Synthetic-Powered Multiple Testing with FDR Control
Multiple hypothesis testing with false discovery rate (FDR) control is a fundamental problem in statistical inference, with broad applications in genomics, drug screening, and outlier detection. In many such settings, researchers may have access not …
Authors: Yonghoon Lee, Meshi Bashari, Edgar Dobriban
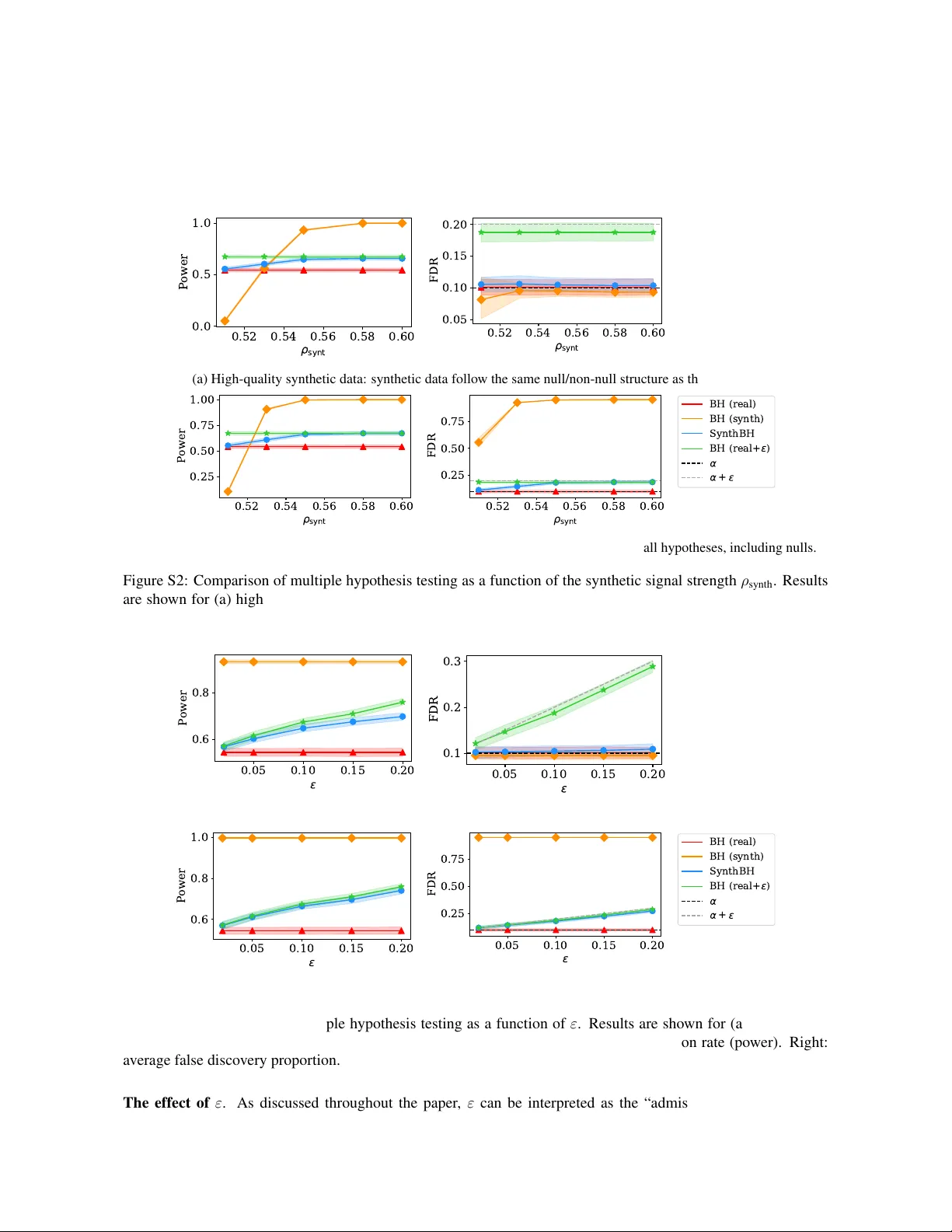
Synthetic-Po wered Multiple T esting with FDR Control Y onghoon Lee ∗ 1 , Meshi Bashari ∗ 2 , Edgar Dobriban 1 , and Y ani v Romano 2,3 1 Department of Statistics and Data Science, The Wharton School, Univ ersity of Pennsylvania, USA 2 Department of Electrical and Computer Engineering, T echnion IIT , Israel 3 Department of Computer Science, T echnion IIT , Israel Abstract Multiple hypothesis testing with false disco very rate (FDR) control is a fundamental problem in statistical inference, with broad applications in genomics, drug screening, and outlier detection. In many such settings, researchers may hav e access not only to real experimental observ ations but also to auxiliary or synthetic data— from past, related e xperiments or generated by generative models—that can provide additional evidence about the hypotheses of interest. W e introduce SynthBH , a synthetic-po wered multiple testing procedure that safely lev erages such synthetic data. W e prove that SynthBH guarantees finite-sample, distribution-free FDR control under a mild PRDS-type positi ve dependence condition, without requiring the pooled-data p-v alues to be valid under the null. The proposed method adapts to the (unknown) quality of the synthetic data: it enhances the sample efficiency and may boost the power when synthetic data are of high quality , while controlling the FDR at a user-specified lev el regardless of their quality . W e demonstrate the empirical performance of SynthBH on tabular outlier detection benchmarks and on genomic analyses of drug–cancer sensiti vity associations, and further study its properties through controlled experiments on simulated data. 1 Intr oduction Multiple hypothesis testing is a cornerstone of modern statistical inference. In lar ge-scale scientific studies— including genomics, drug discovery , high-throughput screening, and large-scale anomaly detection—researchers routinely test thousands to millions of hypotheses simultaneously . In such regimes, controlling the false disco very rate (FDR) (Benjamini and Hochber g, 1995) has become a default target, as it of fers a fav orable balance between statistical validity and po wer compared to more stringent criteria such as family-wise error control. A persistent bottleneck in these applications is that the amount of trusted real data is often limited. For example, in genomics, the number of reliably measured samples can be small relative to the dimensionality; in drug–cancer sensitivity studies, each additional experiment can be costly; and in outlier detection, obtaining a clean reference set of inliers can be expensi ve or require manual verification. At the same time, practitioners increasingly hav e access to large amounts of auxiliary data that are not fully trustworthy but are often informati ve: past experiments on related populations, weakly labeled or automatically curated datasets, and synthetic samples generated by modern generativ e models. Such auxiliary datasets can be far larger than the real dataset, and when they are high quality , they hav e the potential to dramatically sharpen statistical evidence. Howe ver , because the auxiliary data distribution can dif fer from the real one in unkno wn ways, nai vely pooling real and synthetic data in classical testing pipelines can lead to spurious discov eries and inflated FDR. This tension creates a basic methodological gap. On the one hand, ignoring synthetic data can be ov erly con- servati ve and low-po wered in small-sample regimes. On the other hand, treating synthetic data as if they were * Equal contribution. 1 real can destroy the v ery error guarantees that make multiple testing scientifically reliable. This paper asks a con- crete question: Can we le verage arbitrary synthetic/auxiliary data to impro ve the power of multiple testing, while guaranteeing finite-sample FDR contr ol that is r obust to unknown synthetic data quality? 2 Synthetic-P ower ed P-V alues Setting. W e consider a standard multiple hypothesis testing frame work with m hypotheses H 1 , . . . , H m . Each of hypothesis refers to a null claim—for example, H j referring to “the presence of the j -th genomic feature is not associated with the response to a given drug. ” For each hypothesis H j , we assume access to (i) a valid p-value p j computed from the trusted real data only , and (ii) an additional p-v alue ˜ p j computed from the merged real-and- synthetic dataset. The mer ged p-value ˜ p j can be substantially more informativ e when the synthetic data are of high quality (since it effecti vely uses a larger sample), b ut it is generally not guaranteed to be v alid under the null because the synthetic data distribution may be arbitrary . Our contributions in this w ork begin with the formulation of a synthetic-power ed p-value . Let a ∧ b := min( a, b ) and a ∨ b := max( a, b ) denote the minimum and maximum of two numbers, respectiv ely . The synthetic-power ed p-value at level δ ≥ 0 is defined as ˜ p δ j = p j ∧ ( ˜ p j ∨ ( p j − δ )) . (1) This construction is deliberately careful in using synthetic data. Suppose we are handed high-quality synthetic data. If the y pro vide very strong e vidence, so that ˜ p j is smaller than p j , we want to use it instead of the real data p-value p j ; and we tak e p j ∧ ˜ p j to achieve this. At the same time, since the quality of the synthetic data is unkno wn in general, we account for the possibility that they may be poor or misleading, and we cap the ef fect of the synthetic p-value at p j − δ . Generally , ˜ p δ j is not guaranteed to be a super -uniform variable—so not technically a classical p-value—b ut we use the term “synthetic-po wered p-value” with perhaps a slight abuse of notation, because we will use it as an input to multiple testing procedures. 1 From p-values to FDR contr ol: SynthBH . The main technical contribution of this paper is to show how to turn the guarded p-values ˜ p δ j , for appropriate choices of δ ≥ 0 , into a multiple testing procedure with prov able FDR control. W e consider a user -specified admission cost ε ≥ 0 for incorporating synthetic data: lar ger ε allo ws potentially larger po wer gains, but can also potentially increase f alse discoveries. Our proposed method, SynthBH (Algorithm 1), is a Benjamini–Hochberg type step-up procedure that uses rank- adaptive guardrails. When considering k candidate rejections, it only allows each p-value to be reduced by at most k ε/m . This adaptive calibration is crucial: it allo ws the smallest p-v alues—those most lik ely to be non- nulls—to benefit from synthetic data, while pre venting synthetic data from causing an uncontrolled proliferation of false disco veries. Under a natural positiv e dependence condition (a mild extension of classical conditions), we prov e that SynthBH controls the FDR at a level no larger than α + ε in finite samples, without imposing any validity assumptions on the synthetic p-values themselves . When synthetic data are informati ve, SynthBH can yield substantially more discov eries than applying BH to the real data alone, with error α ; when synthetic data are uninformativ e or misleading, the guardrails ensure the error remains controlled at the user -specified α + ε level in the worst-case. Why FDR control is different from prior results on synthetic-powered inference. Earlier work introduced synthetic-powered inference principles for general (monotone) loss control and h ypothesis testing (the G E S P I framew ork; Bashari et al., 2025a) and for conformal prediction (synthetic-powered predicti ve inference; Bashari et al., 2025b). A recurring theme there is that one can guardr ail the influence of synthetic data by intersecting/AND- ing it with a slightly more permissiv e real-data procedure at lev el α + ε , ensuring that the worst-case error is inflated 1 W e show that the final procedure controls the false discov ery rate; thus the terminology of p -values is still justified. 2 by at most ε . In fact, this perspecti ve inspired our definition of synthetic-powered p-values. Howe ver , e xtending this idea to FDR is highly nontrivial: FDR is a ratio that depends on the full data-dependent rejection set and does not correspond to a monotone loss—i.e., enlar ging the rejection set does not necessarily decrease the false discov ery proportion. As a result, existing synthetic-po wered inference theory does not directly apply . Thus, new methodology and completely new analysis are needed to obtain FDR control while still le veraging synthetic evidence to impro ve po wer . 2.1 K ey Contributions This paper makes the follo wing contributions. A synthetic-power ed BH procedure with finite-sample FDR contr ol. W e introduce SynthBH (Algorithm 1), a multiple testing procedure that takes as input both real-data p-v alues ( p j ) and pooled real and synthetic p-v alues ( ˜ p j ) . The method uses the guarded synthetic-po wered p-values (1) with a rank-dependent guardrail δ = k ε/m inside a BH-style step-up rule (2). Distribution-fr ee rob ustness to synthetic data quality . W e prov e that SynthBH controls the FDR in finite samples under an extended PRDS-type dependence condition (Definition 4.3). Crucially , our guarantee does not require ˜ p j to be valid under the null; the synthetic data may be arbitrarily biased or shifted. The role of ε is to quantify the permissible additional tolerance for incorporating synthetic evidence. W eighted extension. Many applications assign heterogeneous importance to hypotheses (e.g., using prior biolog- ical knowledge, study design considerations, or multi-stage pipelines). W e therefore propose a weighted analogue (Algorithm 2) and show an FDR bound that cleanly separates the base le vel α from the synthetic admission term ε (Theorem 4.4). A concrete application with automatic verification of the dependence condition. W e instantiate SynthBH for conformal outlier detection, where p j and ˜ p j are conformal p-v alues computed from a clean inlier reference set and from a larger merged set (possibly constructed from contaminated data via trimming). In this setting, we verify the required positi ve dependence property and obtain distribution-free FDR control (Theorem 5.2), e xtending conformal outlier detection to synthetic-powered re gimes. Empirical evaluation. W e ev aluate SynthBH on tabular outlier detection benchmarks and on genomic analyses of drug–cancer sensitivity associations, and complement these studies with controlled simulations. Across these settings, SynthBH achie ves empirical FDR close to the tar get le vel while impro ving power when synthetic data are informativ e, and it degrades gracefully when synthetic data quality deteriorates. 2 3 Related W ork Multiple testing and FDR control. False discovery rate control was introduced by Benjamini and Hochberg (1995), and the Benjamini–Hochberg (BH) step-up procedure remains the most widely used approach due to its simplicity and strong guarantees. Beyond independence, classical v alidity results rely on positi ve dependence structures such as PRDS (Benjamini and Y ekutieli, 2001) and related formulations (Finner et al., 2009). Our analysis builds on this tradition: we propose an extended PRDS condition (Definition 4.3) tailored to settings with two collections of p-v alues ( p j ) and ( ˜ p j ) , and we use it to establish finite-sample FDR control for SynthBH . Using auxiliary information in multiple testing . There is a large literature on impro ving multiple testing power by incorporating side information, prior studies, or cov ariates—for example through p-value weighting and related 2 Code to reproduce the experiments in this paper is a vailable at https://github .com/Meshiba/synth-bh. 3 optimization framew orks (Spjøtvoll, 1972; Benjamini and Hochber g, 1997; Roeder and W asserman, 2009; Do- briban et al., 2015; Basu et al., 2018). Such approaches can yield substantial gains when the auxiliary information is informati ve, but typically require assumptions that ensure v alidity of the resulting procedure (e.g., independence between cov ariates and null p-values, or explicit modeling assumptions linking current and prior studies). Our setting dif fers in a ke y way: the auxiliary object ˜ p j is produced by pooling with synthetic data whose distrib u- tion can be arbitrary and unkno wn, so treating ˜ p j as a classical p-value (or as a cov ariate satisfying independence conditions) is generally unjustified. Synthetic data for statistically valid inference. This paper is part of a broader effort to dev elop inference meth- ods that can safely le verage synthetic or weakly trusted data. Synthetic-powered predictiv e inference (Bashari et al., 2025b) de velops a score-transport mechanism for conformal prediction that yields finite-sample coverage guarantees while benefiting from synthetic data when score distributions align. More recently , the G E S P I frame- work (Bashari et al., 2025a) formalizes synthetic-powered inference as a general wrapper for controlling losses and error rates, highlighting the role of guardrails at level α + ε . The present work complements these ideas by de vel- oping methods for multiple testing with FDR control. Unlike one-shot hypothesis testing or loss control—where AND/OR-style guardrails can often be analyzed directly—FDR control couples all decisions through the random rejection threshold, making it essential to dev elop new procedures that account for this global dependence. Conformal p-v alues and outlier detection with FDR control. Conformal prediction (V o vk et al., 1999, 2005) provides distrib ution-free, finite-sample v alid p-values under exchangeability . Bates et al. (2023) le verage confor - mal p-values together with BH to obtain distribution-free FDR control for detecting outliers among test points. Our conformal outlier detection application is inspired by this work, but addresses a different bottleneck: conformal p-values computed from a small clean reference set can be conserv ati ve, whereas larger auxiliary datasets are often av ailable but contaminated. By combining a valid real-data conformal p-value with a pooled-data conformal p- value through SynthBH , we retain distrib ution-free FDR control while improving power when the auxiliary data are informativ e. Why we focus on BH-style baselines in experiments. Because our goal is distribution-fr ee FDR control in the presence of potentially arbitrary synthetic data, many alternativ e approaches that rely on the pooled p-v alues being valid (or approximately v alid) do not constitute meaningful competitors: their guarantees can f ail precisely in the regimes we tar get. Accordingly , our comparisons focus on canonical baselines that are always well-defined: BH on real-data p-values, BH at an inflated lev el α + ε (illustrating the ef fect of relaxing the tar get), and BH on pooled- data p-values (illustrating the risks of naiv ely trusting synthetic data). SynthBH sits between these extremes, providing a principled, safe way to capture synthetic-data g ains when av ailable. 4 Synthetic-P ower ed Multiple Hypothesis T esting 4.1 Notations W e write R to denote the real line. For a positiv e integer d , let [ d ] = { 1 , 2 , . . . , d } . For a = ( a 1 , . . . , a d ) and b = ( b 1 , . . . , b d ) in R d , we write a ⪯ b if and only if a j ≤ b j for all j ∈ [ d ] . This defines the usual coordinatewise partial order on R d . 4.2 Review of Benjamini-Hochber g Procedur e The Benjamini-Hochberg procedure constructs the rejection set as follo ws. Given m p -values p 1 , . . . , p m and a predefined lev el α ∈ (0 , 1) , define k ∗ = max n k ∈ [ m ] : m · p ( k ) k ≤ α o , 4 where p ( k ) denotes the k -th smallest p -v alue. The rejection set is then { i ∈ [ m ] : p i ≤ p ( k ∗ ) } . This procedure prov ably controls the FDR at ( m 0 /m ) α , where m 0 is the number of true null hypotheses. The guar- antee holds under independence of the p -values, or under the weaker assumption of positive regression dependence on the true nulls (PRDS), which we formally define below . Recall that a set A ⊂ R m is called incr easing if it is upward closed under the partial order defined by the relation ⪯ , i.e., if, for all x ∈ A , it follo ws that we have y ∈ A for all x ⪯ y . W e then have the following notion of positiv e regression dependence, which has been instrumental in establishing the v alidity of the Benjamini- Hochberg procedure under dependence Benjamini and Hochber g (1995); Benjamini and Y ekutieli (2001). Definition 4.1 (Benjamini and Y ekutieli (2001)) . F or a set I ⊂ { 1 , . . . , m } and a random vector X = ( X 1 , X 2 , . . . , X m ) , X is positively re gr ession dependent (PRDS) on I if, for all k ∈ I , the conditional probability x 7→ P { X ∈ A | X k = x } is nondecreasing on its domain as a function of x ∈ R for any increasing set A ⊂ R m . There is also a somewhat weak er form of PRDS, that we will build on in our analysis: Definition 4.2. In the setting of Definition 4.1, X is weakly positively r e gr ession dependent on I if, for all k ∈ I and for any increasing set A ⊂ R m , x 7→ P { X ∈ A | X k ≤ x } is nondecreasing on its domain. 4.3 The SynthBH Procedur e Now we introduce our procedure. For an y δ ≥ 0 , define ˜ p δ j as in (1), and let ˜ p δ ( k ) denote the k -th smallest element among ˜ p δ 1 , . . . , ˜ p δ m . Then for predetermined lev els α ∈ (0 , 1) and ε ∈ (0 , 1) , define k ∗ = max k ∈ [ m ] : m · ˜ p kε/m ( k ) k ≤ α . (2) W e set k ∗ = 0 if no index satisfies the condition. Observ e that we compare the k -th order statistics of the synthetic powered p-v alues, adjusted in an adapti ve way by k ε/m . For the smaller p-values, it turns out to be reasonable to adjust them by smaller v alues. W e reject the hypotheses corresponding to the smallest v alues of ( ˜ p k ∗ ε/m j ) j ∈ [ m ] , i.e., the set { j ∈ [ m ] : ˜ p k ∗ ε/m j ≤ ˜ p k ∗ ε/m ( k ∗ ) } . This yields at least k ∗ rejections and may yield more if ties occur at the cutoff. See Algorithm 1 for the outline of the procedure. Algorithm 1 SynthBH : Synthetic-powered multiple testing with FDR control Input: Real data D n = { Z 1 , Z 2 , . . . , Z n } . Synthetic data ˜ D N = ( ˜ Z 1 , ˜ Z 2 , . . . , ˜ Z N ) . P-value-generating algo- rithms (Alg j ) j ∈ [ m ] such that p j = Alg j ( D n ) is a v alid p-value under H j . Lev els α, ε ∈ (0 , 1) . Step 1: Compute p j = Alg j ( D n ) and ˜ p j = Alg j ( D n ∪ ˜ D N ) , for j ∈ [ m ] . Step 2: Set k ∗ = 0 and R = ∅ . Then for k = 1 , 2 , . . . , m : Step 2-1: Compute ˜ p kε/m j = p j ∧ ( ˜ p j ∨ ( p j − k ε/m )) , for j ∈ [ m ] . Step 2-2: Find the k -th smallest element ˜ p kε/m ( k ) among ( ˜ p kε/m j ) j ∈ [ m ] . Step 2-3: If ˜ p kε/m ( k ) ≤ α k/m , then update k ∗ ← k , R ← { j ∈ [ m ] : ˜ p kε/m j ≤ ˜ p kε/m ( k ) } . Return: Rejection set R . Further , there are important settings where the p-values ha ve predefined levels of importance, and we w ould like to apply different effecti ve α le vels for the different hypotheses. One way to capture this—leading to weighted hypothesis testing—is to assign weights ( w j ) j ∈ [ m ] satisfying w j ≥ 0 , j ∈ [ m ] , to the different hypotheses; also satisfying the normalization conditions P m j =1 w j = m , see e.g., Spjøtvoll (1972); Benjamini and Hochberg (1997); Roeder and W asserman (2009); Dobriban et al. (2015); Basu et al. (2018), etc. 5 Inspired by this line of work, we develop a method for FDR control with weighted hypotheses, enabling the use of synthetic data (Algorithm 2). Here, the weights modulate the synthetic “admission budget” (how much each hypothesis may be boosted by synthetic data) rather than the base BH critical v alues; when ε = 0 , the method reduces to the unweighted BH procedure at level α . The intuition for this method is similar to the one for the previous case; with the difference that the j -th p-v alue is shifted do wnwards by a term proportional to w j , hence effecti vely allowing us to compare it to a lar ger ef fectiv e α when the weight w j is larger . This procedure reduces to the pre vious one when all weights w j are equal to unity . Ho wev er , our theoretical result for the general case is somewhat different from the one for the uniform case. For clarity , we belie ve it is helpful to state the two methods separately . Algorithm 2 W eighted SynthBH : Synth.-powered multiple testing with FDR control and heterogeneous weights Input: Real data D n = { Z 1 , Z 2 , . . . , Z n } . Synthetic data ˜ D N = ( ˜ Z 1 , ˜ Z 2 , . . . , ˜ Z N ) . V alid p-v alue-generating algorithms (Alg j ) j ∈ [ m ] , Lev els α, ε ∈ (0 , 1) . W eights ( w j ) j ∈ [ m ] satisfying w j ≥ 0 ∀ j ∈ [ m ] and P m j =1 w j = m . Step 1: Compute p j = Alg j ( D n ) and ˜ p j = Alg j ( D n ∪ ˜ D N ) , for j ∈ [ m ] . Step 2: Set k ∗ = 0 and R = ∅ . Then for k = 1 , 2 , . . . , m : Step 2-1: Compute ˜ p kw j ε/m j = p j ∧ ( ˜ p j ∨ ( p j − k w j ε/m )) , for j ∈ [ m ] . Step 2-2: Find the k -th smallest element ˜ p k,ε,w ( k ) among ( ˜ p kw j ε/m j ) j ∈ [ m ] . Step 2-3: If ˜ p k,ε,w ( k ) ≤ α k/m , then update k ∗ ← k , R ← { j ∈ [ m ] : ˜ p kw j ε/m j ≤ ˜ p k,ε,w ( k ) } . Return: Rejection set R . 4.4 Computational Complexity W e now turn to the computational aspects of SynthBH . Although the rank-adaptive formulation may seem com- putationally intensive at first, Appendix B sho ws that it can be exactly reduced to a single run of the classical BH procedure on a carefully constructed set of modified p-values (see Appendix B for details). Thus, SynthBH can be implemented with the same O ( m log m ) time and O ( m ) memory comple xity as BH, while still leveraging synthetic data when beneficial and guaranteeing valid FDR control, as sho wn in the next section. 4.5 Theoretical Guarantee W e introduce the follo wing condition, which is central to our theoretical guarantee. This e xtends the PRDS condi- tion from Finner et al. (2009), by allo wing the conditioning to be done on a different vector Y of random v ariables. Definition 4.3. Fix m ∈ N and let I ⊆ [ m ] . Let X ∈ R d and Y = ( Y 1 , . . . , Y m ) ∈ R m be random vectors. W e say that X is positively r e gression dependent on I with r espect to Y if, for all k ∈ I and for any increasing set A ⊂ R d , the function x 7→ P { X ∈ A | Y k ≤ x } is nondecreasing on its domain. Equipped with these preliminaries, we now state our main result: if the set of real and synthetic p-values are jointly PRDS with respect to the set of null real p-values, then our algorithm controls the f alse discovery rate. Theorem 4.4 ( SynthBH controls the FDR) . Suppose ( p 1 , . . . , p m ) ar e valid p-values for H 1 , . . . , H m , respec- tively . If ( p 1 , p 2 , . . . , p m , ˜ p 1 , . . . , ˜ p m ) ar e positively re gr ession dependent on the set of nulls I 0 = { j ∈ [ m ] : H j is true } with r espect to ( p 1 , . . . , p m ) in the sense of Definition 4.3, then SynthBH (Algorithm 1) contr ols the false discovery rate at le vel ( m 0 /m ) · ( α + ε ) , wher e m 0 = | I 0 | denotes the number of true nulls. Further- mor e, weighted SynthBH (Algorithm 2) contr ols the false discovery rate at level ( m 0 /m ) α + ε m P j ∈ I 0 w j ≤ ( m 0 /m ) α + ε . Such PRDS conditions are widely used in the literature on FDR control. In the ne xt section, we provide a concrete 6 example in which this condition holds. Moreover , Theorem 4.4 sho ws that SynthBH controls the FDR at a le vel adaptiv e to the true number of nulls, with slightly sharper control in the uniform case than in the weighted case. 5 A pplication: Conformal Outlier Detection Suppose we have data D n = ( X 1 , . . . , X n ) iid ∼ P X . Gi ven test points ( X n +1 , . . . , X n + m ) , we aim to detect outliers by testing the following h ypotheses: H j : X n + j ∼ P X , j = 1 , 2 , . . . , m. (3) Bates et al. (2023) introduces a method based on conformal p-values that provides provable finite-sample, distribution- free FDR control. The conformal p-value for H j V ovk et al. (1999, 2005) is gi ven by p j = P n i =1 1 { s ( X i ) ≥ s ( X n + j ) } + 1 n + 1 , (4) where s is a score function, which may be fixed or constructed using a separate split of the data. For e xample, s ( x ) can be a score obtained by some outlier detection algorithm, such that a large value indicates that x “looks unusual” for the machine learning model. The abov e p j is known to be super-uniform under H j V ovk et al. (2005). This p-v alue is always at least 1 / ( n + 1) , implying that when the sample size n is small, the resulting detection procedure can be conservati ve. Now , suppose we also hav e access to a large synthetic dataset ˜ D N = ( ˜ X 1 , . . . , ˜ X N ) . W e can consider the following conformal p-value constructed from the mer ged data D n ∪ ˜ D N : ˜ p j = P n i =1 1 { s ( X i ) ≥ s ( X n + j ) } + P N i =1 1 n s ( ˜ X i ) ≥ s ( X n + j ) o + 1 n + N + 1 . (5) The v ariable ˜ p j can be expected to be less conservati ve, as its smallest possible v alue is 1 / ( n + N + 1) , b ut it is not guaranteed to be super-uniform under H j . Algorithm 3 Synthetic-powered conformal outlier detection Input: Real data D n = { X 1 , X 2 , . . . , X n } . Synthetic data ˜ D N = ( ˜ X 1 , ˜ X 2 , . . . , ˜ X N ) . Score function s : X → R , Lev els α, ε ∈ (0 , 1) . Run the SynthBH procedure with p j and ˜ p j computed according to (4) and (5), respectively , for j = 1 , 2 , . . . , m ; as well as all other giv en input. Return: Set of detected outliers R . Nonetheless, we propose a Benjamini–Hochberg-type outlier detection method (Algorithm 3) that controls the false discovery rate. This guarantee follo ws from our general FDR control results, as we show that the associated conformal p-values satisfy the required PRDS property . In order to accomplish this, we require the following lemma, sho wing that the classic PRDS condition (Defini- tion 4.1), which conditions on exact v alues, implies the weaker conditioning-on- ≤ form (Definition 4.2). Lemma 5.1. F or a fixed measurable set A ⊂ R n , a random vector X ∈ R n and a random variable W , if the function x 7→ P { X ∈ A | W = x } is nondecreasing , then x 7→ P { X ∈ A | W ≤ x } is also nondecr easing. Equipped with this, we can show the follo wing result. Theorem 5.2 (Outlier detection via SynthBH with FDR control) . Consider the hypotheses ( H j ) j ∈ [ m ] defined in (3) . Let p j and ˜ p j be as defined in (4) and (5) , r espectively , for j ∈ [ m ] . Suppose ( X 1 , . . . , X n ) ar e i.i.d. 7 fr om P X , the test points X n +1 , . . . , X n + m ar e mutually independent and independent of ( X 1 , . . . , X n ) , and the synthetic data ( ˜ X 1 , . . . , ˜ X N ) is independent of ( X 1 , . . . , X n + m ) . Let the score function s be fixed and as- sume that the scores ( s ( X i )) i ∈ [ n + m ] and ( s ( ˜ X i )) i ∈ [ N ] ar e almost sur ely all distinct. Then the random vector ( p 1 , p 2 , . . . , p m , ˜ p 1 , . . . , ˜ p m ) is positively re gr ession dependent on the set of true nulls I 0 = { j ∈ [ m ] : H j is true } with r espect to ( p 1 , . . . , p m ) , in the sense of Definition 4.3. Consequently , Algorithm 3 contr ols the FDR at level ( m 0 /m ) · ( α + ε ) . Remark 5.3 . The assumption that the scores are almost surely distinct can always be satisfied by adding a negligible random noise to the scores. 6 Experiments W e demonstrate the performance of our method on conformal outlier detection (Section 6.1) and on a genomic analysis of drug-cancer associations (Section 6.2). W e defer results from controlled experiments on simulated data to Appendix A.1, where we further study the performance of SynthBH under varying settings. W e emphasize that the finite-sample worst-case guarantee for SynthBH is FDR ≤ α + ε (more precisely , FDR ≤ ( m 0 /m )( α + ε ) ), while in many benign re gimes we empirically observe FDR closer to the base le vel α . Methods In each example, we compare the follo wing methods: • BH (real) : The classic BH procedure applied on p-v alues computed from the limited real data. • BH (real + ε ) : Same as BH (real) , but applies the BH procedure at a relax ed level α + ε . • BH (synth) : The classic BH procedure applied on p-v alues computed from the pooled real and synthetic data. This approach benefits from a larger sample size b ut does not provide any FDR control guarantees. • SynthBH : The proposed method, which leverages both real and synthetic data and enjoys FDR control guarantees. 6.1 Conf ormal Outlier Detection In this section, we ev aluate the performance of our method on the conformal outlier detection task described in Section 5. Giv en real data D n = ( X 1 , . . . , X n ) iid ∼ P X and m test points ( X n +1 , . . . , X n + m ) , the goal is to test, for each test point X n + j , whether it is drawn from the inlier distrib ution P X or from a different, outlier distrib ution Q X = P X . Conformal outlier detection pro vides finite-sample, distribution-free FDR control when the conformal p-values (as defined in (4)) are computed solely using inlier data. Howe ver , as discussed in Section 5, this procedure can be ov erly conservati ve when the number of inliers, n , is small. In practice, obtaining a large collection of labeled inliers may be challenging. In contrast, obtaining a lar ge, potentially contaminated dataset (i.e., containing a small fraction of outliers) is often readily available. While such a set does not consist solely of inliers, we are able to lev erage it as synthetic data. As argued in Bashari et al. (2025c), using a contaminated set directly often results in conserv ati ve inference due to the presence of outliers. T o mitigate this, we adopt a cheap, annotation-free approach, where we trim the top ρ % samples (for ρ defined below) of ˜ D N that are marked by an outlier detection model, and treat the remaining samples as synthetic data. As illustrated in Bashari et al. (2025c), this trimmed set cannot be treated as if it contains solely inliers, b ut provides a practical heuristic for leveraging large contaminated sets (which enjoys theoretical guarantees as per our results). Datasets and experimental setup. W e ev aluate performance on three tabular benchmark datasets for outlier detection: Shuttle (Catlett, 1992), KDDCup99 (Stolfo et al., 1999), and Cr edit-card (Group, 2013). The target 8 FDR lev el is α = 10% , and ε = 10% . All additional details are provided in Appendix D.1. Figure 1 presents the performance of the conformal outlier detection methods on the three tabular datasets. All datasets sho w a similar trend. BH (synth) leads to arbitrary—uncontrolled—FDR lev els that depend on the unknown quality of the pooled synthetic and real data, highlighting the need for safe use of synthetic data. BH (real) and BH (real + ε ) suf fer from the limited size of the real dataset: BH (real) conservati vely controls the FDR at le vel α and achiev es lower power , while BH (real + ε ) controls the FDR at a higher le vel but e xhibits high v ariability . In contrast, SynthBH achiev es empirical FDR close to the nominal le vel α with higher po wer . When synthetic data are of high quality—e.g., as in the Shuttle dataset— SynthBH achieves higher power than BH (real) and lower v ariability in error than BH (real + ε ) . KDDCup99 creditcard shuttle Dataset 0.00 0.25 0.50 0.75 Empirical P ower KDDCup99 creditcard shuttle Dataset 0.0 0.2 0.4 FDP 50 100 200 500 n 0.0 0.5 1.0 FDR BH (real) BH (synth) SynthBH B H ( r e a l + ) + Figure 1: Comparison of conformal outlier detection methods on three tabular datasets. The tar get FDR level is α = 10% and ε = 10% . T op: detection rate (empirical power). Bottom: false disco very proportion. W e include additional results in Appendix A.2, showing performance as a function of the real data sample size and as a function of the trimming proportion, with the latter effecti vely illustrating performance under v arying synthetic data quality . T o further illustrate that safely lev eraging high-quality synthetic data can not only achie ve FDR close to the nominal lev el but also improve po wer, Figure 2 presents empirical po wer as a function of the empirical FDR. W e note that 0.000 0.050 0.100 0.150 F D R 0.0 0.2 0.4 P ower 0.000 0.050 0.100 0.150 F D R 0.0 0.2 0.4 P ower (a) Shuttle 0.000 0.050 0.100 0.150 F D R 0.0 0.2 0.4 P ower 0.000 0.050 0.100 0.150 F D R 0.0 0.2 0.4 P ower (b) Credit-card 0.00 0.10 0.20 F D R 0.0 0.2 0.4 0.6 P ower 0.00 0.10 0.20 F D R 0.0 0.2 0.4 0.6 P ower (c) KDDCup99 100 200 300 400 500 n 0.0 0.5 1.0 P ower BH (real) SynthBH Figure 2: Power as a function of the empirical FDR for BH (real) and our proposed method SynthBH across different outlier detection datasets: (a) Shuttle, (b) Credit-card, and (c) KDDCup99. The first ro w corresponds to a trimming proportion of 2%, and the second row corresponds to a trimming proportion of 0%, representing a scenario where synthetic data are not useful. Here, α ∈ [0 , 20%] . 9 this e xperiment is not feasible in practice, as it requires kno wing the false disco veries, but it is included to compare our proposed method with using only the real data when both methods attain the same empirical FDR. Follo wing that figure, the first row sho ws performance when the trimming proportion is ρ = 2% , representing a scenario in which the synthetic data are informativ e. In this setting, SynthBH impro ves po wer relativ e to using only real data while also e xhibiting lower v ariance. This can be e xplained as follows: by design, the effecti ve p-values used by our method are always less than or equal to those computed from only the real data. When the synthetic data are of high quality , the larger sample size can lead to smaller p-values for non-null hypotheses. This can results in a larger rejection set with more true discoveries while maintaining the same false discov ery proportion. The second ro w of that figure presents a scenario in which the synthetic data are not informati ve, with trimming proportion set to ρ = 0% . Here, the synthetic data provides no additional signal, and SynthBH matches the power of the method that utilize only the real data. Additional results with a lo wer ε value are pro vided in Appendix A.2, showing the same trends. 6.2 Genomics of Drug Sensitivity in Cancer W e now demonstrate the performance of SynthBH on a genomics task: testing associations between genomic features and sensitivity to anticancer drugs. Identifying such associations helps characterize the molecular features that influence drug response in cancer cells and can ultimately enable the design of improv ed cancer therapies. Data and experimental setting . W e use data from the Genomics of Drug Sensitivity in Cancer (GDSC) (Y ang et al., 2012), which contains drug response measurements (IC50 values) across a large collection of cancer cell lines, along with genomic annotations such as mutations. Hypotheses . For each cancer type, genomic feature, and drug, we test whether drug response—measured by IC50 values across cell lines—is associated with the presence of the feature. F ormally , the null hypothesis is H ( c,f ,d ) 0 : E f present ( IC 50) = E f absent ( IC 50) . T o test this hypothesis, we partition the cell lines of cancer type c into two groups according to the presence or absence of feature f , and apply a two-sample t -test to obtain a p -v alue for each ( c, f , d ) triple. This follows the general scheme of the GDSC (Y ang et al., 2012) paper and the GDSCT ools python package (Cokelaer et al., 2018); since we consider tissue-specific h ypotheses, we use a two-sample t -test instead of ANO V A—used in these works. W e consider 100 hypotheses of interest for breast in vasi ve carcinoma and lung adenocarcinoma, listed in Appendix D.2. Pan-cancer as synthetic data . The number of cell lines per cancer type can be limited, while pan-cancer data across multiple tissues pro vides abundant auxiliary information. Pan-cancer associations are informativ e when a genomic feature influences drug response through shared biological mechanisms across cancers, b ut uninformati ve or misleading when drug sensitivity is cancer -type specific. W e use data from all other tissues as synthetic data. Since ground-truth labels for each hypothesis are una vailable and the number of real cell lines is limited, we adopt the following scheme to compute an empirical proxy . Specifically , for each hypothesis, we compute a gr ound-truth scor e , defined as the proportion of runs in which the h ypothesis is rejected by the BH procedure at level α . A higher ground-truth score indicates stronger evidence that the hypothesis is non-null. T o estimate this score, we repeat the follo wing procedure 10 times: randomly sample 80% of the cell lines for each tar get cancer tissue, and test the 100 hypotheses of interest. For comparing the different methods, we randomly sample 50% of both real (cancer -type-specific) and synthetic (pan-cancer) cell lines to compute the real and pooled p-v alues, and then apply each method with α = 10% and ε = 10% . W e report the number of rejections and the average ground-truth score of the rejection set, computed 10 ov er 10 trials. Figure 3 shows the performance of multiple testing methods on the GDSC genomic data. On the left, SynthBH yields more rejections than BH (real) . On the right, the av erage ground-truth score of the rejection sets ob- tained by SynthBH is high, and notably lar ger than that of BH (real + ε ) . This indicates that the additional rejections of SynthBH likely correspond to meaningful true disco veries rather than false positives. Interestingly , BH (synth) alone produces fewer rejections with lower ground-truth scores, though it still pro vides useful in- formation for some hypotheses, as evidenced by the performance of SynthBH . W e provide additional results with ε = 5% in Appendix A.3, which present a trend similar to that reported here. 30 40 50 Number of Rejections 0.85 0.90 0.95 1.00 Ground Truth Score 0.85 0.90 0.95 1.00 Ground Truth Score BH (real) BH (synth) SynthBH B H ( r e a l + ) Figure 3: Comparison of multiple testing methods on GDSC genomic data for 100 tissue-feature-drug hypotheses. The target FDR lev el is α = 10% and ε = 10% . Left: number of rejections. Right: av erage ground-truth score of the rejection set. 7 Discussion This work introduces SynthBH , a synthetic-powered multiple testing procedure that safely lev erages auxiliary/syn- thetic data while guaranteeing finite-sample FDR control under a mild PRDS-type dependence condition, without requiring the pooled p-values to be valid. Important future directions include deriving guarantees under weaker (or arbitrary) dependence, de veloping broadly verifiable suf ficient conditions beyond the conformal outlier setting studied here, and designing principled ways to choose ε (or adapt it) and to inte grate data-dependent synthetic filtering/weighting while preserving finite-sample validity . Acknowledgments E. D. and Y . L. were partially supported by the US NSF , NIH, AR O, AFOSR, ONR, and the Sloan Foundation. M. B. and Y . R. were supported by the European Union (ERC, SafetyBounds, 101163414). V iews and opinions expressed are ho we ver those of the authors only and do not necessarily reflect those of the European Union or the European Research Council Executi ve Agency . Neither the European Union nor the granting authority can be held responsible for them. This research was also partially supported by the Israel Science Foundation (ISF grant 729/21). Y . R. acknowledges additional support from the Career Adv ancement Fello wship at the T echnion. Refer ences M. Bashari, Y . Lee, R. M. Lotan, E. Dobriban, and Y . Romano. Statistical inference le veraging synthetic data with distribution-free guarantees. arXiv pr eprint arXiv:2509.20345 , 2025a. M. Bashari, R. M. Lotan, Y . Lee, E. Dobriban, and Y . Romano. Synthetic-powered predictive inference. Advances in Neural Information Pr ocessing Systems , 2025b. 11 M. Bashari, M. Sesia, and Y . Romano. Robust conformal outlier detection under contaminated reference data. In F orty-second International Conference on Mac hine Learning , 2025c. P . Basu, T . T . Cai, K. Das, and W . Sun. W eighted false disco very rate control in large-scale multiple testing. Journal of the American Statistical Association , 2018. S. Bates, E. Candès, L. Lei, Y . Romano, and M. Sesia. T esting for outliers with conformal p-v alues. The Annals of Statistics , 2023. Y . Benjamini and Y . Hochberg. Controlling the f alse discov ery rate: a practical and po werful approach to multiple testing. Journal of the Royal statistical society: series B (Methodological) , 1995. Y . Benjamini and Y . Hochberg. Multiple hypotheses testing with weights. Scandinavian Journal of Statistics , 1997. Y . Benjamini and D. Y ekutieli. The control of the f alse discov ery rate in multiple testing under dependency . The Annals of Statistics , 2001. B. Bischl, G. Casalicchio, M. Feurer , P . Gijsbers, F . Hutter , M. Lang, R. G. Mantov ani, J. N. v an Rijn, and J. V anschoren. OpenML: A benchmarking layer on top of OpenML to quickly create, download, and share systematic benchmarks. Advances in Neural Information Pr ocessing Systems , 2021. J. Catlett. Statlog (Shuttle). UCI Machine Learning Repository , 1992. T . Cokelaer , E. Chen, F . Iorio, M. P . Menden, H. Lightfoot, J. Saez-Rodriguez, and M. J. Garnett. GDSCT ools for mining pharmacogenomic interactions in cancer . Bioinformatics , 2018. E. Dobriban, K. Fortney , S. K. Kim, and A. B. Owen. Optimal multiple testing under a Gaussian prior on the ef fect sizes. Biometrika , 2015. M. Feurer , J. N. van Rijn, A. Kadra, P . Gijsbers, N. Mallik, S. Ravi, A. Mueller, J. V anschoren, and F . Hutter . OpenML-Python: an extensible python api for openml. JMLR , 2021. H. Finner , T . Dickhaus, and M. Roters. On the false disco very rate and an asymptotically optimal rejection curve. The Annals of Statistics , 2009. M. L. Group. Credit Card Fraud Detection Data Set, 2013. F . T . Liu, K. M. T ing, and Z.-H. Zhou. Isolation forest. In International Confer ence on Data Mining . IEEE, 2008. K. Roeder and L. W asserman. Genome-wide significance lev els and weighted hypothesis testing. Statistical science: a r eview journal of the Institute of Mathematical Statistics , 2009. E. Spjøtvoll. On the optimality of some multiple comparison procedures. The Annals of Mathematical Statistics , 1972. S. Stolfo, W . F an, W . Lee, A. Prodromidis, and P . Chan. KDD Cup 1999 Data. UCI Machine Learning Repository , 1999. V . V ovk, A. Gammerman, and C. Saunders. Machine-learning applications of algorithmic randomness. In Inter- national Confer ence on Machine Learning , 1999. V . V ovk, A. Gammerman, and G. Shafer . Algorithmic learning in a r andom world . Springer Science & Business Media, 2005. R. W ang. Elementary proofs of se veral results on false disco very rate. arXiv pr eprint arXiv:2201.09350 , 2022. W . Y ang, J. Soares, P . Greninger , E. J. Edelman, H. Lightfoot, S. Forbes, N. Bindal, D. Beare, J. A. Smith, I. R. Thompson, et al. Genomics of drug sensitivity in cancer (GDSC): a resource for therapeutic biomarker discov ery in cancer cells. Nucleic Acids Researc h , 2012. 12 A Additional Experiments A.1 Experiments with Simulated Data In this section, we present controlled e xperiments based on simulated data to further study the performance of SynthBH under varying settings. Specifically , we consider the follo wing multiple hypothesis testing problem. Consider m null hypotheses ( H 0 ,i ) i ∈ [ m ] tested simultaneously against corresponding alternati ves ( H 1 ,i ) i ∈ [ m ] , where H 0 ,i : q i ≤ 0 . 5 vs. H 1 ,i : q i > 0 . 5 . For each hypothesis i , we observe n real samples drawn independently from Bernoulli ( q i ) and N synthetic samples drawn independently from Bernoulli ( ˜ q i ) . W e then use a randomized binomial test to compute p-values, which are subsequently used by all methods. Unless stated otherwise, we set n = 200 , N = 1000 , α = 10% , and ε = 10% . W e test m = 1000 hypotheses, of which 5% follow the alternative ( q i = 0 . 6 ), and the rest follo w the null. The synthetic samples for each hypothesis are generated from Bernoulli (0 . 5) when H 0 ,i holds, and from Bernoulli ( ρ synth ) with ρ synth = 0 . 55 otherwise. This setup reflects a scenario in which the synthetic signal for non-null hypotheses is weaker than that of the real data, but may still be informativ e due to the larger synthetic sample size. W e report the av erage detection rate (power) and the av erage false discov ery proportion, computed over 100 independent trials. The effect of the real data sample size n . Figure S1 presents the performance of different multiple hypothesis testing methods as a function of the real data sample size n . When n is small (e.g., n = 50 ), both BH (real) and BH (real + ε ) attain nearly zero po wer; as a consequence, SynthBH also attains zero po wer . As n increases, the po wer of both BH (real) and BH (real + ε ) increases, with the former controlling the FDR at le vel α and the latter at the inflated lev el α + ε , and thus achie ving higher power , as expected. In this regime, the synthetic data are informativ e, and SynthBH attains power comparable to BH (real + ε ) . In this benign regime we empirically observe FDR close to the nominal lev el α . For suf ficiently large n , all methods achiev e power close to one. 100 200 300 400 500 n 0.0 0.5 1.0 P ower 100 200 300 400 500 n 0.1 0.2 FDR 100 200 300 400 500 n 0.1 0.2 FDR BH (real) BH (synth) SynthBH B H ( r e a l + ) + Figure S1: Comparison of multiple hypothesis testing as a function of the real data sample size n . Left: average detection rate (power). Right: a verage false discov ery proportion. The effect of the synthetic data quality . Figure S2 presents the performance as a function of the signal strength of the synthetic data. Figure S2a corresponds to a setting in which the synthetic data are informativ e for both null and non-null hypotheses, while Figure S2b illustrates an extreme scenario reflecting worst-case synthetic data (in terms of error), where synthetic data exhibit signal for all hypotheses, nulls and non-nulls; the magnitude of this signal is giv en by the x-axis. W e observe similar trends across both settings. In these simulations, SynthBH attains po wer at least that of BH (real) and increases with the synthetic signal strength, with performance approaching that of BH (real + ε ) as the synthetic signal strengthens. 13 In terms of FDR, in Figure S2a, where the synthetic data are of high quality , SynthBH achie ves FDR close to the target le vel α . In contrast, in Figure S2b, which reflects a worst-case error scenario for synthetic data, BH (synth) e xhibits extremely inflated FDR, while SynthBH controls the FDR at le vel α + ε , as guaranteed in Theorem 4.4. 0.52 0.54 0.56 0.58 0.60 s y n t 0.0 0.5 1.0 P ower 0.52 0.54 0.56 0.58 0.60 s y n t 0.05 0.10 0.15 0.20 FDR (a) High-quality synthetic data: synthetic data follow the same null/non-null structure as the real data. 0.52 0.54 0.56 0.58 0.60 s y n t 0.25 0.50 0.75 1.00 P ower 0.52 0.54 0.56 0.58 0.60 s y n t 0.25 0.50 0.75 FDR 100 200 300 400 500 n 0.1 0.2 FDR BH (real) BH (synth) SynthBH B H ( r e a l + ) + (b) W orst-case synthetic data (in terms of error): synthetic data indicate non-null signal for all hypotheses, including nulls. Figure S2: Comparison of multiple hypothesis testing as a function of the synthetic signal strength ρ synth . Results are shown for (a) high-quality synthetic data and (b) worst-case synthetic data (in terms of error). Left: av erage detection rate (power). Right: a verage false discov ery proportion. 0.05 0.10 0.15 0.20 0.6 0.8 P ower 0.05 0.10 0.15 0.20 0.1 0.2 0.3 FDR (a) High-quality synthetic data: synthetic data follow the same null/non-null structure as the real data. 0.05 0.10 0.15 0.20 0.6 0.8 1.0 P ower 0.05 0.10 0.15 0.20 0.25 0.50 0.75 FDR 100 200 300 400 500 n 0.1 0.2 FDR BH (real) BH (synth) SynthBH B H ( r e a l + ) + (b) W orst-case synthetic data (in terms of error): synthetic data indicate non-null signal for all hypotheses, including nulls. Figure S3: Comparison of multiple hypothesis testing as a function of ε . Results are shown for (a) high-quality synthetic data and (b) worst-case synthetic data (in terms of error). Left: average detection rate (po wer). Right: av erage false discov ery proportion. The effect of ε . As discussed throughout the paper , ε can be interpreted as the “admission cost” in terms of 14 extra error the user is willing to accept to potentially benefit from synthetic data. Therefore, in the worst-case scenario, SynthBH incurs an additional ε error, but at the same time its power increases with ε for all synthetic data qualities. Similar to the previous analyses, we consider two scenarios: (a) high-quality synthetic data, and (b) worst-case synthetic data in terms of error . Figure S3 shows performance as a function of the parameter ε for both scenarios. In Figure S3a, SynthBH improves power as ε increases while maintaining FDR close to the nominal level α for high-quality synthetic data. In contrast, Figure S3b illustrates the worst-case synthetic data scenario: the po wer of SynthBH also increases with ε , but FDR is close to α + ε , remaining controlled. BH (synth) , by comparison, exhibits e xtremely inflated and uncontrolled FDR. A.2 Conf ormal Outlier Detection W e include additional results extending the experiments presented in Appendix 6.1. Figure S4 shows the performance of the conformal outlier detection methods on the Shuttle dataset as a function of the real data sample size n . When n is very small, both BH (real) and BH (real + ε ) achieve nearly zero power , and consequently SynthBH also has zero po wer . As n increases, the po wer of all three methods improv es. In this regime, SynthBH achie ves higher power than BH (real) , while maintaining FDR close to the nominal lev el α , and exhibits lo wer variability than BH (real + ε ) . 100 200 500 1000 n 0.0 0.2 0.4 0.6 Empirical P ower 100 200 500 1000 n 0.0 0.2 0.4 0.6 FDP 50 100 200 500 n 0.0 0.5 1.0 FDR BH (real) BH (synth) SynthBH B H ( r e a l + ) + Figure S4: Comparison of conformal outlier detection methods on the Shuttle dataset as a function of the real data sample size n . Left: detection rate (empirical power). Right: false discov ery proportion. Figure S5 shows the performance of the conformal outlier detection methods as a function of the trimming pro- portion ρ , which ef fectiv ely controls the quality of the synthetic data. For low trimming v alues ( ρ = 1% ), BH (synth) conservati vely controls the FDR at le vel α . In this regime, SynthBH also remains conserva- tiv e, yet notably achieves higher po wer than both BH (real) and BH (synth) . As ρ increases, SynthBH 0.01 0.02 0.025 0.03 0.05 0.0 0.2 0.4 0.6 Empirical P ower 0.01 0.02 0.025 0.03 0.05 0.0 0.2 0.4 0.6 FDP 50 100 200 500 n 0.0 0.5 1.0 FDR BH (real) BH (synth) SynthBH B H ( r e a l + ) + Figure S5: Comparison of conformal outlier detection methods on the Shuttle dataset as a function of the trimming proportion ρ . Left: detection rate (empirical power). Right: false discov ery proportion. becomes less conservati ve, achieving higher po wer than BH (real) while achie ving FDR close to the nominal 15 lev el α . F or high trimming values, BH (synth) exhibits uncontrolled FDR le vels, whereas SynthBH continues to control the FDR at level α + ε , as guaranteed by Theorem 5.2. These results illustrate that SynthBH adapts to the unknown quality of the synthetic data, le veraging them when informativ e and remaining safe when they are not. Figure S6 shows the same experiment as Figure 2, b ut with a lo wer value of ε = 5% . The results follow the same trend: when the synthetic data are informati ve, SynthBH potentially achie ve higher power than BH (real) at the same empirical FDR. When the synthetic data are uninformativ e, SynthBH matches the performance of BH (real) . The potential impro vement depends on ε , with larger values of ε generally allowing for greater power g ains. 0.000 0.050 0.100 0.150 F D R 0.0 0.2 0.4 P ower 0.000 0.050 0.100 0.150 F D R 0.0 0.2 0.4 P ower (a) Shuttle 0.000 0.050 0.100 0.150 F D R 0.0 0.2 0.4 P ower 0.000 0.050 0.100 0.150 F D R 0.0 0.2 0.4 P ower (b) Credit-card 0.00 0.10 0.20 F D R 0.0 0.2 0.4 0.6 P ower 0.00 0.10 0.20 F D R 0.0 0.2 0.4 0.6 P ower (c) KDDCup99 100 200 300 400 500 n 0.0 0.5 1.0 P ower BH (real) SynthBH Figure S6: Power as a function of the empirical FDR for BH (real) and our proposed method SynthBH across different outlier detection datasets: (a) Shuttle, (b) Credit-card, and (c) KDDCup99. The first ro w corresponds to a trimming proportion of 2%, and the second row corresponds to a trimming proportion of 0%, representing a scenario where synthetic data are not useful. Here, α ∈ [0 , 20%] . Results are shown for ε = 5% . A.3 Genomics of Drug Sensitivity in Cancer Figure S7 presents additional results on the GDSC genomic data with ε = 5% . The trends are consistent with those observed in the main manuscript: SynthBH obtains more rejections than BH (real) while maintaining high average ground-truth scores, notably larger than those of BH (real + ε ) . BH (synth) shows the same performance as in the main, as it does not depend on ε . Compared to the results with ε = 10% (Figure 3), SynthBH produces slightly fewer rejections, illustrating that the gain in po wer depends on the value of ε . 30 40 Number of Rejections 0.85 0.90 0.95 1.00 Ground Truth Score 0.85 0.90 0.95 1.00 Ground Truth Score BH (real) BH (synth) SynthBH B H ( r e a l + ) Figure S7: Comparison of multiple testing methods on GDSC genomic data for 100 tissue-feature-drug hypotheses. Left: number of rejections. Right: a verage ground-truth score of the rejection set. Results are shown for ε = 5% . 16 B Computational Complexity and Efficient Implementation Naive implementation cost. As written, Algorithm 1 iterates over k = 1 , . . . , m and (i) recomputes the rank- adaptiv e synthetic-po wered p-values ( ˜ p kε/m j ) j ∈ [ m ] and (ii) finds the k -th order statistic at each iteration. A direct implementation therefore performs Θ( m ) work per k , leading to Θ( m 2 ) time in the worst case (and O ( m ) mem- ory), which can be prohibitiv e in large-scale settings. A static reduction to BH. Despite the rank-adaptiv e definition, SynthBH admits an exact reduction to a single standard BH run on a static set of modified p-values. Fix α ∈ (0 , 1) and ε ≥ 0 , and define the constant c := α/ ( α + ε ) ∈ (0 , 1] . For each hypothesis j ∈ [ m ] , define the static modified p-value v j := p j ∧ ( ˜ p j ∨ ( cp j )) . (6) Lemma B.1 (Static reduction of SynthBH ) . F or every j ∈ [ m ] and every k ∈ [ m ] , the step- k acceptance condition in Algorithm 1 is equivalent to a static BH condition: ˜ p kε/m j ≤ αk /m holds if and only if v j ≤ αk /m . Consequently , the r ejection index k ∗ defined in (2) satisfies k ∗ = max { k ∈ [ m ] : v ( k ) ≤ αk/m } , wher e v ( k ) is the k -th smallest element of ( v j ) j ∈ [ m ] . Moreo ver , the r ejection set r eturned by Algorithm 1 coincides with the BH r ejection set at level α applied to ( v j ) j ∈ [ m ] (with the standar d tie convention of r ejecting all j such that v j ≤ v ( k ∗ ) ). Pr oof. Fix j and write p := p j and ˜ p := ˜ p j . Let t := αk /m and δ := kε/m , so δ = ( ε/α ) t . By definition, ˜ p δ j = p ∧ ( ˜ p ∨ ( p − δ )) . Thus ˜ p δ j ≤ t holds if and only if either p ≤ t , or simultaneously ˜ p ≤ t and p − δ ≤ t . The inequality p − δ ≤ t is equiv alent to p ≤ t + δ = t (1 + ε/α ) = ( α + ε ) t/α , which is in turn equivalent to cp ≤ t for c = α/ ( α + ε ) . Hence ˜ p δ j ≤ t is equi valent to p ≤ t or ( ˜ p ≤ t and cp ≤ t ) , which is exactly the condition p ∧ ( ˜ p ∨ ( cp )) ≤ t , i.e., v j ≤ t . Applying this equiv alence at t = αk /m for each k yields the claim about the feasible set of k s, hence the equality of k ∗ , and the equality of the resulting BH-style rejection sets (up to ties). W eighted case. F or weighted SynthBH (Algorithm 2), define c j := α/ ( α + w j ε ) and v ( w ) j := p j ∧ ( ˜ p j ∨ ( c j p j )) . The same argument (with δ = k w j ε/m ) shows that for ev ery j, k , ˜ p kw j ε/m j ≤ αk /m holds if and only if v ( w ) j ≤ αk /m . Therefore, Algorithm 2 is exactly BH at le vel α applied once to the static values ( v ( w ) j ) j ∈ [ m ] . Time and memory complexity . Computing ( v j ) (or ( v ( w ) j ) ) takes O ( m ) time and O ( m ) memory . Running BH on these values requires sorting, which takes O ( m log m ) time and O ( m ) memory , follo wed by a linear scan to find k ∗ and construct the rejection set. Hence, the step-up overhead of SynthBH matches the classic BH procedure: O ( m log m ) time and O ( m ) memory . In large-scale applications, the dominant additional cost is typically the cost of generating the underlying p-values ( p j ) and ( ˜ p j ) rather than the step-up rule itself. 17 C Pr oofs C.1 Proof of Lemma 5.1 Let h ( x ) = P { X ∈ A | W = x } . Then for x 1 < x 2 , P { X ∈ A | W ≤ x 2 } = P { X ∈ A, W ≤ x 2 } P { W ≤ x 2 } = E [ P { X ∈ A, W ≤ x 2 | W } ] P { W ≤ x 2 } = E [ P { X ∈ A | W } 1 { W ≤ x 2 } ] P { W ≤ x 2 } = E [ h ( W ) 1 { W ≤ x 2 } ] P { W ≤ x 2 } = E [ h ( W ) 1 { W ≤ x 1 } ] + E [ h ( W ) 1 { x 1 < W ≤ x 2 } ] P { W ≤ x 2 } = E [ h ( W ) | W ≤ x 1 ] P { W ≤ x 1 } + E [ h ( W ) | x 1 < W ≤ x 2 ] P { x 1 < W ≤ x 2 } P { W ≤ x 2 } ≥ E [ h ( W ) | W ≤ x 1 ] P { W ≤ x 1 } + E [ h ( W ) | W ≤ x 1 ] P { x 1 < W ≤ x 2 } P { W ≤ x 2 } = E [ h ( W ) | W ≤ x 1 ] = P { X ∈ A | W ≤ x 1 } , where the inequality holds since h is nondecreasing. This completes the proof. C.2 Proof of Theor em 4.4 The proof applies ideas presented in the expository work by W ang (2022). Throughout, let δ r := r ε/m for r ∈ [ m ] . Recall that the algorithm outputs an index k ∗ ∈ { 0 , 1 , . . . , m } and rejects the set R = n j ∈ [ m ] : ˜ p δ k ∗ j ≤ ˜ p δ k ∗ ( k ∗ ) o , with the conv ention that k ∗ = 0 implies R = ∅ . (If ties occur, then |R| ≥ k ∗ ; this only makes the bound below more conservati ve since we upper bound by k ∗ .) Write I 0 = { j ∈ [ m ] : H j is true } and m 0 = | I 0 | . Rewriting FDR and comparing to the BH threshold. By definition of FDR and the rejection rule, FDR = E |R ∩ I 0 | |R| ∨ 1 ≤ E P j ∈ I 0 1 n ˜ p δ k ∗ j ≤ ˜ p δ k ∗ ( k ∗ ) o k ∗ ∨ 1 · 1 { k ∗ ≥ 1 } , where the inequality uses |R| ≥ k ∗ (hence 1 / ( |R| ∨ 1) ≤ 1 / ( k ∗ ∨ 1) ) and R = ∅ when k ∗ = 0 . Next, on the event { k ∗ ≥ 1 } , the definition of k ∗ (Algorithm 1 / (2)) implies ˜ p δ k ∗ ( k ∗ ) ≤ αk ∗ /m . Therefore, by monotonicity of indicators (if a ≤ b then 1 { x ≤ a } ≤ 1 { x ≤ b } ), 1 n ˜ p δ k ∗ j ≤ ˜ p δ k ∗ ( k ∗ ) o ≤ 1 n ˜ p δ k ∗ j ≤ α k ∗ /m o , and hence FDR ≤ E P j ∈ I 0 1 n ˜ p δ k ∗ j ≤ α k ∗ /m o k ∗ ∨ 1 · 1 { k ∗ ≥ 1 } . 18 Conditioning on the value of k ∗ . Use the partition 1 { k ∗ ≥ 1 } = P m r =1 1 { k ∗ = r } and the fact that on { k ∗ = r } we hav e δ k ∗ = δ r : FDR ≤ E m X r =1 1 r X j ∈ I 0 1 n ˜ p δ r j ≤ α r/m o 1 { k ∗ = r } = m X r =1 X j ∈ I 0 1 r E h 1 n ˜ p δ r j ≤ α r/m o 1 { k ∗ = r } i (linearity of expectation) = X j ∈ I 0 m X r =1 1 r P ˜ p δ r j ≤ αr m , k ∗ = r (since E [ 1 { A } 1 { B } ] = P ( A ∩ B ) ) . Using the deterministic guardrail. W e hav e, deterministically for all j and r , ˜ p δ r j ≥ p j − δ r = p j − rε m . Hence, whenev er ˜ p δ r j ≤ αr/m occurs, we must have p j − rε m ≤ αr m , i.e., p j ≤ r ( α + ε ) m . Equi valently , n ˜ p δ r j ≤ αr m o ⊆ n p j ≤ r ( α + ε ) m o . Thus, FDR ≤ X j ∈ I 0 m X r =1 1 r P p j ≤ r ( α + ε ) m , k ∗ = r . Using super -uniformity of null p-v alues. For each ( j, r ) , P p j ≤ r ( α + ε ) m , k ∗ = r = P p j ≤ r ( α + ε ) m · P k ∗ = r p j ≤ r ( α + ε ) m (definition of conditional probability). Since j ∈ I 0 , p j is super-uniform, so for any t ∈ [0 , 1] , P ( p j ≤ t ) ≤ t . Applying this with t = r ( α + ε ) /m yields P p j ≤ r ( α + ε ) m ≤ r ( α + ε ) m . Therefore, FDR ≤ X j ∈ I 0 m X r =1 1 r · r ( α + ε ) m P k ∗ = r p j ≤ r ( α + ε ) m = α + ε m X j ∈ I 0 m X r =1 P k ∗ = r p j ≤ r ( α + ε ) m . PRDS/telescoping bound. Fix j ∈ I 0 . Define x r := r ( α + ε ) /m and q j,r := P ( k ∗ ≤ r | p j ≤ x r ) , r ∈ [ m ] , and let [ r ] 0 := { 0 } ∪ [ r ] . For notational con venience, set q j, 0 := 0 . Whenev er conditioning ev ents ha ve probability zero (e.g., P { ( } p j ≤ x r ) = 0 ), we interpret conditional probabilities via an arbitrary version (equiv alently , set them to 0 ); this does not affect the ar gument since the corresponding unconditional terms vanish. Monotonicity of the event { k ∗ ≤ r } . V iew k ∗ as a function of p = ( p 1 , . . . , p m , ˜ p 1 , . . . , ˜ p m ) ∈ [0 , 1] 2 m , i.e., k ∗ = k ∗ ( p ) . By Lemma C.1, k ∗ ( p ) is coordinate wise nonincreasing: if p ⪯ q then k ∗ ( p ) ≥ k ∗ ( q ) . Hence the set B r := { p : k ∗ ( p ) ≤ r } = ( k ∗ ) − 1 ([ r ] 0 ) 19 is an incr easing set: if p ∈ B r and q ⪰ p , then k ∗ ( q ) ≤ k ∗ ( p ) ≤ r , so q ∈ B r . Applying PRDS. By the PRDS assumption (Definition 4.3) with respect to ( p 1 , . . . , p m ) , for each null j and for any increasing set A , the function x 7→ P ( P ∈ A | p j ≤ x ) is nondecreasing. Applying this with A = B r shows that x 7→ P ( k ∗ ≤ r | p j ≤ x ) is nondecreasing. Since x r ≤ x r +1 , we obtain, for all r ∈ [ m − 1] , q j,r = P ( k ∗ ≤ r | p j ≤ x r ) ≤ P ( k ∗ ≤ r | p j ≤ x r +1 ) . Equiv alently , for r ≥ 1 , P ( k ∗ ≤ r − 1 | p j ≤ x r ) ≥ P ( k ∗ ≤ r − 1 | p j ≤ x r − 1 ) = q j,r − 1 . T elescoping. Using { k ∗ = r } = { k ∗ ≤ r } \ { k ∗ ≤ r − 1 } , P ( k ∗ = r | p j ≤ x r ) = P ( k ∗ ≤ r | p j ≤ x r ) − P ( k ∗ ≤ r − 1 | p j ≤ x r ) ≤ P ( k ∗ ≤ r | p j ≤ x r ) − P ( k ∗ ≤ r − 1 | p j ≤ x r − 1 ) = q j,r − q j,r − 1 . Summing ov er r = 1 , . . . , m and telescoping giv es m X r =1 P ( k ∗ = r | p j ≤ x r ) ≤ m X r =1 ( q j,r − q j,r − 1 ) = q j,m − q j, 0 ≤ 1 , since q j,m ≤ 1 and q j, 0 ≥ 0 . Applying the last display for each j ∈ I 0 yields FDR ≤ α + ε m X j ∈ I 0 1 = m 0 m ( α + ε ) , which prov es the claim for Algorithm 1. For Algorithm 2, define δ j,r := r w j ε/m for r ∈ [ m ] . Repeating the same steps as in the unweighted case yields FDR ≤ X j ∈ I 0 m X r =1 1 r P ˜ p δ j,r j ≤ αr m , k ∗ = r ≤ X j ∈ I 0 m X r =1 1 r P p j ≤ r ( α + w j ε ) m , k ∗ = r , where we used the deterministic inequality ˜ p δ j,r j ≥ p j − δ j,r = p j − r w j ε/m . Now fix j ∈ I 0 and write x j,r := r ( α + w j ε ) /m . Since p j is super-uniform under H j , P { ( } p j ≤ x j,r ) ≤ x j,r , hence FDR ≤ X j ∈ I 0 m X r =1 1 r · r ( α + w j ε ) m P { k ∗ = r | p j ≤ x j,r } = X j ∈ I 0 α + w j ε m m X r =1 P { k ∗ = r | p j ≤ x j,r } . It remains to bound P m r =1 P { k ∗ = r | p j ≤ x j,r } . Define q j,r := P { k ∗ ≤ r | p j ≤ x j,r } for r ∈ [ m ] , and set q j, 0 := 0 . 20 By Lemma C.2, the set { k ∗ ≤ r } is increasing in ( p 1 , . . . , p m , ˜ p 1 , . . . , ˜ p m ) . By the PRDS-with-respect-to- ( p 1 , . . . , p m ) assumption, x 7→ P { ( } k ∗ ≤ r | p j ≤ x ) is nondecreasing. Since x j,r is nondecreasing in r , the same telescoping argument gi ves P m r =1 P { k ∗ = r | p j ≤ x j,r } ≤ 1 . Therefore, FDR ≤ X j ∈ I 0 α + w j ε m = m 0 m α + ε m X j ∈ I 0 w j ≤ m 0 m α + ε, where the last inequality uses P m j =1 w j = m . The following lemmas are used in the proof. Lemma C.1. Let k ∗ = k ∗ ( p ) be defined as in (2) , where p = ( p 1 , p 2 , . . . , p m , ˜ p 1 , . . . , ˜ p m ) ∈ [0 , 1] 2 m . Then for any fixed p , q ∈ [0 , 1] 2 m such that p ⪯ q , it holds that k ∗ ( p ) ≥ k ∗ ( q ) . Pr oof of Lemma C.1. Fix any p ⪯ q , and write p = ( p 1 , p 2 , . . . , p m , ˜ p 1 , . . . , ˜ p m ) and q = ( q 1 , q 2 , . . . , q m , ˜ q 1 , . . . , ˜ q m ) . It suffices to sho w that k ∈ [ m ] : m · ˜ q kε/m ( k ) k ≤ α ⊂ k ∈ [ m ] : m · ˜ p kε/m ( k ) k ≤ α , (7) where ˜ q δ j and ˜ q kε/m ( k ) are defined analogously to ˜ p δ j and ˜ p kε/m ( k ) , respectiv ely . Observe that, by the definition of ˜ p δ j and ˜ q δ j , p ⪯ q implies ˜ p δ j ≤ ˜ q δ j for any j ∈ [ m ] and δ ≥ 0 , which in turn implies ˜ p δ ( k ) ≤ ˜ q δ ( k ) for any k ∈ [ m ] and δ ≥ 0 . This prov es the subset relation (7). Lemma C.2. F ix weights ( w j ) j ∈ [ m ] and let k ∗ w = k ∗ w ( p ) be the r ejection index pr oduced by Algorithm 2, viewed as a function of p = ( p 1 , . . . , p m , ˜ p 1 , . . . , ˜ p m ) ∈ [0 , 1] 2 m . Then k ∗ w is coor dinatewise nonincr easing: if p ⪯ q , then k ∗ w ( p ) ≥ k ∗ w ( q ) . Pr oof. Fix p ⪯ q . For each k ∈ [ m ] and each j ∈ [ m ] , define ˜ p ( k ) j := p j ∧ ( ˜ p j ∨ ( p j − k w j ε/m )) and define ˜ q ( k ) j analogously from q . Because min( · , · ) and max( · , · ) are coordinatewise nondecreasing, p ⪯ q implies ˜ p ( k ) j ≤ ˜ q ( k ) j for all j , hence the k -th order statistics satisfy ˜ p ( k ) ( k ) ≤ ˜ q ( k ) ( k ) . Therefore any k satisfying ˜ q ( k ) ( k ) ≤ αk /m also satisfies ˜ p ( k ) ( k ) ≤ α k/m , implying the feasible set of k ’ s for q is contained in that for p and hence k ∗ w ( p ) ≥ k ∗ w ( q ) . C.3 Proof of Theor em 5.2 The proof applies ideas developed in Bates et al. (2023). W ithout loss of generality , it is enough to assume 1 ∈ I 0 and show that for an y increasing set A ⊂ [0 , 1] 2 m , P { ( p 1 , p 2 , . . . , p m , ˜ p 1 , . . . , ˜ p m ) ∈ A | p 1 = t } is a nondecreasing function of t . For simplicity , let us write S i = s ( X i ) for i ∈ [ n + m ] and ˜ S i = s ( ˜ X i ) for i ∈ [ N ] . Observe that p 1 = R n +1 , where R = n X i =1 1 { S i ≥ S n +1 } + 1 = n X i =1 1 S ( i ) ≥ S n +1 + 1 21 denotes the rank of S n +1 among ( S 1 , . . . , S n , S n +1 ) , and S (1) > S (2) > . . . > S ( n ) denote the order statistics of S 1 , . . . , S n in a decreasing order . Therefore, it suf fices to show that for an y 1 ≤ r 1 < r 2 ≤ n + 1 , P { ( p 1 , p 2 , . . . , p m , ˜ p 1 , . . . , ˜ p m ) ∈ A | R = r 1 } ≤ P { ( p 1 , p 2 , . . . , p m , ˜ p 1 , . . . , ˜ p m ) ∈ A | R = r 2 } . Let ¯ S (1) > ¯ S (2) > . . . > ¯ S ( n ) > ¯ S ( n +1) be the order statistics of S 1 , . . . , S n , S n +1 in a decreasing order . Then, by the definition of R , we hav e ( S (1) , S (2) , . . . , S ( n ) ) = ( ¯ S (1) , . . . , ¯ S ( R − 1) , ¯ S ( R +1) , . . . , ¯ S ( n +1) ) . (8) Now fix an y r ∈ [ n + 1] . Define a rank- r hypothetical v ector of p-values as follo ws. Set p r 1 := r / ( n + 1) and ˜ p r 1 := r + P N i =1 1 n ˜ S i ≥ ¯ S ( r ) o n + N + 1 , and for each j = 2 , . . . , m , define p r j := 1 + P n +1 i =1 , i = r 1 ¯ S ( i ) ≥ S n + j n + 1 , ˜ p r j := 1 + P n +1 i =1 , i = r 1 ¯ S ( i ) ≥ S n + j + P N i =1 1 n ˜ S i ≥ S n + j o n + N + 1 . By construction, on the e vent { R = r } we ha ve ( p 1 , . . . , p m , ˜ p 1 , . . . , ˜ p m ) = ( p r 1 , . . . , p r m , ˜ p r 1 , . . . , ˜ p r m ) . Observe also that p r 1 j ≤ p r 2 j and ˜ p r 1 j ≤ ˜ p r 2 j hold for any r 1 < r 2 , by construction. Indeed, for j ≥ 2 the only dependence on r in p r j (and ˜ p r j ) is through omitting ¯ S ( r ) from the sum over ¯ S ( i ) . Since r 1 < r 2 implies ¯ S ( r 1 ) > ¯ S ( r 2 ) , remo ving ¯ S ( r 1 ) can only decrease (relati ve to removing ¯ S ( r 2 ) ) the count of indices i for which ¯ S ( i ) ≥ S n + j , hence p r 1 j ≤ p r 2 j and similarly for ˜ p r j . Therefore, P { ( p 1 , p 2 , . . . , p m , ˜ p 1 , . . . , ˜ p m ) ∈ A | R = r 1 } = P ( p R 1 , p R 2 , . . . , p R m , ˜ p R 1 , . . . , ˜ p R m ) ∈ A R = r 1 = P { ( r 1 / ( n + 1) , p r 1 2 , . . . , p r 1 m , ˜ p r 1 1 , . . . , ˜ p r 1 m ) ∈ A | R = r 1 } = P { ( r 1 / ( n + 1) , p r 1 2 , . . . , p r 1 m , ˜ p r 1 1 , . . . , ˜ p r 1 m ) ∈ A } , where the last equality holds since for each fixed r the v ector ( p r 1 , . . . , p r m , ˜ p r 1 , . . . , ˜ p r m ) is a measurable function of ( ¯ S (1) , . . . , ¯ S ( n +1) ) , ( ˜ S 1 , . . . , ˜ S N ) , and ( S n +2 , . . . , S n + m ) , all of which are independent of R under H 1 and the stated independence assumptions. Indeed, under H 1 and the distinctness assumption, the rank R of S n +1 among ( S 1 , . . . , S n , S n +1 ) is uniform on [ n + 1] and independent of the order statistics ( ¯ S (1) , . . . , ¯ S ( n +1) ) . Moreover , since A is an increasing set, and due to the inequalities observed above, this is upper bounded by P { ( r 2 / ( n + 1) , p r 2 2 , . . . , p r 2 m , ˜ p r 2 1 , . . . , ˜ p r 2 m ) ∈ A } = P { ( p 1 , p 2 , . . . , p m , ˜ p 1 , . . . , ˜ p m ) ∈ A | R = r 2 } , Thus, by Lemma 5.1, we conclude that the PRDS property from Definition 4.3 holds. By Theorem 4.4, this finishes the proof. 22 D Additional Experimental Details D.1 Outlier Detection Experimental Details Experimental setup and metrics. Unless stated otherwise, we use n = 500 inlier samples D n , and N = 2 , 500 contaminated samples ˜ D N , containing 5% outliers, with trimming proportion of ρ = 2% . The outlier detection model is an Isolation Forest (Liu et al., 2008) with 100 estimators, trained on 5 , 000 samples ( 2 , 500 for the Credit- card dataset) with the same contamination rate as ˜ D N . The test set contains 1 , 000 datapoints with 5% outliers. The target FDR le vel is α = 10% , and ε = 10% . All sets ( D n , ˜ D N , the training set, and the test set) are disjoint. W e report the detection rate and the false discov ery proportion over 100 random splits of the data. Dataset details. W e consider three tabular benchmark datasets, accessed via the openML Python package (Bis- chl et al., 2021; Feurer et al., 2021). Below , we summarize the key characteristics of each dataset, including the total number of samples, the number of outliers, and the number of features. • Shuttle: This dataset inv olves the task of classifying space shuttle flight data, where a subset of classes are considered outliers. It contains 58 , 000 samples, with 12 , 414 labeled as outliers, and has 9 features. • KDDCup99: Used for network intrusion detection, we focus on detecting pr obe attacks. The dataset con- tains 101 , 384 samples, of which 4 , 107 correspond to probe attacks (outliers), including the types Satan , Ipsweep , Nmap , and Portsweep . The data has 41 features. • Credit Card Fraud: This dataset consists of European credit card transactions, with the task of identifying fraudulent activity . It contains 284 , 807 samples, including 492 fraudulent transactions (treated as outliers), with 29 features. D.2 Genomics of Drug Sensitivity in Cancer W e provide the full list of hypotheses tested in the GDSC experiments. As described in Appendix 6.2, each hypothesis corresponds to a specific tissue–feature–drug triple. In total, we test 100 hypotheses. The tested tis- sue–feature–drug triples are listed below . T able S1: List of tissue-feature-drug hypotheses tested in the GDSC experiments. BRCA denotes breast in vasi ve carcinoma and LU AD denotes lung adenocarcinoma. T issue Genomic feature Drug BRCA gain_cnaP ANCAN301_(CDK12,ERBB2,MED24) Ibrutinib BRCA PIK3CA_mut T aselisib BRCA gain_cnaP ANCAN301_(CDK12,ERBB2,MED24) Sapitinib BRCA gain_cnaP ANCAN301_(CDK12,ERBB2,MED24) Osimertinib BRCA PIK3CA_mut Alpelisib BRCA gain_cnaP ANCAN301_(CDK12,ERBB2,MED24) Afatinib BRCA gain_cnaP ANCAN301_(CDK12,ERBB2,MED24) Lapatinib BRCA gain_cnaP ANCAN87 Cediranib BRCA PTEN_mut AZD8186 BRCA loss_cnaP ANCAN93 VTP-B BRCA loss_cnaP ANCAN94 VTP-B Continued on next page 23 T issue Genomic feature Drug BRCA loss_cnaP ANCAN95 VTP-B BRCA loss_cnaP ANCAN96 VTP-B BRCA PTEN_mut Afuresertib LU AD loss_cnaP ANCAN92 Daporinad BRCA gain_cnaP ANCAN301_(CDK12,ERBB2,MED24) Alpelisib BRCA PTEN_mut Ipatasertib BRCA gain_cnaP ANCAN87 PFI-1 LU AD STK11_mut Nutlin-3a (-) BRCA TP53_mut Nutlin-3a (-) LU AD loss_cnaP ANCAN96 Sapitinib BRCA gain_cnaP ANCAN88_(P ABPC1,UBR5) Cediranib BRCA PTEN_mut AZD5363 BRCA loss_cnaP ANCAN210_(F A T1,IRF2) Uprosertib BRCA gain_cnaP ANCAN87 Foretinib BRCA gain_cnaP ANCAN367_(ARFGAP1,GN AS) T ozasertib LU AD loss_cnaP ANCAN96 AZD3759 BRCA gain_cnaP ANCAN367_(ARFGAP1,GN AS) Pyridostatin BRCA gain_cnaP ANCAN272_(PIP5K1A,SETDB1) Navitoclax BRCA gain_cnaP ANCAN280_(ARID4B,FH) BMS-754807 BRCA gain_cnaP ANCAN88_(P ABPC1,UBR5) V inorelbine BRCA gain_cnaP ANCAN363_(ASXL1) Sapitinib BRCA gain_cnaP ANCAN177_(IL7R) Eg5_9814 BRCA gain_cnaP ANCAN87 Paclitax el BRCA loss_cnaP ANCAN210_(F A T1,IRF2) PF-4708671 LU AD loss_cnaP ANCAN96 Erlotinib BRCA gain_cnaP ANCAN88_(P ABPC1,UBR5) Paclitax el LU AD gain_cnaP ANCAN164_(KRAS) T AF1_5496 LU AD loss_cnaP ANCAN96 Gefitinib LU AD STK11_mut Ipatasertib LU AD TP53_mut ERK_2440 BRCA gain_cnaP ANCAN302_(CL TC,PPM1D) AZD7762 LU AD gain_cnaP ANCAN164_(KRAS) OF-1 BRCA gain_cnaP ANCAN280_(ARID4B,FH) MK-1775 BRCA gain_cnaP ANCAN124_(EGFR) Gefitinib LU AD loss_cnaP ANCAN94 Sapitinib LU AD loss_cnaP ANCAN95 Sapitinib LU AD gain_cnaP ANCAN164_(KRAS) LGK974 LU AD gain_cnaP ANCAN91_(MYC) KRAS (G12C) Inhibitor-12 LU AD loss_cnaP ANCAN96 Ibrutinib LU AD loss_cnaP ANCAN337 V eliparib LU AD loss_cnaP ANCAN337 Serdemetan LU AD loss_cnaP ANCAN337 Sapitinib LU AD loss_cnaP ANCAN337 Lenalidomide LU AD loss_cnaP ANCAN337 A vagacestat LU AD loss_cnaP ANCAN337 VE821 LU AD loss_cnaP ANCAN337 V ismode gib LU AD loss_cnaP ANCAN338 CCT007093 LU AD loss_cnaP ANCAN337 GNE-317 LU AD loss_cnaP ANCAN337 BMS-754807 LU AD loss_cnaP ANCAN337 Motesanib Continued on next page 24 T issue Genomic feature Drug LU AD loss_cnaP ANCAN337 JQ1 LU AD loss_cnaP ANCAN337 T anespimycin LU AD loss_cnaP ANCAN337 Bosutinib LU AD loss_cnaP ANCAN337 BI-2536 LU AD loss_cnaP ANCAN337 Rucaparib LU AD loss_cnaP ANCAN338 Pyridostatin LU AD loss_cnaP ANCAN337 T emsirolimus LU AD loss_cnaP ANCAN338 A GK2 LU AD loss_cnaP ANCAN338 Olaparib LU AD loss_cnaP ANCAN338 AMG-319 LU AD loss_cnaP ANCAN338 PD0325901 LU AD loss_cnaP ANCAN337 R O-3306 LU AD loss_cnaP ANCAN338 AZD4547 LU AD loss_cnaP ANCAN338 Crizotinib LU AD loss_cnaP ANCAN337 PD173074 LU AD loss_cnaP ANCAN337 Fulvestrant LU AD loss_cnaP ANCAN338 Luminespib LU AD loss_cnaP ANCAN338 SB216763 LU AD loss_cnaP ANCAN338 Ribociclib LU AD loss_cnaP ANCAN337 MK-1775 LU AD loss_cnaP ANCAN337 Doramapimod LU AD loss_cnaP ANCAN337 Dactinomycin LU AD loss_cnaP ANCAN337 Afatinib LU AD loss_cnaP ANCAN337 T alazoparib LU AD loss_cnaP ANCAN337 Crizotinib LU AD loss_cnaP ANCAN337 Buparlisib LU AD loss_cnaP ANCAN338 LJI308 LU AD loss_cnaP ANCAN337 Dasatinib LU AD loss_cnaP ANCAN338 Ulixertinib LU AD loss_cnaP ANCAN338 Ipatasertib LU AD loss_cnaP ANCAN338 Cediranib LU AD loss_cnaP ANCAN338 5-Fluorouracil LU AD loss_cnaP ANCAN337 LJI308 LU AD loss_cnaP ANCAN338 V inorelbine LU AD loss_cnaP ANCAN337 Gefitinib LU AD loss_cnaP ANCAN338 Osimertinib LU AD loss_cnaP ANCAN338 R O-3306 LU AD loss_cnaP ANCAN337 Bortezomib LU AD loss_cnaP ANCAN337 5-Fluorouracil 25
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment