테스트 시 기계 정체성 없이도 이상음 탐지 성능은 어떻게 변할까
본 논문은 기존 DCASE 기반 이상음 탐지(ASD) 평가에서 가정하던 “테스트 시 기계 정체성(아이디) 제공”이라는 전제를 제거하고, 여러 기계의 테스트 녹음들을 하나의 집합으로 합쳐 평가한다. 동일한 학습 데이터와 평가 지표를 유지하면서, 기계 아이디가 없는 상황에서 대표적인 ASD 모델들의 성능 저하와 기계 식별 정확도 간의 관계를 실험적으로 분석한다. 결과는 기계 식별 정확도가 낮을수록 이상음 탐지 성능이 크게 감소함을 보여주며, 일부 …
저자: Kevin Wilkinghoff, Keisuke Imoto, Zheng-Hua Tan
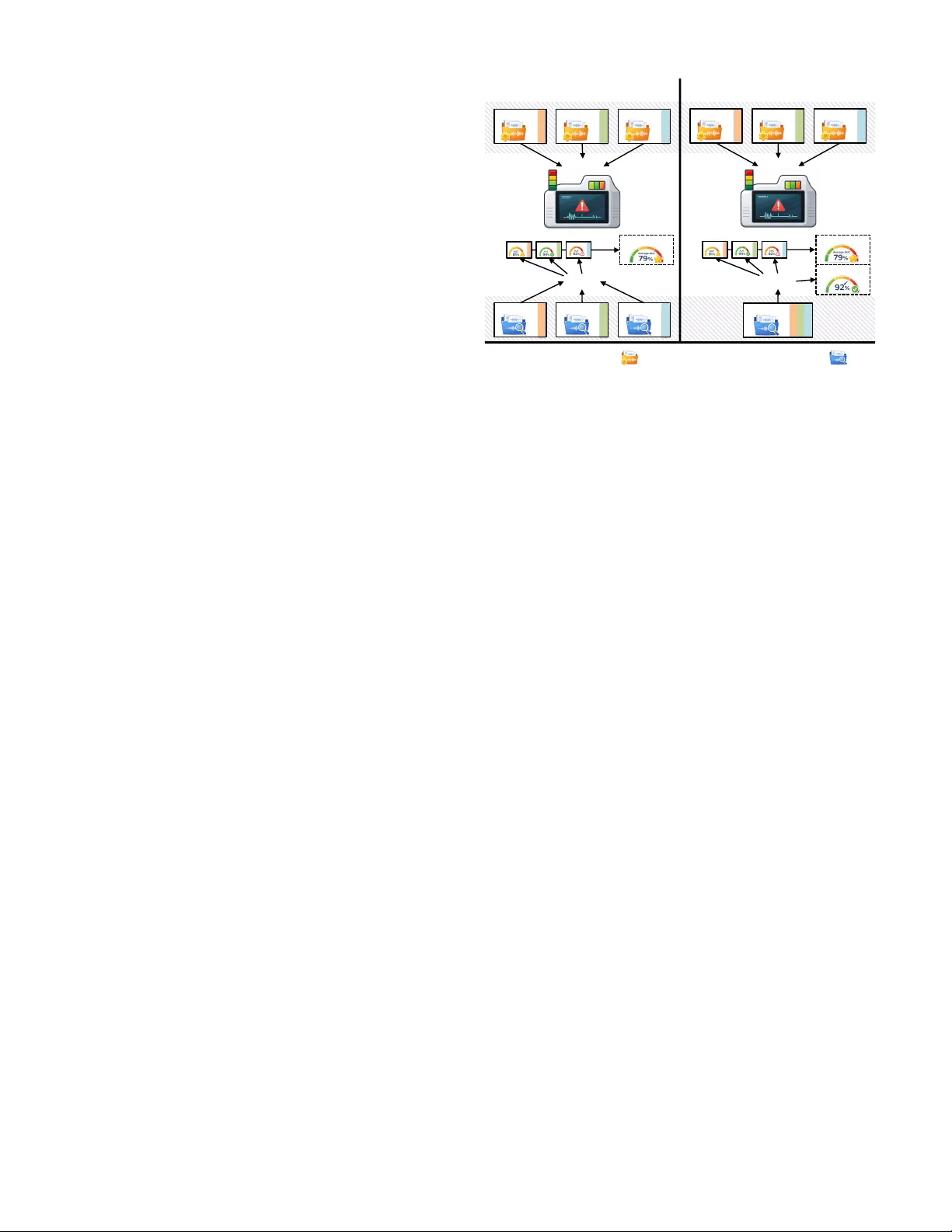
본 논문은 이상음 탐지(Anomalous Sound Detection, ASD) 분야에서 널리 사용되는 DCASE 챌린지 기반 평가 프로토콜이 가지고 있는 숨은 가정을 드러내고, 그 가정을 의도적으로 제거함으로써 실제 산업 현장에서 발생할 수 있는 문제점을 실험적으로 검증한다. 기존 DCASE 평가에서는 각 기계마다 별도의 학습·테스트 데이터를 제공하고, 테스트 단계에서 기계 정체성(ID)을 알고 있다는 전제 하에 모델이 점수를 산출한다. 이는 모델이 기계별 정상 패턴을 직접 참조하거나, 기계별 정규화 파라미터를 적용할 수 있게 해 주지만, 실제 현장에서는 여러 기계가 동시에 작동하고 마이크가 하나만 설치되는 경우가 많아 녹음이 어느 기계에서 발생했는지 사전에 알기 어렵다. 이러한 현실적 제약을 반영하고자 저자들은 다음과 같은 새로운 평가 프로토콜을 제안한다.
1. **테스트 셋 재구성**: 개발(dev) 및 평가(eval) 단계의 모든 테스트 녹음을 하나의 풀(pool)로 합친다. 이때 각 녹음에 대한 기계 ID 라벨은 유지하되, 모델 추론 시에는 전혀 제공하지 않는다.
2. **모델 추론**: 기존에 제안된 ASD 모델들을 그대로 사용한다. 즉, 모델 구조, 특징 추출, 하이퍼파라미터 등을 변경하지 않으며, 오직 입력 오디오만을 이용해 이상점수를 산출한다.
3. **점수 집계**: 기계별 이상점수 s_m(x) 가 존재한다면, 아이디가 없을 때는 최소값 집계 s(x)=min_m s_m(x) 를 적용한다. 이는 “가장 정상적인(가장 낮은 이상점수를 주는) 기계 모델”을 자동으로 선택하는 방식이다.
4. **평가**: 추론이 끝난 후, 사후적으로 원래의 기계 ID와 매핑해 기존 DCASE와 동일한 AUC·pAUC 지표를 사용해 성능을 측정한다. 또한, 집계 과정에서 선택된 기계가 실제 기계와 일치하는 비율을 “암묵적 기계 식별 정확도”로 정의하고, 이를 정규화하여 보고한다.
이론적 분석에서는 식별 정확도가 100%일 경우 새로운 프로토콜과 기존 프로토콜이 동일한 성능을 보이며, 식별 오류가 발생할 경우 성능 저하는 오류 확률에 비례한다는 수식을 제시한다(식 3). 따라서 기계 식별 정확도와 이상음 탐지 성능 사이에 직접적인 상관관계가 존재한다는 가설을 세운다.
**실험 설정**
- **데이터셋**: DCASE 2020~2025까지 다섯 개 연도에 걸친 공개 데이터셋을 사용한다. 각 데이터셋은 MIMII, ToyADMOS, MIMII‑DG, IMAD‑DS 등 다양한 도메인을 포함하며, 7~21대의 기계와 6~7종 타입이 존재한다.
- **모델**: 세 가지 패러다임(판별 학습 모델, 사전학습 임베딩 기반 무학습 모델, 기계별 모델/레퍼런스 기반)을 대표하는 10여 개 모델을 평가한다. 구체적으로 Direct‑ACT, OpenL3, BEATs, EAT, Dasheng, 오토인코더 등이다.
- **정규화 기법**: LDN(Local Density‑based Normalization), VarMin 등 기존에 제안된 점수 정규화 방법을 적용해 비교한다.
**주요 결과**
1. **성능 저하 정도**: 판별 학습 모델은 아이디가 없을 때 평균 Δ_norm이 2~3%에 불과해 가장 견고했다. 반면, 무학습 임베딩 기반 모델은 10~15% 포인트의 AUC 감소를 보였으며, 기계별 모델도 식별 정확도가 낮을 경우 15~20% 정도의 큰 저하를 나타냈다.
2. **정규화 효과**: LDN 정규화는 식별 정확도를 크게 낮추면서도(≈60% 이하) AUC를 오히려 향상시키는 역설적인 현상을 보였다. 이는 정규화가 점수 스케일을 기계 간에 맞추어 잘못된 기계 선택이 전체 성능에 미치는 영향을 완화하기 때문이다. VarMin은 LDN보다 식별 정확도와 성능 저하 사이의 관계를 더 명확히 보여준다.
3. **식별 정확도와 성능 저하의 상관관계**: Figure 2에 나타난 전체 데이터 포인트를 선형 회귀하면, 식별 정확도가 높을수록 성능 저하가 감소한다는 기대와 일치한다. 특히 식별 정확도가 90% 이상이면 추가적인 향상이 미미해, 어느 정도 수준 이상의 식별만 확보하면 대부분의 모델이 충분히 견고하게 동작함을 시사한다.
4. **모델별 특성**: 판별 학습 모델은 학습 단계에서 다양한 기계의 특징을 내재화하기 때문에 테스트 시 기계 ID가 없어도 비교적 안정적인 점수를 산출한다. 반면, 임베딩 기반 무학습 모델은 사전학습된 특징이 기계별 정상음의 미세 차이를 포착하지 못해 식별 정확도가 낮아지고, 그에 따라 성능 저하가 크게 나타난다.
**논의 및 한계**
- **실제 현장 적용**: 제안된 프로토콜은 단일 채널, 단일 기계 음원 전제를 유지한다. 다중 마이크 어레이를 이용한 소스 로컬라이제이션과 결합했을 때의 효과는 다루지 않았다.
- **점수 집계 전략**: 현재는 최소값 집계(min)만을 사용했으며, 베이즈 가중합, 평균, 최대값 등 다른 전략이 성능에 미치는 영향은 추후 연구가 필요하다.
- **데이터 도메인**: 대부분의 데이터셋이 실험실 환경에서 수집된 것이며, 실제 공장 소음, 반향, 다중 기계 동시 작동 등 복합적인 환경에서의 일반화 여부는 추가 검증이 필요하다.
**결론**
본 연구는 ASD 평가에서 “테스트 시 기계 정체성 제공”이라는 숨은 가정을 명시적으로 제거하고, 그 영향을 정량적으로 분석함으로써 두 가지 중요한 메시지를 전달한다. 첫째, 모델 선택 및 점수 정규화 전략에 따라 테스트 시 기계 ID 부재가 성능에 미치는 영향이 크게 달라진다. 둘째, 기계 식별 정확도가 일정 수준(≈80% 이상) 이상이면 대부분의 ASD 모델이 충분히 견고하게 동작한다는 점이다. 따라서 향후 ASD 벤치마크 설계 시 기계 ID를 제공하지 않는 시나리오를 포함시키고, 정규화 기법을 활용해 모델의 실용성을 높이는 방향으로 연구가 진행되어야 한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기