음성 감정 인식을 위한 포컬 손실 기반 레지듀얼 CNN
본 논문은 스펙트로그램과 MFCC와 같은 음성 특징을 입력으로 사용하고, 클래스 불균형 문제를 완화하기 위해 포컬 손실(Focal Loss)을 적용한 18‑layer 레지듀얼 네트워크(ResNet)를 제안한다. IEMOCAP 데이터셋의 즉흥 대화 파트를 대상으로 실험한 결과, 기존 최고 성능 모델 대비 전체 정확도 3.4 %, 클래스 평균 정확도 2.8 % 향상을 달성하였다.
저자: Suraj Tripathi, Abhay Kumar, Abhiram Ramesh
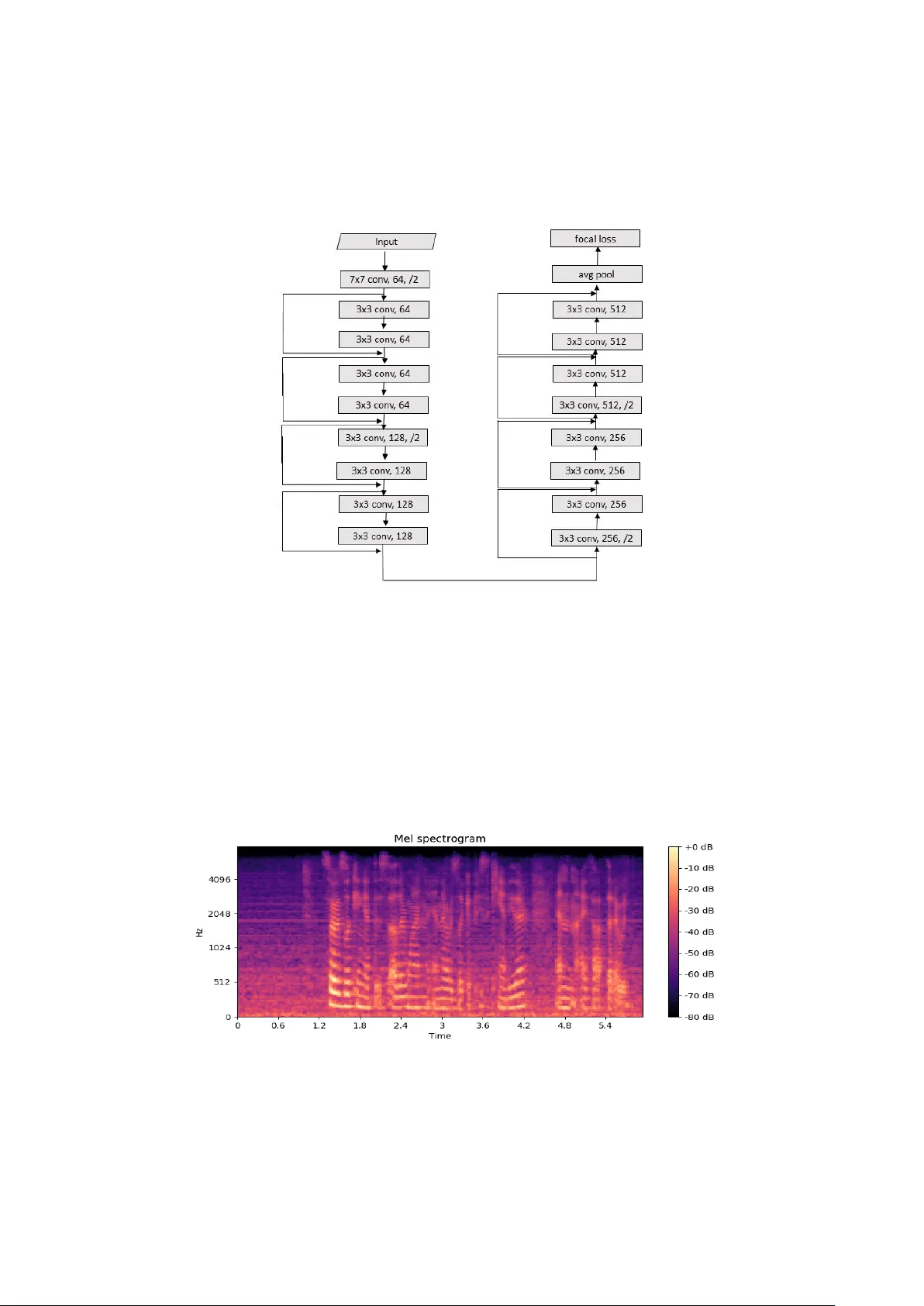
본 논문은 음성 감정 인식(SER) 분야에서 기존 CNN 기반 모델이 직면한 두 가지 주요 한계—특징 추출 깊이 부족과 데이터 클래스 불균형—를 동시에 해결하고자 한다. 이를 위해 저자들은 18층 깊이의 Residual Convolutional Neural Network(ResNet) 구조를 설계하고, 손실 함수로는 포컬 손실(Focal Loss)을 채택하였다.
먼저, 모델 아키텍처는 표준 ResNet 블록을 기반으로 하며, 각 블록은 두 개의 3×3 컨볼루션 레이어와 배치 정규화·ReLU 활성화를 포함한다. 잔차 연결(skip connection)은 입력을 그대로 다음 블록에 전달함으로써 기울기 소실·폭주 문제를 완화하고, 매우 깊은 네트워크에서도 효율적인 학습을 가능하게 한다. 전체 네트워크는 18개의 레이어로 구성되어, 스펙트로그램 혹은 MFCC와 같은 저수준 음성 특징을 고차원 표현으로 변환한다.
데이터 전처리 단계에서는 IEMOCAP 데이터셋의 즉흥 대화 파트를 사용한다. 각 오디오 파일은 6초 이하로 잘라내어 고정 입력 길이를 확보하고, 22050 Hz 샘플링 레이트로 재샘플링한다. 스펙트로그램은 2048 길이의 Hann 윈도우와 2048 FFT를 적용해 128개의 멜 스케일 로그 파워 스펙트럼을 얻으며, MFCC는 동일한 파라미터에 DCT를 추가해 40개의 계수를 추출한다. 이렇게 얻은 2‑D 특징 맵은 채널 차원에 따라 ResNet에 입력된다.
클래스 불균형 문제를 해결하기 위해 포컬 손실을 도입하였다. 포컬 손실은 기존 교차 엔트로피 손실에 (1‑pₜ)ᵞ라는 모듈레이션 팩터를 곱해, 모델이 높은 확신을 가지고 올바르게 예측한 샘플(주로 Neutral)의 손실 기여도를 크게 감소시킨다. γ 파라미터를 2로 설정함으로써, pₜ=0.8인 경우 손실이 Softmax 대비 96 % 감소한다. 이는 학습 과정에서 희소 클래스(Anger, Happiness, Sadness)의 샘플이 더 큰 기여를 하게 만들어, 전체적인 클래스 균형을 맞춘다.
실험은 5‑fold 교차 검증과 stratified K‑fold 샘플링을 통해 수행되었다. 비교 대상으로는 Lee et al., Satt et al., Yenigalla 등 기존 최고 성능 모델이 포함되었으며, 동일한 스펙트로그램 입력을 사용하였다. 결과는 다음과 같다. 스펙트로그램 입력에 대해 제안 모델은 전체 정확도 74.2 %와 클래스 평균 정확도 64.3 %를 달성했으며, MFCC 입력에서는 각각 74.6 %와 66.7 %를 기록했다. 이는 기존 최고 성능(71.2 %/61.9 %)보다 각각 3.0 %p 이상, 2.8 %p 이상 향상된 것이다.
혼동 행렬 분석에서는 Softmax 손실을 사용했을 때 Neutral 클래스의 정확도가 89.1 %에 달했지만, 다른 세 클래스는 20 % 이하에 머물렀다. 반면 포컬 손실을 적용하면 Neutral 정확도가 80.2 %로 약간 감소하는 대신, Happiness(52.0 %), Sadness(81.6 %), Anger(52.9 %)의 정확도가 크게 상승하였다. 이는 포컬 손실이 어려운 샘플에 집중하도록 학습을 유도함을 명확히 보여준다.
Ablation Study에서는 동일 네트워크에 Softmax와 Focal Loss를 교차 적용한 결과, 두 입력 형태 모두에서 Focal Loss가 전체·클래스 정확도를 평균 4 %p 이상 끌어올렸다. 이는 손실 함수 선택이 모델 성능에 미치는 영향이 크며, 특히 불균형 데이터셋에서 포컬 손실이 효과적임을 입증한다.
결론적으로, 이 논문은 (1) 깊은 Residual CNN을 통해 음성 신호의 복합적인 시간‑주파수 패턴을 효과적으로 학습하고, (2) 포컬 손실을 이용해 클래스 불균형을 정량적으로 완화함으로써 SER 성능을 현저히 향상시켰다. 향후 연구 방향으로는 멀티모달(음성 + 텍스트) 통합, 실시간 추론을 위한 경량화, γ와 α 파라미터의 자동 최적화, 그리고 다른 언어·문화권 데이터에 대한 일반화 검증 등이 제시된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기