Modyn: Data-Centric Machine Learning Pipeline Orchestration
In real-world machine learning (ML) pipelines, datasets are continuously growing. Models must incorporate this new training data to improve generalization and adapt to potential distribution shifts. The cost of model retraining is proportional to how…
Authors: Maximilian Böther, Ties Robroek, Viktor Gsteiger
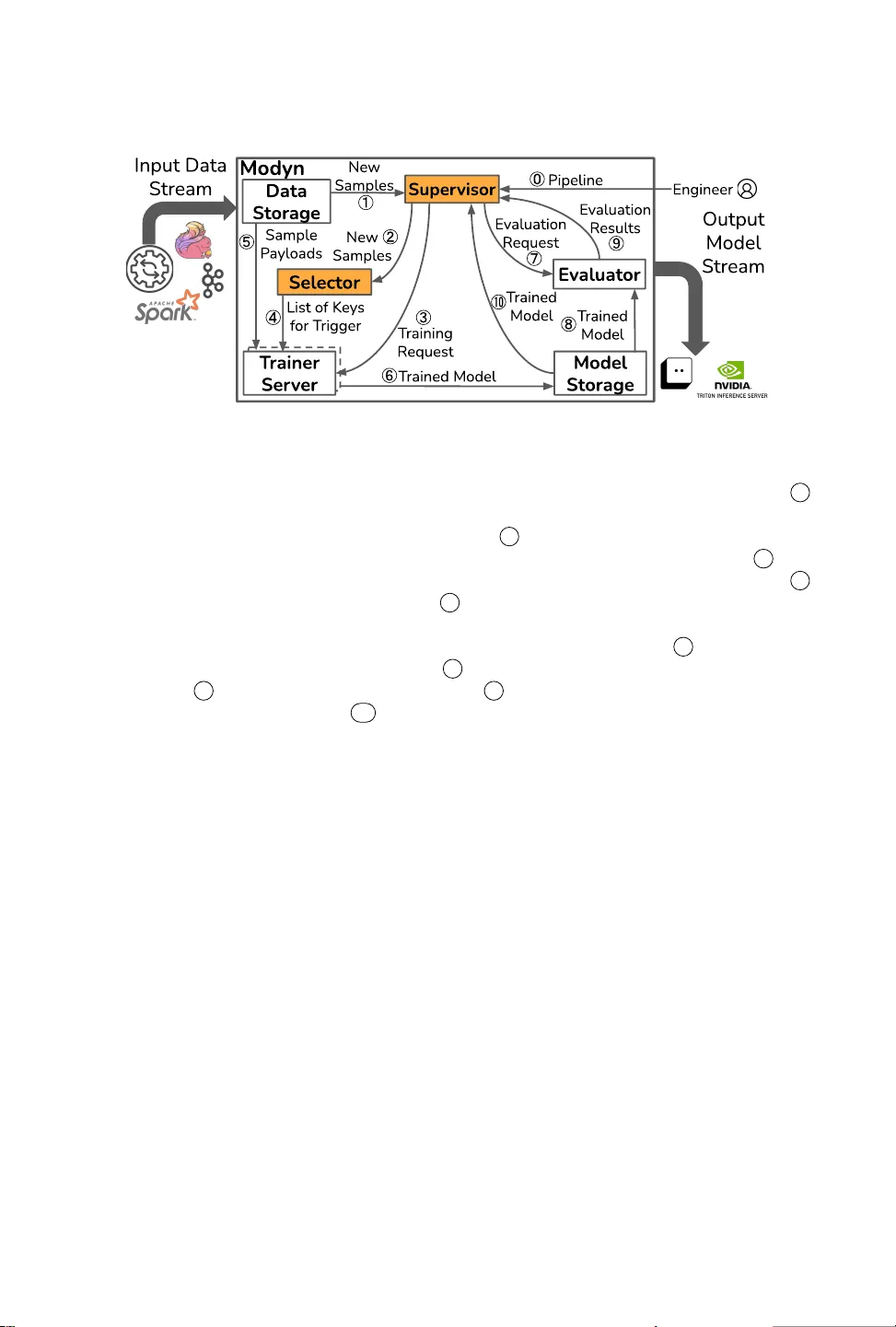
Modyn : Data-Centric Machine Learning Pipeline Orchestration MAXIMILIAN BÖTHER, ETH Zurich, Switzerland TIES ROBROEK, I T University of Copenhagen, Denmark VIKTOR GSTEIGER, ETH Zurich, Switzerland ROBIN HOLZINGER, T echnical University of Munich, Germany XIANZHE MA, ETH Zurich, Switzerland PINAR TÖZÜN, I T University of Copenhagen, Denmark ANA KLIMO VIC, ETH Zurich, Switzerland In real-world machine learning (ML) pipelines, datasets are continuously gro wing. Mo dels must incorporate this new training data to improve generalization and adapt to potential distribution shifts. The cost of model retraining is proportional to how frequently the model is retrained and how much data it is traine d on, which makes the naive approach of retraining fr om scratch each time impractical. W e present Modyn , a data-centric end-to-end machine learning platform. Modyn ’s ML pipeline abstraction enables users to declaratively describe policies for continuously training a model on a gr owing dataset. Modyn pipelines allow users to apply data selection policies (to reduce the number of data p oints) and triggering policies (to reduce the number of trainings). Modyn executes and orchestrates these continuous ML training pipelines. The system is open-source and comes with an e cosystem of benchmark datasets, models, and tooling. W e formally discuss how to measure the performance of ML pipelines by introducing the concept of composite models, enabling fair comparison of pipelines with dierent data selection and triggering p olicies. W e empirically analyze ho w various data selection and triggering policies impact mo del accuracy , and also show that Modyn enables high throughput training with sample-level data selection. CCS Concepts: • Computing methodologies → Online learning settings ; • Information systems → Data management systems ; Computing platforms; Spatial-temporal systems. Additional K ey W ords and Phrases: Machine Learning Pipelines, Online Learning, Data-Centric AI A CM Reference Format: Maximilian Böther, Ties Robroek, Viktor Gsteiger, Robin Holzinger, Xianzhe Ma, Pınar Tözün, and Ana Klimovic. 2025. Modyn : Data-Centric Machine Learning Pipeline Orchestration. Proc. ACM Manag. Data 3, 1 (SIGMOD), Article 55 (February 2025), 30 pages. https://doi.org/10.1145/3709705 1 Introduction The datasets fueling today’s production machine learning (ML) models, which typically come from a myriad of sensors or real-time user click streams, are continuously growing [ 12 , 55 , 106 ]. T o maintain high accuracy , stale models deployed in the wild nee d to b e retrained in order to incorporate new data, particularly as training data may e xp erience distribution drifts [ 39 , 43 , 44 , 53 , A uthors’ Contact Information: Maximilian Böther, mboether@ethz.ch, ETH Zurich, Switzerland; Ties Robroek, titr@itu.dk, I T University of Copenhagen, Denmark; Viktor Gsteiger, vgsteiger@student.ethz.ch, ETH Zurich, Switzerland; Robin Holzinger, robin.holzinger@tum.de, T echnical University of Munich, Germany; Xianzhe Ma, xianzhema@student.ethz.ch, ETH Zurich, Switzerland; Pınar Tözün, pito@itu.dk, IT University of Copenhagen, Denmark; Ana Klimovic, aklimovic@ethz.ch, ETH Zurich, Switzerland. This work is licensed under a Creative Commons Attribution International 4.0 License. © 2025 Copyright held by the owner/author(s). A CM 2836-6573/2025/2-ART55 https://doi.org/10.1145/3709705 Proc. ACM Manag. Data, V ol. 3, No. 1 (SIGMOD), Article 55. Publication date: February 2025. 55:2 Maximilian Böther et al. Loss [47] DLIS [47] Uniform Class-Bal. RS2 [73] RS2 (w/o) [73] Margin [22] Least conf. [22] Entropy [22] 82 85 88 91 Mean Accuracy % Full data training Fig. 1. Mean accuracies of 9 selection strategies (50 % subset) and full data training (see Section 7.1.1). 56 , 61 , 85 , 92 , 95 , 101 , 110 ]. In practice, models may be retrained as often as every day [ 28 ], while the volume of data that models train on can be as high as petabytes or ev en exabytes, depending on the application domain [31, 124]. The cost of continuously training an ML mo del depends on how frequently we retrain the model and how much data we use to train the model each time. The naive approach of retraining a model from scratch on the entire dataset when new data becomes available is prohibitively expensive and slow [ 46 , 60 ]. T o make retraining 1 models practical in real use cases, we need to minimize the frequency and the volume of data that a model is trained on, while maintaining high mo del quality . For example, Figure 1 shows how various data selection policies (x-axis) propose d in ML literature maintain model accuracy comparable to training on all data (dashed line) while training on only 50 % of the yearbook image classication dataset [ 121 ]. Complementary to data selection, data drift detection can help to trigger retraining only when data characteristics change. This can save cost and/or increase model quality compared to xed-interval retraining schedules. Howev er , nding the right data selection and triggering policies is non-trivial. While ML re- searchers have explored how to eectively select imp ortant samples in a dataset with various strategies [ 3 , 4 , 45 , 47 , 49 , 62 , 63 , 73 , 76 , 79 , 81 , 86 ], it is not clear what policy to use for real-world datasets that grow and exhibit distribution shifts over time. ML studies in this space often focus on smaller , static datasets, such as Cif ar [ 51 ] and Mnist [ 54 ], and do not consider the total pipeline cost, or they focus on one particular metric (e.g., information retention in continual learning stud- ies [ 16 , 80 ]). Several drift detection techniques exist [ 34 , 59 , 85 , 90 , 105 ]. Existing studies, however , focus on tabular data, synthetically inject drift, and do not train neural networks in r esp onse to drift [ 2 , 8 , 88 , 89 , 94 , 113 ]. Using such techniques as triggering policies is non-trivial as it involves tuning many hyperparameters. Most pipelines today are still human-driven [42, 95]. Furthermore, it is challenging to implement data selection policies in large-scale gr owing dataset environments while maintaining high training throughput. Data ingestion is a common b ottleneck in ML training [ 52 , 67 , 124 ]. Applying data selection policies requires accessing individual data samples rather than sequentially reading input data les. Such random access patterns can degrade training throughput. In Section 7.3, we show that multiple levels of batching, parallelizing, and prefetching of reads ar e essential to achieve high throughput. Such optimizations should be done transparently by a platform, while ML users focus on dening the logic of ML training and data preprocessing pipelines. While others have also acknowledged the need for a continuous training platform that enables users to explore data sele ction and (re)training p olicies [ 26 , 75 , 96 , 108 ], 1 In this paper , retraining refers to both netuning or training from scratch. Proc. ACM Manag. Data, V ol. 3, No. 1 (SIGMOD), Article 55. Publication date: February 2025. Modyn : Data-Centric Machine Learning Pipeline Orchestration 55:3 current open-source systems only have limited support for retraining [ 10 , 25 , 65 , 107 ]. W e are not aware of any platform supporting sample-level data selection policies. W e present Modyn , a data-centric machine learning pipeline or chestrator that addresses this gap. T o the b est of our kno wle dge, in particular for modalities commonly used in DNN training such as images, Modyn is the rst op en-source orchestrator to support data sele ction and retraining decisions based on the incoming data. Modyn is an end-to-end platform that supports the entire pipeline lifecycle, including sampling-level data selection and management, triggering mo del retraining, continuously evaluating model quality , and managing model snapshots. In this paper , we contribute the following: (1) W e design an ML pip eline abstraction, which enables users to express how to continuously train a model on gro wing data. It allows declaratively specifying data-centric policies for model retraining and training data selection, while decoupling the implementation of these policies. W e design the abstraction to capture a taxonomy of data selection and triggering policies. (2) W e build Modyn , an orchestrator that runs data-centric ML pipelines. Modyn supports various data selection techniques while optimizing for high-throughput sample-level data selection for multiple data formats. It also supports time-, data volume-, performance-, and data drift-based triggering p olicies while managing and continuously evaluating model versions. Modyn enables sample-level data selection with comparable thr oughput to sequentially ingesting data from local storage. (3) W e formalize ML pipelines and introduce comp osite mo dels which describe the p erformance of a pipeline over its lifetime, and allow for a fair comparison of pipelines with dierent selection and triggering policies. W e build an ecosystem around Modyn to facilitate policy exploration. Modyn comes with web-based tooling to compare pipelines in terms of system throughput, training cost, and mo del quality metrics. It also comes with a set of b enchmark models and datasets with timestamped data for policy evaluation. For a subset of the accompanying bench- marks, we include case studies on sele ction and triggering policies, showing how these p olicies impact pipeline performance. 2 Background and Motivation In this section, we discuss the gr owing nature of real ML datasets (Section 2.1) and motivate the need for a new platform (Section 2.2). 2.1 Growing Datasets & ML Perspective Real-world ML datasets are often dynamic, in contrast to static datasets such as ImageNet [ 24 ] that are typically used in ML r esearch [ 14 ]. They either gro w as more samples are collected (e .g., from continuous data sources like sensors or click streams) or shrink as data is deleted (e.g., due to privacy reasons). In this work, we focus on the challenges of training ML models on growing data . Why growing data matters. Incoming data captures current trends and reveals distribution shifts that can be critical in many application domains [ 97 , 110 ], like recommender systems [ 28 , 37 , 39 , 120 , 124 ] and language models [ 53 ]. For e xample, the GrubHub food delivery platform observed a 20 % increase in purchase rate when their mo del is retrained daily rather than weekly [ 28 ]. Even in the absence of signicant distribution shifts, including additional data ov er time can enhance model performance as it improves generalization. For e xample, T esla continuously collects street pictures to rene their autonomous driving models [ 106 ]. Growing data impacts training cost, as the cost is proportional to (i) how often the mo del trains and (ii) the numb er of data samples it trains on [46, 60]. ML perspective on growing data. ML research so far has explored optimizing when to retrain a model and what data to select for training as two isolated dimensions. The eld of continual learning Proc. ACM Manag. Data, V ol. 3, No. 1 (SIGMOD), Article 55. Publication date: February 2025. 55:4 Maximilian Böther et al. (CL) [ 3 , 4 , 7 , 26 , 50 , 58 , 81 ], or incr emental learning [ 18 , 78 , 117 ], adapts ML models to ongoing data streams by focusing on learning new tasks, dened as groups of classes. It is unclear how these techniques apply to real use cases, as CL research has focused on small datasets with synthetic perturbations that lack a true notion of time. Furthermore, both the focus on learning classes over time instead of adapting to distribution shift and the common assumption of limited storage are not realistic, as ackno wle dged by recent works in the CL community [ 32 , 80 ]. Data selection policies outside of CL fo cus on selecting subsets of static datasets [ 47 , 62 , 63 ]. All techniques require sample-level data access on the dataset. While there is work on detecting distribution shift, these papers often focus on theoretical asp ects and do not actually train models [ 2 , 8 , 34 , 55 , 57 , 85 , 90 , 105 ], i.e., they only compare drift scor es. Notably , W erner et al. [ 113 ] train random forests on tabular datasets, and Y uan et al. [ 122 ] consider synthetically perturbed variations of the MNIST dataset from continual learning. T o the best of our knowledge, no paper e xplored applying drift detection techniques to training large neural networks on modalities such as images and text from non-synthetic benchmarks. 2.2 Platform Support Managing when to retrain models and on what data to train models in large-scale growing data environments is challenging. It requires eciently orchestrating continuous training pipelines with congurable triggers and fast access to arbitrary sets of data samples determined by a data selection policy . Model training orchestration and sample-level data fetching should be transparently optimized by a platform in order to help ML researchers focus on policy exploration and to help ML practitioners reliably deploy ML pipelines in production environments. Furthermore , drift detection techniques need to b e closely embedded into the data ow , since they typically need to access the previously trained models and the data stream. Current ML platforms do not address these requirements. The majority of ML training platforms, such as W eights & Biases [ 13 ] or MLFlow [ 20 ], are tailored more to wards experiment tracking than continuous retraining. While a few (often commercial) platforms like Neptune AI [ 70 ], Amazon SageMaker [ 5 ], Continuum [ 107 ], or T ensorow TFX [ 65 ] have partial retraining support, deplo ying continuous retraining still requires a lot of manual plumbing [ 10 , 75 , 95 , 108 ]. Commonly , platforms allow for the performance of the deployed model to trigger a retraining (e .g., SageMaker or tf- serving [ 74 ]). Notably , Hopsworks [ 41 ] supports drift detection on individual features of tabular data, and SageMaker’s Model Monitor allows for the collection of drift metrics on tabular data using the Deequ library [ 93 ]. Images and other modalities are explicitly not supported currently . Platforms such as Ekya [ 12 ], which optimizes retraining for vision models on edge devices, and Ekko [ 98 ], which optimizes model updates for recommendation systems, cater to specic use cases. The aforementioned platforms vie w the datasets as a big blob of data instead of indexing individual samples.Especially for modalities commonly use d in DNN training (images and text), data-centric decision making on when and what data to train on is, to the best of our knowledge, not supported by any available open-source training platform. 3 Modeling Dynamic ML Pipelines Continuous ML pipelines regularly run model trainings on an incoming stream of data 𝑆 with a discrete time clock. The data arrives in batches 𝑆 𝑖 ⊂ 𝑆 , i.e., sequences of new samples, where batch 𝑡 is given as 𝑆 𝑡 = ( 𝑠 1 , . . . , 𝑠 𝑛 𝑡 ) . Each sample 𝑠 𝑖 ∈ 𝑆 𝑡 comprises a unique identier , a label, a timestamp, other metadata, and a data payload. Proc. ACM Manag. Data, V ol. 3, No. 1 (SIGMOD), Article 55. Publication date: February 2025. Modyn : Data-Centric Machine Learning Pipeline Orchestration 55:5 Triggering. The triggering p olicy decides whether to trigger a new training 2 . W e model a triggering policy as a function 𝜋 : P ( 𝑆 ) → Ð ∞ 𝑛 = 0 P ( [ 1 , . . . , 𝑛 ] ) . Given a batch 𝑆 𝑡 , it determines which samples 𝑠 𝑖 ∈ 𝑆 𝑡 trigger a new training process. Formally , it outputs a sequence 𝜋 ( 𝑆 𝑡 ) = ( 𝑖 ∈ [ 1 . . . 𝑛 𝑡 ] | 𝑠 𝑖 ∈ 𝑆 𝑡 causes trigger ) . The triggering policy can be stateful and utilize the observed history of samples, properties of them or the pipeline, to come to a triggering decision. Conceptually , the triggering policy decides on a per-sample basis. For eciency , our implementation evaluates multiple samples simultaneously in batches, while keeping the semantics of per-sample decision- making. Note that triggering on each new data sample is impractical in production, as each newly trained model typically needs to undergo a set of extensive deployment checks, which are e xp ensive to run at high frequency [43, 95]. Data selection. On each trigger , the selection policy chooses which samples to train on. Let 𝑠 𝑘 ∈ 𝑆 𝑡 cause the overall 𝑟 -th retraining trigger . The observed data until trigger 𝑟 is D tot 𝑟 = { 𝑠 𝑖 ∈ 𝑆 𝑡 | 𝑖 ≤ 𝑘 } ∪ Ð 𝑡 ′ < 𝑡 set ( 𝑆 𝑡 ′ ) . A data selection policy is a function 𝜉 𝑟 : D tot 𝑟 → R | D tot 𝑟 | that assigns each item in the total obser ved data a weight. Thereby , the function denes the 𝑟 -th trigger training set D 𝑟 ⊂ D tot 𝑟 × R + . An item is included if its weight is greater than 0. The data selection policy selects from all previously seen data samples, i.e., they can come from any 𝑆 𝑡 ′ with 𝑡 ′ < 𝑡 , and all samples in 𝑆 𝑡 until 𝑠 𝑘 . The sample weights can be used to prioritize samples by multiplying their gradients with the weights during backpropagation. The trigger training set is a subset of all data points seen so far , so it may , but does not have to, contain samples from pr evious triggers. 3.1 Evaluating and comparing pipelines T o compare ML pipelines, we rst need to dene how to quantify the performance and cost of a pipeline. Evaluating the model quality and training cost of an ML pip eline on a growing dataset is more complex than evaluating a single model training on a static dataset. T wo challenges arise. First, ML pipelines train multiple models instead of a single one to deal with the growing data that might exhibit distribution shift. On each retraining trigger 𝑟 we train a new model 𝑚 𝑟 . For a pip eline 𝑃 , let M 𝑃 denote the sequence of all models trained during pip eline execution. Each 𝑚 𝑟 ∈ M 𝑃 is a 4-tuple containing its mo del weights 𝑤 𝑟 , the data it was traine d on D 𝑟 , and the start timestamp 𝑡 𝑠 𝑟 and end timestamp 𝑡 𝑒 𝑟 of the training data, i.e ., 𝑚 𝑟 = 𝑤 𝑟 , D 𝑟 , 𝑡 𝑠 𝑟 , 𝑡 𝑒 𝑟 . W e should not just evaluate a single model from M 𝑃 , e.g., the last one, on the entire dataset since the model is trained on one particular distribution. Instead, we need to consider multiple models. Second, to understand ho w a model’s performance changes over time, we need to dene windo ws over the evaluation data, as discussed by Shankar et al. [ 96 ]. Evaluation data should be separate from training data, e.g., by partitioning the stream 𝑆 . These windows are temporal slices of the dataset on which we then calculate a quality metric per model. Let 𝑃 1 and 𝑃 2 be pipelines with dierent triggering policies 𝜋 1 and 𝜋 2 on the same stream of data. M 𝑃 1 and M 𝑃 2 contain dierent models, in particular with dierent timestamps. The intuitive solution of dening evaluation windows matching the training intervals of the models, i.e., each model 𝑚 𝑟 denes an evaluation windo w from 𝑡 𝑠 𝑟 to 𝑡 𝑒 𝑟 , is not fair across pipelines. Hence, we rst need to decouple determining evaluation intervals from triggering and then dene which model to use for which window . W e dene an evaluation inter val as a 3-tuple ⟨ 𝜏 𝑠 , 𝜏 𝑎 , 𝜏 𝑒 ⟩ . 𝜏 𝑠 and 𝜏 𝑒 dene the start and end of the range from which we consider evaluation data. 𝜏 𝑎 denes the anchor point of the interval, which serves as a reference timestamp that we use in further denitions. Typically , 𝜏 𝑎 = 𝜏 𝑠 or 𝜏 𝑎 = ( 𝜏 𝑠 + 𝜏 𝑒 ) / 2 . W e dene an interval generation function 𝜑 as a procedure that generates inter vals on the evaluation dataset, i.e ., it outputs a sequence of evaluation intervals 𝜏 𝑠 1 , 𝜏 𝑎 1 , 𝜏 𝑒 1 , . . . . W e also use 𝜑 to denote this sequence. The generated intervals can, e.g., b e xed-length sliding- or 2 W e use the terms training and retraining interchangeably . Proc. ACM Manag. Data, V ol. 3, No. 1 (SIGMOD), Article 55. Publication date: February 2025. 55:6 Maximilian Böther et al. training interval evaluation interval trigger / model training ( 𝑚 𝑖 , 𝜑 𝑗 ) ∈ M × 𝜑 currently active model for 𝜑 𝑗 𝜏 𝑎 ( 𝑎𝑛𝑐ℎ𝑜 𝑟 ) 2012 2013 2014 2015 2016 2017 𝑇 1 𝑟 1 at 𝑡 𝑒 1 𝑇 2 𝑟 2 at 𝑡 𝑒 2 𝑇 3 𝑟 3 at 𝑡 𝑒 3 𝑇 4 𝑟 4 at 𝑡 𝑒 4 𝜑 1 𝑇 5 𝑟 5 at 𝑡 𝑒 5 𝜑 2 𝜑 3 𝜑 4 𝜑 5 𝜑 6 model 𝑚 1 𝑚 2 𝑚 3 𝑚 4 𝑚 5 Fig. 2. Visualization of finding the currently active model. tumbling windows. For any metric 𝜎 (e .g., accuracy) and a model 𝑚 𝑥 ∈ M 𝑃 , let 𝜎 ( 𝑚 𝑥 , 𝜑 𝑖 ) denote the score of model 𝑚 𝑥 on data with timestamps in the 𝑖 -th evaluation inter val. W e dene the evaluation matrix 𝑚 𝜎 ,𝑃 ∈ R | M 𝑃 | × | 𝜑 | where, for all 𝑖 ≤ | M 𝑃 | and 𝑗 ≤ | 𝜑 | , 𝑚 𝜎 ,𝑃 [ 𝑖 , 𝑗 ] = 𝜎 𝑚 𝑖 , 𝜑 𝑗 . Each model is evaluated on each window . From matrices to sequence. Currently , each pipeline is associate d with a 2-dimensional evaluation matrix (models and inter vals). When comparing multiple pip elines, we have to consider another dimension for the pipelines themselves. T o reduce the numb er of dimensions, we propose to dene a composite model per pipeline. Formally , the composite model is a partial mapping 𝜇 𝑃 : 𝜑 → M 𝑝 . This allows us to condense the accuracy matrix 𝑚 𝜎 ,𝑃 ∈ R | M 𝑃 | × | 𝜑 | into a sequence of evaluation results Λ 𝜎 ,𝑃 = 𝑚 𝜎 ,𝑃 [ 𝜇 𝑃 ( 𝑖 ) , 𝑖 ] | 𝑖 ≤ | 𝜑 | ∈ R | 𝜑 | . This sequence represents the temporal performance of a pipeline. W e call it the comp osite mo del performance, though the composite model is formally a mapping. W e propose and focus on two variants of composite models. In the currently active composite model, ev er y evaluation window uses the most recent model that has completed training prior to the anchor of the evaluation interval, i.e ., 𝜇 𝑎𝑐𝑡 𝑖 𝑣 𝑒 𝑃 ( 𝜑 𝑖 ) = arg max 𝑚 𝑥 ∈ M 𝑃 { 𝑡 𝑒 𝑥 | 𝑚 𝑥 = 𝑤 𝑥 , D 𝑥 , 𝑡 𝑠 𝑥 , 𝑡 𝑒 𝑥 ∧ 𝑡 𝑒 𝑥 ≤ 𝜏 𝑎 𝑖 } . Inter vals whose anchor is before the rst model, i.e., when no mo del training has nished before the evaluation data comes, do not have a currently active model. It is a modeling de cision of the interval generation function whether the anchor point lies on the left boundar y of the interval, or , e.g., in the center , to allow for a mix of out-of-distribution and in-distribution data. Figure 2 visualizes this with a Gantt chart of the model and evaluation intervals. In this example, we set 𝜏 𝑎 = 𝜏 𝑠 . The training data intervals end with a trigger , indicated by the blue diamond . Conceptually , each evaluation interval searches (arro ws to the left) for the rst model that has nished training before its anchor at the beginning of the b ox. The model associated with the trigger belonging to the dashed vertical line is marked as currently active for the e valuation inter val, indicated by the orange diamond . A model can be active for several ( 𝑟 3 ) or no intervals ( 𝑟 5 ). The curr ently trained composite model is the model follo wing the curr ently active model. Let 𝑖 be the index such that for the 𝑗 -th interval 𝜇 𝑎𝑐𝑡 𝑖 𝑣 𝑒 𝑃 ( 𝜑 𝑗 ) = 𝑚 𝑖 . W e dene 𝜇 𝑡 𝑟 𝑎𝑖𝑛 𝑃 ( 𝜑 𝑗 ) = 𝑚 min ( 𝑖 + 1 , | M 𝑃 | ) . For the e dge case when the currently active model is undened, we set the most recent mo del as currently trained. The curr ently trained model potentially benets from training on data distributions similar to those in the evaluation set. W e will see an example of the dierence between 𝜇 𝑡 𝑟 𝑎𝑖𝑛 𝑃 and 𝜇 𝑎𝑐𝑡 𝑖 𝑣 𝑒 𝑃 Proc. ACM Manag. Data, V ol. 3, No. 1 (SIGMOD), Article 55. Publication date: February 2025. Modyn : Data-Centric Machine Learning Pipeline Orchestration 55:7 in Section 7. These denitions emphasize the current performance of a pipeline. They might not capture other aspects such as retention of previous knowledge . Further dimensionality reduction. For a comparative analysis of pip elines, plotting the temporal accuracy of composite models, i.e., plotting Λ 𝜎 ,𝑃 , may provide visual insights. T o distill this information into a single metric, the series Λ 𝜎 ,𝑃 ∈ R | 𝜑 | (the composite model accuracy) can b e averaged into a pipeline score Σ 𝜎 ,𝑃 ∈ R to obtain an indication of the general pipeline performance over time. This is how we calculated the mean in Figure 1 to compare pipeline performance. Furthermore, this scoring is useful for ranking pipelines in an A utoML setting [40, 89]. Cost trade-o and pipeline comparison. Let 𝒫 be a set of pipelines, each assigned a xed cost 𝑃 𝑐 . Costs can be measured by the number of triggers, the number of samples trained on, or wall clock run time. The number of triggers is only fair when all pipelines use the same selection policy on only the ne w data since the last trigger as in this case each sample from the entir e dataset is traine d on at most once. The number of samples is fair across dierent selection policies but disregards overheads such as the cost of the triggering and selection policies. W all clock time covers everything, but requires pipelines to be run on isolated machines. Having assigned a cost, we can build the cost-accuracy feasible set F 𝒫 = Σ 𝜎 ,𝑃 , 𝑃 𝑐 | 𝑃 ∈ 𝒫 . There might b e several pareto-optimal pip elines. For visually comparing pip elines, we can plot this feasible set and get an understanding of how dierent pipelines perform with r esp ect to the tradeo between training cost and predictive performance. 4 Modyn ’s Design Modyn is designed to implement the pipeline model describ ed in Section 3. Hence, the core unit of execution in Modyn is a pipeline. Users declaratively specify the pipeline which allows to decouple the pipeline policy from how it gets executed and lets users fo cus on model engineering. Still, Modyn allows users to add new models and policies as Python mo dules and oers abstractions to support this (Section 5). Modyn is designed to ll the gap identied in Section 2.2. T o allow users to control which individual data samples to access for training, Modyn ’s storage component assigns each sample a unique ID and associates metadata with each ID. Instead of se eing the dataset as a blob of data, Modyn oers a get_sample_by_id interface to fetch data according to the selection policy during training. Next, to support the rich landscape of selection and triggering policies in its declarative interface, Modyn introduces a taxonomy of these policies (Se ction 5) and implements abstractions to apply these techniques to common DNN data modalities like text or images. Furthermore, w e design Modyn ’s rich evaluation infrastructure to support the ideas outlined in Section 3. Figure 3 shows Modyn ’s components and the basic ow of pipeline execution. Modyn is posi- tioned between the preprocessing of the data and the serving of models. Modyn ingests data from a data source, such as stream processing engines (e.g., Flink [ 17 ]) or batch processing framew orks (e .g., Spark [ 123 ]). W e assume that expensive preprocessing operations, e.g., ltering and do wnscaling a stream of images, happ en oine, i.e., b efore ingestion into Modyn . Online ML preprocessing (e .g., image augmentation) happ ens within Modyn . While data preprocessing for ML provides challenges in itself [ 119 ], existing work addresses those challenges [ 25 , 33 , 92 ]. Modyn expects a labeled input data stream. Such labels can be either obtained automatically (e.g., track which advertisements a user clicked on) or fr om human-in-the-loop annotation systems [ 116 ]. Modyn outputs a stream of traine d models that can then be deployed, using tools like T orchServe [ 84 ], BentoML [11], or Triton Infer ence Ser ver [71]. Overview of control ow and data ow . The user submits a pip eline via Modyn ’s CLI to the super visor 0 , which implements the triggering policy and orchestrates the execution. Modyn Proc. ACM Manag. Data, V ol. 3, No. 1 (SIGMOD), Article 55. Publication date: February 2025. 55:8 Maximilian Böther et al. Fig. 3. Modyn ’s system design. stores data samples streaming in from external sources in its storage, which assigns a unique key to each sample. The data storage component informs the super visor about new samples by their key 1 . The supervisor checks whether any data point in the incoming batch causes a trigger and forwards potential triggers and the sample keys to the selector 2 , which implements the data sele ction policy . Upon trigger , the supervisor contacts the trainer ser ver to start a training pr o cess 3 . The trainer server requests the trigger training set (keys and weights to train on) from the selector 4 . Then, it loads the actual data from the storage 5 and, depending on the conguration, also the previous model from the model storage . The trainer ser ver then runs a training according to the conguration. The trained model is then stored in the model storage component 6 . The supervisor can send an evaluation request to the evaluator 7 , which receives the newly trained model from model storage 8 , evaluates it and returns the results 9 . The supervisor can also receive the new model for new triggering decisions 10 . Finally , the model can be deployed. Example pipeline. Figure 4 shows a declaratively-specied Modyn pipeline. At minimum, a description comprises (1) the model specication, (2) the training dataset and a corresponding bytes parser function that denes how to convert raw sample bytes to model input, (3) the triggering policy , (4) the data selection policy , (5) training hyperparameters such as the the learning rate and batch size, (6) training conguration such as data pr o cessing workers and number of GP Us, and (7) the model storage p olicy , i.e., a denition how the models are compressed and stored. A training may involve ne-tuning a model or training a model fr om scratch with randomly initialized weights; this is a conguration parameter in the triggering policy . The very rst training can run on a randomly initialized or externally provided model. 5 Implementation W e describe the super visor and triggering p olicies (Section 5.1), the selector and data selection policies (Section 5.2), data retrieval (Section 5.3), and the remaining components (Section 5.4). W e build Modyn with the goal of providing an easy-to-use , extensible , and ecient execution platform for data-centric ML pip elines. W e aim to build an ecosystem around Modyn to facilitate policy exploration in practical use cases of ML training in growing data envir onments. T o balance performance and ease-of-use, Modyn components are either written in C++ (e.g., storage ser vice), purely in Python (e.g., trainer ser vice), or Python with C++ extensions (e.g., selector service). While co de on the hot path of data fetching is written in C++ to avoid stalls, the pluggable algorithm modules are written in Python. Having a clean Python interface allows ML researchers to implement policies in a familiar language without worrying about systems aspects. For compatibility , we use existing tooling like PyT orch where possible. Proc. ACM Manag. Data, V ol. 3, No. 1 (SIGMOD), Article 55. Publication date: February 2025. Modyn : Data-Centric Machine Learning Pipeline Orchestration 55:9 1 model : 2 id : ResNet18 3 config : 4 num_classes : 42 5 data : 6 dataset_id : mnist 7 transformations : [ "transforms.Normalize(...)" ] 8 bytes_parser_function : | 9 def bytes_parser_function(data: memoryview) -> Image: 10 return Image.open(io.BytesIO(data)).convert("RGB") 11 trigger : 12 id : DataAmountTrigger 13 num_samples : 100 14 training : 15 use_previous_model : True 16 batch_size : 1234 17 optimizers : ... 18 optimization_criterion : 19 name : "CrossEntropyLoss" 20 selection_strategy : 21 name : "CoresetStrategy" 22 storage_backend : "database" 23 tail_triggers : 0 24 presampling_config : ... 25 downsampling_config : ... 26 model_storage : 27 full_model_strategy : 28 name : "PyTorchFullModel" 29 incremental_model_strategy : 30 name : "WeightsDifference" 31 evaluation : ... Fig. 4. Excerpt from an example Modyn pipeline. Modyn uses gRPC and FTP for data and control ow , and supports Docker Compose for deploy- ment. The codebase, totaling ca. 20 000 lines of Python and 2 500 lines of C++ (excluding tests), is publicly accessible 3 , and undergo es rigorous unit and integration testing, as well as linting, establishing it as more than a research pr ototyp e. T o overcome the limitations impose d by the Global Interpreter Lock (GIL) in Python, our im- plementation employs a hybrid processing and threading approach. It utilizes a gRPC ThreadPool and multiprocessing.Processes , le veraging the SO_REUSEPORT socket option. This combination enables the system to handle multiple gRPC requests concurrently , achieving true parallelism despite the GIL constraints. 5.1 Supervisor The sup ervisor orchestrates the execution of pipelines. Pipelines are submitted via Modyn ’s CLI. The CLI is the interface between supervisor and user . Modyn uses Pydantic models [ 83 ] to guide users in specifying their pipelines. For each submitted pipeline, the super visor spawns a PipelineExecutor , which implements a state machine following the control ow outlined in Section 4. The client frequently polls the supervisor for the current status and displays the current pipeline stage and training progress. Triggering policies. During execution, the supervisor decides to trigger using a triggering policy . Modyn currently supports amount-, time-, performance-, and drift-based triggering policies. Amount triggers re ev er y 𝑛 data points, while time triggers re after a time interval has passed. Performance triggers trigger when the accuracy degrades. They require labels which might arrive 3 A vailable at https://github.com/eth- easl/modyn. Proc. ACM Manag. Data, V ol. 3, No. 1 (SIGMOD), Article 55. Publication date: February 2025. 55:10 Maximilian Böther et al. late in practice [ 97 ]. Drift triggers, however , work unsuper vised and detect covariate shift , i.e., they compare the distribution of the incoming data to some reference data. W e leverage the evidently [ 30 ] and alibi-detect [109] libraries for calculating similarity metrics and hypothesis testing. Data drift variants. For unstructured data such as images or text, we rst need to transform it into a latent emb edding space, and optionally project it to lower dimensionality , e.g., using principal component analysis (PCA). Modyn uses the most recent model of the pipeline to generate embeddings. Modyn builds up a sliding window of curr ent data and reference data ( current data window at the last trigger ). In a dened inter val, a similarity metric between the two windows is obtained. Based on the similarity metric, we need to make a binar y decision about whether there is drift between the reference and current data, i.e., whether we should re a trigger . Modyn supports threshold-based decisions, i.e., we trigger when the metric is higher than a congurable threshold. As this threshold needs to be tuned for each dataset and metric, Modyn also supports dynamic decision making ( AutoDrift ). In this setting, Modyn keeps track of a window of previously observed drift scores and triggers when a new drift score is in a congurable percentile of these scores as a simple outlier detection. Similarity metrics. While tabular data, as used in previous work [ 88 , 94 , 113 ], can be used directly , for images and text, Modyn generates embeddings as dense latent representations, and calculates drift metrics on those embeddings. The embedding dimensions become features as in the tabular data domain. W e nd that some distance metrics, such as the Kolmogorov–Smirno v or Hellinger distance [ 27 ], are commonly used for univariate distributions. In univariate drift detection, we derive one distance metric p er feature , e.g., for 512-dimensional embeddings, we obtain 512 distance values that need to be reduced into a scalar . Multivariate extensions or natively multivariate metrics provide a scalar distance value , even for multivariate distributions. W e focus on the multivariate maximum mean discrepancy (MMD) metric [ 34 ] since we did not nd readily available multivariate implementations of other metrics. Additionally , it has not been explored how to best reduce multiple univariate metrics into a scalar value, how to decide whether the data has drifted, and MMD performed b est in initial experiments. Open questions. Using drift detection on unstructured data such as images is an active area of research. First, the impact of the embedding space, i.e., which model is used to generate emb eddings, has not been explored. Se cond, it has not been studie d what is a sensible interval to run dete ction, what metric to choose in which scenarios, and how big the windows should be. Last, it is not clear what is the best way to make the binary triggering decision, and it likely depends on the metric, dataset, embeddings, etc. Note that our goal is to demonstrate how Modyn enables the use and exploration of dierent triggering policies rather than advocating for a particular policy . W e are actively exploring these questions and discuss the rst results in Section 7.2. Execution modes. Modyn advocates the principle of what you evaluate is what you deploy . Managing separate codebases for research and production is error-prone. Hence , any pip eline can be executed in either experiment mode or production mode . In production mode, the data storage informs the super visor when ne w data points arrive. In experiment mo de, the data storage simulates new data points streaming in by announcing existing data points as “new” to the supervisor . The experiment mode can b e used to (re)play traces and compare how p olicies perform given the same environment. The insights gained from these experiments can then be used to nd a conguration for production. 5.2 Selector The selector implements data selection policies, which generate the trigger training set D 𝑟 upon the 𝑟 -th trigger per pipeline. Proc. ACM Manag. Data, V ol. 3, No. 1 (SIGMOD), Article 55. Publication date: February 2025. Modyn : Data-Centric Machine Learning Pipeline Orchestration 55:11 Fig. 5. Data selection f low in Modyn . 5.2.1 Selection p olicies. A selection policy denes what data to train a model on upon trigger . Every sele ction policy has a window upon the past data, i.e., a pool of data we could train on. This window can be innite (“retrain” on all past data), just include the data since the last trigger (“netune” on ne w data), or include all data up to 𝑛 previous triggers. In order to either reduce the amount of data that we train on or increase information retention, we can then apply sele ction algorithms on this window of data. In the following, we discuss a taxonomy of selection policies. Presampling and downsampling. W e identify two types of sele ction algorithms. Presampling algorithms do not require any information from the model forward pass and are implemented at the selector . Examples include ingesting older samples to increase information retention, sampling in a class-balanced fashion, or use-case sp ecic sampling (e.g., incr easing the weight of pictures at night for autonomous driving pipelines). Downsamplers are general-purp ose techniques which leverage information from the mo del forward pass to pick the b est samples to use for the backward pass [ 22 , 47 , 63 , 79 ]. Downsampling happens at the trainer server . For example, the DLIS policy [47] samples data p oints based on the gradient norm obtained during the forward pass. Any downsampler can be combine d with an oine or online presampling policy . O line/online presampling. Any presampling policy is oine or online. Oine p olicies maintain state by storing all samples during a trigger and running the actual selection on trigger . For example, a strategy sampling class-balanced from the data windo w requires storing all data rst and only samples on trigger after determining the available classes. Online policies perform the sampling directly as data is received. Examples for online policies include continual learning algorithms such as GDumb [81], CLiB [50], and GSS [4]. Supported p olicies. Currently , for presampling, Modyn supports class-balanced sampling (similar to GDumb [ 81 ]), sampling uniformly at random, and trigger-balanced sampling. For down- sampling, Modyn supports RS2 [ 73 ], loss sampling [ 47 ], DLIS [ 47 ], uncertainty downsampling [ 22 ], CRAIG [ 63 ], and GradMa tch [ 48 ]. It also implements a warmup p eriod of not using sampling for the rst triggers to improve upon the initial model more quickly . 5.2.2 Implementation of policies. Presampling and downsampling policies are implemented as Python classes, each category sharing its own common interface. Modyn provides infrastructure , e.g., for storing state , to help engineers and researchers port algorithms. The overall o w of data selection is shown in Figure 5, which we detail in the following paragraphs. When informed about new samples, the selection policy updates its state using a metadata backend mo dule pro vide d by the selector . This state is used to calculate the set D 𝑟 on trigger 𝑟 . This set is then stored on disk using an extension called TriggerSampleStorage (Section 5.3). Proc. ACM Manag. Data, V ol. 3, No. 1 (SIGMOD), Article 55. Publication date: February 2025. 55:12 Maximilian Böther et al. Backends for presampling. For implementing presampling strategies, Modyn provides tw o backends that share an interface to store the state of the sampling strategy . The rst backend is the Postgres backend, which persists the samples to a Postgres table [ 102 ]. The advantage of this backend is the exibility for implementing selection policies, since many policies can be expressed using SQL statements. W e use SQLAlchemy [ 9 ] to allow for easy quer ying of data. Modyn provides quer y boilerplates using inheritance hierarchies, e.g., in order to implement a random sampling balanced across some parameter such as trigger or label, the developer inherits from the AbstractBalancedStrategy and species the column to balance on. The disadvantage of the Postgres backend is the slow insertion speed. Every sample has to be written into the database. W e optimize the ingestion with Postgres’ table partitioning mechanism. W e partition the state table rst by pipeline, then by trigger , and then round-robin with a mo dulus of 16. This avoids the degrading of insertion performance with growing number of triggers, since every trigger denes a new physical table. In order to further optimize the insertion sp eed, we use SQL bulk insertion and run several insertion threads for ne w batches of incoming keys. For datasets with many samples, e.g., recommendation system datasets, using Postgr es can b e very expensive. W e observe maximum insertion speeds of around 100 000 insertions/second. For simple strategies not requiring complex SQL queries ( e.g., train on all the data since the last trigger), or if performance is key , Modyn oers a local backend. This is a C++ e xtension that writes data multithreadedly to a local disk, such as a high performance NVMe drive. These binary les are written and read avoiding unnecessar y memory copies. Strategies such as training on all data, uniform presampling, or mixing old and new data can be implemente d easily on this backend, trading o ease of implementation for speed. Each workload has dierent requirements and Modyn provides building blocks for these use cases. Implementing downsamplers. Downsampling p olicies cannot b e executed at the selector and need supp ort from the trainer server . Modyn ’s training loop has a comp onent which executes the downsampling policy specied in the pipeline. As shown in Figure 5, the presampled trigger training set is transferred to the trainer server , where it is then downsampled. Analogous to oine versus online presampling, downsamplers can be run in either sample-then- batch (StB) or batch-then-sample (BtS) mode. Some downsamplers like RHO-LOSS [ 62 ] explicitly are proposed with BtS or StB mode, and others like DLIS [ 47 ] can be used in both modes. In BtS, the training loop runs inference on a batch and then selects a subset of that batch. This is repeated until we accumulate a new batch of the original batch size, on which we then perform a backward pass. In StB mode, the training loop starts with a sampling phase in which it continuously informs the downsampler about the forward pass, allowing the downsampler to build up state for all samples. Once this state is complete, it generates the downsampled dataset, and we run training on these keys. This sampling phase can be performe d ev er y training epoch or less often. Both StB and BtS mode are abstracted such that engineers just have to implement one version of the downsampling policy . While there can be multiple epochs of training per trigger , Modyn applies the budget constraint per epoch. For example , when we have 1 000 samples, a 10 % budget, and 10 epochs per trigger , we train for 10 epochs of 100 samples each, instead of a single epoch of 1 000 samples. Maintaining the epoch boundar y allows, e.g., consistent setups for learning rate scheduling. 5.3 Fast Data Retrieval Modyn supports dierent data selection policies, which means that the trigger training set is an arbitrary collection of previously stored samples. Regardless of the sele ction policy , the result is a list of training items, i.e., IDs of samples, to train on. This is a shift in architecture from traditional ML deployments, where the training data is typically a big chunk of data that can be read sequentially . Instead, Modyn supports sample-le vel data selection , i.e., retrieving samples based on their identier . Proc. ACM Manag. Data, V ol. 3, No. 1 (SIGMOD), Article 55. Publication date: February 2025. Modyn : Data-Centric Machine Learning Pipeline Orchestration 55:13 Fig. 6. The architecture of the OnlineDataset . For big datasets with potentially billions of small samples like in recommendation systems, this can lead to data stalls during training. In this subsection, we describe how w e engineer Modyn to av oid data stalls while supporting sample-level data selection. W e rst describe the storage component (Section 5.3.1). Then we describe the OnlineDataset abstraction that loads keys from the selector , payloads from storage, parses the bytes, and returns tensors into the training loop (Section 5.3.2). W e furthermore explain how the selector quickly r eturns the list of keys (Section 5.3.3), and how , given a list of keys, the storage quickly returns the r e quested data (Section 5.3.4). 5.3.1 Data Storage. The storage is entirely written in C++ as we found the data wrangling to be particularly expensive in Python. A Postgres database is use d to keep track of all available samples. Each ingested le can contain one or more samples, e.g., a JPEG le contains exactly one sample, while a CSV le contains potentially hundreds of thousands of samples. When the comp onent encounters a new le, it extracts all the samples in that le and inserts the le, the sample IDs, and the labels into the database. The storage makes use of FileSystemWrappers which abstract I/O operations such as reading byte streams from les. Currently , Modyn implements a le system wrapper for the local le system, but this can b e easily extended to support cloud le systems like S3. The storage then uses FileWrappers which abstract how to extract individual samples and labels from les. Examples include the CSVFileWrapper for variable-length CSV data, the BinaryFileWrapper for xed-size columnar data, often used in recommendation systems training, and the SingleSampleFileWrapper for les containing exactly one sample, such as images. The C++ implementation uses SOCI [ 99 ] to operate on the Postgres database . T o optimize the ingestion and query performance, we partition the tables. Since for datasets with billions of samples, even SQL bulk insertion is too slow , we use the Postgr es internal COPY command and stream the data over the raw connection. 5.3.2 The OnlineDataset . The OnlineDataset abstracts away the interaction with the dierent gRPC components from the training loop. The training loop (Section 5.4) uses a standard PyT orch DataLoader to fetch batches to train on. It is not aware of the ongoing netw ork communication. This new abstraction is necessar y due to Modyn ’s sample-level data selection. W e cannot just load a big chunk of data and train on it. Instead, we have to load the data according to the list of keys in the trigger training set. The PyT orch DataLoader uses multiple workers. W e split the trigger training set across these w orkers. The trigger training set consists of xed-size partitions (Section 5.3.3). Each worker gets an equal share of each partition. The data loader fetches batches from the workers in a round-r obin fashion. Proc. ACM Manag. Data, V ol. 3, No. 1 (SIGMOD), Article 55. Publication date: February 2025. 55:14 Maximilian Böther et al. In order to av oid data stalls when the data loader r equests data, each worker (or dataset instance) implements a prefetching mechanism. This architecture is depicted in Figure 6. Each worker has a partition buer of a congurable size. Upon creation, a worker spawns a congurable number of prefetching threads that issue gRPC r e quests. The size of the buer denes ho w many partitions w e prefetch overall, while the number of threads denes how many partitions we prefetch in parallel. T o fetch a partition, we rst obtain a list of keys from the selector , and then ask the storage for the payloads corresponding to these keys. The storage uses gRPC streaming to transfer the payloads to the workers. As soon as data is available in the buer , the main thread of the worker fetches the payload, applies transformations, and yields it to the data loader . This is important, since waiting for a partition to nish transferring would make the batch latency depend on partition size. The only exception is when if shuing is enabled, i.e., we need to shue the samples in each partition and the order of partitions, as we need to alter the sample order . The rst transformation always is a user-dened bytes parser function dening how to transform the bytes of the payload to a tensor , e.g., by deco ding the bytes of a JPEG image or decoding a U TF-8 string. After wards, other transformations are applied as dened by the pipeline, such as image augmentations or tokenization. 5.3.3 Data partitioning. W e need to retrieve the trigger training set, i.e., the keys to train on, as fast as p ossible. Instead of relying on a database, we persist the xe d trigger training set after presampling to disk using the TriggerSampleStorage (TSS). The TSS is a fast C++ extension that persists the list of keys and weights (c.f. Section 3) output by the presampling strategy to disk. The TSS uses the same binary le format as the local backend. W riting to disk. The selection strategy does not pass all keys and weights at once to the TSS. Instead, it passes the keys as multiple partitions. Each partition is a xed-size set of keys. For example, if the trigger training set consists of 1 000 keys and the partition size is 100, the strategy will pass 10 partitions to the TSS. This avoids high memor y utilization by limiting the amount of keys loaded at once. Furthermore, the partitions provide a xed-size unit of data transfer for the trainer server . The backends provide support for partitioning, i.e ., limiting the memory usage. For the Postgres backend, we use Postgres’ server-side cursors. For the local backend, we read the corresponding data via osets. When the TSS writes the nal partition to disk, 𝑛 threads ( within the C++ extension) write the keys and weights of the partition to disk in parallel. Retrieving keys. When retrieving partition data for a worker , we iterate over all les for this partition. The requesting worker ID and the number of total samples correspond to a list of samples for this worker . Howev er , as the number of dataloader workers does not necessarily match the number of threads we used to p ersist the training set to disk, we have to potentially parse subparts of les and correctly and eciently assemble each worker’s share of a partition. This is hidden in the C++ extension and only the nal list of keys is returned. 5.3.4 Storage data retrieval. What makes the storage challenging is that it can receive requests with arbitrary sets of sample keys. When samples are requested, they are distributed across a set of les, and each may be residing at arbitrary locations within those les. The storage needs to eciently build a buer of data that makes it look as if the data came from one continuous le that contained all requested samples. When a worker sends a list of keys to the storage for retrieval, the storage partitions this list into 𝑛 ≥ 1 parts to parallelize the retrieval from disk. Then, each thread obtains lab els and a source le for each sample from Postgres, grouped by le. For each le, it instantiates a FileWrapper and extracts all samples in that le into a send buer . When that buer is full, or once all les have been iterated through, the thread emits the buer to the worker . Besides parallelization, major speed gains for each thread stem from optimized FileWrapper implementations. For example, the Proc. ACM Manag. Data, V ol. 3, No. 1 (SIGMOD), Article 55. Publication date: February 2025. Modyn : Data-Centric Machine Learning Pipeline Orchestration 55:15 BinaryFileWrapper has an optimized bytes-to-int parsing function based on the endianness the le was written with, and operates on std::ifstream s to not load the entire le into memory . 5.4 Other Components 5.4.1 Trainer Ser ver . The trainer server spins up trainers when requested, which execute a general- purpose training loop. Modyn currently implements a Py T orch-based trainer , but its design is agnostic to the ML framework. The trainer supports a variety of features like mixed-precision training or learning rate schedulers with correct support for data sele ction [ 73 ]. Modyn comes with some models (e.g., ResNets [ 38 ], DLRM [ 69 , 72 ], and transformers [ 115 ]) and other models can be added easily . The trainer also performs online featurization, such as image augmentation. 5.4.2 Model Storage. This component is responsible for model storage and retrieval. It supports full model and incremental compression policies. The full model policy denes how to compress the entire model such that it can be restored from just the le itself, analogous to an I-frame in video encoding. Furthermore, the model storage can employ an incr emental policy , which activates a congurable number of times b etween full model steps. In this mo de, Modyn stores just the delta from the base model based on a sp ecied dierence operator . This is similar to a P-frame in video encoding. For full model policies, the model storage currently supports both the native Py T orch format and a custom, stripped binar y storage format, with or without zip compression. For incremental policies, it currently supports an xor and subtraction based dierence operator . Model compression over time is an active ar ea of research [36, 103]. 5.4.3 Evaluator . Each model trained during a pip eline can be evaluated on several evaluation intervals for multiple evaluation metrics. Modyn ’s evaluator implements various interval generation functions 𝜑 , e.g., tumbling- or sliding windows. It also supp orts both decomp osable (e .g., accuracy) and holistic metrics (e .g., ROC-AUC). 6 Benchmark Suite A major hurdle for research on growing datasets is the scarcity of publicly accessible datasets that encapsulate temporal dynamics and distribution shifts. Modyn incorporates a b enchmark suite that curates datasets, pipeline congurations, and models to run pip elines with. It comes with the necessary tooling for making them available on the user’s machine as some datasets involv e post-processing and metadata scraping. The suite includes: (1) The Wild-Time benchmarking suite [ 121 ]: A compilation of ve datasets, ranging from small to medium in size, each exhibiting distribution shifts. (2) Kaggle arXiv and HuffP ost datasets: The arXiv and HuffPost datasets from Wild- Time only have coarse-grained timestamps on a year resolution and have been ltered by unclear criteria. Modyn provides tooling to generate full, high resolution v ersions using the source data from Kaggle [6, 64]. (3) The Criteo 1 TB dataset [ 23 ]: The Criteo click stream dataset for recommendation systems training provides user data ov er 24 days, with roughly 180 million samples p er day . (4) The CGLM dataset(s) [ 80 ]: The paper on CGLM classies images from landmarks on Wikipe dia and uses the upload timestamps. Since the original data is not accessible, Modyn provides an open-source reproducible script and pre-scraped metadata to generate dierent versions of the CGLM dataset, e.g., by using the clean or non-clean and hierchical or non-hierarchical version of the original (non-continual) CGLM dataset [87, 114]. (5) The CLOC dataset [ 16 ]: CLOC is a big continual learning dataset on images with distribution shift. Modyn supports the version processed by Hammoud et al. [35]. Proc. ACM Manag. Data, V ol. 3, No. 1 (SIGMOD), Article 55. Publication date: February 2025. 55:16 Maximilian Böther et al. While such data often is business-critical, to facilitate future research, we call for more datasets with distribution shift to be released. Releasing such datasets can help resear ch to solv e meaningful problems for practice. Modyn comes with tooling for analyzing pipelines. It pro vides an interactive dashboard based on Dash/Plotly that allows users to (a) analyze single pipelines, i.e., dive into the model and system metrics, and (b) compare pipelines to understand which policies perform b est. Most plots in this paper have rst been explored using this dashboard. 7 Evaluation W e evaluate Modyn to answer the following three questions: (1) How do data selection policies inuence accuracy? (2) How do dierent triggering policies compare? In particular , can drift triggers be used to reduce pipeline cost while keeping accuracy? (3) What is the impact of Modyn ’s parallelism, partitioning, and pr efetching optimizations and ho w should the corresponding parameters be set to maximize thr oughput? How does the per-sample data ingestion throughput compare to reading data sequentially from local storage? For all experiments, we use a ser ver with two 16 Core AMD EPY C 7313 CP Us, 256 GB DRAM, a 4 TiB Samsung MZQL23T8HCLS NVMe, and a N VIDIA RTX 3090 GP U. W e use gRPC 1.64.1, Postgres 15.2, Py T orch 2.2.1, NVIDIA GP U driver 545.23.06 with CUD A 12.3, on Ubuntu Ser ver 22.04 with kernel 5.15. Modyn is compiled with GCC 12 and -O3 -march=native . 7.1 Data Selection In this subsection, we explore the impact of data selection policies on pip eline accuracy . Each data selection policy nee ds to dene a window of data, a presampling, and a downsampling policy . W e pick the “netuning” setting, i.e., we netune the model from the previous trigger and set our window to contain the data since the last trigger . W e mostly focus on downsamplers (in BtS mode) because they do not require domain-specic knowledge and are built for increasing accuracy on the current distribution. Due to space constraints, w e consider the yearbook dataset [ 121 ] and the CGLM-landmark dataset. W e run all pipelines on three seeds and average the results. W e shue the training data and use the currently trained comp osite model. W e test presampling uniform at random ( uniform , which samples a subset once and then trains on that for several ep ochs), class-balanced presampling, RS2 with and without r eplacement [ 73 ], loss downsampling [ 47 ], DLIS downsampling [ 47 ], and the margin , least conf. , and entropy variants of uncertainty downsampling [ 22 ]. All policies are implemented in less than 130 lines of code. 7.1.1 yearbook dataset. The yearbook dataset classies school yearbook pictures from 1930 to 2013. W e follo w Y ao et al. [ 121 ] and use their “yearbo oknet” CNN and the training hyperparameters with a batch size of 64, SGD with a learning rate of 0.001, and momentum 0.9. W e also use their evaluation split. W e trigger yearly , i.e., with the highest r esolution p ossible for this dataset, train for 5 epochs per trigger , and use two warmup triggers where we do not apply data selection. Due to the small dataset size (33 431 training samples), we use a three year sliding window as an inter val generation function (Section 3) to smo othen the accuracy curve and only run 50 % subset sele ction. Full data training. In Figure 7, we show the accuracy matrix 𝑚 𝜎 ,𝑃 of full data training on yearbook that we seamlessly obtain using Modyn ’s evaluation support. In the 1970s, w e obser ve a drop in accuracy for models trained on data before this period, in-line with numbers from Y ao et al. [ 121 ] (Figure 4a), indicating distribution shift. W e hypothesize that, e.g., changing hairstyles over the decades could cause the shift. A s expecte d, the highest accuracies lie on the diagonal of Proc. ACM Manag. Data, V ol. 3, No. 1 (SIGMOD), Article 55. Publication date: February 2025. Modyn : Data-Centric Machine Learning Pipeline Orchestration 55:17 1930 1950 1970 1990 2010 Evaluation Y ear 1930 1950 1970 1990 2010 Model trained on data up to 50 75 100 Accuracy % Fig. 7. Accuracy matrix for yearbook full data training. the matrix, and we can that see the rst models undert. The low accuracies in the upper left area show how models trained on newer data forget the past distribution. 50 % subset training. Figure 8 sho ws composite model accuracies per selection strategy in a boxplot. Generally , the uncertainty based downsamplers [ 22 ] perform best. Full data training has an av erage accuracy (pipeline score Σ 𝜎 ,𝑃 ) of 92.3 %, and with 50 % selection, entropy reaches 91.4 %, and least conf. and margin reach 91.2 %. RS2 [ 73 ] reaches 88.8 % (w/o replacement)/88.4 % (w . replacement). Loss and DLIS p erform worse than uniform and class-bal. sampling on this dataset. W e investigate why the average accuracy is higher in Figure 9. DLIS ’s performance degrades during the drift period, while margin is able to handle the drift better , similar to full data training. It is able to identify which data points are the most relevant during the shift. O verall, we nd that with uncertainty-based downsamplers we almost reach full-data model accuracy with a 50 % training budget. 7.1.2 CGLM-landmark dataset. This dataset classies pictures from Wikip edia into 6 404 landmark classes. W e follow Prabhu et al. [ 80 ] without ltering out uncleaned data, as downsampling might help to recognize unclean data. Despite applying weaker lter criteria, we obtain 361 671 samples Full Entropy Least conf. Margin RS2 (w/o) RS2 Class-Bal. Uniform DLIS Loss 60 70 80 90 100 Accuracy % Fig. 8. Currently trained composite mo del accuracies for full data training and 50 % data selection on yearbook . Proc. ACM Manag. Data, V ol. 3, No. 1 (SIGMOD), Article 55. Publication date: February 2025. 55:18 Maximilian Böther et al. 1930 1950 1970 1990 2010 Evaluation Y ear 60 70 80 90 100 Accuracy % Full RS2 DLIS Margin Fig. 9. Composite model accuracy over time for DLIS , margin , and RS2 (w/o) on yearbook . before splitting the e valuation set, while Prabhu et al. [ 80 ] claim to obtain 430 K/580 K images (they mention both numbers). Since their data preprocessing is not public, we cannot investigate the dierences. Following Prabhu et al. [ 80 ], we train a ResNet50 [ 38 ] with pretrained weights fr om ImageNet, and use SGD with a learning rate of 0.005 and momentum of 0.9. W e use a batch size of 128 and train for 5 epochs per trigger . W e trigger every year . Since the rst y ears contain very little data, we use 5 warmup triggers. W e evaluate using one year tumbling windows, and report top-5 accuracy since this is a hard classication task with 6 404 classes. W e lter out the years 2005, 2006, and 2020 due to the low number of samples in the evaluation set. Full data training. This dataset is a good example to showcase the dierence between the currently trained and currently active composite model (Section 3.1). As seen in Figure 10, which shows the accuracy sequence Λ 𝜎 ,𝑃 , the currently trained model has a much higher accuracy ov er time, since due to its denition it connects the spikes instead of the p oint after the spike. The currently trained numbers are in-line with the numbers by Prabhu et al. [ 80 ]. The reason why the individual models have spikes is that many classes are mostly prevalent within a single y ear , i.e., there is a concentration of classes on one particular year . W e explain this with the nature of the dataset: it is likely that landmark pages on Wikipedia get updated in batches, e.g., a user updates pictures of the Big Ben in London in 2015, and then they are not updated for several years again. Hence, models overt to the current pre valent classes, forgetting about the old classes. In a traditional continual learning setup, this might not get noticed. Full data training has an average top-5 accuracy of 51.5 %. 50 %, 25 %, and 12.5 % subsets. For training on 50 % subsets, we show the top-5 accuracies of the composite models for the do wnsamplers in Figure 11. For this dataset with shifts in classes, margin performs best (44 %), followed by DLIS (43.1 %) and RS2 (43 %). RS2, which simply goes through 2007 2010 2015 2020 Evaluation Y ear 0 25 50 75 T op-5 Accuracy % Curr . Trained Curr . Active Fig. 10. Visualization of the currently trained vs. active composite model on CGLM-landmark . The grey dashed lines are a subset of the models trained during the pipeline. Proc. ACM Manag. Data, V ol. 3, No. 1 (SIGMOD), Article 55. Publication date: February 2025. Modyn : Data-Centric Machine Learning Pipeline Orchestration 55:19 Full Margin DLIS RS2 (w/o) RS2 Entropy Least conf. Uniform Loss 20 40 60 T op-5 Accuracy % Fig. 11. Composite model accuracies for full data training and 50 % data selection on CGLM-landmark . the dataset as much as possible under the given budget, performs better than more sophisticated techniques like least conf. and entropy . On this dataset, for 25 % subsets, DLIS performs b est (33.7 %), followed by RS2 (33.6 %). margin (32.6 %) performs worse than RS2 . For 12.5 % subsets, uniform , RS2 , and DLIS all reach ar ound 23 % top-5 accuracy . 7.1.3 T akeaways. For yearbook , where w e have covariate shift, do wnsampling helps achieve near full-data performance on a 50 % budget. For CGLM-landmark , where we have prior-pr obability shift, RS2 , DLIS and margin work well. This is motivating since these cheap sampling strategies do not require subject-spe cic knowledge. Future analyses might extend this to information retention [80] or more expensive do wnsamplers like CRAIG [63]. 7.2 Triggering Policies W e explore triggering policies for full data training o n yearbook , using the setup from Section 7.1. W e also explore the Kaggle arXiv dataset to analyze a dataset with a dierent drift pattern and modality (text). W e use the numb er of triggers instead of wall-clock time as a cost metric since we run the experiments on a shared machine. While all pipelines train on the same number of data points, fewer triggers are desirable due to system overhead per trigger and because the underlying assumption is that we cannot netune on the y due to costly deployment checks. A plot of the cost-accuracy feasible set F (Section 3.1) for dierent triggering policies is shown in Figure 12. W e use the currently active model because the currently trained model strongly favors fewer triggers: if we only trigger at the end, the model that has seen all data is by denition the currently trained model for all evaluations and would have very high accuracy . T o fairly compare policies, we only consider the metrics after e ver y pipeline triggered once since ther e is no active model before the rst trigger . Otherwise, the missing initial values would skew the average. In general, the goal is to minimize the number of triggers while maximizing accuracy . Time and amount triggers. In Section 7.1, we trigger every year , which is the highest time resolution for yearbook . Here, we explor e triggering ev er y 3 and 5 years, as well as every 500 and 1000 samples. Notably , triggering yearly is not optimal: T riggering every 3 years yields 26 instead of 75 triggers 4 , but only a slightly lower average accuracy (92.8 % vs. 93.1 %). Triggering every 500 items performs similarly due to the even distribution of samples across years. When we trigger every 5 years, the performance drops to 92.4 % accuracy . 4 As mentioned, we only consider metrics after all pipelines triggered once. While the yearly trigger overall res 84 times, it res 75 times after all triggers have red once. Proc. ACM Manag. Data, V ol. 3, No. 1 (SIGMOD), Article 55. Publication date: February 2025. 55:20 Maximilian Böther et al. 0 20 40 60 80 Number of triggers 86 89 92 95 Mean Accuracy % Time Drift Amount Performance Fig. 12. Feasible set of triggering polices on yearbook . Performance triggers. These triggers re when the model performance on a window drops below a threshold. For the rst 3 500 samples we warm up and trigger at minimum every 3 years. W e use windows of size 250 and test thresholds of 80 %, 85 %, 90 %, and 95 % accuracy . Generally , higher thresholds r esult in more fr e quent triggers and improved performance. Inter estingly , the 80 % threshold performs better than 85 %. The 80 % thr eshold triggers slightly later , and the r esulting model has a better performance than the mo del from the earlier 85 % trigger . Both mo dels do not cross the threshold for some time, such that the ov erall average performance of 85 % is lower . If labels are available , performance triggers are a simple but well-performing triggering mechanism. Drift triggering. The previous triggers rely on prior knowledge: we congure amount and time triggers based on our experience on when drift occurs and how many samples there are. They also assume a constant drift frequency . This does not reect reality where trend seasonality might be irregular [ 60 ]. Performance triggers r e quire labels as well as expected model performance. Drift-based policies do not r equire this prior knowledge, as they use information from the data itself. W e perform the same warm up as for performance triggers. W e test MMD (using alibi-dete ct [ 109 ]) on embeddings without PCA, use threshold-based triggering, and sweep across detection intervals (100, 250, 500), thresholds (0.05, 0.07, 0.09), and windo w sizes (1 day , 5 days) of which we show a subset in Figure 12. W e also test Modyn ’s automatic threshold mechanism that triggers when the drift score is in the top 5 % of the 15 previously observed scores ( AutoDrift ). 1930 1950 1970 1990 2010 Evaluation Y ear 1930 1932 1935 1939 1941 1954 1968 1971 1975 1978 1988 Model trained on data up to 50 75 100 Accuracy % Fig. 13. The dri MMD (250/0.05/1d) triggering policy on yearbook . The black boxes indicate when a mo del is active, i.e ., the time during which it would be used for inference. Proc. ACM Manag. Data, V ol. 3, No. 1 (SIGMOD), Article 55. Publication date: February 2025. Modyn : Data-Centric Machine Learning Pipeline Orchestration 55:21 0 20 40 60 80 100 120 140 160 Number of triggers 56 59 62 65 68 71 74 77 80 Mean T op-2 Accuracy % Time Amount Drift Performance Fig. 14. Feasible set of triggering polices on Kaggle arXiV . On yearbook , the drift policies trigger not as often. A dete ction interval of 250 samples, with a threshold of 0.05 and 1 day window performs well, as it only triggers 8 times while still having an average accuracy of 90.1 %. In Figure 13 we show how the policy navigates around the drift area: consider the model traine d up to 1954. Shortly before the mo del’s performance degrades in the 1970s, a trigger is red (end of black box) and the model up to 1968 is traine d (netuned on the data seen since 1954). Note that the drift policy do es not have information about future model performance and just uses the information from the data itself to make these decisions. The other congurations perform slightly worse as they are less sensitive . For example, increasing the window to 5 days decreases the number of triggers to 3 with an accuracy of 88 %. A larger window size smoothens the drift scores, as the new data needs to b e signicantly dierent from the data in the larger window . The AutoDrift policy performs well, as it triggers 14 times with an average accuracy of 92.7 %. Importantly , this policy does not r e quire information on the drift metric magnitude . It uses a simple outlier detection mechanism, making drift detection more user-friendly . Overall, these results are promising as the drift policies successfully navigate around yearbook ’s drift area without using prior information on the dataset. Kaggle arXiv dataset. The task of this large ( ∼ 2 M samples from 1990 to 2024) textual dataset is to classify paper titles from arXiv into 172 categories. T extual data uses embe ddings for drift detection. The dataset has a dierent drift pattern, as performance slowly degrades over time. W e train a DistilBERT model [ 91 ] with AdamW , learning rate 0 . 00002 , and 5 epochs per trigger . W e evaluate each pipeline using 6 month tumbling windows, and warm up the drift and performance triggers for 20 k samples. W e show the cost-accuracy scatter in Figure 14. As more papers are submitte d each year , the data density increases, and amount triggers re more frequently than time triggers on this dataset. Performance triggers strongly depend on the threshold, as the 75 % threshold triggers 154 times while 70 % triggers only 12 times. The drift trigger with a threshold of 0.0005 and 1 year windows almost matches the 5 year trigger with 6 triggers and 70 % top-2 accuracy . AutoDrift again performs well with 30 triggers and 73.8 % top-2 accuracy , without the need to congure performance- or drift thresholds manually . Overall, for both yearbook and Kaggle arXiv , data-centric triggering can reduce pipeline cost. 7.3 Training Throughput In this experiment, we train a mo del and evaluate the training throughput for dierent parameters to show how Modyn ’s optimizations impact training throughput. Proc. ACM Manag. Data, V ol. 3, No. 1 (SIGMOD), Article 55. Publication date: February 2025. 55:22 Maximilian Böther et al. 1/0/- 1/1/1 4/0/- 4/1/1 4/2/1 4/6/1 4/6/4 8/0/- 8/1/1 8/2/1 8/6/1 8/6/4 16/0/- 16/1/1 16/2/1 16/6/1 16/6/4 Data W orkers / Prefetch Partitions / Parallel Prefetch Requests 1 2 8 1 2 8 Partition Size / Storage Threads 28 53 69 124 155 166 164 85 156 199 238 243 154 207 236 245 243 36 56 101 159 178 174 173 138 213 267 278 277 240 276 295 302 293 44 54 123 170 167 166 158 158 218 242 244 240 140 147 148 148 148 31 44 116 169 171 153 156 198 323 321 301 275 315 445 437 412 390 36 43 130 182 174 161 158 201 285 280 251 245 332 448 450 419 407 44 44 141 168 173 163 156 244 301 297 283 279 379 413 405 385 372 2.5M 100k Fig. 15. Throughput (x1000) for Criteo (Se ction 7.3.1). The first three rows sho w the results for partitions with 100 k samples, and the last three rows for partitions with 2.5 M samples. For each partition, we show results for 1, 2, and 8 threads at storage. Setup. W e congure the Postgres storage instance to use 96 maximum parallel workers, with 2 maximum workers per gather . All components are deployed on the same machine, to avoid measuring network bandwidth instead of Modyn throughput. W e run all measurements three times and report the average results. W orkloads. W e consider two workloads. In the rst workload, we train a DLRM recommen- dation model [ 69 ] on the Criteo 1TB click stream dataset [ 23 ], which provides user data over 24 days, with roughly 180 million samples per day . Given categorical and numerical features, the task is to predict whether a user will click on a suggestion. W e use this scenario because the high numb er of samples with thousands of samples p er le stress-tests Modyn ’s data-retrieval implementation, in comparison to simpler scenarios such as vision models. W e use NVIDIA ’s DLRM implementation [ 72 ] and follow their “small” setup with a batch size of 65 536. At the storage, we use Modyn ’s BinaryFileWrapper , i.e., the 160 B samples are stored in a xed ro w size binary le format, distributed across les containing ca. 180 000 samples each. The bytes parser function at the trainer creates input tensors directly from a memoryview to avoid unne cessary copies. The second workload trains a ResNet50 [ 38 ] on CGLM, as in Section 7.1.2. W e use Modyn ’s SingleSampleFileWrapper , i.e., each sample is stored in one JPEG le. The bytes parser function converts the data to an RGB PIL.Image on which the dataset applies image augmentations (e .g., resize and crop) to generate a tensor . Throughput measurement. The size of each partition, as discussed in Section 5.2, directly dictates the total number of partitions within the trigger training set. Ever y worker gets an equal share of each partition. Note that we do not synchronize CUDA after each batch, i.e., we allow Py T orch to perform computation while the next batch is being fetched. W e do not shue for this benchmark. W e measure the time from the start of the training loop to the last model update and obtain the throughput by dividing the time by the total number of samples in the trigger . 7.3.1 Criteo Throughput. In Figure 15 we show the throughput of training in the Criteo workload. W e test both a partition size of 100 k ( ≈ 1 . 53 batches per partition) and 2.5 M samples ( ≈ 38 . 15 batches per partition). W e rst discuss the results for a single thread at the storage, i.e ., the top row per partition size. Data loader workers. Using one data loader worker and no prefetching, there is no dierence between the small and big partitions. When enabling prefetching of one partition, i.e., loading the next partition into a buer before its batches are requeste d, the throughput increases by 1.89x and Proc. ACM Manag. Data, V ol. 3, No. 1 (SIGMOD), Article 55. Publication date: February 2025. Modyn : Data-Centric Machine Learning Pipeline Orchestration 55:23 1.42x for small and large partitions, respectively . Note that prefetching a partition means that each worker prefetches its share of a partition. The smaller partitions benet more fr om prefetching. Increasing the number of workers generally increases throughput. For example, for the large partitions with one prefetched partition, using four workers improves throughput by 3.84x, using eight workers by 7.34x, and using 16 workers by 1.11x, compared to a single worker . This increase is explained by the ability to fetch the keys and data from selector and storage in parallel, and the parallelization of the bytes-to-tensor transformation. Notably , in contrast to the single worker scenario, the larger partition size has higher thr oughput with multiple workers than the smaller partition size. For example, for 16 workers and with prefetching one partition (16/1/1), the larger partition setting has 2.15x higher throughput than the smaller partition setting. This is because for the small partitions and 16 workers, a partition does not even cov er 10 % of a batch. For larger partitions, the workers have ∼ 2 . 5 batches per partition, which is sucient to saturate the GP U. More w orkers favor larger partition sizes. Additional prefetching. W e can b oth prefetch more partitions and request more partitions in parallel. For the single threaded storage and the smaller partitions, increasing the number of prefetched partitions–while keeping one parallel request–increases throughput, especially for higher number of workers (e.g. 4/6/1, 8/6/1). Howe ver , there are diminishing returns to increasing the number of prefetch partitions. For example, for four workers, going from 1 (4/1/1) to 2 (4/2/1) prefetched partitions increases throughput by 1.25x, but going from 2 (4/2/1) to 6 (4/6/1) only increases throughput by 1.07x. As soon as we ll up the buer faster than data is consumed, there is no benet from further prefetching data. When using more workers, the benet of prefetching more partitions is higher b ecause xed size partitions are distributed across all workers. Prefetching one partition with four workers prefetches the same amount of samples as eight workers that prefetch 2 partitions. Using more parallel prefetch requests does not improve throughput. This is explained by the fact that Modyn ’s components have upper limits of load the y can handle: Postgres has a maximum number of worker threads, the number of gRPC worker threads is limited, and the disk holding the databases and dataset has limited bandwidth. Many parallel requests overload the system. Multi-threaded storage. The data retrieval at the storage can use multiple threads (Se ction 5.3.1). W e nd that using 2 threads increases throughput, but using 8 threads overloads the system and may lead to worse performance. The throughput increases ar e higher for smaller number of workers. For example, for the setting of one worker and no pr efetching (1/0/- ), on the small partitions, parallelism increases throughput by 1.29x and 1.57x for 2 and 8 threads, r esp ectively . For 16 workers (16/0/-), increasing the storage threads from 2 to 8 decreases performance to 0.58x. The reason for the performance decrease with 8 threads is that, while we parallelize data retrieval, there is a limit on the number of parallel Postgres workers. If 16 workers send a r e quest that gets split upon 8 threads, and each thread emits one quer y that executes with 2 workers in parallel, we need 256 Postgres workers, amplied with increasing parallel prefetch requests. Nev ertheless, in the following, we show that w e reach suciently high training throughput. Comparison to local training. W e compare Modyn to local training to quantify its overhead. For this, we read data sequentially from 90 binary les containing 30 M samples. Each dataloader worker is assigned a share of the les. Note that this not only removes the communication and gRPC overhead, but also remov es the sample-level data selection. Modyn loads each sample individually by key , but the local approach loads entire les sequentially and emits all samples in them. The results are shown in Figure 16a. For each number of dataloader workers, we compar e the best thr oughput we measure for Figure 15 against the local throughput. Modyn reaches 98 %, 85.4 %, 77.8 %, and 71 % of the optimal local performance for 1, 4, 8, and 16 workers. Despite having a Proc. ACM Manag. Data, V ol. 3, No. 1 (SIGMOD), Article 55. Publication date: February 2025. 55:24 Maximilian Böther et al. 1 4 8 16 0 350 700 Throughput 56 182 315 450 57 213 415 634 Modyn Optimal (a) Criteo (x1000) 1 4 8 16 Data W orkers 0 350 700 Throughput 218 477 475 475 219 471 474 472 (b) CGLM Fig. 16. Modyn throughput vs. optimal throughput when loading data sequentially locally . much more inv olved data retrieval process, Modyn reaches ov er 70 % of optimal throughput for the challenging recommendation system case. 7.3.2 CGLM Throughput. Figure 16b compares Modyn to the optimal local throughput. As soon as 4 workers are used, the throughput stagnates at around 475 samples/s. Modyn basically reaches the optimal local throughput for all congurations. This is b ecause computer vision workloads like CGLM (or yearbook ) are compute-bound , while training a recommendation systems model is memory-b ound [ 1 , 21 , 66 , 124 ]. Four workers, with Modyn ’s C++ storage and sele ctor implementa- tions, supply the model with enough data. 8 Conclusion and Future W ork W e present the data-centric Modyn orchestrator for ML pipelines on gro wing datasets, together with an ecosystem of tooling, benchmarks, and concepts to fairly compare ML pipelines. Modyn implements various triggering and data selection p olicies and optimizes the system infrastructure under the hood for high-throughput sample-level data selection. For future work from an ML perspective, it is interesting to extend our analyses across more benchmark datasets, explore more presampling policies, and consider metrics such as information retention [ 16 , 80 ]. Future work might also use Modyn and the ideas on comparing pipelines (Se ction 3) to nd optimal pipeline congurations on benchmarks with an AutoML approach [ 40 , 89 ], and extend Modyn to the unsuper vised case and train generative large language models [ 111 ]. Due to the right to data deletion in regulations such as GDPR and CCP A [ 29 , 100 ], support for data deletion ( dynamic instead of just growing datasets) also is an interesting featur e [15, 112]. From a systems and database perspective, additional research opportunities arise. For e xample, some selection policies require to store huge emb eddings over time [ 82 ] which is a data management challenge in itself. It is also not yet clear how to optimally compress and store multiple model versions over time [ 103 , 104 ]. Last, since Modyn is a centralized system, it can be leveraged for provenance analyses, such as understanding why retraining and selection decisions were made [ 19 , 68 , 77 , 118 ]. Modyn provides a rich environment for such research on dier ent parts of the training pipeline. Acknowledgments Maximilian Böther is supporte d by the Swiss National Science Foundation (project number 200021_204620). Ties Robroek is supported by the Independent Research Fund Denmark’s Sapere Aude pr ogram (grant agreement number 0171-00061B). W e thank Francesco Deaglio, Jingyi Zhu, Robin Oester , and Foteini Strati for their contributions to Modyn ’s codebase. W e also thank the anonymous reviewers for their helpful comments. Proc. ACM Manag. Data, V ol. 3, No. 1 (SIGMOD), Article 55. Publication date: February 2025. Modyn : Data-Centric Machine Learning Pipeline Orchestration 55:25 References [1] Muhammad Adnan, Yassaman Ebrahimzadeh Maboud, Div ya Mahajan, and Prashant J. Nair . 2021. Accelerating recommendation system training by lev eraging popular choices. Proceedings of the VLDB Endowment 15, 1 (2021). https://doi.org/10.14778/3485450.3485462 [2] Gabriel J. Aguiar and Alberto Cano. 2024. A comprehensive analysis of concept drift locality in data streams. Knowledge-Based Systems 289 (2024). https://doi.org/10.1016/j.knosys.2024.111535 [3] Rahaf Aljundi, Eugene Belilovsky , Tinne Tuytelaars, Laurent Charlin, Massimo Caccia, Min Lin, and Lucas Page- Caccia. 2019. Online Continual Learning with Maximal Interfer e d Retrieval. In Proceedings of the Conference on Neural Information Processing Systems (NeurIPS) . [4] Rahaf Aljundi, Min Lin, Baptiste Goujaud, and Y oshua Bengio. 2019. Gradient based sample selection for online continual learning. In Proceedings of the Conference on Neural Information Processing Systems (NeurIPS) . [5] Amazon. 2023. Amazon SageMaker . https://docs.aws.amazon.com/sagemaker/index.html. [6] arXiv .org submitters. 2024. arXiv Kaggle Dataset. https://doi.org/10.34740/KA GGLE/DSV/7548853 [7] Jihwan Bang, Heesu Kim, Y oungJoon Y oo, Jung- W oo Ha, and Jonghyun Choi. 2021. Rainbow Memory: Continual Learning with a Memor y of Diverse Samples. In Proce edings of the IEEE/CVF Conference on Computer Vision and Pattern Re cognition (CVPR) . https://doi.org/10.1109/cvpr46437.2021.00812 [8] Roberto Souto Maior Barros and Silas Garrido T . Car valho Santos. 2018. A large-scale comparison of concept drift detectors. Information Sciences 451–452 (2018). https://doi.org/10.1016/j.ins.2018.04.014 [9] Michael Bayer . 2012. SQLAlchemy . In The A rchitecture of Open Source Applications V olume II: Structure, Scale, and a Few More Fearless Hacks . aosabo ok.org. http://aosabook.org/en/sqlalchemy .html [10] Denis Baylor , Kevin Haas, Konstantinos Katsiapis, Sammy Leong, Rose Liu, Clemens Mewald, Hui Miao, Ne oklis Polyzotis, Mitchell Tr ott, and Martin Zinkevich. 2019. Continuous Training for Pr oduction ML in the T ensorFlow Extended (TFX) Platform. In Procee dings of the USENIX Conference on Operational Machine Learning (OpML) . [11] BentoML. 2023. BentoML: Github Organization. https://github.com/bentoml/. Accessed: 2023-11-28. [12] Romil Bhardwaj, Zheng xu Xia, Ganesh Ananthanarayanan, Junchen Jiang, Y uanchao Shu, Nikolaos K arianakis, Kevin Hsieh, Paramvir Bahl, and Ion Stoica. 2022. Ekya: Continuous Learning of Video Analytics Mo dels on Edge Compute Servers. In Proceedings of the USENIX Symp osium on Networked Systems Design and Implementation (NSDI) . [13] Lukas Biewald. 2020. Experiment Tracking with W eights and Biases. https://ww w .wandb.com/. [14] Maximilian Böther , Foteini Strati, Viktor Gsteiger , and Ana Klimovic. 2023. T owards A Platform and Benchmark Suite for Mo del Training on Dynamic Datasets. In Proceedings of the W orkshop on Machine Learning and Systems (EuroMLSys) . https://doi.org/10.1145/3578356.3592585 [15] Lucas Bourtoule, V arun Chandrasekaran, Christopher A. Choquette-Choo, Hengrui Jia, Adelin T ravers, Baiwu Zhang, David Lie, and Nicolas Papernot. 2021. Machine Unlearning. In Proceedings of the IEEE Symposium on Se curity and Privacy (S&P) . https://doi.org/10.1109/sp40001.2021.00019 [16] Zhipeng Cai, Ozan Sener , and Vladlen Koltun. 2021. Online Continual Learning with Natural Distribution Shifts: An Empirical Study with Visual Data. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) . https://doi.org/10.1109/iccv48922.2021.00817 [17] Paris Carbone, Asterios Katsifodimos, Stephan Ewen, V olker Markl, Seif Haridi, and Kostas T zoumas. 2015. Apache Flink ™ : Stream and Batch Processing in a Single Engine. Bulletin of the T echnical Committee on Data Engineering 38, 4 (2015). [18] Gert Cauwenberghs and T omaso A. Poggio. 2000. Incremental and Decremental Support V ector Machine Learning. In Proceedings of the Conference on Neural Information Processing Systems (NeurIPS) . [19] Adriane Chapman, Paolo Missier , Giulia Simonelli, and Riccardo T orlone. 2020. Capturing and quer ying ne- grained provenance of preprocessing pipelines in data science. Proceedings of the VLDB Endowment 14, 4 (2020). https://doi.org/10.14778/3436905.3436911 [20] Andrew Chen, Andy Chow , Aaron Davidson, Arjun DCunha, Ali Ghodsi, Sue Ann Hong, Andy Konwinski, Clemens Mewald, Siddharth Murching, T omas Nykodym, Paul Ogilvie, Mani Parkhe, A vesh Singh, Fen Xie, Matei Zaharia, Richard Zang, Juntai Zheng, and Corey Zumar . 2020. Developments in MLow: A System to Accelerate the Machine Learning Lifecycle . In Pr o ceedings of the International W orkshop on Data Management for End-to-End Machine Learning (DEEM) . https://doi.org/10.1145/3399579.3399867 [21] Runxiang Cheng, Chris Cai, Selman Yilmaz, Rahul Mitra, Malay Bag, Mrinmoy Ghosh, and Tianyin Xu. 2023. T owards GP U Memory Eciency for Distribute d Training at Scale. In Proce edings of the Symposium on Cloud Computing (SoCC) . https://doi.org/10.1145/3620678.3624661 [22] Cody Coleman, Christopher Y eh, Stephen Mussmann, Baharan Mirzasoleiman, Peter Bailis, Per cy Liang, Jure Leskovec, and Matei Zaharia. 2020. Sele ction via Proxy: Ecient Data Selection for Deep Learning. In Procee dings of the International Conference on Learning Representations (ICLR) . [23] Criteo. 2013. Download T erabyte Click Logs. https://labs.criteo.com/2013/12/download- terabyte- click- logs/. Proc. ACM Manag. Data, V ol. 3, No. 1 (SIGMOD), Article 55. Publication date: February 2025. 55:26 Maximilian Böther et al. [24] Jia Deng, W ei Dong, Richard Socher , Li-Jia Li, Kai Li, and Li Fei-Fei. 2009. ImageNet: A large-scale hierarchical image database. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) . [25] Behrouz Derakhshan, Alireza Rezaei Mahdiraji, Tilmann Rabl, and V olker Markl. 2019. Continuous Deployment of Machine Learning Pipelines. https://doi.org/10.5441/002/EDBT .2019.35 [26] T om Diethe, T om Borchert, Eno Thereska, Borja Balle, and Neil Lawrence. 2018. Continual Learning in Practice. In Proceedings of the W orkshop on Continual Learning at NeurIPS . https://doi.org/10.48550/ARXI V .1903.05202 [27] Gregory Ditzler and Robi Polikar . 2011. Hellinger distance based drift detection for nonstationar y environments. In Proceedings of the Symp osium on Computational Intelligence in D ynamic and Uncertain Environments (CIDUE) , V ol. 3741. https://doi.org/10.1109/cidue.2011.5948491 [28] Alex Egg. 2021. Online Learning for Recommendations at Grubhub. In Proceedings of the Conference on Recommender Systems (Re cSys) . https://doi.org/10.1145/3460231.3474599 [29] European Union. 2016. Art. 17 GDPR: Right to erasure (‘right to be forgotten’). https://gdpr .eu/article- 17- right- to- b e- forgotten/. [30] Evidently AI. 2024. Evidently: Collaborative AI observability platform. https://w ww .evidentlyai.com/. Accessed: 2024-06-26. [31] Clement Farabet and Nicolas Koumchatzky . 2020. Presentation: Inside NVIDIA’s AI Infrastructure for Self-driving Cars. In Presentations of the USENIX Conference on Operational Machine Learning (OpML) . https://w ww .usenix.org/ conference/opml20/presentation/farabet [32] Y asir Ghunaim, Adel Bibi, Kumail Alhamoud, Motasem Alfarra, Hasan Abe d Al K ader Hammoud, Ameya Prabhu, Philip H.S. T orr , and Bernard Ghanem. 2023. Real- Time Evaluation in Online Continual Learning: A New Hope. In Proceedings of te IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) . https://doi.org/10.1109/ cvpr52729.2023.01144 [33] Stefan Graf berger, Paul Groth, and Sebastian Schelter . 2023. Automating and Optimizing Data-Centric What-If Analyses on Native Machine Learning Pip elines. Proceedings of the ACM on Management of Data (SIGMOD) 1, 2 (2023). https://doi.org/10.1145/3589273 [34] Arthur Gretton, Karsten M. Borgwar dt, Malte J. Rasch, Bernhard Schölkopf, and Alexander Smola. 2012. A Kernel T wo-Sample T est. Journal of Machine Learning Research 13, 25 (2012). [35] Hasan Abed Al Kader Hammoud, Ameya Prabhu, Ser-Nam Lim, Philip H. S. T orr , Adel Bibi, and Bernard Ghanem. 2023. Rapid Adaptation in Online Continual Learning: Are W e Evaluating It Right? . In Proceedings of the International Conference on Computer Vision (ICCV) . https://doi.org/10.1109/iccv51070.2023.01728 [36] W ei Hao, Daniel Mendoza, Rafael da Silva, Deepak Narayanan, and Amar P hanishayee. 2024. MGit: A Model V ersioning and Management System. In Proce edings of the International Conference on Machine Learning (ICML) . https://doi.org/10.48550/ARXIV .2307.07507 [37] Kim Hazelwood, Sarah Bird, David Brooks, Soumith Chintala, Utku Diril, Dmytro Dzhulgakov , Mohamed Fawzy, Bill Jia, Y angqing Jia, Aditya Kalro, James Law , Kevin Lee, Jason Lu, Pieter Noordhuis, Misha Smelyanskiy, Liang Xiong, and Xiaodong W ang. 2018. Applied Machine Learning at Facebook: A Datacenter Infrastructure Perspective. In Proceedings of the IEEE International Symp osium on High Performance Computer A rchitecture (HPCA) . https: //doi.org/10.1109/HPCA.2018.00059 [38] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. De ep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) . https://doi.org/10.1109/cvpr . 2016.90 [39] Xinran He, Junfeng Pan, Ou Jin, Tianbing Xu, Bo Liu, Tao Xu, Y anxin Shi, Antoine Atallah, Ralf Herbrich, Stuart Bowers, and Joaquin Quiñonero Candela. 2014. Practical Lessons from Predicting Clicks on Ads at Facebook. In Proceedings of the International W orkshop on Data Mining for Online Adv ertising (ADKDD) . https://doi.org/10.1145/2648584.2648589 [40] Xin He, Kaiyong Zhao , and Xiaowen Chu. 2021. AutoML: A survey of the state-of-the-art. Knowledge-Based Systems 212 (2021), 106622. https://doi.org/10.1016/j.knosys.2020.106622 [41] Hopsworks AB. 2024. Hopsworks Feature Monitoring. https://w ww .hopsworks.ai/dictionary/feature- monitoring. [42] Chip Huyen. 2020. Machine learning is going real-time. https://huyenchip.com/2020/12/27/real- time- machine- learning.html. [43] Chip Huyen. 2022. Designing Machine Learning Systems . O’Reilly Media, Inc. [44] Chip Huyen. 2022. Real-time machine learning: challenges and solutions. https://huyenchip .com/2022/01/02/real- time- machine- learning- challenges- and- solutions.html. [45] Ruoxi Jia, Fan W u, Xuehui Sun, Jiacen Xu, David Dao, Bhavya Kailkhura, Ce Zhang, Bo Li, and Dawn Song. 2021. Scalability vs. Utility: Do W e Have to Sacrice One for the Other in Data Imp ortance Quantication? . In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Re cognition (CVPR) . https://doi.org/10.1109/cvpr46437. 2021.00814 Proc. ACM Manag. Data, V ol. 3, No. 1 (SIGMOD), Article 55. Publication date: February 2025. Modyn : Data-Centric Machine Learning Pipeline Orchestration 55:27 [46] Jaykumar Kasundra, Claudia Schulz, Melicaalsadat Mirsaan, and Stavr oula Skylaki. 2023. A Framework for Monitor- ing and Retraining Language Models in Real- W orld Applications. arXiv preprint (2023). https://doi.org/10.48550/ arXiv .2311.09930 [47] Angelos Katharopoulos and François Fleuret. 2018. Not All Samples Are Created Equal: Deep Learning with Importance Sampling. In Proceedings of the International Conference on Machine Learning (ICML) . [48] KrishnaT eja Killamsetty , Durga Sivasubramanian, Ganesh Ramakrishnan, Abir De, and Rishabh K. Iyer . 2021. GRAD- MA TCH: Gradient Matching based Data Subset Selection for Ecient Deep Model Training. In Proceedings of the International Conference on Machine Learning (ICML) . [49] Andreas Kirsch. 2023. Does ‘Deep Learning on a Data Diet’ reproduce? Overall yes, but GraNd at Initialization does not. Transactions on Machine Learning Research (2023). [50] Hyunseo Koh, Dahyun Kim, Jung-W oo Ha, and Jonghyun Choi. 2022. Online Continual Learning on Class Incremental Blurry T ask Conguration with Anytime Inference. In Proceedings of the International Conference on Learning Representations (ICLR) . [51] Alex Krizhevsky and Georey Hinton. 2009. Learning multiple layers of features from tiny images . Technical Report. University of T oronto, T oronto, Ontario. https://www .cs.toronto.edu/~kriz/learning- features- 2009- TR.pdf [52] Michael Kuchnik, Ana Klimovic, Jiri Simsa, Virginia Smith, and George Amvrosiadis. 2022. Plumb er: Diagnosing and Removing Performance Bottlenecks in Machine Learning Data Pipelines. In Proceedings of the Conference on Machine Learning and Systems (MLSys) . [53] Angeliki Lazaridou, Adhiguna Kuncoro, Elena Gribovskaya, Devang Agrawal, Adam Liska, Tayfun T erzi, Mai Gimenez, Cyprien de Masson d’ Autume, T omás Kociský, Sebastian Ruder , Dani Y ogatama, Kris Cao, Susannah Y oung, and Phil Blunsom. 2021. Mind the Gap: Assessing T emporal Generalization in Neural Language Models. In Proceedings of the Conference on Neural Information Processing Systems (NeurIPS) . [54] Y ann LeCun, Léon Bottou, Y oshua Bengio, and Patrick Haner . 1998. Gradient-based learning applied to document recognition. Proc. IEEE 86, 11 (1998). https://doi.org/10.1109/5.726791 [55] Aodong Li, Alex Boyd, Padhraic Smyth, and Stephan Mandt. 2021. Detecting and Adapting to Irregular Distribution Shifts in Bayesian Online Learning. In Proceedings of the Conference on Neural Information Processing Systems (NeurIPS) . [56] Hanmo Liu, Shimin Di, and Lei Chen. 2023. Incremental Tabular Learning on Heterogeneous Feature Space. Proceedings of the International Conference on Management of Data (SIGMOD) 1, 1 (2023). https://doi.org/10.1145/3588698 [57] David Lopez-Paz and Maxime Oquab. 2017. Revisiting Classier T wo-Sample T ests. In Proceedings of the International Conference on Learning Representations (ICLR) . [58] David Lopez-Paz and Marc’ Aurelio Ranzato. 2017. Gradient Episo dic Memory for Continual Learning. In Procee dings of Advances in Neural Information Processing Systems (NeurIPS) . [59] Jie Lu, Anjin Liu, Fan Dong, Feng Gu, Joao Gama, and Guangquan Zhang. 2018. Learning under Concept Drift: A Review . IEEE Transactions on Knowledge and Data Engineering (2018). https://doi.org/10.1109/tkde.2018.2876857 [60] Ananth Mahadevan and Michael Mathioudakis. 2023. Cost-Eective Retraining of Machine Learning Models. arXiv preprint (2023). https://doi.org/10.48550/arXiv .2310.04216 [61] Kiran Kumar Matam, Hani Ramezani, Fan W ang, Zeliang Chen, Y ue Dong, Maomao Ding, Zhiwei Zhao , Zhengyu Zhang, Ellie W en, and Assaf Eisenman. 2024. QuickUpdate: a Real-Time Personalization System for Large-Scale Recommendation Models. In Proce edings of the USENIX Symposium on Networked Systems Design and Implementation (NSDI) . [62] Sören Mindermann, Jan Markus Brauner , Muhammed Razzak, Mrinank Sharma, Andreas Kirsch, Winnie Xu, Benedikt Höltgen, Aidan N. Gomez, Adrien Morisot, Sebastian Far quhar , and Y arin Gal. 2022. Prioritized Training on Points that are Learnable, W orth Learning, and not yet Learnt. In Proceedings of the International Conference on Machine Learning (ICML) . [63] Baharan Mirzasoleiman, Je A. Bilmes, and Jure Leskovec. 2020. Coresets for Data-ecient Training of Machine Learning Models. In Proceedings of the International Conference on Machine Learning (ICML) . [64] Rishabh Misra. 2022. News Category Dataset. arXiv (2022). [65] Akshay Naresh Modi, Chiu Y uen K o o, Chuan Y u Foo, Clemens Mewald, Denis M. Baylor , Eric Br eck, Heng- Tze Cheng, Jarek Wilkie wicz, Levent K o c, Lukasz Lew , Martin A. Zinkevich, Martin Wicke , Mustafa Ispir , Neoklis Polyzotis, Noah Fiedel, Salem Elie Haykal, Steven Whang, Sudip Roy , Sukriti Ramesh, Vihan Jain, Xin Zhang, and Zakaria Haque. 2017. TFX: A T ensorF low-Based Production-Scale Machine Learning Platform. In Proceedings of the International Conference on Knowledge Discovery and Data Mining (KDD) . https://doi.org/10.1145/3097983.3098021 [66] Dheevatsa Mudigere, Y uchen Hao, Jianyu Huang, Zhihao Jia, Andrew T ulloch, Srinivas Sridharan, Xing Liu, Mustafa Ozdal, Jade Nie, Jongsoo Park, Liang Luo, Jie (Amy ) Y ang, Leon Gao, Dmytro Ivchenko, Aarti Basant, Y uxi Hu, Jiyan Y ang, Ehsan K. Ardestani, Xiaodong W ang, Rakesh Komuravelli, Ching-Hsiang Chu, Serhat Yilmaz, Huayu Li, Jiyuan Qian, Zhuobo Feng, Yinbin Ma, Junjie Y ang, Ellie W en, Hong Li, Lin Y ang, Chonglin Sun, Whitney Zhao, Dimitr y Melts, Krishna Dhulipala, KR Kishore, T yler Graf, Assaf Eisenman, Kiran Kumar Matam, Adi Gangidi, Guoqiang Jerr y Chen, Proc. ACM Manag. Data, V ol. 3, No. 1 (SIGMOD), Article 55. Publication date: February 2025. 55:28 Maximilian Böther et al. Manoj Krishnan, A vinash Nayak, Krishnakumar Nair , Bharath Muthiah, Mahmoud khorashadi, Pallab Bhattacharya, Petr Lapukhov , Maxim Naumov , Ajit Mathews, Lin Qiao , Mikhail Smelyanskiy , Bill Jia, and Vijay Rao. 2022. Software- hardware co-design for fast and scalable training of deep learning recommendation models. In Proceedings of the A nnual International Symposium on Computer A rchitecture (ISCA) . https://doi.org/10.1145/3470496.3533727 [67] Derek G. Murray , Jiří Šimša, Ana Klimovic, and Ihor Indyk. 2021. tf.data: a machine learning data processing framework. Proce edings of the VLDB Endowment 14, 12 (2021). https://doi.org/10.14778/3476311.3476374 [68] Mohammad Hossein Namaki, A vrilia Floratou, Fotis Psallidas, Subru Krishnan, Ashvin Agrawal, Yinghui Wu, Yiwen Zhu, and Markus W eimer . 2020. Vamsa: A utomated Provenance T racking in Data Science Scripts. In Proce edings of the International Conference on Knowledge Discovery & Data Mining (KDD) . https://doi.org/10.1145/3394486.3403205 [69] Maxim Naumov , Dheevatsa Mudigere, Hao-Jun Michael Shi, Jianyu Huang, Narayanan Sundaraman, Jongsoo Park, Xiaodong W ang, Udit Gupta, Carole-Jean Wu, Alisson G. Azzolini, Dmytro Dzhulgakov , Andrey Mallevich, Ilia Cherniavskii, Yinghai Lu, Raghuraman Krishnamo orthi, Ansha Y u, V olodymyr Kondratenko, Stephanie Pereira, Xianjie Chen, W enlin Chen, Vijay Rao, Bill Jia, Liang Xiong, and Misha Smelyanskiy . 2019. Deep Learning Recommendation Model for Personalization and Recommendation Systems. (2019). https://doi.org/10.48550/ARXI V .1906.00091 [70] Neptune. 2023. Neptune.ai ML Metadata Store. https://neptune.ai/. [71] NVIDIA. 2023. N VIDIA Triton Inference Ser ver . https://developer .nvidia.com/nvidia- triton- inference- ser ver. Ac- cessed: 2023-11-28. [72] NVIDIA. 2024. N VIDIA DLRM Example Implementation. https://github.com/NVIDIA/DeepLearningExamples/tree/ master/Py T orch/Recommendation/DLRM. Accessed: 2024-06-26. [73] Patrik Okanovic, Roger W alee, V asilis Mageirakos, Konstantinos E. Nikolakakis, Amin Karbasi, Dionysis Kalogerias, Nezihe Merve Gürel, and The odoros Rekatsinas. 2023. Repeate d Random Sampling for Minimizing the Time-to- Accuracy of Learning. In Proceedings of the International Conference on Learning Representations (ICLR) . [74] Christopher Olston, Noah Fiedel, Kiril Goro voy , Jeremiah Harmsen, Li Lao, Fangw ei Li, Vinu Rajashekhar , Sukriti Ramesh, and Jordan Soyke. 2017. T ensorF low-Serving: Flexible, High-Performance ML Serving. In Procee dings of the W orkshop on ML Systems at NeurIPS . https://doi.org/10.48550/arXiv .1712.06139 [75] Andrei Paleyes, Raoul-Gabriel Urma, and Neil D. Lawrence. 2022. Challenges in Deploying Machine Learning: A Survey of Case Studies. Comput. Sur veys 55, 6 (2022). https://doi.org/10.1145/3533378 [76] Mansheej Paul, Surya Ganguli, and Gintar e Karolina Dziugaite. 2021. Deep Learning on a Data Diet: Finding Important Examples Early in Training. In Proceedings of Advances in Neural Information Processing Systems (NeurIPS) . [77] Débora Pina, Adriane Chapman, Daniel De Oliveira, and Marta Mattoso. 2023. Deep Learning Provenance Data Integration: a Practical Approach. In Proceedings of the A CM W eb Conference (WW W) . https://doi.org/10.1145/ 3543873.3587561 [78] Robi Polikar , Lalita Upda, Satish S. Upda, and V asant Honavar . 2001. Learn++: an incremental learning algorithm for super vised neural networks. IEEE Transactions on Systems, Man and Cyb ernetics, Part C 31, 4 (2001). https: //doi.org/10.1109/5326.983933 [79] Omead Pooladzandi, David Davini, and Baharan Mirzasoleiman. 2022. Adaptive Second Order Coresets for Data- ecient Machine Learning. In Proceedings of the International Conference on Machine Learning (ICML) . https: //proceedings.mlr .press/v162/pooladzandi22a.html [80] Ameya Prabhu, Zhipeng Cai, Puneet Dokania, Philip T orr , Vladlen Koltun, and Ozan Sener . 2023. Online Continual Learning Without the Storage Constraint. arXiv preprint (2023). https://doi.org/10.48550/arXiv .2305.09253 [81] Ameya Prabhu, P hilip H. S. T orr , and Puneet K. Dokania. 2020. GDumb: A Simple Approach that Questions Our Progress in Continual Learning. In Proceedings of the European Conference on Computer Vision (ECCV) . https: //doi.org/10.1007/978- 3- 030- 58536- 5_31 [82] Garima Pruthi, Frederick Liu, Satyen Kale , and Mukund Sundararajan. 2020. Estimating Training Data Inuence by Tracing Gradient Descent. In Proceedings of Advances in Neural Information Processing Systems (NeurIPS) . [83] Pydantic Contributors. 2024. Pydantic Documentation. https://docs.pydantic.dev/latest/. Accessed: 2024-07-07. [84] PyT orch Serve Contributors. 2020. T orchServe: Docs. https://pytorch.org/serve/. Accessed: 2023-11-28. [85] Stephan Rabanser , Stephan Günnemann, and Zachary C. Lipton. 2019. Failing Loudly: An Empirical Study of Methods for Detecting Dataset Shift. In Proceedings of the Conference on Neural Information Processing Systems (NeurIPS) . [86] Srikumar Ramalingam, Daniel Glasner , Kaushal Patel, Raviteja V emulapalli, Sadeep Jayasumana, and Sanjiv Kumar. 2021. Less is more: Selecting informative and diverse subsets with balancing constraints. (2021). https://doi.org/10. 48550/arXiv .2104.12835 [87] Elias Ramzi, Nicolas A udebert, Clément Ramb our , André Araújo , Xavier Bitot, and Nicolas Thome. 2023. Optimization of Rank Losses for Image Retrieval. CoRR abs/2309.08250 (2023). https://doi.org/10.48550/ARXIV .2309.08250 [88] Sergey Redyuk, Zoi Kaoudi, V olker Markl, and Sebastian Schelter . 2021. A utomating Data Quality V alidation for Dynamic Data Ingestion. In Proceedings of the International Conference on Extending Database T e chnology (EDBT) . https://doi.org/10.5441/002/EDBT .2021.07 Proc. ACM Manag. Data, V ol. 3, No. 1 (SIGMOD), Article 55. Publication date: February 2025. Modyn : Data-Centric Machine Learning Pipeline Orchestration 55:29 [89] Sergey Redyuk, Zoi K aoudi, Sebastian Schelter , and V olker Markl. 2024. Assisted design of data science pipelines. The VLDB Journal 33, 4 (2024). https://doi.org/10.1007/s00778- 024- 00835- 2 [90] Gordon J. Ross, Niall M. Adams, Dimitris K. Tasoulis, and David J. Hand. 2012. Exponentially weighted moving average charts for detecting concept drift. Pattern Recognition Letters 33, 2 (2012). https://doi.org/10.1016/j.patrec.2011.08.019 [91] Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas W olf. 2020. DistilBERT , a distilled version of BERT: smaller , faster , cheaper and lighter. In Pr oceedings of the W orkshop on Energy Ecient Machine Learning and Cognitive Computing at NeurIPS . [92] Sebastian Schelter , Stefan Graf berger , Shubha Guha, Bojan Karlas, and Ce Zhang. 2023. Proactively Scr e ening Machine Learning Pipelines with ARGUSEYES. In Companion of the International Conference on Management of Data (SIGMOD) . A CM. https://doi.org/10.1145/3555041.3589682 [93] Sebastian Schelter , Dustin Lange, Philipp Schmidt, Meltem Celikel, Felix Biessmann, and Andreas Grafberger . 2018. A utomating large-scale data quality verication. Proceedings of the VLDB Endowment 11, 12 (2018). https://doi.org/ 10.14778/3229863.3229867 [94] Sebastian Schelter , Tammo Rukat, and Felix Biessmann. 2020. Learning to V alidate the Predictions of Black Box Classiers on Unseen Data. In Proceedings of the International Conference on Management of Data (SIGMOD) . https: //doi.org/10.1145/3318464.3380604 [95] Shreya Shankar , Rolando Garcia, Joseph M. Hellerstein, and Aditya G. Parameswaran. 2024. “W e Have No Idea How Models will Behave in Production until Production”: How Engineers Operationalize Machine Learning. In Proceedings of Conference on Computer-Supp orted Cooperative W ork and Social Computing (CSCW) . https://doi.org/10.1145/3653697 [96] Shreya Shankar , Bernease Herman, and Aditya G. Parameswaran. 2022. Rethinking Streaming Machine Learning Evaluation. In Proce edings of the ML Evaluation Standards W orkshop at ICLR . https://doi.org/10.48550/arXiv .2205.11473 [97] Shreya Shankar and Aditya G. Parameswaran. 2022. T owards Observability for Production Machine Learning Pipelines. Proceedings of the VLDB Endowment 15, 13 (2022). https://doi.org/10.14778/3565838.3565853 [98] Chijun Sima, Y ao Fu, Man-Kit Sit, Liyi Guo , Xuri Gong, Feng Lin, Junyu W u, Y ongsheng Li, Haidong Rong, Pierre-Louis A ublin, and Luo Mai. 2022. Ekko: A Large-Scale Deep Learning Recommender System with Low-Latency Mo del Update. In Proceedings of the USENIX Symposium on Op erating Systems Design and Implementation (OSDI) . [99] Maciej Sobczak and GitHub Contributors. 2023. SOCI - The C++ Database Access Library . https://github.com/SOCI/ soci. Accessed: 2023-11-28. [100] State of California, USA. 2018. Section 1798.130 CCP A. https://ccpa- info.com/california- consumer- privacy- act- full- text/. [101] Monika Steidl, Michael Felderer , and Rudolf Ramler . 2023. The pipeline for the continuous development of articial intelligence mo dels—Current state of research and practice. Journal of Systems and Software 199 (2023). https: //doi.org/10.1016/j.jss.2023.111615 [102] Michael Stonebraker and Lawrence A. Rowe. 1986. The design of POSTGRES. ACM SIGMOD Record 15, 2 (1986). https://doi.org/10.1145/16856.16888 [103] Nils Strassenburg, Dominic Kupfer , Julia Kowal, and Tilmann Rabl. 2023. Ecient Multi-Model Management. In Proceedings of the International Conference on Extending Database T e chnology , (EDBT) . https://doi.org/10.48786/edbt. 2023.37 [104] Nils Strassenburg, Ilin T olovski, and Tilmann Rabl. 2022. Eciently Managing Deep Learning Models in a Distributed Environment. In Procee dings of the International Conference on Extending Database T echnology (EDBT) . https: //doi.org/10.48786/EDBT .2022.12 [105] Ashraf T ahmasbi, Ellango Jothimurugesan, Srikanta Tirthapura, and P hillip B. Gibbons. 2021. DriftSurf: Stable-State / Reactive-State Learning under Concept Drift. In Proceedings of the International Conference on Machine Learning (ICML) . [106] T esla. 2019. T esla Autonomy Day . https://w ww .youtube.com/watch?v=Ucp0T TmvqOE&t=6678s. [107] Huangshi Tian, Minchen Y u, and W ei W ang. 2018. Continuum: A P latform for Cost- A ware, Low-Latency Continual Learning. In Proceedings of the Symposium on Cloud Computing (SoCC) . https://doi.org/10.1145/3267809.3267817 [108] Josh T obin. 2021. T oward continual learning systems. https://gantry .io/blog/toward- continual- learning- systems/. [109] Arnaud V an Looveren, Janis Klaise , Giovanni V acanti, Oliver Cobb, A shley Scillitoe, Robert Samoilescu, and Alex Athorne. 2019. Alibi Detect: Algorithms for outlier , adversarial and drift dete ction. https://github .com/SeldonIO/alibi- detect [110] Daniel V ela, Andrew Sharp, Richard Zhang, Trang Nguyen, An Hoang, and Oleg S. Pianykh. 2022. T emporal quality degradation in AI models. Scientic Reports 12, 1 (2022). https://doi.org/10.1038/s41598- 022- 15245- z [111] Zige W ang, W anjun Zhong, Yufei W ang, Qi Zhu, Fei Mi, Baojun W ang, Lifeng Shang, Xin Jiang, and Qun Liu. 2023. Data Management For Large Language Models: A Survey . arXiv preprint (2023). https://doi.org/10.48550/ARXI V .2312.01700 [112] Alexander W arnecke, Lukas Pirch, Christian W ressnegger , and Konrad Rieck. 2023. Machine Unlearning of Features and Labels. In Proceedings of the A nnual Network and Distributed System Security Symposium (NDSS) . Proc. ACM Manag. Data, V ol. 3, No. 1 (SIGMOD), Article 55. Publication date: February 2025. 55:30 Maximilian Böther et al. [113] Elias W erner , Nishant Kumar , Matthias Lieb er , Sunna T orge, Stefan Gumhold, and W olfgang Nagel. 2024. T owards Computational Performance Engineering for Unsupervised Concept Drift Detection: Complexities, Benchmarking, Performance Analysis. In Proceedings of the International Conference on Data Science, T e chnology and A pplications (DA T A) . https://doi.org/10.5220/0012758600003756 [114] T obias W eyand, Andre Araujo, Bingyi Cao, and Jack Sim. 2020. Google Landmarks Dataset v2 – A Large-Scale Benchmark for Instance-Level Recognition and Retrieval. In Procee dings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) . https://doi.org/10.1109/cvpr42600.2020.00265 [115] Thomas W olf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Remi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer , Patrick von Platen, Clara Ma, Y acine Jernite, Julien Plu, Canwen Xu, T even Le Scao, Sylvain Gugger , Mariama Drame, Quentin Lhoest, and Alexander Rush. 2020. Transformers: State-of-the- Art Natural Language Processing. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP) . https://doi.org/10.18653/v1/2020.emnlp- demos.6 [116] Xingjiao Wu, Luwei Xiao, Yixuan Sun, Junhang Zhang, Tianlong Ma, and Liang He. 2022. A survey of human-in-the- loop for machine learning. Future Generation Computer Systems 135 (2022). https://doi.org/10.1016/j.future.2022.05.014 [117] Y ue Wu, Yinp eng Chen, Lijuan W ang, Yuancheng Y e, Zicheng Liu, Y andong Guo, and Yun Fu. 2019. Large Scale Incremental Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) . https://doi.org/10.1109/cvpr .2019.00046 [118] Yinjun Wu, V al T annen, and Susan B. Davidson. 2020. PrI U: A Provenance-Based Approach for Incrementally Updating Regression Models. In Proceedings of the International Conference on Management of Data (SIGMOD) . https://doi.org/10.1145/3318464.3380571 [119] Doris Xin, Hui Miao, A ditya Parameswaran, and Neoklis Polyzotis. 2021. Production Machine Learning Pipelines: Empirical Analysis and Optimization Opportunities. In Proce edings of the International Conference on Management of Data (SIGMOD) . https://doi.org/10.1145/3448016.3457566 [120] Chen Y ang, Jin Chen, Qian Y u, Xiangdong Wu, Kui Ma, Zihao Zhao , Zhiwei Fang, W enlong Chen, Chaosheng Fan, Jie He, Changping Peng, Zhangang Lin, and Jingping Shao. 2023. An Incremental Update Framework for Online Recommenders with Data-Driven Prior . In Proceedings of the International Conference on Information and Knowledge Management (CKIM) . https://doi.org/10.1145/3583780.3615456 [121] Huaxiu Y ao, Caroline Choi, Bochuan Cao, Y o onho Lee, Pang W ei Koh, and Chelsea Finn. 2022. Wild-Time: A Benchmark of in-the- Wild Distribution Shift over Time. In Proceedings of the Conference on Neural Information Processing Systems (NeurIPS) (Benchmark Track) . [122] Liheng Yuan, Heng Li, Beihao Xia, Cuiying Gao , Mingyue Liu, W ei Y uan, and Xinge Y ou. 2022. Recent Advances in Concept Drift Adaptation Methods for Deep Learning. In Proceedings of the International Joint Conference on A rticial Intelligence (IJCAI) . https://doi.org/10.24963/ijcai.2022/788 [123] Matei Zaharia, Reynold S. Xin, Patrick W endell, Tathagata Das, Michael Armbrust, Ankur Dave, Xiangrui Meng, Josh Rosen, Shivaram V enkataraman, Michael J. Franklin, Ali Ghodsi, Joseph Gonzalez, Scott Shenker, and Ion Stoica. 2016. Apache Spark: a unied engine for big data processing. Commun. A CM 59, 11 (2016), 56–65. https: //doi.org/10.1145/2934664 [124] Mark Zhao, Niket Agar wal, Aarti Basant, Buğra Gedik, Satadru Pan, Mustafa Ozdal, Rakesh Komuravelli, Jerr y Pan, Tianshu Bao, Hao wei Lu, Sundaram Narayanan, Jack Langman, K evin Wilfong, Harsha Rastogi, Carole-Jean Wu, Christos Kozyrakis, and Parik Pol. 2022. Understanding Data Storage and Ingestion for Large-Scale Deep Recommendation Model Training. In Proceedings of the Annual International Symposium on Computer A rchitecture (ISCA) . https://doi.org/10.1145/3470496.3533044 Received July 2024; revised September 2024; accepted November 2024 Proc. ACM Manag. Data, V ol. 3, No. 1 (SIGMOD), Article 55. Publication date: February 2025.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment