오디오 SSL 모델의 뉴런은 무엇을 듣는가
본 논문은 일반 목적 오디오 자기지도 학습(SSL) 모델을 뉴런 수준에서 해석한다. 클래스별 활성화 엔트로피(AAPE)를 이용해 특정 소리 클래스에 선택적으로 반응하는 뉴런을 식별하고, SSL 모델이 다양한 다운스트림 과제에서 거의 모든 클래스를 포괄하는 클래스‑특이 뉴런을 형성함을 보였다. 또한 성별·언어·음높이와 같은 음향·언어적 특성에 공통적으로 반응하는 뉴런이 존재하고, 이러한 뉴런을 억제·강화했을 때 분류 성능에 실질적인 영향을 미치는…
저자: Takao Kawamura, Daisuke Niizumi, Nobutaka Ono
본 논문은 최근 급부상하고 있는 일반 목적 오디오 자기지도 학습(SSL) 모델의 내부 메커니즘을 뉴런 수준에서 규명하고자 한다. 기존 연구들은 SSL 모델이 다양한 다운스트림 과제에서 뛰어난 성능을 보인다는 사실만을 제시했으며, 그 내부 표현이 어떻게 일반화를 가능하게 하는지는 명확히 밝혀지지 않았다. 저자들은 이러한 공백을 메커니즘 해석(framework of mechanistic interpretability) 관점에서 접근한다.
먼저, 클래스‑특이 뉴런을 정의하기 위해 Audio Activation Probability Entropy(AAPE)라는 새로운 지표를 제안한다. AAPE는 각 뉴런이 특정 클래스에 대해 양성 활성화를 보이는 비율을 기반으로 엔트로피를 계산한다. 엔트로피가 낮을수록 해당 뉴런은 제한된 클래스에만 반응한다는 의미이며, 이를 ‘클래스‑특이’라 부른다. 저자들은 (1) 활성도가 충분히 낮은 하위 5% 뉴런을 제외하고, (2) 전체 뉴런 중 AAPE가 가장 낮은 r%를 선택, (3) 최종적으로 클래스별 활성화 확률이 상위 5%에 해당하는 뉴런을 타깃 뉴런으로 지정하는 3단계 필터링 절차를 적용한다.
실험에 사용된 모델은 Vision Transformer(ViT) 기반 인코더이며, 두 가지 학습 방식으로 비교한다. 첫 번째는 Masked Modeling Duo(M2D) 방식을 이용한 SSL 사전학습 모델이며, 두 번째는 AudioSet으로 완전 감독 학습된 SL 모델이다. 두 모델 모두 12개의 Transformer 블록, 각 블록당 3072개의 뉴런(768×4)으로 구성된다.
다양한 도메인의 8개 데이터셋(ESC‑50, GISE‑51, VoxForge, VoxCeleb1, CREMA‑D, GTZAN, Surge, NSynth)을 활용해 ‘보지 않은’ 과제에서도 클래스‑특이 뉴런이 존재하는지를 검증한다. 결과는 SSL 모델이 거의 모든 클래스에 대해 최소 하나 이상의 특이 뉴런을 보유하고 있음을 보여준다. 예를 들어 ESC‑50, GISE‑51, GTZAN, NSynth 등에서는 클래스 커버리지 비율이 98~100%에 달했으며, 평균 클래스‑특이 뉴런 수는 101.7개에 이른다. 반면 SL 모델은 동일 과제에서 커버리지가 현저히 낮아, 특히 VoxCeleb1에서는 49%에 불과했다. 이는 SSL이 사전학습 단계에서 다양한 음향 패턴을 포괄적으로 학습함으로써 내부 표현의 다양성을 확보한다는 점을 시사한다.
다음으로, 식별된 뉴런들의 공유 정도를 분석한다. 성별 구분이 가능한 음성 데이터(VoxCeleb1, CREMA‑D)에서는 남성·여성 각각에 대응하는 뉴런이 서로 겹치는 비율이 높았다. 특히 SSL 모델은 성별 라벨이 사전학습에 포함되지 않았음에도, 음성의 스펙트럼·포먼트 차이를 반영하는 뉴런을 자동으로 형성했다. 반면 SL 모델은 이러한 공유가 거의 관찰되지 않았다.
음악 분야에서는 옥타브(피치) 별 뉴런이 두 데이터셋(Surge, NSynth) 전반에 걸쳐 일관되게 나타났다. 특히 저음·고음 영역에서 공유 뉴런 비율이 높았으며, 이는 피치가 가장 기본적인 음향 특성임을 뒷받침한다.
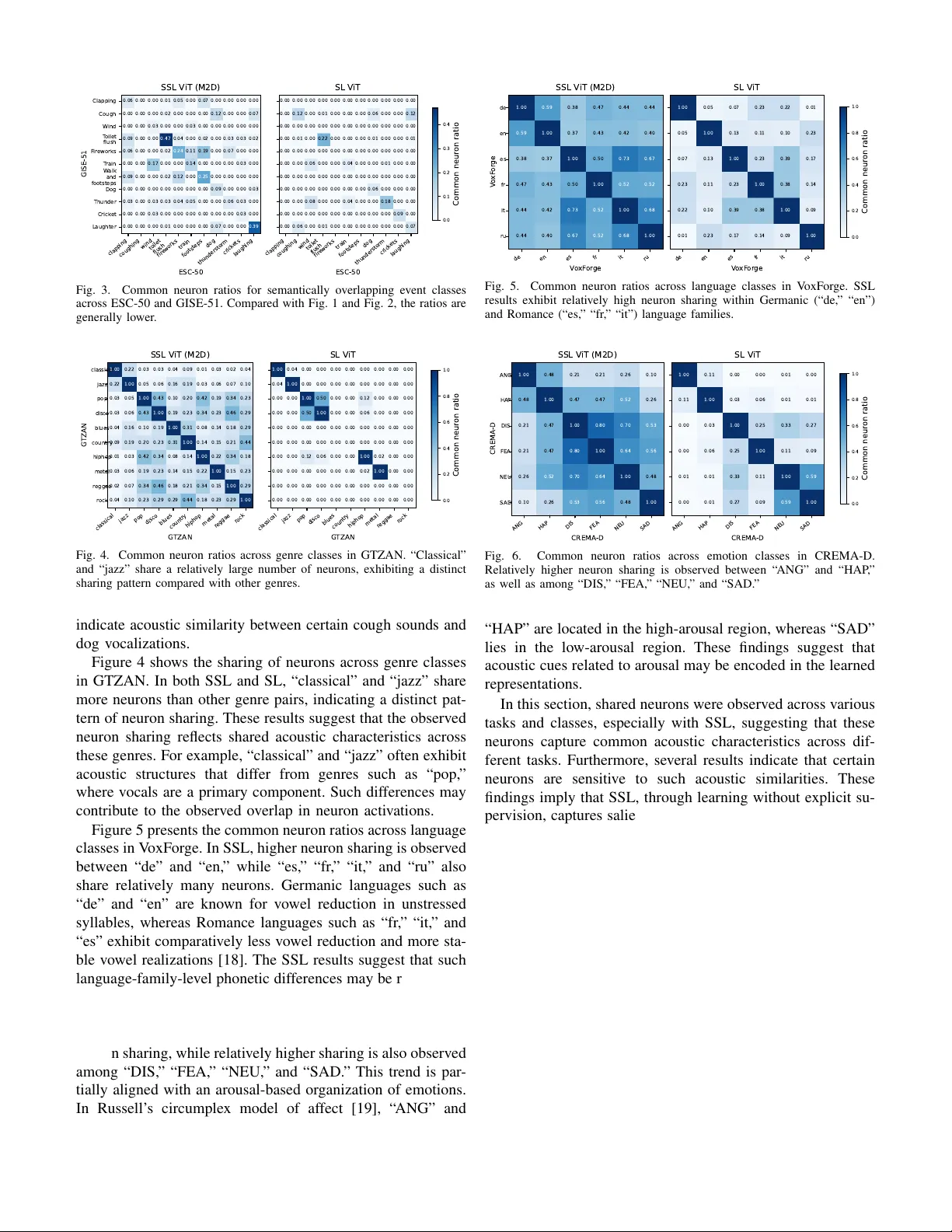
또한, 의미적으로 겹치는 이벤트 클래스(예: “Cough” vs “coughing”, “Thunder” vs “thunderstorm”)에 대해서는 공유 뉴런 비율이 상대적으로 낮았다. 이는 같은 의미를 갖는 소리라도 녹음 환경·배경 잡음 등에 따라 음향적 변이가 커서, 클래스‑특이 뉴런이 서로 다른 음향 패턴을 포착하기 때문으로 해석된다.
마지막으로, 식별된 클래스‑특이 뉴런을 ‘스티어링’(활성도 조절)하여 분류 성능에 미치는 영향을 평가한다. SSL 모델에서 특정 뉴런을 억제하면 해당 클래스에 대한 정확도가 감소하고, 반대로 활성화를 강화하면 성능이 향상되는 현상이 관찰되었다. 이는 뉴런 수준의 조작이 실제 모델 예측에 직접적인 영향을 미친다는 강력한 증거이며, 모델 디버깅 및 특화된 다운스트림 파인튜닝에 활용될 가능성을 열어준다.
종합하면, 이 논문은 (1) SSL 기반 일반 목적 오디오 모델이 풍부하고 포괄적인 클래스‑특이 뉴런을 자동으로 학습한다, (2) 이러한 뉴런은 성별·언어·피치 등 음향·언어적 공통 특성을 여러 과제에 걸쳐 공유한다, (3) 뉴런 수준의 조작이 다운스트림 성능에 실질적인 영향을 미친다, 라는 세 가지 핵심 인사이트를 제공한다. 이는 향후 오디오 foundation model의 설계, 해석, 그리고 인간 청각 메커니즘과의 비교 연구에 중요한 토대를 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기