Quantifying and Attributing Submodel Uncertainty in Stochastic Simulation Models and Digital Twins
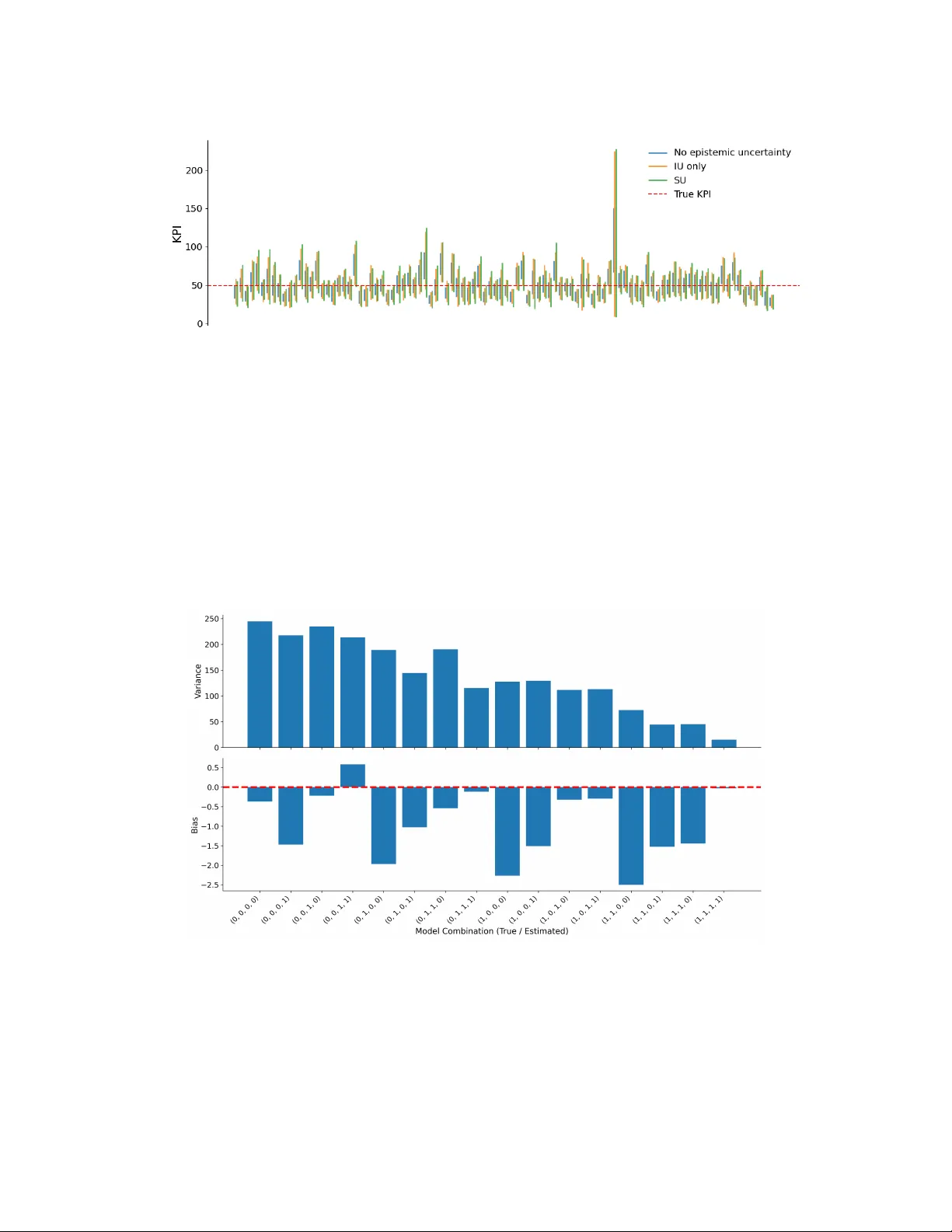
Stochastic simulation is widely used to study complex systems composed of various interconnected subprocesses, such as input processes, routing and control logic, optimization routines, and data-driven decision modules. In practice, these subprocesse…
Authors: Mohammadmahdi Ghasemloo, David J. Eckman, Yaxian Li
Q U A N T I F Y I N G A N D A T T R I B U T I N G S U B M O D E L U N C E RTA I N T Y I N S T O C H A S T I C S I M U L A T I O N M O D E L S A N D D I G I T A L T W I N S Mohammadmahdi Ghasemloo Department of Industrial and Systems Engineering T exas A&M Univ ersity College Station, TX, USA mohammad_ghasemloo@tamu.edu David J . Eckman Department of Industrial and Systems Engineering T exas A&M Univ ersity College Station, TX, USA eckman@tamu.edu Y axian Li Intuit AI Mountain V ie w , CA, USA yaxian_li@intuit.com A B S T R A C T Stochastic simulation is widely used to study complex systems composed of v arious interconnected subprocesses, such as input processes, routing and control logic, optimization routines, and data-driv en decision modules. In practice, these subprocesses may be inherently unknown or too computationally intensiv e to directly embed in the simulation model. Replacing these elements with estimated or learned approximations introduces a form of epistemic uncertainty that we refer to as submodel uncertainty . This paper inv estigates how submodel uncertainty affects the estimation of system performance metrics. W e de velop a frame work for quantifying submodel uncertainty in stochastic simulation models and extend the frame work to digital-twin settings, where simulation experiments are repeatedly conducted with the model initialized from observed system states. Building on approaches from input uncertainty analysis, we le verage bootstrapping and Bayesian model a veraging to construct quantile-based confidence or credible intervals for key performance indicators. W e propose a tree-based method that decomposes total output variability and attrib utes uncertainty to individual submodels in the form of importance scores. The proposed framework is model-agnostic and accommodates both parametric and nonparametric submodels under frequentist and Bayesian modeling paradigms. A synthetic numerical experiment and a more realistic digital-twin simulation of a contact center illustrate the importance of understanding how and ho w much indi vidual submodels contribute to o verall uncertainty . Keyw ords Uncertainty Quantification, Digital T win, Stochastic Simulation, AI-driv en Simulation 1 Introduction Many stochastic systems studied in operations research and management science can be viewed as collections of interconnected subprocesses that each represent a specific aspect of system beha vior such as demand generation, service dynamics, routing logic, or optimization-based decision making. When such systems are studied using stochastic simulation, the modeler must determine ho w to model each subprocess. In man y cases, the true subprocess cannot be accessed or fully understood and instead can only be observed in the real world, such as when observing customer arriv als in a service system. In other cases, the true subprocess may be accessible, such as when it represents some operational decision made according to some polic y or sophisticated solution method, e.g., optimization, but directly embedding the subprocess within the simulation may be impractical due to concerns about priv acy , latency , computational cost, or data accessibility . For these reasons, the modeler may , out of necessity or choice, replace certain subprocesses with approximate representations, such as generati ve models, simplified decision rules, heuristics, or optimization proxies trained on historical data. These approximations, which we henceforth refer to as submodels , may take se veral forms. In the case of modeling stochastic inputs, such as customer demand or service times, probability distributions are fitted to real-world data. In other cases, a submodel may be a function mapping subsystem inputs to outputs trained on input-output data from that subprocess using supervised learning techniques. In both cases, submodel selection can in volve trade-of fs between accuracy , interpretability , and computational cost. The use of submodels within a stochastic simulation model introduces errors that propagate through the model to its outputs. Understanding how these errors propagate is critical for quantifying uncertainty in estimators of key performance indicators (KPIs) and directing efforts to reduce uncertainty . While prior work in the simulation literature has extensi vely studied input uncertainty (IU) [ 4 , 19 , 23 ]—the epistemic uncertainty due to estimating stochastic input models from limited data—less attention has been gi ven to uncertainty originating from other types of submodels that influence the internal dynamics of the simulated system, including the decision logic, e vent ordering, and system state. The errors introduced by both types of submodels can influence simulation behavior in comple x and path-dependent ways. Along these lines, [ 11 ] adopt methods from IU to study uncertainty arising from embedding machine learning (ML) surrogates of decision-support systems (DSSs) within simulation models. This paper builds on the ideas of [ 11 ] to introduce a unifying frame work that encompasses man y potential sources of epistemic uncertainty in stochastic simulation models. W e collectiv ely refer to this more general form of epistemic uncertainty as submodel uncertainty . This paper presents general-purpose methods for systematically quantifying submodel uncertainty to support and enhance operational decision making. More specifically , we employ bootstrapping and Bayesian model a veraging (BMA) to generate plausible submodels that dri ve a designed simulation e xperiment. W e lev erage design of experiments (DOE), specifically stacked Latin hypercube (LH) designs, to more efficiently e xplore the space of submodel instances when studying systems with multiple submodels. The experiment results are then used to construct quantile-based confidence or credible intervals (CIs) that account for both aleatoric and epistemic uncertainty . W e propose a tree-based method that provides importance scores quantifying ho w the ov erall uncertainty can be decomposed into aleatoric and epistemic terms and ho w the epistemic uncertainty can be further attrib uted to individual submodels. These importance scores enable practitioners to identify the most influential submodels and thereby prioritize further efforts to reduce ov erall uncertainty by , for example, acquiring additional training data or refining their modeling specifications. The frame work’ s strength is its generality , as it can accommodate both parametric and non-parametric submodels under either the frequentist or Bayesian modeling paradigms. Moreover , whereas some existing approaches for analyzing IU assume that the input models are independent of each other [ 15 ], we make no such assumption about the submodels. Submodel uncertainty is also highly relev ant in digital-twin settings, wherein a simulation model is enhanced by integrating real-time or periodically observed system state data to maintain a synchronized virtual representation of the physical system [ 25 , 16 , 34 ]. Digital twins are used for monitoring, forecasting, and ev aluating alternative operational strategies in real time. Recent work has emphasized the central role of uncertainty quantification (UQ) for reliable prediction and decision support. For example, [ 37 ] de velop a non-intrusi ve sensiti vity-metrics toolbox for inte grating black-box digital twins into the design process in the presence of uncertain data and ev olving performance indicators. In digital-twin settings, simulation models are repeatedly initialized from observed system states and commonly rely on submodels—such as forecasting tools, routing models, or optimization proxies—to emulate future system behavior . For more discussion on the increasing use of ML submodels within digital twins, see [ 35 ]. W e extend our frame work to the digital-twin setting by accommodating cases in which the system state ev olves over time and the submodels may be time dependent. In particular , we apply our tree-based method on each state and aggregate the importance scores across states to quantify and compare the relativ e contributions of different submodels to uncertainty o ver time. W e also propose a method for estimating a form of state-a verage bias when data on historical system states and KPIs are av ailable. In summary , our approach provides a unified and scalable frame work for uncertainty quantification and decomposition that supports reliable decision making in offline simulation and online digital-twin applications. The remainder of the paper is org anized as follo ws. Section 2 formally defines submodels in simulated systems and categorizes them based on their functional forms. Section 3 mathematically introduces submodel uncertainty . Sections 4 and 5 describe resampling-based methods for UQ and tree-based methods that attribute uncertainty to individual submodels along with a numerical example. Submodel uncertainty is extended to the digital-twin setting in Section 6 and demonstrated through a contact-center e xample. Concluding remarks and future research directions are gi ven in Section 7. 2 Submodels in Simulated Systems A stochastic simulation model can be viewed as a mapping g that takes as input a collection of user-specified v ariables X and random primitiv es ξ and returns a response Y , i.e., Y = g ( X , ξ ) . (1) 2 Simulation models typically consist of multiple interconnected subprocesses, each of which emulates a specific aspect of system beha vior . V arious practical limitations often make it infeasible to incorporate the real-world subprocess directly in the simulation model. First, the true subprocess may not be fully accessible. For example, input processes gov erning customer arri v als to a service system are inherently una v ailable. Second, e ven when the true subprocess is accessible, data intensity and latency constraints often render it infeasible to make repeated calls to the true subprocess from within the simulation model. Third, in many real-world settings, decision modules, such as those that support routing, dispatch, and allocation decisions, are shared across real-time applications. Directly in v oking these modules within a simulation e xperiment may therefore interfere with li ve operations, introduce contention for computational resources, or expose sensiti ve information. These issues can generally be resolv ed by approximating or replacing the real-world subprocesses with submodels. F or a more detailed discussion of the moti vations for replacing DSSs with ML surrogate models, see [11]. The submodels we in vestigate in this paper can generally be expressed in the form of (1) . W e categorize submodels into three classes depending on whether their mapping g features only X , only ξ , or both X and ξ . 2.1 Deterministic Submodels W e call submodels for which Y = g ( X ) deterministic submodels , because their output is a deterministic function of the input variables. Deterministic submodels do not introduce any aleatoric uncertainty to the simulation. Roughly speaking, deterministic submodels can be thought of as rules-based logic in the simulation that maps the system state X to a deterministic decision or action Y . A deterministic submodel g is trained on data consisting of paired observations ( X , Y ) and then embedded within the simulation model. The mapping g may correspond to an optimization proxy [ 7 ] that replaces an optimization solv er and is in vok ed within the simulation whene ver an instance of the corresponding optimization problem needs to be solved. In this case, X denotes the set of parameters describing the problem instance and Y is the resulting optimal solution, which is then used to advance the simulation. Alternati vely , g may approximate the actions of a reinforcement learning (RL) [ 32 ] or otherwise intelligent agent, where X is the state of the system and Y is the associated action. Inv erse reinforcement learning (IRL) [ 2 ] can be used to learn a re ward function from historical state-action observations and subsequently train a polic y . The submodel g might then be the table in tabular learning or be parameterized by a deep neural network [ 36 ] that determines the optimal polic y . The DSSs studied in [11] are examples of deterministic submodels. 2.2 Unconditional Stochastic Submodels W e refer to submodels that inject aleatoric uncertainty into the simulation model and are not influenced by external factors as unconditional stochastic submodels . These submodels are of the form Y = g ( ξ ) , where ξ represents random primitiv es, Y is a random quantity , and g can be parametric or nonparametric. Training data for this class of submodels consist solely of observations of Y . W ell-known examples of unconditional stochastic submodels arise in random variate generation, where the function g could be an in verse cumulati ve distribution function that transforms a pseudo-random number ξ ∼ U (0 , 1) into a random v ariate Y or could represent an acceptance-rejection algorithm giv en access to a sequence of pseudo-random numbers [ 9 ]. In more modern generativ e modeling approaches, such as neural input modeling (NIM) [ 6 ], the mapping g may be parameterized by a neural network, for e xample, within a v ariational autoencoder (V AE), while the latent v ariable ξ is typically assumed to follo w a standard normal distribution. Alternatively , g may be represented by neural architectures that incorporate recurrent components, such as long short-term memory (LSTM) layers, to capture temporal dependencies in the input process [6]. 2.3 Conditional Stochastic Submodels W e refer to submodels of the general form Y = g ( X , ξ ) as conditional stochastic submodels . As an example, g may be a generativ e metamodel (surrogate) of a stochastic simulation model embedded within a larger simulation framew ork. In this case, X may include the system state used to e xecute the submodel, while ξ is generated from the stochastic input models that govern the simulation submodel’ s aleatoric uncertainty . Building upon a previous example of deterministic submodels, g may instead represent a stochastic optimization proxy [ 1 ] that replaces a stochastic optimization solver within the simulation model. Here, X is again the set of parameters describing the problem instance and ξ captures either inherent stochasticity in the optimization algorithm or that emanating from a stochastic submodel (e.g., a simulation submodel) in voked by the solver in the course of its run. Random variate generators that depend on contextual information X , such as conditional v ariational autoencoders (CV AEs) [6], also fall into this category . 3 2.4 Supply Chain Example W e no w provide an illustrativ e example of a supply chain simulation model featuring the three types of submodels. Consider a multi-echelon supply chain in which products must be dynamically allocated from factories to distribution centers and retail locations based on incoming demand information and the current state of in ventories and transportation resources. Decisions made at each epoch influence future in ventory le vels, production schedules, and transportation av ailability across the network. A stochastic simulation model of this system may contain sev eral submodels. First, customer demand arriv als and their associated order quantities can be represented through unconditional stochastic submodels that generate demand realizations and serve as inputs to the simulation model [ 30 ]. Second, allocation decisions regarding where to send each product across the netw ork may be carried out by repeatedly in voking smaller embedded simulation models that e v aluate mean completion times [ 31 ]. Or , if such simulation submodels are too computationally expensi ve to embed, they could be replaced with cheaper conditional stochastic submodels, such as CV AEs, that generate synthetic outputs of the simulation submodel. Finally , within each factory , production scheduling and sequencing decisions may be made by RL agents trained to optimize operational performance over time. When the true RL policy is inaccessible or too computationally expensiv e to deploy online, its behavior can be approximated by a deterministic submodel that learns the rew ard function using IRL. 3 Submodel Uncertainty Let S c = ( S c 1 , S c 2 , . . . , S c L ) represent a collection of L true subprocesses that govern the real-world system. When hypothetically driving a stochastic simulation model with the true subprocesses, the (random) output on a giv en replication j = 1 , 2 , . . . can be expressed as Y j ( S c ) = µ ( S c ) + ε j ( S c ) , where µ ( S c ) ≡ E [ Y j ( S c )] represents the expected output, and ε j ( S c ) is a mean-zero random variable capturing the aleatoric uncertainty in the output. In this paper , we study the estimation of a single expected simulation output, hence Y j ( S c ) is a scalar . A standard approach to estimating µ ( S c ) is to obtain estimated submodels ˆ S from real-world data, run n independent replications using ˆ S , and compute ¯ Y ( ˆ S ) = 1 n n X j =1 Y j ( ˆ S ) . A confidence interv al for µ ( S c ) can then be constructed as ¯ Y ( ˆ S ) ± t α/ 2 ,n − 1 · s/ √ n , where s is the sample standard deviation of Y 1 ( ˆ S ) , Y 2 ( ˆ S ) , . . . , Y n ( ˆ S ) , and t α/ 2 ,n − 1 is the 1 − α/ 2 quantile of a Student’ s t -distribution with n − 1 degrees of freedom. This confidence interval, ho wev er , overlooks the epistemic uncertainty from estimating S c using ˆ S and therefore may fail to co ver µ ( S c ) with the prescribed confidence. This undercoverage can be e xplained by the observation that replacing S c with ˆ S can affect both the v ariance and bias of the estimator ¯ Y ( ˆ S ) . Understanding the variance of ¯ Y ( ˆ S ) is crucial for building an asymptotically valid confidence interv al or credible interval for µ ( S c ) . Applying the la w of total v ariance, the variance of ¯ Y ( ˆ S ) —where ˆ S is treated as random—can be decomposed as V ar ( ¯ Y ( ˆ S )) = V ar ( E [ ¯ Y ( ˆ S ) | ˆ S ]) + E [ V ar ( ¯ Y ( ˆ S ) | ˆ S )] ≡ σ 2 SU + σ 2 MC . This decomposition separates the aleatoric uncertainty (i.e., the simulation noise) σ 2 MC , from the epistemic uncertainty introduced by the use of submodels, σ 2 SU . This additiv e decomposition of the total uncertainty into epistemic and aleatoric uncertainty has been used e xtensi vely in the IU literature [ 4 ]. W e further attrib ute σ 2 SU across submodels in Section 5. The presence of estimated submodels also affects the bias of the estimator: Bias = E [ µ ( ˆ S )] − µ ( S c ) , where the expectation in the first term is taken ov er both ˆ S and replications of the simulation model. Although bias estimation is not the primary focus of this paper , it nonetheless can play an important role in how well the resulting CIs cov er µ ( S c ) . Bias has recei ved less attention in the IU literature, partly because it is dif ficult to estimate and is expected to vanish f aster than the variance as the size of the training data increases asymptotically [ 21 ]. In Section 6, we propose a method to estimate a related form of bias when outputs from the real-world system are a v ailable. Our framew ork for studying the ef fects of submodel uncertainty on KPI estimation entails obtaining random instances of each submodel and using them to dri ve the simulation model in a designed experiment. The next two sections elaborate on how to generate these instances, design the e xperiment, and analyze the results. 4 4 (Re)Sampling Submodels In this section, we discuss ways to sample from the space of submodels when they are formulated under the frequentist and Bayesian statistical philosophies. 4.1 Frequentist Submodels and Bootstrapping In the frequentist paradigm, a submodel is assumed to hav e a fixed but unknown structure or parameterization. Parametric submodels are typically constructed by first selecting a functional or distributional form based on domain kno wledge and then estimating parameters from data. Uncertainty arises from limited data and submodel misspecification and is commonly assessed through resampling-based techniques such as bootstrapping [ 10 ]. Bootstrapping is a non-parametric resampling technique that in volves resampling observ ations with r eplacement to create multiple bootstrapped datasets and has been extensi vely applied to quantify IU [ 4 ]. A straightforward way to lev erage bootstrapping for studying submodel uncertainty is to resample the training data with replacement and generate plausible instances of the submodel by successi vely fitting it to the bootstrapped datasets [ 33 ]. Although bootstrapping does not impose strong distrib utional assumptions on the data, it can be challenging to apply in certain contexts, e.g., time series data, which could arise, for example, if the submodel were a forecasting tool. Specialized techniques, such as mo ving block bootstrap [ 18 ] or stationary bootstrap [ 24 ], hav e been dev eloped to address this case, but they can be harder to implement. Bootstrapping also tends to multiply the required computational eff ort by the number of bootstrap instances. In certain IU settings, bootstrapping is relativ ely inexpensiv e because it entails fitting probability distributions to data, which is typically fast. In contrast, when bootstrapping is used to quantify , for instance, a deterministic or conditional stochastic submodel’ s uncertainty , the computational burden can be higher because a supervised learning model needs to be trained on each bootstrapped dataset. Complex ML models, such as deep neural networks, often require substantial training time, especially when the data are high dimensional or the model architecture is deep. When using bootstrapping for IU, the dominant cost is often the simulation runs themselv es, whereas with submodel uncertainty the cost of repeatedly training submodels may become comparable or ev en dominant. 4.2 Bayesian Submodels and Bayesian Model A veraging Bayesian submodels explicitly consider uncertainty by treating submodel parameters as random variables. Prior distributions encode e xisting kno wledge or beliefs and are updated using observ ed data to produce posterior distributions. Bayesian model av eraging offers a principled frame work for accounting for uncertainty in the form of a posterior distribution—obtained via Bayes’ rule—which inherently captures the remaining uncertainty about the model after observing the data [ 8 ]. This probabilistic formulation yields a collection of plausible submodels when sampling from the posterior . Bayesian models, e.g., GPs or BNNs, are equipped with posterior distributions on their predictions as functions of inputs for GPs [ 26 ] or parameter weights for BNNs [ 22 ]. Instead of resampling and retraining the submodel multiple times, as required in bootstrapping, Bayesian model averaging requires simply sampling from the posterior distribution of the model parameters. For example, when working with BNNs, generating ne w submodels requires only sampling from the posterior distribution rather than performing a full retraining process. On the other hand, sampling from GPs becomes increasingly expensi ve as the number of ev aluation points gro ws, which in our setting corresponds to the number of times the submodel is in voked within a simulation replication. 5 Uncertainty Quantification Let { ˆ S ( b ) l : b = 1 , 2 , . . . , B and l = 1 , 2 , . . . , L } represent B instances of each submodel generated via either bootstrap- ping or BMA. W e assume a common B across submodels, but this is not strictly necessary . It can be prohibitiv ely expensi ve to simulate all B L possible combinations (henceforth called configurations) of these instances, ev en for moderate v alues of B and L . T o address this challenge, we turn to design of experiments (DOE) to choose a smaller design of configurations that cov ers the space of submodel instances. In this paper , we employ Latin Hypercube (LH) designs [29], which ensure that ev ery level of e very factor (in our conte xt, ev ery sampled instance of every submodel) appears exactly once in a design. More specifically , a LH design is constructed by sampling without r eplacement from the set of B instances of each submodel to form configurations until all instances ha ve been exhausted. This process can be repeated to create additional LH designs, which can then be stacked to form a larger design [ 28 ]. The total number of configurations in such a stacked design is B ′ = B S , where S is the number of stacks. The simulation model is then run n times at each configuration. 5 The choices of B , S , and n affect the computational cost of the experiment and the accuracy of our estimation of the distribution of ¯ Y ( ˆ S ) . Increasing B enhances the di versity of the sampled submodel instances, increasing S improv es the cov erage of the cross-product of those instances, and increasing n reduces the impact of simulation noise by averaging ov er more replications. Note that the number of submodels that must be fitted or retrained depends on B , not S . Our framew ork can also accommodate time-dependent submodels, e.g., models of time non-homogeneous arri v als. If we can assume that the beha vior of the submodel is unchanging within certain periods, then the submodel can be further divided into distinct submodels—one for each period—and our approach applied as described. W e next describe how one can construct a CI for µ ( S c ) and use regression trees to decompose and attribute ov erall uncertainty to individual submodels. 5.1 Confidence and Credible Inter vals and Decomposing Uncertainty Suppose the sample means { ¯ Y ⟨ 1 ⟩ , ¯ Y ⟨ 2 ⟩ , . . . , ¯ Y ⟨ B ′ ⟩ } are obtained from the designed experiment, where ¯ Y ⟨ b ′ ⟩ = 1 n n X j =1 Y j ( ˆ S ⟨ b ′ ⟩ ) for b ′ = 1 , 2 , . . . , B ′ . An approximate 100(1 − α )% quantile-based confidence or credible interval for µ ( S c ) is giv en by Q α/ 2 ¯ Y , Q 1 − α/ 2 ¯ Y , (2) where Q p ( ¯ Y ) denotes the empirical p -quantile of the sample means. This CI incorporates both submodel and aleatoric uncertainty . In the frequentist setting, the confidence interval is asymptotically v alid as the size of the training datasets grows lar ge, assuming that the true subprocesses belong to the chosen classes of submodels. Note that the CI in (2) does not distinguish the submodels’ individual contributions to overall uncertainty . Consequently , decision makers looking to reduce uncertainty—such as by increasing the number of simulation replications, collecting more real-world data, or enhancing the submodels through hyperparameter tuning or switching to a more flexible architecture—could benefit from techniques that attribute uncertainty to specific submodels. W e present a method for quantifying the contribution of dif ferent sources to overall uncertainty . Our approach lev erages variable importance metrics from re gression trees [ 17 ], which assign a v alue to each feature based on the total reduction in the total sum of squares (TSS) resulting from splits on that feature. Our approach strongly resembles analysis of v ariance (ANO V A); howe ver , whereas ANO V A separately accounts for interaction effects, tree-based importance scores absorb interactions into the main effects. Interaction contributions are typically dif ficult to interpret and may not correspond to actionable modeling or data-collection decisions. For e xample, e ven if a strong interaction is detected between two submodels, it may not be clear whether additional data should be collected for one submodel, the other , or both simultaneously . Because our approach forces the interaction effects on certain submodels, we do not assume that submodels are independent, which we belie ve is unlik ely to hold in practice. Furthermore, our approach can preserve any inherent or assumed dependence across submodels by bootstrapping the training data or sampling from the joint posterior distribution accordingly . W e first consider a regression tree trained on the dataset produced by the designed experiment, where the L submodels are treated as categorical features with le vels corresponding to the B sampled submodel instances, e.g., ˆ S (1) ℓ , ˆ S (2) ℓ , . . . , ˆ S ( B ) ℓ for ℓ = 1 , 2 , . . . , L . The tree is gro wn using recursive binary splitting, iterati vely minimizing the residual sum of squares (RSS), until each configuration is its own terminal node, at which point the RSS corresponds to the portion of the TSS that is not explained by the submodels. The TSS is defined as TSS = B ′ X b ′ =1 n X j =1 Y ⟨ b ′ ⟩ j − ¯ ¯ Y 2 , where ¯ ¯ Y = 1 nB ′ B ′ X b ′ =1 n X j =1 Y ⟨ b ′ ⟩ j , and the RSS is giv en by: RSS = B ′ X b ′ =1 n X j =1 Y ⟨ b ′ ⟩ j − ˆ Y ⟨ b ′ ⟩ j 2 , where ˆ Y ⟨ b ′ ⟩ j is the predicted v alue of the KPI for configuration b ′ from the fully gro wn regression tree, which in our case is ¯ Y ⟨ b ′ ⟩ . T o further understand the role of model complexity in this frame work, we consider the concept of de gr ees of freedom (DoF), which represents the effecti ve number of parameters used by a model to fit data. In regression settings, DoF is 6 often interpreted as a measure of a model’ s flexibility or complexity and plays a critical role in error decomposition [ 38 ]. For re gression trees, a common approximation for DoF is the number of terminal (leaf) nodes [ 13 ]. Furthermore, the contribution of indi vidual features to model complexity is the number of times each feature is used for splitting, where each split contributes approximately one additional DoF [ 20 ]. T o attribute uncertainty to each source, we compute the reduction in TSS attributable to each submodel and normalize it by the number of times the corresponding submodel appears in the tree splits. Finally , we divide the RSS by its DoF , nB ′ − B ′ + 1 , to obtain the simulation error’ s contribution to the o verall variance. Regression trees, are known to exhibit high v ariance, as small perturbations in the training data can lead to substantially dif ferent tree structures. T o mitigate this v ariability , we adopt a bootstrap aggregation (bagging) strate gy [ 5 ]. Specifically , we first generate bootstrap training datasets by resampling observations with replacement. For each bootstrap sample, a regression tree is trained and feature importance scores are computed as described abo ve. The resulting importance scores are then averaged across bootstrap instances, in a manner analogous to the aggregation mechanism used in random forests. This aggregation can also be performed using a weighted av erage, where the weights are deriv ed either from the distribution of the observed system states or from the relativ e magnitude of the total TSS associated with each tree. This procedure yields a set of importance estimates with reduced variance relati ve to those obtained from a single regression tree, without needing to train additional submodels or run more simulation replications. 5.2 Numerical Example In our first experiment, we study the ef fect of submodel uncertainty on the output of a synthetic simulation model. W e consider two independent stochastic input models X 1 ∼ N (1 , 0 . 5 2 ) and X 2 ∼ N (1 , 2 2 ) and two deterministic transformation functions p ( x ) = x 7 + x 4 + 3 x 3 + sin( x ) + 4 and q ( x ) = x 3 + x 2 + 4 x . The output of the simulation model is defined as Y = p ( X 1 ) + q ( X 2 ) and our quantity of interest is the expected value E [ Y ] , which can be deriv ed analytically and equals 49 . 13 . W e examine three cases that dif fer in terms of the sources of epistemic uncertainty that are accounted for . 1. No epistemic uncertainty: The simulation is run using only the estimated submodels. 2. Input uncertainty only: UQ is performed for the input models associated with X 1 and X 2 , while only the estimated submodels for p and q are used. This setting represents the existing practice of analyzing IU. 3. Submodel uncertainty: UQ is performed for all submodels, including input models. For each case, we conduct 100 macro-replications. Within each macro-replication, a training dataset of size 50 is generated for each submodel by running 50 replications of the simulation model with the true submodels, i.e., we obtain 50 observations of { X 1 , p ( X 1 ) , X 2 , q ( X 2 ) , Y } . W e then bootstrap this dataset to generate B = 100 training datasets of size 50. For the input models X 1 and X 2 , observations are resampled independently , whereas for the response models p and q , the corresponding input-output pairs are resampled jointly . For each bootstrapped dataset, the necessary submodels are estimated and the simulation model is then run for n = 50 replications to estimate E [ Y ] . On each macro-replication, we construct 90% empirical confidence interv als for E [ Y ] via Equation (2) and calculate their cov erages and av erage widths across macro-replications. The 100 confidence intervals for each case are sho wn in Figure 1 and their summary statistics are reported in T able 1. As seen in T able 1, the coverage and a verage width of the intervals increase as more sources of uncertainty are considered. T able 1: Cov erage and av erage confidence interval width under dif ferent uncertainty scenarios. Scenario Coverage (%) A vg. CI Width No epistemic uncertainty 61.0 20.45 ± 0.14 Input uncertainty only 82.0 36.14 ± 0.35 Submodel uncertainty 87.0 38.60 ± 0.37 Because the true data-generating mechanisms are known, we further analyze all 2 4 = 16 combinations of true and estimated submodels. For each configuration, we generate 500 independent training datasets of size 50 . When a submodel is estimated in a giv en configuration, it is fitted using the corresponding training dataset and then embedded in the simulation model and the simulation is run for n = 500 replications under that configuration. Figure 2 shows the estimated variance and bias of the resulting estimator for each combination. Figures 3a and 3b show response grid plots (RGPs) [ 3 ] where the responses are the variance and the bias, respectiv ely . The plots show that the v ariance of the estimator decreases when fe wer submodels are utilized, and the bias increases when p ( · ) is estimated. The ANO V A results indicate that X 1 ( p-value = 0 . 023 ) and p ( p-value ≈ 0 ) ha ve a statistically significant effect on the output 7 Figure 1: Confidence interv als ov er 100 macro-replications when accounting for no epistemic uncertainty , only input uncertainty , or submodel uncertainty (SU). variance, whereas q ( p-value = 0 . 04 ) exhibits comparati vely weaker evidence of significance and X 2 ( p-value = 0 . 12 ) is not statistically significant. Figure 4 sho ws the decomposition of the v ariance across sources of uncertainty when using the bagging approach on one macro replication. The results align with those of the RGP plot and the ANO V A in that X 1 and p are identified as contributing the most to the uncertainty . Overall, this suggests that one should prioritize obtaining more data for modeling X 1 and training p in order to reduce the epistemic uncertainty . Figure 2: Bias and v ariance across combinations. The elements in each tuple correspond to X 1 , X 2 , p , and q , respectiv ely; 1 indicates that the true model is used, and 0 indicates that the estimated model is used. W e also compare the variance of the feature importance scores obtained from the regression tree and the bagging approach. The experiment was conducted ov er 100 macro-replications. In each macro-replication, B ′ = 512 configurations ( B = 8 , S = 64 ) were evaluated using training datasets of size 25 for each submodel. The bagging approach used 50 regression trees. T able 2 reports the v ariance reduction factors (VRFs) across macro-replications and shows that bagging leads to considerable reduction in the v ariance of the reported importance scores. 8 (a) V ariance. (b) Bias. Figure 3: Response grid plots for a 2 4 full factorial design of the four submodels (true vs estimated). The radius of each circle indicates the relativ e magnitude. Blue (red) circles show positi ve (negati ve) values. Figure 4: Feature importance plot attributing uncertainty to each of the estimated submodels and aleatoric uncertainty . T able 2: V ariance reduction factors (VRF) for indi vidual submodels. Submodel X 1 X 2 p q VRF 5.4 4.7 3.6 5.6 9 6 Submodel Uncertainty in Digital-T win Settings A digital twin serves as a virtual counterpart of a physical system and enables forward-looking performance ev aluation, robustness analysis, and what-if experimentation under alternati ve operating scenarios [ 12 ]. A simulation model can be extended into a digital twin by continuously ingesting real-time system information and updating the state, input models, and submodel parameters accordingly . In the context of digital twins, a simulation model can be repeatedly initialized using observ ed system state information and used to forecast KPIs ov er some future time horizon and support monitoring, planning, and decision making. T o extend our UQ frame work to digital-twin settings, we first address how the state of the physical system is observed in an online manner . In this setting, our objectiv e is not only to quantify the ov erall uncertainty in the future KPI giv en the current state, but also to understand ho w individual submodels contrib ute to this uncertainty . 6.1 Uncertainty Quantification in Digital T wins In a digital twin, the state of the physical system is observed at the beginning of an epoch, at which time the simulation model is hot started to predict the KPI at the end of the epoch. Let X t denote the (observed) state of the system at the start of epoch t , and let S c t denote the true subprocesses gov erning the system during epoch t . Gi ven the state and true subprocesses, the simulation output at the end of epoch t on a giv en replication j = 1 , 2 , . . . can be expressed as Y j ( X t , S c t ) ≡ µ ( X t , S c t ) + ϵ j ( X t , S c t ) . In contrast to the offline simulation setting, the state of the system is now an explicit input to the simulation model that can v ary across configurations. As a result, we slightly modify the DOE frame work introduced in Section 5. Recall that in the LH designs we assume a common number of resampled instances for each submodel: B . In the digital-twin setting, howe ver , the number of states of interest—whether observed in the past or produced from a future forecast—need not equal B . For each state of interest, we propose forming B ′ design points via a LH design, as described in the pre vious section, and form a per -state dataset as depicted in T able 3. For computational reasons, the value of B ′ may be chosen to be smaller than that in the offline simulation setting. Creating a separate design for each state is motiv ated by our desire to eliminate the impact of the variability of the system state on the variability of the KPI. W e believ e that in a digital-twin setting, a decision maker is interested in understanding how much each estimated submodel contrib utes to the o verall uncertainty acr oss dif fer ent states . This is partly because decisions that are informed by the resulting importance scores—such as from which subprocesses more data should be collected—will typically not depend on any one particular state. W e therefore propose applying our tree-based method on each state’ s design and reporting the av erage importance scores of each submodel across states as indicators of their aggr egate contrib utions to epistemic uncertainty . A weighted average can alternativ ely be used, where the average sum of squares (TSS) in each bagged tree is used as the weight, assigning more importance to states with higher variance. 6.2 Bias Estimation in Digital T wins Recent research has examined the (mis)alignment between digital twins and their physical counterparts [ 27 , 14 ], where simulation outputs are periodically compared against observed data using statistical tests. W e propose a method for quantifying a related form of bias that uses the same data as in the aforementioned design and does not require additional simulation runs. Suppose that the real system is observed at states { x t 1 , x t 2 , . . . , x t N } with corresponding observed KPIs { y ( x t 1 , S c t 1 ) , y ( x t 2 , S c t 2 ) , . . . , y ( x t N , S c t N ) } . W e define the state-avera ge bias to be η N = 1 N N X i =1 E h Y x t i , ˆ S t i i − µ x t i , S c t i . The state-av erage bias measures the av erage discrepancy between the simulated and observ ed KPIs across the set of observed system states. This bias quantifies the systematic misalignment between the digital twin and the physical system that could persist o ver time if uncorrected. For each configuration in T able 3, b ′ = 1 , 2 , . . . , B ′ , we can calculate a corresponding point estimate of this bias across states: ˆ η ⟨ b ′ ⟩ N = 1 N N X i =1 1 n n X j =1 Y j x t i , ˆ S ⟨ b ′ ⟩ t i − y x t i , S c t i . An approximate 100(1 − α )% CI for the state-average bias can then be constructed using the empirical quantiles of the bootstrapped (or resampled) estimates ˆ η ⟨ 1 ⟩ N , ˆ η ⟨ 2 ⟩ N , . . . , ˆ η ⟨ B ′ ⟩ N as Q α/ 2 ( ˆ η N ) , Q 1 − α/ 2 ( ˆ η N ) , where Q p ( ˆ η N ) denotes the empirical p -quantile. 10 T able 3: Sampling frame work for submodel uncertainty in digital-twin setting. State Submodels Output X t ˆ S ⟨ 1 ⟩ t Y ⟨ 1 ⟩ t, 1 = Y 1 ( X t , ˆ S ⟨ 1 ⟩ t ) Y ⟨ 1 ⟩ t, 2 = Y 2 ( X t , ˆ S ⟨ 1 ⟩ t ) . . . Y ⟨ 1 ⟩ t,n = Y n ( X t , ˆ S ⟨ 1 ⟩ t ) X t ˆ S ⟨ 2 ⟩ t Y ⟨ 2 ⟩ t, 1 = Y 1 ( X t , ˆ S ⟨ 2 ⟩ t ) Y ⟨ 2 ⟩ t, 2 = Y 2 ( X t , ˆ S ⟨ 2 ⟩ t ) . . . Y ⟨ 2 ⟩ t,n = Y n ( X t , ˆ S ⟨ 2 ⟩ t ) . . . . . . . . . X t ˆ S ⟨ B ′ ⟩ t Y ⟨ B ′ ⟩ t, 1 = Y 1 ( X t , ˆ S ⟨ B ′ ⟩ t ) Y ⟨ B ′ ⟩ t, 2 = Y 2 ( X t , ˆ S ⟨ B ′ ⟩ t ) . . . Y ⟨ B ′ ⟩ t,n = Y n ( X t , ˆ S ⟨ B ′ ⟩ t ) 6.3 Numerical Example T o illustrate the effects of submodel uncertainty in the digital-twin setting, we consider a simulation model of a contact center with two contact groups and three e xpert groups. Contacts from each group are assumed to arri ve according to two independent nonhomogeneous Poisson processes with piece wise-constant arri v al rate functions that v ary by hour . For each contact group, patience times and service times are jointly distributed with Gamma marginal distrib utions coupled through a Gaussian copula. The KPI of interest is the expected av erage waiting time of contacts in the second contact group. Each expert group has two e xperts. The first expert group serv es only the first contact group, the second expert group serv es only the second contact group, and the third e xpert group serves both contact groups with priority giv en to the first contact group. A routing mechanism dynamically assigns contacts to experts based on system conditions and is triggered when one of two scenarios occurs: If a contact arriv es to find their contact group queue is empty and one or more compatible experts are av ailable, the contact is immediately assigned to one of the av ailable experts. Alternativ ely , if an expert becomes av ailable when queues are present, a waiting contact is selected to be serviced by that expert. W e consider two distinct routing processes: a contact-triggered routing process, denoted by S c C , and an expert-triggered routing process, denoted by S c E . Both S c C and S c E are rules-based functions with non-trivial decision rules. For the frequentist case, we use maximum likelihood estimators (MLEs) for the input submodels and logistic regression models for the routing submodels. For the Bayesian case, we use non-informative priors for the input submodels—which yields the same estimates as the MLEs—and for the routing submodels, we train two Bayesian neural networks, each with one hidden layer with 128 nodes. The simulation model is run for a single nine-hour day , and the state of the system is recorded at each 30-minute interv al for a total of 18 epochs. At the end of the day , data on customer arriv als, patience times, handle times, and routing decisions are collected and used to construct the estimated submodels. In the case without submodel uncertainty , the simulation is run for 100 replications for each of the observed system states. In the presence of submodel uncertainty , 180 configurations are selected, where for each configuration we use one of the five resampled instances of each submodel as denoted by the Latin hypercube (LH) design. Since we hav e observed 18 states, we pick 2 stacks each with 5 configurations of submodels for each state. T o obtain the true KPI value for each state, an additional 1,000 replications are performed and the results treated as the ground-truth benchmark. Figure 5 reports 90% confidence and credible interv als for the mean waiting-time KPI of the second contact group at the end of each epoch under the tw o experimental settings for both frequentist and Bayesian settings. As observed, the width of the interv als increases as submodel uncertainty is incorporated. For each observ ed system state, we compute importance scores using the bagging approach with 40 trees and av erage these scores across all states to obtain an overall importance measure for both the 11 frequentist and Bayesian settings, as sho wn in Figure 6. The second contact group’ s arriv al and patience-and-handle time submodels contrib ute the most to the o verall uncertainty . Therefore one should prioritize enhancing the second contact group’ s input modeling in the frequentist setting, for instance, by collecting more data. In the Bayesian setting, the expert-side routing submodel contrib utes the most to the overall uncertainty , thus collecting more training data or considering a more flexible ML model could potentially reduce the epistemic uncertainty . Calculating the overall bias yields CIs of ( − 0 . 33 , − 0 . 12) and ( − 0 . 61 , − 0 . 38) for the frequentist and Bayesian settings, respectively . These results indicate that the use of estimated submodels has led to a potential misalignment in KPI estimation. Whether this degree of state-av erage bias is practically significant will depend on the business purpose. (a) Frequentist submodels. (b) Bayesian submodels. Figure 5: 90% confidence and credible intervals when considering submodel uncertainty and not considering submodel uncertainty for (a) frequentist and (b) Bayesian submodels. 7 Conclusion This paper dev elops a general framew ork for quantifying uncertainty that arises from embedding submodels within stochastic simulation models. W e employ bootstrapping and Bayesian model averaging to construct quantile-based confidence and credible interv als that capture both epistemic and aleatoric uncertainty . T o understand the drivers of this uncertainty , we use regression-tree-based v ariable-importance measures to identify the most influential submodels. W e further show ho w the proposed framew ork can be e xtended to digital-twin settings with time-v arying submodels. Numerical experiments demonstrate that con ventional methods may substantially underestimate uncertainty , whereas accounting for submodel uncertainty yields more reliable inference. Future work can in vestigate the role of uncertainty quantification in model calibration and activ e learning approaches for dynamically training and updating submodels in digital-twin settings. 12 (a) Frequentist submodels. (b) Bayesian submodels. Figure 6: Importance scores for the submodels in the second e xperiment for (a) frequentist and (b) Bayesian formula- tions. Acknowledgement This work w as supported by the Intuit Uni versity Collaboration Program. W e also thank Dusan Bosnjako vic for his support throughout the project. References [1] Antonio Alcántara, Carlos Ruiz, and Calvin Tsay . A quantile neural network framew ork for two-stage stochastic optimization. Expert Systems with Applications , page 127876, 2025. [2] Saurabh Arora and Prashant Doshi. A survey of in verse reinforcement learning: Challenges, methods and progress. Artificial Intelligence , 297:103500, 2021. [3] Russell R Barton. Response grid plots for model-agnostic machine learning insight. IMA J ournal of Management Mathematics , 36(4):623–648, 2025. [4] Russell R Barton, Henry Lam, and Eunhye Song. Input uncertainty in stochastic simulation. In The P algrave Handbook of Operations Resear ch , pages 573–620. Springer , Cham, Switzerland, 2022. [5] Leo Breiman. Random forests. Machine Learning , 45(1):5–32, 2001. [6] W ang Cen and Peter J Haas. Nim: Generativ e neural networks for automated modeling and generation of simulation inputs. A CM T ransactions on Modeling and Computer Simulation , 33(3):1–26, 2023. [7] W enbo Chen, Mathieu T anneau, and Pascal V an Hentenryck. Real-time risk analysis with optimization proxies. Electric P ower Systems Resear ch , 235(1):110822, 2024. [8] Stephen E Chick. Input distribution selection for simulation experiments: Accounting for input uncertainty . Operations Resear ch , 49(5):744–758, 2001. [9] Luc Devroye. Nonuniform random variate generation. Handbooks in Operations Researc h and Management Science , 13:83–121, 2006. [10] Bradley Efron and Robert J. T ibshirani. An Introduction to the Bootstr ap . Chapman and Hall/CRC, New Y ork, NY , 1994. [11] Mohammadmahdi Ghasemloo, David J Eckman, and Y axian Li. Quantifying uncertainty from machine learning surrogate models embedded in simulation models. In 2025 W inter Simulation Conference (WSC) , pages 3418–3429. IEEE, 2025. [12] Michael Grieves and John V ickers. Digital T win: Mitigating Unpredictable, Undesirable Emer gent Behavior in Complex Systems . Springer Series in Advanced Manuf acturing. Springer , Cham, Switzerland, 2016. [13] T re vor Hastie, Robert Tibshirani, and Jerome Friedman. The Elements of Statistical Learning: Data Mining, Infer ence, and Pr ediction . Springer Series in Statistics. Springer , New Y ork, 2nd edition, 2009. [14] Linyun He, Luk e Rhodes-Leader , and Eunhye Song. Digital twin v alidation with multi-epoch, multi-v ariate output data. In 2024 W inter Simulation Conference (WSC) , pages 347–358. IEEE, 2024. [15] Linyun He and Eunhye Song. Introductory tutorial: Simulation optimization under input uncertainty . In 2024 W inter Simulation Confer ence (WSC) , pages 1338–1352. IEEE, 2024. [16] Ziqi Huang, Y ang Shen, Jiayi Li, Marcel Fey , and Christian Brecher . A surve y on ai-driv en digital twins in industry 4.0: Smart manufacturing and adv anced robotics. Sensors , 21(19):1–23, 2021. [17] Gareth James, Daniela Witten, Tre vor Hastie, and Robert Tibshirani. An Intr oduction to Statistical Learning: W ith Applications in R . Springer T exts in Statistics. Springer , New Y ork, 2nd edition, 2021. 13 [18] Soumendra N. Lahiri. Resampling Methods for Dependent Data . Springer Series in Statistics. Springer, Ne w Y ork, 2003. [19] Henry Lam and Huajie Qian. Subsampling to enhance efficienc y in input uncertainty quantification. Operations Resear ch , 70(3):1891–1913, 2022. [20] Lucas Mentch and W eijia Zhou. Randomization as regularization: A degrees of freedom explanation for random forests. Journal of Mac hine Learning Research , 21(202):1–39, 2020. [21] Lucy E Morgan, Barry L Nelson, Andrew C T itman, and David J W orthington. Detecting bias due to input modelling in computer simulation. Eur opean Journal of Operational Resear ch , 279(3):869–881, 2019. [22] Radford M. Neal. Bayesian Learning for Neural Networks . PhD thesis, Univ ersity of T oronto, 2012. [23] Barry Nelson and Linda Pei. F oundations and Methods of Stochastic Simulation , v olume 187. Springer , 2nd edition, 2021. [24] Dimitris N. Politis and Joseph P . Romano. The stationary bootstrap. Journal of the American Statistical Association , 89(428):1303–1313, 1994. [25] Christos Pylianidis, V al Snow , Hiske Overweg, Sjoukje Osinga, John Kean, and Ioannis N Athanasiadis. Simulation-assisted machine learning for operational digital twins. En vir onmental Modelling & Software , 148:105274, 2022. [26] Carl Edward Rasmussen and Christopher K. I. W illiams. Gaussian Pr ocesses for Machine Learning . MIT Press, Cambridge, MA, 2006. [27] Luke A Rhodes-Leader and Barry L Nelson. Tracking and detecting systematic errors in digital twins. In 2023 W inter Simulation Confer ence (WSC) , pages 492–503. IEEE, 2023. [28] Susan M Sanchez, P aul J Sanchez, and Hong W an. W ork smarter , not harder: A tutorial on designing and conducting simulation experiments. In 2020 W inter Simulation Confer ence (WSC) , pages 1128–1142. IEEE, 2020. [29] Thomas J. Santner , Brian J. W illiams, and W illiam I. Notz. The Design and Analysis of Computer Experiments . Springer, Ne w Y ork, 2nd edition, 2018. [30] David Simchi-Levi, Philip Kaminsk y , and Edith Simchi-Levi. Designing and Mana ging the Supply Chain: Concepts, Str ate gies, and Case Studies . McGraw-Hill, 2007. [31] Simio LLC. Simio simulation software. https://www.simio.com , 2023. Accessed: 2026-02-13. [32] Richard S. Sutton and Andrew G. Barto. Reinforcement Learning: An Introduction . MIT Press, Cambridge, MA, 1998. [33] Zhou T ang and T ed W estling. Consistency of the bootstrap for asymptotically linear estimators based on machine learning. arXiv pr eprint arXiv:2404.03064 , 2024. [34] Simon JE T aylor, Charles M Macal, Andrea Matta, Markus Rabe, Susan M Sanchez, and Guodong Shao. Enhancing digital twins with adv ances in simulation and artificial intelligence: Opportunities and challenges. In 2023 W inter Simulation Confer ence (WSC) , pages 3296–3310. IEEE, 2023. [35] Adam Thelen, Xiaoge Zhang, Olga Fink, Y an Lu, Sayan Ghosh, Byeng D Y oun, Michael D T odd, Sankaran Mahadev an, Chao Hu, and Zhen Hu. A comprehensi ve re view of digital twin — part 2: Roles of uncertainty quantification and optimization, a battery digital twin, and perspectiv es. arXiv pr eprint arXiv:2208.12904 , 2022. [36] Markus W ulfmeier, Peter Ondruska, and Ingmar Posner . Maximum entropy deep in verse reinforcement learning. arXiv pr eprint arXiv:1507.04888 , 2015. [37] Jiannan Y ang, Robin S. Langley , and Luis Andrade. Digital twins for design in the presence of uncertainties. Mechanical Systems and Signal Pr ocessing , 179:109338, 2022. [38] Jianming Y e. On measuring and correcting the effects of data mining and model selection. Journal of the American Statistical Association , 93(441):120–131, 1998. 14
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment