Resp-Agent: An Agent-Based System for Multimodal Respiratory Sound Generation and Disease Diagnosis
Deep learning-based respiratory auscultation is currently hindered by two fundamental challenges: (i) inherent information loss, as converting signals into spectrograms discards transient acoustic events and clinical context; (ii) limited data availa…
Authors: Pengfei Zhang, Tianxin Xie, Minghao Yang
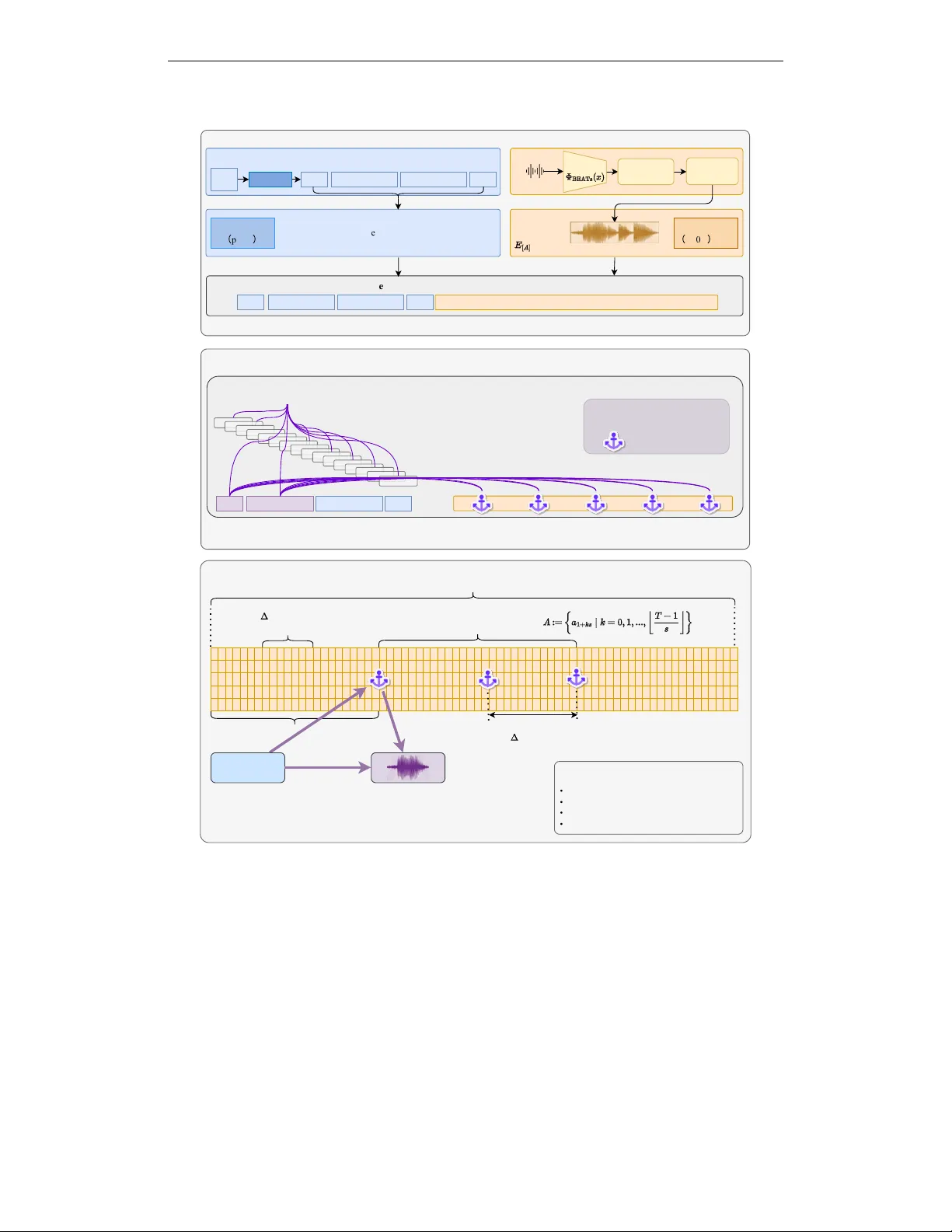
Published as a conference paper at ICLR 2026 R E S P - A G E N T : A N A G E N T - B A S E D S Y S T E M F O R M U L T I - M O D A L R E S P I R A T O RY S O U N D G E N E R A T I O N A N D D I S - E A S E D I A G N O S I S Pengfei Zhang, T ianxin Xie, Minghao Y ang, Li Liu ∗ The Hong K ong Univ ersity of Science and T echnology (Guangzhou) A B S T R A C T Deep learning-based respiratory auscultation is currently hindered by two fun- damental challenges: (i) inherent information loss, as con verting signals into spectrograms discards transient acoustic ev ents and clinical context; (ii) limited data av ailability , exacerbated by se vere class imbalance. T o bridge these gaps, we present Resp-Agent , an autonomous multimodal system orchestrated by a nov el Activ e Adversarial Curriculum Agent (Thinker-A 2 CA). Unlike static pipelines, Thinker -A 2 CA serves as a central controller that actively identifies diagnostic weaknesses and schedules tar geted synthesis in a closed loop. T o address the representation gap, we introduce a Modality-W eaving Diagnoser that weav es EHR data with audio tokens via Strategic Global Attention and sparse audio anchors, capturing both long-range clinical context and millisecond-lev el transients. T o address the data gap, we design a Flo w Matching Generator that adapts a text- only Large Language Model (LLM) via modality injection, decoupling patho- logical content from acoustic style to synthesize hard-to-diagnose samples. As a foundation for these efforts, we introduce Resp-229k , a benchmark corpus of 229k recordings paired with LLM-distilled clinical narratives. Extensive exper- iments demonstrate that Resp-Agent consistently outperforms prior approaches across div erse ev aluation settings, improving diagnostic robustness under data scarcity and long-tailed class imbalance. Our code and data are av ailable at https://github.com/zpforlove/Resp- Agent . 1 I N T R O D U C T I O N Respiratory auscultation is a fundamental component of clinical diagnosis, providing critical acoustic evidence for assessing pulmonary health (Heitmann et al., 2023; Bohadana et al., 2014). Accurate and automated analysis of respiratory sounds holds substantial clinical value for the early screening, diagnosis, and monitoring of respiratory diseases (Rocha et al., 2019). Although deep learning has driv en significant progress in this domain, e xisting methods remain constrained by fundamental limitations that hinder both performance and practical deployment (Huang et al., 2023; Xia et al., 2022; Coppock et al., 2024). The first challenge is a unimodal representational bottleneck. Audio models often con vert signals into mel-spectrograms for image-style CNNs (Bae et al., 2023; He et al., 2024), which discards phase and blurs fine temporal structure, obscuring transient ev ents such as crackles(Paliwal et al., 2011). Conv ersely , text-only models capture electronic health record (EHR) context b ut lack objecti ve acoustic e vidence, limiting discrimination between conditions with similar narratives but distinct auscultatory patterns. W ithout deep multimodal fusion, performance and reliability saturate. The second limitation is the lack of large, well-annotated multimodal datasets. Most public respiratory- sound corpora are small, cover only a few conditions, and lack systematic curation (Zhang et al., 2024a). Even when auxiliary metadata such as demographics and symptoms is av ailable, existing approaches rely on basic fusion techniques and task-specific designs, limiting the dev elopment of generalized multimodal models (Zhang et al., 2024b). ∗ Corresponding author: avrillliu@hkust-gz.edu.cn 1 Published as a conference paper at ICLR 2026 A third challenge lies in the disconnect between analysis and generation. Current research is heavily ske wed to wards diagnostic tasks like classification and detection (Huang et al., 2023; Xia et al., 2022), leaving the potential of generativ e modeling largely unexplored (Kim et al., 2023). The ability to synthesize respiratory sounds with specific pathological characteristics would not only support medical education, data augmentation, and interpretability research but also serv e as a stringent test of a system’ s multimodal understanding. Howe ver , no existing frame work unifies analysis and synthesis within a single coherent system (Zhang et al., 2024a;b). T o systematically address these challenges, we introduce Resp-Agent, a multimodal agent framework inspired by the design philosophy of intelligent agents. Resp-Agent decomposes complex functional- ity into specialized modules coordinated by a central controller that plans and schedules tasks. This design enables unified processing of respiratory sounds for both diagnostic analysis and generati ve synthesis, advancing the state of multimodal respiratory intelligence. In summary , we propose Resp-Agent , a closed-loop framew ork that turns passiv e analysis into generation ↔ diagnosis co-design. The contributions of our method are: 1) Resp-229k: A large-scale, clinically contextualized benchmark. R E S P - 2 2 9 K contains approximately 408 hours and 229k respiratory recordings spanning 16 diagnostic categories. W e pair each sample with a clinical narrativ e synthesized from EHR records using LLMs and refined for accuracy . The benchmark features source-disjoint splits to rigorously test model generalization, while the correspondence between text and audio supports multimodal modeling and transparent verification. 2) Controllable Synthesis. W e design a Generator that augments a compact LLM to synthesize high-fidelity respiratory audio. Disease semantics are conditioned on text, while acoustic style is captured by BEA Ts(Chen et al., 2023) tokens. A conditional flow-matching decoder reconstructs wa veforms with high fidelity . This design is instantiated as R E S P - M L L M , to the best of our kno wledge, the first multimodal large language model trained with aligned text–audio supervision for controllable respiratory sound synthesis. Flow matching ensures stable, phase-aware reconstruction of transient e vents, and the BEA Ts-deri ved style tokens, which model device and timbre f actors, are essential for clinical realism. 3) Robust Diagnosis. W e introduce a Diagnoser based on modality weaving , which interleav es audio embeddings with text. A strategically designed global-attention mechanism enables the model to jointly condition on fused text while parsing the acoustic stream at ≈ 80ms resolution, capturing fleeting ev ents that characterize respiratory sounds. By le veraging a Longformer(Beltagy et al., 2020) backbone to capture long-range dependencies, our approach yields superior performance and improved generalization across v arying domains. 2 R E L AT E D W O R K Respiratory Sound Classification (RSC) has largely relied on audio-only pipelines trained on small, single-source datasets, which limits out-of-domain generalization. Standard approaches utilize pre- trained backbones lik e P ANNs (K ong et al., 2020) and AST (Gong et al., 2021) to mitigate data scarcity . The OPERA benchmark has begun to close the data gap via domain-specific pretrain- ing (Zhang et al., 2024a); howe ver , most systems remain constrained by single-modality supervision and in-distrib ution e valuation. Our w ork departs from this paradigm in two ke y ways. (i) Multimodal fusion. W e weave EHR-style textual tok ens and acoustic tokens within a long-context T ransformer . Unlike RespLLM (Zhang et al., 2024b), which feeds concatenated modality tok ens through dense full attention, we introduce Str ate gic Global Attention with sparse audio anchors, drawing on ideas from ef ficient Transformers (Beltagy et al., 2020; Zaheer et al., 2020) to route clinical context to transient acoustic ev ents at sub-quadratic cost. W e ev aluate on source-disjoint splits to stress-test generalization under realistic distrib ution shifts (K oh et al., 2021) and label imbalance (Johnson & Khoshgoftaar, 2019). (ii) T argeted augmentation. Recent generati ve models enable high-fidelity audio synthesis (Borsos et al., 2023; Lipman et al., 2022; Liu et al., 2022; Peebles & Xie, 2023), but e xisting augmentation strategies are typically untargeted, relying on generic perturbations such as SpecAugment (Park et al., 2019) or unconditional generation (Kim et al., 2023). W e introduce Resp-Agent , a closed-loop system in which an LLM-based Thinker-A 2 CA diagnoses model failures and requests condition-controlled synthesis from a flo w-matched generator , turning augmentation into a precise instrument for adversarial edge-case creation and distrib ution balancing. 2 Published as a conference paper at ICLR 2026 [DIAGNOSIS] (T ext) Reference Audio (BEA T s features) Synthetic Respiratory Sound W ave (Label-T rue, High-Fidelity) Bias Subsequent Actions (e.g., T argeted Synthesis) [DESCRIPTION] (EHR Summary) BEA T s Frame Features (10s Audio, Aligned) Feedback to Thinker (Close Loop) Controllable Synthesis Style-Prefix T okens [DIAGNOSIS] [AUDIO_0]...[AUDIO_K-1] Discrete Acoustic Units DiT -style Flow-Matching Decoder (Mel-spectrograms) Neural V ocoder Audio Paths, EHR T able, T arget Class Semantic Intent Parsing Thinker- (DeepSeek-V3.2-Exp) Recycle Rationales, Error Profiles, Calibrated Confidence (Structured Arguments) Deterministic I/O Schemas & Concise Logs Plan-Execute T ool Routing Clinical Inference Modality W eaving (Early T oken-Level Fusion) Longformer Encoder Audio Anchors Sparse Global Attention [CLS] [DESCRIPTION] ... Calibrated Confidence Score Anchor-Level Attribution Map ... (a) (b) (c) (Modality Injection) Resp-MLLM Figure 1: Overvie w of Resp-Agent. The framework functions as a closed-loop system composed of three interacting modules: (a) Thinker: A compute-aware planner (Thinker -A 2 CA) that parses semantic intents and routes tasks to other agents based on recycled error profiles and calibrated confidence. (b) Generator: A synthesis module utilizing modality injection to condition the Resp- MLLM on both textual diagnosis and reference acoustic style, decoding discrete units via conditional flow matching. (c) Diagnoser: A clinical inference module employing modality weaving to fuse EHR summaries with audio features early in the network, lev eraging sparse global attention for rob ust cross-modal reasoning. 3 R E S P - 2 2 9 K : A L A R G E - S C A L E , M U LT I - S O U R C E , C R O S S - D O M A I N B E N C H M A R K W e introduce Resp-229k to address the scarcity of multimodal supervision and the lack of robust cross-domain e valuation in respiratory sound analysis. Unlike existing datasets, R E S P - 2 2 9 K provides paired audio with standardized clinical summaries, con verting di verse metadata into a format suitable for multimodal modeling. W e also establish a strict out-of-domain ev aluation protocol to explicitly test model generalization. The dataset comprises 229,101 quality-controlled samples sourced from fiv e public databases, categorized into 16 classes (15 conditions and 1 control). A core contrib ution is the textual supervision. Instead of full electronic health records, each clip is paired with a standardized clinical summary , a concise paragraph synthesized from av ailable source fields. Summaries adapt to source co verage: when demographics and symptoms exist, they are included; when only auscultation e vents and acquisition conte xt are present, the summary focuses on those. Concretely , we retain two typical regimes as a modeling challenge: technical/event-dri ven summaries (auscultatory ev ents, site, sensor/filter , phases, wheezes/crackles) and clinically enriched summaries (demographics, smoking status, comorbidities, symptoms, past medical history). W e programmatically con vert heterogeneous CSV/TXT/JSON fields and filename-derived codes into standardized summaries using DeepSeek-R1-Distill-Qwen-7B (Guo et al., 2025) as a lightweight data-to-text engine. The model does not interpret audio; instead, it consolidates existing metadata into a schema-grounded paragraph with a consistent style across sources, enabling reproducible, lo w-cost annotation refreshes while preserving diagnostically relev ant heterogeneity . T o mitigate hallucination and governance risks, all LLM-generated clinical summaries under go a second-stage audit that combines rule-based consistency checks, critique from a stronger reasoning model acting as a verifier , and sampling-based human re view . This process ensures that only summaries that pass the pipeline, or are re written and rev erified after being flagged, are retained in R E S P - 2 2 9 K . A detailed description of the auditing pipeline is provided in Appendix E. T o standardize comparisons, we specify two tasks and metrics: (i) multimodal disease classification, reporting accuracy and macro-F1; and (ii) controllable audio generation conditioned on disease semantics, reporting objectiv e acoustic similarity and clinical-event fidelity . W e report both in- domain v alidation results and strictly out-of-domain test results. For e valuation, R E S P - 2 2 9 K enforces a strict cross-domain split: training/v alidation on ICBHI, SPRSound, and UK CO VID-19, and testing 3 Published as a conference paper at ICLR 2026 T able 1: R E S P - 2 2 9 K ov erview: split statistics and source datasets. The dataset identifiers correspond to UK CO VID-19 (Coppock et al., 2024; Budd et al., 2024; Pigoli et al., 2022), ICBHI (Rocha et al., 2017), SPRSound (Zhang et al., 2022), COUGHVID (Orlandic et al., 2021), and KA UH (Fraiwan et al., 2021). (a) Resp-229k split statistics (effective samples) Split #Files Hours Mean (s) Max (s) T rain 196,654 341 6.2 86 V alid 16,931 31 6.6 71 T est 15,516 36 8.4 30 T otal 229,101 408 6.4 86 (b) Source datasets f or the curation of R E S P - 2 2 9 K Name Role Device Sample Rate (kHz) Mean Duration (s) UK CO VID-19 T rain/V alidation Microphone 48 5.9 ICBHI T rain/V alidation Stethoscope 4–44.1 22.2 SPRSound T rain/V alidation Stethoscope 8 11.0 COUGHVID T est Microphone 48 6.9 KA UH T est Stethoscope 4 15.0 exclusi vely on KA UH and COUGHVID (unseen during training). This design assesses robustness across institutions, sensors, and collection protocols. Concise split statistics and per-dataset metadata appear in T able 1. A complete specification of the 16-class label space (15 disease categories plus a healthy control group) is provided in Appendix A. 4 R E S P - A G E N T : A N L L M - O R C H E S T R A T E D L O O P F O R U N I FI E D D I A G N O S I S A N D C O N T R O L L A B L E S Y N T H E S I S The overall architecture of Resp-Agent is depicted in Figure 1. Gi ven the paired text–audio supervision and the cross-domain split established by R E S P - 2 2 9 K , Resp-Agent is designed as a centrally planned, compute-aware multi-agent system that integrates standalone audio and NLP modules into a closed loop. A compute-ef ficient planner , Thinker -A 2 CA (DeepSeek-V3.2-Exp; (Guo et al., 2025)), performs semantic intent parsing and plan–execute tool routing using structured arguments (audio paths, EHR tables, and target classes), enforcing deterministic I/O schemas and emitting concise, instrumented logs. Beyond dispatch, the controller reuses model rationales, error profiles, and calibrated confidence to bias subsequent actions (e.g., tar geted synthesis for failure modes), thereby coupling data generation and diagnosis under tight accelerator budgets without compromising coverage or reproducibility . The Thinker coordinates two task-specific agents detailed belo w: a Generator (Section 4.1) that synthesizes controllable respiratory audio via modality injection and conditional flow matching, and a Diagnoser (Section 4.2) that fuses clinical narrativ es with audio tokens through modality weaving and strategic global attention. 4 . 1 G E N E R A T O R : D I S C R E T E - U N I T P L A N N I N G A N D C F M R E C O N S T R U C T I O N W e target controllable respiratory-sound synthesis that disentangles pathological content (what to generate) from timbral style (ho w it should sound). The Generator follo ws a tw o-stage design. Stage 1 retools a unimodal L L M into a multimodal unit generator conditioned on diagnosis semantics and a reference style, as illustrated in Figure 2. Stage 2 reconstructs high-fidelity audio from the predicted discrete units via conditional flow matching (C F M ) and a neural vocoder . 4 . 1 . 1 S T Y L E - C O N D I T I O N E D U N I T M O D E L I N G W I T H A R E T O O L E D L L M W e retool a light text-only backbone (Qwen3-0.6B-Base(Y ang et al., 2025)) into a truly multimodal unit generator and denote the trained model Resp-MLLM. The con version relies on modality injection with a trainable style projector while leaving the language backbone architecture intact. Let Z ∈ R T × D be framewise B E A T S features from a 10 s, 16 kHz reference ( T =496 ). W e compress Z into K style 4 Published as a conference paper at ICLR 2026 Inputs: Disentangled Content & Style [DIAGNOSIS] Pneumonia Prompt Construction Reference Audio (10s,16kHz) BEA TS Encoder (Frozen) T emporal Pooling (Pool) Style Projector (Trainable 2-layer MLP) Features Descriptors Style Embeddings Input Embedding Layer (Modality Injection) [AUDIO_0]...[AUDIO_k-1] ... Disease Semantics (d) [DIAGNOSIS] Diagnosis Semantics Resp-MLLM Core (T rainable Qwen3-0.6B-Base Backbone) Transformer Transformer Causal Masking Orange = T rainable Component Blue = Data, T okens Purple = Embeddings Output Head (Softmax over BEA T s Codebook size V) Content Style Leak-free Conditioning (T raining Mechanism) t - 1 ... ... Random Mask Sampling (M ≈ 10%) Prevents peeking at oracle (t - 1) token when predicting Predicted Discrete Acoustic Units ... EHR [END] Figure 2: Detailed architecture of Resp-MLLM (Stage 1 of the Generator). The model functions as a style-conditioned multimodal unit generator . T op: A modality injection mechanism fuses textual diagnosis semantics with acoustic style embeddings (projected from temporally pooled BEA Ts features) to prompt the Qwen3-0.6B-Base backbone. Bottom: A leak-free conditioning strategy is employed during training: random mask sampling ( M ≈ 10% ) pre vents the model from peeking at oracle tokens, ensuring rob ust autoregressi ve prediction of discrete acoustic units. descriptors and map them to the L L M hidden space via a two-layer MLP: P = P o ol K ( Z ) ∈ R K × D , E style = St ylePro j( P ) ∈ R K × H . (1) In the input, we reserve K placeholders [ AUDIO 0 ] , . . . , [ AUDIO K − 1 ] and replace their embeddings with rows of E style . The mix ed prompt [ DIAGNOSIS ] d | {z } content [ AUDIO 0 ] · · · [ AUDIO K − 1 ] | {z } style binds disease semantics d to a reference timbre without modifying the language stack. Resp-MLLM then autoregressi vely predicts a sequence of discrete acoustic units y = ( y 1 , . . . , y L ) from a B E A T S 5 Published as a conference paper at ICLR 2026 codebook of size V : L Resp = − L X i =1 log p Resp y i | y Class-Prior > No-Synth across all held-out sources confirms that the planner’ s benefits are robust across sources rather than split-specific. Experiment 6 v alidates that the Generator can independently control pathological content and acoustic style. In the style-swap setting, we fix the pathology to a rare label (“Bronchiolitis”) and v ary the style reference across four cross-domain clips. The Generator achie ves high style similarity (Style-Sim 0.89–0.92), while the held-out Diagnoser preserves the target pathology with a Pathology-Acc of 97.5–98.1% and a Fr ´ echet Audio Distance (F AD) of 1.14–1.21. In the complementary content- swap setting, a single “Control Group” style reference is held fixed while synthesizing four different pathologies. Style-Sim remains stable at ≈ 0 . 93 –0.94, and Pathology-Acc remains high (94.8–97.2%) with F AD in the range of 1.17–1.22. T ogether , these tests provide quantitati ve evidence that the two-stage Generator disentangles semantic content from recording style and can reliably instantiate rare pathology–style combinations. Experiment 7 ablates the Diagnoser architecture on T est-CD by v arying text quality , fusion strategy , and attention anchors. T able 4 shows that replacing raw metadata with LLM-rendered EHR yields modest but consistent gains (Accuracy 0.835 → 0.849 and Macro-F1 0.195 → 0.212 when anchors and modality weaving are present). A simple late-fusion baseline with LLM EHR reaches an Accurac y of 0.790 and a Macro-F1 of 0.160. Modality weaving without anchors improves Macro-F1 to 0.189 b ut destabilizes the architecture, reducing Accurac y to 0.650. Reintroducing strate gic audio anchors in the full Resp-Agent Diagnoser restores stability and further improves performance to an Accuracy of 0.849 and a Macro-F1 of 0.212. These results confirm that the gains arise from deliberate co-design: high-quality clinical text, tight modality weaving, and anchor-based global attention are all necessary to fully exploit the synthetic data deli vered by the Thinker -guided Generator . 6 C O N C L U S I O N W e present Resp-Agent, a centrally orchestrated, closed-loop multi-agent framew ork that unifies controllable, high-fidelity respiratory sound synthesis with multimodal disease diagnosis. Our framew ork is underpinned by R E S P - 2 2 9 K , a large-scale cross-domain benchmark with a strict ev aluation protocol. A curriculum-aware Think er-A 2 CA planner decomposes diagnostic goals and allocates them between a controllable multimodal Generator and a modality-weaving Diagnoser , turning pre viously isolated modules into an analyze–synthesize loop. W e en vision clinician-in-the- loop deployments in which Resp-Agent synthesizes edge-case exemplars and provides audio-informed decision support at the point of care, advancing trustw orthy medical-audio AI. 10 Published as a conference paper at ICLR 2026 E T H I C S S T A T E M E N T All authors ha ve read and adhere to the ICLR Code of Ethics. This w ork relies exclusi vely on publicly av ailable, pre viously de - identified data; no ne w human - subject data were collected, and no Personally Identifiable Information (PII) or Protected Health Information (PHI) was accessed or processed at any stage. Below , we detail the prov enance, licensing, and intended usage of the data to ensure transparency and reproducibility . Data Pr ovenance and Privacy . The R E S P - 2 2 9 K benchmark is curated from multiple public respiratory - sound corpora, including ICBHI, SPRSound, UK CO VID - 19, COUGHVID, KA UH, and HF Lung V1. Each recording retains explicit provenance, including the source dataset identifier, device metadata (e.g., an electronic stethoscope vs. a microphone), and sampling rate. T o ensure rigorous e valuation, we enforce a strict cross - institution and cross - device protocol: the training and validation sets are deriv ed exclusiv ely from ICBHI, SPRSound, and UK CO VID - 19, whereas the test set consists solely of unseen recordings from KA UH and COUGHVID. All source data were de-identified by their original custodians prior to public release. Licensing and Compliance. W e strictly adhere to the original licenses and terms of use for all constituent datasets. Specifically , our usage complies with the Open Go vernment Licence v3.0 (UK CO VID - 19), Creativ e Commons Attrib ution 4.0 International (CC BY 4.0) (COUGHVID, HF Lung V1, KA UH, SPRSound), and CC0 Public Domain Dedication (ICBHI). Our deriv ed code, models, and synthetic examples will be released under open - source terms that are compatible with these licenses to facilitate reproducible research while preserving data pri vac y . Intended Use and Safety . The Resp - Agent system and the R E S P - 2 2 9 K benchmark are dev eloped strictly for research purposes. This system is not a certified medical de vice and has not undergone regulatory approv al for clinical use. It must not be deplo yed to mak e diagnostic decisions or influence patient care without appropriate clinical validation and re gulatory ov ersight. R E P R O D U C I B I L I T Y S T A T E M E N T W e ha ve tak en extensi ve steps to facilitate reproducibility . All source code, including training and inference scripts and configuration files with e xact commands to reproduce reported results, is publicly av ailable at https://github.com/zpforlove/Resp- Agent . The curated R E S P - 2 2 9 K dataset is released at https://huggingface.co/datasets/AustinZhang/ resp- agent- dataset . Trained model checkpoints are hosted at https://huggingface. co/AustinZhang/resp- agent- models . Architectural and algorithmic details are specified in the main text, while complete hyperparameters, optimizer settings, and training schedules are consolidated in the appendix. R E F E R E N C E S Sangmin Bae, June-W oo Kim, W on-Y ang Cho, Hyerim Baek, Soyoun Son, Byungjo Lee, Changwan Ha, K yongpil T ae, Sungnyun Kim, and Seyoung Y un. Patch-mix contrastiv e learning with audio spectrogram transformer on respiratory sound classification. In 24th International Speech Com- munication Association, Interspeech 2023 , pp. 5436–5440. International Speech Communication Association, 2023. Iz Beltagy , Matthew E Peters, and Arman Cohan. Longformer: The long-document transformer . arXiv pr eprint arXiv:2004.05150 , 2020. Abraham Bohadana, Gabriel Izbicki, and Stev e S Kraman. Fundamentals of lung auscultation. New England Journal of Medicine , 370(8):744–751, 2014. Zal ´ an Borsos, Rapha ¨ el Marinier , Damien V incent, Eugene Kharitonov , Olivier Pietquin, Matt Sharifi, Dominik Roblek, Olivier T eboul, David Grangier , Marco T agliasacchi, et al. Audiolm: a language modeling approach to audio generation. IEEE/A CM transactions on audio, speech, and languag e pr ocessing , 31:2523–2533, 2023. 11 Published as a conference paper at ICLR 2026 Jobie Budd, Kieran Baker , Emma Karoune, Harry Coppock, Selina Patel, Richard P ayne, Ana T endero Canadas, Alexander T itcomb, David Hurley , Sabrina Egglestone, et al. A large-scale and PCR-referenced vocal audio dataset for CO VID-19. Scientific data , 11(1):700, 2024. Y i Chang, Zhao Ren, Thanh T am Nguyen, W olfgang Nejdl, and Bj ¨ orn W Schuller . Example-based e x- planations with adversarial attacks for respiratory sound analysis. arXiv pr eprint arXiv:2203.16141 , 2022. Sanyuan Chen, Y u W u, Chengyi W ang, Shujie Liu, Daniel T ompkins, Zhuo Chen, W anxiang Che, Xiangzhan Y u, and Furu W ei. BEA Ts: audio pre-training with acoustic tokenizers. In Pr oceedings of the 40th International Confer ence on Machine Learning , pp. 5178–5193, 2023. Harry Coppock, George Nicholson, Iv an Kiskin, V asiliki K outra, Kieran Baker , Jobie Budd, Richard Payne, Emma Karoune, Da vid Hurley , Alexander T itcomb, et al. Audio-based ai classifiers sho w no evidence of improv ed covid-19 screening over simple symptoms checkers. Natur e Machine Intelligence , 6(2):229–242, 2024. Jia Deng, W ei Dong, Richard Socher , Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern r ecognition , pp. 248–255. Ieee, 2009. Jacob Devlin, Ming-W ei Chang, Kenton Lee, and Kristina T outano va. Bert: Pre-training of deep bidirectional transformers for language understanding. In Pr oceedings of the 2019 confer ence of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short paper s) , pp. 4171–4186, 2019. Gaoyang Dong, Y ufei Shen, Jianhong W ang, Mingli Zhang, Ping Sun, and Minghui Zhang. Respira- tory sounds classification by fusing the time-domain and 2d spectral features. Biomedical Signal Pr ocessing and Contr ol , 107:107790, 2025. Zach Ev ans, Julian D Parker , CJ Carr, Zack Zuk owski, Josiah T aylor, and Jordi Pons. Stable audio open. In ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Pr ocessing (ICASSP) , pp. 1–5. IEEE, 2025. Mohammad Fraiwan, Luay Fraiwan, Basheer Khassa wneh, and Ali Ibnian. A dataset of lung sounds recorded from the chest wall using an electronic stethoscope. Data in Brief , 35:106913, 2021. Siddhartha Gairola, Francis T om, Nipun Kwatra, and Mohit Jain. Respirenet: A deep neural network for accurately detecting abnormal lung sounds in limited data setting. In 2021 43rd Annual International Confer ence of the IEEE Engineering in Medicine & Biology Society (EMBC) , pp. 527–530. IEEE, 2021. Jort F Gemmeke, Daniel PW Ellis, Dylan Freedman, Aren Jansen, W ade Lawrence, R Channing Moore, Manoj Plakal, and Marvin Ritter . Audio set: An ontology and human-labeled dataset for audio e vents. In 2017 IEEE international conference on acoustics, speech and signal pr ocessing (ICASSP) , pp. 776–780. IEEE, 2017. Y uan Gong, Y u-An Chung, and James Glass. AST: Audio spectrogram transformer . arXiv pr eprint arXiv:2104.01778 , 2021. Anmol Gulati, James Qin, Chung-Cheng Chiu, Niki P armar , Y u Zhang, Jiahui Y u, W ei Han, Shibo W ang, Zhengdong Zhang, Y onghui W u, et al. Conformer: Conv olution-augmented transformer for speech recognition. arXiv pr eprint arXiv:2005.08100 , 2020. Daya Guo, Dejian Y ang, Haowei Zhang, Junxiao Song, Peiyi W ang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incenti vizing reasoning capability in llms via reinforcement learning. arXiv pr eprint arXiv:2501.12948 , 2025. W entao He, Y uchen Y an, Jianfeng Ren, Ruibin Bai, and Xudong Jiang. Multi-vie w spectrogram trans- former for respiratory sound classification. In ICASSP 2024-2024 IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) , pp. 8626–8630. IEEE, 2024. 12 Published as a conference paper at ICLR 2026 Julien Heitmann, Alban Glangetas, Jonathan Doenz, Juliane Dervaux, Deeksha M Shama, Daniel Hin- jos Garcia, Mohamed Rida Benissa, A ymeric Cantais, Alexandre Perez, Daniel M ¨ uller , et al. Deepbreath—automated detection of respiratory pathology from lung auscultation in 572 pediatric outpatients across 5 countries. NPJ digital medicine , 6(1):104, 2023. Fu-Shun Hsu, Shang-Ran Huang, Chien-W en Huang, Chao-Jung Huang, Y uan-Ren Cheng, Chun- Chieh Chen, Jack Hsiao, Chung-W ei Chen, Li-Chin Chen, Y en-Chun Lai, et al. Benchmarking of eight recurrent neural network v ariants for breath phase and adventitious sound detection on a self-dev eloped open-access lung sound database—hf lung v1. PLoS One , 16(7):e0254134, 2021. Dong-Min Huang, Jia Huang, K un Qiao, Nan-Shan Zhong, Hong-Zhou Lu, and W en-Jin W ang. Deep learning-based lung sound analysis for intelligent stethoscope. Military Medical Researc h , 10(1): 44, 2023. Justin M Johnson and T aghi M Khoshgoftaar . Surve y on deep learning with class imbalance. J ournal of big data , 6(1):27, 2019. June-W oo Kim, Chihyeon Y oon, Miika T oikkanen, Sangmin Bae, and Ho-Y oung Jung. Adver- sarial fine-tuning using generated respiratory sound to address class imbalance. arXiv pr eprint arXiv:2311.06480 , 2023. June-W oo Kim, Sangmin Bae, W on-Y ang Cho, Byungjo Lee, and Ho-Y oung Jung. Stethoscope- guided supervised contrasti ve learning for cross-domain adaptation on respirat ory sound classifi- cation. In ICASSP 2024-2024 IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) , pp. 1431–1435. IEEE, 2024a. June-W oo Kim, Miika T oikkanen, Sangmin Bae, Minseok Kim, and Ho-Y oung Jung. Repaugment: Input-agnostic representation-level augmentation for respiratory sound classification. In 2024 46th Annual International Confer ence of the IEEE Engineering in Medicine and Biology Society (EMBC) , pp. 1–6. IEEE, 2024b. June-W oo Kim, Miika T oikkanen, Y era Choi, Seoung-Eun Moon, and Ho-Y oung Jung. BTS: Bridging text and sound modalities for metadata-aided respiratory sound classification. In Pr oc. Interspeec h 2024 , pp. 1690–1694, 2024c. Pang W ei K oh, Shiori Sagaw a, Henrik Marklund, Sang Michael Xie, Marvin Zhang, Akshay Bal- subramani, W eihua Hu, Michihiro Y asunaga, Richard Lanas Phillips, Irena Gao, et al. W ilds: A benchmark of in-the-wild distribution shifts. In International confer ence on machine learning , pp. 5637–5664. PMLR, 2021. Qiuqiang Kong, Y in Cao, Turab Iqbal, Y uxuan W ang, W enwu W ang, and Mark D. Plumbley . P ANNs: Large-scale pretrained audio neural networks for audio pattern recognition. IEEE/ACM T r ansactions on Audio, Speech, and Langua ge Pr ocessing , 28:2880–2894, 2020. Chae Y oung Lee, Anoop T offy , Gue Jun Jung, and W oo-Jin Han. Conditional wa veg an. arXiv pr eprint arXiv:1809.10636 , 2018. Conglong Li, Zhe wei Y ao, Xiaoxia W u, Minjia Zhang, Connor Holmes, Cheng Li, and Y uxiong He. Deepspeed data efficiency: Improving deep learning model quality and training efficiency via ef ficient data sampling and routing. In Pr oceedings of the AAAI Confer ence on Artificial Intelligence , v olume 38, pp. 18490–18498, 2024. Tsung-Y i Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Doll ´ ar . Focal loss for dense object detection. In Pr oceedings of the IEEE international confer ence on computer vision , pp. 2980–2988, 2017. Y aron Lipman, Ricky T . Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flo w matching for generativ e modeling. arXiv pr eprint arXiv:2210.02747 , 2022. Haohe Liu, Y i Y uan, Xubo Liu, Xinhao Mei, Qiuqiang Kong, Qiao Tian, Y uping W ang, W enwu W ang, Y uxuan W ang, and Mark D Plumbley . Audioldm 2: Learning holistic audio generation with self-supervised pretraining. IEEE/A CM T ransactions on A udio, Speech, and Language Pr ocessing , 32:2871–2883, 2024. 13 Published as a conference paper at ICLR 2026 Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow . arXiv preprint , 2022. Y inhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy , Mik e Lewis, Luke Zettlemoyer , and V eselin Stoyano v . Roberta: A rob ustly optimized bert pretraining approach. arXiv pr eprint arXiv:1907.11692 , 2019. Y i Ma, Xinzi Xu, and Y ongfu Li. Lungrn+ nl: An improved adv entitious lung sound classification using non-local block resnet neural network with mixup data augmentation. In Interspeech , pp. 2902–2906, 2020. Ilyass Moummad and Nicolas Farrugia. Pretraining respiratory sound representations using metadata and contrasti ve learning. In 2023 IEEE W orkshop on Applications of Signal Pr ocessing to A udio and Acoustics (W ASP AA) , pp. 1–5. IEEE, 2023. T ruc Nguyen and Franz Pernkopf. Lung sound classification using co-tuning and stochastic normal- ization. IEEE T ransactions on Biomedical Engineering , 69(9):2872–2882, 2022. Lara Orlandic, T omas T eijeiro, and Da vid Atienza. The COUGHVID cro wdsourcing dataset, a corpus for the study of large-scale cough analysis algorithms. Scientific Data , 8(1):156, 2021. Kuldip Paliwal, Kamil W ´ ojcicki, and Benjamin Shannon. The importance of phase in speech enhancement. speec h communication , 53(4):465–494, 2011. Daniel S Park, W illiam Chan, Y u Zhang, Chung-Cheng Chiu, Barret Zoph, Ekin D Cubuk, and Quoc V Le. Specaugment: A simple data augmentation method for automatic speech recognition. arXiv pr eprint arXiv:1904.08779 , 2019. W illiam Peebles and Saining Xie. Scalable diffusion models with transformers. In Pr oceedings of the IEEE/CVF International Confer ence on Computer V ision (ICCV) , pp. 4195–4205, 2023. Lam Pham, Dat Ngo, Khoa Tran, T ruong Hoang, Alexander Schindler , and Ian McLoughlin. An ensemble of deep learning frame works for predicting respiratory anomalies. In 2022 44th annual international confer ence of the IEEE engineering in medicine & biology society (EMBC) , pp. 4595–4598. IEEE, 2022. Davide Pigoli, Kieran Baker, Jobie Budd, Lorraine Butler , Harry Coppock, Sabrina Egglestone, Ste ven G Gilmour , Chris Holmes, Da vid Hurley , Radka Jersak ov a, et al. Statistical design and anal- ysis for robust machine learning: a case study from CO VID-19. arXiv pr eprint arXiv:2212.08571 , 2022. Alec Radford, Jong W ook Kim, T ao Xu, Gre g Brockman, Christine McLea vey , and Ilya Sutske ver . Robust speech recognition via large-scale weak supervision. In International confer ence on machine learning , pp. 28492–28518. PMLR, 2023. Zhao Ren, Thanh T am Nguyen, and W olfgang Nejdl. Prototype learning for interpretable respiratory sound analysis. In ICASSP 2022-2022 IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) , pp. 9087–9091. IEEE, 2022. BM Rocha, Dimitris Filos, Lea Mendes, Ioannis V ogiatzis, Eleni Perantoni, Ev angelos Kaimakamis, P Natsiav as, Ana Oliveira, C J ´ acome, A Marques, et al. A respiratory sound database for the dev elopment of automated classification. In International confer ence on biomedical and health informatics , pp. 33–37. Springer , 2017. Bruno M Rocha, Dimitris Filos, Lu ´ ıs Mendes, Gorkem Serbes, Sezer Ulukaya, Y asemin P Kahya, Nik ˇ sa Jako vljevic, T atjana L T urukalo, Ioannis M V ogiatzis, Eleni Perantoni, et al. An open access database for the evaluation of respiratory sound classification algorithms. Physiological measur ement , 40(3):035001, 2019. Hubert Siuzdak. V ocos: Closing the gap between time-domain and fourier-based neural vocoders for high-quality audio synthesis. arXiv pr eprint arXiv:2306.00814 , 2023. 14 Published as a conference paper at ICLR 2026 Jianhong W ang, Gao yang Dong, Y ufei Shen, Minghui Zhang, and Ping Sun. Lightweight hierarchical transformer combining patch-random and positional encoding for respiratory sound classification. In 2024 9th International Confer ence on Signal and Image Pr ocessing (ICSIP) , pp. 580–584. IEEE, 2024. Zijie W ang and Zhao W ang. A domain transfer based data augmentation method for automated respiratory classification. In ICASSP 2022-2022 IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) , pp. 9017–9021. IEEE, 2022. Y usong W u, Ke Chen, T ian yu Zhang, Y uchen Hui, T aylor Ber g-Kirkpatrick, and Shlomo Dubnov . Large-scale contrasti ve language-audio pretraining with feature fusion and keyw ord-to-caption augmentation. In ICASSP 2023-2023 IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) , pp. 1–5. IEEE, 2023. T ong Xia, Jing Han, and Cecilia Mascolo. Exploring machine learning for audio-based respiratory condition screening: A concise revie w of databases, methods, and open issues. Experimental Biology and Medicine , 247(22):2053–2061, 2022. An Y ang, Anfeng Li, Baosong Y ang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Y u, Chang Gao, Chengen Huang, Chenxu Lv , et al. Qwen3 technical report. arXiv pr eprint arXiv:2505.09388 , 2025. Zijiang Y ang, Shuo Liu, Meishu Song, Emilia Parada-Cabaleiro, and Bj ¨ orn W . Schuller . Adventitious Respiratory Classification Using Attentiv e Residual Neural Networks. In Interspeech 2020 , pp. 2912–2916, 2020. doi: 10.21437/Interspeech.2020- 2790. Manzil Zaheer , Guru Guruganesh, Kumar A vina va Dube y , Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ra vula, Qifan W ang, Li Y ang, et al. Big bird: T ransformers for longer sequences. Advances in neur al information pr ocessing systems , 33:17283–17297, 2020. Qing Zhang, Jing Zhang, Jiajun Y uan, Huajie Huang, Y uhang Zhang, Baoqin Zhang, Gaomei Lv , Shuzhu Lin, Na W ang, Xin Liu, et al. SPRSound: Open-source SJTU paediatric respiratory sound database. IEEE T ransactions on Biomedical Cir cuits and Systems , 16(5):867–881, 2022. Y uwei Zhang, T ong Xia, Jing Han, Y u W u, Georgios Rizos, Y ang Liu, Mohammed Mosuily , J Ch, and Cecilia Mascolo. T owards open respiratory acoustic foundation models: Pretraining and benchmarking. Advances in Neur al Information Pr ocessing Systems , 37:27024–27055, 2024a. Y uwei Zhang, T ong Xia, Aaqib Saeed, and Cecilia Mascolo. Respllm: Unifying audio and text with multimodal llms for generalized respiratory health prediction. arXiv pr eprint arXiv:2410.05361 , 2024b. 15 Published as a conference paper at ICLR 2026 T able 5: Unified 16-class taxonomy and sample distribution for R E S P - 2 2 9 K (raw N = 238 , 074 ). The counts highlight the sev ere long-tail imbalance. Class name (unified) T otal count Control Group 156,527 CO VID-19 77,994 Pneumonia 1,909 COPD 820 Asthma 324 Bronchitis 188 Bronchiectasis 103 Hemoptysis 65 Other respiratory diseases 49 UR TI 42 Bronchiolitis 18 Pulmonary hemosiderosis 13 Chronic cough 11 Airway foreign body 6 Kawasaki disease 3 LR TI 2 T otal 238,074 A L A B E L S P A C E T axonomy Note. The raw R E S P - 2 2 9 K corpus is constructed by aggreg ating heterogeneous public respiratory-sound datasets and inheriting their original diagnostic labels. Across sources, this yields an initial 20-class label space, including se veral synonymous or o verly fine-grained categories (e.g., se verity-specific pneumonia labels). The raw corpus contains 238,074 clips; after discarding corrupted or too-short recordings, 229,101 quality-controlled clips remain and are used for all main-paper experiments. T o enhance clinical coherence and facilitate a more rob ust analysis of label imbalance, we program- matically consolidate the original 20-class label space into a clinically unified 16-class taxonomy . The unification map is applied once at preprocessing time before any dataset splitting, ensuring that each recording is assigned a unique, consistent diagnosis across training, v alidation, and test splits. Concretely , the mapping is defined as: • Bronchiectasis: all samples labeled “Bronchiectasia” are relabeled as “Bronchiectasis”. • UR TI: all samples labeled “ Acute upper respiratory infection” are relabeled as “UR TI”. • Pneumonia: all se verity-specific pneumonia labels (e.g., “Pneumonia (non-severe)”, “Pneu- monia (sev ere)”, “Pneumonia (unspecified)”) are relabeled to the parent class “Pneumonia”. After applying this unification, a full recount of the 238,074 raw recordings yields the class distribution summarized in T able 5. The resulting label space comprises 15 disease categories and one healthy control group: Airway foreign body , Asthma, Br onchiectasis, Bronc hiolitis, Br onchitis, COPD (Chr onic Obstructive Pulmonary Disease), CO VID-19, Chr onic cough, Hemoptysis, Kawasaki disease, LRTI (Lower Respiratory T ract Infection), Pneumonia, Pulmonary hemosider osis, URTI (Upper Respiratory T ract Infection), Other r espiratory diseases , and Contr ol Group (health y). This distribution makes explicit the extreme class imbalance present in R E S P - 2 2 9 K , with the ma- jority of diagnostic categories residing in the long tail. This moti vates the generati ve, agent-based rebalancing strategy pursued in the main paper . B S U P P L E M E N TA L R E S U LT S The Dual Challenge: Data Scarcity and T ransient Event Localization. Under the strict cross- domain protocol (KA UH+COUGHVID held out), the ev aluation re veals two fundamental barriers to real-world deplo yment: (i) the representation g ap, where standard encoders fail to localize brief, low-ener gy e vents (e.g., crackles) within the 16-class taxonomy (Appendix A), and (ii) the data gap, 16 Published as a conference paper at ICLR 2026 causing minority underdiagnosis due to se vere label ske w . T o rigorously v alidate our architectural and generativ e solutions, we conducted comprehensiv e ablation studies. B . 1 V A L I DAT I O N O F U N I M O D A L B A S E L I N E S A N D F U S I O N S T R A T E G I E S Robustness of T ext Baselines (Experiment 1). T o preclude the possibility that the multimodal gains of Resp-Agent stem merely from a weak textual baseline, we benchmark ed strong T ransformer-based text encoders against the audio-only Conformer . As detailed in T able 6, while modern T ransformers (BER T(Devlin et al., 2019), RoBER T a(Liu et al., 2019), Longformer-T ext) significantly outperform the LSTM baseline ( 0 . 0401 → 0 . 0813 Macro-F1), they remain substantially inferior to the audio-only Conformer ( 0 . 1935 Macro-F1). This large modality gap confirms that textual clinical summaries alone are insufficient for accurate diagnosis and that our system’ s performance deriv es from effecti ve cross-modal synergy rather than a “stra wman” text baseline. T able 6: Performance comparison of text-only , audio-only , and multimodal models on the cross- domain test set (original, imbalanced data). T e xt-only Transformers impro ve o ver LSTM b ut fail to match audio-only baselines, justifying the need for multimodal fusion. Model Modality Accuracy Macro-F1 LSTM (main paper baseline) T ext 0.0912 0.0401 BER T -base T e xt 0.1420 0.0710 RoBER T a-base T ext 0.1513 0.0742 Longformer-base (te xt-only) T ext 0.1585 0.0813 Conformer (audio-only) Audio 0.7200 0.1935 Resp-Agent Diagnoser (Ours) A udio + T ext 0.8494 0.2118 Efficacy of Modality W eaving and A udio Backbones (Experiment 2). W e further scrutinized the contribution of our fusion architecture versus the choice of audio backbone. T able 7 compares our Modality W eaving against standard late-fusion strategies (concatenation of embeddings and logit voting). Simple fusion yields marginal gains ov er the audio baseline (Macro-F1 ≈ 0 . 20 ). In contrast, our deep wea ving mechanism achiev es superior integration (Macro-F1 0 . 2118 ), confirming that architectural interlea ving is crucial for grounding textual symptoms in acoustic features. Furthermore, replacing the Conformer with a Whisper -Small(Radford et al., 2023) encoder yields only a slight improv ement in the audio-only setting ( 0 . 2010 Macro-F1) and does not close the gap to the full multimodal Diagnoser . This indicates that the system’ s robustness is dri ven primarily by the Modality W eaving and Strate gic Global Attention mechanisms rather than the specific acoustic encoder . T able 7: Ablation on fusion strate gies and audio encoder backbones (original, imbalanced data). Deep Modality W eaving outperforms shallo w fusion methods, and the choice of fusion architecture outweighs marginal gains from changing the audio backbone. Model / Fusion Strategy Modality Accuracy Macro-F1 Conformer (audio-only , main paper) Audio 0.7200 0.1935 Whisper-Small (audio-only) Audio 0.7310 0.2010 Conformer + LSTM (Concat-MLP) Audio + T ext (Late) 0.8012 0.2003 Conformer + BER T (Concat-MLP) Audio + T ext (Late) 0.8124 0.2040 Conformer + BER T (Logit-V oting) Audio + T ext (Late) 0.8043 0.1992 Resp-Agent Diagnoser (Ours) A udio + T ext (W eaving) 0.8494 0.2118 B . 2 A R C H I T E C T U R A L A N D D AT A - S I D E S O L U T I O N S Architectural Solution: Anchored Attention f or T ransient Event Localization. Beyond fusion strategy , the mechanism of attention pro ves critical. Anchor-based global attention on the audio stream directly tar gets transient ev ent localization. Removing anchors degrades performance to 0.6495 Accuracy and 0.1890 Macro-F1 (T able 8), falling belo w e ven the audio-only Conformer . W ith T =496 frames per 10 s, one anchor e very four frames establishes an ≈ 80.6 ms grid (guaranteeing alignment within ≤ 40.3 ms of any transient). This enables attention heads to precisely lock onto 17 Published as a conference paper at ICLR 2026 T able 8: Summary of performance on R E S P - 2 2 9 K under the original (imbalanced) and class-balanced regimes. The substantial gains in the balanced regime highlight the ef ficacy of the Generator , while the multimodal improv ements confirm the value of the Diagnoser’ s architecture. Accuracy Macro-F1 ∆ vs. Conformer (audio-only) Model Original Balanced Original Balanced ∆ Acc (Orig.) ∆ Acc (Bal.) ∆ F1 (Orig.) ∆ F1 (Bal.) LSTM (text-only) 0.0912 0.3020 0.0401 0.2140 -0.6288 -0.4800 -0.1534 -0.3220 Conformer (audio-only) 0.7200 0.7820 0.1935 0.5360 0.0000 0.0000 0.0000 0.0000 Longformer (no anchors) 0.6495 0.7630 0.1890 0.5200 -0.0705 -0.0190 -0.0045 -0.0160 Ours: Resp-Agent (multimodal) 0.8494 0.8870 0.2118 0.5980 +0.1294 +0.1050 +0.0183 +0.0620 Notes. ∆ columns are absolute impro vements ov er the Conformer baseline under the same regime. fleeting wheezes or crackles and align them with clinical te xt. The ablation gap indicates that anchors are not merely additiv e but essential for stable cross-modal reasoning in this domain. Data-Side Solution: Controllable Synthesis to Overcome Scarcity . While architecture solves representation, it cannot inv ent missing data distributions. Balancing classes with our diagnosis- conditioned Generator ele vates the multimodal Longformer to 0.8870 Accuracy and 0.5980 Macro-F1 (T able 8; ∆ F1 +0 . 3862 ). Notably , this gain is structurally consistent, with the audio-only Conformer also impro ving significantly ( 0 . 1935 → 0 . 5360 ) when trained on our synthetic data. Con versely , naiv e, pathology-agnostic perturbations (duplication, pitch/time shift, noise) actively harm cross- domain minority sensiti vity (Conformer 0 . 1935 → 0 . 1688 ; Appendix D.1). Our Generator, which offers superior fidelity and controllability (F AD = 1 . 13 , style cosine = 0 . 92 ; Appendix D.2), outperforms c-W av eGAN(Lee et al., 2018) and AudioLDM 2(Liu et al., 2024) under matched budgets (Appendix D.3), establishing content-awar e balancing as the decisi ve le ver for minority-class resilience. Synthesis: A Data–Model Co-Design for Rob ust Diagnosis. T aken together , the evidence supports a synergistic co-design: (1) Anchored global attention is essential. It furnishes a precise architectural mechanism for transient localization and stable text ↔ audio interaction at clinically meaningful timescales. (2) Controllable synthesis is decisiv e. It supplies diagnostically informati ve examples for rare classes, con verting architectural observ ability into large Macro-F1 gains. (3) System-level synergy is paramount. Orchestrated by the Thinker , model-side anchors ( wher e ) and data-side generation ( what ) act jointly to produce models that are accurate on common cases, sensitiv e to rare ev ents, and robust under domain shift. C E X P E R I M E N TA L S E T U P T asks and Metrics. W e ev aluate respiratory disease classification on the R E S P - 2 2 9 K benchmark under two re gimes: (i) the original, class-imbalanced split, and (ii) a label-balanced v ariant created using our Generator . W e report Accuracy for ov erall performance and Macro-F1 Score to specifically assess performance on minority classes, which is crucial under label ske w . Baselines and Proposed Model. W e compare our multimodal approach against two strong single- modality baselines. All models were trained for 10 epochs using the AdamW optimizer ( β 1 = 0 . 9 , β 2 = 0 . 999 , weight decay of 0.01) and Cross-Entropy Loss. The BiLSTM and Conformer baselines used a batch size of 32 and a Cosine Annealing learning rate scheduler with a peak LR of 1 × 10 − 4 . Our Longformer model was trained using DeepSpeed (Li et al., 2024), with gradient checkpointing enabled, and a OneCycleLR schedule with a maximum learning rate of 1 × 10 − 5 . F or reproducibility , all random seeds were fixed. W e report the performance of the checkpoint with the best validation loss for all models. T e xt-only (BiLSTM). Clinical summaries are tokenized into a vocabulary b uilt with a minimum word frequency of 2. Sequences are padded or truncated to a fix ed length of 100 tokens. The model consists of a 256-dim embedding layer , followed by an 8-layer bidirectional LSTM with a hidden dimension of 512 and a dropout rate of 0.5. The final hidden states are passed to a linear head for classification. Audio-only (Conformer). W e process 10-second, 16 kHz audio clips to compute 128-bin log-mel spectrograms. The STFT uses a 1024-point FFT , a windo w length of 1024 samples, and a hop length 18 Published as a conference paper at ICLR 2026 of 160 samples, covering frequencies from 50 to 8,000 Hz. The spectrograms are then mean-std normalized. Our Conformer architecture comprises an 8-layer encoder with a model dimension of 512 and 8 attention heads, followed by adapti ve a verage pooling for classification. Multimodal (Ours). Our diagnostic agent is based on the longformer-base-4096 model. As described in Section 4.2, we employ “modality wea ving” by replacing 496 placeholder tokens with projected BEA Ts features. T o enhance robustness, we apply token dropout to text ( p = 0 . 2 ) and frame dropout to audio features ( p = 0 . 1 ) during training. Sparse global attention is strategically assigned to the [CLS] and [DESCRIPTION] tokens, as well as to audio anchors sampled with a stride of 4. ICBHI evaluation pr otocol. Split and task. Of ficial ICBHI 60–40% train–test split for four-class RSC ( Normal , Crackle , Wheeze , Both ); metrics are Specificity (Sp), Sensiti vity (Se), and the ICBHI Score = 1 2 (Sp + Se) . F airness. On ICBHI we use plain cross-entropy with no class re weighting or resampling to match prior practice; reported results follow the of ficial metric definitions. Optimization. AdamW with a OneCycleLR schedule peaking at 1 × 10 − 5 ; gradient checkpointing is enabled for memory ef ficiency . Unless otherwise stated, all remaining hyperparameters (token budgets, feature checkpoints, anchor stride) are specified in our released configs and scripts. Pr etraining (summary). W e pretrain on HF Lung V1 and SPRSound with F ocal Loss to emphasize minority pathologies while using an LLM to render heterogeneous metadata into standardized clinical summaries paired with audio. During ICBHI fine-tuning, we remove focal/balancing heuristics for strict apples-to-apples comparisons. D D E T A I L E D E X P E R I M E N T A L V A L I D A T I O N O F T H E G E N E R A T I V E A G E N T This appendix provides a comprehensi ve ev aluation of the Generator component within the Resp- Agent system. W e systematically v alidate its necessity and efficac y through a series of rigorous experiments. Our analysis is structured around two independent “chains of e vidence”: (i) objective similarity metrics that quantify the fidelity and controllability of the generated audio, and (ii) the downstream clinical value of the synthetic data when used to train diagnostic models. W e further include detailed ablation studies to dissect the contributions of k ey architectural choices. All e v alua- tions are conducted under the strict cross-domain protocol defined in the main paper to ensure that our findings reflect true generalization capabilities. D . 1 T H E I N A D E Q UA C Y O F N A I V E A U G M E N TA T I O N F O R C RO S S - D O M A I N G E N E R A L I Z A T I O N Rationale. A foundational premise of our work is that sophisticated generati ve modeling is not merely an alternati ve b ut a necessity for robustly handling the se vere class imbalance in respiratory sound data. T o establish this, we first conducted a counterfactual e xperiment to determine whether naiv e, traditional audio augmentation techniques can improve cross-domain generalization. Such methods include ov er-sampling, pitch/time shifting, and noise injection. Our hypothesis is that these pathology-agnostic transformations distort crucial, low-ener gy diagnostic cues (e.g., the transient structure of crackles and wheezes) and fail to introduce meaningful ne w v ariations, thereby degrading rather than improving performance on unseen data sources. Experimental Design. • Model : W e used a unimodal Conformer (audio-only), identical to the baseline described in the main paper , to isolate the effect of data quality from multimodal interactions. • T raining Sets : W e compared two training regimes: (A) the original, imbalanced training data, and (B) a balanced version created using naive augmentation techniques (simple duplication, pitch shifting within ± 15%, time-stretching between 0.85 × and 1.15 × , and injection of moderately high-SNR noise). • T est Set : Ev aluation was performed exclusi vely on the held-out cross-domain test set (KA UH + COUGHVID) to measure real-world generalization. • Metrics : W e report Accuracy and Macro-F1 Score, with the latter being particularly sensitiv e to performance on rare classes. 19 Published as a conference paper at ICLR 2026 Results and Discussion. As sho wn in T able 9, nai ve augmentation leads to a clear de gradation in performance on the cross-domain test set. Both Accuracy and Macro-F1 score decreased, with the F1-score dropping by 0.0247. This result provides strong empirical e vidence for our central claim: simplistic augmentations, while balancing class counts, actually amplify dataset-specific biases and destroy diagnostically salient audio micro-structures. They teach the model to o verfit to superficial features of the limited minority-class samples, which do not generalize to dif ferent devices, patient populations, or clinical environments. This negati ve result firmly establishes the need for a more intelligent, content-aware data generation strate gy . T able 9: De gradation of Cross-Domain Performance with nai ve Augmentation. The model trained on the balanced set created by traditional augmentation techniques performs worse on unseen test data than the model trained on the original imbalanced set, highlighting the failure of these methods to produce generalizable synthetic data. T raining Data Strategy T est Acc. ∆ Acc F1-Macro ∆ F1 Original Imbalanced 0.7200 – 0.1935 – naiv e Augmentation Balanced 0.6914 -0.0286 0.1688 -0.0247 D . 2 E V I D E N C E C H A I N I : O B J E C T I V E F I D E L I T Y A N D S T Y L E C O N T RO L L A B I L I T Y Rationale. The first pillar of our v alidation assesses the Generator’ s core technical capabilities: can it produce audio that is not only high-fidelity but also accurately conditioned on a specific pathological class (content) while matching the acoustic characteristics of a reference audio (style)? W e compare our proposed Generator against strong, general-purpose audio generation baselines. Experimental Design. W e compare four generativ e models under a unified individualized- reconstruction protocol: • Generative Models. W e benchmark: – c-W aveGAN : a conditional wa veform GAN baseline trained on disease labels only . – A udioLDM 2 (fine-tuned) : a modern text-to-audio dif fusion model adapted to our disease-conditioned prompts. – StableA udio Open (fine-tuned) : a strong contemporary text-to-audio model, fine- tuned on R E S P - 2 2 9 K disease+style pairs using the same diagnosis prompts and reference-style conditioning protocol as our Generator . – Resp-Agent (Ours) : our proposed generator, conditioned on both the disease label (content) and a style embedding extracted from the reference audio. • Metrics. – Cosine Similarity : we measure the cosine similarity between the BEA Ts embedding of the reference audio and the generated audio. Higher v alues indicate better style adherence and individualized timbre control. – Fr ´ echet A udio Distance (F AD) : a distributional perceptual-quality metric between generated and real recordings; lower v alues are better . Results and Discussion. T able 10 presents the results. The fine-tuned StableAudio Open(Evans et al., 2025) baseline substantially improv es over c-W a veGAN and AudioLDM 2, reaching a cosine similarity of 0 . 83 ± 0 . 08 and a F AD of 1 . 54 . Howe ver , our Resp-Agent Generator still achieves the best overall quality , with a cosine similarity of 0 . 92 ± 0 . 04 and the lowest (best) F AD of 1 . 13 . This demonstrates that, e ven against a strong contemporary text-to-audio system, our content/style disentanglement and flow-matching decoder yield more faithful style preservation and higher-fidelity wa veforms. These objectiv e results confirm that Resp-Agent is superior at producing controllable, high-fidelity , and clinically relev ant respiratory audio. D . 3 E V I D E N C E C H A I N I I : D OW N S T R E A M C L I N I C A L V A L U E O F G E N E R A T E D DA T A Rationale. While objecti ve similarity is important, the ultimate measure of a medical data generator is its downstream v alue—its ability to improv e the performance of a clinical diagnostic model. This 20 Published as a conference paper at ICLR 2026 T able 10: Objecti ve e v aluation of individualized audio reconstruction. Our Generator (Resp-Agent) achiev es the highest style adherence (Cosine Similarity) and best perceptual fidelity (F AD), outper- forming strong generativ e baselines including a fine-tuned StableAudio Open model. Generative Model Cosine Similarity ↑ F AD ↓ c-W av eGAN 0 . 61 ± 0 . 15 2.85 AudioLDM 2 (fine-tuned) 0 . 76 ± 0 . 11 1.92 StableAudio Open (fine-tuned) 0 . 83 ± 0 . 08 1.54 Resp-Agent (Ours) 0 . 92 ± 0 . 04 1.13 is the gold standard for e v aluating its utility . W e therefore create class-balanced training sets using each generativ e method and measure the performance of do wnstream classifiers trained on these sets. Experimental Design. • T ask. Multimodal and unimodal respiratory disease classification on the cross-domain T est- CD split (KA UH + COUGHVID), following the strict source-disjoint protocol described in the main paper . • T raining Sets. W e construct six distinct training sets: 1. Original Imbalanced data (control). 2. naive A ugmentation Balanced : a balanced set obtained via classical audio augmentation (time/pitch perturbation, noise injection) without generativ e modeling. 3. c-W aveGAN Balanced : a class-balanced set created by sampling from c-W av eGAN. 4. AudioLDM 2 Balanced : a class-balanced set synthesized by a fine-tuned AudioLDM 2 model. 5. StableAudio Open Balanced : a class-balanced set synthesized by a fine-tuned StableAu- dio Open model using the same diagnosis prompts and style-conditioning protocol as our Generator . 6. Resp-Agent Balanced : a class-balanced set created by our Resp-Agent Generator under the Thinker -A 2 CA planning policy . • Downstr eam Models. F or each of the six datasets above, we train two diagnostic models: (i) a unimodal Conformer (audio-only) and (ii) our multimodal Longformer (audio + te xt) Diagnoser , both configured exactly as in the main paper . This allo ws us to assess the utility of generated audio in both purely acoustic and multimodal settings. Results and Discussion. T ables 11 and 12 show the results for the Longformer and Conformer models, respectiv ely . The findings are consistent and robust: • Across both diagnostic models, the training set balanced by our Resp-Agent Generator yields the highest performance in terms of both Accuracy and, most critically , Macro-F1. Generativ e balancing with c-W aveGAN, AudioLDM 2, and StableAudio Open already produces lar ge gains o ver the imbalanced and nai ve-augmentation baselines, but Resp-Agent consistently provides the strongest impro vements. • For the multimodal Longformer, Resp-Agent’ s synthetic data boosts the Macro-F1 from 0 . 2118 (original imbalanced) to 0 . 5980 , a relati ve increase of +0 . 3862 . The fine-tuned StableAudio Open model achie ves a stronger improv ement than prior generativ e baselines ( +0 . 3502 vs. +0 . 3147 for AudioLDM 2 and +0 . 2402 for c-W aveGAN), yet still trails Resp-Agent. This indicates that higher -fidelity , style-consistent synthesis directly translates into greater clinical utility . • A similar trend is observ ed for the audio-only Conformer . Balancing with StableAudio Open raises the Macro-F1 to 0 . 5050 , outperforming c-W av eGAN and AudioLDM 2, but the Resp-Agent Balanced regime remains best with a Macro-F1 of 0 . 5360 . This sho ws that our Generator not only improves the multimodal Diagnoser b ut also strengthens a purely acoustic classifier , underscoring the generality of the gains. These results provide a po werful second chain of evidence. The synthetic audio from Resp-Agent is not only objecti vely superior in fidelity and controllability , b ut also contains more diagnostically 21 Published as a conference paper at ICLR 2026 salient information than that produced by strong baselines, including a fine-tuned StableAudio Open model. It successfully teaches do wnstream models to recognize rare diseases, dramatically impro ving their clinical utility and fairness on a challenging, unseen test set. T able 11: Performance on the cross-domain T est-CD set using different balanced training sets (multimodal Longformer Diagnoser). Balancing with Resp-Agent yields the lar gest improv ement in Macro-F1 ov er the imbalanced baseline, ev en compared to a strong StableAudio Open baseline. T raining Set Strategy Accuracy F1-Macr o Relative ∆ F1 (vs. Imbalanced) Original Imbalanced 0.8494 0.2118 – naiv e Augmentation Balanced 0.7520 0.1720 − 0 . 0398 c-W av eGAN Balanced 0.8650 0.4520 +0 . 2402 AudioLDM 2 Balanced 0.8781 0.5265 +0 . 3147 StableAudio Open Balanced 0.8830 0.5620 +0 . 3502 Resp-Agent Balanced 0.8870 0.5980 +0 . 3862 T able 12: Performance on the cross-domain T est-CD set using different balanced training sets (unimodal Conformer). StableAudio Open improves substantially o ver older baselines, b ut the Resp-Agent Balanced regime remains strongest. T raining Set Strategy Accuracy F1-Macr o Original Imbalanced 0.7200 0.1935 naiv e Augmentation Balanced 0.6914 0.1688 c-W av eGAN Balanced 0.7420 0.4010 AudioLDM 2 Balanced 0.7560 0.4760 StableAudio Open Balanced 0.7700 0.5050 Resp-Agent Balanced 0.7820 0.5360 D . 4 A B L AT I O N A N D R O B U S T N E S S A NA LY S I S T o ensure our model’ s design is well-justified, we performed tar geted ablation studies on its ke y components. D . 4 . 1 I M PAC T O F S T Y L E P R E FI X L E N G T H ( K ) Rationale. The number of style tok ens, K, is a critical hyperparameter that mediates the trade-of f between style representation capacity and model comple xity . W e in vestigated its impact on both generativ e quality and downstream task performance. Experimental Design. W e varied K in the set { 0 , 2 , 4 , 8 } , where K=0 disables style conditioning entirely . W e ev aluated its effect on the indi vidualized reconstruction task (Similarity/F AD) and the final do wnstream F1-Macro score of the Longformer model trained on data generated with the corresponding K value. Results and Discussion. T able 13 sho ws a clear trend. Increasing K from 0 to 8 monotonically improv es performance across all metrics: style similarity increases, F AD decreases, and the down- stream Macro-F1 score rises. This validates our architectural choice to use style prefix tokens for conditioning and confirms that a richer style representation (K=8) allo ws the Generator to produce more effecti ve training data. T able 13: Ablation Study on the Number of Style T okens (K). Performance impro ves consistently with a larger style prefix, v alidating the ef fectiv eness of our style conditioning mechanism. K (Style T okens) Similarity (Cosine) ↑ F AD ↓ Longformer F1-Macr o ↑ 0 (Style Disabled) 0.80 ± 0.09 1.52 0.542 2 0.85 ± 0.08 1.38 0.563 4 0.87 ± 0.06 1.29 0.577 8 (Default) 0.92 ± 0.04 1.13 0.591 22 Published as a conference paper at ICLR 2026 D . 4 . 2 C H O I C E O F D E C O D E R P A R A D I G M : F L O W - M A T C H I N G V S . D I FF U S I O N Rationale. The second stage of our Generator relies on a decoder to transform discrete tokens into a continuous waveform. W e compared our choice, Conditional Flow-Matching (CFM), against a traditional Denoising Dif fusion Probabilistic Model (DDPM) to v alidate its superiority in both quality and efficienc y . Experimental Design. W e trained tw o decoders with identical conditioning inputs and a fixed inference budget of 32 steps. W e compared their F AD, style similarity , and relati ve inference latency . Results and Discussion. T able 14 demonstrates the adv antages of CFM. At the same step count, CFM achie ves a better F AD (1.13 vs 1.31) and higher similarity (0.92 vs 0.90), indicating superior sample quality and fidelity . Crucially , it achie ves this with approximately 40% less inference time ( ≈ 0 . 6 × latency). This efficienc y is vital for practical applications, enabling faster generation of large-scale balanced datasets. This result confirms that CFM is a more effecti ve and ef ficient choice for the wa veform reconstruction stage in our architecture. T able 14: Comparison of Decoder Paradigms. Conditional Flow-Matching (CFM) surpasses the traditional DDPM in both audio quality (F AD, Similarity) and inference speed. Decoder T ype Steps F AD ↓ Similarity ↑ Inference Latency DDPM 32 1.31 0.90 1.0 × CFM (Ours) 32 1.13 0.92 ≈ 0.6 × E A U D I T A N D V A L I D A T I O N O F L L M - G E N E R A T E D C L I N I C A L S U M M A R I E S T o ensure the reliability of the multimodal frame work, we conducted a comprehensi ve audit of the LLM-generated clinical summaries paired with the R E S P - 2 2 9 K audio. This experiment quantifies the fidelity of the te xt-generation process, verifying that summaries deri ved from heterogeneous metadata are accurate and free from critical hallucinations. Methodology . The clinical summaries were not synthesized from raw audio (audio-to-text) but were generated from e xisting structured metadata (data-to-te xt) using a 7B parameter model (DeepSeek-R1- Distill-Qwen-7B). This schema-grounded approach ensures that summaries strictly rephrase existing fields (e.g., demographics, symptoms, auscultatory findings) rather than in venting new information. T o guarantee high fidelity , we implemented a distinct, two-stage quality assurance (QA) pipeline operating on all 238,074 generated summaries: • Stage 1: Heuristic Pre-scr eening. All descriptions were first passed through a heuris- tic filter to identify suspicious records, specifically flagging empty or truncated text ( EMPTY OR TRUNCATED ), overly long text ( OVERLONG ), or leakage of instructional prompts ( PROMPT LEAK ). • Stage 2: LLM-based QA and A udit. All suspicious records identified in Stage 1, plus a 1% random sample of heuristically “clean” records, were forwarded to a separate validator LLM (DeepSeek-V3.2-Exp). This QA model operated under a strict prompt forbidding the in vention of patient metadata (e.g., age, se x, comorbidities) or the alteration of high-le vel pathology labels. Quantitative Results. The QA pipeline audited the entire set of 238,074 records. The results, detailed in T able 15, confirm the high initial quality of the data-to-text synthesis. The process yielded an ef fectiv e rewrite rate of only 0.7451% , indicating that fe wer than 1 in 130 descriptions required modification. Error T ypology and V erification. A breakdo wn of the flagged issues is presented in T able 16. The analysis re veals that the v ast majority of interventions (1,747 out of 1,774 re writes) were triggered by technical artifacts, specifically OVERLONG OR PROMPT LEAK , rather than substanti ve clinical errors or hallucinations. 23 Published as a conference paper at ICLR 2026 T able 15: Quantitati ve results of the two-stage te xt summarization QA pipeline ( N = 238 , 074 ). The low re write rate confirms the high fidelity of the initial synthesis. Metric V alue T otal records 238,074 Heuristic suspicious ( EMPTY / OVERLONG / PROMPT LEAK ) 3,356 Randomly audited (heuristic-clean samples) 2,300 T otal sent to QA LLM 5,656 LLM kept as OK 3,766 LLM rewrote (suspicious only) 1,774 LLM flagged in random audit (no edit applied) 116 API / parse errors 0 Effective r ewrite rate 0.7451% (1,774 / 238,074) T able 16: Breakdo wn of heuristic flags and LLM-identified error types during the audit. The primary errors were technical artifacts (e.g., prompt leaks) rather than clinical hallucinations. Heuristic Category (Suspicious) LLM-Identified Error T ype (All Audited) T ype Count Error T ype Count OVERLONG 3,031 OK 3,766 PROMPT LEAK 300 OVERLONG OR PROMPT LEAK 1,747 EMPTY OR TRUNCATED 25 OTHER QUALITY ISSUE 113 EMPTY OR TRUNCATED 30 Key Findings. • High Fidelity: The data-to-text generation process is highly reliable, with a rewrite rate below 0.75%. • Dominant Error T ype: The primary issues identified were technical artifacts (e.g., prompt leakage or verbose boilerplate) rather than clinical hallucinations. • Human-in-the-Loop: As a final safeguard, all 1,774 LLM-proposed re writes underwent manual re view by the authors to ensure consistenc y with the original structured metadata and disease labels, prev enting the introduction of ungrounded patient information. F L L M U S A G E S TA T E M E N T W e utilized Large Language Models (LLMs) for three distinct purposes in this work, spanning core system architecture, data curation, and writing assistance: 1. Core System Architectur e (The “Thinker” Agent): As described in Section 4, the central controller of our proposed Resp-Agent frame work, denoted as Thinker - A 2 CA , is instantiated using DeepSeek-V3.2-Exp . This LLM serves as the reasoning core responsible for semantic intent parsing, tool routing, and dynamic planning of the analysis-synthesis loop. 2. Data Curation and V alidation ( R E S P - 2 2 9 K Benchmark): As detailed in Section 3 and Appendix E, we employed LLMs to construct and v alidate the textual component of the dataset: • Data-to-T ext Generation: W e used DeepSeek-R1-Distill-Qwen-7B to synthesize standardized clinical narrativ es from heterogeneous structured metadata. • Quality Assurance: W e used DeepSeek-V3.2-Exp to audit, flag, and correct potential quality issues in the generated summaries. 3. Writing Assistance: W e utilized general-purpose LLMs to assist with polishing grammar , refin- ing stylistic elements, and formatting L A T E X tables. The authors revie wed and retain full responsibility for all text and data presented in this manuscript. 24
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment