Focal Loss based Residual Convolutional Neural Network for Speech Emotion Recognition
This paper proposes a Residual Convolutional Neural Network (ResNet) based on speech features and trained under Focal Loss to recognize emotion in speech. Speech features such as Spectrogram and Mel-frequency Cepstral Coefficients (MFCCs) have shown …
Authors: Suraj Tripathi, Abhay Kumar, Abhiram Ramesh
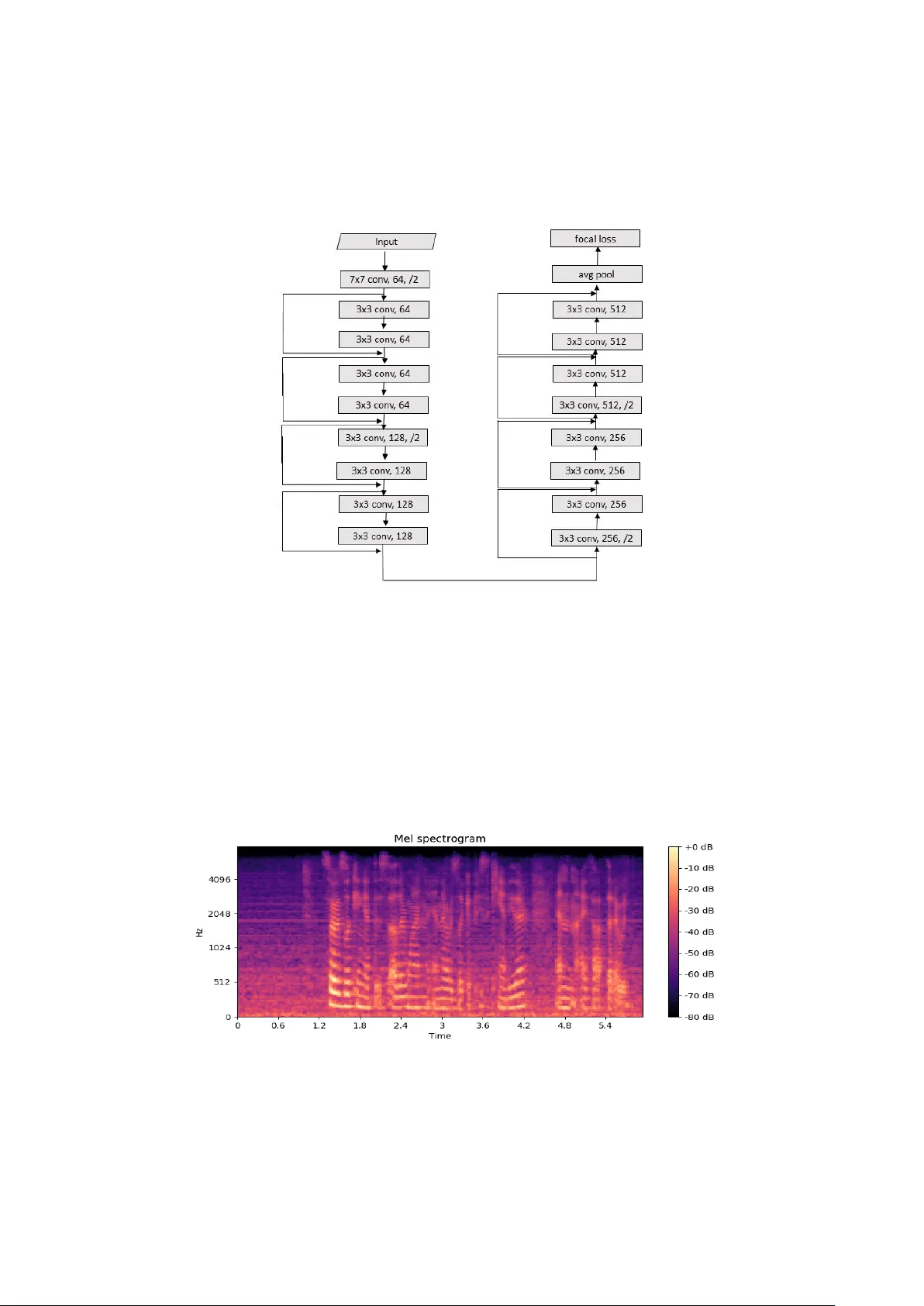
Focal Loss based Residual Convolutional Neural Network for Speech Emotion Recognition Suraj Tripathi 1 , Abhay Kumar 1 *, Abhiram Ramesh 1 *, Chirag Singh 1 * , Promod Yenigalla 1 1 Samsung R&D Institute India – Bangalore suraj.tri@samsung.com, abhay1.kumar@samsung.com, a.ramesh@samsung.com c.singh@samsung.com, promod.y@samsung.com Abstract. This paper proposes a Residual Convolutional Neural Netw ork (ResNet) based on speech features and trained under Focal Loss to recognize emotion in speech. Speech features such as Spectrogram and Mel-frequency Cepstral Coefficie nts (MFCCs) have shown the ability to characterize e motion better than just plain text. Further Fo cal Loss, first used in One-Stage Ob ject Detectors, has shown the ability to focus the training proc ess m ore towards hard-examples and down-weight the loss assigned to well-classified examples, thus preventing the model from being o verw helmed by easily classifiable ex- amples. After experimenting with several Deep Neural Network (DNN) archi- tectures, we propose a ResNet, which takes in Spectrogram o r MFCC as input and supervised b y Focal Loss, id eal for speech inpu ts where there exists a large class imbalance. Maintain ing continuity with previous work in this area, we have used the University of So uthern Cal ifornia’s In teractive Emotional Motion Capture (USC- IEMOCAP) database’s Improvised Topics in this work. This da- taset is ideal for our work, as there exists a significant class imbalance among the various emotions. Our best model achieved a 3.4 % improvement in overall accuracy and a 2.8% improvement in class accuracy when co mpared to existing state- of -the-art methods. Keywords: Residual Network, Focal Loss, Spectrogram, MFCC, Speech Emo- tion Recognition 1 INTRODUCTION Standard Natural Language Proce ssing (NLP) s ystems first tr anscribe speech into tex t and then apply deep learni ng techniques to r ecognize emotion in spee ch. Converting speech into text provides us with contextual data required for emotion recognition, but this co nversion makes t he s ystem speaker i ndependent a nd deprives the network o f valuable spec tral i nformation that could be key to character izing emotion in sp eech. Speech features, such a s Spec trogram a nd MFCC, provide variations o f speech over frequency and time ideal for Speech E motion Recognition (SER) systems, which are ____________ _____________________ _____________________ _______________ * equal contribution 2 dependent on the spea ker’s speech para meters such as pitch, a mplitude , etc. In r ecent years CNN, w hich turns speech signals into feature m aps, has been wide- ly used i n such areas of research [1] [2]. The drawback here is t hat such CNN b ased SER syste ms do not extend beyo nd a few con volutional la yers as convergence is slow and the models becom e d i fficult to train. T ypical arc hitectures consist firstl y of some convolutional layers, then a few recurre nt layers and finall y endi ng with fully con- nected feedforward layers. Such networks are not deep enough to extract rich i nfor- mation to be ab le to classify the input a mong dif ferent emotion classes accurately . ResNets [3] o n the o ther hand allow us to have a very de ep architectures ideal for obtaining very deep features. Taking the many li mitations of the traditiona l CNN based SER systems into con- sideratio n; we propo se a speech feat ures based 18 -layer ResNet architecture, super- vised by Focal Loss, which outperforms the state - of -the-art SER ac curacies. Focal Loss was chosen over the wid ely used Soft max Loss as the latter has a tendency to be influenced heavily by trivial examples in case of d ata imbalance [4]. A big p roportion of spoken utterances in day- to -day li fe have no strong emotion associated with it , i.e. they are Neutral in nature. T herefore, training under such an enviro nment with large class imbalance results in a Softmax based system focusing itself more to wards such easy example s (Neutral), whereas it should be giving more p riority towards the harder emotion cla sses. Focal Los s, w hich is a dynamically scaled versio n o f So ftmax Loss, focuses the training towards the sparse set of hard examples while preventin g the influence of a lar ge number of easy examples o n the system. The main contributions o f the current work are: ─ The first attempt, as per our knowledge, to use Focal Loss in addressing the is sue of class imbalance in Sp eech E motion Recognition ( SER) systems ─ Proposed speech feat ures based ResNet ar chitecture, tr ained on IEMOC AP data, which outperforms the state - of -the-art emotion reco gnition accuracies 2 RELATED WORK Deep Learning tech niques ha ve been the reason for significant breakthroug hs in Natu- ral Language Understandin g (NLU) in the l ast few years. Baseline models, which don’t work on the principle of deep learning, w ere significantly improved b y Deep Belief Networks (DB N) for SER, proposed b y Kim et al. [5] and Zheng et al. [6]. [1] used Spectr ograms w ith Deep CNNs whereas Fayek et al. [7] made use of dee p hier- archical architectures, data augmentation , and reg ularization with a DNN for SER. Ranganathan et al. [8] experimented with Convolutional Deep Belief Net works (CDBN), which lear n salient m ultimodal features o f expressions, to achiev e good accuracies. Satt et al. [2] used deep CNNs in combinatio n with Long Short T erm Memory (LSTM) cells to achieve better re sults on the IEM OCAP dataset. In recent years Rec urrent Ne ural Net works (RNNs), capable of modelling long his- tories, have been used e xtensively in sequential modeling. LSTMs and Bidirectional LSTMs, which fix the gradie nt vanishing prob lem, have also been used in ASR sys- 3 tems. Gra ves et a l. [9 ] were the first to apply bidirec tional traini ng to LSTM net works to classify p honemes frame wise in continuous speech reco gnition. Lee et a l. [10] used a bi-directional LST M mod el to train feature sequences and ac hieved an e motion recognition accuracy o f 62.8% on the IEMOCAP [1 1] d ataset. LST Ms , however, become a co mputation bottleneck f or very lar ge sequences as they, at each time stamp, store multiple neural gate responses. CNNs were introd uced to ASR as an alternative to LSTMs as they were much ea sier o n co mputing po wer. Abdel-Hamid et al. [ 12], Amodei et al. [13], and Palaz et al. [ 14] were one of the earliest to u se CNNs in ASR, but they only e mployed a few convolutional layers. Qian et al. [ 15] used very deep CNNs for effecti ve recognition of noisy speec h. As very d eep CNNs were observed to suffer from a slo w rate of co nvergence and performance saturation and degrad ation, ResNets proved to be a good alternative with its s kip connections i n residual blocks. Luo et a l. [16] considered the high perfor- mance of Recurrent Ne ural N etworks and ResNets in speec h and image related classi - fication tasks to propose an e nsemble SER system, which outperfor med t he best sin- gle-classifier, based SER system. T zirakis et al. [17 ] utilized a CNN and a 50 -layered ResNet to extract features from speech and visual data r espectively. Loss functions that dea l with class imbalance have bee n a to pic of interest in recent times. Lin et al. [ 4] proposed a new loss called Focal loss, which addresses class i m- balance by dynamicall y scaling the standard cross -entrop y loss such that the loss as - sociated with easil y classifia ble examples are do wn- weighted. T hey used it in t he field of Den se Objec t Detection and were able to match t he speed of prev ious o ne- stage detectors while surpassing the acc uracy o f all existing state - of -th e-art t wo-stage detectors. Yang et al. [ 18] propo sed skip-con nections in CNN structures trained under Focal loss to en hance feature learning for Ve hicle Detection in Aerial I mages. 3 PROPOSED METHODS Deep learning methods have b een succe ssfully applied on speech features to extract high-order non-linear relatio nships. CNNs , in par ticular, have been used exten sively to gather information fro m raw signals i n various ap plications s uch as speec h reco gni- tion, image reco gnition, etc. [1 9] [20 ]. Deep CNNs i mprove generalization and eas ily outperform s hallow networks , but they have a tende ncy to converge slo wly and ca n be difficult to train. ResNets were prop osed to ease this difficulty in training very deep CNNs. ResNets, when used with speech feat ures such as Spectrogra m and MFCC, pro vide the req uired high-le vel features to better c apture e motion in speech. Experiments have been perfor med on speech features supervised by Focal Loss to address the class imbala nce in IEMOCAP d ataset and achieve high accuracies. 3.1 Model Architecture When a network b ecomes ver y deep , we encounter a couple o f unavoidable pro blems. One is that t he gradients tend to either vanish or explod e. T he other is that as dep th increases the ac curacies tend t o either sat urate or fall. ResN ets, fir st i ntroduced b y He 4 et al. [3], consists of a number of stacked residual block s with out puts fro m the lower layers li nked to the inputs o f the higher la yers. T hese “shortcut connections” turn t he input maps into identity maps. Fig. 1. Residual block The residual block d escribed in Figure 1 is d efined as: 𝑦 = 𝐹 ( 𝑥 , 𝑊 𝑖 ) + 𝑥 (1) Where 𝑥 and 𝑦 ar e the input and the o utput layers resp ectivel y, and 𝐹 ( 𝑥 , 𝑊 𝑖 ) is t he stacked non -linear mapping function. These residua l conne ctions help i mprove con- vergence speed during traini ng and do not degrade in performance with an increase in depth. The residual function 𝐹 ( 𝑥 , 𝑊 𝑖 ) is flexible and could contain multiple la yers, 2 in our case . In add ition, the above notations are app licable to multiple convolutional layers a nd not just to full y connected layers. Our propo sed n etwork, shown i n Fig ure 2, is an 18 -layer ResNet, w hich takes speech features as in put. We apply Batch Nor- malization before co mputing the Rec tified Linear Un it (ReLU) activations. Contrar y to the norm, we have introduced a Focal loss module after the last hidden layer. 3.2 Feature Extraction The presented models use Spectrogra m and MFCC as inp ut to the ResNet. As t he audio files in the IEMOC AP’s Im provised To pic dataset vary in d uration, the length of each clip was restricted to 6 seconds or less. This was done under the assumption that the feature variations, which could possibly c haracterize the e motion in a speech signal, will be p resent throughout the dialogue, and hence will not b e lost by t his re- duction in audio len gth. The Mel -frequency scale, which the Spectro gram and MF CC are scaled to, puts emphasis on the lower end of the frequency spectr um o ver the higher ones, th us imitating the p erceptual hearing capab ilities of humans. We used the "librosa" python package to compute the Spectrogra m and Cepstral coefficients. 5 Fig. 2. Model architecture Spectrogra ms Mel -Spectrogram i s a 2 D representation of log- magnitude intensity ( dB) over f re- quency a nd time. The audio signal is sampled at the sampling rate of 220 50Hz. Sub- sequently, each a udio frame is windowed using a “ hann ” windo w o f length 2048 to increase its continuit y at t he end points. To calculate t he p ower spectr um of eac h frame, w e ap ply Shor t T erm Fourier Transform (ST FT) on windowed aud io sa mples. We use Fast Fourier Transfor m (FFT) windows of length 20 48 and an ST FT hop - length equal to 51 2. Fig. 3. Sample spectrogr am for an audio recording from IEMOCAP dataset. 6 The obtained Sp ectrogram magnitudes ar e then converted to Mel -scale to get Mel - frequency spectru m. 128 Spectrogram coefficients per windo w are used in our model. MFCC Mel -frequency Cepstrum (M FC) i s a 2D representation of the S hort-Ter m Po wer Spectrum of sound. It is based on a linear cosine transfor m of a log power spectrum on a non-linear Mel-scale of frequency. T he par ameters used in the ge neration o f MFCC are same as the ones describ ed for Spectrogram . The only addition al step for MFCC generation compared to Spectr ogra m i s that a Discrete Cosine Transfor m (DCT) is perfor med on the ob tained coefficient s. 4 0 MFCCs per w indow were gener- ated compared to the 12 8 for Spectrogram. Fig. 4. Sample MFCC for an audio recording from IEMOCAP dataset. 3.3 Focal Loss A p roperty of the widely used Cross-Entrop y Los s is that even easily clas sifiable ex- amples ( 𝒑 𝒕 ≥ 0.5) result in a loss with a significant magnitude [4] . The losses incurred during training f rom easy examples, which co nstitute the majority of the dataset, can have a negative impact on t he rarer classes. T he Neutral emotion, which co vers a majority o f the data set, tends to comprise the bulk of the loss and ends up do minating the gradient. Focal Loss maneuvers th is by reshapin g the Cross -Entrop y Loss function by giving less importance to the easy examples and focusing more on the hard ones. A general way of for mulating Focal loss is: 𝐹𝐿 ( 𝑝 𝑡 ) = − ( 1 − 𝑝 𝑡 ) 𝛾 log ( 𝑝 𝑡 ) (2) Where 𝒑 𝒕 is the model’s esti mated p robability for the class , an d 𝜸 ≥ 𝟎 is the tunable focusing parameter. For inputs t hat are misclassified their contribution to total loss is not affected as the modulating factor is c lose to one a nd 𝒑 𝒕 is small. For inputs that are classified cor rect- ly, the m odulating factor bec omes very s mall, a nd the l oss is s ignificantly do wn- weighted thus reducing it s contribution to total lo ss even if the y are large in nu mber and preventing the model from being overwhelmed b y such examples. 7 For instance when 𝒑 𝒕 = 0.8 and 𝜸 = 2 Focal Loss i s 96% lower compared to Cros s - Entropy Loss, which means that the correctl y classified examples ’ effect on the gradi- ents is reduced heavily. W hen 𝒑 𝒕 is already lo w (< 0.1) the loss pretty much remains the same aiding the model in learning these hard examples. 4 Dataset T he University o f Sout hern C alifornia’s In teractive E motional Motion Capture (USC - IEMOCAP) database consists of five sessions, each se ssion comprising of a conversa- tion bet ween two people, in both scrip ted and i mprovised to pics. Gend er b ias is min- imized as each session is ac ted upon and voiced b y bo th male and f emale voices . T he data collected is first split in to utterances of length varying b etween 3 -15 seconds and then labelled by 3- 4 eval uators. To label the emotion, t he assessors had to choose among 10 different emotion c lasses (Hap piness, Surprise, F ear, Sad ness, Frustration, Excited, Anger, Disgust, Neutral and other). We limited our e motion classes to just four (A nger, Happiness, Sadness and Neutral ) to remain co nsistent with ear lier re- search. We chose only those utterances where at least 2 experts w ere in a greement with t heir d ecided labels and only used Impr ovised T opic data, again bei ng co nsistent with prio r research. We excluded scripted data as it sho wed too stron g a correlatio n with labeled emotions, which could lead to lingual content learning. The p roportions of the four classes in the final experimental dataset are Neutral (48.8 % of the total dataset), Happiness (1 2.3%), Sadness (2 6.9%) and Anger (12%). As the re exists an imbalance for data b etween d ifferent e motional clas ses, we present our results on overall accurac y; average cla ss accuracy and also show th e confusion matrix (refer Table 2 and 3 ). 5 EVALUATION AND DISCUSSION W e have sho wn the e ffectiveness of the pr oposed met hods for emotion detectio n with our benchmark r esults on IEMOC AP dataset and compared with the previous related research . We have split the dataset into training and test set s using strati fied K- folds. Comparison of our 5-fold cross-validation experimental results is made with s o me of the recent results on e motion classi ficatio n and is presented in T able 1. The proposed ResNet models are based on Spec trogram and MFCC inputs and ar e supervised by Focal L oss, with o ur best model achieving an overall accuracy i mprovement o f 3.4% and a class accuracy i mprove ment of 2.8 %. Overall accu racy is a measure of tota l counts irrespective of class, and class accuracy is the mean of accurac ies obtained in each of the emotion class es . 8 Table 1. Comparison of accuracies Methods Input Overall Accuracy Class Accuracy Lee et al. [10 ] Spectrogram 62.8 63.9 Satt et al. [2 ] Spectrogram 68.8 59.4 Yenigalla [21] Spectrogram 71.2 61 .9 Proposed Model Spectrogram 74.2 64.3 Proposed Model MFCC 74.6 66.7 5.1 Ablation study of the effectiveness of foca l loss: As mentio ned ea rlier, the dataset is not well bala nced, with Neutral constituting almost half of it . Tables 2 and 3 r epresent the confusion matrix showing mi sclassifica- tion rates b etween each pair of classe s for the MFCC based ResNet, but independent- ly trained on So ftmax Loss or Fo cal Loss, for an equal number of ep ochs, respective- ly. Table 2 clearly validates t he prob lems with using Softmax Loss in situations where there is a si gnificant class i mbalance in t he dataset. T he net w ork has t uned itsel f to work very well in classi fying the most abundant e motion, Neutral , with an 89.1 % accuracy, b ut s uffers in cla ssifying t he rar er emotions co rrectly. However, when the network is trained on Fo cal L oss, we can clearly see in Table 3 the impro vement in recognition accuracies for the rarer classes. T he r ate of recognition for Hap piness almost doubles; Sad ness and Anger also ob serve significant i mprovement bu t with a slight drop in Neutral. Table 2. Confusion matrix (ResNet on MFCC input), in percentage, trained on Softmax Loss Class Labels Prediction Neutral Happiness Sadness Anger Neutral 89.1 5.4 3.7 1.8 Happiness 70.5 25.2 4.3 0.0 Sadness 24.6 2.7 70.5 2.2 Anger 48.7 5.6 2.9 42.8 Table 3. Confusion matrix (ResNet on MFCC input), in percentage, trained on Focal Loss Class Labels Prediction Neutral Happiness Sadness Anger Neutral 80.2 3.2 15.2 1.4 Happiness 34.7 52.0 8.5 4.8 Sadness 16.4 1.2 81.6 0.8 Anger 39.4 5.4 2.3 52.9 Additionally, we ha ve exper imented with different settings of the loss functions (softmax or focal loss) and p resented the comparative study of the same in T able 4. For bo th inputs, spectrogra m and MFCC, accurac y have increased in focal loss setting as co mpared to softmax loss setti ng . Super vision of Focal Loss helps the models to 9 focus more to wards hard -examples and do wn-weight the loss assigned to well - classified examples during the tr aining process. The below comparative accuracy clearly shows the advantage o f using Focal los s instead of Softmax Loss Table 4. Ablation study of the effectiveness of Focal Loss Input Features Loss functions settings Overall Accuracy Class Accuracy Spectrogram Softmax Loss 70 .2 55.8 Spectrogram Focal Loss 74.2 64.3 MFCC Softmax Loss 70.7 56.9 MFCC Focal Loss 74.6 66.7 6 CONCLUSIONS In this p aper, we have pr oposed a speech feat ures based ResNet architect ure trained under Focal Los s, which beats the previous state- of -the-art e motion recognition ac cu- racies. Our best model (MFCC) outperforms t he bench mark results b y 3.4% and 2.8% for overall and class accurac ies respectively. The use of Spectro grams a nd MFCC provides low-level features, whic h when co mbined with ResNets has allowed us to extract very deep features b oosting the model perfor mance. With the help of Focal Loss, we have significantly improved recognition o f t he rar er e motion classes (Anger, Sadness and Happiness) as shown in our co nfusion matrices. Focal loss, w hich to the best of o ur knowledge has n ot been used earlier i n SE R systems, has he lped us miti- gate considerab le class i mbalance . Focal Loss helps to scale the standard cross- entropy loss to do wn-weight loss correspo nding to easily classifiable examples dy- namically and focus more on hard examples to make the system p er form better on hard exa mples as well. For fut ure w ork, w e ca n experiment using Focal Loss in vari- ous architectures like CNN, RNN, and Inceptio n Networks. References 1. Zheng, W.Q., Yu, J.S., Zou, Y.X.: An experimental study of speech emotion recognition based o n deep convolutional n eural networks. In: Intern ational Conference on Affective Computing and Intelligent Interaction, pp. 827-831, 2015. 2. Satt, A., Rozenberg, S., Hoory, R.: Efficie nt Emotion Recognition from Sp eech Usin g Deep Learning on Spectrograms. In: Interspeech, Stockholm, 2017. 3. He, K., Zhang, X., Ren, S. , Sun, J. : Deep Residual Learning for Image Recognition. 4. Lin, T.Y., Goy al, P ., Girshick, R., He K. , Dollar P. : Focal Loss for Dense Object Detec- tion. In : IEEE International Conference on Computer Vision (ICCV), 2017. 5. Kim, Y., Lee, H. , P rovost, E. M.: Deep Learning for Ro bust Feature Generation in Audio - visual Emotion Recognition. In: I EEE In ternational Conference on Acoustics, Speech and Signal Processing, pp. 3687-3691, 2013. 10 6. Zheng, W. L., Zhu, J., Peng, Y.: EEG -based Emotion Classification using Deep Belief Networks. In: IEEE International Conference on Multimedia & Expo, pp. 1-6, 2014. 7. Fayek, H. M., L ech, M. , Cavedon, L. : Towards real-time Sp eech Emotion Recogni tion us- ing Deep Neural Networks. In: International Con ference on Signal P rocessing and Com- munication Systems, pp.1-5, 2015. 8. Ranganathan, H., Chakraborty, S. , P anchanathan, S. : Mu ltimodal Emotion Recognition u s- ing Deep Learning Architectures. In: 2016 IEEE Winter Conference on Applications of Computer Vision, 2016. 9. Graves, A., Schmidhub er, J. : Framewise P honeme Classification with Bidirectional LSTM and other Neural Network Architectures. In: Neural Networks, 18:602 – 610, 2005. 10. Lee, J., T ashev, I .: High-level Feature Representation using Recurrent Neural Network f or Speech Emotion Recognition. In: Interspeech, 2015. 11. Busso, C., Bulut, M., L ee, C.C., Kaz emzadeh, A., Mower, E., Kim , S., Chang, J.N., Le e, S., Naray anan, S.S. : I EMOCAP: Interactive Emotional Dyadic Moti on Capture Database. In: Journal of Language Resources and Evaluation vol. 42 no. 4, pp . 335 -359, 2008. 12. Abdel-Hamid, O., Abdel-Rahman, M., Jiang, H., Deng, L., Penn, G. , Yu , D. : Convolution- al Neural Networks for Speech Recognition. In: IEEE/ACM Transactions o n Audio, Speech, and Language Processing, 22(10):1533 – 1545, 2014. 13. Amodei, D., Anubhai, R., Battenberg, E., Case, C., Casper, J., Catanzaro, B., Ch en, J., Chrzanowski, M., Coates, A., Diamos, G. : End- to - En d Speech Recognition in English and Mandarin . 14. P alaz, D., M agimai-Doss, M. and Collobert, R. : Analysis of CNN-based Speech Recogni- tion System using Raw Speech as Input. In: Interspeech, 2015. 15. Qian, Y. , Woodland, P. C.: V ery Deep Convolu tional Neural Networks for Robust Sp eech Recognition. In: IEEE Spoken Language Technology Workshop (SLT), pp. 481 – 488, 2016. 16. Luo, D., Zuo, Y., Huang, D. : Speech Emotion Recognition via Ensembling Neural Net- works. In: Proceedings of APSIPA Annual Summit and Conference, 2017. 17. Tzirakis, P., Trigeorgis, G., Nicolaou, M. A ., Schuller, B., Zafeiriou, S. : End- to -End Mu l- timodal Emotion Recognition using Dee p Neural Netw orks. In: IEEE Journal of Selected Topics in Signal Processing, 2017. 18. Yang, M. Y., Liao, W., Li, X. , Rosenhahn, B. : Vehicle Detection in Aerial Images. arX iv 19. Zh ang, Y., Chan, W., Jaitly, N. : Very Dee p Convolutional Networks for End- to -End Speech Recognition. In: IEEE International Conference on Acou stics, Speech and Signal Processing, 2017. 20. Krizhevsky, A., Sutskever, I. , Hinton, G. : ImageNe t Classificatio n with Deep Convolu- tional Neural Networks. In: NIPS, pp. 1106 – 1114, 2012. 21. Yenigalla, P., Kumar, A., Tripathi, S ., Kar, S., Vepa, J.: Speech E motion Recognition us- ing Spectrogram & Phoneme Embedding, In: Interspeech, 2018.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment