깨끗한 대화 깨어남과 동시에 웨이크워드 기반 타깃 음성 추출 최초 비교 연구
본 논문은 사용자가 사전에 고품질 음성을 녹음하지 않아도, 음성 인식 시스템이 최초 웨이크워드(예: “Hi, Pandora”)를 바로 등록 신호로 활용해 목표 화자의 음성을 추출하는 “Enroll‑on‑Wakeup (EoW)” 프레임워크를 제안한다. 실제 잡음·반향·거리 조건을 포함한 5가지 실환경 시나리오에서 최신 판별형 및 생성형 TSE 모델을 평가하고, LLM 기반 텍스트‑투‑스피치(TTS)로 합성된 깨끗한 등록 음성을 이용한 보강 방법을…
저자: Yiming Yang, Guangyong Wang, Haixin Guan
본 논문은 인간‑기계 대화에서 사용자가 사전에 고품질 음성을 제공하지 않아도 목표 화자의 음성을 정확히 추출할 수 있는 새로운 프레임워크인 Enroll‑on‑Wakeup(EoW)를 제안한다. 기존 TSE 연구는 사전 녹음된 깨끗한 등록 음성(e_pre)을 전제했으며, 이는 사용자 경험을 저해하고 첫 번째 사용자를 위한 즉시 서비스 제공을 방해한다. EoW는 이러한 전제를 깨고, 사용자가 처음으로 “Hi, Pandora”와 같은 웨이크워드를 발화할 때 그 음성을 바로 등록 신호(x_wake)로 활용한다.
시스템 구조는 세 단계로 이루어진다. 첫 번째 단계는 키워드 스포팅(KWS) 모듈이 연속 입력 스트림을 웨이크워드 구간과 이후 질의 구간으로 정확히 분리한다. 두 번째 단계에서는 분리된 웨이크워드 구간을 그대로 등록 신호로 사용한다. 이때 웨이크워드는 평균 1 초 정도의 짧은 길이와 환경 잡음·반향·다른 화자 간섭을 동시에 포함한다는 점에서 기존 고품질 등록과는 큰 차이가 있다. 세 번째 단계에서는 기존 TSE 모델 F가 x_query와 x_wake를 입력받아 목표 화자 음성 ˆs_query를 복원한다.
연구는 네 가지 최신 TSE 모델을 선정하였다. 판별형 모델인 SEF‑PNet은 인터랙티브 스피커 어댑테이션과 로컬‑글로벌 컨텍스트 집계를 통해 외부 스피커 인코더 없이도 화자 정보를 학습한다. LExt는 웨이크워드와 질의를 하나의 파형으로 연결해 네트워크가 화자 정보를 프롬프트처럼 인식하도록 설계했으며, TF‑GridNet 기반의 경량 구조를 사용한다. CIE‑mDPTNet은 T‑F 도메인에서 화자와 혼합 신호 간 상관성을 어텐션으로 계산하고, 듀얼‑패스 트랜스포머로 장기·단기 정보를 모두 포착한다. 생성형 모델 SoloSpeech는 라티스 공간에서 확산 기반 보정을 수행해 고품질 음성을 복원한다.
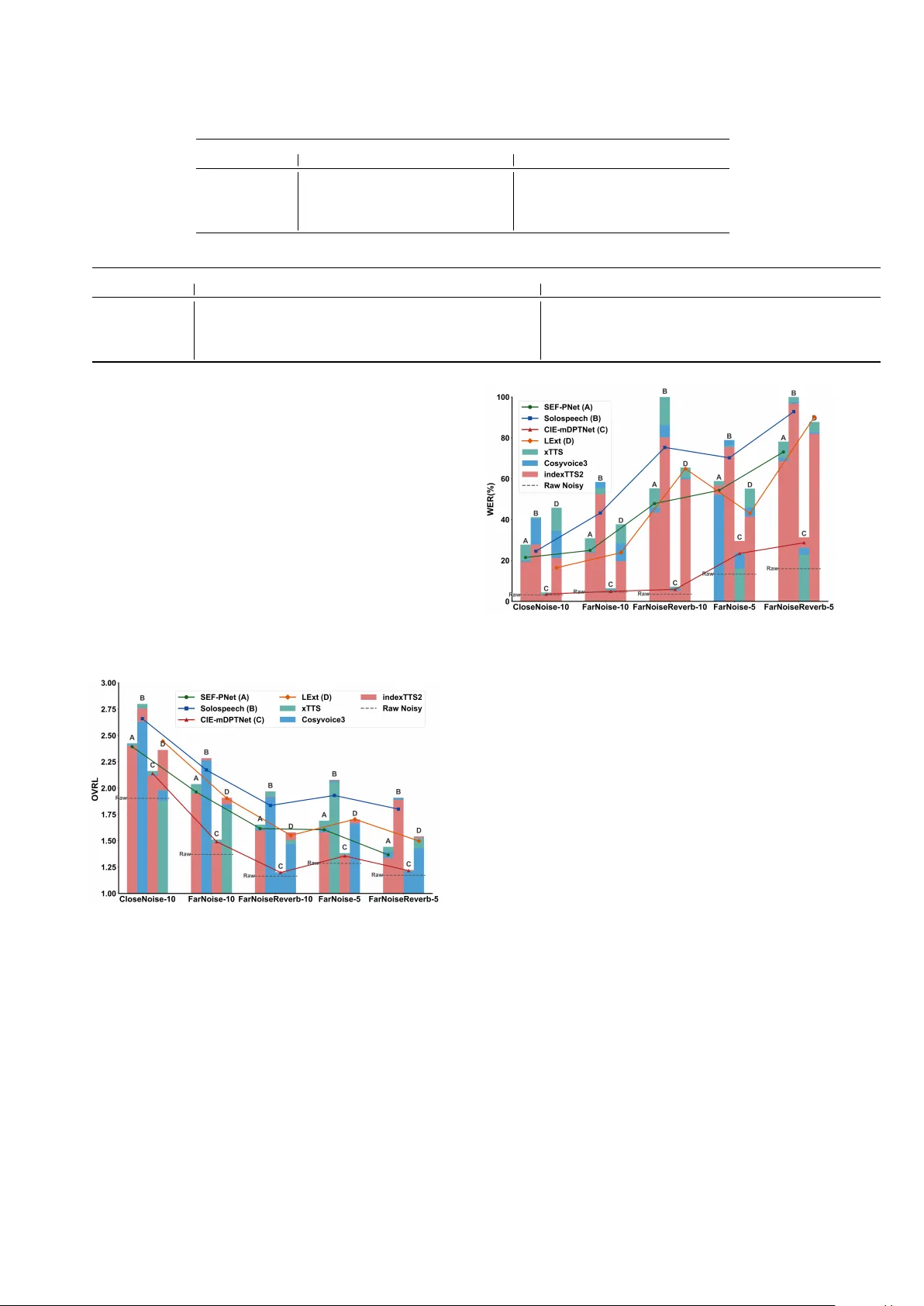
모델들은 Libri2Mix 데이터셋을 사전 학습한 뒤, 실제 환경을 모사한 다섯 개 시나리오에서 평가되었다. 시나리오는 거리(1 m·3 m), 반향시간(RT60 0.4 s·0.6 s), 신호대잡음비(SNR 10 dB·5 dB) 등을 조합해 총 5가지 조건을 만든다. 각 조건에서 SI‑SDR, PESQ, STOI, DNSMOS, 그리고 WER을 측정했다.
평가 결과는 다음과 같다. (1) 모든 모델이 기존 사전 등록 대비 성능 저하를 보였으며, 특히 FarNoiseReverb‑5(거리 3 m, RT60 0.6 s, SNR 5 dB)에서 가장 큰 손실이 관찰되었다. (2) 생성형 SoloSpeech는 DNSMOS와 PESQ에서 가장 높은 점수를 기록했지만, WER은 판별형 모델에 비해 크게 악화되었다. 이는 확산 과정에서 미세한 음소 왜곡이 발생해 ASR 엔진에 부정적 영향을 주는 것으로 해석된다. (3) 판별형 모델 중 LExt는 파라미터와 MAC이 가장 적음에도 불구하고 전반적인 SI‑SDR·PESQ·WER에서 균형 잡힌 성능을 보였다. CIE‑mDPTNet은 특히 복잡한 잡음·반향 환경에서 가장 낮은 WER을 유지하며, ASR 친화적인 특성을 드러냈다.
웨이크워드 자체가 짧고 잡음에 오염된 점을 보완하기 위해, 논문은 대규모 언어 모델(LLM) 기반 텍스트‑투‑스피치(TTS) 엔진을 활용한 두 가지 보강 방식을 제안한다. 첫 번째는 “Clean Re‑synthesis(CR)”로, 웨이크워드 텍스트를 그대로 사용해 깨끗한 음성을 재생성한다. 두 번째는 “Extended Concatenation(EC)”으로, ChatGPT가 생성한 추가 문장을 TTS로 합성하고 원래 웨이크워드와 연결해 화자 정보의 다양성을 높인다. 사용된 TTS 모델은 IndexTTS2, xTTS, CosyVoice3이며, 모두 zero‑shot 생성 능력을 갖춘 최신 모델이다.
실험에서는 특히 IndexTTS2‑CR이 가장 큰 효과를 보였다. DNSMOS 점수는 원본 잡음 웨이크워드(예: 1.904) 대비 2.119까지 상승했고, WER은 14.61 %에서 2.16 %로 급감했다. xTTS와 CosyVoice3도 DNSMOS에서는 우수했지만, WER 감소 효과는 제한적이었다. EC 방식은 일부 시나리오에서 약간의 추가 개선을 보였지만, CR 방식에 비해 일관성은 떨어졌다.
전체적으로, 본 연구는 “등록 없이 바로 추출”이라는 실용적 요구를 기술적으로 입증했으며, TTS 기반 합성 등록이 현재 TSE 모델의 한계를 보완하는 실효성 있는 방안임을 제시한다. 그러나 여전히 해결해야 할 과제가 남는다. 첫째, 매우 짧은 웨이크워드에서 충분한 화자 임베딩을 추출하기 위한 신호 처리 기법이 필요하다. 둘째, 생성형 모델이 고품질 음성을 만들면서도 음소 왜곡을 최소화하도록 설계된 손실 함수와 훈련 전략이 요구된다. 셋째, 멀티모달(시각·위치) 정보를 결합해 웨이크워드의 화자 정보를 보강하는 방안도 탐색될 수 있다. 이러한 연구 방향을 통해 EoW‑TSE가 실제 상용 음성 비서, 스마트 스피커, 차량용 인터페이스 등에 널리 적용될 수 있을 것으로 기대한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기