합성 데이터 활용 FDR 제어를 위한 SynthBH 방법
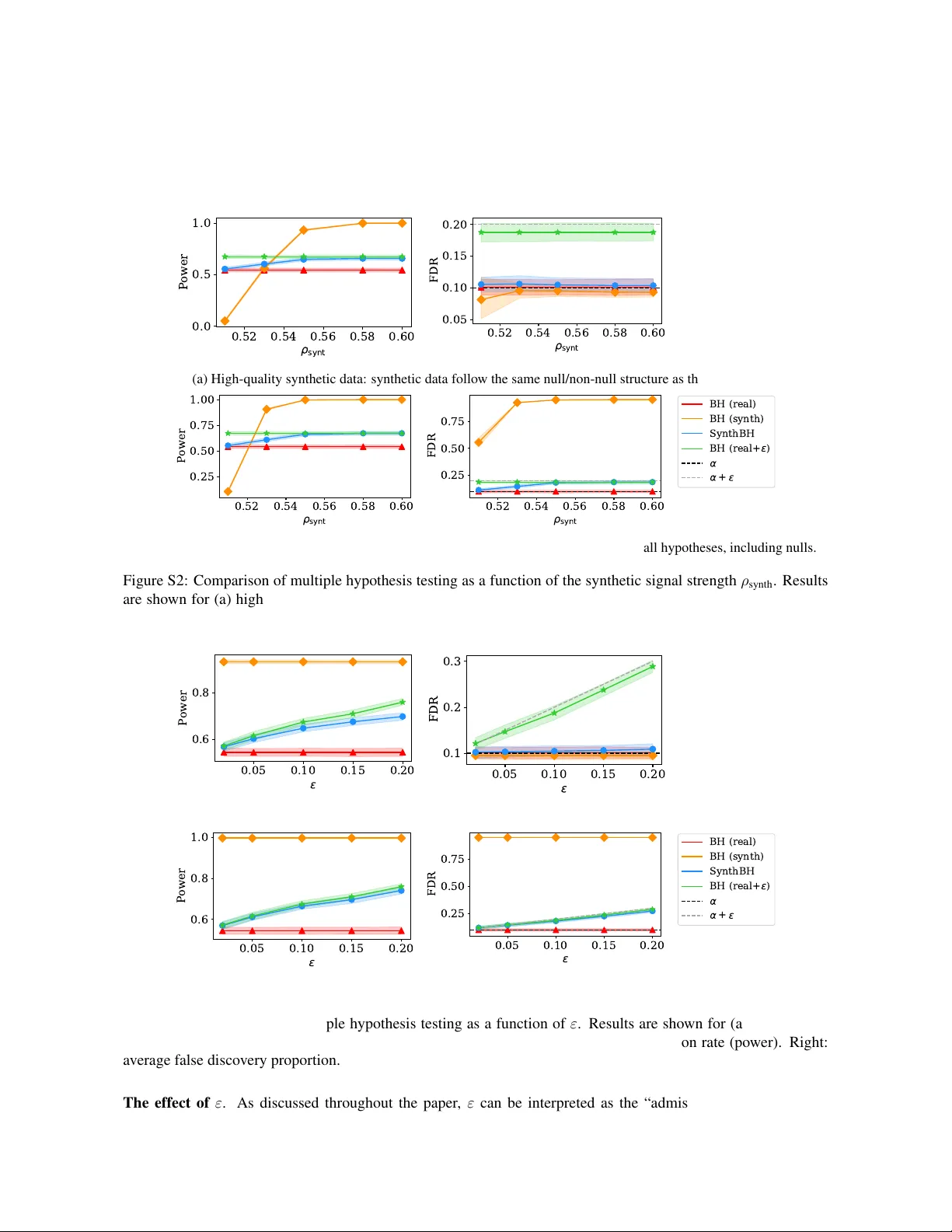
SynthBH는 실제 데이터에서 얻은 유효 p‑값과 합성 데이터를 포함한 보조 p‑값을 결합해, PRDS 형태의 약한 양의 의존성 하에서 유한 표본 FDR를 α+ε 수준으로 보장한다. 합성 데이터의 품질에 따라 자동으로 힘을 조절하며, 품질이 낮아도 허용 오차 ε만큼만 오류가 증가한다.
저자: Yonghoon Lee, Meshi Bashari, Edgar Dobriban
본 연구는 실제 실험 데이터가 제한적인 상황에서, 과거 실험, 약하게 라벨링된 데이터, 혹은 최신 생성 모델을 통해 만든 합성 데이터와 같은 보조 정보를 안전하게 활용하여 다중 가설 검정의 검출력을 높이는 방법을 제안한다. 기존 다중 검정 방법은 p‑값이 정확히 null 분포를 따를 것을 전제로 하지만, 합성 데이터는 그 분포가 알려지지 않거나 편향될 수 있다. 따라서 단순히 두 데이터를 합쳐 p‑값을 계산하면 FDR가 크게 상승할 위험이 있다.
이를 해결하기 위해 저자들은 “synthetic‑powered p‑value” ˜p_{δj}=p_j∧(˜p_j∨(p_j−δ)) 를 정의한다. 여기서 p_j는 실제 데이터만을 사용해 얻은 유효 p‑값이며, ˜p_j는 실제와 합성 데이터를 모두 사용해 얻은 p‑값이다. δ는 현재 검정 단계 k에 비례해 ε·k/m 으로 설정되며, 이는 합성 데이터가 제공하는 이득을 제한적으로 허용하는 guardrail 역할을 한다. 즉, 합성 데이터가 고품질이면 ˜p_j가 p_j보다 작아져 p_j∧˜p_j 로 대체되고, 품질이 낮으면 p_j−δ 로 제한돼 실제 p‑값이 크게 변하지 않는다.
SynthBH 알고리즘은 이 guardrail‑adjusted p‑값을 Benjamini–Hochberg 절차에 적용한다. 단계별로 k=1,…,m 에 대해 ˜p_{kε/m,j} 를 계산하고, k번째 작은 값이 α·k/m 이하이면 해당 k를 현재 최댓값 k* 로 저장한다. 최종적으로 k* 에 해당하는 임계값 이하인 모든 가설을 거절한다. 이 과정은 “rank‑adaptive” 라는 특징을 갖는데, 작은 p‑값일수록 더 큰 ε·k/m 보정을 받게 되어, 비영가설 가능성이 높은 가설에 합성 데이터의 이점을 더 많이 부여한다.
이론적 분석에서는 두 가지 핵심 가정을 제시한다. 첫째, (p_1,…,p_m) 와 (˜p_1,…,˜p_m) 가 확장된 PRDS(Positive Regression Dependence on a Subset) 조건을 만족한다. 이는 기존 PRDS가 요구하는 독립성 혹은 약한 양의 의존성을 두 집합 모두에 적용하도록 일반화한 것이다. 둘째, 사용자가 사전에 지정한 ε≥0 가 “admission cost” 로 작용해, 합성 데이터가 제공할 수 있는 최대 오류 증가량을 제한한다. 이러한 가정 하에 Theorem 4.2 는 SynthBH 가 유한 표본에서 FDR ≤ α+ε 를 보장한다는 것을 증명한다.
가중치가 부여된 가설에 대해서는 Algorithm 2 를 제시한다. 각 가설에 가중치 w_j 를 할당하고, ε·w_j/m 만큼의 guardrail을 적용한다. 이 경우에도 FDR는 α와 ε가 선형적으로 분리된 형태로 제어되며, 가중치에 따라 합성 데이터의 활용 정도를 조절할 수 있다(정리 4.4).
실험에서는 두 가지 실제 응용을 다룬다. 첫 번째는 tabular outlier detection 로, 작은 청정 레퍼런스 집합에서 얻은 conformal p‑값은 보수적이지만, 대규모 합성 데이터(예: 트리밍된 데이터)를 포함한 p‑값과 결합하면 탐지 파워가 크게 향상된다. 두 번째는 drug‑cancer sensitivity 분석으로, 유전체와 약물 반응 데이터를 결합한 대규모 합성 데이터가 실제 실험 데이터와 차이가 있더라도 SynthBH 가 FDR를 목표 수준에 가깝게 유지하면서 더 많은 유의미한 연관성을 발견한다. 시뮬레이션을 통해 합성 데이터 품질을 점진적으로 낮추어도 FDR가 α+ε 이하로 유지되는 것을 확인하였다.
결론적으로, 이 논문은 “synthetic‑powered inference” 개념을 FDR 제어라는 비선형 오류 지표에 성공적으로 적용했으며, 합성 데이터의 분포가 전혀 알려지지 않아도 강력한 오류 보장을 제공한다는 점에서 기존 side‑information 기반 방법과 차별화된다. 또한, guardrail‑based rank‑adaptive 설계는 실제 데이터가 부족한 현대 과학·공학 분야에서 합성 데이터를 안전하게 활용할 수 있는 실용적인 도구가 될 것으로 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기