Enroll-on-Wakeup: A First Comparative Study of Target Speech Extraction for Seamless Interaction in Real Noisy Human-Machine Dialogue Scenarios
Target speech extraction (TSE) typically relies on pre-recorded high-quality enrollment speech, which disrupts user experience and limits feasibility in spontaneous interaction. In this paper, we propose Enroll-on-Wakeup (EoW), a novel framework wher…
Authors: Yiming Yang, Guangyong Wang, Haixin Guan
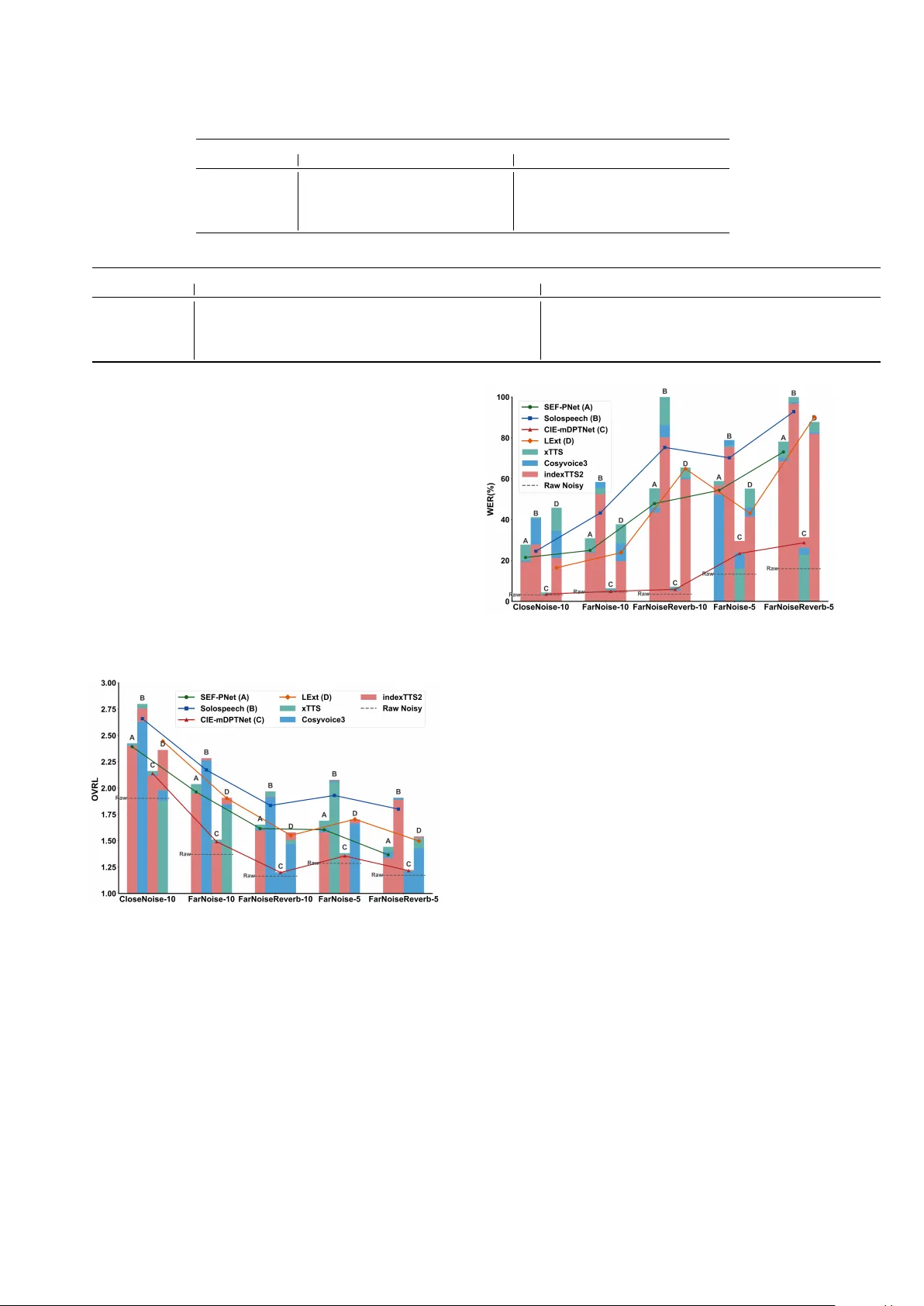
Enr oll-on-W akeup: A First Comparativ e Study of T arget Speech Extraction f or Seamless Interaction in Real Noisy Human-Machine Dialogue Scenarios Y iming Y ang 1 , Guangyong W ang 2 , Haixin Guan 2 , Y anhua Long 1 , ∗∗ 1 Shanghai Normal Uni versity , Shanghai, China 2 Unisound AI T echnology Co., Ltd., Beijing, China y2379286479@outlook.com, yanhua@shnu.edu.cn Abstract T arget speech extraction (TSE) typically relies on pre-recorded high-quality enrollment speech, which disrupts user experi- ence and limits feasibility in spontaneous interaction. In this paper , we propose Enroll-on-W akeup (EoW), a no vel frame- work where the wake-w ord segment, captured naturally during human-machine interaction, is automatically utilized as the en- rollment reference. This eliminates the need for pre-collected speech to enable a seamless experience. W e perform the first systematic study of EoW -TSE, ev aluating advanced discrimi- nativ e and generative models under real diverse acoustic con- ditions. Given the short and noisy nature of wake-word seg- ments, we in vestigate enrollment augmentation using LLM- based TTS. Results sho w that while current TSE models face performance degradation in EoW -TSE, TTS-based assistance significantly enhances the listening experience, though gaps re- main in speech recognition accuracy . Index T erms : T arget speech extraction, seamless interaction, EoW -TSE 1. Introduction T arget speech extraction (TSE) aims to isolate a specific speaker’ s voice from a multi-talker or noisy acoustic environ- ment by le veraging a set of auxiliary clues, such as a ref- erence enrollment utterance from the tar get speaker . T radi- tional TSE frameworks typically operate under the assump- tion that a high-quality , pre-recorded enrollment signal is read- ily available to guide the extraction backbone in characterizing the speaker’ s unique embedding [1–3]. Ho wever , in practical human-machine dialogue scenarios, requiring users to provide a pre-collected enrollment sample beforehand significantly dis- rupts the fluidity of interaction and limits the system’ s feasi- bility for spontaneous or first-time users. T o bridge this gap and enable truly seamless interaction, it is essential to move to- ward an “Enroll-on-W akeup” (EoW) TSE. In this setting, the system must extract the target speech using only the brief and often noise and interferer corrupted wake-word segment cap- tured during the initial triggering phase, posing a significant yet necessary challenge for current TSE research. Existing methods for providing target speaker clues in TSE can be broadly categorized into three paradigms: audio- only , audio-visual (A V -TSE), and spatial-assisted auditory TSE. Audio-only-enrollment based TSE primarily relies on pre- trained speaker verification models [4] or dedicated speaker en- coders [5–7] to extract target speaker identity embeddings. Re- cently , speaker embedding-free methods [8–10] and wa veform- lev el concatenation approaches [11] hav e demonstrated rob ust performance across various TSE tasks. Despite their success, ** indicates the corresponding author . these methods remain dependent on the requirement of pre- recorded enrollment. T o le verage multi-modal information, A V - TSE [12–14] incorporates visual cues such as lip mov ements, while recent works [15] integrate the linguistic knowledge of large language models to compensate for acoustic degrada- tion. Ho we ver , A V -TSE is fundamentally limited by line-of- sight requirements and raises significant priv acy and compu- tational concerns for low-power embedded devices. Alterna- tiv ely , spatial-assisted TSE [16, 17] utilizes multi-channel fea- tures or direction-of-arriv al information to localize the target speaker . While ef fective, these systems necessitate specific multi-microphone array configurations, limiting their versatil- ity across div erse hardware. Ultimately , regardless of the target speaker clues utilized, most existing frame works ov erlook the practical challenge of obtaining high-quality references in spontaneous dialogue. The dependency on pre-collected data or specialized hardware re- mains a bottleneck for seamless human-machine interaction. T o address these limitations, this paper inv estigates the feasibility of TSE using only the intrinsic information a v ailable during the interaction process itself. Specifically , we propose an EoW -TSE that directly adopts the wake-word se gment as the enrollment reference. This approach eliminates the user’ s burden of manual enrollment. The main contrib utions are summarized as follo ws: • W e introduce the Enroll-on-W akeup (EoW) TSE paradigm, utilizing the triggering wake-word as an automatic enroll- ment clue to facilitate zero-ef fort, seamless human-machine interaction. • W e present the first systematic study of EoW -TSE, provid- ing a comprehensi ve ev aluation of adv anced generati ve and discriminativ e models under diverse acoustic conditions and complex interferences; • W e inv estigate enrollment augmentation methods using LLM-based TTS, demonstrating that synthetic enrollment significantly enhances perceptual quality under se vere acous- tic degradation, while identifying the remaining challenges in balancing speech intelligibility with ASR accuracy . 2. Problem Definition This section defines the Enr oll-on-W akeup (EoW) TSE frame- work, illustrated in Figure 1. The goal of EoW -TSE is to e xtract target speech from a continuous noisy mixture by using only the transient wake-w ord segment as the enrollment reference. 2.1. Con ventional TSE F ormulation In a traditional TSE task, the observ ed noisy mixture x ( t ) in the time domain is typically modeled as: x ( t ) = s ( t ) + n ( t ) (1) Figure 1: Illustration of EoW -TSE system. where s ( t ) represents the clean target speech and n ( t ) denotes the sum of additi ve noise and interfering talk ers. Standard mod- els isolate s ( t ) by lev eraging a high-quality enrollment utter- ance e pre , which is pre-recorded under controlled, clean condi- tions. The extraction process can be expressed as: ˆ s ( t ) = F ( x ( t ) | e pre ; Θ) (2) where F is the TSE mapping function and Θ represents the model parameters. As discussed in Section 1, the reliance on a pre-collected e pre limits the system’ s spontaneity and disrupts the user experience. 2.2. The EoW -TSE Architectur e and Challenges Unlike the con ventional approach, the proposed EoW -TSE de- riv es the target speaker enrollment clue directly from the inter- action process. As shown in Figure 1, the input stream contains the wake-up command (e.g., “Hi, Pandora”) followed imme- diately by the target query (e.g., “What’ s the weather like to- day?”). The workflow of EoW -TSE can be defined as follo ws: • KWS-Segmentation: A keyw ord spotting (KWS) module segments the incoming stream into the wake-word se gment x wak e and the subsequent noisy mixture x quer y ; • Enroll-on-W akeup: The system automatically utilizes x wak e as the EoW reference. Unlike the static e pre , x wak e is inherently characterized by limited duration and acoustic corruption with en vironmental noise and interference; • T arget Extraction: The TSE model uses this noisy , short- duration enrollment to extract the target speech ˆ s quer y from the query mixture: ˆ s quer y = F ( x quer y | x wak e ; Θ) (3) The core innov ation of EoW -TSE lies in its zero-eff ort en- rollment , which enables seamless interaction without the con- ventional “enroll-then-extract” constraint. Howe ver , this archi- tecture shift introduces significant challenges: the brevity of x wak e falls to pro vide rob ust target speaker clues, and real-time en vironmental interference leads to “clue contamination”, re- sulting in significant performance degradation. 3. Enroll-on-W akeup TSE Systems This section details our experimental framework for evaluating EoW -TSE. W e describe fiv e real-world recording scenarios cap- turing diverse acoustic en vironments, followed by the four ad- vanced TSE models used in our comparativ e study . Finally , we introduce the integration of LLM-based TTS engines for enroll- ment augmentation. T able 1: Acoustic conditions of five EoW-TSE test scenarios. ‘ d ’ denotes distance to the micr ophone (m), ‘ RT ’ is the r ever - beration time ( RT 60 in seconds), and ‘*-10/-5’ indicates SNR levels of 10dB and 5dB r espectively . Scenario Condition #spk/#utt A verage duration (s) enrollment mixture CloseNoise-10 d=1, R T=0.4 45/503 1.08 1.78 FarNoise-10 d=3, R T=0.4 45/502 1.08 1.78 FarNoiseRe verb-10 d=3, R T=0.6 30/278 1.17 1.79 FarNoise-5 d=3, R T=0.4 45/503 1.08 1.78 FarNoiseRe verb-5 d=3, R T=0.6 15/226 0.97 1.76 3.1. Scenario Description T o ev aluate the robustness of EoW -TSE in real-world condi- tions, we utilize an internal dataset collected by Unisound 1 con- sisting of real-w orld recordings across fiv e distinct a coustic sce- narios. These scenarios are designed to reflect the complexities of actual human-machine dialogue, varying in terms of speaker distance ( d ), reverberation time ( RT 60 ), and signal-to-noise ra- tio (SNR). The detailed statistics are summarized in T able 1. The specific configurations and challenges are as follows: • Interference and Noise T ypes: In the CloseNoise scenario, the recording is conducted in a relatively clean environment. In contrast, the other four scenarios ( F arNoise and F arNois- eReverb variants) feature a challenging acoustic background consisting of audio from a television v ariety show . Both the enrollment segments ( x wak e ) and the noisy mixtures ( x quer y ) in these scenarios contain complex TV background noise, non-target human speech from the program, and addi- tional spontaneous interfering talkers in the recording room. • Acoustic V ariabilities: W e ev aluate the impact of distance by comparing close-talk ( d = 1 m, CloseNoise ) and far-field ( d = 3 m, F arNoise ) configurations. W e also assess the im- pact of increased rev erberation by varying RT 60 from 0.4s to 0.6s ( F arNoiseReverb ). T o further test the noise robustness of TSE models, we include both 10dB and 5dB SNR lev els under these far -field conditions. • W ake-up Phrases: The enrollment utilize two specific Chi- nese wake-up commands: “Hi, Pandora” or “Hello, Cube”. As detailed in T able 1, our test set includes a di verse col- lection of speakers, with 15 to 45 unique identities per scenario and ov er 2,000 utterances in total. Notably , the average enroll- ment duration ( x wak e ) is approximately 1.0s. This is signifi- cantly shorter than the multi-second or multi-utterance enroll- ments used in con ventional TSE benchmarks. This brief du- ration, combined with the aforementioned real-world interfer- ences, highlights the critical target speaker guidance informa- tion scarcity and contamination challenges of the EoW -TSE. 1 https://www .unisound.com/ 3.2. T arget Speech Extraction Systems In this study , we ev aluate four advance TSE models proposed in recent years to assess their performance under the EoW - TSE paradigm, including three discriminati ve systems (SEF- PNet [9], LExt [11], and CIE-mDPTNet [10]) and one gener- ativ e frame work (SoloSpeech [18]). 3.2.1. Discriminative TSE Models SEF-PNet [9] is a speaker-embedding-free TSE model that di- rectly integrates enrollment and mixture using an interactive speaker adaptation (ISA) module plus a local–global context aggregation (LCA) mechanism. By performing iterative T -F do- main interaction between the enrollment and mixture, the model achiev es rob ust personalized speech enhancement without rely- ing on external speak er encoders or pre-trained speaker models. It has demonstrated superior performance across all three TSE conditions on the Libri2Mix [19] benchmark. LExt [11] simply prepends an enrollment utterance (plus a tiny glue segment) to the mixture waveform so the network “hears” the target speaker first. The model learns to use that artificial onset as a prompt to extract the later target speech. This remarkably simple training-time concatenation trick works with standard separator architectures (such as TF-GridNet [20] or TF-LocoFormer [21]) and achiev es strong TSE performance on WSJ0-2mix [22] and WHAM! [23]/ WHAMR! [24]. CIE-mDPTNet [10] focuses on directly e xploiting conte x- tual information in the T -F domain to overcome the limitations of insufficient context utilization. It employs a simple attention mechanism to compute correlation weights between the enroll- ment speech and the mixture. Combined with a dual-path trans- former architecture [25], it effecti vely captures both short-term spectral variations and long-term temporal dependencies, ev en in complex, multi-speaker TSE en vironments. 3.2.2. Generative TSE Model SoloSpeech [18] is a cascaded generative TSE pipeline com- prising an audio compressor , a speaker -embedding-free extrac- tor , and a T -F domain diffusion corrector . By operating in the latent space and employing an iterative correction process, it effecti vely ov ercomes the artifacts and naturalness degradation common in discriminati ve methods. It achie ves SO T A results in both intelligibility and perceptual quality , demonstrating e xcep- tional robustness in out-of-domain and real-w orld scenarios. 3.3. A ugment Enrollment with LLM-based TTS Models The core challenge of EoW -TSE lies in the target guidance information scarcity and contamination, as enrollment signals consist of extremely short and noisy wake-up fragments. T o ad- dress this, three SO T A zero-shot generative TTS models are em- ployed: the IndexTTS2 2 [26], xTTS 3 [27], and CosyV oice3 4 [28]. By using x wak e as an acoustic prompt, these models G ( · ) perform target-identity-preserving synthesis to generate high-fidelity , clean enrollment speech. T wo enrollment aug- mentation methods are explored: 1) Clean Re-synthesis (CR): W e re-synthesize the original wak e-up transcript t wak e to pro- duce a clean version ˆ x wak e = G ( t wak e | x wak e ) , which serves as the sole enrollment for EoW -TSE extraction; 2) Extended 2 https://huggingface.co/IndexT eam/IndexTTS-2 3 https://huggingface.co/coqui/XTTS-v2/tree/v2.0.2 4 https://huggingface.co/FunAudioLLM/Fun-CosyV oice3-0.5B- 2512 Concatenation (EC): T o increase identity-clue div ersity , we generate an auxiliary clean segment a gen = G ( t gen | x wak e ) using a ChatGPT -generated sentence t gen . This is then concate- nated with the original segment to form an e xtended enrollment: e aug = [ y wak e ⊕ a gen ] . These methods aim to ev aluate whether substituting or aug- menting contaminated enrollment fragments with synthesized clean speech can effectiv ely stabilize the target speaker guid- ance under the EoW -TSE scenario. 4. Experimental Setup Datasets : W e ev aluate all models on the fi ve-scenario test set detailed in T able 1 at a 16 kHz sampling rate. For the dis- criminativ e systems: SEF-PNet, CIE-mDPTNet, and LExt, they all are trained on the Libri2Mix tr ain-100 subset under the mix both (2-speaker + noise) and min duration modes. For the generativ e SoloSpeech, we used the original authors’ pre- trained checkpoint 5 , which was trained on the Libri2Mix train- 360 subset under identical mixture conditions. Configurations: SEF-PNet and CIE-mDPTNet were trained for 130 epochs using the Adam [29] optimizer with an initial learning rate (LR) of 5e-4 and gradient clipping [30] at an L2-norm of 1. The LR was decayed by 0.98 ev ery two epochs for the first 100 epochs, and by 0.9 thereafter . LExt used an ini- tial LR of 1e-4 with a weight decay of 1e-5. For its TF-GridNet backbone, we adopted a more compact configuration than the original TF-GridNetV1 [11] to ensure a fast training. Evaluation Metrics: W e emplo y SI-SDR [31], PESQ [32], and STOI [33] to ev aluate signal fidelity and quality , while DNSMOS [34] and word error rate (WER) assess perceptual performance and intelligibility across the five real-world sce- narios. All WER results are calculated via the Fun-ASR 6 [35] service and the meeteval toolkit [36] to ensure consistent scoring across div erse acoustic and segmentation conditions. T able 2: Results on Libri2Mix 2-Speaker+Noise. ⋆ ar e the r e- sults r epr oduced by us. Models SI-SDR PESQ STOI Params MA Cs Mixture -1.96 1.08 64.73 - - SEF-PNet [9] 8.18 1.55 82.67 6.08M 15.87G CIE-mDPTNet [10] 9.47 1.78 85.35 2.9M 12.10G ⋆ LExt [11] 10.47 1.88 87.26 3.9M 8.63G SoloSpeech [18] 11.12 1.89 - 9.39G - 5. Results and Discussion 5.1. Results on Libri2mix 2spk+noise Condition T able 2 sho ws the comparati ve performance of the selected models on the challenging Libri2Mix 2-speaker+noise condi- tion. W e ev aluate a diverse set of architectures v arying in pa- rameter size and computational complexity (MACs). Among discriminativ e models, LExt achie ves the best trade-of f between efficienc y and performance. The generative SoloSpeech attains SO T A results in both SI-SDR and PESQ. Overall, all selected models exhibit competitiv e performance, establishing a robust baseline for inv estigating their behavior under the more con- strained EoW -TSE scenarios. 5 https://wanghelin1997.github .io/SoloSpeech-Demo/ 6 https://huggingface.co/FunAudioLLM/Fun-ASR-Nano-2512 T able 3: Results on enr ollments synthesized using differ ent TTS models. Conditions DNSMOS ↑ WER ↓ Noisy xTTS IndexTTS2 CosyV oice3 Noisy xTTS IndexTTS2 CosyV oice3 CloseNoise-10 2.029 2.472 2.564 2.609 14.61 39.76 11.23 40.36 FarNoise-10 1.590 2.464 2.237 2.428 27.74 40.04 19.27 54.88 FarNoiseRe verb-10 1.262 2.549 1.917 2.114 19.69 33.45 16.10 59.71 FarNoise-5 1.440 2.274 2.063 2.400 45.13 46.57 36.58 80.62 FarNoiseRe verb-5 1.251 2.473 1.743 2.107 70.58 55.86 44.47 102.54 T able 4: EoW -TSE r esults with differ ent enr ollment augmentation methods on CIE-mDPTNet. Conditions DNSMOS ↑ WER ↓ Noisy xTTS (CR) IndexTTS2 (CR) xTTS(EC) IndexTTS2(EC) Noisy xTTS(CR) IndexTTS2(CR) xTTS(EC) IndexTTS2(EC) CloseNoise-10 1.904 2.163 2.119 2.197 2.170 3.10 4.37 3.24 3.91 3.48 FarNoise-10 1.371 1.511 1.481 1.527 1.500 4.54 6.41 5.38 6.81 5.14 FarNoiseRe verb-10 1.165 1.202 1.200 1.214 1.195 3.52 7.15 5.06 7.00 6.08 FarNoise-5 1.286 1.379 1.366 1.396 1.371 13.31 16.01 29.55 15.92 25.61 FarNoiseRe verb-5 1.173 1.216 1.223 1.217 1.212 15.95 22.89 31.32 23.12 28.36 5.2. Overall P erformance of EoW -TSE Systems Figures 2 and 3 show the results of four advanced TSE mod- els under the EoW -TSE paradigm. Regarding perceptual qual- ity , the generati ve SoloSpeech consistently achie ves the highest O VRL scores across all scenarios, followed by SEF-PNet and LExt with comparable performance, while CIE-mDPTNet lags behind. Howev er , this trend reverses in the speech intelligibil- ity measured by WER. CIE-mDPTNet demonstrates the most robust ASR performance, whereas SoloSpeech suffers from a dramatic WER increase as en vironmental complexity intensi- fies (e.g., in far-field and re verberant conditions). Notably , none of these TSE models outperforms the raw noisy mixture’ s di- rect WER in these challenging scenarios. This discrepanc y sug- gests that while generativ e models are great at generating high- quality speech, they may introduce phonetic distortions that hin- der ASR accuracy , highlighting a critical area for future opti- mization in EoW -TSE research. Figure 2: O VRL scor es on five scenarios: Original EoW-TSE vs. TTS-augmented (CR). 5.3. Effect of Synthetic Enrollment Results in T able 3 aim to assess the quality of synthetic en- rollment generated by IndexTTS2, xTTS and CosyV oice3. It is clear to see that while xTTS and CosyV oice3 achie ve supe- rior DNSMOS, only IndexTTS2 consistently reduces the WER compared to raw noisy enrollment. This trend is mirrored in Figures 2 and 3, where IndexTTS2-augmented models (red bars) significantly outperform other synthetic variants in speech intelligibility , effecti vely stabilizing the TSE output. T able 4 further explores the impact of the proposed enroll- ment augmentation methods on the most WER rob ust TSE sys- tem, CIE-mDPTNet. While both Clean Re-synthesis (CR) and Figure 3: WERs on five scenarios: Original EoW-TSE vs. TTS- augmented (CR). Extended Concatenation (EC) consistently improve the DNS- MOS of the extracted target speech compared to the noisy mixture, neither method succeeds in reducing the WER . This trend aligns with the findings in Figure 3, confirming that exist- ing TSE models introduce significant phonetic distortion while suppressing noise, thereby hindering ASR performance even with enhanced guidance. Notably , although the EC method marginally improv es perceptual quality over CR, it of fers com- parable WER , suggesting that simply increasing enrollment du- ration does not ef fectively compensate for these intelligibil- ity losses. These results underscore a critical challenge in EoW -TSE: while zero-shot LLM-based TTS effecti vely miti- gates guidance contamination, balancing perceptual enhance- ment with linguistic fidelity remains an open problem. 6. Conclusion This paper presents the first systematic study of TSE under the Enroll-on-W akeup paradigm. Our ev aluation across five real-world scenarios re veals a clear perceptual-recognition gap: while advanced TSE models, especially generative ones, can notably improve audio quality , they often fail in ASR perfor- mance. W e show that current TSE systems fall short of ideal performance when limited to a one-second wake-up reference. Furthermore, while TTS helps reduce enrollment noise, the trade-off between speech perceptual and intelligibility remains a major bottleneck. These findings establish a key baseline and offer practical guidelines for building next-generation ro- bust EoW -TSE systems for seamless human-machine interac- tion. The EoW -TSE audio samples and demos are av ailable at https://yym-line.github .io/Yym-line/. 7. References [1] K. ˇ Zmol ´ ıkov ´ a, M. Delcroix, K. Kinoshita, T . Ochiai, T . Nakatani, L. Bur get, and J. ˇ Cernock ` y, “Speakerbeam: Speaker aware neural network for target speaker extraction in speech mixtures, ” IEEE Journal of Selected T opics in Signal Processing , v ol. 13, no. 4, pp. 800–814, 2019. [2] Q. W ang, H. Muckenhirn, K. W . W ilson et al. , “V oiceFilter: T argeted V oice Separation by Speaker-Conditioned Spectrogram Masking, ” in Pr oc. Interspeech , 2018. [3] H. W ang, C.-Y . Liang, S. W ang et al. , “W espeaker: A Research and Production Oriented Speaker Embedding Learning T oolkit, ” in Pr oc. ICASSP , 2022, pp. 1–5. [4] B. Desplanques, J. Thienpondt, and K. Demuynck, “ECAP A- TDNN: Emphasized Channel Attention, Propagation and Ag- gregation in TDNN Based Speaker V erification, ” in Pr oc. Inter- speech , 2020, p. 3830–3834. [5] C. Xu, W . Rao, E. S. Chng et al. , “SpEx: Multi-Scale T ime Do- main Speaker Extraction Network, ” IEEE/A CM Tr ansactions on Audio, Speech, and Language Pr ocessing , vol. 28, p. 1370–1384, 2020. [6] M. Ge, C. Xu, L. W ang et al. , “SpEx+: A Complete Time Domain Speaker Extraction Network, ” in Proc. Interspeec h , 2020. [7] J. Chen, W . Rao, Z. W ang et al. , “MC-SpEx: T owards Effectiv e Speaker Extraction with Multi-Scale Interfusion and Conditional Speaker Modulation, ” in Pr oc. Interspeec h , 2023. [8] B. Zeng and M. Li, “USEF-TSE: Universal Speaker Embedding Free T arget Speaker Extraction, ” IEEE T ransactions on Audio, Speech and Languag e Pr ocessing , 2025. [9] Z. Huang, H. Guan, H. W ei, and Y . Long, “SEF-PNet: Speaker Encoder-Free Personalized Speech Enhancement with Local and Global Contexts Aggreg ation, ” in Pr oc. ICASSP , 2025, pp. 1–5. [10] X. Y ang, C. Bao, J. Zhou, and X. Chen, “T arget speaker extrac- tion by directly exploiting contextual information in the time- frequency domain, ” in Pr oc. ICASSP , 2024, pp. 10 476–10 480. [11] P . Shen, K. Chen, S. He et al. , “Listen to Extract: Onset-Prompted T arget Speaker Extraction, ” IEEE T ransactions on Audio, Speech and Language Pr ocessing , vol. 33, pp. 4832–4843, 2025. [12] J. Lin, X. Cai, H. Dinkel et al. , “A v-Sepformer: Cross-Attention Sepformer for Audio-V isual T arget Speaker Extraction, ” in Pr oc. ICASSP , 2023, pp. 1–5. [13] J. Li, K. Zhang, S. W ang et al. , “MoMuSE: Momentum Multi- modal T arget Speaker Extraction for Real-time Scenarios with Im- paired V isual Cues, ” in Proc. IEEE International Conference on Multimedia and Expo (ICME) , 2025, pp. 1–6. [14] Z. Pan, G. Wichern, Y . Masuyama et al. , “Scenario-aware audio- visual TF-Gridnet for target speech extraction, ” in Proc. W ork- shop on IEEE Automatic Speech Recognition and Understanding (ASR U) , 2023, pp. 1–8. [15] W . W u, S. W ang, X. W u, H. Meng, and H. Li, “ELEGANCE: Ef fi- cient LLM Guidance for Audio-V isual T arget Speech Extraction, ” arXiv pr eprint arXiv:2511.06288 , 2025. [16] M. Ge, C. Xu, L. W ang et al. , “L-SpEx: Localized T arget Speaker Extraction, ” in Pr oc. ICASSP , 2022, pp. 7287–7291. [17] D.-J. Alcala Padilla, N. L. W esthausen, S. V ivekananthan, and B. T . Meyer , “Location-aware target speaker extraction for hear- ing aids, ” in Pr oc. Interspeech , 2025, pp. 2975–2979. [18] H. W ang, J. Hai, D. Y ang et al. , “SoloSpeech: Enhancing Intelligi- bility and Quality in T arget Speech Extraction through a Cascaded Generativ e Pipeline, ” arXiv pr eprint arXiv:2505.19314 , 2025. [19] J. Cosentino, M. Pariente, S. Cornell, A. Deleforge, and E. V in- cent, “Librimix: An open-source dataset for generalizable speech separation, ” arXiv preprint , 2020. [20] Z.-Q. W ang, S. Cornell, S. Choi et al. , “TF-GridNet: In- tegrating full-and sub-band modeling for speech separation, ” IEEE/ACM T ransactions on Audio, Speech, and Languag e Pro- cessing , vol. 31, pp. 3221–3236, 2023. [21] K. Saijo, G. W ichern, F . G. Germain et al. , “TF-Locoformer: T ransformer with local modeling by con volution for speech sep- aration and enhancement, ” in Proc. W orkshop on International Acoustic Signal Enhancement (IW AENC) , 2024, pp. 205–209. [22] J. R. Hershey , Z. Chen, J. Le Roux, and S. W atanabe, “Deep clus- tering: Discriminative embeddings for segmentation and separa- tion, ” in Pr oc. ICASSP , 2016, pp. 31–35. [23] G. Wichern, J. Antognini, M. Flynn et al. , “WHAM!: Extend- ing speech separation to noisy environments, ” arXiv pr eprint arXiv:1907.01160 , 2019. [24] M. Maciejewski, G. Wichern, E. McQuinn, and J. Le Roux, “WHAMR!: Noisy and reverberant single-channel speech sepa- ration, ” in Pr oc. ICASSP , 2020, pp. 696–700. [25] J. Chen, Q. Mao, and D. Liu, “Dual-path transformer network: Direct context-aw are modeling for end-to-end monaural speech separation, ” in Pr oc. Interspeech , 2020, pp. 2642–2646. [26] S. Zhou, Y . Zhou, Y . He et al. , “IndexTTS2: A Break- through in Emotionally Expressive and Duration-Controlled Auto-Regressi ve Zero-Shot T ext-to-Speech, ” arXiv pr eprint arXiv:2506.21619 , 2025. [27] E. Casanov a, K. Da vis, E. G ¨ olge et al. , “XTTS: a Massi vely Mul- tilingual Zero-Shot T ext-to-Speech Model, ” in Pr oc. Interspeech , 2024. [28] Z. Du, C. Gao, Y . W ang et al. , “Cosyvoice 3: T owards in-the- wild speech generation via scaling-up and post-training, ” arXiv pr eprint arXiv:2505.17589 , 2025. [29] D. Kinga, J. B. Adam et al. , “ A method for stochastic optimiza- tion, ” in Pr oc. International confer ence on learning repr esenta- tions (ICLR) , vol. 5, no. 6, 2015. [30] J. Zhang, T . He, S. Sra, and A. Jadbabaie, “Why gradient clip- ping accelerates training: A theoretical justification for adaptiv- ity , ” arXiv preprint , 2019. [31] J. Le Roux, S. Wisdom, H. Erdogan, and J. R. Hershey , “SDR– half-baked or well done?” in Pr oc. ICASSP , 2019, pp. 626–630. [32] A. W . Rix, J. G. Beerends, M. P . Hollier , and A. P . Hekstra, “Per- ceptual ev aluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs, ” in Pr oc. ICASSP , v ol. 2, 2001, pp. 749–752. [33] C. H. T aal, R. C. Hendriks, R. Heusdens, and J. Jensen, “A short- time objectiv e intelligibility measure for time-frequency weighted noisy speech, ” in Pr oc. ICASSP , 2010, pp. 4214–4217. [34] C. K. Reddy , V . Gopal, and R. Cutler , “DNSMOS P . 835: A non- intrusiv e perceptual objectiv e speech quality metric to evaluate noise suppressors, ” in Pr oc. ICASSP , 2022, pp. 886–890. [35] K. An, Y . Chen, Z. Chen, C. Deng et al. , “Fun-asr technical re- port, ” arXiv preprint , 2025. [36] T . v on Neumann, C. Boeddeker, M. Delcroix, and R. Haeb- Umbach, “MeetEval: A T oolkit for Computation of W ord Error Rates for Meeting Transcription Systems, ” in Proc. 7th Interna- tional W orkshop on Speec h Pr ocessing in Everyday En vironments (CHiME 2023) , 2023, pp. 27–32.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment