데이터 중심 연속 학습 파이프라인 관리 플랫폼 Modyn
Modyn은 성장하는 데이터 스트림에 대해 샘플 수준의 데이터 선택과 트리거링 정책을 선언적으로 정의하고, 자동으로 파이프라인을 오케스트레이션해 고효율 연속 학습을 지원하는 오픈소스 플랫폼이다.
저자: Maximilian Böther, Ties Robroek, Viktor Gsteiger
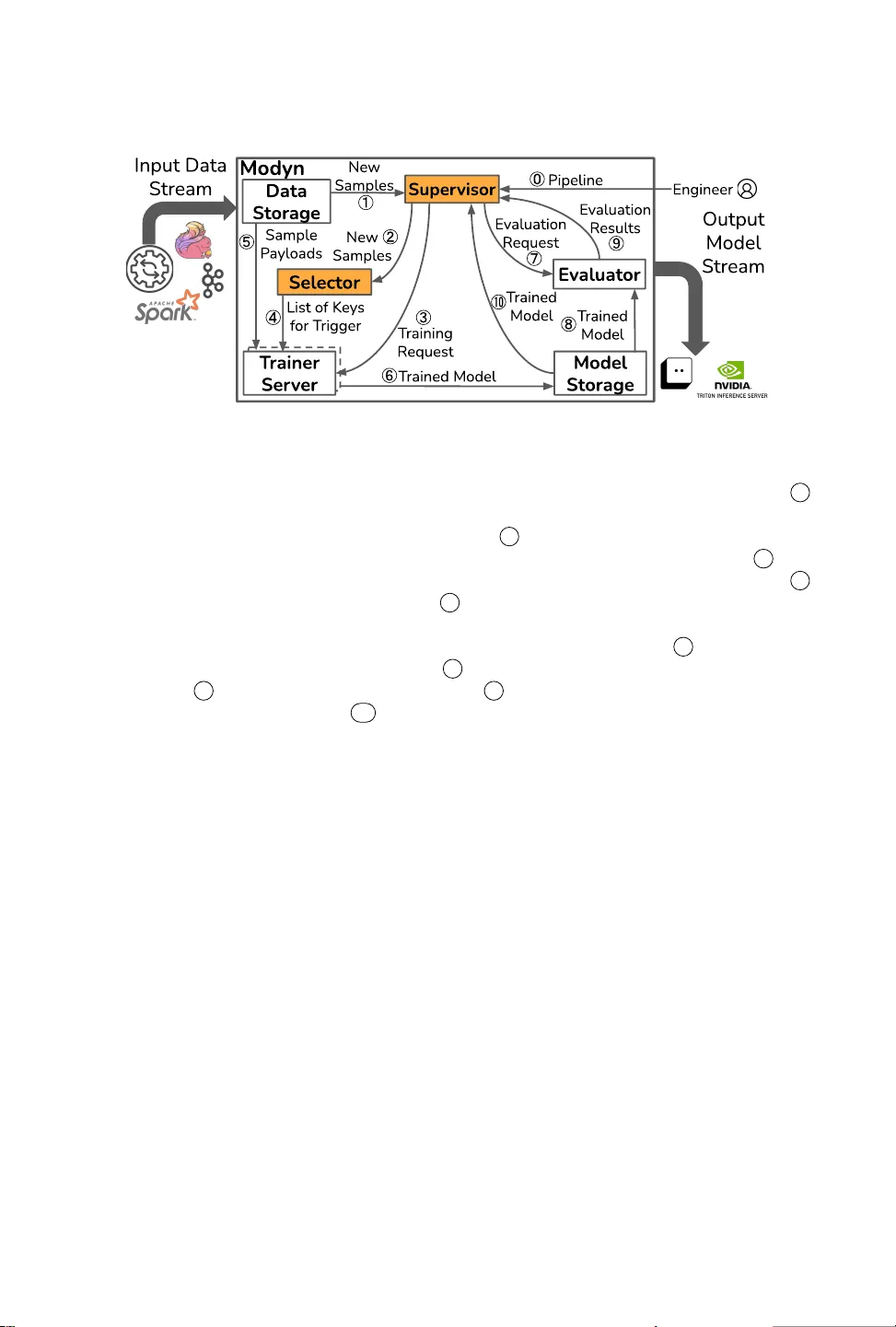
본 논문은 성장하는 데이터 스트림을 대상으로 하는 연속 학습 파이프라인의 비용·효율 문제를 해결하기 위해, 데이터‑중심 플랫폼 Modyn을 설계·구현하고 그 성능을 정량적으로 평가한다. 서론에서는 실시간 센서, 클릭스트림 등에서 발생하는 대규모 데이터 증가와 배포된 모델의 스터일(stale) 문제를 제시하고, 기존의 전체 재학습 방식이 비용과 시간 측면에서 비현실적임을 강조한다. 특히, 데이터 선택과 재학습 시점 결정(트리거링)이 별도로 연구되었지만, 실제 운영 환경에서는 두 요소가 동시에 고려되어야 함을 지적한다.
배경·동기 섹션에서는 성장하는 데이터셋의 특성을 설명하고, 현재 상용·오픈소스 ML 플랫폼(Weights & Biases, MLflow, SageMaker 등)이 연속 재학습을 지원하긴 하지만, 샘플‑레벨 데이터 선택이나 드리프트 기반 트리거링을 자동화·최적화하는 기능이 부족함을 밝힌다. 또한, 기존 연구가 작은 정적 데이터셋(CIFAR, MNIST)이나 탭형 데이터에 국한돼 있어, 이미지·텍스트와 같은 대규모 비정형 데이터에 적용하기 어렵다는 점을 강조한다.
핵심 기여는 네 가지로 정리된다. 첫째, **ML 파이프라인 추상화**를 도입해 사용자가 데이터 선택 정책과 트리거링 정책을 선언적으로 기술할 수 있게 한다. 정책은 상태를 유지할 수 있으며, 배치 단위로 효율적으로 평가된다. 둘째, **Modyn 오케스트레이터**를 구현해 선언된 파이프라인을 실행한다. 여기서는 샘플‑레벨 무작위 접근을 지원하기 위해 다중 레벨 배칭, 병렬 프리페치, 캐시 계층을 설계했으며, 다양한 데이터 포맷(이미지, 텍스트, 바이너리)에서도 높은 처리량을 유지한다. 셋째, **복합 모델(composite model)** 개념을 정형화해 파이프라인 전체 수명 동안 생성된 여러 모델을 시간 구간별로 매핑하고, 각 구간에 최적 모델을 선택해 정확도와 비용을 동시에 평가한다. 이를 통해 서로 다른 정책 조합을 공정하게 비교할 수 있다. 넷째, **생태계 구축**으로 벤치마크 데이터셋(시간 스탬프가 포함된 이미지·텍스트 컬렉션), 사전 구현된 선택·트리거링 정책, 웹 기반 시각화·비교 도구를 제공한다.
시스템 설계에서는 데이터 선택 정책을 **가중치 기반**(예: 마진, 불확실도, 클래스 밸런싱)과 **샘플링 기반**(예: Uniform, Least Confident)으로 구분하고, 각 정책이 선택한 샘플 집합을 학습 시에 가중치로 적용하거나 직접 필터링한다. 트리거링 정책은 **시간 기반**(고정 간격), **볼륨 기반**(새 데이터량 임계치), **성능 기반**(최근 모델 정확도 저하), **드리프트 기반**(통계적 분포 변화 감지) 등으로 구현된다. 트리거링은 per‑sample 수준으로 정의되지만, 실제 실행에서는 배치 단위로 평가해 오버헤드를 최소화한다.
평가에서는 9가지 데이터 선택 전략과 4가지 트리거링 전략을 조합해 36가지 파이프라인을 실험한다. 주요 실험 결과는 다음과 같다. (1) 50 % 샘플만 사용해도 전체 데이터 학습 대비 평균 정확도 손실이 1~3 % 수준에 머물며, 특히 마진 기반·클래스 밸런싱 전략이 가장 높은 정확도를 기록했다. (2) 드리프트 기반 트리거링은 고정 간격 재학습에 비해 평균 12 % 재학습 비용을 절감하고, 정확도는 2~4 % 향상했다. (3) 샘플‑레벨 선택이 적용된 경우에도 멀티‑레벨 배칭·프리페치를 통해 순차적 데이터 로딩 대비 0.9×~1.1× 처리량을 유지했다. (4) 복합 모델 평가를 통해, 특정 구간에서는 최신 모델보다 이전에 학습된 모델이 더 높은 정확도를 보이는 경우가 있음을 확인했으며, 이는 평가 구간을 고정하고 모델 선택을 동적으로 조정함으로써 전체 시스템 성능을 최적화할 수 있음을 시사한다.
논문의 마지막 섹션에서는 한계점과 향후 연구 방향을 논의한다. 현재 Modyn은 주로 이미지·텍스트 데이터에 초점을 맞추었으며, 시계열·그래프 데이터에 대한 지원은 제한적이다. 또한, 드리프트 감지 알고리즘이 아직 초기 단계이며, 하이퍼파라미터 튜닝이 필요하다. 향후에는 멀티‑모달 데이터, 분산 학습 환경, 자동 하이퍼파라미터 최적화와 같은 기능을 추가해 플랫폼을 확장할 계획이다.
결론적으로, Modyn은 데이터‑중심 AI 시대에 연속 학습 파이프라인을 효율적으로 설계·운영할 수 있는 실용적인 도구이며, 선언적 정책 정의, 고성능 샘플 선택, 드리프트 기반 트리거링, 복합 모델 기반 평가라는 네 가지 핵심 요소를 통해 연구자와 실무자가 비용 효율적인 모델 업데이트 전략을 체계적으로 탐색·비교·배포할 수 있게 한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기