콘텐츠 적응형 공간 연산자를 활용한 경량 얼굴 위조 탐지
본 논문은 MobileNetV3에 콘텐츠‑적응형 인볼루션 연산자를 삽입한 CASO‑PAD 모델을 제안한다. RGB 단일 프레임만 사용하며, 위치‑특정·채널‑공유 커널을 동적으로 생성해 스푸핑 힌트를 정밀하게 포착한다. 파라미터 3.6 M, FLOPs 0.64 G, 256×256 입력 기준으로 경량성을 유지하면서 Replay‑Attack, Replay‑Mobile, ROSE‑Youtu, OULU‑NPU 등 4개 데이터셋에서 99 % 이상 정확도와…
저자: Shujaat Khan
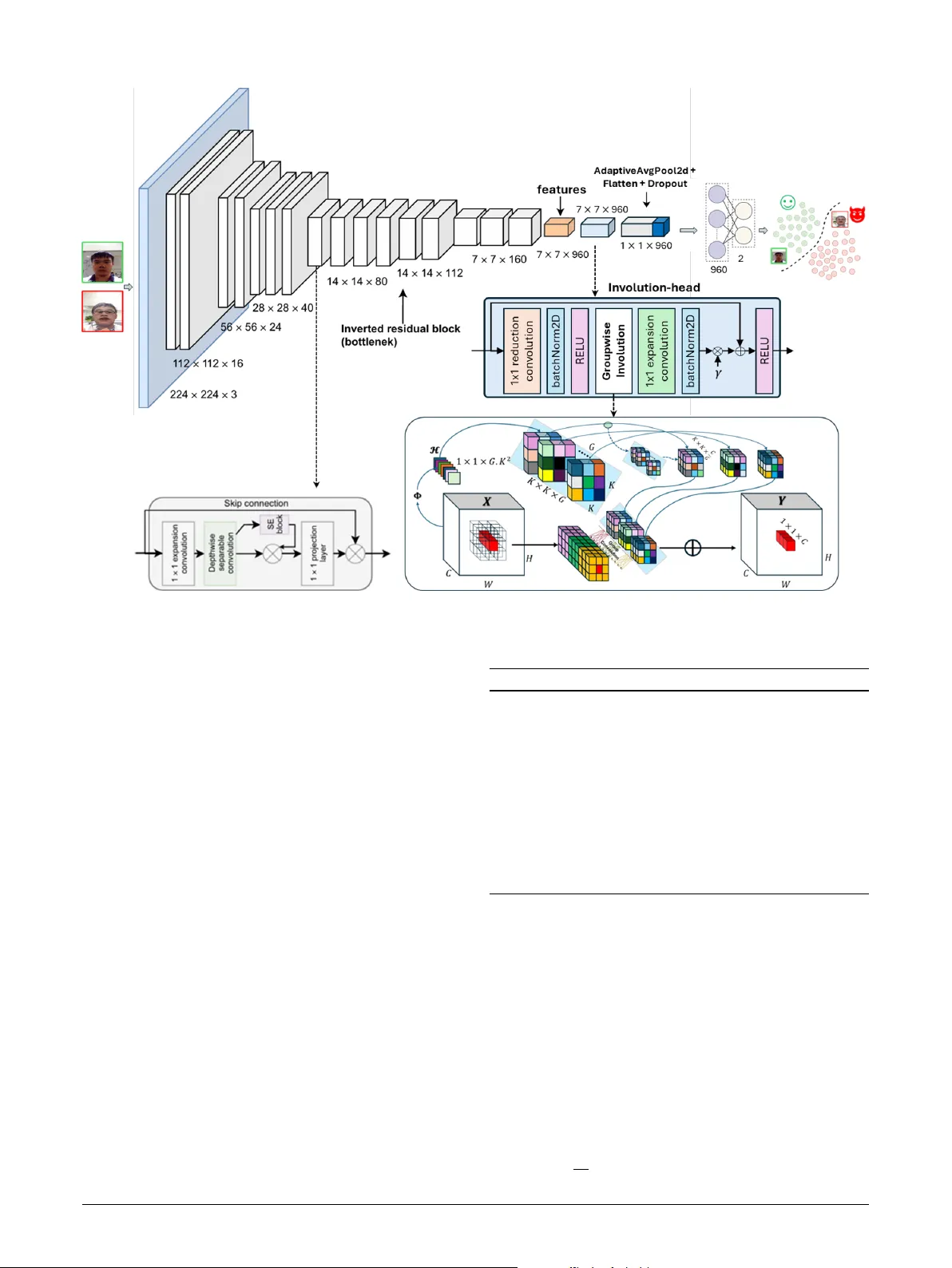
본 연구는 얼굴 인증 시스템에서 프린트, 비디오 리플레이, 3D 마스크 등 다양한 위조 공격에 대응하기 위한 경량화된 얼굴 위조 탐지(Face Presentation Attack Detection, FacePAD) 모델을 제안한다. 기존의 고성능 FacePAD 모델은 대규모 연산량과 멀티모달 센서(깊이, 적외선, rPPG 등)에 의존하거나, 다중 프레임을 이용해 시간적 정보를 활용한다. 이러한 접근은 모바일 디바이스와 같은 제한된 환경에서 실시간 적용이 어려운 단점이 있다.
CASO‑PAD는 이러한 문제점을 해결하고자, MobileNetV3‑Small이라는 이미 검증된 경량 백본에 콘텐츠‑적응형 공간 연산자(involution)를 삽입한다. 인볼루션은 전통적인 컨볼루션과 달리, 입력 특성에 따라 위치‑특정 커널을 동적으로 생성한다. 이때 커널은 채널 전체에 공유되므로 연산량은 크게 증가하지 않는다. 논문에서는 인볼루션을 한 단계 확장한 Group‑Involution(GI) 방식을 도입한다. GI는 채널을 G개의 그룹으로 나누고, 각 그룹마다 위치‑특정 커널을 공유한다. 이렇게 하면 1×1 포인트와이즈 레이어가 채널 간 상호작용을 담당하고, 공간 연산은 그룹‑레벨에서 적응적으로 수행돼 스푸핑 시 발생하는 미세한 텍스처 차이, 반사, 프린트 경계 등을 효과적으로 포착한다.
구조적으로는 MobileNetV3의 초반 레이어(특히 첫 번째 bottleneck) 직후에 GI 레이어를 삽입하고, 이후에는 기존 depthwise separable 컨볼루션과 squeeze‑excitation 블록을 그대로 유지한다. 이 배치는 저해상도 특징을 강화하면서도 전체 모델의 파라미터 수를 3.6 M, FLOPs를 0.64 GFLOPs(256×256 입력) 수준으로 제한한다.
학습은 표준 binary cross‑entropy 손실을 사용하고, 데이터 증강으로 랜덤 크롭, 색상 변형, 가우시안 노이즈 등을 적용한다. 실험은 5개의 대표적인 FacePAD 벤치마크(Replay‑Attack, Replay‑Mobile, OULU‑NPU, ROSE‑Youtu, SiW‑Mv2)에서 수행되었다. Replay‑Attack, Replay‑Mobile, ROSE‑Youtu, OULU‑NPU에서는 각각 100 %, 100 %, 98.9 %, 99.7 %의 테스트 정확도와 AUC 0.9995 이상, HTER 0 %에 근접하는 성능을 기록했다. 특히 대규모 SiW‑Mv2 Protocol‑1에서는 95.45 % 정확도, 3.11 % HTER, 3.13 % EER를 달성해 다양한 공격 유형에 대한 강인성을 입증했다.
Ablation study에서는 GI 레이어의 위치와 그룹 수(G) 설정이 성능에 미치는 영향을 분석했다. 헤드 근처에 배치하고 G를 4~8로 설정했을 때 가장 높은 정확도와 최소 연산량을 동시에 얻을 수 있었다. 또한, 커널 크기를 3×3에서 5×5로 확대하면 미세한 텍스처 감지는 향상되지만 FLOPs가 급증하는 trade‑off가 존재함을 확인했다.
본 논문의 주요 기여는 다음과 같다. (1) 콘텐츠‑적응형 인볼루션을 경량 백본에 효율적으로 통합한 CASO‑PAD 모델 제안, (2) 그룹‑인볼루션을 통해 채널‑그룹 간 효율적인 상호작용을 구현, (3) 다양한 공개 데이터셋에서 최첨단 성능을 달성하면서도 모바일 디바이스에 실시간 적용 가능한 경량성을 확보, (4) 학습된 커널 시각화를 통해 스푸핑 힌트가 어디에서 강조되는지 해석 가능성을 제공.
한계점으로는 단일 프레임 기반이라 동적 생체 신호(눈 깜박임, 입 움직임) 활용이 제한된다는 점이며, 이는 향후 시계열 모델과 결합하거나 멀티모달 센서와 통합해 보완할 수 있다. 또한, 그룹 수와 커널 크기 선택이 데이터셋 특성에 따라 민감하게 변할 수 있어 실제 제품에 적용할 때는 사전 튜닝이 필요하다. 전반적으로 CASO‑PAD는 높은 보안 요구와 제한된 연산 자원을 동시에 만족시키는 실용적인 FacePAD 솔루션으로 평가된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기