절차적 환각을 일으키는 주의력 결함
대형 언어 모델이 긴 컨텍스트에서 계산한 값을 마지막 단계에서 잘못 보고하는 현상을 “절차적 환각”이라 정의하고, 이를 두 단계(게이트 단계와 바인딩 단계)로 분해한다. 실험을 통해 어려운 상황에서는 바인딩 단계 오류가 대부분을 차지함을 확인하고, 최종 레이어 잔차 스트림에 정답 정보가 존재함에도 출력에 활용되지 않음을 선형 탐지기로 증명한다. 정보‑이론적 프레임워크와 가짜 사전(pseudo‑prior) 개입을 도입해 “존재하지만 사용되지 않음…
저자: Ahmed Karim, Fatima Sheaib, Zein Khamis
본 논문은 대형 언어 모델(LLM)이 복잡한 절차를 수행하면서도 마지막 단계에서 자신이 계산한 값을 잘못 보고하는 현상을 “절차적 환각(procedural hallucination)”이라 명명한다. 이는 모델이 프롬프트 내부에 존재하는 정답 정보를 충분히 인코딩했음에도 출력 단계에서 이를 활용하지 못하는 ‘정보 라우팅 실패’로 정의된다.
**문제 정의와 단계적 분해**
절차적 환각은 프롬프트 W와 후보 집합 C가 주어졌을 때, 명시적 함수 g(W) ∈ C가 존재함에도 모델의 출력 ˆY ≠ g(W)인 경우로 정의한다. 저자는 이를 두 단계로 나눈다.
- **Stage 2A (게이트 단계)**: 모델이 답변 모드에 진입했는지 판단한다. 로그잇 차이 GateGap = max_{v∈C} z(v) − max_{x∉C} z(x) 로 측정한다. GateGap > 0이면 후보 토큰 중 하나를 선택하고, < 0이면 전혀 다른 토큰(구두점, 회피 문구 등)을 출력한다.
- **Stage 2B (바인딩 단계)**: 모델이 정답 후보를 정확히 선택했는지 평가한다. ValueGap = z(V) − max_{v∈C\{V}} z(v) 로 정의한다. 양수이면 올바른 바인딩, 음수이면 잘못된 바인딩이다.
**실험 설계**
저자는 ‘키‑값 바인딩’ 작업을 설계해, 키와 값이 여러 번 등장하고 긴 filler 토큰(k = 20~1024) 사이에 섞이도록 만든다. 후보 집합은 단일 토큰 문자열로 제한해 정답을 명확히 검증할 수 있게 했다. 또한 자연어 기반 변형인 notes_binding을 추가해 실제 텍스트에서도 동일 현상이 나타나는지 확인한다.
**주요 발견**
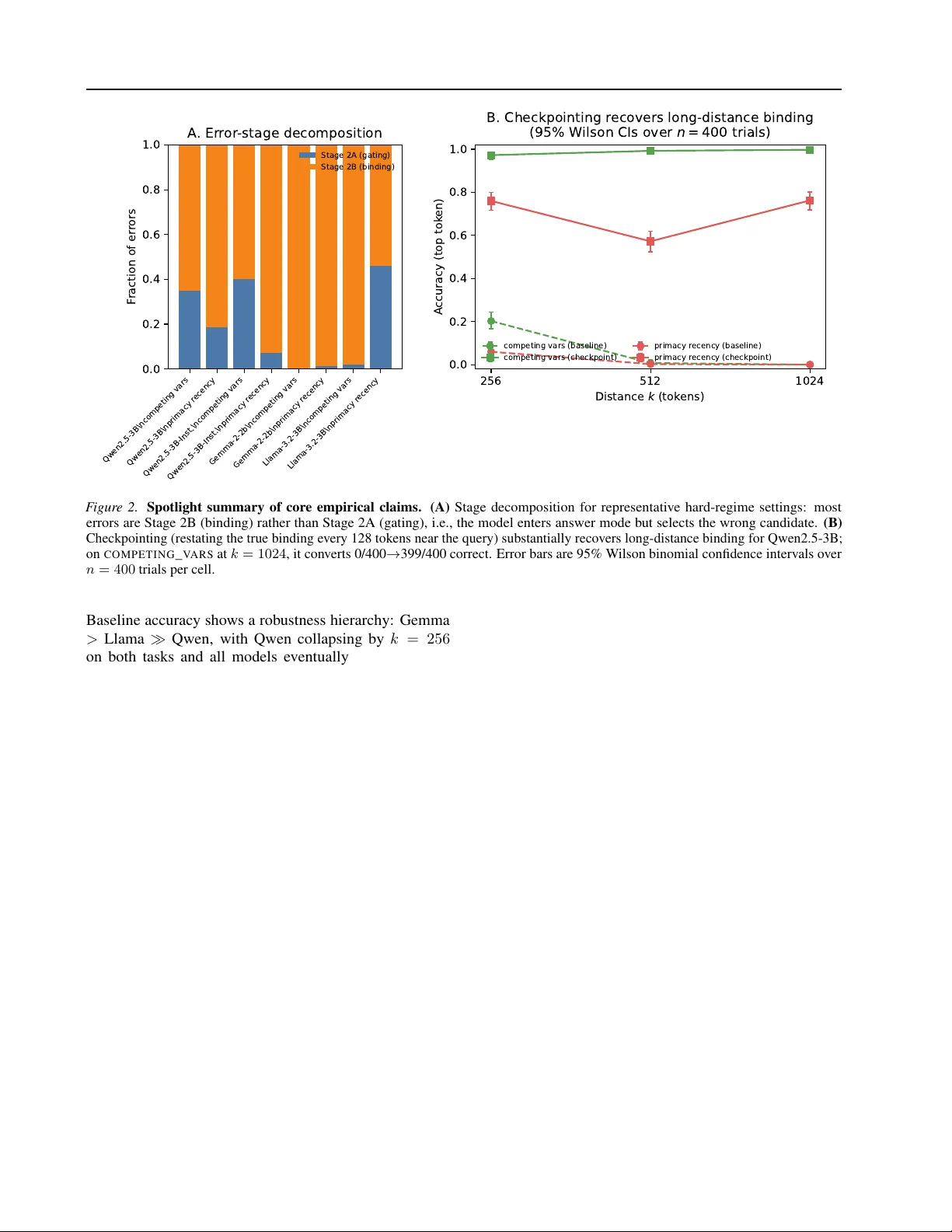
1. **Stage 2B 오류가 주를 이룸**: 어려운 거리(k ≥ 512)에서는 전체 오류의 80 % 이상이 Stage 2B 바인딩 오류이며, Stage 2A 게이트 오류는 상대적으로 드물다(표 1). 이는 모델이 질문을 인식하고 후보 집합 내 토큰을 선택하려 하지만, 오래된 정보보다 최근에 등장한 잘못된 값에 더 크게 편향된다는 것을 의미한다.
2. **정답 정보는 내부에 존재**: Stage 2B 오류가 발생한 샘플에 대해 최종 레이어 잔차 스트림(H_k)에 선형 탐지기(probe)를 학습하면 정답 토큰을 70 %~74 % 정확도로 복원한다(예: Qwen2.5‑3B, 표 2). 이는 I_avail = I(V; H_k)가 크게 남아있지만 I_used = I(V; Y_k)가 매우 작아 라우팅 효율 η ≪ 1임을 보여준다.
3. **정보‑이론적 프레임워크**: I_avail와 I_used를 정의하고, 라우팅 효율 η = I_used/I_avail 로 측정한다. Fano 불평등을 이용해 오류율 ε와 I_used 사이의 하한 관계를 도출하고, ε가 클수록 I_used이 작아진다는 정량적 연결고리를 제공한다(정리 1, 명제 2, 3). 또한, ‘가짜 사전(pseudo‑prior)’ 개념을 도입해 증거를 제거한 프롬프트(예:
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기