Attention Deficits in Language Models: Causal Explanations for Procedural Hallucinations
Large language models can follow complex procedures yet fail at a seemingly trivial final step: reporting a value they themselves computed moments earlier. We study this phenomenon as \emph{procedural hallucination}: failure to execute a verifiable, …
Authors: Ahmed Karim, Fatima Sheaib, Zein Khamis
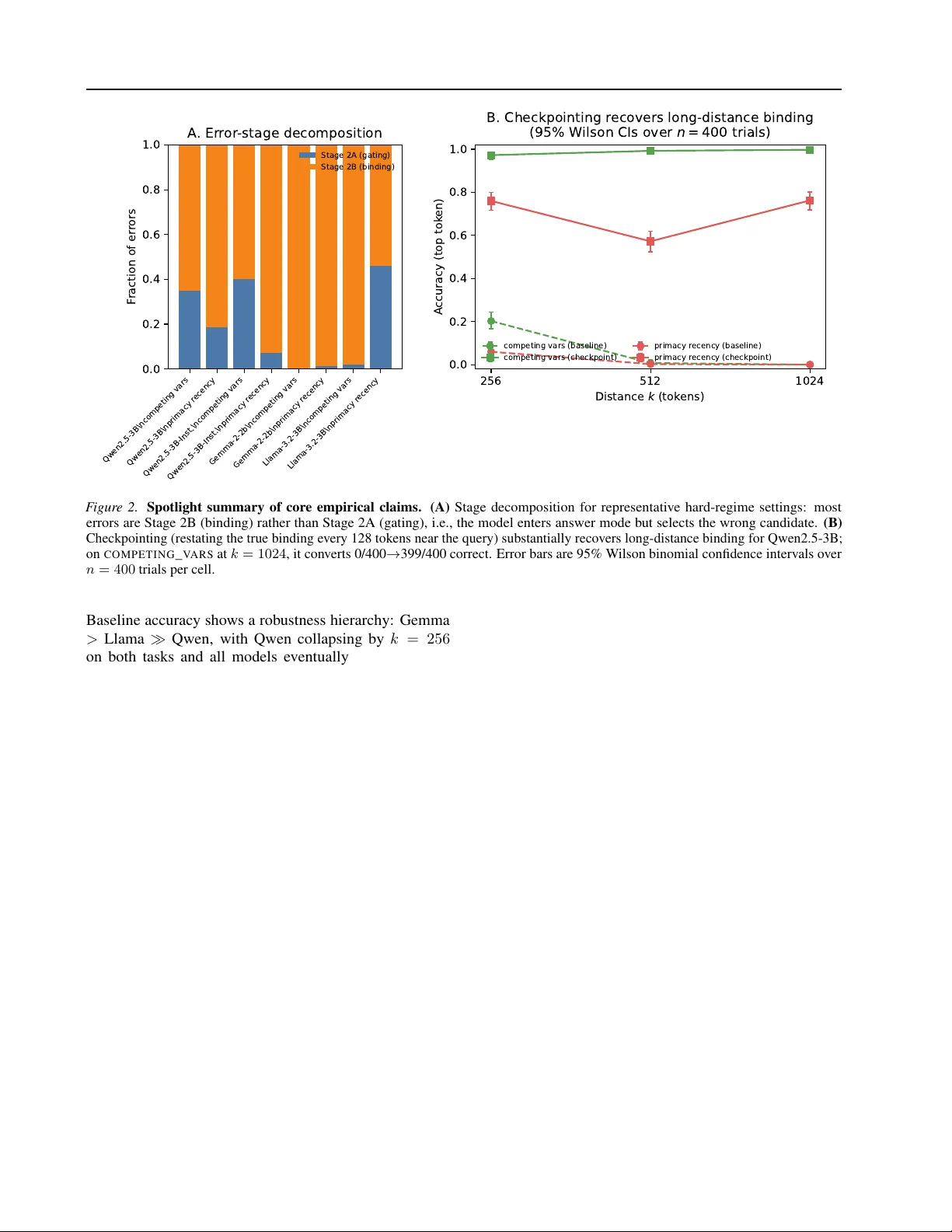
Attention Deficits in Language Models: Causal Explanations f or Pr ocedural Hallucinations Ahmed Karim 1 Fatima Sheaib 1 Zein Khamis 1 Maggie Chlon 1 Jad A wada 1 Leon Chlon 1 2 Abstract Large language models can follo w complex pro- cedures yet fail at a seemingly tri vial final step: reporting a v alue they themselv es computed mo- ments earlier . W e study this as pr ocedural halluci- nation : failure to execute a verifiable, pr ompt- gr ounded specification ev en when the correct value is present in-context. In long-context bind- ing tasks with a known single-token candidate set, we find that many errors are readout-sta ge r outing failur es . Specifically , failures decompose into Stage 2A (gating) errors where the model does not enter answer mode, and Stage 2B (bind- ing) errors where it enters answer mode but se- lects the wrong candidate (often due to recency bias). In the hard regime, Stage 2B accounts for most errors across model families in our tasks (T able 1 ). On Stage 2B error trials, a linear probe on the final-layer residual stream reco vers the cor - rect value far above chance (e.g., 74% vs. 2% on Qwen2.5-3B; T able 2 ), indicating the answer is encoded but not used. W e formalize “present but not used” via av ailable vs. used mutual infor - mation and pseudo-prior interv entions, yielding output-computable diagnostics and information- budget certificates. Finally , an oracle checkpoint- ing intervention that restates the true binding near the query can nearly eliminate Stage 2B failures at long distance (e.g., Qwen2.5-3B 0/400 → 399/400 at k = 1024 ; T able 8 ). 1. Introduction When a language model fabricates a historical date or in- vents a citation, we call this a factual hallucination : the model lacks the relev ant kno wledge. But a different failure mode is equally important and far less understood. Consider the strawberry counting task (see Appendix A ): “How many r’ s are in strawberry?” The model shows its work 1 Hassana Labs 2 Univ ersity of Oxford. Correspondence to: Leon Chlon . via chain-of-thought , enumerating letters and maintaining a running count. For short traces, this works. But as the trace grows longer , the final answer drifts: at length k = 20 , the model outputs 6; at k = 30 , it outputs 8. The compu- tation was f aithful throughout. The failure occurred at the final step, where the readout mechanism selected a wrong statistic (a cumulati ve or recenc y-weighted count) instead of the intended one. The model did not lack the information; it simply failed to use it. W e call this a procedural hallucination : a failure to follow a verifiable pr ompt-gr ounded specification . Formally , we study settings where a specification function g ( W ) deter- ministically maps a prompt W to a single-token answer in a known candidate set, and a procedural hallucination occurs when the model outputs ˆ Y = g ( W ) despite g being unam- biguous (Definition 1 ). Unlike factual hallucination, which concerns world knowledge, procedural hallucination con- cerns the model’ s ability to faithfully ex ecute a specification giv en in its o wn context. When the required e vidence is al- ready present in-context, scaling or retriev al is not suf ficient on its own: the remaining challenge is r outing that evidence to the output. This is not a knowledge failure. The model computed the correct value; probing its hidden state on error trials re- cov ers the answer with high accuracy . The information is present; it is not routed to the output. This observ ation raises two questions. First, can we decompose these failures into interpretable stages? Second, can we formalize “informa- tion is present b ut not used” in a way that yields prov able guarantees? This paper answers both. 1.1. Overview of Contrib utions W e de velop a theory of procedural hallucinations grounded in information theory and causal reasoning, then validate it empirically across model families. Results at a glance (core claims). • Stage 2B dominates in the hard regime: when these binding tasks fail, the model usually enters answer mode but selects the wr ong candidate (Stage 2B), rather than refusing to answer (Stage 2A) (T able 1 , 1 Attention Deficits in Language Models Figure 2 ). • Information is present on err or trials: on Stage 2B errors, a linear probe on the final-layer residual stream recov ers the correct value f ar above chance (e.g., 74% vs. ≈ 2% on Qwen2.5-3B) (T able 2 ). • Checkpointing restor es long-context binding: re- stating the true binding near the query can conv ert near-zero baseline accurac y into near-perfect accuracy at long distance (e.g., Qwen2.5-3B 0/400 → 399/400 at k = 1024 ) (T able 8 , Figure 2 ). Scope. Our main empirical results use synthetic long-context binding tasks ( C O M P E T I N G _ V A R S , P R I - M A C Y _ R E C E N C Y ) where the target is a single token from a known candidate set (Definition 1 ); we addition- ally include one option-randomized naturalistic variant ( notes_binding ; Appendix T able 9 ). W e do not claim that the same mechanisms fully explain all long-context failures in naturalistic tasks such as document QA; we treat that as an open validation tar get (Limitations, Section 7 ). Contributions (with e vidence pointers). • Stagewise decomposition + diagnostics. W e define logprob-deriv ed margins ( GateGap , V alueGap ) that classify each error as Stage 2A (gating) vs. Stage 2B (binding), and sho w Stage 2B dominates errors in the hard regime across model families (Definition 1 , T a- ble 1 ). • Routing-efficiency theory . W e formalize “present but not used” via av ailable vs. used information ( I av ail , I used ) and deri ve certificates and slack decompositions connecting error rates to information b udgets (Sec- tion 4 , Appendix proofs). • Pseudo-priors as causal baselines. W e introduce pseudo-priors induced by evidence-scrubbing interven- tions and prov e tight “bits-to-trust” lower bounds for ov ercoming model biases (Section 4.3 , Theorem 2 ). • Empirical + mechanistic validation and mitiga- tion. W e show (i) probes recover the correct value on Stage 2B errors (T able 2 ), (ii) activ ation patching localizes failures to late components (Section 5 ), and (iii) checkpointing recov ers accuracy at long distance (T able 8 ). Artifact. An anonymized reproducibility package (scripts + cached outputs) is included in the supplemental material; see Appendix Section D . P r o m p t W k ( e v i d e n c e + k f i l l e r + q u e r y ) H i d d e n s t a t e H k a v a i l a b l e i n f o I a v a i l ( k ) O u t p u t Y k u s e d i n f o I u s e d ( k ) Stage 2A : gate G a t e G a p Stage 2B: bind V a l u e G a p pr obe (r ecoverable) er r ors (mis-r outing) pseudo -prior d o ( E = ) C h e c k p o i n t i n g i n c r e a s e s I a v a i l ; trace audits compar e r equir ed vs observed info budgets F igur e 1. Framework overvie w: Stage 2A g ating and Stage 2B binding failures correspond to low routing ef ficiency I used /I av ail , diagnosed via pseudo-prior interventions. 2. Related W ork Procedural hallucinations relate to long-context failures where the answer is explicitly present yet not produced (“know but don’t tell”) ( Liu et al. , 2024 ; Lu et al. , 2024 ; W u et al. , 2025 ) and to broader hallucination/faithfulness taxonomies ( Ji et al. , 2023 ; Maynez et al. , 2020 ). Our di- agnostics draw on mechanistic interpretability (causal trac- ing/editing, circuit discov ery , and binding analyses) ( Meng et al. , 2022 ; Conmy et al. , 2023 ; W ang et al. , 2023 ; Elhage et al. , 2021 ) and information-theoretic frame works for rep- resentation and bottlenecks ( Tishby et al. , 1999 ; Belghazi et al. , 2018 ; Cov er & Thomas , 2006 ). W e operationalize these threads into an API-compatible stagewise decomposi- tion, routing efficiency metric, and pseudo-prior information budgets. 3. Stagewise Slot Population W e no w formalize the setting in a way that is both precise and operationally compatible with API-accessible outputs. The key insight is that slot-population errors can fail in two distinct ways, and distinguishing them clarifies both diagnosis and mitigation. W e refer to these as Stage 2A/2B to emphasize that they are r eadout-sta ge failures (Stage 2): they occur after an implicit Stage 1 in which the model computes/encodes the correct value in its hidden state. Definition 1 (Procedural hallucination) . Fix a candidate set C ⊂ V and a specification function g that deterministically maps a prompt W to a target value V = g ( W ) ∈ C . Let ˆ Y ( W ) denote the model’ s next-token output at the readout position under greedy decoding. W e say the model exhibits a pr ocedur al hallucination on W if ˆ Y ( W ) = g ( W ) in settings where g ( W ) is unambiguous and verifiable from the prompt (i.e., the answer is deterministically reco verable 2 Attention Deficits in Language Models by an explicit procedure). 3.1. Prompt Structur e A prompt W k has three components: (i) a binding region where keys are assigned v alues, (ii) k filler tokens, and (iii) a query requesting a specific value. V alues come from a candidate set C ⊂ V of single-token strings. W e study two task variants: C O M P E T I N G _ VAR S P R I M AC Y _ R E C EN C Y KEY1 = [apple] KEY = [alpha] [k filler tokens] [k filler tokens] KEY2 = [banana] KEY = [beta] [k filler tokens] [k filler tokens] What is KEY1? KEY1 = [ KEY = [gamma] [k filler tokens] What was the FIRST value of KEY? KEY = [ Different keys hold different values; the competitor is a dis- tractor . Same key reassigned; recency bias activ ely competes with the correct answer . 3.2. Stage 2A: Does the Model Enter Answer Mode? Let z θ ( x | W k ) denote the next-token logit for token x at the readout position. W e define: Y k := arg max v ∈C z θ ( v | W k ) (best candidate) (1) ˆ Y k := arg max x ∈V z θ ( x | W k ) (best ov erall token) (2) The indicator G k := 1 { ˆ Y k ∈ C } marks whether the model “enters answer mode” by outputting a candidate token. W e quantify this with the gate margin : GateGap( W k ) := max v ∈C z θ ( v | W k ) − max x / ∈C z θ ( x | W k ) . When GateGap > 0 , the model will output a candidate; when GateGap < 0 , it will output something else entirely (e.g., punctuation or a hedging phrase). Negati ve gate mar - gin indicates a Stage 2A failure. 3.3. Stage 2B: Does the Model Select the Right Candidate? Conditional on entering answer mode, we ask whether the model selects correctly . Let V ∈ C denote the ground-truth value. The value mar gin is: V alueGap( W k ) := z θ ( V | W k ) − max v ∈C\{ V } z θ ( v | W k ) . Positi ve v alue mar gin means correct binding; ne gati ve v alue margin means the model prefers a wrong candidate. This is a Stage 2B failure. 3.4. Why This Decomposition Matters The distinction between Stage 2A and Stage 2B is not merely taxonomic. The two failure modes hav e different signatures and different remedies: • Stage 2A failures indicate that the model does not recognize the query as requesting a value from C . This is a format or instruction-following problem. • Stage 2B failures indicate that the model understands the task format but routes to the wrong value. This is an information-routing problem, often dri ven by recency bias. W e report global accuracy P ( ˆ Y k = V ) , candidate accuracy P ( Y k = V ) , and an err or decomposition into gating vs. binding failures via F rac - 2 A := P ( G k = 0 | ˆ Y k = V ) and F rac - 2 B := P ( G k = 1 | ˆ Y k = V ) (so F rac - 2 A + F rac - 2 B = 1 ). 4. Inf ormation-Theoretic Framew ork W e no w formalize “information is present but not used. ” The key objects are a vailable information (what the hidden state knows) and used information (what the output exploits). Proofs appear in B . 4.1. A vailable versus Used Inf ormation Let H k denote the model’ s internal state at the readout position (e.g., the final-layer residual stream). The data- generating process forms a Markov chain: V → W k → H k → Y k , where V is the ground-truth v alue, W k is the prompt, H k is the hidden state, and Y k is the model’ s candidate-set decision. Definition 2 (A vailable and used information) . W e define: I av ail ( k ) := I( V ; H k ) , I used ( k ) := I( V ; Y k ) , and the routing efficiency : η k := I used ( k ) I av ail ( k ) ∈ [0 , 1] . Proposition 1 (Data processing) . F or any k , we have 0 ≤ η k ≤ 1 . Routing efficienc y captures how much of the av ailable in- formation the model actually exploits. Procedural halluci- nations correspond to η k ≪ 1 : the hidden state encodes the answer ( I av ail is large), b ut the output ignores it ( I used is small). In practice, I used can be lower -bounded from 3 Attention Deficits in Language Models candidate-set error rates via Fano, and I av ail can be lo wer- bounded (when acti vations are av ailable) via probe perfor - mance, yielding an empirical routing-certificate summary (Appendix T able 12 ). 4.2. From Err or Rates to Information: F ano Bounds Let M := |C | and define the candidate-set error rate ε ( k ) := P ( Y k = V ) . Theorem 1 (F ano lo wer bound) . If V is uniform on C , then: I used ( k ) ≥ log M − h ( ε ( k )) − ε ( k ) log( M − 1) , wher e h ( · ) is binary entr opy in nats. This bound says that high error implies lo w used informa- tion. But is the bound tight? The follo wing proposition says yes, and characterizes exactly when. Proposition 2 (Minimax tightness) . F or every M and ε ∈ [0 , 1 − 1 / M ] , the M -ary symmetric channel achieves equality in 1 . This c hannel is minimax optimal: it minimizes I( V ; Y ) among all channels with err or rate ε . When does the bound hav e slack? The following decompo- sition makes this precise. Proposition 3 (F ano slack decomposition) . Under the con- ditions of 1 , define E = 1 { Y = V } . Then: I( V ; Y ) = log M − h ( ε ) − ε log( M − 1) | {z } F ano lower bound + h ( ε ) − H( E | Y ) | {z } Jensen slac k ≥ 0 + ε · log( M − 1) − H( V | Y , E = 1) | {z } non-uniform confusion slack ≥ 0 . (3) The first slack term vanishes iff the err or rate is constant acr oss output values. The second vanishes if f, given an err or , all wr ong values ar e equally likely . Corollary 1 (F ano in v ersion) . Define Φ M ( ε ) := log M − h ( ε ) − ε log( M − 1) . Then I( V ; Y ) ≥ Φ M ( ε ) implies ε ≥ Φ − 1 M (I( V ; Y )) . Under the M -ary symmetric channel, this is an equality . 4.3. Pseudo-Priors and Decompression Bounds The Fano bounds connect error to used information. But how much information does the model need ? This depends on its baseline bias. A model with strong recenc y bias needs more evidence to o vercome that bias than an unbiased model would. W e formalize this via a causal intervention that removes the binding evidence. Definition 3 (Pseudo-prior) . Let E denote the binding evi- dence (e.g., “KEY1 = [apple]”). Define a null distrib ution by the intervention: ˜ W k ∼ do( E = ∅ ) , which removes E while preserving the template, candi- date set, and competing cues (e.g., recency). Let ˜ Y k be the model’ s decision under ˜ W k . The pseudo-prior is: ˜ p k := P ( ˜ Y k = V ) . 4 . 3 . 1 . O P E R AT I O N A L I Z I N G do( E = ∅ ) : S T RU C T U R E - P R E S E RV I N G E V I D E N C E A B L A T I O N The interv ention do( E = ∅ ) is a design pattern : remove the semantic support for a binding while preserving the structur e of the instance so that differences in behavior can be attributed to the missing evidence rather than to superficial prompt changes. Design goal (inv ariances of the null). Our null operator is chosen to preserv e: (i) the prompt template (role labels, span IDs, delimiters, formatting), (ii) the query and candidate set, and (iii)—as far as practical—length and locality statistics (so that “distance” and recency cues remain comparable). This answers the “empty string vs. noise vs. alternative binding” ambiguity: we target structure-pr eserving evidence ablation , not an arbitrary prompt corruption. Operator used in experiments. In binding experiments, we implement do( E = ∅ ) by removing the key–v alue content while keeping the ke y line and delimiters (e.g., re- placing KEY1 = [apple] with KEY1 = [REDACTED] ). In trace auditing ( C ), we implement do( E = ∅ ) as span scrub- bing : for a step citing spans S i , we replace the contents of those spans with a fixed placeholder (default [REDACTED] ) while preserving span labels and delimiters, and re-run the verifier on the scrubbed prompt to obtain p 0 ,i . What the pseudo-prior means (and why [REDACTED] is not “cheating”). W e emphasize that [REDACTED] is not distribution-neutral. It is an explicit marker for “e vidence remov ed. ” Accordingly , ˜ p should be interpreted as the mod- el/verifier’ s pr obability when e xplicitly denied access to that evidence , which is exactly the counterfactual required for budgeting. Empirically , this tends to be conservati v e: scrub- bing usually driv es p 0 downw ard (more UNSURE /abstain behavior), which increases the required bits-to-trust and therefore flags mor e , not fe wer , instances. Robustness via a null family (env elope certification). T o av oid ov er-committing to a single null implementation, we can define a small family of structure-preserving null oper- 4 Attention Deficits in Language Models ators N (e.g., delete-span, redact-span, same-length mask- ing), and compute a pseudo-prior interval p min 0 := min ν ∈N p ( ν ) 0 , p max 0 := max ν ∈N p ( ν ) 0 . For budget tests of the form KL(Ber( p 1 ) ∥ Ber( p 0 )) ≥ KL(Ber( τ ) ∥ Ber( p 0 )) , we then certify against the hardest null (worst-case o ver ν ∈ N ), i.e. require the inequality to hold for all ν ∈ N . This “env elope” move is directly analo- gous to the assumption-free, output-computable robustness layer used in compression-based ISR planners: we do not claim a single null is uniquely correct, we certify ag ainst a small, explicit family . The pseudo-prior measures how lik ely the model is to guess correctly without the critical evidence. If recency bias is strong and the correct answer appeared first, ˜ p k will be small. Theorem 2 (Bernoulli-projected decompression bound) . Let P and Q be distrib utions with P ( A ) = p and Q ( A ) = ˜ p for some event A . Then: KL( P ∥ Q ) ≥ KL(Ber( p ) ∥ Ber( ˜ p )) . Mor eover , for any ( p, ˜ p ) ther e e xists a pair ( P , Q ) achie ving equality . Corollary 2 (Bits-to-trust) . T o achie ve success pr oba- bility p fr om pseudo-prior ˜ p , the model needs at least KL(Ber( p ) ∥ Ber( ˜ p )) nats. Concrete example. Suppose recenc y bias giv es the correct answer a pseudo-prior of ˜ p = 0 . 05 . T o achiev e 90% accurac y , the model needs at least KL(Ber(0 . 9) ∥ Ber(0 . 05)) ≈ 2 . 25 nats ≈ 3 . 2 bits of evi- dence. This is the “bits-to-trust” cost of overcoming the bias. 4.4. Certifying “Present b ut Not Used” Estimating I av ail = I( V ; H k ) requires access to hidden states. But we can certify routing failure without a tight estimate. Proposition 4 (Certification via probing) . F or any pr obe f : I( V ; H k ) − I( V ; Y k ) ≥ I( V ; f ( H k )) − I( V ; Y k ) . If a linear probe achieves higher mutual information with V than the model’ s own output does, then the model is prov ably failing to use av ailable information. W e do not need to estimate I av ail exactly; we only need a probe that outperforms the model. 4.5. Distance Dependence Why do binding failures w orsen with distance? W e formal- ize this via strong data processing inequalities (SDPI). Definition 4 (SDPI coefficient) . For a channel K mapping distributions on X to distributions on X ′ : α ( K ) := sup P = Q KL( P K ∥ QK ) KL( P ∥ Q ) ∈ [0 , 1] . Theorem 3 (SDPI contraction) . F or a Markov c hain U → X → X ′ with channel K : I( U ; X ′ ) ≤ α ( K ) I( U ; X ) . F or a chain V → S 0 → S 1 → · · · → S k → H k : I( V ; H k ) ≤ k Y t =1 α ( K t ) I( V ; S 0 ) . Information decays geometrically with distance. This is not merely an upper bound; for “cop y-or-noise” channels, the decay is exact ( 5 in Appendix). Implication for checkpointing. Checkpointing injects fresh copies of the evidence, resetting the distance. This increases I av ail ( k ) and thus the attainable accuracy . 5. Empirical Results Our experiments test three predictions of the frame work: 1. Stage 2B errors (wrong candidate) should dominate ov er Stage 2A errors (no candidate) in binding tasks. 2. On Stage 2B error trials, probes should recov er the cor - rect answer at abov e-chance rates, certifying “present but not used. ” 3. Checkpointing should recov er accuracy by shortening the effecti v e evidence distance. W e also localize the failure mechanistically via activation patching. Full protocols appear in E . Models and tasks. For stage decomposition and prob- ing, we e v aluate Qwen2.5-3B (and Qwen2.5-3B-Instruct), Llama-3.2-3B, and Gemma-2-2b . F or checkpointing and scaling controls, we additionally e valuate Llama- 3.2-3B-Instruct and Gemma-2-2b-it. W e study C O M P E T - I N G _ V A R S and P R I M AC Y _ R E C E N C Y tasks with distances k ∈ { 256 , 512 , 1024 , 2048 } tokens. Sample sizes are n = 800 for stage decomposition and probing, n = 400 for baseline comparisons and checkpointing, and n ≈ 160 for patching (paired clean/corrupt runs). 5.1. Prediction 1: Stage 2B Dominates T able 1 sho ws the stage decomposition across models and tasks. In C O M P E T I N G _ V A R S , Stage 2B accounts for 65– 100% of errors depending on model and distance. The model enters answer mode but selects the wrong candidate. 5 Attention Deficits in Language Models Qwen2.5-3B\ncompeting vars Qwen2.5-3B\nprimacy r ecency Qwen2.5-3B-Inst.\ncompeting vars Qwen2.5-3B-Inst.\nprimacy r ecency Gemma-2-2b\ncompeting vars Gemma-2-2b\nprimacy r ecency Llama-3.2-3B\ncompeting vars Llama-3.2-3B\nprimacy r ecency 0.0 0.2 0.4 0.6 0.8 1.0 F raction of er r ors A . Er r or -stage decomposition Stage 2A (gating) Stage 2B (binding) 256 512 1024 D i s t a n c e k ( t o k e n s ) 0.0 0.2 0.4 0.6 0.8 1.0 A ccuracy (top tok en) B. Checkpointing r ecovers long-distance binding ( 9 5 % W i l s o n C I s o v e r n = 4 0 0 t r i a l s ) competing vars (baseline) competing vars (checkpoint) primacy r ecency (baseline) primacy r ecency (checkpoint) F igur e 2. Spotlight summary of core empirical claims. (A) Stage decomposition for representative hard-regime settings: most errors are Stage 2B (binding) rather than Stage 2A (gating), i.e., the model enters answer mode but selects the wrong candidate. (B) Checkpointing (restating the true binding every 128 tokens near the query) substantially recov ers long-distance binding for Qwen2.5-3B; on C O M P E T I N G _ V A R S at k = 1024 , it con verts 0/400 → 399/400 correct. Error bars are 95% W ilson binomial confidence intervals ov er n = 400 trials per cell. Baseline accuracy sho ws a robustness hierarchy: Gemma > Llama ≫ Qwen, with Qwen collapsing by k = 256 on both tasks and all models ev entually failing on P R I - M A C Y _ R E C E N C Y at suf ficient distance (Appendix T able 7 ). 5.2. Prediction 2: Probes Certify Inf ormation Presence On trials where the model outputs the wrong candidate (Stage 2B errors), we train a linear probe on the final-layer residual stream to predict the correct answer . T able 2 shows the results. At k = 256 in C O M P E T I N G _ V A R S , the final-layer probe achiev es 0.739 accuracy , which is 37 × above chance, e ven though the model output the wrong answer . This sho ws that the correct value remains decodable from the hidden state on error trials, supporting the “present but not used” hypothesis. W e can make the magnitude of this gap more concrete by con verting accuracies into the Fano expression in 1 (with |C | ≈ 50 ). In this regime, Cand-Acc = 0 . 255 implies I used ≳ 0 . 45 nats. For intuition, applying the same expres- sion to the final-layer probe’ s 0.739 accuracy on Stage 2B errors yields ≈ 2 . 32 nats; since this is conditioned on errors (and thus may change the entropy of V ), we treat it as an interpretable proxy rather than a formal bound (Appendix T able 12 ). 5.3. Mechanistic Localization: Activation Patching W e localize the routing failure using activ ation patching. For each layer and component (attention vs. MLP), we patch activ ations from a “clean” run (where the model w ould be correct) into a “corrupt” run (where it errs) and measure how much the correct answer’ s logit margin recovers. Across three model families, we observe a consistent mo- tif: late attention layers restore correct bindings, while late MLPs corrupt them (complete layer -component results in Appendix T able 10 ). W e also identify model-specific heads; notably , Gemma exhibits an “anti-recency” head that coun- terbalances a misbinding head (Appendix T able 6 ). 5.4. Prediction 3: Checkpointing Recovers Accuracy T o test whether failures reflect distance rather than inca- pacity , we introduce oracle checkpointing: restating bind- ings every 128 tokens. T able 3 shows dramatic recovery . T o guard against an alternati ve explanation (format repeti- tion rather than content-specific routing), our checkpointing suite also defines sham and wrong-checkpoint controls (Ap- pendix E.5 ); in this paper we report oracle checkpointing results. Qwen recov ers from 0% to 99.8% accuracy at k = 1024 . The one exception is Llama at k = 2048 on P R I - 6 Attention Deficits in Language Models Model T ask k Acc Cand Acc Frac 2A Frac 2B GateGap V alueGap Qwen2.5-3B C O M P E T I N G 256 0.107 0.158 0.350 0.650 0.56 -1.81 Qwen2.5-3B P R I M AC Y 256 0.043 0.045 0.185 0.815 0.96 -3.40 Qwen2.5-3B-Inst. C O M P E T I N G 256 0.276 0.360 0.402 0.598 0.61 -0.77 Qwen2.5-3B-Inst. P R I M A C Y 256 0.061 0.059 0.072 0.928 2.10 -3.96 Gemma-2-2B C O M P E T I N G 256 0.995 0.995 0.000 1.000 3.03 2.28 Gemma-2-2B P R I M AC Y 256 0.801 0.804 0.013 0.987 1.65 0.47 Llama-3.2-3B C O M P E T I N G 2048 0.385 0.369 0.018 0.982 2.01 -0.28 Llama-3.2-3B P R I M AC Y 2048 0.001 0.014 0.461 0.539 -0.08 -5.14 T able 1. Stage decomposition ( n = 800 , greedy next-token decoding; bracket prompt style; decoy_heavy filler; |C | ≈ 50 single-token candidates). Acc is P ( ˆ Y = V ) (top token), Cand-Acc is P ( Y = V ) (best candidate). Frac-2A/Frac-2B are fractions of errors (conditional on ˆ Y = V ), decomposing errors into gating (non-candidate output) vs. binding (wrong candidate) failures. For Llama we report k = 2048 to reach comparable dif ficulty . T ask k Acc Cand Acc Frac 2B Probe@0 Probe@18 Probe@35 C O M P E T I N G 256 0.200 0.255 0.641 0.019 0.083 0.739 C O M P E T I N G 512 0.000 0.000 0.968 0.008 0.029 0.390 P R I M AC Y 256 0.069 0.074 0.754 0.020 0.040 0.354 P R I M AC Y 512 0.000 0.000 0.994 0.020 0.020 0.124 T able 2. Probing on Stage 2B errors (Qwen2.5-3B, n = 800 ; bracket prompt style; decoy_heavy filler; |C | ≈ 50 ). Frac-2B is a fraction of err ors (conditional on ˆ Y = V ) attrib utable to Stage 2B binding f ailures. Layers 0/18/35 are embedding, mid, and final residual streams. Chance is ≈ 2%. At k = 256 , the final-layer probe recovers the correct answer on 74% of error trials. M A C Y _ R E C E N C Y , where checkpointing fails (0% → 0.3%). Inspection re veals that Stage 2A gating has collapsed: the model no longer enters answer mode. This confirms the stagewise picture: Stage 2B failures are distance-limited and recov erable; Stage 2A failures at extreme distance are a distinct breakdown. Naturalistic binding at 8B–9B scale. W e also e valu- ate an option-randomized notes_binding task at 8B–9B scale. Checkpointing partially recovers Meta-Llama-3.1-8B- Instruct at long distance and yields near-perfect performance for Gemma-2-9b-it (Appendix T able 9 ). Extension: audited reasoning traces. W e e xtend pseudo- priors to chain-of-thought auditing by scrubbing cited ev- idence and comparing required vs. observed information budgets; details and full results are in Appendix C . T oolkit and repr oducibility . An anonymized repro- ducibility package (scripts + cached outputs) is included in the supplemental material and is sufficient to regener - ate the reported tables and Figure 2 ; see Appendix D for commands and en vironment notes. 6. Discussion Procedural versus factual hallucination. Our results suggest that many structured-generation failures are not about missing kno wledge b ut about mis-commitment . The model encodes the correct answer (probes recover it) but routes its output tow ard a biased competitor . This is qual- itativ ely different from factual hallucination and requires different interv entions. Why the theory giv es more than necessary conditions. Our theory uses standard information-theoretic tools, but aims to make them actionable for diagnosing LLM failures. Fano’ s inequality is a necessary condition: low information implies high error . Propositions 2 and 3 characterize when this necessary condition is close to sufficient (error rates near the minimax channel) and provide a measurable slack decomposition. The Bernoulli decompression bound ( 2 ) is a tight specialization that yields closed-form “bits-to-trust” costs. Mitigation strategies. Our results point to two lev ers. First, incr ease availability : checkpointing, retriev al, and shorter contexts all increase I av ail . Second, increase r outing efficiency : the patching results suggest that late MLPs are a bottleneck. Gemma’ s anti-recency head shows that architec- tural solutions exist; whether they can be trained or induced 7 Attention Deficits in Language Models Model T ask k Baseline +Checkpoint Qwen2.5-3B C O M P E T I N G 1024 0.000 0.998 Qwen2.5-3B P R I M AC Y 1024 0.000 0.763 Llama-3.2-3B-Inst. C O M P E T I N G 2048 0.000 0.853 Llama-3.2-3B-Inst. P R I M A C Y 1024 0.003 0.915 Gemma-2-2B-it P R I M AC Y 1024 0.440 0.968 T able 3. Checkpointing summary ( n = 400 ; greedy next-tok en decoding; bracket prompt style; decoy_heavy filler; |C | ≈ 50 ). Oracle checkpointing inserts a compact serialization of the true binding e very 128 tok ens in the tail filler , and can c onv ert near-zero accuracy into near-perfect accuracy at long distance; see Appendix T able 8 for full results. T asks are C O M P E T I N G _ V A R S ( C O M P E T I N G ) and P R I M AC Y _ R E C E N C Y ( P R I M AC Y ). is an open question. 7. Limitations Our mechanistic claims (probing, patching) require acti- vation access and thus apply directly only to open-weight models. For hosted APIs, we provide output-le v el and trace- lev el diagnostics but cannot estimate I av ail (and hence η ) without acti vations; in this paper we therefore emphasize bounds and certificates deriv ed from error rates and probes. T race auditing detects certificate failures, that is, claims that lack suf ficient e vidential support, but does not prov e faithful- ness to the model’ s hidden chain-of-thought. A model could produce a valid-looking trace via post-hoc rationalization. Our experiments focus on synthetic binding tasks designed to isolate the phenomena. Whether the same mechanisms explain failures in naturalistic long-conte xt tasks (e.g., doc- ument QA) remains to be validated. 8. Broader Impact and Ethics Potential positive impacts. Procedural hallucinations can undermine trust in systems that rely on long-context reason- ing and tool-augmented generation. By decomposing fail- ures into interpretable readout stages and providing concrete diagnostics, this work may help practitioners (i) detect when a model “kno ws but does not use” needed information, (ii) design mitigations such as checkpointing or answer -gating, and (iii) audit reasoning traces for unsupported claims. Potential negati ve impacts and misuse. Diagnostic tools for model beha vior can potentially be repurposed to find brit- tle points or to craft adversarial prompts that exploit model biases. W e mitigate this by releasing no new model weights and by focusing on synthetic tasks and analysis code; users should apply the toolkit responsibly and in accordance with the underlying model and API terms of use. Privacy and human subjects. Our experiments use syn- thetic prompts and do not in v olve human subjects or per- sonal data. When using the optional API-based trace- auditing components, practitioners should avoid sending sensitiv e data to third-party services unless permitted and appropriate. 9. Conclusion W e hav e presented a rigorous framew ork for understand- ing procedural hallucinations: failures where the model possesses information but does not use it. The frame- work decomposes errors into gating (Stage 2A) and bind- ing (Stage 2B) failures, formalizes “present but not used” via information-theoretic routing ef ficiency , provides tight bounds connecting error rates to information b udgets, and extends to auditing reasoning traces. Empirically , Stage 2B errors dominate in binding tasks. Probes certify that correct information is encoded on error trials. Activ ation patching localizes failures to late MLPs. Checkpointing can substantially recover long-distance bind- ing by shortening the evidence path. An anonymized toolkit and reproducibility package are in- cluded in the supplemental material, and we plan to release them publicly upon acceptance. 8 Attention Deficits in Language Models References Belghazi, M. I., Baratin, A., Rajeshwar , S., Ozair , S., Ben- gio, Y ., Courville, A., and Hjelm, R. D. Mutual infor- mation neural estimation. In Pr oceedings of the 35th International Confer ence on Machine Learning , 2018. Conmy , A., Mavor -Park er , A., L ynch, A., et al. T owards au- tomated circuit discovery for mechanistic interpretability . In Advances in Neural Information Pr ocessing Systems , 2023. Cov er , T . M. and Thomas, J. A. Elements of Information Theory . W iley , 2 edition, 2006. Elhage, N., Nanda, N., Olsson, C., et al. A mathematical framew ork for transformer circuits. T ransformer Circuits Thread, 2021. Ji, Z., Lee, N., Frieske, R., Y u, T ., Su, D., et al. Survey of hallucination in natural language generation. ACM Computing Surve ys , 55(12), 2023. Liu, N. F ., Lin, K., He witt, J., et al. Lost in the middle: How language models use long conte xts. T ransactions of the Association for Computational Linguistics , 2024. Lu, T ., Gao, M., Y u, K., Byerly , A., and Khashabi, D. In- sights into llm long-context failures: When transformers know but don’ t tell. In F indings of the Association for Computational Linguistics: EMNLP , 2024. Maynez, J., Narayan, S., Bohnet, B., and McDonald, R. On faithfulness and f actuality in abstractiv e summariza- tion. In Pr oceedings of the 58th Annual Meeting of the Association for Computational Linguistics , 2020. Meng, K., Bau, D., Andonian, A., and Belinkov , Y . Locating and editing factual associations in gpt. In Advances in Neural Information Pr ocessing Systems , 2022. T ishby , N., Pereira, F . C., and Bialek, W . The information bottleneck method. In Pr oceedings of the 37th Annual Allerton Confer ence on Communication, Contr ol, and Computing , 1999. W ang, K., V ariengien, A., Conmy , A., Shlegeris, B., and Steinhardt, J. Interpretability in the wild: a circuit for in- direct object identification in gpt-2 small. In International Confer ence on Learning Repr esentations , 2023. W u, W ., W ang, Y ., Xiao, G., Peng, H., and Fu, Y . Retriev al head mechanistically explains long-conte xt factuality . In International Confer ence on Learning Repr esentations , 2025. 9 Attention Deficits in Language Models A. Strawberry Counting Analysis Prompt: “How many r’ s are in ‘strawberry’?” The correct word-le vel statistic is W = 3 . For long traces, the final readout misbinds to competing statistics: WORD (intended), TO T AL (total count in the full trace), or SUFFIX (a recent suf fix window). Empirically , baseline misbinds for k > 10 : at k = 20 the final output is 6 (TO T AL), and at k = 30 it is 8 (SUFFIX); larger k yields TO T AL. A binding intervention that forces the final to match the word-le v el statistic returns final = 3 for all tested k with perfect trace fidelity (character match and run-count consistenc y both 1.00). B. Proofs B.1. Proof of 1 Pr oof. Since Y k is a function of H k , we hav e the Markov chain V → H k → Y k . By data processing, I( V ; Y k ) ≤ I( V ; H k ) . Nonnegati vity of mutual information yields 0 ≤ η k ≤ 1 . B.2. Proof of 1 and 2 Pr oof sketc h. For uniform V on C , H ( V ) = log M . Fano’ s inequality gi ves H ( V | Y ) ≤ h ( ε ) + ε log( M − 1) . Therefore I( V ; Y ) = H ( V ) − H ( V | Y ) ≥ log M − h ( ε ) − ε log( M − 1) . T ightness: the M -ary symmetric channel has P ( Y = V ) = 1 − ε and P ( Y = y = V ) = ε/ ( M − 1) . For this channel, H ( V | Y ) attains the Fano upper bound. Minimax optimality follows because the symmetric channel maximizes H ( V | Y ) giv en ε . B.3. Proof of 3 Pr oof. Let E = 1 { Y = V } . Since E is deterministic gi ven ( V , Y ) , we hav e H( E | V , Y ) = 0 . By chain rule: H( V | Y ) = H( E , V | Y ) − H( E | V , Y ) = H( E | Y ) + H( V | Y , E ) . Since H( V | Y , E = 0) = 0 (when correct, V = Y ), we have H( V | Y , E ) = ε H( V | Y , E = 1) . Thus: H( V | Y ) = H( E | Y ) + ε H( V | Y , E = 1) . Using I( V ; Y ) = log M − H( V | Y ) and adding/subtracting Fano bounds yields ( 3 ) . Nonnegati vity: H( E | Y ) ≤ h ( ε ) by Jensen; H( V | Y , E = 1) ≤ log ( M − 1) by support size. B.4. Proof of 3 Pr oof. Express mutual information as average KL: I( U ; X ) = E u KL( P ( X | U = u ) ∥ P ( X )) . Since X 7→ X ′ is channel K : P ( X ′ | U = u ) = P ( X | U = u ) K and P ( X ′ ) = P ( X ) K . By definition of α ( K ) : KL( P ( X ′ | U = u ) ∥ P ( X ′ )) ≤ α ( K ) KL( P ( X | U = u ) ∥ P ( X )) . A veraging yields I( U ; X ′ ) ≤ α ( K )I( U ; X ) . Chain bound follo ws by iteration. B.5. Proof of 2 Pr oof sketc h. Let f ( ω ) = 1 { ω ∈ A } . By data processing for KL: KL( P ∥ Q ) ≥ KL( P ◦ f − 1 ∥ Q ◦ f − 1 ) = KL(Ber( p ) ∥ Ber( ˜ p )) . T ightness: choose P as the I-projection of Q onto { P : P ( A ) = p } . B.6. Proof of 4 Pr oof. By data processing, I( V ; f ( H k )) ≤ I( V ; H k ) . Subtracting I( V ; Y k ) yields the result. 10 Attention Deficits in Language Models Setting k Acc(%) Pass(%) Acc(pass)(%) Acc(flag)(%) Lift(pp) Mistral-7B (baseline) 1024 98.3 54.8 100.0 97.0 3.0 Mistral-7B (baseline) 2048 87.0 68.6 99.5 63.7 35.8 T able 4. Trace-b udget audit ( τ = 0 . 75 ). At lar ge distance, errors concentrate in flagged traces. V ariant n Pass(%) Acc(pass)(%) Acc(flag)(%) Lift(pp) E [ p 1 ] E [ p NE 0 ] baseline 369 21.1 83.3 61.5 21.8 0.398 0.036 rag 378 25.1 81.1 60.4 20.6 0.428 0.039 checkpoint 383 24.0 82.6 59.5 23.2 0.430 0.037 T able 5. QuALITY audit with null-family env elope certification ( τ = 0 . 75 , Llama-3.1-8B-Instruct). Pass means the b udget test holds for all null operators ν ∈ N (redact, delete, same-length mask, and no-evidence). E [ p NE 0 ] reports the no-evidence pseudo-prior . Proposition 5 (Exact contraction for copy-or -noise) . F or the copy-or-noise channel with par ameter α (copies input with pr obability α , else outputs noise fr om ν ): I( U ; X ′ ) = α I( U ; X ) . Pr oof. Let B ∼ Ber( α ) be independent of ( U, X ) and Z ∼ ν be independent noise. Since B is independent of U : I( U ; X ′ ) = I( U ; X ′ | B ) = α I( U ; X ′ | B = 1) + (1 − α ) I( U ; X ′ | B = 0) . When B = 0 , X ′ = Z independent of U , so I( U ; X ′ | B = 0) = 0 . When B = 1 , X ′ = X , so I( U ; X ′ | B = 1) = I( U ; X ) . C. A udited Reasoning T races W e extend the framew ork to reasoning traces. The model produces a chain-of-thought, and we audit whether each step is supported by the evidence it cites. C.1. T race Format W e prompt the model to produce a structured trace T = { ( c i , S i , o i ) } T i =1 where c i is an atomic claim, S i is a set of cited span identifiers, and o i is an optional confidence. A separate verifier labels each step as ENTAILED , CONTRADICTED , NOT_IN_CONTEXT , or UNVERIFIABLE . An ex ecutor then deriv es the answer using only verified steps. C.2. T race-Level Pseudo-Priors For each step i , we define a pseudo-prior by scrubbing its cited spans: ˜ W ( i ) := do( spans in S i := [REDACTED] ) . Let p 0 ,i be the verifier’ s probability that step i is entailed under ˜ W ( i ) , and p 1 ,i be the probability under the full context. W e define: ReqBits i := KL(Ber( o i ) ∥ Ber( p 0 ,i )) , ObsBits i := KL(Ber( p 1 ,i ) ∥ Ber( p 0 ,i )) . If ObsBits i < ReqBits i , the step is under -budget : the cited e vidence does not justify the claimed confidence. C.3. Empirical V alidation On synthetic binding tasks (Mistral-7B-Instruct, k ∈ { 1024 , 2048 } , n = 300 ), the audit isolates errors effecti vely . At k = 2048 , the pass subset achieves 99.5% accurac y while the flagged subset drops to 63.7% (T able 4 ). On QuALITY reading comprehension, we use an e vidence-only verifier (since correct answers often require inference rather than literal entailment). T able 5 sho ws that passing the audit is strongly predicti ve of correctness: 81–83% accuracy for pass vs. 59–62% for flagged. Additional QuALITY robustness sweeps across τ and null operators appear in E.7 . 11 Attention Deficits in Language Models D. T oolkit and Reproducibility Reproducibility package (anonymized). This submission includes an anon ymized reproducibility package containing: (i) experiment scripts under experiments/ (see also experiments/results_manifest.md ), (ii) the cached CSV/JSON out- puts used to populate the reported tables, and (iii) a small plotting script ( experiments/spotlight_make_figures.py , requires matplotlib ) that regenerates Figure 2 from cached outputs. Core Python dependencies are listed in experiments/requirements.txt . W e plan to release a public repository upon acceptance. T oolkit. W e include a toolkit that implements the diagnostics described in this paper for any API model e xposing token logprobs. The toolkit provides four capabilities. First, Stage 2A/2B scoring : giv en a prompt and candidate set, compute gate margin, value mar gin, and stage classification from the model’ s next-token logprobs. Second, structured trace generation : prompt the model to produce a JSON-formatted trace with span citations, using schema-constrained decoding. Third, trace verification : run a separate verifier model on each claim-span pair and compute p 0 (scrubbed) and p 1 (full context) from logprobs. Fourth, budget computation : calculate ReqBits and ObsBits for each trace step and flag under-b udget claims. W e additionally include a robustness suite implementing option-randomized long-conte xt binding (including k = 0 controls and checkpointing) and output-only routing certificates. LLM usage in the toolkit. The trace-auditing extension uses a separate verifier model queried via API logprobs (our implementation supports OpenAI’ s API, including gpt-4o-mini , and can be e xtended to other pro viders). The core binding experiments and mechanistic analyses in this paper use open-weight models locally; the y do not require API models. Existing assets and licenses/terms. W e e v aluate released model weights under their respective terms of use: Qwen2.5 mod- els under the Qwen Research license ( https://huggingface.co/Qwen/Qwen2.5- 3B/blob/main/LICENSE ); Llama 3.2 models under the Llama 3.2 Community License ( https://huggingface.co/meta- llama/Llama- 3.2- 3B/blob/ main/LICENSE.txt ) and associated use policy ( https://huggingface.co/meta- llama/Llama- 3.2- 3B/blob/ main/USE_POLICY.md ); and Gemma 2 models under Google’ s Gemma terms ( https://ai.google.dev/gemma/ terms ). Example repr oduction commands. T o regenerate Figure 2 from cached outputs: python experiments/spotlight_make_figures.py T o rerun a representative stage-decomposition slice (Prediction 1; Qwen2.5-3B, k = 256 , n = 800 per task): torchrun --nproc_per_node 1 experiments/prediction1_stage2b/stage2b_multimodel_suite.py \ --models Qwen/Qwen2.5-3B \ --tasks competing_vars primacy_recency \ --k_values 256 \ --filler_types decoy_heavy \ --trials_per_condition 800 \ --batch_size 1 \ --decoy_reps 12 \ --n_distractors 48 \ --dtype bf16 \ --attn_impl sdpa \ --outdir repro_out/stage2b \ --out_csv stage2b_summary.csv \ --out_json stage2b_summary.json T o rerun the checkpointing sweep used in Figure 2 B (Prediction 3; Qwen2.5-3B, n = 400 per cell): torchrun --nproc_per_node 1 experiments/prediction3_checkpointing/checkpoint_mitigation_suite.py \ --models Qwen/Qwen2.5-3B \ --tasks competing_vars primacy_recency \ --k_values 256 512 1024 \ --filler_types decoy_heavy \ --trials_per_k 400 \ --batch_size 1 \ 12 Attention Deficits in Language Models --checkpoint_every 128 \ --checkpoint_mode oracle \ --dtype bf16 \ --attn_impl sdpa \ --out_csv repro_out/checkpointing.csv \ --out_json repro_out/checkpointing.json T o rerun the mechanistic localization sweep (activation patching; Qwen2.5-3B, k = 256 ): python experiments/mechanistic_localization/mech_stage2b_circuit_suite.py \ --model Qwen/Qwen2.5-3B \ --task competing_vars \ --k 256 \ --prompt_style bracket \ --clean_filler random \ --corrupt_filler decoy_heavy \ --decoy_reps 12 \ --n_pairs 40 \ --layers last8 \ --top_layers 2 \ --top_heads 12 \ --dtype bf16 \ --attn_impl sdpa \ --outdir repro_out/mech E. Experimental Protocols and Additional Results E.1. Experimental Protocols Candidate sets and tokenization. All binding tasks in this paper are single-token classification problems: the correct value V is a single v ocabulary token. For each model, we build a model-specific candidate pool by filtering a fixed list of short English words (fruits/Greek letters/colors/etc.) to those that tok enize to exactly one non-special tok en under that model’ s tokenizer (preferring leading-space forms when applicable), yielding |C | ≈ 50 candidates. W e use a bracket prompt style ( KEY=[ · ] ) to make the answer boundary explicit. In scripts where a string-based prompt is used, we include an extra delimiter (whitespace or a bracket separator) to av oid tokenizer-dependent merges at the value boundary; in token-ID–constructed prompts, v alues are inserted as standalone token IDs. Unless otherwise stated, each example’ s candidate set contains the target, its main competitor(s), and 48 additional distractors sampled from the candidate pool, so |C | ≈ 50 and chance accuracy is ≈ 2% . Filler regimes. W e v ary the distance k by inserting k filler tokens between evidence and query . W e use four filler re gimes: repeat (repeat a single filler token), coherent (repeat a short natural-language paragraph), random (sample random non-special tokens), and decoy_heavy (mostly filler , but insert the competitor token decoy_reps times at uniformly spaced positions, plus light random sprinkling). Unless otherwise stated, main-te xt stage decomposition and probing results use decoy_heavy with decoy_reps =12 to induce Stage 2B errors. Seeds and candidate pools. Candidate pools and distractor choices are seeded and thus can differ slightly across experiment suites; all reported results use fix ed seeds and maintain |C | ≈ 50 . T asks and variants. In addition to C O M P E T I N G _ V A R S and P R I M AC Y _ R E C E N C Y (defined in 3 ), we use D E - C OY _ I N J E C T I O N , where a single key is assigned once to a target value but the filler contains many repetitions of a decoy competitor token; this isolates competition from frequenc y alone. For completeness, the code also includes strawberry- style binding tasks (Appendix A ) and a f actorized prompt v ariant that reduces misbinding by e xplicitly separating competing statistics. Decoding and stage metrics. W e ev aluate greedy ne xt-token decoding at the readout position. W e compute Acc as P ( ˆ Y = V ) (top-vocab ulary token), Cand-Acc as P ( Y = V ) (best candidate token), GateGap as (max v ∈C z ( v )) − (max x / ∈C z ( x )) , and V alueGap as z ( V ) − max v ∈C\{ V } z ( v ) . Stage 2A vs. Stage 2B are defined by whether the model’ s top token ˆ Y is outside vs. inside C on error trials. 13 Attention Deficits in Language Models Head Mean patch restoration Mean ablation ∆ margin n L25H2 (misbinding/interference) 0.169 +0.508 159 L22H3 (counterbalances recency) 0.121 -0.321 159 T able 6. Gemma-2-2b-it head-lev el patching/ablation on P R I M A C Y _ R E C E N C Y ( k = 256 ; brack et prompt style; clean filler random ; corrupt filler decoy_heavy with decoy_reps =12). Patch restoration is normalized mar gin recovery; ablation ∆ margin is m ablated − m corrupt (positiv e means ablating the head helps correct-vs-competitor margin; ne gativ e means ablation hurts). Uncertainty (confidence intervals). For headline accuracies, we report 95% W ilson binomial confidence interv als ov er the n independent prompt instances in each cell (e.g., Figure 2 uses n = 400 ). These CIs reflect instance-to-instance variability under the stated prompt generator and fix ed seeds; they do not capture v ariability from retraining or changing model checkpoints. Compute and resour ces. All reported experiments are inference-only on released models (no training or fine-tuning of foundation models). As a hardware-agnostic proxy , we report the number of e valuated prompts and the maximum distance k . Reference configuration for reproduction is a single NVIDIA A100 40GB (e.g., Colab A100) with batch_size=1 as in the Appendix commands; wall-clock time depends on hardware and scales approximately linearly with the number of e v aluated prompts. The Stage 2B suite cached in experiments/prediction1_stage2b/ ev aluates 48,000 prompts total (60 condi- tions × n = 800 ) with k up to 2048. The checkpointing suites cached in experiments/prediction3_checkpointing/ ev aluate 9,600 prompts total across Qwen and Gemma (12 e valuated conditions × n = 400 per model: 2 tasks × 3 k value s × {baseline, checkpoint}), with k up to 1024. Mechanistic patching uses paired clean/corrupt prompts (typically n ≈ 160 pairs per model/setting; see Appendix tables). The provided scripts run on NVIDIA GPUs via PyT orch/ torchrun ; the mechanistic revie w-pack scripts are designed to be runnable on a Colab A100-class GPU (see script headers). Probing . For probe results, we train a linear softmax probe on hidden states at the readout position to predict the tar get token ID. For each (task, k , filler) condition we collect n trials, split them 50/50 into train/test, train for 100 full-batch gradient steps with L 2 regularization, and report test accuracy specifically on Stage 2B error trials (and on correct trials as a sanity check). Activation patching . For mechanistic localization, we build paired clean/corrupt prompts that share the same key/v alue tokens and positions and dif fer only in the filler distrib ution (clean: random ; corrupt: decoy_heavy with the competitor injected). W e patch clean acti vations into the corrupt run and measure restoration of the target-vs-competitor logit margin at the readout position. At the layer-component le vel, we patch either (i) the concatenated attention-head output v ector (the input to o_proj ) or (ii) the MLP output v ector . At the head le vel, we patch or ablate indi vidual head slices at the o_proj input. E.2. Head-Level Causal Analysis: Gemma “Anti-Recency” Head T able 6 provides a concrete example of a model-specific head-lev el motif in Gemma-2-2b-it on P R I M A C Y _ R E C E N C Y at k = 256 . W e find a head whose ablation impr oves the target-vs-competitor margin (a misbinding/interference head) and a head whose ablation hurts the margin (a counterbalancing head that resists recency), moti v ating the informal term “anti-recency . ” E.3. Baseline Accuracy E.4. Checkpointing (Full Results) E.5. Checkpointing Controls Checkpointing could in principle help by repeating formatting cues rather than by injecting the correct content. T o separate these explanations, our checkpointing suite defines two simple controls: sham checkpointing , which inserts an irrelev ant b ut similarly formatted checkpoint statement, and wrong checkpointing , which inserts a checkpoint that states the competitor/decoy v alue. Under a content-specific routing interpretation, we would expect sham checkpointing to provide little benefit, while wrong checkpointing should systematically steer the output toward the wrong value. The experiment script supports these conditions via –checkpoint_mode {oracle,sham,wrong} ; in this paper we report 14 Attention Deficits in Language Models T ask k Qwen2.5-3B Llama-3.2-3B-Inst. Gemma-2-2b-it competing_vars 256 0.203 0.993 1.000 512 0.008 0.993 1.000 1024 0.000 0.455 0.998 2048 — 0.000 — primacy_recenc y 256 0.060 0.868 0.963 512 0.003 0.553 0.798 1024 0.000 0.003 0.440 2048 — 0.000 — T able 7. Baseline accuracy ( n = 400 ; greedy next-token decoding; bracket prompt style; decoy_heavy filler; |C | ≈ 50 single-token candidates). All models e ventually fail on P R I M AC Y _ R E C E N C Y at sufficient distance. Model T ask k Baseline +Checkpoint ∆ Acc V alueGap base V alueGap chk Qwen2.5-3B competing_vars 256 0.203 0.973 +0.770 -1.02 +2.81 competing_vars 512 0.008 0.993 +0.985 -5.75 +2.61 competing_vars 1024 0.000 0.998 +0.998 -9.93 +2.88 primacy_recenc y 256 0.060 0.760 +0.700 -2.88 +0.80 primacy_recenc y 512 0.003 0.573 +0.570 -6.53 +0.26 primacy_recenc y 1024 0.000 0.763 +0.763 -9.05 +1.01 Llama-3.2-3B-Inst. competing_vars 256 0.993 0.998 +0.005 +8.89 +9.20 competing_vars 1024 0.455 0.998 +0.543 +0.03 +8.96 competing_vars 2048 0.000 0.853 +0.853 -3.78 +1.44 primacy_recenc y 256 0.868 0.995 +0.127 +1.81 +3.48 primacy_recenc y 512 0.553 0.973 +0.420 +0.16 +2.95 primacy_recenc y 1024 0.003 0.915 +0.912 -4.30 +1.64 primacy_recenc y 2048 0.000 0.003 +0.003 -4.02 -1.35 Gemma-2-2b-it competing_vars 256 1.000 1.000 0.000 +8.82 +7.98 competing_vars 512 1.000 1.000 0.000 +7.72 +8.10 competing_vars 1024 0.998 1.000 +0.003 +6.55 +7.71 primacy_recenc y 256 0.963 0.993 +0.030 +2.74 +3.80 primacy_recenc y 512 0.798 0.963 +0.165 +1.37 +2.36 primacy_recenc y 1024 0.440 0.968 +0.528 -0.62 +2.70 T able 8. Checkpointing results ( n = 400 ; greedy ne xt-token decoding; bracket prompt style; decoy_heavy filler; |C | ≈ 50 ). Checkpoints insert a compact serialization of the true binding ev ery 128 tokens in the tail filler . Qwen recov ers from 0% to 99.8% at k = 1024 . Exception: Llama at k = 2048 on P R I M AC Y _ R E C E N C Y shows checkpoint failure, as Stage 2A gating has collapsed and cannot be recov ered by re-statement. oracle checkpointing results. E.6. Naturalistic notes_binding at 8B–9B Scale E.7. QuALITY Robustness T able 13 shows robustness of the null-family en velope evidence-only audit across reliability targets τ ∈ { 0 . 65 , 0 . 70 , 0 . 75 , 0 . 80 } . 15 Attention Deficits in Language Models Meta-Llama-3.1-8B-Instruct Gemma-2-9b-it k Acc (base) P [ Z ] (base) Acc (+Chk) Acc (base) P [ Z ] (base) Acc (+Chk) 0 0.435 0.185 0.510 0.330 0.490 1.000 64 0.575 0.130 0.590 0.415 0.300 1.000 256 0.550 0.155 0.550 0.640 0.150 0.995 1024 0.435 0.105 0.580 0.740 0.015 1.000 2048 0.430 0.055 0.600 0.820 0.000 1.000 T able 9. Naturalistic notes_binding at 8B–9B scale with randomized choice ordering ( n = 200 per cell). P [ Z ] is the abstention rate (Stage 2A failure). Llama degrades at long distance and is partially recov ered by checkpointing; Gemma is near-perfect under checkpointing and exhibits a lar ge reduction in abstention as k increases. Qwen2.5-3B-Instruct Llama-3.2-3B-Instruct Gemma-2-2b-it L C Rest ∆ M L C Rest ∆ M L C Rest ∆ M 28 attn -0.03 -0.50 20 attn -0.04 0.04 18 attn 0.02 -0.41 28 mlp 0.03 0.59 20 mlp 0.04 0.03 18 mlp 0.01 0.17 29 attn 0.06 1.02 21 attn 0.23 0.06 19 attn 0.10 0.12 29 mlp -0.01 -0.24 21 mlp -0.04 0.00 19 mlp -0.03 -0.05 30 attn -0.04 -0.71 22 attn -0.03 0.09 20 attn -0.01 0.02 30 mlp 0.07 1.34 22 mlp 0.01 0.01 20 mlp -0.01 0.01 31 attn -0.01 -0.19 23 attn -0.03 -0.15 21 attn -0.09 -0.55 31 mlp 0.08 1.45 23 mlp 0.07 0.14 21 mlp 0.00 0.21 32 attn 0.11 2.09 24 attn 0.02 -0.04 22 attn 0.31 0.40 32 mlp 0.05 0.81 24 mlp 0.05 0.05 22 mlp -0.01 0.02 33 attn 0.18 3.44 25 attn 0.10 0.23 23 attn 0.03 0.03 33 mlp -0.04 -0.81 25 mlp -0.10 -0.19 23 mlp -0.16 0.07 34 attn 0.01 0.21 26 attn 0.21 0.24 24 attn -0.01 0.04 34 mlp -0.11 -1.99 26 mlp -0.01 -0.22 24 mlp 0.02 0.10 35 attn 0.01 0.10 27 attn 0.19 0.20 25 attn 0.36 0.98 35 mlp -0.20 -3.30 27 mlp 0.07 0.18 25 mlp -0.19 -0.47 T able 10. Complete layer-component patching results (paired clean/corrupt prompts; greedy next-token decoding; brack et prompt style; k = 256 ; clean filler random ; corrupt filler decoy_heavy with decoy_reps =12; n ≈ 160 Stage 2B pairs per model). Rest is mean normalized restoration ( m patched − m corrupt ) / ( m clean − m corrupt ) of the tar get-vs-competitor logit mar gin m ; ∆ M is the mean change in margin ( m patched − m corrupt ) . Qwen uses C O M P E T I N G _ V A R S ; Llama/Gemma use P R I M AC Y _ R E C E N C Y . T ask Filler k Acc Cand-Acc Frac-2A Frac-2B GateGap V alueGap competing_vars decoy_heavy 128 0.999 0.999 0.000 1.000 3.74 5.12 competing_vars decoy_heavy 256 0.107 0.158 0.350 0.650 0.56 -1.81 competing_vars decoy_heavy 512 0.003 0.001 0.023 0.977 1.99 -7.26 competing_vars decoy_heavy 1024 0.000 0.000 0.033 0.968 1.79 -10.10 competing_vars repeat 128 0.030 0.080 0.570 0.430 -0.07 -3.39 competing_vars repeat 256 0.026 0.069 0.792 0.208 -0.80 -4.33 competing_vars repeat 512 0.000 0.094 0.988 0.013 -2.97 -3.46 competing_vars repeat 1024 0.000 0.249 1.000 0.000 -7.76 -1.83 decoy_injection decoy_heavy 128 0.979 0.994 0.824 0.176 3.23 7.14 decoy_injection decoy_heavy 256 0.240 0.907 0.993 0.007 -1.17 2.41 decoy_injection decoy_heavy 512 0.000 0.294 1.000 0.000 -6.92 -1.24 decoy_injection decoy_heavy 1024 0.000 0.149 1.000 0.000 -8.09 -2.57 decoy_injection repeat 128 0.065 0.996 1.000 0.000 -2.03 5.03 decoy_injection repeat 256 0.000 0.779 1.000 0.000 -6.98 1.51 decoy_injection repeat 512 0.000 0.292 1.000 0.000 -9.58 -1.09 decoy_injection repeat 1024 0.000 0.295 1.000 0.000 -10.53 -1.33 primacy_recency decoy_heavy 128 0.734 0.755 0.146 0.854 1.68 0.64 primacy_recency decoy_heavy 256 0.043 0.045 0.185 0.815 0.96 -3.40 primacy_recency decoy_heavy 512 0.000 0.000 0.005 0.995 2.55 -7.77 primacy_recency decoy_heavy 1024 0.000 0.000 0.049 0.951 1.31 -8.14 primacy_recency repeat 128 0.036 0.046 0.370 0.630 0.33 -3.69 primacy_recency repeat 256 0.020 0.046 0.807 0.193 -0.62 -3.86 primacy_recency repeat 512 0.000 0.142 1.000 0.000 -3.42 -2.47 primacy_recency repeat 1024 0.000 0.139 1.000 0.000 -7.06 -2.48 T able 11. Complete Stage 2A/2B results for Qwen2.5-3B ( n = 800 per row; greedy ne xt-token decoding; bracket prompt style; |C | ≈ 50 single-token candidates). Acc is P ( ˆ Y = V ) (top token), Cand-Acc is P ( Y = V ) (best candidate). Frac-2A/Frac-2B are fractions of errors (conditional on ˆ Y = V ). 16 Attention Deficits in Language Models T ask k Cand-Acc I used ≥ Probe@35 (Stage 2B err) I proxy probe , err competing_vars 256 0.255 0.45 0.739 2.32 competing_vars 512 0.000 0.00 0.390 0.87 primacy_recenc y 256 0.074 0.04 0.354 0.75 primacy_recenc y 512 0.000 0.00 0.124 0.13 T able 12. Conv erting accuracies into mutual-information quantities using the Fano expression Φ M ( ε ) from 1 with M = 50 (candidate set size ≈ 50 ; nats). For the model’ s candidate decision (Cand-Acc; unconditional, with V uniform by construction), Φ M is a v alid lower bound on I used . For the final-layer probe accuracy restricted to Stage 2B error trials, we report the same quantity as an interpr etable pr oxy (conditioning can change H ( V ) , so the lo wer-bound interpretation need not hold). For finite-sample cells with Cand-Acc < 1 / M we clamp the bound to 0. τ V ariant Pass(%) Acc(pass)(%) Acc(flag)(%) Lift(pp) 0.65 baseline 24.7 83.5 60.4 23.1 0.65 checkpoint 27.4 81.0 59.0 22.0 0.65 rag 28.6 79.6 60.0 19.6 0.70 baseline 22.5 84.3 60.8 23.5 0.70 checkpoint 25.3 82.5 59.1 23.4 0.70 rag 26.2 81.8 59.9 22.0 0.75 baseline 21.1 83.3 61.5 21.8 0.75 checkpoint 24.0 82.6 59.5 23.2 0.75 rag 25.1 81.1 60.4 20.6 0.80 baseline 15.7 87.9 62.1 25.9 0.80 checkpoint 20.1 83.1 60.5 22.7 0.80 rag 21.2 86.2 60.1 26.2 T able 13. Robustness of the QuALITY null-family env elope audit across reliability targets τ . Passing is consistently associated with substantially higher answer accuracy . Null operator V ariant Pass(%) Acc(pass)(%) Acc(flag)(%) Lift(pp) no-evidence baseline 22.8 79.8 62.1 17.7 no-evidence checkpoint 25.1 81.2 59.6 21.7 no-evidence rag 26.5 79.0 60.8 18.2 redact-span baseline 27.4 81.2 60.4 20.7 redact-span checkpoint 30.8 78.8 58.9 19.9 redact-span rag 31.2 80.5 58.8 21.7 delete-span baseline 29.3 82.4 59.4 23.0 delete-span checkpoint 31.6 77.7 59.2 18.5 delete-span rag 33.1 80.0 58.5 21.5 mask-same-len baseline 26.0 84.4 59.7 24.7 mask-same-len checkpoint 31.1 80.7 58.0 22.7 mask-same-len rag 30.4 80.9 58.9 21.9 en velope (all) baseline 21.1 83.3 61.5 21.8 en velope (all) checkpoint 24.0 82.6 59.5 23.2 en velope (all) rag 25.1 81.1 60.4 20.6 T able 14. Sensitivity of QuALITY audit to the concrete pseudo-prior operator at τ = 0 . 75 . “En velope” requires the b udget test to pass for all null operators; it provides a conserv ativ e, assumption-light certificate while retaining strong predictiv e lift. k n Pass(%) E [ p 1 ] E [ p min 0 , p max 0 ] 512 200 66.0 0.756 [0.179, 0.272] 1024 200 0.0 0.728 [0.097, 0.184] 2048 200 100.0 0.841 [0.181, 0.361] T able 15. Null-family statistics for a synthetic binding audit ( τ = 0 . 75 ). Although p 0 varies across null operators, the pass/fail decision is in variant across the null f amily in this setting (en velope equals any single-null decision). 17
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment