How Much Does Machine Identity Matter in Anomalous Sound Detection at Test Time?
Anomalous sound detection (ASD) benchmarks typically assume that the identity of the monitored machine is known at test time and that recordings are evaluated in a machine-wise manner. However, in realistic monitoring scenarios with multiple known ma…
Authors: Kevin Wilkinghoff, Keisuke Imoto, Zheng-Hua Tan
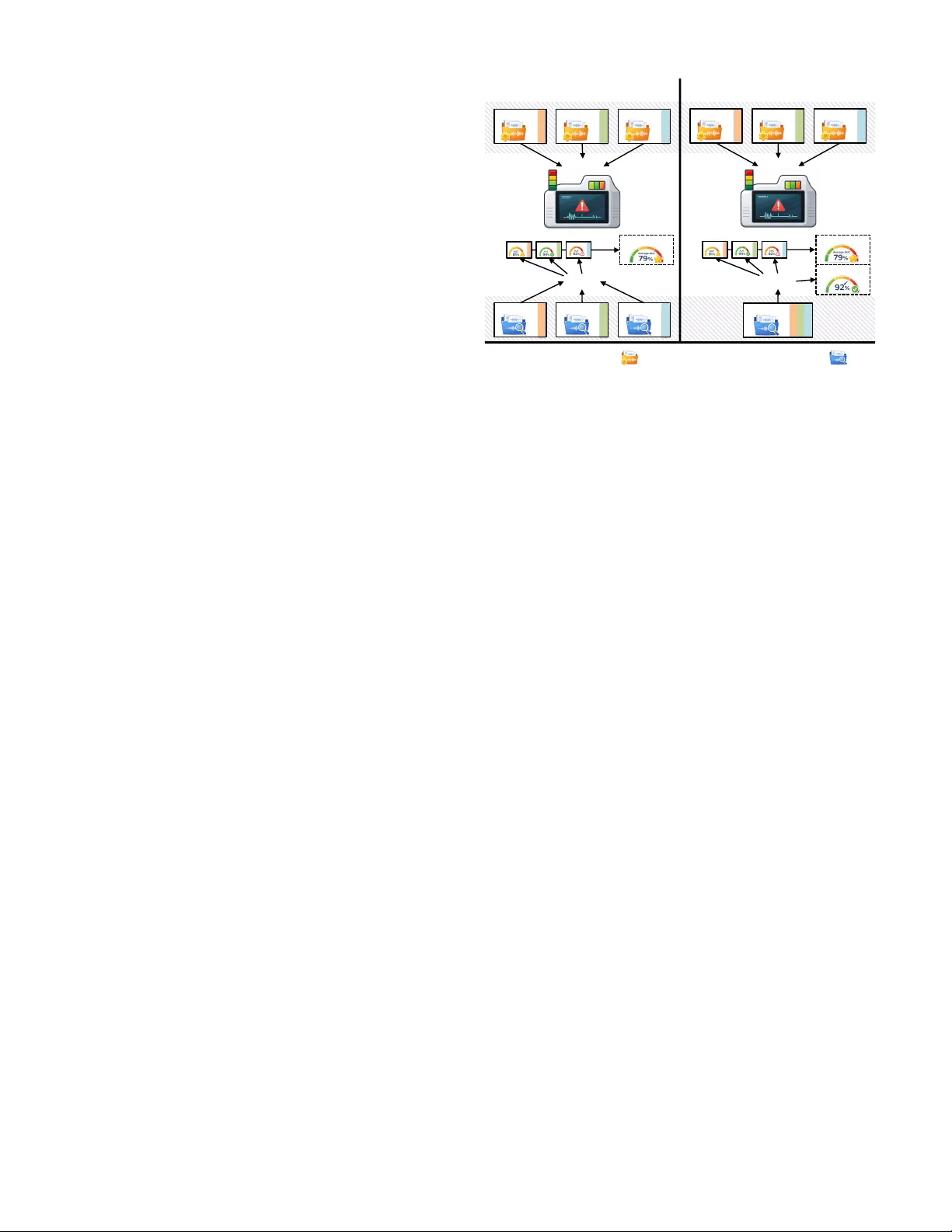
Ho w Much Does Machine Identity Matter in Anomalous Sound Detection at T est T ime? K evin W ilkinghoff 1 , 2 , K eisuke Imoto 3 , Zheng-Hua T an 1 , 2 1 Aalborg Univ ersity , Denmark, 2 Pioneer Centre for Artificial Intelligence, Denmark, 3 Kyoto Uni versity , Japan Abstract —Anomalous sound detection (ASD) benchmarks typ- ically assume that the identity of the monitored machine is known at test time and that recordings ar e evaluated in a machine- wise manner . However , in realistic monitoring scenarios with multiple known machines operating concurrently , test record- ings may not be reliably attributable to a specific machine, and requiring machine identity imposes deployment constraints such as dedicated sensors per machine. T o reveal performance degradations and method-specific differences in rob ustness that are hidden under standard machine-wise evaluation, we consider a minimal modification of the ASD evaluation protocol in which test recordings from multiple machines ar e merged and evaluated jointly without access to machine identity at inference time. T raining data and evaluation metrics r emain unchanged, and machine identity labels are used only for post hoc evaluation. Experiments with repr esentative ASD methods show that r elaxing this assumption reveals performance degradations and method- specific differences in rob ustness that are hidden under standard machine-wise e valuation, and that these degradations ar e str ongly related to implicit machine identification accuracy . Index T erms —anomalous sound detection, machine condition monitoring, evaluation protocols, rob ustness analysis I . I N T R O DU C T I O N Anomalous sound detection (ASD) aims to detect unusual sounds and is widely used in machine condition monitoring. The DCASE Challenge [1] has become a central benchmark for ASD. Recent editions emphasize robustness to domain shifts [2]–[6], moti vating e xtensive w ork on domain adaptation and generalization [7]. Despite these advances, current ASD ev aluations rely on an implicit assumption: T est recordings are associated with a known machine identity and ev aluated in a machine-wise manner . While the first-shot setting [4]– [6] reduces overly optimistic ev aluation by enforcing disjoint machine types between system development and ev aluation, it still assumes access to machine identity at test time. This assumption does not always hold in practice. In re- alistic monitoring scenarios, multiple known machines may operate concurrently , and test recordings cannot always be reliably attrib uted to a specific machine. From an operator perspectiv e, it is therefore desirable for a system to identify which machine behav es abnormally , rather than assuming that machine identity is giv en. One alternative is to use microphone arrays and sound source localization to infer the originating machine, but such solutions increase cost, system complexity , and installation ef fort, and are often impractical in existing industrial settings. Moreov er , relying on dedicated sensing infrastructure for each machine limits fle xibility when machine layouts or in ventories change. Evaluating ASD without ma- chine identity therefore supports more scalable and reusable monitoring systems that can be deployed across different factories and operating conditions. These practical constraints are not reflected in current e val- uation protocols. Many approaches rely on machine-specific models [8], machine-specific operating-condition information [9], [10], or machine-specific test-set statistics for anomaly score normalization [11]. All of these require access to machine identity or delayed aggregation of test data. Such assumptions may not hold in realistic monitoring scenarios, causing standard ev aluations to hide robustness differences that only emerge when they are violated. Throughout this work, we consider the same scope assump- tions as current DCASE benchmarks: single-channel record- ings that contain sounds from a single machine, and a fixed, known set of machines. The only assumption that is relaxed is the av ailability of machine identity at test time. T est recordings from multiple known machines are merged into a single test set and ev aluated jointly , while training data and ev aluation metrics remain unchanged. Machine identity labels are used only for post hoc ev aluation. Rather than proposing new detection models, our goal is to analyze how representative ASD methods behav e when this single ev aluation assumption is relaxed. The contributions of this work are: • W e make explicit the implicit assumption of known machine identity in current ASD e valuation protocols; • W e propose a minimal ev aluation protocol that removes machine identity at inference time while keeping all other aspects unchanged; • W e empirically show that relaxing this assumption ex- poses method-specific robustness differences and link anomaly detection performance degradation to implicit machine identification accuracy , quantified via an auxil- iary post hoc identification task. I I . B AC K G RO U N D A N D P RO B L E M S E T T I N G W e briefly summarize the standard ASD formulation and ev aluation protocol in the DCASE Challenge to make explicit the assumptions relev ant to this work and position our setting relativ e to existing benchmarks. A. Anomalous Sound Detection Setup In acoustic machine condition monitoring, ASD aims to detect sounds that deviate from a machine’ s normal operat- ing behavior , typically under the assumption that anomalous examples are rare or unav ailable during training. The DCASE Challenge on unsupervised ASD [2]–[6], [12] has become the de facto benchmark for this task. In the standard DCASE setting, datasets are organized into dev elopment and ev aluation splits, each containing machine- specific training and test data. Training data consist exclusi vely of normal recordings from indi vidual machines and are asso- ciated with machine IDs. At ev aluation time, test recordings are grouped by machine, include both normal and anomalous samples, and performance is reported using machine-wise metrics. Models are therefore trained either separately for each machine or using a shared model with access to machine identity at inference time. B. Implicit Assumption of Known Machine Identity An implicit but central assumption in this protocol is that machine identity is known at test time. Each test recording is assumed to be associated with a specific machine ID, and anomaly scores are computed and ev aluated within machine- wise partitions. While this assumption simplifies both mod- eling and ev aluation, it does not necessarily hold in practical monitoring scenarios, where multiple known machines may operate concurrently and recordings cannot always be reliably attributed to a specific machine. In the remainder of this paper, we analyze the consequences of relaxing this assumption. I I I . E V A L U A T I O N P R OT O C O L W I T H O U T M A C H I N E I D E N T I T Y W e introduce a minimal modification to the standard DCASE ev aluation protocol in which machine identity is unav ailable at test time. All other aspects of the benchmark are left unchanged, allowing us to isolate the impact of this assumption on ASD performance. Figure 1 compares the standard DCASE ev aluation protocol with the proposed identity-free variant. A. T est Set Construction For both the de velopment and ev aluation splits of the dataset (cf. Section II-A), all test recordings from multiple known machines are merged into a single test set, spanning different machine types. The original dev elopment–ev aluation split and label distributions are preserved. Machine identity information is removed at inference time, while the audio recordings themselves are used as-is. B. T asks and Outputs The primary task remains anomaly detection, defined ex- actly as in the standard ASD setting: Giv en an input audio recording, the system produces an anomaly score indicating the likelihood that the recording de viates from normal oper- ation. Models are not informed of the machine identity and must process all test recordings jointly . W e additionally consider a secondary task in which a method predicts the machine ID of a test recording. This task is not part of the main ASDobjective and is e valuated only after Standard DCASE E valuation Proposed E valuation (No Machine ID) Machine A Machine B Machine C Machine C Machine B ASD System Tra i ni n g Te s t i n g Machine A Machine A Machine B Machine C ASD System Tra i ni n g Te s t i n g No Machine ID ASD Performance Identificat ion Acc. training data: only normal sample test da t a: normal and anomalou s samples ASD Performance Machine identities unavailable at test ti me Machine A Machine - wise ASD Perf ormance Machine B Machine C Machine A Machine B Machine C Machine - wise ASD Perf ormance Fig. 1. Comparison of the standard DCASE ev aluation protocol and the proposed evaluation without machine identity . T raining data and anomaly detection metrics are unchanged; machine identity is unavailable at inference time, and machine identification accuracy is reported as an auxiliary metric. inference using machine identity labels that are unav ailable to the model at test time. Beyond serving as a diagnostic tool, it is also practically motiv ated by monitoring scenarios in which identifying the abnormal machine is required. W e now formalize the relationship between anomaly detec- tion without machine identity and implicit machine identifi- cation. Let s m ( x ) denote a machine-specific anomaly score for a test recording x , obtained either from a machine-specific model or implicitly via reference data. When machine identity is known, detection is based on s m ∗ ( x ) , where m ∗ is the true machine. In the absence of machine identity , a natural aggregation strategy is s ( x ) = min m s m ( x ) , (1) corresponding to selecting the machine whose notion of nor- mality best explains the test recording [13]. In contrast to open-set classification, the machine set is fixed and known, and the challenge lies in resolving the correct machine-specific normality model without identity labels, rather than handling unseen classes. W ithout access to machine identity at inference time, anomaly detection performance matches the standard protocol precisely when arg min m s m ( x ) = m ∗ for all x, (2) highlighting that anomaly detection without machine iden- tity implicitly requires correct machine identification. Conse- quently , any degradation in anomaly detection performance relativ e to the standard setting arises from incorrect implicit machine identification. For rank-based metrics such as the area under the R OC curve (A UC) and partial A UC (pA UC) [14], [15], this degradation occurs only when an incorrect machine is selected and thus grows with the probability of such errors, P arg min m s m ( x ) = m ∗ . (3) C. Evaluation Metrics In contrast to the modified test set construction described abov e, ev aluation itself follows the standard DCASE protocol. After inference, anomaly scores are retrospectively associated with machine IDs and ev aluated per machine using A UC and pA UC with p = 0 . 1 , followed by averaging across machines as in the original benchmark. In addition to anomaly detection performance, we report implicit machine identification accuracy , which is chance- normalized to account for differing numbers of machines across datasets and defined as ( a − 1 /K ) / (1 − 1 /K ) , where a denotes the raw identification accuracy and K the num- ber of machines. T o relate anomaly detection performance degradation to implicit machine identification accuracy , we define a chance-normalized degradation of anomaly detection performance. Since both A UC and pA UC have a fixed chance lev el of 0 . 5 , the normalized degradation is giv en by ∆ norm = 1 − A unknown − 0 . 5 A known − 0 . 5 , (4) where A known and A unknown denote anomaly detection perfor- mance with known and unknown machine identity , respec- tiv ely , computed using the standard DCASE ev aluation proto- col. The measure is undefined when A known ≤ 0 . 5 , i.e., when no discriminative performance abov e chance is av ailable. This quantity represents the fraction of performance above chance lost when machine identity is unav ailable and is directly com- parable to chance-normalized machine identification accuracy . Machine identity labels are used for e valuation and are ne ver provided to the models during inference. Any performance differences relativ e to the standard protocol can therefore be at- tributed solely to the absence of machine identity information at test time. Throughout the paper , “identification accuracy” denotes implicit machine identification via score aggregation, not an explicit classifier . I V . E X P E R I M E N T A L S E T U P In the previous section, we introduced an ev aluation proto- col without machine identity at test time. Here, we quantify the resulting performance changes across different ASD systems. A. Datasets W e conduct our experimental ev aluation on five publicly av ailable datasets for semi-supervised acoustic anomaly de- tection from the DCASE Challenge. Specifically , we consider DCASE2020 [12], constructed from MIMII [16] and T o y- ADMOS [17]; DCASE2022 [3], based on MIMII-DG [18] and T oyADMOS2 [19]; DCASE2023 [4], extending MIMII- DG and T o yADMOS2+ [20]; DCASE2024 [5], incorporating MIMII-DG, T oyADMOS2# [21], and recordings collected un- der the IMAD-DS setup [22]; and DCASE2025 [6], consisting of MIMII-DG, T o yADMOS2025 [23], and IMAD-DS. Across these datasets, each dev elopment and ev aluation set contains between 7 and 21 machines belonging to 6–7 machine types. Except for DCASE2020, which contains a single domain, all datasets provide 990 source-domain and 10 target-domain training samples per machine. In the test sets, samples from different domains are balanced, but explicit domain labels are not provided. For both the dev elopment and ev aluation splits, test recordings are merged per split following the procedure described in Section III-A. Results are computed separately for dev elopment and ev aluation splits, and reported individually (Fig. 2) and aggregated across splits and datasets following the standard DCASE averaging protocol (T able I). B. ASD Systems W e ev aluate a diverse set of ASD systems spanning three commonly used modeling paradigms [24]: (i) discriminativ ely trained models that learn to distinguish between machine identities or operating states during training, (ii) training- free approaches based on pre-trained embeddings, including OpenL3 [25], BEA Ts [26], EA T [27], and Dasheng [28], and (iii) methods relying on machine-specific models or reference data. These paradigms are not intended to be exhausti ve, but to cover representative and widely used classes of ASD approaches in the DCASE literature. In particular, many generativ e-based methods ultimately produce machine-specific anomaly scores and fall into category (iii) under the proposed ev aluation setting. Owing to space constraints, we omit de- scriptions of indi vidual methods. All systems are e v aluated exactly as originally proposed, reusing the reported feature extraction pipelines and hyperparameters, without architectural modifications or tuning for the proposed ev aluation setting. In addition, we assess the effect of commonly used anomaly score normalization strategies that are designed to improv e robustness under domain shifts. Specifically , we consider normalization approaches that adjust anomaly scores using machine-specific reference samples prior to score computation [29]–[31]. These normalization methods are applied on top of the ev aluated ASD systems and analyzed with respect to both anomaly detection performance and implicit machine identification accuracy . V . R E S U L T S W e analyze robustness across ASD systems and relate de- tection degradation to implicit machine identification accurac y . A. Robustness of ASD Systems to Unknown Machine Identity T able I summarizes a verage anomaly detection performance, measured by A UC and pA UC and averaged as in the DCASE protocol, with and without access to machine identity across all e valuated datasets. In addition to absolute performance, the table reports chance-normalized anomaly detection degra- dation and chance-normalized implicit machine identification accuracy . Discriminatively trained models exhibit the smallest relativ e performance degradation, indicating strong robustness when machine identity is unav ailable. In contrast, training- free methods based on pre-trained embeddings or machine- specific models sho w substantially lar ger drops, reflecting their sensitivity to incorrect implicit machine selection. A noteworthy exception is the behavior of local density- based anomaly score normalization (LDN). Although it sub- stantially reduces implicit machine identification accuracy , it T ABLE I A V E RA G E A N O M ALY D E TE C T I ON P ER F O R MA N C E W I TH A ND WI T H O UT AC C ES S TO M A CH I N E I D EN T I T Y , T O G ET H E R W I TH C HA N C E - N O R M AL I Z ED I M PL I C I T M AC H I N E I D E N TI FI C A T I O N AC C U RA C Y , F O R D I FF E RE N T A S D S Y S TE M S A CR OS S T H E D E V E LO P M E NT AN D EV A L UA T I O N S E T S O F TH E D C AS E 2 0 20 , DC A S E 20 2 2 , D C A SE 2 0 2 3, DC A S E 20 2 4 , A N D D C A SE 2 0 2 5 D A TA SE T S . Score normalization ASD performance ASD system LDN [29], [30] V arMin [31] known ID unknown ID ∆ norm ID acc. (norm.) Discriminative models Direct-A CT [29], [30] ✗ 70 . 31% 69 . 66% 3 . 20% 88 . 85% Direct-A CT [29], [30] (variant) ✗ ✗ 70 . 83% 70 . 35% 2 . 30% 89 . 31% Direct-A CT [29], [30] (variant) 66 . 02% 65 . 76% 1 . 62% 92 . 59% T raining-fr ee embedding-based approac hes openL3-based [32] ✗ ✗ 65 . 44% 63 . 51% 12 . 50% 81 . 61% BEA Ts-based [32] ✗ ✗ 68 . 71% 67 . 30% 7 . 54% 84 . 23% BEA Ts-based [32] (variant) ✗ 67 . 29% 65 . 38% 11 . 05% 80 . 55% BEA Ts-based [32] (variant) 64 . 47% 63 . 80% 4 . 63% 90 . 53% EA T -based [32] ✗ ✗ 65 . 69% 63 . 53% 13 . 77% 74 . 20% Dasheng-based [32] ✗ ✗ 64 . 59% 62 . 98% 11 . 03% 82 . 43% Machine-specific models autoencoder [12] (re-implementation) 56 . 71% 55 . 40% 19 . 52% 86 . 43% 50 60 70 80 90 100 0 20 40 Chance-normalized identification accuracy (%) Chance-normalized ASD degradation (%) DCASE2020 (dev) DCASE2020 (eval) DCASE2022 (dev) DCASE2022 (eval) DCASE2023 (dev) DCASE2023 (eval) DCASE2024 (dev) DCASE2024 (eval) DCASE2025 (dev) DCASE2025 (eval) Fig. 2. Relation between chance-normalized machine identification accuracy and anomaly detection performance degradation across ASD systems. The dashed line shows a global least-squares fit over all plotted data points. Dataset-specific fits (not shown) exhibit negative slopes, with reduced magni- tude when identification accuracy is already near its ceiling for most systems. simultaneously improves absolute anomaly detection perfor- mance. In fact, ev en without access to machine identity at test time, systems using LDN outperform their counterparts ev aluated with known machine identity but without LDN. This observation indicates that high identification accuracy is not a strict prerequisite for strong anomaly detection performance. Robustness to unknown machine identity also depends on how anomaly scores are structured and aggregated, not solely on how reliably machines can be identified. B. Relation between Identification and Detection P erformance T o directly test the relationship suggested by the analy- sis in Section V -A, we jointly examine anomaly detection performance degradation and implicit machine identification accuracy across all ev aluated ASD systems. The results, sho wn in Figure 2, support the formalization in Section III-B, which predicts increasing detection degradation as the probability of selecting an incorrect machine increases. V I . D I S C U S S I O N Removing access to machine identity at test time reveals robustness differences that are largely hidden under standard machine-wise ev aluation. While all ASD systems necessarily rely on machine-specific reference data to define normal behavior , the key distinction is not whether such information is used, but how reliably a method can recover the correct machine-specific notion of normality when machine identity is unav ailable. In this reg ard, discriminativ ely trained mod- els exhibit particularly strong robustness. Because they are explicitly trained to discriminate between machine identities (and, where applicable, operating conditions), they are less sensitiv e to background noise and other nuisance factors that do not conv ey machine identity [33], resulting in smaller performance degradations when machine labels are remov ed. In contrast, methods relying on machine-specific models or reference statistics are more vulnerable, as incorrect implicit machine selection directly affects the anomaly score used for detection. Intuitively , if a system cannot reliably distinguish between machines, it is unlikely to detect subtle deviations from machine-specific normal sounds. The observed degradation can also be interpreted from a ranking perspecti ve. When machine identity is unknown, each test recording is compared against multiple machine-specific notions of normality , and errors occur when an incorrect machine yields a lower anomaly score than the true one. This reflects overlap between machine-specific score distributions. Rank-based metrics such as A UC and pA UC capture this be- havior directly , explaining the strong empirical relationship be- tween anomaly detection performance de gradation and implicit machine identification accuracy . These results suggest that robustness to missing machine identity should be considered an explicit ev aluation dimension in future ASD benchmarks. Finally , the proposed ev aluation setting has several limita- tions. W e assume single-channel recordings containing sounds from a single machine and a fixed set of machines. While consistent with current DCASE benchmarks, these assump- tions limit applicability to more complex deployments. In practice, recordings may contain multiple simultaneously oper- ating machines and overlapping normal and anomalous ev ents, requiring systems to identify all active machines and produce machine-specific anomaly scores. Extending the ev aluation to such scenarios is an important direction for future work. V I I . C O N C L U S I O N In this work, we in vestigated ho w much machine iden- tity matters for anomalous sound detection at test time by introducing a minimal modification to the standard DCASE ev aluation protocol that removes access to machine identity during inference. W e sho wed that this assumption has a substantial impact on reported performance and that relaxing it rev eals clear differences in robustness hidden by standard machine-wise ev aluation. Importantly , machine identity does not matter uniformly across methods: Approaches that can implicitly recov er the correct machine-specific notion of nor- mality are largely unaf fected, whereas methods relying on explicit machine-specific models degrade due to ambiguity in score selection and ov erlapping score distributions. W e further demonstrated a strong relationship between anomaly detection performance degradation and implicit machine identification accuracy , providing a simple explanation of when and why machine identity matters and motiv ating its consideration as an explicit ev aluation dimension in future ASD benchmarks. V I I I . G E N E R A T I V E A I D I S C L O S U R E Generativ e AI tools were used for language editing and pol- ishing of the manuscript. All scientific content, interpretations, and conclusions are the responsibility of the authors. R E F E R E N C E S [1] A. Mesaros, R. Serizel, T . Heittola, T . V irtanen, and M. D. Plumbley , “ A decade of DCASE: Achiev ements, practices, ev aluations and future challenges, ” in Proc. ICASSP , 2025. [2] Y . Kawaguchi et al. , “Description and discussion on DCASE 2021 chal- lenge task 2: Unsupervised anomalous detection for machine condition monitoring under domain shifted conditions, ” in Proc. DCASE , 2021. [3] K. Dohi et al. , “Description and discussion on DCASE 2022 Challenge T ask 2: Unsupervised anomalous sound detection for machine condi- tion monitoring applying domain generalization techniques, ” in Pr oc. DCASE , 2022. [4] ——, “Description and discussion on DCASE 2023 Challenge T ask 2: First-shot unsupervised anomalous sound detection for machine condition monitoring, ” in Pr oc. DCASE , 2023. [5] T . Nishida et al. , “Description and discussion on DCASE 2024 Chal- lenge T ask 2: First-shot unsupervised anomalous sound detection for machine condition monitoring, ” in Pr oc. DCASE , 2024. [6] ——, “Description and discussion on DCASE 2025 challenge task 2: First-shot unsupervised anomalous sound detection for machine condition monitoring, ” in Pr oc. DCASE , 2025. [7] K. Wilkinghof f, T . Fujimura, K. Imoto, J. Le Roux, Z.-H. T an, and T . T oda, “Handling domain shifts for anomalous sound detection: A revie w of DCASE-related work, ” in Pr oc. DCASE , 2025. [8] N. Harada, D. Niizumi, Y . Ohishi, D. T akeuchi, and M. Y asuda, “First- shot anomaly sound detection for machine condition monitoring: A domain generalization baseline, ” in Pr oc. EUSIPCO , 2023. [9] K. Wilkinghof f, “Combining multiple distrib utions based on sub-cluster AdaCos for anomalous sound detection under domain shifted condi- tions, ” in Proc. DCASE , 2021. [10] H. Chen, Y . Song, L. Dai, I. McLoughlin, and L. Liu, “Self-supervised representation learning for unsupervised anomalous sound detection under domain shift, ” in Pr oc. ICASSP , 2022. [11] P . Saengthong and T . Shinozaki, “Deep generic representations for domain-generalized anomalous sound detection, ” in Proc. ICASSP , 2025. [12] Y . K oizumi et al. , “Description and discussion on DCASE2020 Chal- lenge T ask2: Unsupervised anomalous sound detection for machine condition monitoring, ” in Pr oc. DCASE , 2020. [13] D. M. J. T ax and R. P . W . Duin, “Support vector data description, ” Mac h. Learn. , vol. 54, no. 1, pp. 45–66, 2004. [14] D. K. McClish, “ Analyzing a portion of the R OC curve, ” Medical decision making , vol. 9, no. 3, 1989. [15] T . Fawcett, “ An introduction to ROC analysis, ” P attern Recognit. Lett. , vol. 27, no. 8, 2006. [16] H. Purohit et al. , “MIMII dataset: Sound dataset for malfunctioning industrial machine investig ation and inspection, ” in Pr oc. DCASE , 2019. [17] Y . Koizumi, S. Saito, H. Uematsu, N. Harada, and K. Imoto, “T oyAD- MOS: A dataset of miniature-machine operating sounds for anomalous sound detection, ” in Pr oc. W ASP AA , 2019. [18] K. Dohi et al. , “MIMII DG: Sound dataset for malfunctioning industrial machine inv estigation and inspection for domain generalization task, ” in Pr oc. DCASE , 2022. [19] N. Harada, D. Niizumi, D. T akeuchi, Y . Ohishi, M. Y asuda, and S. Saito, “T oyADMOS2: Another dataset of miniature-machine operating sounds for anomalous sound detection under domain shift conditions, ” in Pr oc. DCASE , 2021. [20] N. Harada, D. Niizumi, D. T akeuchi, Y . Ohishi, and M. Y asuda, “T oyADMOS2+: Ne w T oyadmos data and benchmark results of the first- shot anomalous sound event detection baseline, ” in Proc. DCASE , 2023. [21] D. Niizumi, N. Harada, Y . Ohishi, D. T akeuchi, and M. Y asuda, “T oyADMOS2#: Yet another dataset for the DCASE2024 challenge task 2 first-shot anomalous sound detection, ” in Proc. DCASE , 2024. [22] D. Albertini, F . Augusti, K. Esmer, A. Bernardini, and R. Sannino, “IMAD-DS: A dataset for industrial multi-sensor anomaly detection under domain shift conditions, ” in Proc. DCASE , 2024. [23] N. Harada, D. Niizumi, Y . Ohishi, D. T akeuchi, and M. Y asuda, “T oyADMOS2025: The ev aluation dataset for the DCASE2025T2 first- shot unsupervised anomalous sound detection for machine condition monitoring, ” in Proc. DCASE , 2025. [24] K. Wilkinghof f, “ Audio embeddings for semi-supervised anomalous sound detection, ” Ph.D. dissertation, Univ ersity of Bonn, 2024. [25] A. Cramer , H. W u, J. Salamon, and J. P . Bello, “Look, listen, and learn more: Design choices for deep audio embeddings, ” in Pr oc. ICASSP , 2019. [26] S. Chen et al. , “BEA Ts: Audio pre-training with acoustic tokenizers, ” in Pr oc. ICML , 2023. [27] W . Chen, Y . Liang, Z. Ma, Z. Zheng, and X. Chen, “EA T : self-supervised pre-training with efficient audio transformer, ” in Pr oc. IJCAI , 2024. [28] H. Dinkel, Z. Y an, Y . W ang, J. Zhang, Y . W ang, and B. W ang, “Scaling up masked audio encoder learning for general audio classification, ” in Pr oc. Interspeech , 2024. [29] K. W ilkinghoff, H. Y ang, J. Ebbers, F . G. Germain, G. W ichern, and J. L. Roux, “Keeping the balance: Anomaly score calculation for domain generalization, ” in Proc. ICASSP , 2025. [30] ——, “Local density-based anomaly score normalization for domain generalization, ” IEEE T rans. Audio, Speech, Lang. Pr ocess. , vol. 33, 2025. [31] M. Matsumoto, T . Fujimura, W . Huang, and T . T oda, “ Adjusting bias in anomaly scores via variance minimization for domain-generalized discriminativ e anomalous sound detection, ” in Proc. DCASE , 2025. [32] K. Wilkinghof f, S. Y adav , and Z.-H. T an, “T emporal pooling strategies for training-free anomalous sound detection with self-supervised audio embeddings, ” 2026, submitted to T ASLP . [33] K. Wilkinghof f and F . K urth, “Why do angular mar gin losses w ork well for semi-supervised anomalous sound detection?” IEEE/ACM T rans. Audio, Speech, Lang. Pr ocess. , vol. 32, 2024.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment