시뮬레이션 서브모델 불확실성 정량화와 기여도 분석
본 논문은 복합 시스템 시뮬레이션에서 사용되는 서브모델(입력 모델, 의사결정 로직, 최적화 프록시 등)의 추정·학습 과정에서 발생하는 에피스테믹 불확실성을 ‘서브모델 불확실성’이라 정의하고, 이를 정량화·분해하는 일반화된 프레임워크를 제시한다. 부트스트랩과 베이지안 모델 평균화(BMA)를 활용해 서브모델 인스턴스를 생성하고, 설계된 실험을 통해 전체 출력 변동성을 알레아토릭(시뮬레이션 잡음)과 서브모델 에피스테믹 변동으로 분리한다. 이후 트리 …
저자: Mohammadmahdi Ghasemloo, David J. Eckman, Yaxian Li
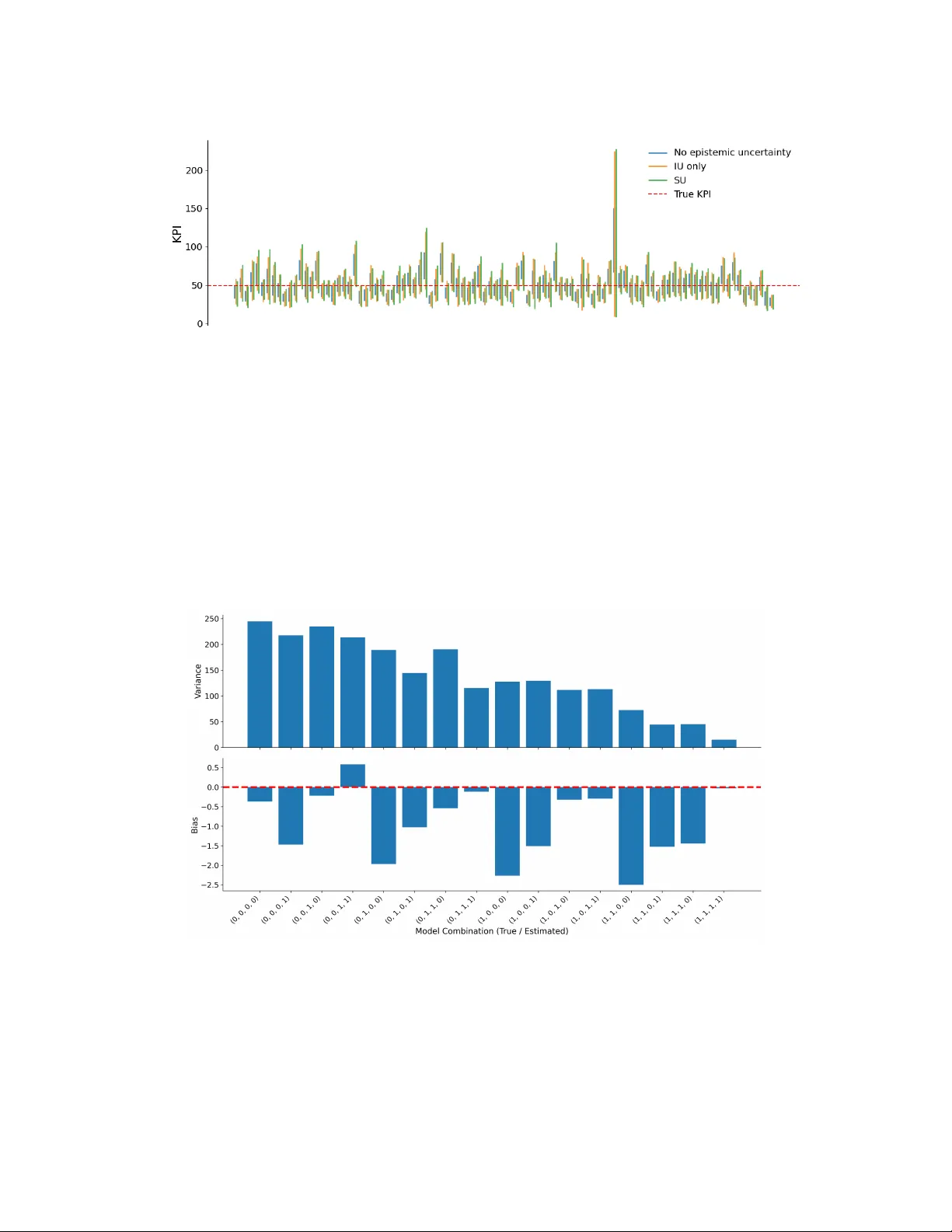
본 논문은 복합 시스템의 시뮬레이션 모델에서 실제 프로세스를 직접 구현하기 어려운 경우, 해당 프로세스를 대체하는 ‘서브모델’이 도입되는 현실을 다루며, 이러한 서브모델이 초래하는 에피스테믹 불확실성을 ‘서브모델 불확실성’이라 명명한다. 서브모델은 크게 (1) 결정적 서브모델, (2) 무조건적 확률적 서브모델, (3) 조건부 확률적 서브모델로 구분된다. 결정적 서브모델은 입력 X에만 의존해 출력이 고정되며, 주로 규칙 기반 로직이나 최적화 프록시, 강화학습 정책 등을 포함한다. 무조건적 확률적 서브모델은 난수 ξ만을 입력으로 받아 확률분포를 구현하는 변량 생성기나 VAE와 같은 생성 모델을 의미한다. 조건부 확률적 서브모델은 입력 X와 난수 ξ를 동시에 사용해 상황에 따라 변동하는 확률적 출력을 만든다(예: CVAE, 조건부 시뮬레이션 서브모델).
시뮬레이션 출력 Y는 실제 서브프로세스 집합 Sc에 의해 결정되는 기대값 μ(Sc)와 시뮬레이션 잡음 ε로 표현된다. 실제 서브프로세스를 추정한 서브모델 Ŝ를 사용하면, 추정된 평균 ¯Y(Ŝ)의 분산은 전체 변동을 알레아토릭 변동(σ²_MC)과 서브모델 에피스테믹 변동(σ²_SU)으로 분해할 수 있다. 이때 σ²_SU는 서브모델이 추정 과정에서 발생하는 불확실성을 의미한다. 논문은 이 σ²_SU를 다시 개별 서브모델별로 분해하고, 각 서브모델이 전체 불확실성에 기여하는 정도를 정량화하는 방법을 제시한다.
정량화 방법은 크게 두 단계로 구성된다. 첫째, 서브모델 인스턴스를 생성한다. 빈도주의 관점에서는 부트스트랩을 통해 원본 데이터에서 재표집하여 다수의 서브모델을 만든다. 베이지안 관점에서는 사후 분포에서 샘플링하거나 베이지안 모델 평균화(BMA)를 이용해 여러 후보 모델을 가중 평균한다. 둘째, 생성된 서브모델 집합을 설계실험(Design of Experiments, DOE)으로 시뮬레이션에 투입한다. 여기서는 스택된 라틴 하이퍼큐브(Latin Hypercube) 설계를 사용해 다차원 서브모델 공간을 효율적으로 탐색한다. 실험 결과로 얻은 시뮬레이션 출력 집합에 대해, 전체 분산을 위에서 언급한 두 성분으로 분해하고, 트리 기반 회귀 모델을 이용해 각 서브모델이 분산 감소에 기여한 정도를 중요도 점수(importance score)로 산출한다. 트리는 각 서브모델 인스턴스가 출력에 미치는 영향을 단계별로 파악하고, 변수 중요도는 해당 변수가 포함된 노드에서의 분산 감소량으로 정의된다.
디지털 트윈 환경에서는 시뮬레이션이 실시간 또는 주기적으로 관측된 시스템 상태에서 초기화된다. 따라서 서브모델이 시간에 따라 변하거나, 상태에 따라 다른 서브모델이 적용될 수 있다. 논문은 이러한 상황을 고려해, 각 시간 단계별로 트리 분석을 수행하고, 시간에 걸친 중요도 점수를 평균·집계함으로써 서브모델의 시간별 기여도를 파악한다. 또한, 실제 시스템 KPI와 시뮬레이션 KPI가 동시에 관측 가능한 경우, 상태 평균 편향(state‑average bias)을 추정하는 절차를 제안한다. 이는 서브모델이 시스템 전반에 미치는 체계적 오차를 보정하는 데 활용될 수 있다.
실험 부분에서는 두 가지 사례를 제시한다. 첫 번째는 파라미터가 알려진 합성 모델에 대해, 일부 서브모델을 의도적으로 오차가 있는 형태(예: 잘못된 분포 추정, 부정확한 정책 모델)로 교체하고, 부트스트랩·BMA 기반의 신뢰구간이 실제 평균을 적절히 포함함을 확인한다. 이 과정에서 트리 기반 중요도 점수가 오차가 큰 서브모델에 높은 점수를 부여함으로써, 불확실성 원인 식별에 유용함을 보여준다. 두 번째는 콜센터 디지털 트윈 사례이다. 여기서는 (1) 고객 도착 예측 모델, (2) 라우팅 정책 모델, (3) 스케줄링 최적화 프록시라는 세 종류 서브모델을 사용한다. 각 서브모델을 부트스트랩·BMA로 다수 생성하고, 스택된 LH 설계로 시뮬레이션을 실행한다. 결과적으로 라우팅 정책 모델이 전체 KPI(예: 평균 대기시간) 변동에 가장 큰 기여를 한다는 것이 트리 기반 중요도 점수를 통해 드러났으며, 이는 데이터 수집·모델 개선 우선순위를 제시하는 실질적인 인사이트를 제공한다.
논문의 주요 기여는 다음과 같다. (1) 서브모델 불확실성을 포괄적으로 정의하고, 입력 불확실성 연구를 확장한 일반화된 프레임워크를 제시한다. (2) 빈도주의와 베이지안 양쪽 접근을 모두 지원하는 서브모델 샘플링 기법을 도입한다. (3) 설계실험과 트리 기반 중요도 분석을 결합해 전체 불확실성을 알레아토릭·에피스테믹으로 분해하고, 개별 서브모델 기여도를 정량화한다. (4) 디지털 트윈 환경에 적용 가능한 시간‑연속 불확실성 분석 방법을 제시한다. (5) 합성 및 실제 사례를 통해 프레임워크의 실효성을 입증한다.
한계점으로는 (a) 서브모델 수가 많아지면 설계실험 차원이 급증해 계산 비용이 증가할 수 있다. (b) 베이지안 접근 시 사전 분포 선택이 결과에 민감할 수 있다. (c) 트리 기반 중요도 점수는 비선형 상호작용을 완전히 포착하지 못할 가능성이 있다. 향후 연구에서는 적응형 샘플링, 메타모델 기반 차원 축소, 서브모델 편향 보정 기법 등을 통합해 확장성을 높이고, 실시간 디지털 트윈에서의 온라인 업데이트 메커니즘을 개발하는 방향을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기