Continual uncertainty learning
Robust control of mechanical systems with multiple uncertainties remains a fundamental challenge, particularly when nonlinear dynamics and operating-condition variations are intricately intertwined. While deep reinforcement learning (DRL) combined wi…
Authors: Heisei Yonezawa, Ansei Yonezawa, Itsuro Kajiwara
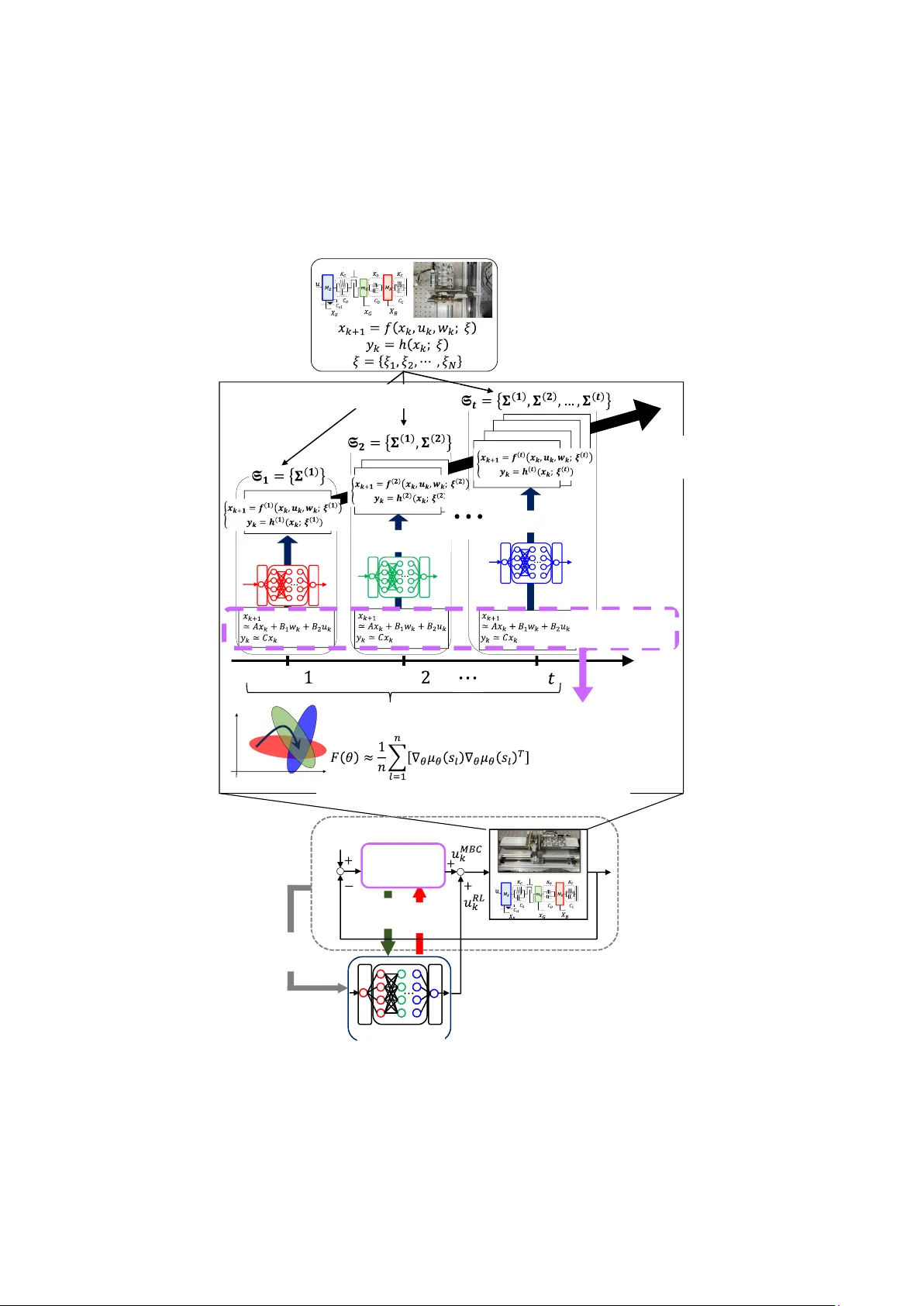
Continual uncertainty learning #1(Correspond ing author) Division of Mech anical and Aerospace En gineering, Hokkaido U niversity N13, W8, Kita-ku, S apporo, Hokkaido 060-8628, Japan E-mail: yonezawah[ at]eng.hokudai.ac.jp #2 Department of Mechanical Engine ering, Kyushu Univ ersity 744 Motooka, Nis hi-ku, Fukuoka 819-0395, Japan #3 Division of Mech anical and Aerospace En gineering, Hokkaido U niversity N13, W8, Kita-ku, S apporo, Hokkaido 060-8628, Japan Abstract we jointly incorporate a model-based cont roller (MBC), w hich guarant ees a shared baseline performance across the pla nt sets, into the l earning process to accel erate the convergence Keywords 1. Introduction 1.1. Motivation In modern industrial applica tions, including automotive powertrain systems [ 1][2] and robotic platform s [3][4], performance demands have be come progressively more stringen t, r esulting in a marked increase in system comp lexity. Such mecha nical systems commonly exhibit nonlinear behaviors [ 5] , communication delays, and uncertain ties induced by variations in system paramet ers [6]. As a consequence, control strategies must be designed to simultaneously address these multiple sources of uncertainty in an integrated manner in order to achieve reliable performance. Model-based control has achieved numerous successes across a wide range of mechanical systems; however, it fundamentally relies on the assumption that accurate and complete models of real -world systems are available. In practice, t his assumption i s rarely satisfied, and performance degradation caused by discrepancies between plant models and real system s is widely recognized as the robust control problem in control theory and as the sim- to -real gap in t he machine learning community. For robotic and a utomotive systems characterized by intertwined parameter variations and strong nonlinearities, conventional robust control approaches, suc h as control [7], are increas ingly reaching th eir practi cal limitation s. Meanwh ile, rapid advances in computat ional resour ces have driven remarkable progress in artificial intelligence, which has recently demonstrated strong potent ial as an alternative co ntrol parad igm through numerous industrial application s. In particular, deep reinforcement learning (DRL) [8][9], emerging from the i ntegra tion of deep neural networks (DNNS) and reinfo rcement learning (RL) [10], has attracted significant attention. A growing body of related work has shown that D RL c an learn practically effective control po licies for nonlinear, complex, large- scale, and high-dimensional plant s such as robotic systems [11], powertrain control [12] and complex vibration control pr oblems [ 13][14][15] wi thout relying on explicit system models. However, since DRL is based on trial-and-error interactions with the environment, learning directly in real -world systems is inherently dangerous [16]. Moreover, collecting the massive amounts of t raining data required through repeated real-world exper iments is often impract ical [17]. 1.2. Related works The success of DRL i s largely attributed to its model -free nature and the generalization capability of DNNs . In recent years, increasing atten tion has been paid to training in simu lation environmen ts using domain randomization (DR) [16][18][19]. In simulation, where safety concerns are eliminated and virtually unlimited t raining data can be generated, DR intentionally injects random variations i nto the parameters of the simulation dynamics during training. Intuitively, by exposing an agent to a wide range of plant dynamics and e ncouraging it to learn policies that perform well across such va riations, robustness against real-world systems ca n be enhanced. As a resu lt, DR has been widely adopted as an effective sim- to -real transfer for complex systems in which m odeling state transition dynamics is challenging, such as r oboti c control [16], locomotion tasks [20][21], and humanoid robots [22][23] . Nevertheless, when the training environment simultaneously involves multiple nonlinear charac teristics and parameter variations, DR is known to produce overly conservative and sub -optima l policies [19]. This is because excessive randomization across many dynamic factors increases uncer tainty perceived by the agent and exacerbates task complexity, t hereby making l earning more difficult and time - consuming. Several approaches have been proposed to address this challenge. Active domain randomization [24] aims to identify the m ost informative r egions of the parameter space by exploiting discrepancies between policy rollouts in randomized and r eference environments, thereby addressing the limitations of uniform parameter sampling. Automatic domain randomization [25] adaptively adjusts the range of parameter r andomization. Specifically, a curriculum strategy is employed in which the randomization strength is gradua lly increased as long as the po licy successfully learn s under the current env ironment . However, when a plant simultan eously exh ibits multiple and diverse sources of u ncertainty, the aforementioned app roaches alone m ay not be sufficient to ac hieve satisfactory pe rformance. In recent years, continual learning ( CL) has attracted substantial attention in the machine learning community [26][27 ][28]. When neural networks are trained on new tasks, they overwrite previously acquired knowledge, a phenomenon commonly referred to as catastrophic forgetting . CL aims to alleviate this difficulty by enabl ing the accumulation of knowledge ac ross a sequence of distinct tasks . Existing C L approaches can be broadly c ategorized int o several c lasses. Regular ization -based methods [26][27] introduce additional constraints into the objective function to prevent parameters that are important for prev iously learned tasks from being excessively updated during t he learning of new tasks. Expansion-based methods [29][30] dynamically extend the network architectur e as new tasks are introduced, while replay-based methods [31] retain a small subset of data from past tasks i n a replay buffer and repeatedly reuse it during subsequent training phases. More recently, these ideas have been further extended to the mor e challenging setting of continual RL [28][32]. Despite t hese advances, CL remains vulne rable to catastroph ic forgetting when the number of tasks increases or when the discrepancy between tasks becomes pronounced [33][34]. Increasing the model capacity ca n mitigate forgetting to some extent [35]; however, this strategy i s o ften i mpractical due to the associated computational and training costs [33][36]. Among empirical studies investigating robustness against forgetting, one not able insi ght is the effe ctiveness o f the pret rain-then-finetune pa radigm in large-sca le language models and image classification networks [37]. This observation implies the importance of first establishing a shared baseline level of perf ormance that is transferable across tasks, prior to task- specific adaptat ion . A natural ques tion that arises here is how such baseline perfo rmance (i.e., nominal performance) is def ined within the framewo rk of robust control theory. 1.3. Contribution and nove lty This study proposes a novel learning framework for acquiring robust control policies for complex controlled plants in which nonlinear characterist ics and parameter variations are intricately intertwined. Trying to address all sources of uncertainty simultaneous ly within a single training process often constitutes a funda mental cause of failure. A natural alternative is to progressivel y accumulat e learning in a sequential manner, while retaining knowledge from previous ly learned policies. The proposed learning approach i s outlined in Fig. 1. This is b uilt upon two key id eas as follows. Motivated by a notable similar work [19], the first key idea i s to decompose the original control problem according to individual sources of uncertainty and to v iew the learn ing pro cess as continua l lear ning, in which strategies for handling each uncertain ty are acquired sequentially. Rather than addressing all nonlinearities and parameter variations simultaneous ly, a robust policy can be obtained more effectively through learning across a sequence of tasks. To this end, we newly define a set of plant models whose dynamic uncer tainties are g radually expanded and diversified as learning progr esses. By incrementall y enlarging this plant set namely, by gradually increasing the difficulty of the learning t asks policies capable of compensating for each source of uncertainty are acquired in a progressive manner. The knowledge obta ined at each task is stab ly accumulated through CL without indu cing abrupt chang es in the policy, i.e., cat astrophic forgetting. The second idea involves the new integration of CL and residual reinforce ment learning (RRL) [38] [39][40]. Inspired by insights from previou s research [37], we incorporate a physical model-based controller (MBC), which guarantees baseline performance for each task (i.e., each plant set), into the learning process to acc elerate t he convergenc e of the re sidual po licy. Conseque ntly, the DRL agent c an focus on task-specific optimization for each uncertai nty by starting from a sha red baseline level of performance. Th is strategy contributes to improved data efficien cy and accelerated learning. In summary, the con tributions and technical novelties o f this study are as fo llows: 1. This s tudy pro poses a new cur riculum-based continua l learni ng algo rithm, re ferred to as con tinual uncertainty learning (CUL), for control problems involving nonlinear systems in which multiple sources of uncertainty are simultaneously superimposed. The original system is extended into a finite set of plant models with progressiv ely expanding uncertainties, and the acquisition of a robust policy is formulated as an optimization proble m with respect to the average performance over this pl ant set. Furthermore, the policy adaptation across the entire plant set corresponding to tasks defined by different uncertainty configurations is formulated as a continual learning process in which t he policy is updated s equentially for each task. 2. To prevent catas trophic forgetting of know ledge associated with previ ously learned uncerta inties, this st udy employs Elastic Wei ght Consolidation (EWC) [26]. Moreover, to avoid the growth of memory storage requ irements with the number of task s, we combine online EWC [41] with Deep Deterministic Policy Gradient (DDPG) [42][43] for pol icy optimization in continuous action spaces. 3. To prevent the degradation of learning efficiency caused by an i ncreasing number of tasks and pronounced inter-task variations, RRL is incorpor ated into the proposed framework. The introduction of MBC, which ensures a baseline level of performance for the plant sets, supports the continual lea rning process and signi ficantly accele rates convergence. 4. As a practical industrial application, this study applies the proposed learning algorithm to the design of an active vibration control system for automot ive powertra ins. Through comparative validation with conventional methods, we confirmed that the resulting policy is robust against structural nonli nearities and dyna mic variations, facilita ting successful sim- to -real t ransfer. Fig. 1 Outline of the proposed approach. This paper proceeds by first defining the problem i n Sect ion 2 and r eviewing standard deep reinforcement learning setups in Section 3. Section 4 presents the proposed m ethod in detail. Its Complexity and diversity Residual gap Residual gap Backlash Dynamical system with multiple uncertainties T ask number T ask T ask T ask DRL agent Model-based controller Facilitate learning Reference value Improve robustness Backlash States, Reward Finite set of plants Continual uncertainty learning Shared baseline performance Linear nominal model Elastic W eight Consolidation (EWC) performance is substantiat ed in Section 5 through num erical experi ments inv olving an uncertain powertrain model, with a focus on active vibration control and r obustness verification. A summary of findings is provide d in Section 6. 2. Problem formulation We consider a disc rete-time nonlinear sys tem described by (1) (2) where , , and denote the system stat e, control i nput, and externa l disturbance at time step , respectively, and represents the control led output. The nonlinear mapping characterizes the state transition dynamics, while defines the system output. Both func tions are subject to uncertainties. The symbol denotes a set of all system uncertaint ies arising from parame ters var iations and nonlinearit ie s, w here each u ncertainty ha s an interna l parameter space . The con trol obje ctive is to de termine the c ontrol inp ut s equence such that the tracking erro r asymptoticall y converges to zero , i.e., where denotes a given reference signal. Under a control policy , the associated finite-horizon optima l control problem over a time horizon is formulated using an immed iate cost function : (3) wher e is a pos itive-definite stage cost . In this paper , we employ the quad ratic stage cost: (4) where and are positive semi-definite and positive definite symmetric matric es, respectively. From the perspective of robust control, the original system can be vi ewed as an uncertain system in which th e linear nominal model i s subjec t to multiple a dditive uncer tainties. For l inear models, opti mal model-based controllers can be easily designed, providing the baseline performance common to each task in CL. For most industrial systems, partially known sys tem dynamics are available to derive the linearized no minal model. The following assu mptions are introduced in this study. Assumption : We have the lineari zed nominal model for the non linear system in Eq s. (1 ) and (2): (5) (6) where , , , and . Sever al methods, including data-driven methods, system identification, and first principle-based model ing, can provide these system matrices . The model-based control input can be generated by designing a model-based linear controller for the above l inear approximation model in t he form of the followin g discrete state -space representation. (7) (8) where , , , and . Here, is an i nternal state vector of the MBC. 3. Deep reinfor cement learning 3.1. Markov decis ion proc ess 3.2. Deep determ inistic policy gradien t (13) (14) (15) 4. Proposed appr oach 4.1. Continual un certainty learning For the system with multiple uncertainties i n Eqs. (1) and (2), w e newly consider a set of nonlinear dynamical sy stems, each o f which has its own structu ral uncertainties such as pa rameter variat ions and nonlinear charact eristics. We then def ine progressive expansion of the plant set f or continual learning. The original plant d ynamics in Eqs. (1) an d (2) depend on a set of uncertainty components, (16) where each represents a distinct source of m odel uncertainty such as parameter variations or nonlinear effect s. Training a controller directly on the plant containin g all components of simultaneously can be difficult due to the l arge variability induced by the com bined uncertainties. To mitigate this difficulty, we propose a stage-wise continual uncertainty learning procedure in which the number of active uncertainty components is gradually in creased. At training s tage , we define the active uncertainty set as (17) As increases, the set of uncer tainties is expanded in the sense that (18) where each contains all uncertainty components introduced in the previous training stages and one additional component . The fi nal stage recovers the original plant with the full uncertainty set . This construction ensures that the complexity of the pl ant set used for CL increases gradually as l earning progresses. Corresponding ly, the plant dynamics added a t training stage are denoted as (19) where and denote the system mappings i n which only the uncertainty components are treated as va riable, while the re maining component s are fixed to nomina l values. The corresponding set of plants ava ilable for training at stage is defined as (20) The goal of this study is to design a learning-based controller that realizes desirable control performance over the entire se t . To formalize the idea that the control policy is t rained on gradually m ore diverse and complex plants, we introduce an increasing sequence of plant sets , ind exed by the tas k training stage . We assume that each plant is associated with a scalar-valued measure of control difficulty, denoted by . This i ndex may reflect stru ctural comp lexity, t he number or magnitude of uncertain parameters, the severity of nonlinear characterist ics, or stability-related properties of the plant. The se quence of plants satisfies a monotonic ordering: (21) Under this assum ption, the sequence of expande d plant sets for CL is defined: (22) naturally represents a curriculum in which the learning algorithm encounters increasingly difficult plants as the t raining advan ces. During the training process, a single new plant is added one at a time at each stage accor ding to (23) This formulation ensures that the training environment grows step -by-step as the learning progresses, rather than incorporating a batch of new pl ants simultaneously. In the final stage, the set of uncertainties becomes , and the plant represents the or iginal system with al l uncertainty com ponents active. Exceptionally, denotes an idealized plant with all uncertainties disabled, i.e., the linearized nominal system in Eqs. (5) and (6 ). At training stage , the control policy is optimized over the plant set . The corresponding learning proble m is gi ven as (24) where denotes a task probability distribution defined over (e.g., uniform distribution), and is the cumul ative cost of policy when applied to pla nt . This formulation allow s the controller to be trained on t he subset of plants available at stage , while progressively adapting to increasing variability in su bsequent stages. We aim to f ind the optimal global p olicy tha t minimize s the expected performa nce with respect to probabi lity distribution across all multip le control tasks. Solving the optimal control problem in Eq. (24) over can be i nterpreted, from the viewpoint of machine lea rning, as a CL problem involving mu ltiple tasks. Here, the con trol of eac h plant corresponding to a specific type of uncert ainty is regarded as an i ndividual task. More specifically , the sequential policy update should be formula ted as the solution t o a regularized optimizat ion problem: (25) where is a regularization term that penalizes abrupt large deviations from the previous policy (e.g., weight-dist ance or K ullback Leibler divergence), and is a coefficient used to have a trade-off between learning a new task and not forgetting already-experienced old tasks. This formulation provides a natural bridge to CL techniques such as weigh t regularization and consolidation . In a sequence of consecutive tasks, a newly introduced plant at a later stage of Eq. (2 3) may differ significantly from those previously used for training, resulting in abrupt discrepancies between tasks. To prevent overfitt ing to such newly introduced plants, a regularization term is incorpor ated. This term suppresses abrupt and excessive changes in the policy, which would otherwise l ead to forgetting previously learned tasks. 4.2. Combination o f online-EWC and DDPG This study empl oys EW C, a regulation-base d CL algorithm insp ired by task-specific synap tic consolidation in the human brain [26]. EWC is an approximate Bayesian approach that enables continual learning across multiple sequential tasks while mitiga ting the forgetting of previously acquired knowledge. EWC alleviates catastrophic f orgetting by selectively sl owing down updates of parameters that are deemed important for past t asks, thereby preserving the performance achieved on t hose tasks without inducing catastrophic forgetting. The importance of each parameter is quantified using t he Fisher information matrix (FIM) [26]. According ly, the l oss function to be minimized during the training of the actor network is augmented with a weighted quadratic penalty based on the parameter importance for past tasks: (26) where denotes the index of each parameter. Here, represents the parameter vector t o be optimized for t he current -th task, and is its -th component. The overall loss function consists of the task-specific l oss for the current task and a regularization term that penalizes too deviations from parameters optimized for previous tasks. The importance of each parameter for the -th task is quantified by , which corresponds to the diagonal elements of FIM computed for ea ch task. The diagonal empirical F IM for the latest task is computed using th e squared gradients of the log-likelihood s of the action pred icted by the actor policy [19]: (27) where and denote the input and ou tput of the policy network, and the number of samples in the replay buffer is rep resented as . However, standard EWC requires storing t he FIMs and the optimal parameters for all previously learned tasks (i.e., plant uncertainties), which leads to substantial storage requirem ents. To alleviate this issue, this study proposes integrating online-EWC [41] wi th D DPG. Specifically, only the optimal parame ters and the correspon ding online FIM from the most recent task ar e retain ed, and the following loss function is minimized: (28) The online F IM is updated using the Fisher information of the current task and a hyperparameter : (29) The quantification of parameter importance using FIM can be extended to DDPG with a deterministic policy as follows [44]: (30) (31) where the importance of each parameter for the previo us task is m easured by , which correspon ds to the diagonal elements of . 4.3. Latent Markov d ecision process To enhance the gene ralization cap ability of the ac tor policy, this s tudy consistently applies DR throughout the CL process. Specifically, for the environment model selected at each episode, the uncertain dynamics parameters are r andomly sampled according to a probabil ity di stribution . Accordingly, the environment dynamics are modeled as a latent MDP, which consists of a collection of MDPs with varying dyn amics [18,45,46]. Formally, a set of parameters parameterize the dynamics of the plant simulator [16]. Let denote a collection of finite-horizon MDPs with horizon , each corresponding to a different realization of the parameters . The resulting LMD P is represented as , where specifies the distribution of over [18][45]. Under this formulation, the objective function can be defined based on the expec ted return over the di stribution of dynamics model [16,18,45 ]: (32) where the likelihood of a trajectory is denoted by under the policy . Therefore, the le arning problem in E q. (25) is more specifical ly formulated: (33) 4.4. Residual reinfor cement learning As the number of tasks increases or the discrepancy between consecutive tasks becomes pronounced, the lea rning ef ficiency of CL may de teriorate. I n additi on, solving the op timization problem in Eq. (33) that i nvolves three nested expectation operators requires a substantia l number of samples. To mitigate this issue, this study integrates MBC into the training process, thereby accelerating learning progress and improving adaptation across tasks. Th is improvement arises from the fact that MBC in Eqs. (8) and (9) provides a shared baseline perform ance that captu res fundamental control behaviors common across plant sets . Consequently, MBC relieves t he DRL agent fr om the need to learn the base control structure from scratch, allowing it to focus instead on compens ating for each residual gap between a base line level of performance an d the desired opt imal behavior. Accordingly, we define the control i nput based on a l inear combinat ion o f the MBC i nput and the DRL as follows: (34) (35) In the above fra mework, the s tate transit ion of the training en vironment , which is randomly sampled at the beginning o f each episode, satisfies the Ma rkov property [10][47] as fo llows: (36) where t he state of the closed loop system is denoted by . Accordingly, we can theoretically for mulate LMDP even with Eq. (34). The proposed learn ing algorithm is outlined in Algo rithm 1 . Algorithm 1: The CUL Al gorithm. 1 Input: Environment and trajectories pool 2 Output: Optima l policy 3 Randomly initial ize the critic parameters and th e policy paramete rs. 4 Design an MBC w ith a linearized nominal mode l . 5 for each task do 6 increase the act ive uncertainty set. 7 expand the set of plant dynamics. 8 for each episode do 9 randomly select a plant from . 10 randomly samp le dynamics for in DR. 11 randomly selected env ironment. 12 Generate rollout with dyn amics and . 13 14 DRL control inpu t from the actor p olicy . 15 combination of the DRL policy and the model-based control . 16 for each gradien t step do 17 Update the critic p arameters by min imizing the mean squared er ror. 18 Compute the actor loss with a weighted quadratic penalty based on the parameter importance. 19 Update the actor par ameters using the samp led policy gradient. 20 with update. 21 update the hybrid con trol. 22 end 23 end 24 Compute the Fishe r information of the cu rrent task. 25 Save the snapshot o f the optimal actor parameters of the current task. 26 end 5. Numerical verification 5.1. Active vibration con trol of a pow ertrain system w ith multiple uncertain ties This se ction evaluates the proposed continual learning framework through numerical verifications simulating an active vibration control problem of an automotive powertrain system. The powertrain dynamics involve heterogeneous uncertainties, including parametric variations, operating -conditio n changes, and nonlinear effects, all of which are known to complicate vibration suppression [12]. Th e system overview is shown in Fig. 2. A nonli near automotive powertrain model [ 48][49] is considered, where the controlled output is the vehicle body vibration response . The control objective is to attenuate transient vibrations by applying a control input to the actuator such that t he tracking error converges to zero , as stated in Section 2. In addition to nominal dynamics shown in Table 1, the system is subject to the following source s of uncertainty: 1. Mass variations in the vehicle body and the actuator ; 2. Damping coeffic ients variations in t he drivetrain , , and ; 3. Operating-condition chang es, represented by va riations in the reference signal ; 4. Nonlinear dynam ics arising from mechanical backlash, w hich has the va rious width , in the drivetra in. In particular, t he backlash i ntroduce s a dead-zone nonlinearity that causes disc ontinuou s mode switching between contact and non-contact phases , thereby increasing control difficulty. The coexistence of these uncertainties motivates the adoption of a learning-based control framework capable of systematic adapt ation under progressive ly more challenging c onditions. Fig. 2 Complex pow ertrain system with mul tiple uncertainties. To design an MBC in Eqs. (7) and (8), a linearized nominal model of the powertrain system is employed, where backlash effects and paramete r va riations are neglected. Based on this no minal model, an output - feedback controller is designed using standard linear control theory [50][51]. For powertrain applications, a fe edforward term is incorporated into the contro ller. Mechanical connection Backlash traverse Backlash mode Contact mode Disconnection by gap Mechanical contact Force Nonlinear Backlash Parameter distribution Actuator mass variation Parameter distribution V ehicle body mass variation Parameter distribution Damping coefficient variation Parameter distribution Damping coefficient variation Parameter distribution Damping coefficient variation Powertrain with multiple uncertainties Control input Fig. 3 App lication of the proposed learning fra mework to active vibration control of the powertrain sys tem. 5.2. CL task des ign with progressive unc ertainty expansion To explicitly assess CL under increasing control difficulty, a sequence of learning tasks is constructed by gradually expan ding the set of plan t uncertainties. Five tasks are defined as follo ws. • Task 0 : The linear n ominal model is cons idered. All param eters are fixed at their nominal values listed in Table 1, the re ference signal is also fixed, and no backlash nonlin earity is present. • Task 1 ( ) : In addi tion to Task 0, domain randomization is applied to the masses and . The reference signal is randomly sampled at the begin ning of each episode. Model-based controller FC ReLU FC ReLU FC ReLU FC ReLU Action Observation Observation Action V alue Critic Actor DDPG agent Control input Model-based control signal Uniform randomize dynamics parameter Time Time Time Environment 1 Environment 2 Environment N Sample T rajectory 1 T rajectory 2 T rajectory N T raining Latent MDP Backlash Control input Real -world environment State A set of plant dynamics 1 T ask distribution EWC • Task 2 ( ) : Building upon Tasks 0 and 1, domain randomizati on i s further applied to the damping coefficients , , and , introducing add itional parametric unce rtainty in the driv etrain. • Task 3 ( ) : A f ixed-width backlash nonlinearity is introduced, structurally transforming the pow ertrain i nto a nonlinear system. Th e randomization range of the reference signal is also enlarged to inc rease operating-condit ion variability. • Task 4 ( ) : In addi tion to all uncertainti es considered in Tasks 0 3, t he backlash width itsel f is randomized, making the nonl inear characteristics subject to domain randomization. Through Tasks 0 4, both the type and extent of uncerta inties are monotonically in creased, resulting in a curriculum where control di fficulty progressively grows. This task sequence enabl es systema tic investigation of CL whe n robustness must be a ccumulated across heterog eneous uncertaintie s. 5.3. Verification settings The reinforcement l earning agent observes the reference signal, the vehicle body vi bration , t he tracking error, its integral and derivative, and the control input from MBC. All ob servation componen ts are normalized to facilitate stable learning. The reward is defined as t he negative of a quadratic stage cost in Eq. (4) that penalizes tracking error and control effort. The choices of and are available in the literature [12]. For each task, the unce rtain parameters associated with the corresponding uncertainty set are randomized at the beginning of every ep isode acco rding to uniform d istributions. The hyp erparameters involved in the proposed algorithm are summarized in Table 2. The parameter vari ation rang es used for each uncertain ty are listed in Table 3. All training and ev aluation procedu res are conducted in MATLAB R2024b. The procedure is outlined in Fig. 3. We implement multiple baselines for compa rison: 1. No MBC : CL (i.e., online-EWC- DDP G ) is conducted without MBC. 2. Full randomizat ion : The policy is trained by activating all the uncertaintie s together at the same time from the begin ning without any CL , while th e support by MBC is present. 3. Only MBC : A model-based linear controller al one is direct ly app lied to the pow ertrain system (referred to as O nly MBC ), which has no compensation for p arametric va riations a nd nonlineari ty. Tab le 2. Hy perpa ramete rs for the pr oposed algor ithm. Hype rparam eter Value Samp ling ti me s Crit ic lea rning rate Actor lear ning r ate Disco unt fa ctor Exp loratio n nois e Ornst ein-Uh lenbe ck Act ion No ise Numb er of the neu rons i n the h idden layer s Size of th e mini-b atch Size of th e repla y buf fer Targe t smo oth fac tor Hor izon Netw ork ar chitec ture Fully conne cted + ReLu Numb er of e pisode s Numb er of e pisode s on e ach t ask EWC reg. c onst . EWC replay batch EWC replay sampl es onli ne-EWC Tab le 3. Ra ndomi zed pa ramet ers. Para meter Rang e Vehic le bod y mas s: Nomin al va lue : Actua tor m ass: Nomin al va lue : Damp ing coe ffic ient: Nomin al va lue : Damp ing coe ffic ient: Nomin al va lue : Damp ing coe ffic ient: Nomin al va lue : Lengt h o f bac klash : (rand omized only in Scena rio 2 ) Nomin al va lue : Steady value of the referenc e sign al from 0 to 2s: Steady value of the referenc e sign al from 2 to 4s: 5.4. Results and di scussion Figure 4 shows the training curves i n terms of episode rewards obtained by each DRL-based m ethod. The continual le arning task is switched e very 100 episo des. Compared with the proposed method (red line), No M BC (cyan line) requires a larger number of episodes to converge and exhibits an unstable learning process. In particular, a noticeable degradatio n in episode rewards i s observed between 200 and 400 episodes, which suggests pronounced discrepancies between consecutive tasks. In the absence of MBC, which provides a baseline performance, the agent must learn control behavio rs from scratch. As a result, inc reased exploration is required, rendering t he learning process m ore vulnera ble to task switching. In contrast , the proposed method follows a stable learning trajectory without engaging in unnece ssary exploration. The rapid convergence achieved with fewer episodes indicates that MBC effectively improves the learning efficiency in CL . Full ra ndomization shows immediate and significant r eward fluctuations, while the proposed method s reward varianc e grows i ncrementa lly over episodes. This r eflects the differing learning mechanisms , i.e., full randomizat ion jointly incorpora tes all randomized uncerta inties in all episodes. Fig. 4 Reward curve. Figure 5 illustrates the control results for the linear nominal system, where the upper and lower plots represent the time histories of the vehicle body vibration and the control input, respectively. Table 4 provides a quantitative comparison of the considered m ethods by evaluating t he 2-norm of the control error from the ideal reference res ponse (green li ne in Fig. 5). All active control methods achieve sufficient vib ration suppression compared with the ope n-loop response (blue line). The slight overshoot observed in the magenta line suggests a conserva tive policy induced by full randomization . According to Table 4, only MBC achieves the best performance. Since the plant considered in Fig. 5 contains no uncertainties and si m- to -real gap is absent, this result is theo retically reasonable. The combinations of parameter variations ar e virtually i nfinite with in the r anges listed in Table 3. Therefore, this study presents results for several representative cases, specifically those corresponding to verification conditions where each characteri stic takes its m aximum or minimum deviation. Figures 6 8 show the corresponding control results, and Tables 5 7 provide quantitative evaluations of Figs . 6 8 based on the 2-norm of the tracking error, respect ively. In all verification cases, the proposed method achieve s the smallest norm values, thereby demonstrat ing superior robust ness. In Fig. 6, in con trast to the proposed method ( red l ine), which achieves sa tisfactory tracking performance, No MBC (cyan li ne) exhibits sustained vi brations. As discussed in Fi g. 4, this result indicates that t he presence or absence of MBC affects not only the efficiency of CL but also th e robustness of the resulting policy. From the immaturity of the learning process observed i n Fig. 4 and the insufficien t vibration su ppression in F ig. 6, it can b e concluded th at the curren t number of e pisodes may be inadequate for solely leveraging DRL . In other words, without the baseline performance ensu red by MBC, t he sample efficiency of C L deterio rates. Although there exist con ditions under which satisfactory con trol performance is achieved, as shown in Fig . 7 and Table 6, the e ffects of insuffi cient learning convergence become evident when the reference value corresponding to driving conditions in real vehicles changes drastically, as illustrated in Fig. 6. This can be attributed to t he fact that learning with DRL alone does not provide extrapolation ca pability based on physical laws ; consequently, when the discrep ancies between tasks are pronounced, the agent is forced to reacquire baseline control action through trial-and-error. From this perspective, the comparison between t he red and cyan lines de monstrates that MBC plays a crucial role in improving the learn ing efficiency. Although full randomizati on maintains robustness under many conditions, residual vibrations and overshoot are observed in Fig s. 7 and 8. This is due to the learning process i n which all uncertainties are handled simultaneousl y within a single training stage. When numerous parameters are domain - randomized from the outset in addition to nonlinear characteristics, the training environment becomes excessively uncertain, making it difficult for the DRL agent to acquire appropriate control behaviors. As a result, t he resulting policy is robust but tends to be overly conservative . For example, in Figs. 6 8, fu ll random ization exh ibits w eak sup pression of ov ershoot immediately after the driving condition is switched at 2 s econds. This behavior stems from insufficient learning of how t o handle t he backlash nonlinearity. When multip le uncertainties are addressed simultaneou sly during training, t he learnin g for each i ndividual unc ertainty can beco me incomplete, pot entially leading to the negl ect of certain dynamics. Consequent ly, the comparison between the red and magenta li nes supports the necessity of CL in which environm ental uncertainties are p rogressively expan ded and diversified. The control perfor mance achieved by Only MBC exhibits significant variability depending on th e uncertainty conditions. For instance, w hile perfo rmance com parable to t he p roposed me thod is attaine d in Fig. 6, a noticeable degradation approaching the stability limit is observed in Fig . 7, where the mass i s smaller and vibrations are more easily excited. From the presence of the sim- to -real gap, such variability in performance is reasonable and will be discussed in the next section. Compared with t he black line, t he red and magenta lines demonstrate the improved generalization capability of DRL through domain r andomization. Fig. 5 Time responses of the vehicle body vibration (upper graph) and the control input (lowe r graph) for the linea r nominal system. Fig. 6 Time responses of the vehicle body vibration ( upper graph) and the control i nput (lower graph) with , , , , , , , and . Fig. 7 Time responses of the vehicle body vibration ( upper graph) and the control input (lower graph) with , , , , , , , and . Fig. 8 Time responses of the vehicle body vibration ( upper graph) and the control i nput (lower graph) with , , , , , , , and . 5.5. Monte Carlo s imulation To statisticall y eva luate the control performanc e of each method, Monte Car lo s imulations were conducted. Spec ifically, each method was applied t o 100 plant instance s generated by randomly perturbing the uncertain ty-related parame ters, and their cont rol performance s were stati stically analyzed. Figure 9 presents the mean time-history r esponses obtained over the 100 trials. In addition, Table 8 r eports the mean and standard deviation of the 2 -norm of the control error across the 100 simulations. The proposed method ac hieves the best overall control performance, indicating the most stable cont rol on average across various plant variation s. In particular, as shown in Table 8, the proposed method attains the smallest standard deviation, demonstrating m inimal variability in control performance with respect to plant variat ions. This is due t o the curriculu m that progressively and syste matically acquires robustness against uncertainties, together with the stable policy updates enabled by EWC. In contrast, Only MBC exhibits a con siderably large r standard deviat ion, suggesting su bstantial perfo rmance variability a nd the existe nce of plan t conditions under which con trol performance deteriorates significantly. Full randomization achieves the second smallest standard deviation. While jointly randomizing all uncertainties often leads to a sub-optimal policy, it can still m oderate performanc e variability. The poor results of No MBC reflect insufficient learning maturity. As suggested in prior work [ 37], optimizing individual tasks without a f oundational shared performance not only requires more training da ta but also increases vulne rability to abrupt ta sk transitions. Fig. 9 Mean time responses of 100 trials when random variations are applied to the powertra in parameter s. 6. Conclusion CRediT au thorship contri bution statement Heisei Y onezawa Ansei Y o nezawa Itsuro Kajiwara Declaration of co mpeting inter est Acknowledgmen t Referenc es [1] F. Wang, T. Wu, Y. Ni, P. Ye, Y. Cai , J. Guo, C. Wang, Torsional oscillatio n suppression- oriented t orque compensate control for regenerat ive braking of electric powertrain based on mixed logic dynamic mode l, Mech. Syst. Si gnal Process. 190 (2023) 110114. https://doi.org /10.1016/j.ymssp.2023.110114. [2] F. Wang, P. Ye, X. Xu, Y. Cai, S. Ni, H. Que, Novel regenerative braking method for transien t torsional oscillation suppression of planetary-gear electrical powertrain, Mech. Syst. Signal Process. 163 (2022) 1 08187. https://doi.org /10.1016/j.ymssp.2021. 10 8187. [3] C. Wu, K. Guo, J. Sun, Y. Liu, D. Zheng, Active vibration control in roboti c grinding using six- axis accelerat ion feedback, Mech. Syst. Signal Process. 214 ( 2024) 111379. https://doi.org /10.1016/j.ymssp.2024.111379. [4] S. Zaare, M.R. Soltanpour, Adaptive fuzzy global coupled nonsingu lar fast termi nal sliding mode co ntrol of n-rigid-link elastic-joint robot manip ulators i n presence of u ncertainties, Mech. Syst. Signal Proce ss. 163 (2022) 108165. https://doi.org/10.1016 /j .ymssp.2021.1 08165. [5] Y. Yang, C. Liu, T. Zhang, X. Zhou, J. Li, Event -triggered composite sliding mode anti-sway control for tower crane systems and experimental verif ication, Mech. Syst. Signal Process. 230 (2025) 112578. h ttps://doi.org/10.1016 /j.ymssp.2025.112578. [6] Z. Xu, G. Qi, Q. Liu, J. Yao, ESO-based adaptive full state constraint control of uncertain systems and its application to hydraulic servo systems, Mech. Syst. Signal Process. 167 (2022) 108560. https://doi. org/10.1016/j.ymssp.2021.1 08560. [7] S. Xu, X. Liu, Y. Wang, Z. Sun, J. Wu, Y. Shi, Frequency shaping- pneumatic vibration isolation with input voltage saturation, Mech. Syst. Signal Process. 220 (2024) 111705. h ttps://doi.org/10.1016 /j.ymssp.2024.111705. [8] V. Mni h, K. Kavukcuoglu, D. Sil ver, A. Graves, I. Antonoglou, D. Wierstra, M. Riedmiller, Playing Atari with Deep Reinforcement Learning, ArXiv Prepr. (2013). https://doi.org /https://doi.org/10.48550/arX iv.1312.5602. [9] V. Mnih, K. Kavukcuoglu, D. Silver, A.A. Rusu, J. Veness, M.G. Bellemare, A. Graves, M. Riedmiller, A.K. Fidjeland, G. Ostrovski, S. Petersen, C. Beattie, A. Sadik, I. Antonoglou, H. King, D. Kumaran, D. Wi erstra, S. Legg, D. Hassabis, Human-level control through deep reinforcement learning, Nature. 518 (20 15) 529 533. https://doi.org/10.1038 /nature14236. [10] R.S. Sutton, A.G . Barto, Reinforc ement l earning: An introduction, 2nd ed., MIT Press, Cambridge, 2018. [11] G. Chen, Z. Ch en, L. Wang, W. Zhan g, Deep Determ inistic Policy Gradien t and Act ive Disturbance Rejection Controller based coordinated control for ge arshift manipulator o f driv ing robot, Eng. Ap pl. Artif. Intell. 117 (2023 ) 105586. https://doi.org /10.1016/j.engappai.2022.105586 . [12] H. Yonezawa, A. Yonezawa, I. Kajiwara, Model-based controller assisted domain randomization for transient vibration suppression of nonlinear powertra in sys tem with parametric uncertain ty, Mech. Syst. Signal Process. 241 (202 5) 113570. https://doi.org /10.1 016/j.y mssp.2025.113570. [13] J. Panda, M. Chopra, V. Matsagar, S. Chakraborty, Co ntinuous control of structural vibrations using hybrid deep reinforcem ent learning policy, E xpert Syst. Appl. 252 (2024) 124075. https://doi.org /10.1016/j.eswa.2024.124075. [14] Z. Qiu, Y. Liu, X. Zhang, Reinforcement learning vibrat ion control and trajectory plannin g optimization of translatio nal flexible hinged plate system, Eng. Appl. Artif. Intell. 133 (2024) 108630. https://doi. org/10.1016/j.engappa i.2024.108630. [15] C. Wang, W. Cheng, H. Zh ang, W. Dou, J. Chen, An immune optimization dee p reinforcement learning control method used for magnetorheologica l elastomer vi bration absorber, Eng. Appl. Artif. Intell. 137 (2024) 109108. https: //doi.org/10.1016/j.enga ppai.2024.109108. [16] X. Bin Peng, M. Andrychowicz, W. Zaremba, P. Abbeel, Sim- to -Real Transfer of Robotic Control with Dynamics Randomization, in: 2018 IEEE Int. Conf. Robot. Autom., IEEE, 2018: pp. 3803 3810. htt ps://doi.org/10.1109/IC RA.2018.8460528. [17] T. Slawik, B. We hbe, L. Christensen, F. Kirchner , Deep Reinforcemen t Learning for Path - Following Control of an Autonomous Surface Vehicle using Domain Randomiz ation, IFAC- PapersOnLine. 58 (2024) 21 26. https://doi.o rg/10.1016/j.ifacol.202 4.10.027. [18] J. Zhang, C. Zh ao, J. Ding, Deep reinforcemen t learning with domain randomization for overhead crane control with payload mass variations, Control Eng. Pract. 141 (2023) 105689. https://doi.org /10.1016/j.conengprac.2023.105 689. [19] J. Josifovsk i, S. Auddy, M. Malmir, J. Piater, A. Knoll, N. Navarro-Guerrero, Continual Doma in Randomization, in: 2024 I EEE/RSJ Int. Conf. Intell. Robot. Sys t., IEEE, 2024: pp. 4965 4972. https://doi.org /10.1109/IROS58592.2024.108020 60. [20] X. Bin Peng, E. Coumans, T. Zhang, T.-W. Lee, J. Tan, S. Levine, Learning Agile Robotic Locomotion Skills by Imitating Animals, i n: Robot. Sci. Syst., Robotics: Science and Systems Foundation, 2020. https://doi.org/10.15607 /RSS.2020.X VI.064. [21] Z. Li, X. Cheng, X. Bin Peng, P. Abbeel, S. Levine, G. Berseth, K. Sreenath, Reinforcement Learning for Robust Parameterized Locomotion Control of Bipedal Robots, in: 2021 IEEE Int. Conf. Robot. Autom., IEEE, 2021: pp . 2811 2817. https://doi.org /10.1109/ICRA48506.2021.956076 9. [22] Q. Liao, B. Zhang, X. Huang, X. Huang, Z. Li, K. Sreena th, Berkeley Humanoi d: A Research Platform for Learning-based Control, ArXiv Prepr. (2024). https://doi.org /https://doi.org/10.48550/arX iv.2407.21781. [23] X. Gu, Y.-J. Wang, X. Zhu, C. Shi, Y. Guo, Y. Liu, J. Chen, Advanc ing H umanoid Locomotion: Mastering Challenging Terrains with Denoising World Model Learning, in: Robot. Sci. Syst., Robotics: Scienc e and Systems Foundation, 202 4. https://doi.org/1 0.15607/RSS.2024.XX.058. [24] B. Mehta, M. Diaz, F. Gole mo, C.J. Pal, L. Paul l, Active Domain Randomization, in: Proc. Conf. Robot Learn. PMLR, 2020: pp. 1162 1176. https://doi.org /https://doi.org/10.48550/arX iv.1904.04762. [25] 51. https://doi.org /https://doi.org/10.48550/arX iv.1910.07113. [26] J. Kirkpatrick, R. Pascanu, N. Rabinowitz, J. Veness, G. Desjardins, A.A. Rusu, K. Milan, J. Quan, T. Ramalho, A. Grabska-Barwinska, D. Hassabis, C. Clopath, D. Kumaran, R. Hadsell, Overcoming catastrophic forgett ing in neural netwo rks, Proc. Natl. A cad. Sci. 114 (2017) 3521 3526. https://doi.o rg/10.1073/pnas.161183511 4. [27] R. Aljundi, F. Babiloni, M. Elhoseiny, M. Rohrbach, T. Tuytelaars, Memory Aware Synapses: Learning What (not) to Forget, in: Lect. Notes Comput. Sci. (Including Subser. Lect. Notes Artif. Intell. Lect. Notes Bioinformatics), 2018: pp. 144 161. https://doi.org/10.1007/978-3- 030- 01219-9_9. [28] K. Khetarpal, M. Riemer, I. Rish, D. Pre cup, Towards Continual Reinforce ment Learning: A Review and Perspectives, J. Artif. Intell. Res. 75 (2022) 1401 1476. https://doi.org /10.1613/jair.1.13673. [29] A.A. Rusu, N.C. Rabinowitz, G. Desjardins, H. Soyer, J. Kirkp atrick, K. Kavukcuog lu, R. Pascanu, R. Hadsell, Progressive Neural Networks, ArXiv Prepr . (2022). https://doi.org /https://doi.org/10.48550/arX iv.1606.04671. [30] J. Yoon, E. Yang, J. Le e, S.J. Hwang, Lifelong L earning with Dynamica lly Expandable Networks, 6th I nt. Conf. Learn. Represent. ICLR 2018 - Conf. T rack Proc. (2018) 1 11. https://doi.org /https://doi.org/10.48550/arX iv.1708.01547. [31] D. Rolnick, A. Ahuja, J. Schwarz, T.P. Lillicrap, G. Wayne, Experience Replay for Continual Learning, Adv. Neural Inf. Process. Syst. 32 (2019). https://doi.org /https://doi.org/10.48550/arX iv.1811.11682. [32] J. Josifovski, S. Gu, M. Malmir, H. Huang, S. Auddy, N. Navarro-Guerrero, C. Spanos, A. Knoll, Safe Continual Domain Adaptation after Sim2Real Transfer of Reinforcement Learning Policies in Robotics, ArX iv Prepr. (2025). https ://doi.org/https://doi.o rg/10 .48550/arXiv. 2503.10949. [33] -Task Assoc iation in Co ntinual Le arning, in: Comput. Vis. ECCV 2022 17th Eur. Conf., 2022: pp. 519 535. https://doi.org /https://doi.org/10.1007/978-3-031- 20083-0_31. [34] S. Roy, V. Verma, D. Gupta, Efficient Expansion and Gradient Based Task Inferenc e for Replay Free Incremental Learning, i n: Proc. IEEE/CVF Winter Conf. Appl. Comput. Vis., 2024: pp. 1165 1175. https:/ /doi.org/https://doi.org /10.48550/arXiv.2312.0 1188. [35] S. Iman Mirzadeh, A. Chaudhry, D. Yin, H. Hu, R. Pascanu, D. Gorur, M. Farajtabar, Wide Neural Networks Forget Less Catastrophica lly, in: Proc. 39th Int. Conf. Mach. Learn. PMLR, 2022: pp. 15699 1571 7. https://doi.org/ht tps://doi.org/10.48550 /arXiv.2110.11526. [36] J. Zhang, J. Zhang, S. Ghosh, D. Li, J. Zhu, H. Zhang, Y. Wang, Regularize, Expand and Compress: NonE xpansive Continual Learning, in: Pro c. I EEE/CVF Wi nter Con f. Appl. Comput. Vis., 2020: pp. 854 8 62. https://doi.org/10.1 109/WACV45572.2020. 9093585. [37] V. Ramasesh, A. Lewkowycz, E. Dyer, EFFECT OF MODEL AND PRETRAINI NG SCALE ON C ATASTROPHIC FORGETTI NG IN NEURAL N ETWORKS, in : Tenth Int. Conf. Learn. Represent. ICLR 2022, 2022: pp. 1 33. https: //openreview.net/forum ?id=GhVS8_yPeEa. [38] T. Johannink, S. Bahl, A. Nair, J. Luo, A. Kumar, M. Loskyll, J.A. Ojea, E. Solow jow, S. Levine, Residual Reinforce ment Learning for Robot Control, in: 2019 Int. Conf. Robot. Auto m., IEEE, 2019: pp. 6023 6029. https://doi.org/10.1109/I CRA.2019.879412 7. [39] Y.T. Liu, E. Price, M.J. Black, A. Ahmad, Deep Residual Re inforcement Learning base d Autonomous Bl imp Control, in: 2022 IEEE/RSJ In t. Conf. Intell. Ro bot. Syst., IE EE, 2022: pp. 12566 12573. http s://doi.org/10.1109/IR OS47612.2022.9981182. [40] Reinforcement Learning, in: 2023 IEE E 19th I nt. Conf. Autom. Sci. Eng., IEEE, 2023: pp . 1 8. https://doi.org /10.1109/CASE56687.202 3.10260561. [41] J. Schwarz, J. Luketina, W.M. Czarnecki, A. Grabska-Barwinska, Y.W. Teh, R. Pascanu, R. Hadsell, Progress & Compress: A scalable framework f or continual learning, 35th Int. Conf. Mach. Learn. IC ML 2018. 10 (2018) 71 99 7208. http://arxiv.or g/abs/1805.06370. [42] D. Silver, G. Lever, N. Heess, T. Degris, D. Wierstra, M. Riedmiller, Deterministic policy gradient algorithm s, in: 31st Int. Con f. Mach. Learn. IC ML 2014, 2014: pp. 387 395. [43] T.P. Lillicrap, J.J. H unt, A. Pri tzel, N. Heess, T. Erez, Y. Tassa, D. Silver, D. Wierstra, Continuous control w ith deep r einforcement learning, in: 4th Int. Con f. Learn. Represent. ICLR 2016 - Conf. Track P roc., 2015. http [44] J. Ruan, J. Xia, J. Hu, H. Wan, Y. Li, Y. Q in, Continuous learning energ y manage ment strategy design based on EWC-DDPG for electric vehicles, Energy. 335 (2025) 138158. https://doi.org /10.1016/j.energy.2025.138 158. [45] X. Chen, J. Hu, C. Jin, L. Li, L. Wang, Understanding Domain Randomization for Sim - to -rea l Transfer, in: ICLR 2022 - 10th Int. Conf. Lear n. Represent., 2021: pp. 1 28. https://doi.org /https://doi.org/10.48550/arX iv.2110.03239. [46] J. Kwon, Y. Efr oni, C. Caramanis, S. Mannor, RL for Latent MDPs: Regret Guarantees and a Lower Bound, Adv. Neura l Inf. Process. Syst. 34 (2021) 24523 24534. https://doi.org /https://doi.org/10.48550/arX iv.2102.04939. [47] Y. Okawa, T. Sasaki, H. Iwane, Control Approach Combining Reinforcement Learning and Model-Based Control, in: 2019 12th Asian Control Conf. ASCC 2019, JSME, 20 19: pp. 1419 1424. [48] H. Yonezawa , A. Yonezaw a, T. Hatano, S. Hiramatsu, C. Nishidom e, I. Kajiwara, Fuzzy - reasoning-based robust vibrati on controller for drivetra in mechanis m with variou s control input updating timings, Mech. Mach. Theory. 175 (2022) 104957. https://doi.org /10 .1016/j.mechm achtheory.2022.10495 7. [49] H. Yonezawa, A. Yone zawa, I. Kajiwara, Expe rimental validation o f adaptive grey w olf optimizer-based powertrain vibration control with back lash h andling, Mech. Mach. Theory. 203 (2024) 105825. h ttps://doi.org/10.1016 /j.mechmachtheory.2024.105 825. [50] Trans. Automa t. Contr. 41 (1996) 358 367. ht tps://doi.org/10.1109 /9.486637. [51] Zhou K, Doyle JC, G lover K, Robust and Opt imal Control, Pren ticeHall, New Je rsey, 1996.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment