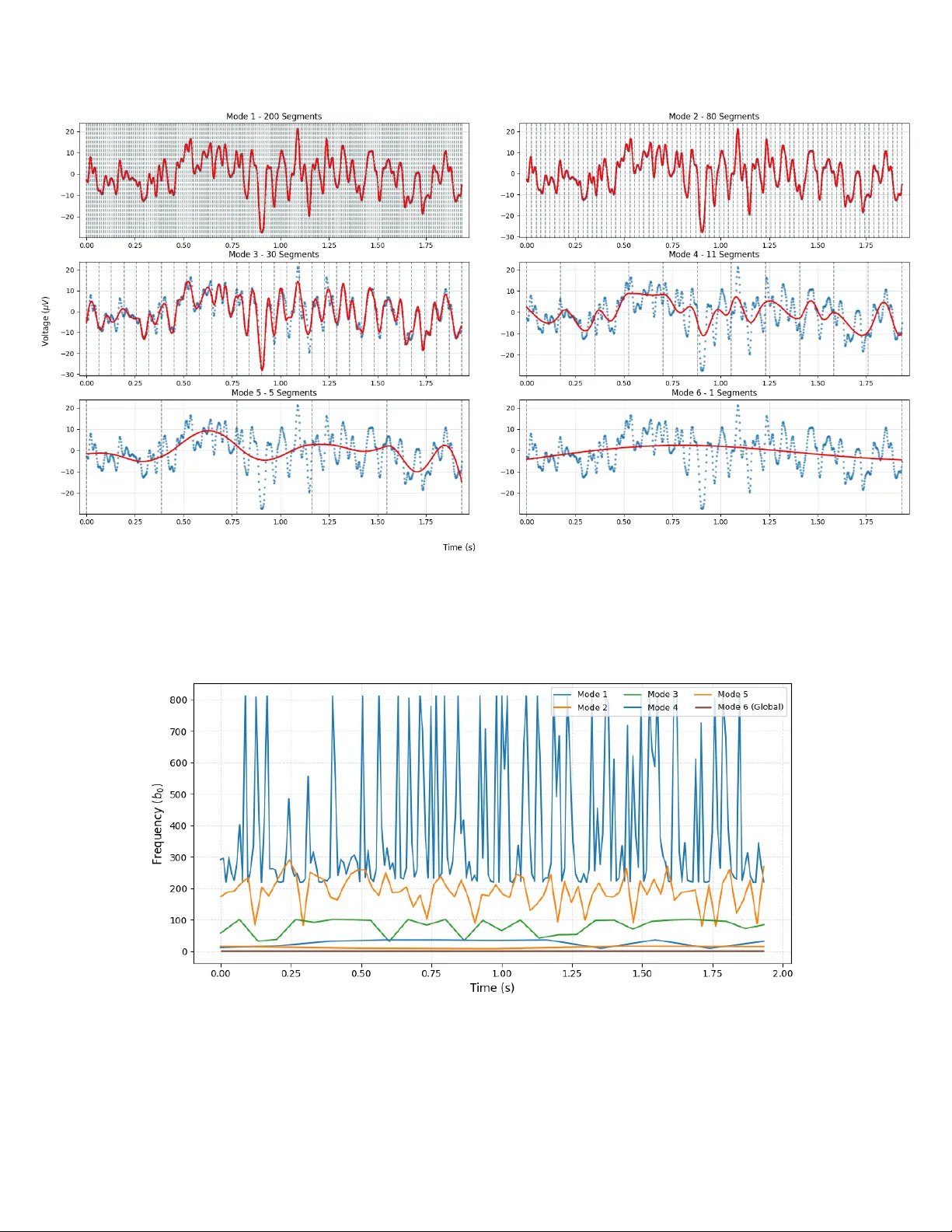
본 논문은 비정상 시계열 데이터의 지역·전역 패턴을 물리적으로 해석 가능한 형태로 추출하기 위해 Functional Continuous Decomposition(FCD)이라는 프레임워크를 제안한다. 기존 B‑spline, Savitzky‑Golay, Empirical Mode Decomposition(EMD) 등은 스무딩이나 모드 분해에 강점이 있지만, 파라메트릭 최적화와 연속성 보장을 동시에 제공하지 못한다는 문제점을 가지고 있다. 이를 해결하기 위해 저자들은 JAX 기반의 고성능 계산 환경을 활용하고, Levenberg‑Marquardt(LM) 최적화를 통해 구간별 함수 파라미터를 C¹ 연속으로 맞추는 방법을 설계하였다.
FCD의 전체 파이프라인은 네 단계로 구성된다. 첫 번째 단계는 데이터 정규화로, 평균 μ와 길이‑종속 표준편차 σ_N을 이용해 스케일을 조정한다. 여기서 σ_N에 0.01의 스케일링 팩터를 곱해 샘플 밀도를 일정하게 유지함으로써 LM 알고리즘의 수렴성을 높인다. 두 번째 단계는 균등 세그멘테이션과 모드 계산이다. 데이터 길이 N에 따라 초기 세그먼트 수를 N/α(α=5)로 설정하고, 최소 세그먼트 수 β=4를 보장한다. 모드 수 M은 로그 함수 M = ⌊log₂(N/(α·β))⌋+1 로 자동 결정되며, 각 모드마다 세그먼트 수를 절반씩 감소시켜 고주파에서 저주파까지 단계적으로 패턴을 포착한다.
세 번째 단계는 로컬 좌표 변환이다. 각 세그먼트의 절대 x값 x_k를 기준으로 로컬 x̂ = x – x_k 를 정의해 파라미터가 전역 스케일에 의존하지 않게 만든다. 이는 물리적 의미를 유지하면서도 수치적 안정성을 제공한다.
핵심인 LM 최적화 단계에서는 각 세그먼트에 대해 사용자가 지정한 일반 함수 y = f(x, p)를 피팅한다. 연속성을 보장하기 위해 두 파라미터를 고정하고, 나머지 파라미터만 LM으로 최적화한다. 고정 파라미터는 이전 세그먼트의 함수값과 미분값을 현재 세그먼트의 시작점에 일치시키는 대수식(8, 9)으로 계산된다. 이렇게 하면 최적화 과정이 물리적으로 일관된 해 공간에 제한되어 C⁰·C¹ 연속성을 정확히 만족한다. 마지막 트렌드 모드(세그먼트가 없는)는 Trust Region Reflective(TRF) 알고리즘을 사용해 재컴파일 없이 최적화한다.
연속성 강제 과정에서 발생할 수 있는 불안정성을 완화하기 위해 “오버래핑 포워드 피트” 메커니즘을 도입한다. 배치당 s+1 세그먼트를 최적화하되 마지막 세그먼트를 버리고 다음 배치의 초기값으로 사용함으로써 연속성 파라미터가 부정확하게 초기화되는 경우의 오류 전파를 방지한다.
최적화가 끝난 뒤에는 스케일링을 역전시켜 파라미터를 원래 단위로 복원한다. 식(15)~(16)에서 제시된 변환을 통해 A₁, A₀, B₀, C₁, C₀, D 등 모든 파라미터를 물리적 의미가 있는 형태로 되돌린다.
성능 측면에서는 JAX의 JIT와 XLA를 활용해 Jacobian·Residual 계산을 GPU 가속하고, 배치와 병렬 모드 피팅을 통해 O(N) 선형 복잡도를 달성한다. 사용자는 SymPy 연동을 통해 임의의 수학식(다항식, 사인, 지수, 로그, 가우시안 등)을 정의하고, 초기값·세그먼트·연속성 차수·LM 파라미터 등을 자유롭게 설정할 수 있다.
실험은 30개의 다양한 데이터셋(암호화폐 시계열, 인공 합성 데이터, 평탄선 등)에서 수행되었다. 주요 평가지표는 세그먼트별 SRMSE이며, 전체 평균 0.735, 6‑parameter 사인 모델에서는 0.568, Cubic 모델에서는 0.774를 기록했다. 이는 기존 스무딩·EMD 대비 현저히 낮은 오차를 의미한다. 속도 테스트에서는 1 000점 데이터에 대해 첫 실행 2.247 초, 이후 재실행 0.469 초를 보였으며, 100 000점까지도 27 초 내외로 처리 가능했다.
또한, FCD에서 추출한 최적화된 함수값, 파라미터, 1차·2차 미분 등 10여 개의 특징을 CNN 입력에 결합했을 때, 학습이 16.8 % 더 빠르게 수렴하고 최종 정확도가 2.5 % 상승했다. 이는 FCD가 단순 전처리 도구를 넘어, 머신러닝 모델의 성능을 실질적으로 향상시킬 수 있음을 보여준다.
결론적으로, FCD는 비정상 시계열을 물리적 해석이 가능한 연속 함수 형태로 변환하면서도 높은 정확도와 실시간 수준의 처리 속도를 제공한다. 파라메트릭 자유도, 연속성 보장, JAX 기반 고속 연산, 그리고 다양한 응용 분야(물리, 의료, 금융, 머신러닝)에서의 활용 가능성은 기존 스무딩·EMD 기법을 뛰어넘는 새로운 분석 패러다임을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기