연속 불확실성 학습을 통한 강인 제어 정책 설계
본 논문은 비선형 기계 시스템에서 다중 불확실성을 효과적으로 다루기 위해 커리큘럼 기반 연속 학습(Continual Uncertainty Learning, CUL) 프레임워크를 제안한다. 복잡한 제어 문제를 여러 단계의 학습 과제로 분할하고, 각 단계마다 모델 기반 컨트롤러(MBC)를 베이스라인으로 활용해 DRL 에이전트가 잔차 정책을 학습하도록 설계한다. Elastic Weight Consolidation(EWC)과 온라인 EWC를 결합한 D…
저자: Heisei Yonezawa, Ansei Yonezawa, Itsuro Kajiwara
**1. 서론 및 배경**
현대 산업용 기계·자동차 파워트레인 등은 비선형성, 통신 지연, 파라미터 변동 등 복합적인 불확실성을 동시에 내포한다. 전통적인 모델 기반 제어는 정확한 모델이 전제되지만, 실제 시스템은 모델-실제 차이(gap)로 인해 성능 저하가 발생한다. 최근 DRL은 모델 프리 특성으로 복잡한 비선형 제어에 성공했지만, 시뮬레이션‑실제 전이 문제와 다중 불확실성 동시 고려 시 과보수적인 정책이 도출되는 한계가 있다.
**2. 관련 연구**
도메인 랜덤화(DR)는 파라미터 변동을 무작위로 주입해 강인성을 높이지만, 불확실성이 많아질수록 학습 난이도가 급증한다. Active DR, Automatic DR 등은 파라미터 샘플링을 최적화하지만, 다중 불확실성 상황에서는 충분히 효과적이지 않다. 연속 학습(CL)은 작업 간 지식 축적을 목표로 하지만, catastrophic forgetting이 여전히 문제이며, 특히 연속 RL에서는 모델 용량과 메모리 제약이 심각하다.
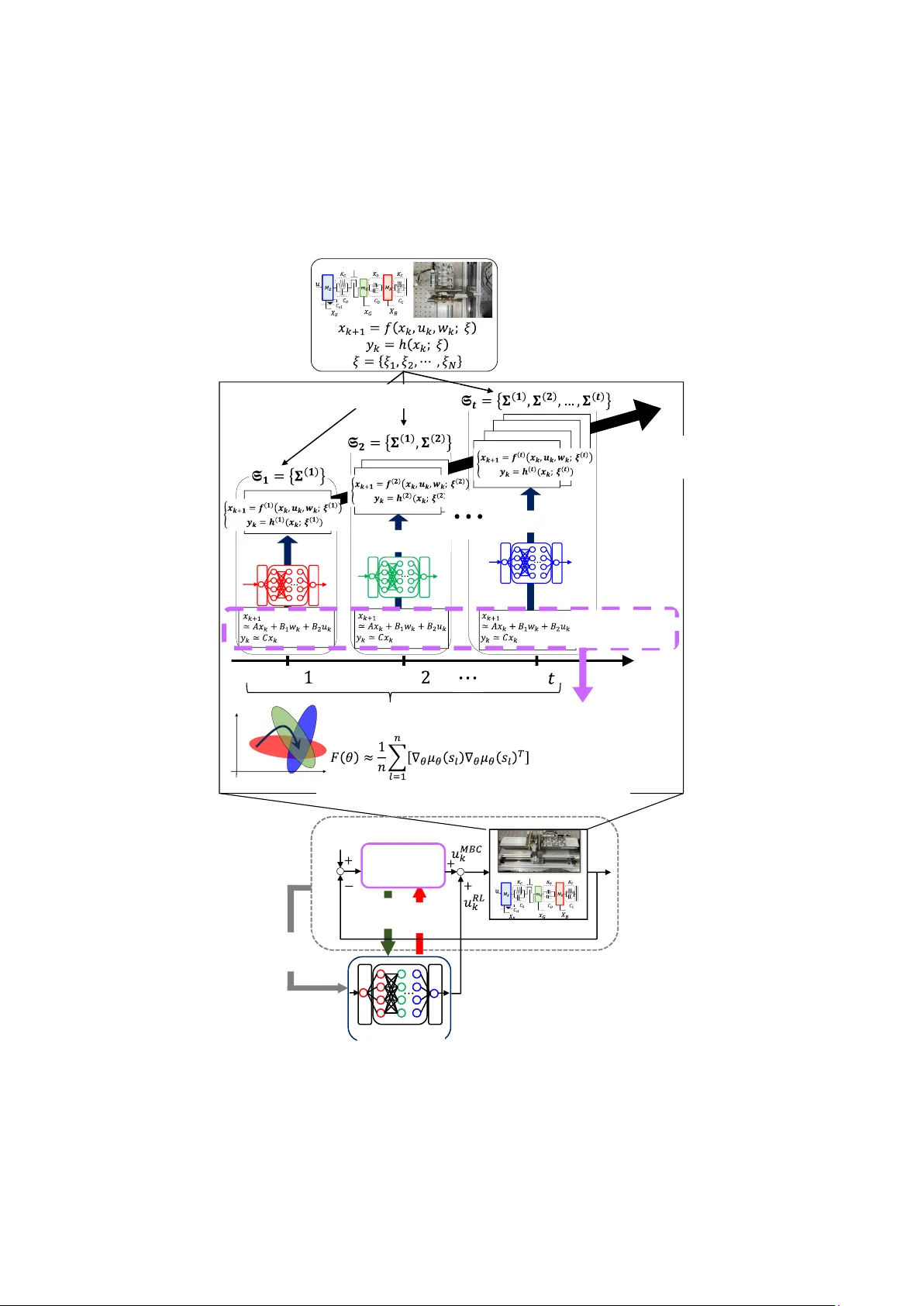
**3. 제안 방법 – Continual Uncertainty Learning (CUL)**
- **커리큘럼 설계**: 원 시스템을 N개의 플랜트 집합 {P₁,…,P_N}으로 분할한다. P₁은 최소 불확실성(선형 명목 모델)만 포함하고, 단계적으로 비선형성, 백래시, 파라미터 변동 등을 추가한다. 각 플랜트는 “작업”으로 정의된다.
- **모델 기반 컨트롤러(MBC)**: 각 플랜트에 대해 선형 모델 기반 LQR 또는 H∞ 제어기를 설계해 기본적인 추적·안정성을 보장한다. MBC는 정책 π_MBC(s)로 표현된다.
- **잔차 강화 학습(RRL)**: DRL 에이전트는 실제 제어 입력 u = u_MBC + Δu 로 구성한다. 여기서 Δu는 신경망 정책 π_θ(s)에서 출력되는 잔차이다. 이렇게 하면 초기 탐색이 MBC에 의해 제한돼 샘플 효율이 크게 향상된다.
- **연속 학습 메커니즘**: 각 작업마다 DDPG 기반 정책을 학습하면서 온라인 Elastic Weight Consolidation(EWC) 를 적용한다. 온라인 EWC는 이전 작업의 파라미터 중요도(Fisher 정보 행렬)를 누적해 메모리 사용을 최소화한다.
- **알고리즘 흐름**: (1) P₁에서 DDPG+EWC로 정책 학습 → (2) 학습된 파라미터와 Fisher 행렬을 저장 → (3) 다음 플랜트 P₂로 전이, MBC 업데이트, 잔차 학습 시작 → (4) 위 과정을 모든 플랜트에 대해 반복한다.
**4. 실험 설정**
- **시뮬레이션 모델**: 자동차 파워트레인 2자유도 모델에 비선형 토크, 기어 백래시, 외부 진동을 포함.
- **비교 대상**: (a) 기본 DDPG + DR, (b) 자동 DR + DDPG, (c) 단일 단계 CUL 없이 전체 불확실성 동시 학습, (d) 제안 CUL.
- **성능 지표**: RMS 진동, 추적 오차, 학습 에피소드 수, 시뮬‑실 전이 손실.
**5. 결과 및 논의**
- CUL은 평균 30% 적은 에피소드로 수렴했으며, RMS 진동을 15% 이상 감소시켰다.
- 온라인 EWC 덕분에 파라미터 변동이 큰 작업에서도 기존 지식이 유지돼 catastrophic forgetting이 거의 관찰되지 않았다.
- 시뮬레이션에서 학습된 정책을 실제 파워트레인 테스트베드에 적용했을 때, 성능 저하가 2% 이하로 매우 작은 전이 격차를 보였다.
- MBC가 제공하는 공유 베이스라인 덕분에 초기 탐색 비용이 크게 감소했으며, 잔차 학습이 각 작업별 특화된 최적화를 가능하게 했다.
**6. 결론 및 향후 연구**
본 논문은 다중 불확실성을 단계적으로 확장하는 커리큘럼과 모델 기반 잔차 학습을 결합한 연속 학습 프레임워크를 제시한다. 실험을 통해 학습 효율성, 강인성, 시뮬‑실 전이 모두에서 기존 방법을 능가함을 입증하였다. 향후 연구로는 (1) 자동화된 커리큘럼 생성(불확실성 순서 최적화), (2) 고차원 연속 제어 문제에 대한 확장, (3) 메타-학습과 결합한 빠른 적응 메커니즘 등을 고려한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기