What Do Neurons Listen To? A Neuron-level Dissection of a General-purpose Audio Model
In this paper, we analyze the internal representations of a general-purpose audio self-supervised learning (SSL) model from a neuron-level perspective. Despite their strong empirical performance as feature extractors, the internal mechanisms underlyi…
Authors: Takao Kawamura, Daisuke Niizumi, Nobutaka Ono
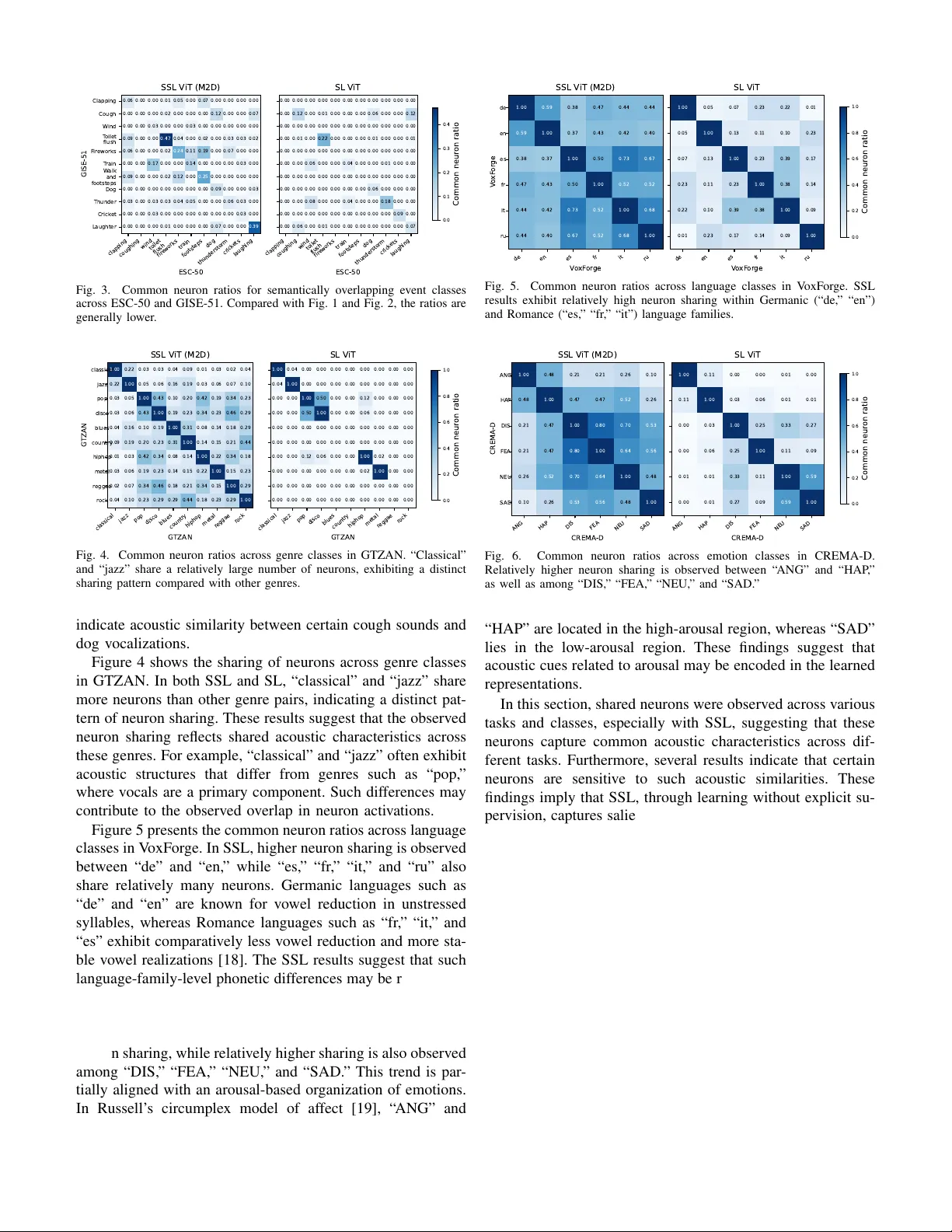
What Do Neurons Listen T o? A Neuron-le v el Dissection of a General-purpose Audio Model T akao Kaw amura, Daisuke Niizumi, and Nob utaka Ono Graduate School of Systems Design, T okyo Metr opolitan Univer sity T okyo, Japan kawamura-takao@ed.tmu.ac.jp, daisukelab .cs@gmail.com, onono@tmu.ac.jp Abstract —In this paper , we analyze the internal repr esentations of a general-purpose audio self-supervised learning (SSL) model from a neuron-lev el perspective. Despite their strong empirical performance as feature extractors, the internal mechanisms underlying the rob ust generalization of SSL audio models remain unclear . Drawing on the framework of mechanistic interpretabil- ity , we identify and examine class-specific neurons by analyzing conditional activation patterns across diverse tasks. Our analysis re veals that SSL models foster the emergence of class-specific neurons that pro vide extensive cov erage across nov el task classes. These neurons exhibit shared responses across different semantic categories and acoustic similarities, such as speech attrib utes and musical pitch. W e also confirm that these neurons have a func- tional impact on classification performance. T o our knowledge, this is the first systematic neuron-level analysis of a general- purpose audio SSL model, pro viding new insights into its internal repr esentation. Index T erms —mechanistic interpr etability , audio activation probability entropy , general-purpose audio representation, self- supervised learning I . I N T RO D U C T I O N Self-supervised learning (SSL)-based general-purpose au- dio representation models [1]–[3] achieve strong performance across a wide range of tasks, including audio classification and captioning. These models encode acoustic information into general-purpose representations that can be used for down- stream tasks. Their effecti veness has primarily been e valuated through downstream task performance. Howe ver , how such robust generalization is manifested within the model’ s internal representations remains an open question. While ev aluations on div erse do wnstream tasks demonstrate multifaceted practical effecti veness, they provide limited insight into how acoustic information is encoded inside the model. A deeper understanding of how these internal representations emerge is therefore essential to explain the success of general-purpose audio foundation models. In parallel, recent studies ha ve increasingly focused on mechanistic interpretability to in vestig ate the mechanisms underlying neural network generalization [4]. At the neuron lev el, particularly in large language models (LLMs), these approaches analyze conditional acti v ation patterns to localize attribute-sensiti ve neurons, such as those associated with lan- guage [5] and culture [6]. Such analyses provide fundamental This work was supported by JST SICORP Grant Number JPMJSC2306 and JSPS KAKENHI Grant Number 24KJ1866. insights into ho w general-purpose models mechanistically en- code heterogeneous information. In this paper , we address the lack of interpretability in general audio foundation models by applying a neuron-lev el analysis framework based on [5] to a SSL-based general- purpose model [2] that exhibits strong generalization perfor- mance. Centered on the identification of class-specific neurons, we conduct a comprehensive in vestigation into ho w these units behav e across div erse tasks, spanning en vironmental, speech, and music audio. Through an analysis across diverse tasks, we provide answers to our fundamental research questions: (1) Are there class-specific neurons in unseen tasks? (2) What do these neurons share across different classes? and (3) Do class-specific neurons contrib ute to classification? Our analysis rev eals that SSL models de velop class-specific neurons that provide near-complete coverage across div erse nov el task classes. Notably , we identify shared neuronal re- sponses for speech attrib utes (gender , language, arousal), mu- sical pitch, and acoustic similarities (e.g., across music genres). The validity of these identified neurons is further supported by their measurable impact on classification performance. T o our knowledge, this is the first systematic neuron-le vel analysis of a general-purpose audio SSL model. W e publicly release our code 1 for further adv ances and reproducibility in the field. I I . I D E N T I F Y I N G C L A S S - S P E C I FI C N E U R ON S W e in vestigate whether audio models contain neurons that respond selectiv ely to specific sound properties, and address this question through activ ation-based neuron analysis. T o this end, we identify class-specific neurons using Audio Activ ation Probability Entropy (AAPE), an entropy-based metric adapted from Language Activ ation Probability Entropy (LAPE) [5] originally proposed in the NLP domain, which quantifies ho w selectiv ely a neuron activ ates across sound classes. For each layer l and neuron n , AAPE is defined as AAPE l,n = − X c ∈C ˜ P ( c ) l,n log ˜ P ( c ) l,n , (1) where C denotes the set of event classes and ˜ P ( c ) l,n = P ( c ) l,n P c ′ ∈C P ( c ′ ) l,n . (2) 1 The URL will replace this placeholder after the notification. Here, P ( c ) l,n represents the class-wise activation pr obability , defined as the proportion of samples belonging to class c for which neuron ( l , n ) produces a positive activ ation (i.e., activ ation v alue greater than zero). A lo wer AAPE v alue indicates that the neuron tends to activ ate preferentially for a limited subset of sound classes, and such neurons are regarded as more class-specific. T o identify class-specific neurons, we follo w LAPE by applying a three-step filter: (1) excluding the bottom 5% of neurons with insufficient acti vation, (2) selecting those within the lowest r AAPE percentile of AAPE scores to ensure high selectivity , and (3) designating the top 5% by class-specific activ ation probability as the tar get neurons. The threshold r AAPE is calibrated based on the task’ s class composition. Giv en that our target model is based on the Transformer encoder architecture, we define the activ ations within the encoder blocks as individual neurons, a practice commonly adopted in the interpretability literature (e.g., LAPE). I I I . E M P I R I C A L A N A L Y S E S In the experiments, we identified neurons responsive to div erse sounds and analyzed their relationships across dif ferent classes and tasks (datasets) to better understand the mecha- nisms underlying the model’ s generalization. Additionally , we conducted ablation by steering the identified neurons’ activity to observe its impact on classification performance. A. Experimental Setup W e identified class-specific neurons for each task, repre- sented by unique IDs ⟨ layer, neuron ⟩ , to detect overlaps across classes and tasks. The target model consists of 12 layers, each containing 768 × 4 = 3072 neurons. W e set the entropy threshold r AAPE to 2% for ESC-50 and GISE-51 due to their div erse class compositions, while 1% was used for other tasks following LAPE. T o ev aluate classification performance during steering ab- lations, we employed linear e v aluation using the ev aluation platform (EV AR 2 ) following [2]. 1) Models: W e utilized a V ision T ransformer [7] (V iT) pre-trained via Masked Modeling Duo [2] (M2D), a SOT A self-supervised model. M2D is ideal for our analysis because it learns robust audio representations through simple masked prediction, demonstrating high generalization 3 . For compar- ison, we also evaluated a V iT with the same architecture, randomly initialized and trained via supervised learning (SL) on AudioSet [8] from scratch. Hereafter, we denote the former as SSL V iT (M2D) and the latter as SL V iT . 2) T asks (Datasets): W e employed di verse tasks mostly following [2], focusing on single-source clips to ensure that our neuron-lev el analysis remained unaffected by multiple acoustic features. • ESC-50 [9] comprises 2000 samples across 50 general sound ev ent classes, including animal vocalizations, nat- ural soundscapes, and urban noises such as sirens. Due 2 https://github .com/nttcslab/ev al- audio- repr 3 W e used the M2D/0.7 weight file from https://github.com/nttcslab/m2d to its class-balanced design, it serves as a controlled benchmark for e valuating our analysis. • GISE-51 [10] consists of 51 isolated general sound event classes with 16,357 samples. Although it shares a similar class taxonomy with ESC-50, GISE-51 presents a more challenging scenario due to its class imbalance and v ari- able sample durations. • V oxFor ge [11] comprises speech samples across six lan- guage classes. W e utilized 5000 samples per language, for a total of 30,000. • V oxCeleb1 [12] (VC1) comprises div erse speech from individuals. W e selected 1500 samples for which both gender (male/female) and nationality (spanning 35 coun- tries) are a vailable. • CREMA-D [13] comprises 7438 largely class-balanced speech samples with acted emotion classes. Additionally , we utilized gender information as an alternative class in our experiments. • GTZAN [14], [15] comprises 1000 class-balanced music audio samples across ten genres. • Pitch Audio Dataset (Sur ge synthesizer) [16] (Surge) comprises synthesizer note samples. W e categorized the 44,000 samples into 9 octav e classes by aggregating the original 88 indi vidual pitch classes. • NSynth [17] also consists of synthesizer note samples. For our experiments, we utilized a subset of 22,000 samples, labeled by either their 11 instrument family classes or 9 octave classes. W e aggregated the original pitch classes into octav e classes, as in Sur ge. B. RQ1: Are Ther e Class-specific Neur ons in Unseen T asks? T o address this question, we examine the emergence of class-specific neurons in various unseen tasks, providing in- sight into how models generalize beyond their training data. Specifically , we compare the abundance and selectivity of these neurons in SSL and SL models to assess their capacity for representing nov el categories. T ables I and II summarize the statistics of class-specific neurons. SSL achiev es a class co verage ratio close to 100% for most tasks, whereas SL covers substantially fewer classes (e.g., 49% in VC1). SSL also yields twice as many mean class- specific neurons compared to SL. Consequently , SSL fosters the emer gence of a comprehensi ve set of class-specific neurons that cover no vel class hierarchies, which likely underpins its robust generalization. In contrast, SL appears to be constrained by its fixed training class definitions, potentially hindering the dev elopment of neurons for unseen task categories and suggesting a fundamental bottleneck in supervised cov erage. C. RQ2: What Do These Neur ons Shar e Acr oss Differ ent Classes? In this section, we in vestigate the degree of sharing across classes and tasks among the neurons identified in SSL in the previous section. Figure 1 sho ws the observations of shared neurons related to gender in speech. For this analysis, classes in VC1 were T ABLE I S T A T IS T I C S O F C LA S S - SP E C I FIC N EU R ON S ( S S L ). S SL AC H I EV E S A C L AS S C OV E R AG E R A T I O C L OS E T O 1 0 0 %, I N DI C A T IN G T H A T C L AS S - S PE C I FIC N E UR ON S S PA N N EA R LY A L L C L A SS E S . Mean class-specific neurons Class coverage ratio CREMA-D 172.0 100% ESC-50 37.9 98% GISE-51 42.3 100% GTZAN 70.2 100% NSynth 98.5 100% Surge 164.9 100% VC1 28.7 100% V oxForge 199.2 100% A verage 101.7 100% T ABLE II S T A T IS T I C S O F C LA S S - SP E C I FIC N EU R ON S ( S L ) . S L C OV E R S S U BS TA NT I A LLY F E W ER C LA S S E S ( E . G . , 4 9 % I N V C 1 ) , I N D I CAT IN G T H A T T H EI R N E U RO N S E XH I B I T L I M I TE D C L A S S - L E V EL C OV ER AG E . Mean class-specific neurons Class coverage ratio CREMA-D 98.7 100% ESC50 24.7 94% GISE-51 23.4 80% GTZAN 48.1 75% NSynth 49.7 100% Surge 81.7 100% VC1 8.4 49% V oxForge 106.7 100% A verage 55.2 87% defined by gender and nationality , whereas those in CREMA- D were defined solely by gender . The values represent the Jaccard coef ficient (intersection ov er union) between each class in VC1 and each class in CREMA-D, indicating the proportion of shared neurons. In this paper , we refer to these values as common neur on ratios . The results sho w that neurons shared across tasks are substantially more numerous in SSL than in SL. In particular, VC1 female classes share neurons primarily with CREMA-D female classes, and a similar pattern is observed for male classes. Although SSL is trained without explicit gender information, the neurons in SSL respond to speech characteristics associated with gender . Figure 2 presents the shared neurons associated with pitch in musical sounds. NSynth and Surge consist of synthetic musical sounds generated using different synthesis methods. For this analysis, nine octa ve-based labels were assigned to each task. In contrast to the gender analysis (Fig. 1), shared neurons associated with pitch are observed ev en in SL. Moreover , in both SSL and SL, shared neurons are more frequently observed at both lower and higher octaves. These results suggest that pitch height is a salient acoustic attribute that characterizes sounds. Figure 3 presents the shared neurons for semantically ov erlapping event classes across ESC-50 and GISE-51 (e.g., “Cough” vs. “coughing” and “Thunder” vs. “thunderstorm”). In contrast to the previous analyses (Fig. 1 and Fig. 2), the F emale Male CREMA -D F emale (AU) F emale (A T) F emale (BR) F emale (CA) F emale (CN) F emale (HR) F emale (DK) F emale (FR) F emale (DE) F emale (G Y) F emale (IN) F emale (IR) F emale (IE) F emale (IL) F emale (IT) F emale (MX) F emale (NL) F emale (NZ) F emale (NO) F emale (PH) F emale (PL) F emale (PT) F emale (RU) F emale (KR) F emale (ES) F emale (LK) F emale (SE) F emale (T T) F emale (UK) F emale (US) Male (AU) Male (CA) Male (CL) Male (CN) Male (HR) Male (DK) Male (DE) Male (IN) Male (IE) Male (IT) Male (MX) Male (NL) Male (NZ) Male (NO) Male (PH) Male (PT) Male (SG) Male (ZA) Male (ES) Male (SD) Male (SE) Male (CH) Male (UK) Male (US) VC1 0.02 0.00 0.02 0.00 0.02 0.00 0.03 0.00 0.02 0.00 0.01 0.00 0.03 0.00 0.02 0.00 0.02 0.00 0.01 0.00 0.03 0.00 0.01 0.01 0.03 0.00 0.02 0.00 0.03 0.00 0.03 0.00 0.02 0.00 0.03 0.00 0.02 0.00 0.03 0.00 0.03 0.00 0.03 0.00 0.03 0.00 0.03 0.01 0.02 0.01 0.03 0.00 0.02 0.00 0.03 0.00 0.03 0.00 0.03 0.00 0.00 0.03 0.00 0.02 0.00 0.01 0.00 0.04 0.00 0.04 0.00 0.01 0.00 0.03 0.00 0.02 0.00 0.02 0.00 0.03 0.00 0.01 0.00 0.03 0.00 0.02 0.00 0.01 0.00 0.01 0.00 0.03 0.00 0.01 0.00 0.01 0.00 0.02 0.00 0.02 0.00 0.03 0.00 0.01 0.00 0.03 0.00 0.02 SSL V iT (M2D) F emale Male CREMA -D 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.01 0.00 0.00 0.00 0.01 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.01 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.01 0.00 0.01 0.00 0.00 0.00 0.00 0.00 0.01 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.01 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 SL V iT 0.000 0.005 0.010 0.015 0.020 0.025 0.030 0.035 0.040 Common neur on ratio Fig. 1. Shared neurons between VC1 and CREMA-D under gender-based class definitions. SSL demonstrates clear cross-task sharing of neurons aligned with gender, whereas SL exhibits negligible sharing. 0 1 2 3 4 5 6 7 8 Sur ge 0 1 2 3 4 5 6 7 8 NSynth 0.33 0.30 0.26 0.16 0.07 0.04 0.05 0.09 0.13 0.33 0.34 0.32 0.21 0.09 0.04 0.05 0.09 0.12 0.21 0.22 0.27 0.23 0.12 0.07 0.06 0.07 0.09 0.08 0.08 0.12 0.17 0.13 0.09 0.06 0.04 0.04 0.04 0.04 0.07 0.11 0.16 0.19 0.12 0.07 0.06 0.02 0.02 0.03 0.05 0.09 0.19 0.24 0.19 0.16 0.09 0.09 0.10 0.09 0.12 0.15 0.27 0.31 0.29 0.15 0.15 0.14 0.11 0.09 0.10 0.21 0.31 0.36 0.18 0.17 0.15 0.12 0.08 0.09 0.17 0.25 0.32 SSL V iT (M2D) 0 1 2 3 4 5 6 7 8 Sur ge 0.15 0.16 0.14 0.07 0.03 0.00 0.00 0.00 0.00 0.13 0.14 0.18 0.11 0.03 0.00 0.00 0.00 0.00 0.09 0.11 0.15 0.13 0.03 0.00 0.00 0.00 0.00 0.03 0.03 0.09 0.14 0.04 0.00 0.00 0.00 0.00 0.00 0.00 0.01 0.02 0.04 0.07 0.02 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.04 0.19 0.14 0.06 0.00 0.00 0.00 0.00 0.00 0.02 0.14 0.24 0.17 0.00 0.00 0.00 0.00 0.00 0.02 0.07 0.18 0.21 0.00 0.00 0.00 0.00 0.00 0.01 0.04 0.12 0.19 SL V iT 0.00 0.05 0.10 0.15 0.20 0.25 0.30 0.35 Common neur on ratio Fig. 2. Common neuron ratios for each octa ve class in NSynth and Surge. Despite differences in synthesis methods and dataset characteristics, octave- specific neurons are consistently observed across both tasks. common neuron ratios are generally lower overall. The sounds within each event class appear to exhibit considerable varia- tion, which may reduce acoustic commonality across datasets. Among these classes, “T oilet flush” and “Laughter” show higher common neuron ratios, suggesting more consistent acoustic patterns across datasets. Con versely , for “T rain” and “Cough”, higher common neuron ratios are observed with acoustically different classes rather than with their semanti- cally ov erlapping classes. For e xample, “T rain” exhibits higher commonality with “W ind, ” likely reflecting the co-occurrence of background wind noise in train recordings. In contrast, “Cough” sho ws higher commonality with “Dog, ” which may clapping coughing wind toilet flush fir eworks train footsteps dog thunderstor m crick ets laughing ESC-50 Clapping Cough W ind T oilet flush F ir eworks T rain W alk and footsteps Dog Thunder Crick et Laughter GISE-51 0.06 0.00 0.00 0.01 0.05 0.00 0.07 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.02 0.00 0.00 0.00 0.12 0.00 0.00 0.07 0.00 0.00 0.03 0.00 0.00 0.03 0.00 0.00 0.00 0.00 0.00 0.09 0.00 0.00 0.47 0.04 0.00 0.02 0.00 0.03 0.03 0.02 0.06 0.00 0.00 0.02 0.24 0.11 0.19 0.00 0.07 0.00 0.00 0.00 0.00 0.17 0.00 0.00 0.14 0.00 0.00 0.00 0.03 0.00 0.09 0.00 0.00 0.02 0.12 0.00 0.25 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.09 0.00 0.00 0.03 0.03 0.00 0.03 0.03 0.04 0.05 0.00 0.00 0.06 0.03 0.00 0.00 0.00 0.03 0.00 0.00 0.00 0.00 0.00 0.00 0.03 0.00 0.00 0.00 0.00 0.01 0.00 0.00 0.00 0.07 0.00 0.00 0.39 SSL V iT (M2D) clapping coughing wind toilet flush fir eworks train footsteps dog thunderstor m crick ets laughing ESC-50 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.12 0.00 0.01 0.00 0.00 0.00 0.06 0.00 0.00 0.12 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.01 0.00 0.22 0.00 0.00 0.00 0.01 0.00 0.00 0.01 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.06 0.00 0.00 0.04 0.00 0.00 0.01 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.06 0.00 0.00 0.00 0.00 0.00 0.08 0.00 0.00 0.04 0.00 0.00 0.18 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.09 0.00 0.00 0.06 0.00 0.01 0.00 0.00 0.00 0.00 0.00 0.00 0.07 SL V iT 0.0 0.1 0.2 0.3 0.4 Common neur on ratio Fig. 3. Common neuron ratios for semantically overlapping event classes across ESC-50 and GISE-51. Compared with Fig. 1 and Fig. 2, the ratios are generally lower . classical jazz pop disco blues country hiphop metal r eggae r ock G TZAN classical jazz pop disco blues country hiphop metal r eggae r ock G TZAN 1.00 0.22 0.03 0.03 0.04 0.09 0.01 0.03 0.02 0.04 0.22 1.00 0.05 0.06 0.16 0.19 0.03 0.06 0.07 0.10 0.03 0.05 1.00 0.43 0.10 0.20 0.42 0.19 0.34 0.23 0.03 0.06 0.43 1.00 0.19 0.23 0.34 0.23 0.46 0.29 0.04 0.16 0.10 0.19 1.00 0.31 0.08 0.14 0.18 0.29 0.09 0.19 0.20 0.23 0.31 1.00 0.14 0.15 0.21 0.44 0.01 0.03 0.42 0.34 0.08 0.14 1.00 0.22 0.34 0.18 0.03 0.06 0.19 0.23 0.14 0.15 0.22 1.00 0.15 0.23 0.02 0.07 0.34 0.46 0.18 0.21 0.34 0.15 1.00 0.29 0.04 0.10 0.23 0.29 0.29 0.44 0.18 0.23 0.29 1.00 SSL V iT (M2D) classical jazz pop disco blues country hiphop metal r eggae r ock G TZAN 1.00 0.04 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.04 1.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 1.00 0.50 0.00 0.00 0.12 0.00 0.00 0.00 0.00 0.00 0.50 1.00 0.00 0.00 0.06 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.12 0.06 0.00 0.00 1.00 0.02 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.02 1.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 SL V iT 0.0 0.2 0.4 0.6 0.8 1.0 Common neur on ratio Fig. 4. Common neuron ratios across genre classes in GTZAN. “Classical” and “jazz” share a relati vely large number of neurons, exhibiting a distinct sharing pattern compared with other genres. indicate acoustic similarity between certain cough sounds and dog vocalizations. Figure 4 sho ws the sharing of neurons across genre classes in GTZAN. In both SSL and SL, “classical” and “jazz” share more neurons than other genre pairs, indicating a distinct pat- tern of neuron sharing. These results suggest that the observed neuron sharing reflects shared acoustic characteristics across these genres. For example, “classical” and “jazz” often exhibit acoustic structures that differ from genres such as “pop, ” where v ocals are a primary component. Such dif ferences may contribute to the observed overlap in neuron acti vations. Figure 5 presents the common neuron ratios across language classes in V oxFor ge. In SSL, higher neuron sharing is observ ed between “de” and “en, ” while “es, ” “fr , ” “it, ” and “ru” also share relativ ely many neurons. Germanic languages such as “de” and “en” are known for vo wel reduction in unstressed syllables, whereas Romance languages such as “fr, ” “it, ” and “es” exhibit comparativ ely less v owel reduction and more sta- ble v owel realizations [18]. The SSL results suggest that such language-family-le vel phonetic differences may be reflected in the shared internal representations. Figure 6 presents the common neuron ratios across emotion classes in CREMA-D. “ ANG” and “HAP” show ele v ated neuron sharing, while relatively higher sharing is also observed among “DIS, ” “FEA, ” “NEU, ” and “SAD. ” This trend is par - tially aligned with an arousal-based or ganization of emotions. In Russell’ s circumplex model of affect [19], “ ANG” and de en es fr it ru V o xF or ge de en es fr it ru V o xF or ge 1.00 0.59 0.38 0.47 0.44 0.44 0.59 1.00 0.37 0.43 0.42 0.40 0.38 0.37 1.00 0.50 0.73 0.67 0.47 0.43 0.50 1.00 0.52 0.52 0.44 0.42 0.73 0.52 1.00 0.68 0.44 0.40 0.67 0.52 0.68 1.00 SSL V iT (M2D) de en es fr it ru V o xF or ge 1.00 0.05 0.07 0.23 0.22 0.01 0.05 1.00 0.13 0.11 0.10 0.23 0.07 0.13 1.00 0.23 0.39 0.17 0.23 0.11 0.23 1.00 0.38 0.14 0.22 0.10 0.39 0.38 1.00 0.09 0.01 0.23 0.17 0.14 0.09 1.00 SL V iT 0.0 0.2 0.4 0.6 0.8 1.0 Common neur on ratio Fig. 5. Common neuron ratios across language classes in V oxForge. SSL results exhibit relatively high neuron sharing within Germanic (“de, ” “en”) and Romance (“es, ” “fr , ” “it”) language families. ANG HAP DIS FEA NEU S AD CREMA -D ANG HAP DIS FEA NEU S AD CREMA -D 1.00 0.48 0.21 0.21 0.26 0.10 0.48 1.00 0.47 0.47 0.52 0.26 0.21 0.47 1.00 0.80 0.70 0.53 0.21 0.47 0.80 1.00 0.64 0.56 0.26 0.52 0.70 0.64 1.00 0.48 0.10 0.26 0.53 0.56 0.48 1.00 SSL V iT (M2D) ANG HAP DIS FEA NEU S AD CREMA -D 1.00 0.11 0.00 0.00 0.01 0.00 0.11 1.00 0.03 0.06 0.01 0.01 0.00 0.03 1.00 0.25 0.33 0.27 0.00 0.06 0.25 1.00 0.11 0.09 0.01 0.01 0.33 0.11 1.00 0.59 0.00 0.01 0.27 0.09 0.59 1.00 SL V iT 0.0 0.2 0.4 0.6 0.8 1.0 Common neur on ratio Fig. 6. Common neuron ratios across emotion classes in CREMA-D. Relativ ely higher neuron sharing is observ ed between “ ANG” and “HAP , ” as well as among “DIS, ” “FEA, ” “NEU, ” and “SAD. ” “HAP” are located in the high-arousal region, whereas “SAD” lies in the low-arousal region. These findings suggest that acoustic cues related to arousal may be encoded in the learned representations. In this section, shared neurons were observed across various tasks and classes, especially with SSL, suggesting that these neurons capture common acoustic characteristics across dif- ferent tasks. Furthermore, sev eral results indicate that certain neurons are sensitiv e to such acoustic similarities. These findings imply that SSL, through learning without explicit su- pervision, captures salient acoustic attributes that may support higher-le vel semantic classification tasks such as audio e vent recognition. D. RQ3: Do Class-specific Neur ons Contribute to Classifica- tion? In this section, we conduct an ablation study to examine whether class-specific neurons contrib ute to the prediction of their corresponding classes. W e examine the effects of de- activ ating class-specific neurons on do wnstream classification performance by setting the outputs of their activ ation functions to zero during inference. Specifically , we focus on GTZAN, targeting the 26 class- specific neurons shared between “classical” and “jazz” (as shown in Fig. 4), and CREMA-D, targeting the 22 neurons shared between “ ANG” and “HAP” (as sho wn in Fig. 6). As classical jazz pop disco blues country hiphop metal r eggae r ock P r edicted label classical jazz pop disco blues country hiphop metal r eggae r ock T rue label 31 0 0 0 0 0 0 0 0 0 0 27 0 0 0 0 0 0 0 0 0 0 22 4 0 0 3 0 0 1 0 0 1 27 0 0 0 0 1 0 0 2 0 1 28 0 0 0 0 0 1 0 1 0 1 24 0 0 0 3 0 0 1 1 0 0 25 0 0 0 0 0 0 0 0 0 0 26 0 1 0 0 1 1 0 1 2 0 21 0 0 0 1 2 2 1 2 5 2 17 Nor mal Confusion Matrix classical jazz pop disco blues country hiphop metal r eggae r ock P r edicted label T rue label 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 -1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 -1 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 Diff (T ar geted Neur ons) classical jazz pop disco blues country hiphop metal r eggae r ock P r edicted label T rue label 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 Diff (R andom Neur ons) Fig. 7. Ablation impact on GTZAN genre classification. Left: Original model. Middle/Right: Deviations after ablating class-specific vs. random neurons. The results indicate that class-specific neurons have a greater functional impact on classification than randomly selected ones. ANG HAP DIS FEA NEU S AD P r edicted label ANG HAP DIS FEA NEU S AD T rue label 223 13 17 4 6 2 23 200 12 11 18 1 36 20 172 8 5 24 10 21 11 176 12 34 3 7 0 0 209 8 0 14 31 45 27 148 Nor mal Confusion Matrix ANG HAP DIS FEA NEU S AD P r edicted label T rue label -4 0 5 -1 0 0 -1 -1 2 0 -1 1 0 -3 3 0 0 0 -1 1 0 -1 0 1 0 0 0 0 0 0 0 -3 0 -4 4 3 Diff (T ar geted Neur ons) ANG HAP DIS FEA NEU S AD P r edicted label T rue label -2 0 3 -1 0 0 0 -3 1 2 0 0 0 -2 0 0 2 0 0 1 0 0 -2 1 0 0 0 0 1 -1 0 -5 2 0 1 2 Diff (R andom Neur ons) Fig. 8. Ablation impact on CREMA-D genre classification. Left: Original model. Middle/Right: Deviations after ablating class-specific vs. random neurons. The results indicate that class-specific neurons have a clearer targeted impact on classification compared to the random baseline. a baseline for comparison, we randomly deactiv ate the same number of neurons. The experimental results confirm that deactiv ating the class- specific neurons af fects class-lev el classification performance. In Fig. 7 (GTZAN), although “classical” and “jazz” achiev e 100% accuracy in the original model, ablating the targeted neurons improves performance for “country” and “pop, ” sug- gesting that reducing an over -reliance on these specific neu- rons mitigated previous misclassifications. In contrast, random ablation had no impact on performance. In Fig. 8 (CREMA-D), deacti vating targeted neurons de- grades the accuracy of “ ANG” and “HAP , ” while other classes show minor fluctuations. In contrast, random ablation leads to smaller, scattered impacts across the classes. These results suggest that the identified class-specific neurons contrib ute to the representation of their associated classes. In summary , these observations validate our LAPE-based approach for identifying neurons and confirm that these class- specific neurons play a functional role in classification. I V . C O N C L U S I O N This paper inv estigated how general-purpose audio SSL models generalize to pre viously unseen tasks through the lens of mechanistic interpretability . W e showed that SSL neurons provide near-complete coverage of the classes defined in div erse unseen tasks and that these neurons hav e measurable effects on the classification performance of the classes to which they responded. Notably , shared neuronal responses emerged for speech attributes such as gender , language family , and arousal-based emotional structure, as well as for the mu- sical attribute of pitch octa ve classes, while neurons sensiti ve to acoustic similarity appeared to contribute to classes, such as music genres. Our findings provide a neuron-level, mechanistic under- standing of the generalization capability of general-purpose audio models, opening new directions for principled adv ances in the de velopment of audio foundation models. R E F E R E N C E S [1] Y . Gong, C.-I. Lai, Y .-A. Chung, and J. Glass, “SSAST: Self-supervised audio spectrogram transformer, ” in Proc. AAAI , v ol. 36, No. 10, 2022, pp. 10 699–10 709. [2] D. Niizumi, D. T akeuchi, Y . Ohishi, N. Harada, and K. Kashino, “Masked modeling duo: T owards a universal audio pre-training frame- work, ” IEEE/A CM T ransactions on Audio, Speech, and Language Pro- cessing , vol. 32, pp. 2391–2406, 2024. [3] X. Li, N. Shao, and X. Li, “Self-supervised audio teacher-student transformer for both clip-lev el and frame-lev el tasks, ” IEEE/ACM T rans. Audio, Speech, Language Pr ocess. , vol. 32, pp. 1336–1351, 2024. [4] L. Sharkey , B. Chughtai et al. , “Open problems in mechanistic inter - pretability , ” T rans. Mach. Learn. Res. , 2025. [5] T . T ang, W . Luo, H. Huang, D. Zhang, X. W ang, X. Zhao, F . W ei, and J.-R. W en, “Language-specific neurons: The key to multilingual capabilities in lar ge language models, ” in Proc. ACL , 2024, pp. 5701– 5715. [6] D. Namazifard and L. G. Poech, “Isolating culture neurons in multilin- gual large language models, ” in Pr oc. IJCNLP-AACL , 2025, pp. 768– 785. [7] A. Dosovitskiy , L. Beyer , A. Kolesnik ov , D. W eissenborn, X. Zhai, T . Unterthiner , M. Dehghani, M. Minderer, G. Heigold, S. Gelly , J. Uszkoreit, and N. Houlsby , “ An image is worth 16x16 words: T ransformers for image recognition at scale, ” in Pr oc. ICLR , 2021. [8] J. F . Gemmeke, D. P . W . Ellis, D. Freedman, A. Jansen, W . Lawrence, R. C. Moore, M. Plakal, and M. Ritter , “Audio Set: An ontology and human-labeled dataset for audio ev ents, ” in Pr oc. ICASSP , 2017, pp. 776–780. [9] K. J. Piczak, “ESC: Dataset for environmental sound classification, ” in Pr oc. ACM-MM , 2015, pp. 1015–1018. [10] S. Y adav and M. E. Foster , “GISE-51: A scalable isolated sound ev ents dataset, ” 2021. [11] K. MacLean, “V oxFor ge, ” 2018. [Online]. A vailable: https://www . voxfor ge.org/ [12] A. Nagrani, J. S. Chung, and A. Zisserman, “V oxCeleb: A Large-Scale Speaker Identification Dataset, ” in Pr oc. Interspeech , 2017, pp. 2616– 2620. [13] H. Cao, D. G. Cooper , M. K. Keutmann, R. C. Gur , A. Nenkov a, and R. V erma, “CREMA-D: Crowd-sourced emotional multimodal actors dataset, ” IEEE T ransactions on Af fective Computing , v ol. 5, no. 4, pp. 377–390, 2014. [14] G. Tzanetakis and P . Cook, “Musical genre classification of audio signals, ” IEEE T ransactions on Speech and A udio Processing , vol. 10, no. 5, pp. 293–302, 2002. [15] B. L. Sturm, “The GTZAN dataset: Its contents, its faults, their effects on ev aluation, and its future use, ” arXiv preprint , 2013. [16] J. T urian, J. Shier , G. Tzanetakis, K. McNally , and M. Henry , “One billion audio sounds from GPU-enabled modular synthesis, ” in Pr oc. D AFx , 2021, pp. 222–229. [17] J. Engel, C. Resnick, A. Roberts, S. Dieleman, M. Norouzi, D. Eck, and K. Simonyan, “Neural audio synthesis of musical notes with Wa veNet autoencoders, ” in Proc. ICML , vol. 70, 2017, pp. 1068–1077. [18] J. Fletcher, “The prosody of speech: T iming and rhythm, ” in The Handbook of Phonetic Sciences , 2nd ed., W . J. Hardcastle, J. Laver , and F . E. Gibbon, Eds. Oxford: Wile y-Blackwell, 2010, pp. 523–602. [19] J. A. Russell, M. Lewicka, and T . Niit, “ A cross-cultural study of a circumplex model of affect, ” Journal of P ersonality and Social Psychology , vol. 57, no. 5, pp. 848–856, 1989.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment