RespAgent 멀티모달 호흡음 생성 및 진단 시스템
Resp-Agent는 활성 적대적 커리큘럼 에이전트(Thinker‑A²CA)를 중심으로, 임상 전자건강기록(EHR)과 호흡음 오디오를 전략적 전역 어텐션으로 융합하고, 텍스트‑전용 대형 언어 모델을 모드 주입과 흐름 매칭 디코더로 확장해 고품질 호흡음 합성을 수행한다. 229 k개의 라벨이 달린 데이터셋(Resp‑229k)을 구축하고, 진단‑합성 폐쇄 루프를 통해 데이터 불균형과 정보 손실 문제를 동시에 완화한다.
저자: Pengfei Zhang, Tianxin Xie, Minghao Yang
본 연구는 호흡음 청진이 임상 진단에서 차지하는 중요성을 강조하면서, 현재 딥러닝 기반 자동 청진 시스템이 직면한 두 가지 근본적인 문제—(i) 스펙트로그램 변환으로 인한 순간 음향 이벤트와 임상 맥락 손실, (ii) 데이터 양의 부족과 라벨 불균형—를 동시에 해결하고자 한다. 이를 위해 저자들은 ‘Resp‑Agent’라는 멀티모달 에이전트 프레임워크를 설계했으며, 핵심 제어 모듈인 ‘Thinker‑A²CA(Active Adversarial Curriculum Agent)’를 도입해 진단 모델의 약점을 자동 탐지하고, 목표 지향적인 합성 작업을 폐쇄 루프 형태로 수행한다.
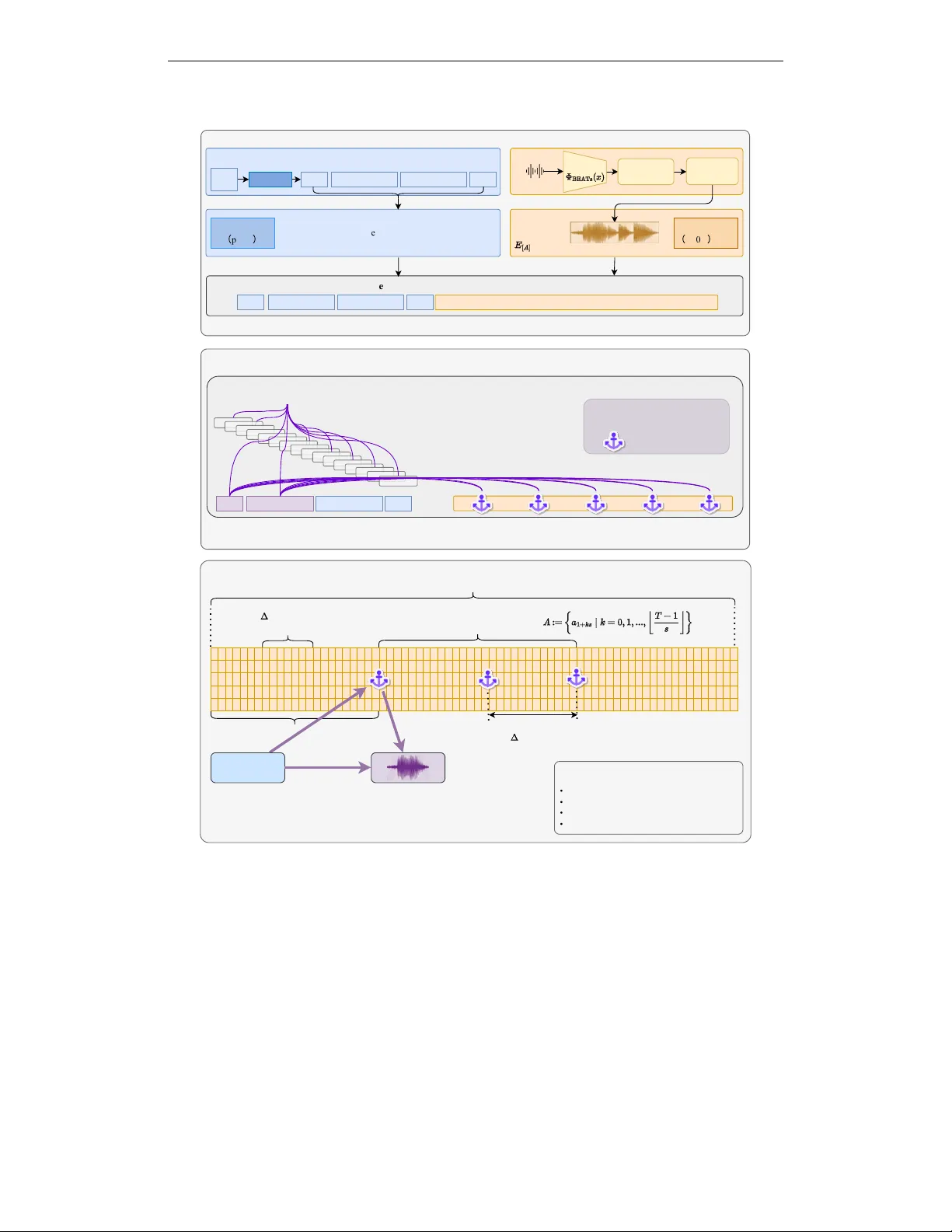
Thinker‑A²CA는 DeepSeek‑V3.2‑Exp 기반의 의미 의도 파싱 엔진을 사용해 입력된 텍스트·오디오·목표 클래스 정보를 구조화된 인수로 변환한다. 모델의 오류 프로파일과 캘리브레이션된 신뢰도 점수를 재활용해, 특정 질환에 대한 낮은 정확도나 높은 불확실성이 감지되면 ‘Generator’에게 해당 질환·특정 청진기 스타일(예: stethoscope, microphone)로 합성된 샘플을 요청한다. 이때 I/O 스키마와 로그 기록이 엄격히 정의돼 재현성과 추적 가능성을 보장한다.
‘Generator’는 두 단계로 구성된다. 첫 번째 단계에서는 텍스트‑전용 대형 언어 모델(Qwen‑3‑0.6B‑Base)을 ‘modality injection’ 방식으로 확장한다. 구체적으로, BEATs(베이스 오디오 토큰) 특징을 10 초 길이의 레퍼런스 오디오에서 추출하고, 이를 두 층 MLP를 통해 스타일 임베딩으로 변환한다. 이 스타일 임베딩은
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기