Face Presentation Attack Detection via Content-Adaptive Spatial Operators
Face presentation attack detection (FacePAD) is critical for securing facial authentication against print, replay, and mask-based spoofing. This paper proposes CASO-PAD, an RGB-only, single-frame model that enhances MobileNetV3 with content-adaptive …
Authors: Shujaat Khan
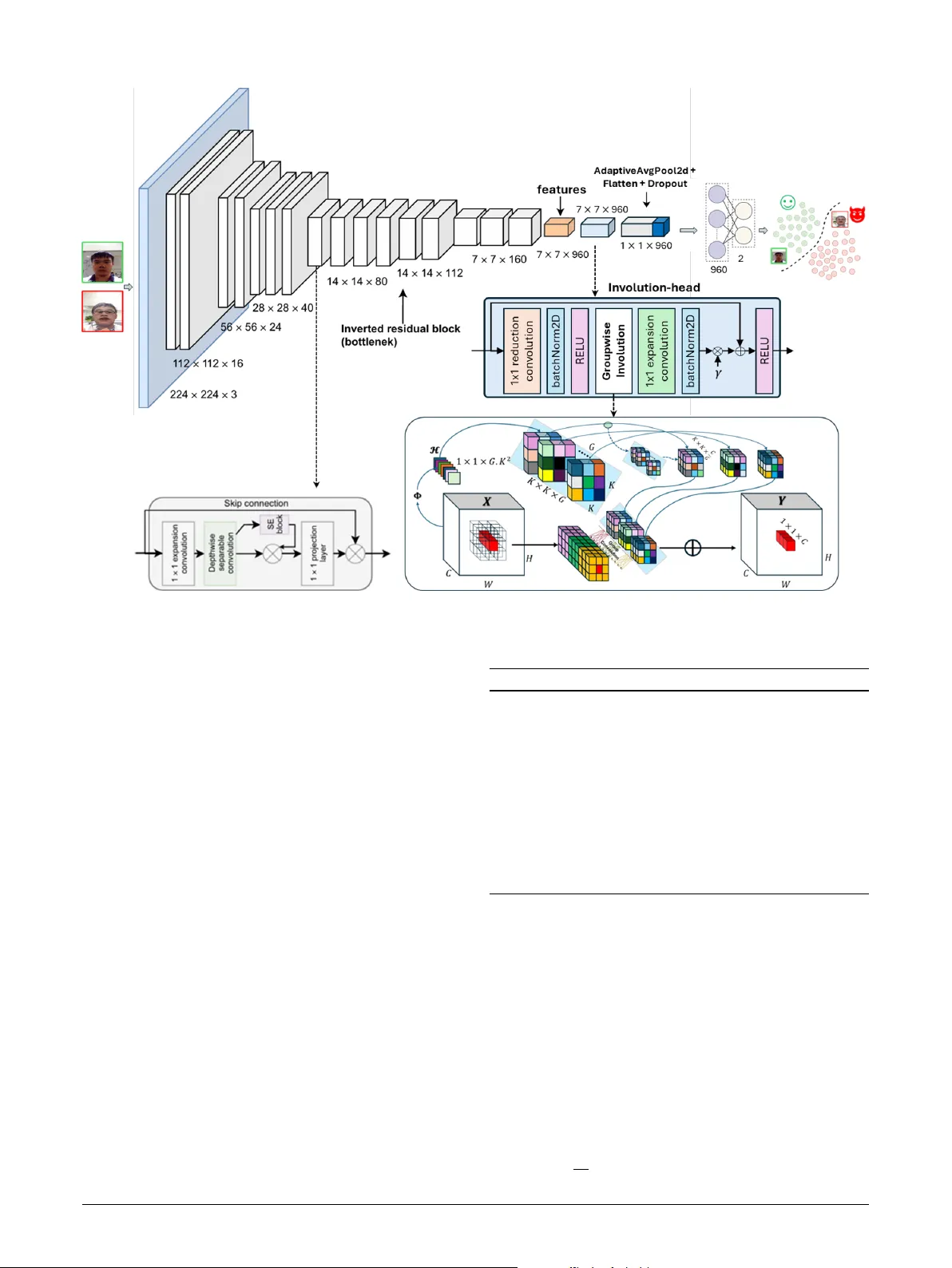
Face Presentation Attac k Detection via Content- A daptiv e Spatial Operators Shujaat Khan a,b , ∗ a Department of Computer Engineering, Colleg e of Computing and Mathematics, King F ahd Univ ersity of P etr oleum & Minerals, Dhahran, 31261, Saudi Arabia b SDAIA–KFUPM Joint Researc h Center for Ar tificial Intelligence, King F ahd Univer sity of P etr oleum & Minerals, Dhahr an, 31261, Saudi Arabia A R T I C L E I N F O Keyw ords : Face presentation attack detection Face anti-spoofing Inv olution Content-A daptive Spatial Operator A B S T R A C T Face presentation attack detection (FaceP AD) is critical for securing facial authentication against print, replay , and mask-based spoofing. This paper proposes CASO-P AD, an RGB-onl y , single- frame model that enhances MobileNetV3 with content-adaptive spatial operators (in volution) to better capture localized spoof cues. Unlik e spatially shared conv olution kernels, the proposed operator generates location-specific, channel-shared kernels conditioned on the input, improving spatial selectivity with minimal ov erhead. CASO-P AD remains lightweight (3.6M parameters; 0.64 GFLOPs at 256 × 256 ) and is trained end-to-end using a standard binary cross-entropy objectiv e. Extensive experiments on Replay- Attack, Repla y-Mobile, ROSE- Y outu, and OULU-NPU demonstrate strong performance, achieving 100/100/98.9/99.7% test accuracy, AUC of 1.00/1.00/0.9995/0.9999, and HTER of 0.00/0.00/0.82/0.44%, respectiv ely . On t he larg e-scale SiW-Mv2 Protocol-1 benchmark, CASO-P AD furt her att ains 95.45% accuracy with 3.11% HTER and 3.13% EER, indicating improv ed robustness under diverse real-world attacks. Ablation studies show that placing the adaptive operator near the network head and using moderate group shar ing yields the best accuracy–efficiency balance. Overall, CASO-P AD provides a practical pathway for robust, on-device FaceP AD with mobile-class compute and without auxiliary sensors or temporal stacks. 1. Introduction Facial recognition is now integ ral to mobile pa yments, surveillance, border control, and personal device aut henti- cation. Its appeal lies in being non-intrusive and accurate, pow ering applications such as smartphone unlocking [ 1 ], mobile pa yments [ 2 ], sur veillance sy stems [ 3 ], access con- trol [ 4 ], and attendance monitoring [ 5 ]. Lev eraging larg e datasets and high-per formance computing, moder n recog- nition systems hav e surpassed 99% accuracy [ 6 ]. Y et, this very sensitivity to facial data intr oduces vulnerabilities to spoofing att acks, where adv ersaries use counter f eit inputs such as pr inted photos, displa y repla ys, or 3D masks [ 7 ]. As adoption expands into sensitiv e domains like finance and healthcare, the need f or reliable anti-spoofing solutions has become paramount. FaceP AD systems aim to distinguish genuine ( bonafide ) inputs from spoof attempts, ensur ing the security of facial recognition technologies [ 8 ]. Applications extend beyond traditional security to e-commerce, mobile device aut hen- tication, and remote access and t he demand for robust and deployment-friendly P AD methods has nev er been g reater [ 9 ]. Earl y approaches to FaceP AD relied on handcrafted f eatures such as SIFT [ 10 ], SURF [ 11 ], and HOG [ 12 ], often combined with SVMs or LDA classifiers. T exture- and motion-based cues, including eye blinks and lip motion, also pro ved useful [ 13 , 14 ]. Ho we ver , these techniques str uggled ∗ Corresponding author shujaat.khan@kfupm.edu.sa (S. Khan) OR CI D (s): under variable lighting, backgrounds, and camera qualities, limiting their real-w orld applicability . Bey ond basic photo or video replay s, adversaries now employ sophisticated techniques, including high-fidelity 3D masks, adversarial per turbations, and machine learning- driven attacks [ 15 , 16 ] and the arms race between attack ers and FaceP AD continues. Although data augmentation and unified frame wor ks such as UniF AD [ 17 ] ha ve been pro- posed, they often require larg e-scale datasets and remain limited to specific attack scenar ios, especially under chal- lenging white-box conditions. Compounding the difficulty , no benc hmark dataset can encompass the diversity of possi- ble attack types [ 18 ]. T o address data scarcity , generativ e models such as GANs hav e been explored for synthesizing spoofing samples [ 19 , 20 ]. Recent works demonstrate that adversarial train- ing with synthetic data can improv e P AD robustness [ 21 ], though challenges of model scalability and efficiency re- main. Deep learning, par ticularly Con volutional Neural Net- w orks (CNNs), has since transf or med FaceP AD by captur ing subtle, discriminative f eatures. CNN-based models per f or m well but often their high computational cost hinders real- time use in resource-limited environments such as mobile devices. T o deal with the challenges of FaceP AD, we propose a content-adaptive framew ork for resource-constrained envi- ronments. The proposed netw ork utilizes a computationall y efficient backbone architecture specifically designed for edge devices [ 22 ]. The major contr ibutions of t he proposed S. Khan: Preprint submitted to Elsevier Page 1 of 14 CASO P AD system lie in its cont ent-adaptive spatial oper ators mech- anism, whic h fuses feature extraction with no vel g roup- wise inv olution [ 23 ] signal processing to detect input- specific, fine-grained spoofing cues effectiv ely . U nlike fixed depthwise filters, the proposed approach generates location- specific, channel-shared ker nels conditioned on t he input, thereby enhancing spatial adaptivity and improving discrim- ination of spoof artifacts. The contributions of t his w ork are as f ollow s: • A R GB single-frame FaceP AD model, CASO-P AD, that augments MobileNetV3 [ 22 ] wit h content-adaptive in volution [ 23 ] la yers at selected stages f or enhanced spoof detection. • A detailed audit of lear ned kernels and their interpre- tation f or model e xplainability . • A streamlined training setup with ablations ov er model architectures, kernel size, placement strategy , image size, and group sharing f or efficient learning. • Comprehensiv e evaluation on Repla y- Attac k [ 24 ], Repla y-Mobile [ 25 ], OUL U-NPU [ 26 ], ROSE- Y outu [ 27 ], and SiW -Mv2 [ 28 ] datasets using standard met- rics (e.g., Accuracy , AUC, EER, HTER, APCER, BPCER, and ACER, etc), showing s trong HTER – efficiency trade-offs ag ainst baselines. The remainder of this paper is str uctured as follo ws: Section 2 re view s e xisting FaceP AD methods and their lim- itations. Section 3 det ails the proposed framew ork. Section 4 discusses findings and compar isons, while Section 5 and 6 present t he kernel audit and detailed ablation studies respectiv ely . Finally Section 7 concludes the study . 2. Related W ork FaceP AD has attracted substantial interest, producing a broad tax onomy of methods: (i) spatial/appear ance tech- niques that analyze frame-lev el texture and color cues; (ii) tempor al approac hes that e xploit motion and dynamics; and (iii) multimodal methods that incor porate auxiliar y signals such as Remote pho toplethysmograph y (rPPG), depth, ther - mal, or infrared. Recent work also explores adversarial ro- bustness and domain generalization. Below , we synt hesize these directions and highlight gaps motiv ating an efficient, R GB-only solution. 2.1. Spatial/Appearance Methods Classical handcrafted featur es. Early P AD relied on handcrafted descriptors to capture fine-grained te xtural dif- f erences betw een bonafide and spoof images. Common choices include Local Binary Patterns (LBP) [ 29 ], His- tograms of Oriented Gradients (HOG) [ 12 ], and SIFT [ 10 ]. Määttä et al. [ 30 ] used LBP to expose pr int-induced ar tifacts, while other works explored color spaces (e.g., HSV , Y CbCr) and frequency cues to better separate spoof patterns from genuine skin reflectance [ 31 , 32 , 33 ]. Although these meth- ods are effective against simple photo attacks, they degrade under varied illuminations, cameras, and high-quality 3D mask or repla y attacks [ 34 ]. Deep learning and hybr id models. CNN-based FaceP AD superseded handcrafted approac hes by lear ning discr im- inative f eatures end-to-end. R epresent ativ e adv ances in- clude two-stream or attention mechanisms ov er R GB and illumination-in variant spaces, pixel-lev el supervision f or local spoof cues [ 15 ], and f eature fusion with learned or autoencoder -der ived representations [ 35 ]. Additional strands in vestig ate adv ersar ial robus tness [ 36 ], one-class client- specific modeling [ 37 ], domain adaptation/generalization [ 38 , 39 ], and diffusion-aided h ybr ids [ 40 ]. Hybr id methods deliberately combine handcrafted te xture with CNNs or integrate classical f eatures to improv e cross-dataset general- ization [ 41 ]. While t hese designs of ten boost accuracy , many are computationally expensiv e and less suit able for real-time deployment on edge de vices. 2.2. T emporal and Motion-Based Methods T emporal inf ormation helps re veal inconsistencies c har- acteristic of repla y and mask attacks. Classic works used optical flo w or mo tion patterns [ 42 ] and e ye-blink analy- sis via undirected conditional random fields (CRFs) [ 13 ]. With deep lear ning, CNN-RNN hybrids (e.g., CNN+LSTM) capture spatiotemporal dependencies, while deep dynamic textures and flow -guided models fur ther enhance temporal sensitivity [ 43 ]. More recent efforts compress or summar ize clip dynamics t hrough temporal sequence sampling and stack ed recur rent encoders [ 44 , 45 ]. Despite strong accuracy , these approaches are slo w in nature due to high latency and can also be parameter - and compute-intensiv e, limiting use on mobile hardw are. 2.3. Multimodal Signals: rPPG, Depth, and Infrared The rPPG lev erages subtle color chang es induced by blood flow as a liveness pr ior . Methods range from cor re- spondence features and noise-aw are templates to transf or mer - based encoders [ 46 , 47 , 48 ]. rPPG can separate bonafide from spoof ed content and has been applied to 3D mask scenarios [ 49 ], but it is sensitive to illumination, mo tion, and video quality , often req uir ing longer capture window s [ 50 , 51 ]. Be yond rPPG, multispectral and infrared imaging capture non-visible cues and temperature or mater ial dif- f erences [ 52 , 53 ]. These systems are pow er ful but typically demand specialized hardw are, limiting scalability in low - cost deplo yments. 2.4. Summary and Motivation Classical texture and motion pipelines are fast but fragile under domain shif ts and sophisticated spoofs [ 34 ]. Deep models substantially improv e accuracy , yet many require hea vy bac kbones, auxiliary sensors, or complex training that impedes real-time use [ 40 ]. Multimodal signals (rPPG, S. Khan: Preprint submitted to Elsevier P age 2 of 14 CASO P AD T able 1 Overview of the b enchmark datasets used for evaluation. Dataset Release Y ear Pa rticipants Authentic / Attack Samples Replay-A ttack [ 24 ] 2012 50 300 / 1000 Replay-Mobile [ 25 ] 2016 40 550 / 640 OULU-NPU [ 26 ] 2017 55 990 / 3,960 ROSE-Y outu [ 27 ] 2018 20 1000 / 2350 SiW-Mv2 [ 28 ] 2022 600 785 / 915 depth, ther mal/IR) enhance robus tness but demand con- trolled capture conditions or specialized hardware [ 49 , 52 , 53 ]. Temporal encoders strengthen repla y/mask detection [ 43 , 44 , 45 ], but LSTM/transf ormer stacks are of ten parameter - intensive for phones and embedded devices. These trade-offs motivate efficient, RGB-onl y models that retain strong discr iminative po wer while meeting edge constraints. Lightweight backbones such as MobileNetV2/V3 and ShuffleNet achie ve fa v orable accuracy–efficiency via depthwise separable conv olutions and attention; how ev er, their spatiall y shared ker nels can under-captur e localized spoof artifacts. To address this, involution [ 23 ] replaces channel-specific, spatially shared kernels with spatially specific, channel-shar ed kernels produced by a lightweight generator , enabling content-adaptive filter ing with low over - head. 3. Proposed Me thod This section outlines t he datasets employ ed in t his study , the per f or mance ev aluation criter ia, the architecture of the proposed netw ork, and t he adopted training protocol. 3.1. Datasets T o assess the robustness and generalization capabil- ity of the proposed approach, fiv e well-established face anti-spoofing datasets are used: R eplay -A ttack [ 24 ], Repla y- Mobile [ 25 ], OULU-NPU [ 26 ], ROSE- Y outu [ 27 ], and SiW - Mv2 [ 28 ]. A concise summary of their characteristics is pro vided in T able 1 . Figure 1: Sample frames from authentic and sp o ofed videos in (a) RA, (b) RM, (c) OULU-NPU, (d) RY, and (e) SiW-Mv2 datasets. Genuine samples app ear in the top ro w, while the b ottom row sho ws different attack types. 3.1.1. Replay-Attack The Repla y- Attack dataset [ 24 ] comprises 1,300 video sequences encompassing both genuine and attack scenar - ios (including photos and video replay s). The data were collected from 50 individuals under both controlled and variable illumination using different cameras. The dataset is partitioned into disjoint training, dev elopment, and testing subsets, ensuring that no subject appears in more t han one split. Figure 1 (a) presents illustrativ e frames from genuine and spoof ed sequences. 3.1.2. Replay-Mobile The Repla y-Mobile dataset [ 25 ] was curated to ev alu- ate mobile-based face recognition and presentation attack detection systems. It consists of 1,190 video samples from 40 participants, captured in diverse lighting settings using smartphone cameras. The attacks include both pr inted photo and digital replay types. Example genuine and spoof frames are sho wn in Figure 1 (b). 3.1.3. OULU-NPU The OUL U-NPU [ 26 ] dat aset consists of 4 , 950 video samples collected from 55 subjects using six mobile devices (HTC Desire Eye, ASUS Zenfone Selfie, Oppo N3, Meizu MX5, Son y Xperia C5 Ultra Dual, and Samsung Galaxy S6 Edge). The data were acquired across t hree sessions under varying background scenes and illumination conditions. Pre- sentation attacks were g enerated using two pr int and tw o displa y devices. The dataset is par titioned subject-disjointl y into training and testing sets with 20 subjects each, while the remaining 15 subjects are reserved f or validation. Example genuine and spoof frames are sho wn in Figure 1 (c), 3.1.4. ROSE- Y outu The R OSE- Y outu dat aset [ 27 ] includes 3,350 videos from 20 subjects, recorded under multiple illumination con- ditions and using different camera models. It contains t hree distinct spoof types: video replay , pr inted photo, and paper mask att acks. As illustrated in Figure 1 (d), this dataset poses a considerable challeng e for FaceP AD research due to its diverse acquisition conditions and attac k modalities. 3.1.5. Spoofing in the Wild (SiW-Mv2) Dataset SiW -Mv2 [ 28 ] is a lar ge-scale FaceP AD benchmark de- signed t o ev aluate robustness under a wide variety of spoof- ing scenarios, comprising 14 different presentation attack categories. The dataset includes 915 spoof videos collected from 600 subjects, along with 785 bona fide recordings from 493 individuals. The attack set co v ers div erse and challenging conditions such as replay-based attacks, par tial manipulation of f acial regions (e.g., e ye-onl y spoofs), sil- icone mask presentations, and paper -based ar tifacts. Rep- resentative sample frames from SiW -Mv2 are illustrated in Figure 1 (e). 3.2. Pre-processing In this work, the pre-processing stage inv olv es a center- cropping strategy designed to retain the natural aspect ratio of each frame while av oiding geometric distortion dur ing resizing. For both the training and testing phases, the same procedure is applied to ensure consistency . The adaptiv e cropping operation f ollow s the steps below : • Determine the smaller dimension 𝜌 between the frame height ( 𝑀 ) and width ( 𝑁 ) . S. Khan: Preprint submitted to Elsevier P age 3 of 14 CASO P AD • Extract a centered square region of size ( 𝜌 × 𝜌 ) from the original frame. Figure 2 illustrates the adaptive center -cropping proce- dure implemented in this study , which ser ves as the f ounda- tion f or subsequent dat a augmentation and normalization. Figure 2: Illustration of the adaptive center-cropping process used in the pre-p ro cessing pip eline. This op eration ensures consistent framing and preserves the o riginal asp ect ratio across all samples. 3.3. Proposed Netw ork Arc hitecture In CNNs, a conv olution la yer typically apply a single spatial k er nel unif ormly across the f eature map. This entails tw o well-kno wn constraints: 1. Spatially agnostic kernels: the same filter is reused at ev er y location, limiting sensitivity to local te xture, scale, and s tr ucture. 2. Fix ed cross-channel coupling: channel interactions are prescribed by t he lear ned 𝐶 ′ × 𝐶 ker nel and remain independent of spatial context. Bef ore contrasting alternative operators, w e fix notation and the receptiv e-field con vention used t hroughout. Notation. Let 𝑋 ∈ ℝ 𝐻 × 𝑊 × 𝐶 denote the input, 𝑌 ∈ ℝ 𝐻 × 𝑊 × 𝐶 ′ the output, and let Ω = {( 𝑢, 𝑣 ) ∶ | 𝑢 | ≤ ⌊ 𝑘 ∕2 ⌋ , | 𝑣 | ≤ ⌊ 𝑘 ∕2 ⌋ } be the 𝑘 × 𝑘 receptive field. With t his notation, the con v entional con volution la yer can be written as: 3.3.1. Standard Convolution 𝑌 ( 𝑖, 𝑗 , 𝑐 𝑜 ) = 𝐶 ∑ 𝑐 𝑖 =1 ∑ ( 𝑢,𝑣 )∈Ω 𝐾 ( 𝑐 𝑜 , 𝑐 𝑖 , 𝑢, 𝑣 ) 𝑋 ( 𝑖 + 𝑢, 𝑗 + 𝑣, 𝑐 𝑖 ) , (1) where a single k er nel 𝐾 is shared across all spatial positions ( 𝑖, 𝑗 ) . While standard conv olution mix es all channels ev er y- where, many efficient bac kbones restr ict cross-channel mix- ing to subsets to reduce cost. This yields group (and in the extreme, depthwise) conv olution: 3.3.2. Group Conv olution Partition channels into 𝐺 disjoint groups of size 𝑆 = 𝐶 ∕ 𝐺 . Mixing occurs onl y within the same group: 𝑌 ( 𝑖, 𝑗 , 𝑐 𝑜 ) = ∑ 𝑐 𝑖 ∈ ( 𝑐 𝑜 ) ∑ ( 𝑢,𝑣 )∈Ω 𝐾 𝑔 ( 𝑐 𝑜 , 𝑐 𝑖 , 𝑢, 𝑣 ) 𝑋 ( 𝑖 + 𝑢, 𝑗 + 𝑣, 𝑐 𝑖 ) , (2) where 𝑔 = 𝑔 ( 𝑐 𝑜 ) ∈ {1 , … , 𝐺 } index es the group of 𝑐 𝑜 and ( 𝑐 𝑜 ) is its input-channel set. Standard con volution is 𝐺 =1 ; depthwise con volution cor responds to 𝐺 = 𝐶 . Both of the abov e still reuse the same spatial ker nel at ev - ery location, which dilutes sensitivity to position-dependent artifacts typical in FaceP AD (e.g., specular highlights or print borders). T o address this, w e adopt a location-adaptiv e operator . 3.3.3. Inv olution (location-adaptive, channel-shared) In volution [ 23 ] replaces a spatially invariant kernel with location-specific kernels 𝐻 ( 𝑖, 𝑗 , 𝑢, 𝑣 ) that are shared across channels: 𝑌 ( 𝑖, 𝑗 , 𝑐 ) = ∑ ( 𝑢,𝑣 )∈Ω 𝐻 ( 𝑖, 𝑗 , 𝑢, 𝑣 ) 𝑋 ( 𝑖 + 𝑢, 𝑗 + 𝑣, 𝑐 ) , (3) where 𝐻 is generated on-the-fly from features (e.g., via a compact kernel-generator network). In volution preserves the low compute of depthwise/grouped designs while allowing the spatial ker nel to vary across ( 𝑖, 𝑗 ) , a property we will exploit in our content-adaptive head. 3.3.4. Proposed Group in volution (GI) Building on the advantages of in volution, w e introduce an adaptiv e group in v olution (GI). The proposed operator is gr oup-wise and location-adaptiv e . For 𝐺 groups, where one spatial kernel per group and location is generated; t hat kernel is shar ed across c hannels within the group and applied depthwise (no c hannel mixing in the spatial op): 𝑌 ( 𝑖, 𝑗 , 𝑐 ) = ∑ ( 𝑢,𝑣 )∈Ω 𝐻 ( 𝑖, 𝑗 , 𝑔 ( 𝑐 ) , 𝑢, 𝑣 ) 𝑋 ( 𝑖 + 𝑢, 𝑗 + 𝑣, 𝑐 ) , (4) where 𝑔 ( 𝑐 ) ∈ {1 , … , 𝐺 } maps c hannel 𝑐 to its g roup. Cross-channel interaction is provided by surrounding 1×1 pointwise la yers (squeeze/expand), while t he spatial opera- tor itself remains g roup-shared and content-adaptive. Remar ks. • Special cases: 𝐺 = 𝐶 reduces to depthwise in v olu- tion [ 23 ] (one kernel per channel); 𝐺 =1 reduces to channel-shared inv olution[ 23 ]. • Efficiency: the spatial application in ( 4 ) scales as ( 𝐶 𝑘 2 𝐻 𝑊 ) , while t he kernel-generator cost scales with group count 𝐺 and the reduction ratio in the 1×1 bottleneck; both are lightweight compared to full 𝐶 × 𝐶 ′ con volution. The proposed GI pro vides a flexible trade-off between expressivity and efficiency by (i) adapting kernels to spatial content and (ii) controlling channel sharing via t he number of groups 𝐺 . This is especially beneficial f or lightw eight backbones (e.g., MobileNetV3) and tasks demanding fine spatial aw areness (e.g., f ace P AD, texture analy sis, medical imaging), where directional, content-adaptive filtering im- pro ves selectivity without incurr ing the cost of full 𝐶 × 𝐶 ′ spatial mixing. S. Khan: Preprint submitted to Elsevier P age 4 of 14 CASO P AD Figure 3: Schematic diagram of the p rop osed content adaptive spatial op erator-based deep learning net wo rk. 3.3.5. Proposed MobV3-GI: Content-Adaptive Spatial Operator -based Netw ork The proposed network arc hitecture (as shown in Fig- ure 3 ) begin with MobileNetV3-Lar ge [ 22 ]. A typical block comprises e xpansion ( 1×1 ), depthwise 3×3 , squeeze-and- ex citation (SE), and projection ( 1×1 ). Herein, selected depth- wise con volutions are replaced by proposed gr oup inv olu- tion : 𝐘 ( 𝑖, 𝑗 , ∶) = ∑ ( 𝑢,𝑣 )∈Ω 𝑘 𝑖,𝑗 ( 𝑢, 𝑣 ) 𝐗 ( 𝑖 + 𝑢, 𝑗 + 𝑣, ∶) , (5) where 𝑖,𝑗 ∈ ℝ 𝑘 × 𝑘 is spatiall y varying and channel-shared. Kernels are generated by a lightweight function 𝑔 𝜙 (e.g., 1×1 con vs + BN + nonlinear ity) from a squeezed version of 𝐗 . Group sharing ( 𝐺 ) reduces cost b y generating ker nels per channel-group. Global av erage pooling yields 𝐳 ∈ ℝ 𝑑 ; a linear head produces logits 𝐬 = 𝑊 𝐳 + 𝑏 ∈ ℝ 2 . W e optimize cross- entropy with optional label smoothing ( 𝜖 =0 . 05 ): Placement. T o balance accuracy and efficiency , in volu- tion/GI is applied at both low - and high-resolution stag es; Section 6 ablates early v s. late placement. Algorit hm 1 summarizes the o verall inf erence w orkflow of t he proposed CASO-P AD system. It outlines how the MobV3-GI backbone extracts spatially adaptiv e features from each input frame, and per forms classification via a Algorithm 1: Input: Batc h of videos 𝑋 ∈ ℝ 𝐵 × 𝐶 × 𝐻 × 𝑊 Output: Class predictions 𝑦 ∈ ℝ 𝐵 × num_classes 1 Initialize Model: 2 Load MobV3-GI as t he bac kbone CNN 3 F r ame-Level F eature Extraction: 4 Extract f eatures 𝐟 = CNN ( 𝑋 [∶ , ∶ , ∶ , ∶]) ∈ ℝ 𝐵 ×960 5 F ully Connect ed Layer: 6 Classify: 𝑦 = FC ( 𝐅 av g ) 7 return Class predictions 𝑦 lightweight full y connected head. The algorit hmic outline emphasizes the model’ s simplicity and computational effi- ciency , making it easily reproducible f or mobile and embed- ded implementations. 3.4. T raining Setup The training of the proposed model is performed using the Adam optimizer with a learning rate of 10 −4 . The opti- mization objective is the binar y cross-entropy (BCE) loss, f or mulated as: 𝐿 = − 1 𝑁 𝑁 ∑ 𝑖 =1 [ 𝑦 𝑖 log( 𝑝 𝑖 ) + (1 − 𝑦 𝑖 ) log(1 − 𝑝 𝑖 ) ] , (6) S. Khan: Preprint submitted to Elsevier P age 5 of 14 CASO P AD T able 2 P erformance of the proposed metho d on Replay-A ttack (RA), Repla y-Mobile (RM), OULU-NPU, ROSE-Y outu (RY), and SiW-Mv2 (Proto col-1) datasets. Results a re rep orted as mean ± std over 3 run s where applicable. Metric Dataset RA RM OULU RY SiW-Mv2 T est Accuracy (%) 100 ± 0.0 100 ± 0.0 99.68 ± 0.13 98.90 ± 0.35 95.45 ± 1.63 Y ouden Index (YI) 1.0 ± 0.0 1.0 ± 0.0 0.991 ± 0.001 0.98 ± 0.0 0.938 ± 0.020 AUC-ROC 1.0 ± 0.0 1.0 ± 0.0 0.9999 ± 0.0000 0.99 ± 0.0 0.9906 ± 0.0022 EER (%) 0.0 ± 0.0 0.0 ± 0.0 0.44 ± 0.11 0.82 ± 0.09 3.13 ± 0.70 F AR (%) 0.0 ± 0.0 0.0 ± 0.0 0.23 ± 0.24 0.82 ± 0.09 2.76 ± 0.55 HTER (%) 0.0 ± 0.0 0.0 ± 0.0 0.44 ± 0.04 0.82 ± 0.21 3.11 ± 1.02 FRR (%) 0.0 ± 0.0 0.0 ± 0.0 0.65 ± 0.26 0.82 ± 0.34 3.45 ± 1.75 where 𝑦 𝑖 denotes the g round-trut h label and 𝑝 𝑖 represents the model’ s estimated probability f or the genuine (live) class. Tr aining is conducted for 100 epochs using mini-batches of size 32 . Early stopping with a patience threshold of 5 epochs is employ ed to prevent ov er fitting, based on the validation loss trend. Dur ing the testing phase, inference is performed with a batch size of 256 to ensure computational efficiency . All e xperiments are implemented in t he PyT orch frame- w ork and executed on an NVIDIA GeF orce RTX 5080 GPU equipped with 16 GB of VRAM. Unless other wise stated, all input frames are resized to a spatial resolution of 256 × 256 pixels. The source code and implementation details are pub- licly av ailable at: https://github.com/Shujaat123/CASO- PAD . 4. Results and Discussion This section presents a detailed evaluation of the pro- posed me t hod acr oss standard benc hmark datasets and mul- tiple performance metrics. W e first discuss the quantitativ e outcomes obtained on Replay -A ttack (RA), Repla y-Mobile (RM), OULU-NPU , R OSE- Y outu (R Y), and SiW -Mv2, f ol- low ed by a comparative analysis with e xisting state-of-the- art FaceP AD appr oaches. 4.1. P er formance Evaluation The proposed Content- Adaptiv e Spatial Oper ators for F aceP AD (CASO-P AD) is built on an inv olution-augmented MobileNetV3 backbone. T able 2 reports the o verall per f or- mance under the default configuration ( 256 × 256 input reso- lution, 𝐺 =120 groups, reduction f actor 𝑟 =4 , and k er nel size 𝑘 =5 ). Across five benchmarks, CASO-P AD demonstrates strong discr iminative capability , achieving per fect or near- perfect separation on controlled datasets and maintaining robust per formance on t he more challenging in-the-wild protocol. On Repla y- Attack (RA) and Repla y-Mobile (RM), CASO- P AD achie ves flaw less separation betw een bona fide and spoof classes, reaching 100% accuracy and A UC-R OC of 1.0 with 0.0% EER/HTER. These results indicate strong generalization under the controlled capture conditions and device variations typical of RA/RM. On OULU-NPU , which introduces larg er variability in illumination, bac kground, capture devices, and attack in- struments, CASO-P AD maintains near -ceiling per f or mance T able 3 Repla y-Attack (RA): comparison of test HTER (%) sorted from highest (wo rst) to low est (b est). Metho d Y ear HTER (%) EfficientNet-B0 [ 54 ] 2024 36.88 InceptionV4 [ 55 ] 2020 13.54 3D ConvNet [ 56 ] 2023 11.70 SCNN [ 55 ] 2020 7.53 Multi-Blo ck LBP [ 57 ] 2023 6.98 MIQF+SVM [ 58 ] 2022 5.38 Go ogLeNet+GMM [ 37 ] 2021 3.76 SfSNet [ 59 ] 2020 3.10 V GG16+GMM [ 37 ] 2021 1.46 MobileNet+Image Diffusion [ 40 ] 2023 0.09 ResNet50V2 [ 60 ] 2023 0.03 Hyb ridNet I I [ 61 ] 2025 0.02 Light weight 3D-DNN [ 62 ] 2024 0.00 HaTF AS [ 63 ] 2024 0.00 Hyb ridNet I [ 61 ] 2025 0.00 Defo rmable Convolution [ 64 ] 2025 0.00 Spatio-T emp oral [ 65 ] 2025 0.00 A dvSp o ofGuard [ 21 ] 2025 0.00 Dual-Branch [ 66 ] 2025 0.00 CASO-P AD (Prop osed) 2025 0.00 (99.68% accuracy , A UC-R OC 0.9999) wit h low er ror rates (EER 0.44%, HTER 0.44%). R OSE- Y outu (R Y) is more c hallenging due to diverse spoof types (print, replay , and mask/paper-mask) and het- erogeneous acquisition settings. CASO-P AD sust ains strong robustness wit h 98.90% accuracy , AUC-R OC 0.99, and EER/HTER of 0.82%, while preserving balanced sensitivity and specificity (Y ouden Index 0.98). Finall y , on SiW -Mv2 Protocol-1, which reflects large- scale, in-the-wild spoofing conditions with substantial sub- ject and att ack diversity , CASO-P AD achiev es 95.45% ac- curacy and A UC-ROC 0.9906 with 3.11% HTER and 3.13% EER. Overall, these results confir m t hat the proposed content- adaptive spatial oper ator improv es discriminability on stan- dard benchmarks while remaining robus t under more realis- tic, unconstrained att ack scenar ios. 4.2. Comparison with the State of the Art T o benchmark its performance, we compare against a broad range of contemporar y approaches on RA, RM, OULU-NPU , R Y , and SiW -Mv2 datasets using standard ev aluation metrics. 4.2.1. Replay-Attack (RA) As sho wn in T able 3 , CASO-P AD achiev es perf ect clas- sification on the Repla y- Attack dataset with 0.0% HTER, matching or outper forming the most recent high-per f or ming models such as AdvSpoofGuard [ 21 ], Dual-Branch [ 66 ], and Def or mable Con volution [ 64 ]. Earlier methods, including EfficientNet-B0 [ 54 ] and InceptionV4 [ 55 ], show consid- erably higher error rates, confirming the prog ress made S. Khan: Preprint submitted to Elsevier P age 6 of 14 CASO P AD T able 4 Repla y-Mobile (RM): comparison of test HTER (%) sorted from highest (wo rst) to low est (b est). Metho d Y ear HTER (%) V GG16+GMM [ 37 ] 2021 17.21 Go ogLeNet+GMM [ 37 ] 2021 13.56 SMKFNS [ 67 ] 2020 11.88 3D ConvNet [ 56 ] 2023 8.70 MK-SVDD-Slim [ 68 ] 2021 7.60 MKL [ 68 ] 2021 6.70 InceptionV4 [ 55 ] 2020 5.94 W A (PSO+PS) [ 69 ] 2021 5.85 W A (GA+MMS+PS) [ 70 ] 2022 5.12 SCNN [ 55 ] 2020 4.96 EfficientNet-B0 [ 54 ] 2024 4.62 MobileNet+Image Diffusion [ 40 ] 2023 1.14 Light weight 3D-DNN [ 62 ] 2024 0.45 ResNet50V2 [ 60 ] 2023 0.00 Defo rmable Convolution [ 64 ] 2025 0.00 Spatio-T emp oral [ 65 ] 2025 0.00 A dvSp o ofGuard [ 21 ] 2025 0.00 Dual-Branch [ 66 ] 2025 0.00 CASO-P AD (Prop osed) 2025 0.00 T able 5 OULU-NPU (complete protocol): comparison of test p erfo r- mance sorted b y ACER from highest (wo rst) to low est (b est). Method Y ear APCER / BPCER / ACER (%) T exture (V AR) [ 71 ] 2021 14.5 / 15.0 / 14.8 ED-LBP (V AR) [ 72 ] 2021 11.3 / 8.4 / 9.9 Fak e-Net (V AR) [ 73 ] 2021 5.4 / 6.9 / 6.2 OFT (V AR) [ 74 ] 2022 5.7 / 2.7 / 4.2 UCDCN [ 75 ] 2024 2.6 / 1.01 / 1.82 3DLCN [ 76 ] 2024 1.5 / 0.5 / 1.0 Spatio-T emporal [ 65 ] 2025 0.13 / 1.11 / 0.62 KD+Depth [ 66 ] 2025 0.28 / 0.83 / 0.56 CASO-P AD (Proposed) 2025 0.00 / 0.83 / 0.42 by moder n lightw eight architectures. The zero-er ror per- f or mance achie ved b y CASO-P AD underscores its strong f eature discrimination and adaptation capabilities. 4.2.2. Replay-Mobile (RM) The results on the Replay -Mobile dataset, summar ized in T able 4 , f ollow a similar trend. CASO-P AD again attains 0.0% HTER, positioning it among the t op-per forming meth- ods such as Dual-Branch [ 66 ] and AdvSpoofGuard [ 21 ]. Older handcrafted and hybrid approaches (e.g., W A [ 69 , 70 ] and SCNN [ 55 ]) show much higher er ror rates between 5–12%. These findings highlight CASO-P AD’ s ability to generalize across mobile capture environments character - ized b y unstable illumination and v ar ying conditions. 4.2.3. OULU T able 5 repor ts comparative per f or mance on the OULU- NPU benchmark under the complete protocol, where meth- ods are e valuated using the standardized APCER, BPCER, and ACER metrics. CASO-P AD achie ves an A CER of 0.42%, deliv ering one of t he best ov erall results among T able 6 ROSE-Y outu (RY): compa rison of test HTER/EER (%) sorted b y HTER from highest (wo rst) to low est (b est). Entries without rep o rted HTER are listed last. Method Y ear HTER/EER (%) 3D ConvNet [ 56 ] 2023 21.30/- ResNet50+GMM [ 37 ] 2021 14.69/- ViViT [ 77 ] 2023 13.28/2.46 EfficientNet-B0 [ 54 ] 2024 9.54/- F ASNet [ 36 ] 2021 8.57/- Fatemifa r et al. [ 78 ] 2022 6.34/- W A (PSO+PS) [ 69 ] 2021 5.61/- W A (GA+MMS+PS) [ 70 ] 2022 5.12/- MobileNet+Image Diffusion [ 40 ] 2023 4.92/4.95 ResNet50V2 [ 60 ] 2023 2.53/2.64 AdvSpoofGuard [ 21 ] 2025 1.97/1.08 Spatio-T emp oral ( 𝜏 =1 ) [ 65 ] 2025 1.47/0.85 CA-F AS [ 79 ] 2024 1.37/- Deformable Convolution [ 64 ] 2025 1.26/0.80 Dual-Branch [ 66 ] 2025 1.02/1.15 CASO-P AD (Prop osed) 2025 0.82/0.82 recent s tate-of-t he-ar t appr oaches. In par ticular, t he pr o- posed method obtains an APCER of 0.00%, indicating perfect rejection of attack present ations, while maintaining a competitiv e BPCER of 0.83%. Compared with earlier handcrafted f eature baselines such as T exture (V AR) [ 71 ] and ED-LBP (V AR) [ 72 ], CASO-P AD reduces ACER by more t han an order of magni- tude. Further more, CASO-P AD remains highly competitive against recent deep architectures including 3DLCN [ 76 ] (ACER 1.0%) and KD+Depth [ 66 ] (A CER 0.56%). These results demonstrate that CASO-P AD generalizes strongly across t he diverse illumination, camera, and spoofing con- ditions present in OULU-NPU. 4.2.4. ROSE- Y outu (R Y) T able 6 reports comparative per f or mance on the more challenging R OSE- Y outu benchmark. Here, CASO-P AD achie ves an HTER of 0.82% and an EER of 0.82%, outper - f or ming several recent high-per forming methods including Dual-Branch [ 66 ] (1.02/1.15) and Def ormable Conv olu- tion [ 64 ] (1.26/0.80). Compared with earlier arc hitectures such as ViV iT [ 77 ] or EfficientNet-B0 [ 54 ], the improv ement margin e xceeds 90%, demonstrating substantial gains in discriminability and generalization. The results on ROSE- Y outu validate CASO-P AD’ s robustness against diverse spoofing modalities and sensor variations. 4.2.5. Spoofing in the Wild (SiW-Mv2) T able 7 repor ts results on the SiW -Mv2 Protocol-1 benchmark, a larg e-scale and challenging dat aset charac- terized by substantial subject diversity , varied att ack instru- ments, and r ealistic capture conditions. Under this pro tocol, CASO-P AD achie ves an HTER of 3.11% and an EER of 3.13%, yielding the low est er ror rates among the compared methods. S. Khan: Preprint submitted to Elsevier P age 7 of 14 CASO P AD T able 7 SiW-Mv2 (Proto col-1): compa rison of test HTER/EER (%) so rted b y HTER from highest (wo rst) to lo west (best). Metho d Y ear HTER/EER (%) V GG16 [ 80 ] 2014 10.54/10.45 Spatio-T emp oral ( 𝜏 =1 ) [ 65 ] 2025 6.11/6.63 MobileNetV3 large [ 22 ] 2019 5.93/5.87 Inceptionv3 [ 81 ] 2016 5.77/5.78 Depth-aug. T eacher [ 66 ] 2025 5.82/6.08 ResNet50V2 [ 60 ] 2023 5.18/6.08 MobileNetV3 small [ 22 ] 2019 5.56/5.51 Defo rmMobileNet [ 64 ] 2025 4.88/4.83 EfficientNet-B0 [ 54 ] 2024 4.82/5.80 CASO-P AD (Prop osed) 2026 3.11/3.13 Compared with recent lightweight architectures such as EfficientNet-B0 [ 54 ] (4.82/5.80) and DeformMobileNet [ 64 ] (4.88/4.83), CASO-P AD reduces HTER by appro ximately 35–40%, indicating improv ed generalization under diverse spoof scenar ios. Relative to ResNet50V2 [ 60 ] (5.18/6.08) and the depth-augmented teacher model [ 66 ] (5.82/6.08), the reduction in HTER ex ceeds 40%, despite relying solely on R GB input without auxiliary depth or temporal modeling. Furt hermore, CASO-P AD substantially outperforms ear - lier baselines such as MobileNetV3 [ 22 ] and V GG16 [ 80 ], where er ror rates remain abov e 5–10%. These results demon- strate that the proposed content-adaptive spatial operator enhances discr iminative capability in comple x, real-w orld spoofing conditions while preser ving a lightweight and deployment-friendly architecture. 4.2.6. Over all Discussion Across all three datasets, CASO-P AD consistently matches or sur passes the stronges t recent competitors while main- taining a compact and comput ationally efficient architecture. Its use of conte xt-adaptive inv olution ker nels allo w s the model to dynamically capture spatial dependencies, yielding robust anti-spoofing per formance. These results collectively establish CASO-P AD as a reliable and scalable framew ork f or real-w orld FaceP AD systems. 5. Kernel Audit T o better understand the adaptive behavior of the pro- posed model, w e per f or med a comprehensiv e audit of t he learned kernel functions. This anal ysis is conducted on R Y dataset and it f ocuses on f our com plement ary indicators that collectiv ely descr ibe the k er nel’ s spatial and spectral properties: • HF/LF ratio — the proportion of high- to low - frequency energy , where higher values indicate shar per, edge-rich responses; • Anisotrop y — t he deg ree of or ientation selectivity ( 0 indicates isotropic kernels, while larger v alues reflect strong er directional sensitivity); • DC offset — the mean value of kernel weights, where values near zero cor respond to center–sur round or high-pass beha vior without brightness bias; and • P osition variance — a measure of spatial non-stationar ity , with low er values denoting g reater position inv ar i- ance. T est-set summar y. The ev aluation on the held-out test se t rev eals that the in v olution-based head produces k er nels that are nearl y zero-mean and spatially inv ariant (DC offse t ≈ 0 . 0000 ± 0 . 0000 , position variance ≈ 4 × 10 −6 ± 3 × 10 −6 ). These ker nels e xhibit moderate or ientation selec- tivity (anisotropy 0 . 1832 ± 0 . 0696 ) and a noticeable high- frequency preference (HF/LF 17 . 58 ± 4 . 65 ). Figure 4: Kernel audit visualization (normalized to [0 , 1] ). Left: Mean kernel showing directional p ola rity contrast, resembling an edge-detecting filter. Right: Mean energy distribution, radially compact and indicative of high-pass/edge-emphasizing b ehavio r. Figure 4 illustrates these proper ties. The mean kernel (left) shows a localized polar ity contrast, similar to an ori- ented edge detector rat her than a symmetric center–sur round pattern. The corresponding energy map (right) display s a radially concentrated distribution, characteristic of high- pass filter ing. Tog ether, these visualizations confir m that the model learns to enhance structural gradients and texture cues typical of genuine facial regions, while naturally suppressing smooth or redundant low-fr equency content. Class-wise differ ences. A class-wise breakdown of the learned kernels rev eals clear distinctions betw een genuine and spoof ed inputs. As depicted in Figure 5 , attack samples exhibit a higher HF/LF ratio (18.46 vs. 15.02) but a low er anisotrop y (0.161 vs. 0.248) than genuine f aces. This indi- cates that spoofed frames tend to contain ar tificially sharp, broadband textures but lack coherent directional organiza- tion, consistent wit h reflections or pr inting ar tifacts. Cohen ’ s effect size fur ther quantifies these differences: HF/LF ( 𝑑 = + 0 . 782 ) suggests moderately higher sharpness in att acks, while anisotrop y ( 𝑑 = − 1 . 486 ) reflects a larg e effect f av oring genuine faces with stronger directional coher- ence. The histograms in Figure 5 illustrate these tendencies: real samples cluster around higher anisotropy values, while attack samples dominate t he higher HF/LF range. Over all, S. Khan: Preprint submitted to Elsevier P age 8 of 14 CASO P AD (a) Anisotropy distribution (b) HF/LF dis tr ibution Figure 5: Kernel audit overlays on the test set. ( a ) Real faces sho w higher directional consistency (anisotropy), while ( b ) attack samples exhibit excessive sha rpness (higher HF/LF) but weak er organization. anisotropy emerges as the more discriminative feature, cap- turing str uctural regularity inherent in authentic facial geom- etry , whereas HF/LF primar ily responds to o ver -sharpening and specular effects common in spoof attempts. Interpr etation. The ker nel audit suggests that the inv olu- tion lay ers act as adaptive edg e-oriented spatial filters . They enhance str uctured g radients aligned with genuine facial geometry while down-w eighting homogeneous or specular regions often found in spoof media. The combination of near -zero DC bias, balanced frequency response, and mod- erate directional selectivity highlights the interpretability of the learned filters. In essence, the model implicitly lear ns a phy sics-consistent representation, accentuating meaningful texture and geome tr ic cues t hat distinguish real from fake f acial imagery . 6. Ablation Studies This section presents a ser ies of ablation experiments de- signed to ev aluate the contr ibution of different architectural and training f actors to the proposed method’ s ov erall per - f or mance. W e systematicall y analyze the effects of netw ork backbone, g roup count in the inv olution head, placement of the proposed group-inv olution (GI) module, input image resolution, and reduction ratio. The section concludes with computational complexity analy sis and qualitative interpre- tation using Grad-C AM visualizations. 6.1. Effect of Ne twor k Architecture T o understand how backbone design influences perfor - mance, tw o MobileNet variants were tested: MobileNetV2 and MobileN etV3-Large, each integrated wit h the proposed GI head. Both models were ev aluated using the ROSE- Y outu dataset with identical training conditions. Key results are summarized in T able 8 . MobileNetV3-Lar ge consistently outperforms MobileNetV2, achie ving higher accuracy and a lo wer HTER despite re- duced comput ational cost (0.643 vs. 0.932 GFLOPs). The T able 8 Compa rison of different MobileNet backb ones with proposed GI head on the ROSE-Y outu dataset (reduction ratio = 4, groups = 120). Results are rep orted as mean ± std over 3 runs. Model Pa rams (M) GFLOPs Y ouden max ↑ HTER (%) ↓ MobileNetV3+GI 3.635 0.643 0 . 984 ± 0 . 004 0 . 82 ± 0 . 21 MobileNetV2+GI 3.399 0.932 0 . 971 ± 0 . 006 1 . 43 ± 0 . 34 T able 9 Ablation over group count ( 𝐺 ) in the GI head (input size 256 × 256 ). Results a re mean ± std over 3 runs. Groups Pa rams (M) GFLOPs Y ouden ↑ HTER (%) ↓ 16 3.476 0.623 0.977 ± 0.004 1.16 ± 0.19 30 3.497 0.626 0.977 ± 0.010 1.14 ± 0.50 60 3.543 0.631 0.972 ± 0.020 1.41 ± 1.01 120 3.635 0.643 0.984 ± 0.004 0.82 ± 0.21 240 3.818 0.666 0.965 ± 0.020 1.77 ± 0.98 impro vement can be attr ibuted to MobileNetV3’ s more expressiv e activation functions and squeeze-and-ex citation modules, whic h be tter complement t he adaptiv e behavior of the in volution head. 6.2. Effect of Group Count in the GI Head The number of g roups ( 𝐺 ) in the inv olution operator controls spatial diversity and computational load. T able 9 summarizes performance for v ar ious g roup counts. Per- f or mance peaks at 𝐺 =120 , while smaller or larger values degrade results due to underfitting or ov er -parameter ization. Moderate group sizes allo w the model to capture suf- ficient spatial variation without unnecessary ov erhead. Ex- cessive grouping ( 𝐺 =240 ) increases FLOPs and parameters without measurable benefit, while very low values reduce the netw ork’ s representational capacity . 6.3. Effect of Proposed GI Placement T o assess ho w the position of the GI module affects performance, tw o placements wer e ev aluated: (1) at the S. Khan: Preprint submitted to Elsevier P age 9 of 14 CASO P AD Figure 6: t-SNE emb eddings of features b efore the classification lay er across different input resolutions. Higher resolutions yield b etter class separation. T able 10 Effect of GI blo ck placement in MobileNetV3 (groups = 120 ). V alues are mean ± std over 3 runs. GFLOPs measured on 256 × 256 input. Placement Pa rams (M) GFLOPs Y ouden max ↑ HTER (%) ↓ Beginning 2.975 0.645 0 . 968 ± 0 . 014 1 . 59 ± 0 . 70 End 3.635 0.643 0 . 984 ± 0 . 004 0 . 82 ± 0 . 21 T able 11 P erformance for different input image sizes on the ROSE-Y outu dataset. Mean ± std over 3 runs. Metric Image Size 𝟓𝟏𝟐 × 𝟓𝟏𝟐 𝟐𝟓𝟔 × 𝟐𝟓𝟔 𝟏𝟐𝟖 × 𝟏𝟐𝟖 𝟔𝟒 × 𝟔𝟒 Accuracy (%) 98.97 ± 0.43 98.90 ± 0.35 98.15 ± 1.01 93.48 ± 1.17 AUC-ROC 0.9994 ± 0.0003 0.9995 ± 0.0003 0.9971 ± 0.0033 0.9724 ± 0.0063 EER (%) 0.90 ± 0.36 0.82 ± 0.09 1.61 ± 0.80 8.21 ± 1.16 HTER (%) 0.61 ± 0.23 0.82 ± 0.21 1.64 ± 0.70 7.70 ± 1.42 Y ouden Index (YI) 0.988 ± 0.005 0.984 ± 0.004 0.967 ± 0.014 0.846 ± 0.028 Pa rams (M) 3.635 3.635 3.635 3.635 GFLOPs 2.563 0.643 0.163 0.043 beginning of the MobileNetV3 backbone and (2) at the end , right before adaptive a verag e pooling. Results are summa- rized in T able 10 . Placing the GI at the end yields superior results, in- dicating that conte xt-adaptive filter ing benefits most from high-lev el semantic representations. Early placement offers slightly reduced computational cost but sacr ifices discrimi- native power . 6.4. Effect of Input Imag e Size T o study the trade-off between input resolution and accuracy , models were trained wit h image sizes of 64 × 64 , 128 × 128 , 256 × 256 , and 512 × 512 . Results are reported in T able 11 and illustr ated in Figure 6 . The t-SNE plots sho w a clear resolution-separation trend: at 64×64 the bona fide and spoof clusters ov erlap notably; at 128×128 and 256×256 clusters become more compact wit h wider margins; at 512×512 separation is stronges t, matching the best EER/HTER. Perf or mance improv es with higher resolutions, with t he best results achie ved at 512 × 512 (HTER 0.61%). Ho w- ev er , computational cost gro ws rapidly , from 0.043 to 2.563 GFLOPs. The 256 × 256 resolution pro vides a balanced trade-off, offer ing near-maximum accuracy with manage- able complexity , making it t he most practical choice for real- time applications. T able 12 Effect of reduction ratio ( reduce ∈ {1 , 4 , 8} ) in the END-placed involution [ 23 ] head ( 𝐺 =120 ). Mean ± std over 3 runs. Reduce Pa rams (M) GFLOPs Y ouden max ↑ HTER (%) ↓ 1 5.775 0.919 0 . 965 ± 0 . 028 1 . 75 ± 1 . 40 4 3.635 0.643 0 . 984 ± 0 . 004 0 . 82 ± 0 . 21 8 3.303 0.600 0 . 967 ± 0 . 016 1 . 65 ± 0 . 78 6.5. Effect of R eduction Ratio T able 12 ex amines the influence of t he reduction ratio ( r educe ) in the kernel generator of the in volution head. As the bottlenec k ratio increases, parameter count and FLOPs decrease, but performance f ollow s a non-linear trend. The optimal configuration is r educe = 4 , which deliv ers the highest Y ouden Inde x ( 0 . 984 ± 0 . 004 ) and low est HTER ( 0 . 82 ± 0 . 21 ). A small bottleneck ( reduce = 1 ) ov erfits and increases computational load, while an over ly larg e one ( reduce = 8 ) restricts t he kernel g enerator’ s capacity . A moderate setting at reduce = 4 str ikes the best balance between efficiency and expressiv eness. 6.6. Computational Complexity and Efficiency Analy sis T o examine computational efficiency , CASO-P AD is ev aluated against representative lightweight architectures, including ShuffleNetV2 [ 82 ], Once-f or- All [ 83 ], MobileNetV2 [ 84 ], MobileVi TV2 [ 85 ], GhostN et [ 86 ], and MobileNe tV3 [ 22 ]. All networ ks are trained and tested using identical settings with a 224 × 224 input resolution, ImageNet initializa- tion, and consistent optimization parameters. Performance and complexity measurements are obtained under unif orm benchmarking conditions to ensure f air comparison. Figure 7 illustrates t he relationship between spoof detec- tion performance and model complexity from two comple- mentar y perspectiv es. The parameter -based analy sis (left) show s that CASO-P AD attains t he low est HTER (1.02%) de- spite ha ving only moderate model size (3.635M parameters), indicating super ior parameter efficiency . Sev eral smaller netw orks, such as ShuffleNe tV2, exhibit noticeabl y higher er ror rates, sugg esting that reduced parameter count alone does not guarantee robust liv eness representation. S. Khan: Preprint submitted to Elsevier P age 10 of 14 CASO P AD Figure 7: T rade-off compa rison b etw een mo del complexit y and performance. (Left) HTER vs. numb er of pa rameters. (Right) HTER vs. GFLOPs. T able 13 Inference latency compa rison on NVIDIA Jetson Orin Nano fo r input resolution 224 × 224 (CUDA execution). Method Jetson Orin Nano Latency (ms) ShuffleNetV2 [ 82 ] 22.6 ± 0.6 Once-for-All [ 83 ] 49.36 ± 0.4 Mobile ViTV2 [ 85 ] 28.87 ± 0.8 MobileNetV2 [ 84 ] 19.0 ± 0.4 MobileNetV3 (la rge) [ 22 ] 23.17 ± 0.7 GhostNet [ 86 ] 37.8 ± 0.2 CASO-P AD (Prop osed) 25.6 ± 0.8 Values denote average inference latency (mean ± std) over 100 runs on NVIDIA Jetson Orin Nano (25W mode, CUDA). The GFLOPs-based view (r ight) fur ther reveals that CASO-P AD achiev es strong discriminative per f or mance at low computational cost (0.48 GFLOPs). Impor tantly , mod- els with comparable or ev en lower FLOPs do not consis- tently matc h this accuracy lev el, highlighting t hat effective architectural design and f eature modeling play a more cr iti- cal role than raw operation count. These obser vations collec- tivel y indicate that CASO-P AD impro v es generalization ef- ficiency by extracting more inf or mative representations per unit of computation rather than rel ying on lar ger ne tworks. 6.6.1. Edg e Deployment : Jetson Or in Nano T able 13 repor ts inf erence latency on the NVIDIA Jetson Orin Nano, reflecting realistic edge deployment conditions. While cer tain models exhibit slightly lo wer latency , these netw orks are associated with substantiall y higher HTER values (Fig. 7 ), indicating weak er spoof discr imination ca- pability . CASO-P AD maintains competitive r untime per - f or mance while delivering significantly impro ved detection accuracy , demonstrating that modest increases in latency can be justified by notable gains in reliability and robustness. This beha vior underscores a critical practical considera- tion: minimal inf erence time alone is insufficient f or secure biometric sys tems if accompanied b y degraded liv eness detection. The results confir m that CASO-P AD achiev es a f av orable accuracy–efficiency balance, making it suit able f or resource-constrained, real-time f ace authentication scenar- ios. 6.7. Model Interpretability via Grad-C AM T o inter pret the model’ s decision-making process, Grad- CAM heatmaps w ere generated f or both genuine and spoof samples (Figure 8 ). The activation maps show that the net- w ork emphasizes meaningful f acial regions, such as skin texture, e yes, and lips, while also f ocusing on artifacts such as mask and print borders in spoofed ones. This behavior validates the discriminative nature of the learned f eatures, illustrating that CASO-P AD effectivel y lever ages spatial and textural cues associated with f acial liveness. 7. Conclusion This paper introduced CASO-P AD, a lightw eight Face Presentation Attack Detection (FaceP AD) model that inte- grates content-adaptiv e spatial operators (in v olution) into a MobileNetV3 backbone. By replacing selected depthwise con volutions with a group-wise, location-adaptive opera- tor , CASO-P AD improv es spatial selectivity for spoof cues while retaining mobile-class efficiency and operating in an R GB-only , single-fr ame setting. Extensive experiments on Replay -A ttack, Repla y-Mobile, OULU-NPU , ROSE- Y outu, and SiW -Mv2 (Protocol-1) demon- strate that CASO-P AD achie ves perfect or near -ceiling performance on controlled benchmarks and maintains robust accuracy under in-the-wild conditions (e.g., 3.11% HTER and 3.13% EER on SiW-Mv2 Protocol-1). Ablation studies furt her sho w that placing the adaptive operator near t he net- w ork head and using moderate group sharing yields the best accuracy–efficiency trade-off. In addition, the kernel audit and Grad-C AM anal ysis pro vide interpretable e vidence that CASO-P AD emphasizes meaningful textur e and boundar y S. Khan: Preprint submitted to Elsevier P age 11 of 14 CASO P AD Figure 8: Grad-CAM [ 87 ] visualizations on genuine and sp o of frames from the ROSE-Y outu dataset. The mo del fo cuses on discriminative cues such as eyes, lips, and mask edges (b est view ed in color). cues, while Jetson Orin N ano measur ements confirm its suitability f or real-time edge deployment. The implementation of CASO-P AD is publicly av ailable at: https://github.com/Shujaat123/CASO- PAD . A ckno wledgment Shujaat Khan acknow ledg es t he suppor t from t he King Fahd University of Pe troleum & Minerals (KFUPM) under Earl y Career Researc h Grant no. EC241027. Ref erences [1] K. W ang, M. Huang, G. Zhang, H. Y ue, G. Zhang, Y . Qiao, Dynamic f eature queue for sur veillance face anti-spoofing via prog ressive train- ing, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Patter n Recognition, 2023, pp. 6371–6378. [2] W . Y e, W . Chen, L. For tunati, Mobile payment in china: A study from a sociological perspectiv e, Jour nal of Communication Inquiry 47 (2023) 222–248. [3] H. Fang, A. Liu, J. W an, S. Escalera, C. Zhao, X. Zhang, S. Z. Li, Z. Lei, Surveillance face anti-spoofing, IEEE Transactions on Inf or mation Forensics and Security 19 (2023) 1535–1546. [4] H. Lee, S.-H. Park, J.-H. Y oo, S.-H. Jung, J.-H. Huh, Face recognition at a distance for a stand-alone access control system, Sensors 20 (2020) 785. [5] K. Alhanaee, M. Alhammadi, N. Almenhali, M. Shatnawi, Face recognition smar t attendance system using deep transfer lear ning, Procedia Computer Science 192 (2021) 4093–4102. [6] P . Grother, P . Grother, M. Ngan, K. Hanaoka, Face recognition vendor test (fr vt) par t 2: Identification, 2019. [7] J. Galbally , et al., Biometric anti-spoofing methods: A sur vey in face recognition systems, IEEE Security and Privacy 12 (2014) 30–37. [8] Y . Wen, et al., Face spoof detection with image distor tion analysis, in: IEEE Transactions on Information Forensics and Security, volume 10, 2015, pp. 746–761. [9] Z. Yu, Y . Qin, X. Li, C. Zhao, Z. Lei, G. Zhao, Deep lear ning f or face anti-spoofing: A sur ve y , IEEE transactions on pattern analysis and machine intelligence 45 (2022) 5609–5631. [10] D. G. Low e, Distinctiv e image features from scale-invariant key - points, International jour nal of computer vision 60 (2004) 91–110. [11] H. Bay , T . Tuytelaars, L. V an Gool, Surf: Speeded up robust f eatures, in: Computer Vision–ECCV 2006: 9th European Conf erence on Computer V ision, Graz, Austria, Ma y 7-13, 2006. Proceedings, Part I 9, Springer, 2006, pp. 404–417. [12] N. Dalal, B. Triggs, Histograms of or iented gradients for human detection, in: 2005 IEEE computer society conference on computer vision and patter n recognition (CVPR’05), volume 1, Ieee, 2005, pp. 886–893. [13] G. Pan, L. Sun, Z. Wu, Y . W ang, Eyeblink -based anti-spoofing in face recognition from a generic webcamera, 2007 IEEE 11th Inter national Conf erence on Computer Vision (2007) 1–8. [14] J. Komulainen, A. Hadid, M. Pietikäinen, Context based f ace anti- spoofing, in: 2013 IEEE sixth inter national conference on biometrics: theory, applications and systems (BT AS), IEEE, 2013, pp. 1–8. [15] W . Sun, Y . Song, C. Chen, J. Huang, A. C. Kot, Face spoofing de- tection based on local ter nary label super vision in fully conv olutional netw orks, IEEE Transactions on Information Forensics and Security 15 (2020) 3181–3196. [16] C. Szeg edy , W . Zaremba, I. Sutskev er, J. Bruna, D. Erhan, I. Good- f ellow , R. Fer gus, Intriguing proper ties of neural netw orks, arXiv preprint arXiv:1312.6199 (2013). [17] D. Deb, X. Liu, A. K. Jain, Unified detection of digital and physical face attacks, in: 2023 IEEE 17th International Conference on Aut o- matic Face and Gesture Recognition (FG), IEEE, 2023, pp. 1–8. [18] Z. Zhang, J. Y an, S. Liu, Z. Lei, D. Yi, S. Z. Li, A face antispoofing database with diverse attacks, in: 2012 5th IAPR international conf erence on Biometr ics (ICB), IEEE, 2012, pp. 26–31. [19] E. L. Denton, S. Chintala, A. Szlam, R. Fergus, Deep generative image models using a Laplacian pyramid of adversarial networks, in: Adv ances in Neural Information Processing Systems (NeurIPS), volume 28, 2015, pp. 1486–1494. [20] A. Radf ord, L. Metz, S. Chintala, Unsupervised representation learning with deep conv olutional generativ e adversarial networks, arXiv prepr int arXiv:1511.06434 (2015). [21] T . H. M. Siddique, S. Khan, Z. W ang, K. Huang, Advspoofguard: Optimal transpor t dr iven robust face presentation attack detection system, Know ledge-Based Systems (2025) 113759. [22] A. How ard, M. Sandler, G. Chu, L.-C. Chen, B. Chen, M. T an, W . W ang, Y . Zhu, R. P ang, V . V asudevan, et al., Searching for mo- bilenetv3, in: Proceedings of the IEEE/CVF Inter national Conference on Computer Vision, 2019, pp. 1314–1324. [23] D. Li, J. Hu, C. W ang, X. Li, Q. She, L. Zhu, T. Zhang, Q. Chen, Inv o- lution: Inv er ting t he inherence of convolution for visual r ecognition, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 12321–12330. [24] I. Chingo vska, A. Anjos, S. Marcel, On the effectiv eness of local binary patterns in face anti-spoofing, in: 2012 BIOSIG-proceedings of the international conf erence of biometr ics special interest group (BIOSIG), IEEE, 2012, pp. 1–7. [25] A. Cos ta-Pazo, S. Bhattacharjee, E. V azquez-Fernandez, S. Mar - cel, The repla y-mobile face presentation-attack database, in: 2016 International Conference of the Biometrics Special Interest Group (BIOSIG), IEEE, 2016, pp. 1–7. [26] Z. Boulkenaf et, J. Komulainen, L. Li, X. Feng, A. Hadid, Oulu-npu: A mobile face presentation att ack database wit h real-wor ld variations, in: 2017 12th IEEE international conference on automatic face & gesture recognition (FG 2017), IEEE, 2017, pp. 612–618. [27] H. Li, W . Li, H. Cao, S. W ang, F . Huang, A . C. K ot, Unsupervised domain adaptation f or face anti-spoofing, IEEE T ransactions on S. Khan: Preprint submitted to Elsevier P age 12 of 14 CASO P AD Inf or mation Forensics and Security 13 (2018) 1794–1809. [28] X. Guo, Y . Liu, A. Jain, X. Liu, Multi-domain learning for updating face anti-spoofing models, in: ECCV , 2022. [29] T . Ojala, M. Pietikainen, T . Maenpaa, Multiresolution gray-scale and rotation inv ariant texture classification with local binar y patter ns, IEEE Transactions on pattern analy sis and machine intelligence 24 (2002) 971–987. [30] J. Määttä, A. Hadid, M. Pietikäinen, Face spoofing detection from single images using micro-te xture analysis, in: 2011 Inter national Joint Conference on Biometrics (IJCB), IEEE, 2011, pp. 1–7. [31] Z. Boulkenaf et, J. Komulainen, A. Hadid, Face anti-spoofing using color te xture analy sis, IEEE Transactions on Information Forensics and Secur ity 11 (2016) 1818–1830. [32] Z. Boulk enafet, J. Komulainen, A. Hadid, Face anti-spoofing based on color texture analy sis, in: 2015 IEEE inter national conference on image processing (ICIP), IEEE, 2015, pp. 2636–2640. [33] J. Li, Y . W ang, T . Tan, A. K. Jain, Liv e face detection based on the analy sis of f our ier spectra, in: Biometric technology f or human identification, volume 5404, SPIE, 2004, pp. 296–303. [34] V . M. Patel, N. K. Ratha, R. Chellappa, Secure face unlock: Spoof de- tection on smar tphones, IEEE Transactions on Inf or mation Forensics and Secur ity 11 (2016) 2268–2283. [35] Y . A. U. Rehman, L.-M. Po, M. Liu, Z. Zou, W . Ou, Y . Zhao, Face liveness detection using conv olutional-f eatures fusion of real and deep netw ork generated face images, Journal of Visual Communication and Image Representation 59 (2019) 574–582. [36] N. Bousnina, L. Zheng, M. Mikram, S. Ghouzali, K. Minaoui, Un- ra veling robustness of deep face anti-spoofing models against pix el attacks, Multimedia Tools and Applications 80 (2021) 7229–7246. [37] S. Fatemif ar, S. R. Arashloo, M. A w ais, J. Kittler, Client-specific anomaly detection for face presentation att ack detection, Patter n Recognition 112 (2021) 107696. [38] G. W ang, H. Han, S. Shan, X. Chen, Unsupervised adversarial domain adaptation for cross-domain face presentation attack detection, IEEE Transactions on Inf or mation Forensics and Secur ity 16 (2020) 56–69. [39] Z. W ang, Z. W ang, Z. Y u, W . Deng, J. Li, T. Gao, Z. W ang, Domain generalization via shuffled style assembly for face anti-spoofing, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 4123–4133. [40] M. O. Alassafi, M. S. Ibrahim, I. Naseem, R. AlGhamdi, R. Alotaibi, F . A. Kateb, H. M. Oqaibi, A. A. Alshdadi, S. A. Y usuf, A nov el deep learning architecture with image diffusion for robust face presentation attack detection, IEEE Access 11 (2023) 59204–59216. [41] K. P atel, H. Han, A. K. Jain, Cross-database f ace antispoofing with robust f eature representation, in: Chinese Conference on Biometric Recognition, Springer, 2016, pp. 611–619. [42] W . Bao, H. Li, N. Li, W . Jiang, Liveness detection for face recognition based on optical flow field, 2009 Inter national Conference on Image Analy sis and Signal Processing (2009) 233–236. [43] R. Shao, X. Lan, P . C. Y uen, Joint discr iminative learning of deep dynamic textures for 3d mask face anti-spoofing, IEEE Transactions on Information Forensics and Security 14 (2018) 923–938. [44] U. Muhammad, Z. Y u, J. Komulainen, Self-supervised 2d face presentation attack detection via temporal sequence sampling, Patter n Recognition Letters (2022). [45] C. Dhiman, A. Antil, A. Anand, S. Gakhar, A deep f ace spoof de- tection framew ork using multi-lev el elbps and stacked lstms, Signal, Image and Video Processing (2024) 1–14. [46] S.-Q. Liu, X. Lan, P . C. Y uen, Remote photoplethy smography correspondence feature f or 3d mask face presentation attack detection, in: Proceedings of the European Conf erence on Computer Vision (ECCV), 2018. [47] S.-Q. Liu, X. Lan, P . C. Y uen, Multi-channel remote pho toplethys- mography cor respondence feature f or 3d mask face presentation attack detection, IEEE Transactions on Information Forensics and Security 16 (2021) 2683–2696. [48] Z. Y u, X. Li, P . W ang, G. Zhao, Transrppg: Remote photopleth ys- mography transformer for 3d mask face presentation attack detection, IEEE Signal Processing Letters (2021). [49] Y . Liu, X. Zhang, S. Zhang, H. Liu, J. Shi, L. Liu, S. Fu, 3d mask face anti-spoofing wit h remote phot oplethysmography , IEEE Signal Processing Letters 23 (2016) 1589–1593. [50] C. Y ao, S. W ang, J. Zhang, W . He, H. Du, J. Ren, R. Bai, J. Liu, rppg- based spoofing detection f or face mask attack using efficientnet on weighted spatial-temporal representation, in: 2021 IEEE International Conf erence on Image Processing (ICIP), IEEE, 2021, pp. 3872–3876. [51] S. Liu, X. Lan, P . Yuen, Temporal similar ity analy sis of remote photo- plethy smography for fast 3d mask face presentation attack detection, in: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2020, pp. 2608–2616. [52] K. Kotwal, S. Bhattacharjee, S. Marcel, Multispectral deep em- beddings as a counter measure to cus tom silicone mask presentation attacks, IEEE Tr ansactions on Biometrics, Behavior , and Identity Science 1 (2019) 238–251. [53] D. Li, G. Chen, X. Wu, Z. Y u, M. Tan, Face anti-spoofing with cross- stage relation enhancement and spoof material perception, Neural Netw orks 175 (2024) 106275. [54] V . D. Huszár , V . K. Adhikarla, Secur ing phygital gameplay: Strategies f or video-replay spoofing detection, IEEE Access (2024). [55] R. Koshy , A. Mahmood, Enhanced deep learning architectures f or face liveness detection f or static and video seq uences, Entropy 22 (2020) 1186. [56] S. Giurato, A. Or tis, S. Battiato, Real-time multiclass face spoofing recognition through spatiotemporal conv olutional 3d features, in: In- ternational Conf erence on Imag e Anal ysis and Pr ocessing, Springer , 2023, pp. 356–367. [57] A. Günay Yılmaz, U. Turhal, V . Nabiyev , Face present ation attack de- tection per formances of f acial regions with multi-block lbp features, Multimedia Tools and Applications 82 (2023) 40039–40063. [58] H.-H. Chang, C.-H. Y eh, Face anti-spoofing detection based on multi- scale image quality assessment, Image and Vision Computing 121 (2022) 104428. [59] A. Pinto, S. Goldenstein, A. Fer reira, T. Car valho, H. Pedrini, A. Rocha, Le veraging shape, reflectance and albedo from shading for face presentation attack detection, IEEE Transactions on Information Forensics and Security 15 (2020) 3347–3358. [60] M. O. Alassafi, M. S. Ibrahim, I. Naseem, R. AlGhamdi, R. Alotaibi, F . A. Kateb, H. M. Oqaibi, A. A. Alshdadi, S. A. Y usuf, Fully supervised contrastive learning in latent space for f ace presentation attack detection, Applied Intelligence 53 (2023) 21770–21787. [61] A. S. Biswas, S. Dey , S. V erma, K. V erma, Deep guard: An enhanced hybrid ensemble classifier for f ace presentation attack detection in- tegrating gabor and binarized statistical image features descriptors with deep learning, Computers and Electrical Engineer ing 127 (2025) 110566. [62] P . J. Seegehalli, B. N. Krupa, Lightweight 3d-studentnet f or defending against face replay att acks, Signal, Image and Video Processing (2024) 1–17. [63] J. Zhang, Y . Zhang, F . Shao, X. Ma, S. Feng, Y . Wu, D. Zhou, Effi- cient face anti-spoofing via head-aw are transformer based know ledge distillation with 5 mb model parameters, Applied Soft Computing 166 (2024) 112237. [64] S. M. Ibrahim, M. S. Ibrahim, S. Khan, Y .-W . Ko, J.-G. Lee, Improv - ing face presentation attack detection through def or mable convolution and transfer learning, IEEE Access (2025). [65] S. Khan, T. H. M. Siddique, M. S. Ibrahim, A. J. Siddiqui, K. Huang, Spatio-temporal deep learning f or impr oved face presentation attack detection, Knowledg e-Based Systems (2025) 113059. [66] M. S. Jabbar, T . H. M. Siddique, K. Huang, S. Khan, Knowledg e distillation with predicted depth f or robust and lightweight face presentation attac k detection, Know ledge-Based Sy stems (2025) 114325. [67] S. R. Arashloo, Unseen face presentation attack detection using sparse multiple kernel fisher null-space, IEEE Transactions on Circuits and Systems for Video T echnology 31 (2020) 4084–4095. S. Khan: Preprint submitted to Elsevier P age 13 of 14 CASO P AD [68] S. R. Arashloo, Matr ix-regularized one-class multiple kernel lear ning f or unseen face presentation attack detection, IEEE Transactions on Inf or mation Forensics and Security 16 (2021) 4635–4647. [69] S. Fatemif ar, M. A wais, A. Akbar i, J. Kittler, Particle swarm and pattern search optimisation of an ensemble of face anomaly detectors, in: 2021 IEEE Inter national Conference on Image Processing (ICIP), IEEE, 2021, pp. 3622–3626. [70] S. Fatemif ar, S. Asadi, M. A wais, A. Akbar i, J. Kittler, Face spoofing detection ensemble via multistage optimisation and pruning, Pattern recognition letters 158 (2022) 1–8. [71] N. Daniel, A. Anitha, T exture and quality anal ysis for face spoofing detection, Computers & Electrical Engineering 94 (2021) 107293. [72] X. Shu, H. T ang, S. Huang, Face spoofing detection based on chromatic ed-lbp texture feature, Multimedia Systems 27 (2021) 161– 176. [73] M. Alshaikhli, O. Elhar rouss, S. Al-Maadeed, A. Bouridane, Face- fak e-net: The deep learning method for image f ace anti-spoofing detection: Paper id 45, in: 2021 9th European W orkshop on Visual Inf or mation Processing (EUVIP), IEEE, 2021, pp. 1–6. [74] Z. Li, et al., Facepad: a critical revie w of face presentation att ack detection systems, Patter n Recognition 113 (2022) 107749. [75] J. Zhang, Q. Guo, X. W ang, R. Hao, X. Du, S. Tao, J. Liu, L. Liu, Ucdcn: a nested arc hitecture based on central difference conv olution f or face anti-spoofing, Complex & Intelligent Systems 10 (2024) 4817–4833. [76] Z. Ning, W . Zhang, J. Y ang, Face anti-spoofing based on 3d learnable conv olutional operators, in: 2024 36th Chinese Control and Decision Conf erence (CCDC), IEEE, 2024, pp. 4034–4040. [77] M. Marais, D. Brown, J. Connan, A. Boby , Facial liveness and anti-spoofing detection using vision transformers, in: Sout hern Africa T elecommunication Netw orks and Applications Conference (SA TN AC), volume 8, 2023, p. 2023. [78] S. F atemifar, M. A w ais, A. Akbar i, J. Kittler, Dev eloping a generic framew ork for anomaly detection, Pattern Recognition 124 (2022) 108500. [79] X. Long, J. Zhang, S. Shan, Confidence a ware learning f or reliable face anti-spoofing, IEEE T ransactions on Information Forensics and Security (2025). [80] K. Simony an, A. Zisserman, V er y deep convolutional networks f or large-scale image recognition, arXiv preprint (2014). [81] C. Szegedy , V . V anhouck e, S. Ioffe, J. Shlens, Z. W ojna, Rethinking the inception architecture for computer vision, in: Proceedings of the IEEE conf erence on com puter vision and pattern recognition, 2016, pp. 2818–2826. [82] N. Ma, X. Zhang, H.- T . Zheng, J. Sun, Shufflenet v2: Practical guidelines f or efficient cnn architecture design, in: Proceedings of the European conference on computer vision (ECCV), 2018, pp. 116– 131. [83] H. Cai, C. Gan, T . W ang, Z. Zhang, S. Han, Once-for -all: Train one netw ork and specialize it for efficient deployment, arXiv preprint arXiv:1908.09791 (2019). [84] M. Sandler, A. How ard, M. Zhu, A. Zhmoginov , L.-C. Chen, Mo- bilenetv2: Inv er ted residuals and linear bo ttlenecks, in: Proceedings of the IEEE conf erence on computer vision and pattern recognition, 2018, pp. 4510–4520. [85] S. Meht a, M. Rastegari, Separable self-attention for mobile vision transf or mers, arXiv preprint arXiv:2206.02680 (2022). [86] K. Han, Y . W ang, Q. Tian, J. Guo, C. Xu, C. Xu, Ghostnet: More f eatures from cheap operations, in: Proceedings of t he IEEE/CVF conf erence on computer vision and patter n recognition, 2020, pp. 1580–1589. [87] R. R. Selvaraju, M. Cogswell, A. Das, R. V edantam, D. Parikh, D. Batra, Grad-cam: Visual e xplanations from deep netw orks via gradient-based localization, in: Proceedings of t he IEEE inter national conf erence on computer vision, 2017, pp. 618–626. S. Khan: Preprint submitted to Elsevier P age 14 of 14
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment