HiGitClass: Keyword-Driven Hierarchical Classification of GitHub Repositories
GitHub has become an important platform for code sharing and scientific exchange. With the massive number of repositories available, there is a pressing need for topic-based search. Even though the topic label functionality has been introduced, the m…
Authors: Yu Zhang, Frank F. Xu, Sha Li
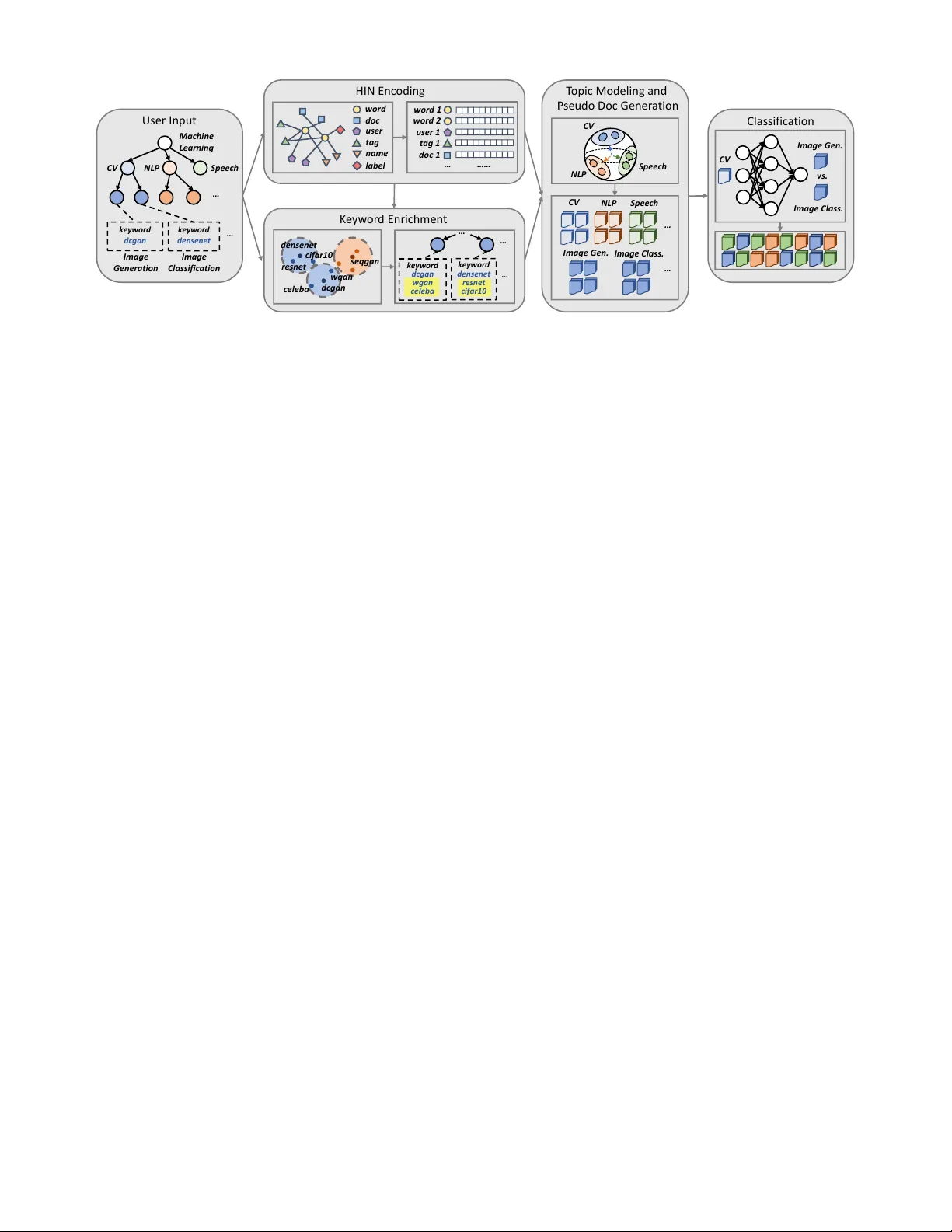
H I G I T C L A S S : K e yword-Dri v en Hierarchical Classification of GitHub Repositories Y u Zhang 1 , Frank F . Xu 2 , Sha Li 1 , Y u Meng 1 , Xuan W ang 1 , Qi Li 3 , Jiawei Han 1 1 Department of Computer Science, Univ ersity of Illinois at Urbana-Champaign, Urbana, IL, USA 2 Language T echnologies Institute, Carnegie Mellon Univ ersity , Pittsburgh, P A, USA 3 Department of Computer Science, Iow a State University , Ames, IA, USA { yuz9, shal2, yumeng5, xwang174, hanj } @illinois.edu, frankxu@cmu.edu, qli@iastate.edu Abstract —GitHub has become an important platf orm for code sharing and scientific exchange. With the massi ve number of repositories av ailable, there is a pressing need for topic-based search. Even though the topic label functionality has been introduced, the majority of GitHub repositories do not ha ve any labels, impeding the utility of sear ch and topic-based analysis. This work targets the automatic repository classification problem as k eyword-driven hierarchical classification . Specifically , users only need to pro vide a label hierarch y with keywords to supply as supervision. This setting is flexible, adaptive to the users’ needs, accounts for the different granularity of topic labels and requires minimal human effort. W e identify three key challenges of this problem, namely (1) the presence of multi-modal signals; (2) supervision scarcity and bias; (3) supervision format mismatch. In recognition of these challenges, we propose the H I G I T C L A S S framework, comprising of thr ee modules: heter ogeneous inf orma- tion network embedding; keyword enrichment; topic modeling and pseudo document generation. Experimental results on two GitHub repository collections confirm that H I G I T C L AS S is superior to existing weakly-supervised and dataless hierarchical classification methods, especially in its ability to integrate both structured and unstructured data for repository classification. Index T erms —hierarchical classification, GitHub, weakly- supervised learning I . I N T RO D U C T I O N For the computer science field, code repositories are an indispensable part of the knowledge dissemination process, containing valuable details for reproduction. For software engineers, sharing code also promotes the adoption of best practices and accelerates code development. The needs of the scientific community and that of software de velopers hav e facilitated the gro wth of online code collaboration platforms, the most popular of which is GitHub, with ov er 96 million repositories and 31 million users as of 2018. W ith the ov er- whelming number of repositories hosted on GitHub, there is a natural need to enable search functionality so that users can quickly tar get repositories of interest. T o accommodate this need, GitHub introduced topic labels 1 which allowed users to declare topics for their o wn repositories. Ho wev er , topic- based search on GitHub is still far from ideal. For example, when searching for repositories related to “phylogenetics”, a highly rele vant repository opentree 2 with many stars and forks does not e ven sho w up in the first 10 pages of search 1 https://help.github .com/en/articles/about- topics 2 https://github .com/OpenT reeOfLife/opentree results as it does not contain the “phylogenetics” tag. Hence, to improv e the search and analysis of GitHub repositories, a critical first step is automatic r epository classification . In the process of examining the automatic repository clas- sification task, we identify three dif ferent cases of missing labels: (1) Missing annotation : the majority of repositories (73% in our M AC H I N E - L E A R N I N G dataset and 78% in our B I O I N F O R M A T I C S dataset) ha ve no topic labels at all; (2) Incomplete annotation : since topic labels can be arbitrarily general or specific, some repositories may miss coarse-grained labels while others miss fine-grained ones; (3) Evolving label space : related GitHub topics tags may not have e xisted at the time of creation, so the label is naturally missing. Missing annotation is the major drive behind automatic classification, but this also implies that labeled data is scarce and expen- siv e to obtain. Incomplete annotation reflects the hierarchical relationship between labels: repositories should not only be assigned to labels of one lev el of granularity , but correspond to a path in the class hierarchy . Finally , the evolving label space requires the classification algorithm to quickly adapt to a ne w label space, or take the label space as part of the input. Combining these observations, we define our task as ke ywor d- driven hierar chical classification for GitHub repositories. By keyw ord-driven, we imply that we are performing classifica- tion using only a few keyw ords as supervision. Compared to the common setting of fully-supervised classi- fication of text documents, ke yword-driven hierar chical classi- fication of GitHub repositories poses unique challenges. First of all, GitHub repositories are complex objects with metadata, user interaction and textual description. As a result, multi- modal signals can be utilized for topic classification, including user ownership information, existing tags and README text. T o jointly model structured and unstructured data, we propose to construct a heter ogeneous information network (HIN) cen- tered upon words. By learning node embeddings in this HIN, we obtain word representations that reflect the co-occurrence of multi-modal signals that are unique to the GitHub repository dataset. W e also face the supervision scarcity and bias problem as users only provide one keyword for each class as guidance. This single keyw ord may reflect user’ s partial kno wledge of the class and may not achiev e good coverage of the class distribution. In face of this challenge, we introduce a keywor d enrichment module that expands the single k eyword to a keyw ord set for each category . The newly selected ke ywords are required to be close to the tar get class in the embedding space. Meanwhile, we keep mutual exclusi vity among ke yword sets so as to create a clear separation boundary . Finally , while users provide a label hierarchy , the classification algorithm ultimately operates on repositories, so there is a mismatch in the form of supervision. Since we already encode the structured information through the HIN embeddings, in our final classification stage we represent each repository as a document. T o transform ke ywords into documents, we first model each class as a topic distribution ov er words and estimate the distribution parameters. Then based on the topic distributions, we follo w a two-step procedure to generate pseudo documents for training. This also allo ws us to employ powerful classifiers such as CNNs for classification, which would not be possible with the scarce labels. T o summarize, we hav e the following contributions: • W e present the task of keyw ord-driv en hierarchical classi- fication of GitHub repositories. While GitHub has been of widespread interest to the research community , no previ- ous efforts have been dev oted to the task of automatically assigning topic labels to repositories, which can greatly facilitate repository search and analysis. T o deal with the ev olving hierarchical label space and circumvent expen- siv e annotation efforts, we only rely on the user-provided label hierarchy and keywords to train the classifier . • W e design the H I G I T C L A S S framework, which consists of three modules: HIN construction and embedding; key- word enrichment; topic modeling and pseudo document generation. The three modules are carefully devised to ov ercome three identified challenges of our problem: the presence of multi-modal signals; supervision scarcity and bias; supervision format mismatch. • W e collect two datasets of GitHub repositories from the machine learning and bioinformatics research community . On both datasets we sho w that our proposed framework H I G I T C L A S S outperforms existing supervised and semi- supervised models for hierarchical classification. The remainder of this paper is organized as follows. In Section II, we formally introduce our problem definition, multi-modal signals in a GitHub repository and heterogeneous information networks. In Section III, we elaborate our framework H I G - I T C L A S S with its three components. Then in Section IV , we present experimental results and discuss our findings. Section V cov ers related literature and we conclude in Section VI. I I . P R E L I M I NA R I E S A. Problem Definition W e study hierarchical classification of GitHub repositories where the categories form a tree structure. Traditional hierar- chical classification approaches [7], [19] rely on a lar ge set of labeled training documents. In contrast, to tackle the ev olving label space and alleviate annotation efforts, we formulate our task as ke yword-driven classification, where users just need to provide the label hierarchy and one ke yword for each leaf category . This bears some similarities with the dataless Use r Name D e scripti on T ags RE AD ME Fig. 1. A sample GitHub repository with the user’ s name, the repository name, description tags, and README (only the first paragraph is shown). classification proposed in [33] that utilizes an user -defined label hierarchy and class descriptions. There is no requirement of any labeled repository . Formally , our task is defined as follows. Problem Definition. ( K E Y W O R D - D R I V E N H I E R A R C H I C A L C L A S S I FI C A T I O N .) Given a collection of unlabeled GitHub r epositories, a tr ee-structured label hierar chy T and one ke yword w i 0 for each leaf class C i ( i = 1 , ..., L ) , our task is to assign appr opriate cate gory labels to the r epositories, wher e the labels can be either a leaf or an internal node in T . B. GitHub Repositories Fig. 1 sho ws a sample GitHub repository 3 . W ith the help of GitHub API 4 , we are able to extract comprehensiv e infor- mation of a repository including metadata, source code and team dynamics. In H I G I T C L A S S , we utilize the following information: User . Users usually have consistent interests and skills. If two repositories share the same user (“ Natsu6767 ” in Fig. 1), they are more likely to have similar topics (e.g., deep learning or image generation). Name. If two repositories share the same name, it is likely that one is forked from the other and the y should belong to the same topic category . Besides, indicative keywords can be obtained by segmenting the repository name properly (e.g., “ DCGAN ” and “ PyT or ch ” in Fig. 1). Description. The description is a concise summary of the repository . It usually contains topic-indicating words (e.g., “ DCGAN ” and “ CelebA ” in Fig. 1). T ags. Although a large proportion of GitHub repositories are not tagged, when a vailable, tags are strong indicators of a repository’ s topic (e.g., “ dcgan ” and “ generative-model ” in Fig. 1). 3 https://github .com/Natsu6767/DCGAN-PyT orch 4 https://dev eloper .github.com/v3/ ke ywo r d d cg a n wgan cel eba Use r I np ut M achi ne L earni ng CV N L P S peech … ke y w o r d d cg a n k ey w o r d d en se n et … HI N Enc odi ng w o rd do c user t ag l ab el na m e … …… w ord 1 w ord 2 user 1 t ag 1 T opi c Modeli ng an d P se udo Doc Gene r a ti on CV N L P S peech … Cl assi f i c a t i on CV v s. K e y w or d Enr ichme n t CV NLP S peech ke ywo r d d en se n et r es n et ci fa r 1 0 … I m ag e G en er a ti o n I m ag e Cl ass i f i c at i on do c 1 … … I m ag e G en. I m ag e C l ass . … I m ag e G en. I m ag e C l ass . dc ga n den s ene t c el eba w ga n s eqga n re s ne t cif ar10 Fig. 2. The H I G IT C L A SS framework. Three key modules (i.e., HIN encoding, keyw ord enrichment, and pseudo document generation) are used to tackle the aforementioned three challenges, respectiv ely . README. The README file is the main source of textual information in a repository . In contrast to the description, it elaborates more on the topic but may also div erge to other issues (e.g., installation processes and code usages). The latter introduces noises to the task of topic inference. W e concatenate the description and README fields into a single Document field, which serves as the textual feature of a repository . C. Hetero geneous Information Networks In our proposed framew ork H I G I T C L A S S , we model the multi-modal signals of GitHub repositories as a heterogeneous information network (HIN) [34], [35]. HINs are an extension of homogeneous information networks to support multiple node types and edge types. W e formally define a heteroge- neous information network as below: Heterogeneous Inf ormation Network (HIN). An HIN is defined as a graph G = ( V , E ) with a node type mapping φ : V → T V and an edge type mapping ψ : E → T E . Either the number of node types |T V | or the number of relation types |T E | is lar ger than 1. As we all kno w , one adv antage of networks is the ability to go beyond direct links and model higher-order relationships which can be captured by paths between nodes. W e introduce the notion of meta-paths, which account for dif ferent edge types in HINs. Meta-Path. In an HIN, meta-paths [35] are an abstraction of paths pr oposed to describe multi-hop relationships. F or an HIN G = ( V , E ) , a meta-path is a sequence of edge types M = E 1 - E 2 -...- E L ( E i ∈ T E ). Any path that has the same types as the meta-path is an instance of the meta-path. When edge types are a function of the node types, we also r epr esent a meta-path as M = V 1 - V 2 -...- V L ( V i ∈ T V and V i - V i +1 ∈ T E for any i ). I I I . M E T H O D W e lay out our H I G I T C L A S S framew ork in Fig. 2. H I G I T - C L A S S consists of three ke y modules, which are proposed to solve the three challenges mentioned in Introduction, respec- tiv ely . T o deal with multi-modal signals , we propose an HIN encoding module (Section III-A). Giv en the label hierarchy and keywords, we first construct an HIN to characterize different kinds of connections between words, documents, users, tags, repository names and labels. Then we adopt E S I M [31], a meta-path guided heterogeneous network embedding technique, to obtain good node representations. T o tackle supervision scar city and bias , we introduce a ke y- wor d enrichment module (Section III-B). This module expands the user-specified ke yword to a semantically concentrated keyw ord set for each category . The enriched keywords are required to share high proximity with the user-giv en one from the view of embeddings. Meanwhile, we keep mutual exclu- sivity among ke yword sets so as to create a clear separation boundary . T o overcome supervision format mismatch , we present a pseudo-document gener ation technique (Section III-C). W e first model each class as a topic distribution o ver w ords and estimate the distribution parameters. Then based on the topic distributions, we follow a two-step procedure to generate pseudo documents for training. This step allo ws us to employ powerful classifiers such as con volutional neural network [16]. Intuitiv ely , the neural classifier is fitting the learned word distributions instead of a small set of keywords, which can effecti vely prevent it from overfitting. A. HIN Construction and Embedding HIN Construction. The first step of our model is to con- struct an HIN that can capture all the interactions between different types of information regarding GitHub repositories. W e include six types of nodes: words ( W ), documents ( D ), users ( U ), tags ( T ), tokens segmented from repository names ( N ) and labels ( L ). There is a one-to-one mapping between documents ( D ) and repositories ( R ), thus document nodes may also serve as a representation of its corresponding repository in the network. Since the goal of this module is to learn accurate word representations for the subsequent classification step, we adopt a wor d-centric star schema [36], [37]. The schema is shown in Fig. 3(a). W e use a sample ego network of the word “ DCGAN ” to help illustrate our schema (Fig. 3(b)). The word User T ag s Name Labe l Doc W or d (a) Our HIN schema DC GAN ( word ) Na tsu6767 ( us er ) DC GA N ( name ) PyT or c h ( name ) de ep l earning ( t ag ) g an ( t ag ) Imag e - Gen er a ti on ( l abel ) Compu t er - Vi sion ( l abel ) R ep o001 ( doc ume n t ) (b) A sample ego network under the schema Fig. 3. Our HIN schema and a sample network under the schema. The five edge types characterize different kinds of second-order proximity between words. vocab ulary is the union of words present in the documents, tags, se gmented repository names and user -provided keywords. Follo wing the star schema, we then hav e 5 types of edges in the HIN that represent 5 types of word co-occurrences: (1) W – D . The wor d-document edges describe document- lev el co-occurrences, where the edge weight between word w i and document d j indicates the number of times w i appears in d j (i.e., term frequency , or tf ( w i , d j ) ). From the perspecti ve of second-or der proximity [38], W – D edges reflect the fact that two words tend to ha ve similar semantics when they appear in the same repository’ s document. (2) W – U . W e add an edge between a word and a user node if the user is the owner of a repository that contains the word in its document field. The edge weight between word w i and user u j is the sum of the term frequenc y of the word w in each of the user’ s repositories: X k : do cumen t d k belongs to user u j tf ( w i , d k ) . (3) W – T . The wor d-tag relations encode tag-level word co- occurrences. The edge weight between word w i and tag t j is X k : do cumen t d k has tag t j tf ( w i , d k ) . (4) W – N . W e segment the repository name using “-”, “ ” and whitespace as separators. For example, we obtain two tokens “ DCGAN ” and “ PyT or ch ” by segmenting the repository name “ DCGAN-PyT orc h ” in Fig. 1. The edge weight between word w i and name token n j also defined through term frequency: X k : do cumen t d k has name token n j tf ( w i , d k ) . (5) W – L . The word-label relations describe category- lev el word co-occurrences. Only user-provided ke ywords will be link ed with label nodes and its parents. For example, if we select “ DCGAN ” as the keyword of a (leaf) cate- gory “$I M A G E - G E N E R A T I O N ”, “ DCGAN ” will hav e links to “$I M AG E - G E N E R AT I O N ” and all of its parent cate gories (e.g., “$C O M P U T E R - V I S I O N ”). HIN Embedding. Once we hav e an HIN, we proceed to learn representations for nodes in the netw ork. Then the embedding vectors of word nodes can be applied for repository topic classification. There are many popular choices for network representation learning on HINs, such as M E TA P A T H 2 V E C [6] and H I N 2 V E C [9]. W e adopt E S I M [31] as our HIN embedding algorithm as it achieves the best performance in our task. (W e will validate this choice in Section IV -C.) Random walk based methods [11], [27] have enjoyed success in learning node embeddings on homogeneous graphs in a scalable manner . E S I M adapts the idea for use on HINs, and restricts the random walk under guidance of user-specified meta-paths. In H I G I T C L A S S , we choose W – D – W , W – U – W , W – T – W , W – N – W and W – L – W as our meta-paths, modeling the fiv e different types of second-order proximity between words. Follo wing the selected meta-paths, we can sample a large number of meta-path instances in our HIN (e.g., W – D – W is a valid node sequence, while D – W – D is not). Given a meta- path M and its corresponding node sequence P = u 1 – u 2 –...– u l , we assume that the probability of observing a path given a meta-path constraint follo ws that of a first-order Markov chain: Pr( P |M ) = Pr( u 1 |M ) l − 1 Y i =1 Pr( u i +1 | u i , M ) , where Pr( v | u, M ) = exp( f ( u, v , M )) P v 0 ∈ V exp( f ( u, v 0 , M )) (1) and f ( u, v , M ) = µ M + p T M e u + q T M e v + e T u e v . Here, µ M is the global bias of meta-path M . p M and q M are d -dimensional local bias of M . e u and e v are d -dimensional embedding vectors of nodes u and v , respectiv ely . e u , e v , p M , q M and µ M can be learned through maximizing the likelihood. Howe ver , the denominator in Equation (1) requires summing ov er all nodes, which is very computationally expensiv e giv en the large network size. In our actual computation, we estimate this term through negati ve sampling [24]. Pr( v | u, M ) = exp( f ( u, v , M )) P v 0 ∈ V − exp( f ( u, v 0 , M )) + exp( f ( u, v , M )) , where V − is the set of nodes that serve as negati ve samples. B. Ke yword Enrichment Since we only ask users to provide one keyw ord for each category , in case of scarcity and bias, we de vise a keyw ord enrichment module to automatically expand the single key- word w i 0 the a keyw ord set K i = { w i 0 , w i 1 , ..., w iK i } so as to better capture the semantics of the category . From the HIN embedding step, we hav e obtained the embedding vector e w for each word w . W e perform nor- malization so that all embedding vectors reside on the unit sphere (i.e., e w ← e w / || e w || ). Then the inner product of two embedding vectors e T w 1 e w 2 is adopted to characterize the proximity between two words w 1 and w 2 . For each class C i , we add words sharing the highest proximity with w i 0 into its enriched keyw ord set. Meanwhile, to create a clear Algorithm 1 K E Y W O R D E N R I C H ( w 10 , ..., w L 0 ) 1: K i = { w i 0 } , i = 1 , ..., L 2: w i,last = w i 0 , i = 1 , ..., L 3: while K i ∩ K j = ∅ ( ∀ i, j ) do 4: for i = 1 to L do 5: w i,last = arg max w / ∈K i e T w 0 i e w 6: K i = K i ∪ { w i,last } 7: end for 8: end while 9: K i = K i / { w i,last } , i = 1 , ..., L //Remove the last added keyw ord to keep mutual exclusivity 10: output K 1 , ..., K L separation boundary between categories, we require K 1 , ..., K L to be mutually exclusive . Therefore, the expansion process terminates when any two of the keyw ord sets tend to intersect. Algorithm 1 describes the process. Note that on a unit sphere, the inner product is a re- verse measure of the spherical distance between two points. Therefore, we are essentially expanding the keyw ord set with the nearest neighbors of the giv en keyword. The termination condition is that two “neighborhoods” have overlaps. C. T opic Modeling and Pseudo Document Generation T o leverage keywords for classification, we face two prob- lems: (1) a typical classifier needs labeled repositories as input; (2) although the keyword sets have been enriched, a classifier will likely be overfitted if it is trained solely on these keywords. T o tackle these issues, we assume we can generate a training document ˜ d for class C i giv en K i through the following process: q ( ˜ d | C ) = q ( ˜ d | Θ i ) p (Θ i |K i ) . Here q ( ·| Θ i ) is the topic distribution of C i parameterized by Θ i , with which we can “smooth” the small set of ke ywords K i to a continuous distribution. For simplicity , we adopt a “bag- of-words” model for the generated documents, so q ( ˜ d | Θ i ) = Q | ˜ d | i =0 q ( w i | Θ i ) . Then we draw samples of words from q ( ·| Θ i ) to form a pseudo document following the technique proposed in [22]. Spherical T opic Modeling. Given the normalized embed- dings, we characterize the word distrib ution for each category using a mixture of von Mises-Fisher (vMF) distributions [1], [10]. T o be specific, the probability to generate keyw ord w from category C i is defined as q ( w | C i ) = m X j =1 α j f ( e w | µ j , κ j ) = m X j =1 α j c p ( κ j ) exp( κ j µ T j e w ) , where f ( e w | µ j , κ j ) , as a vMF distribution, is the j -th com- ponent in the mixture with a weight α j . The vMF distrib ution can be interpreted as a normal distribution confined to a unit sphere. It has two parameters: the mean direction vector µ i and the concentration parameter κ i . The ke yword embeddings concentrate around µ i , and are more concentrated if κ i is lar ge. c p ( κ i ) is a normalization constant. Follo wing [23], we choose the number of vMF components differently for leaf and internal categories: (1) For a leaf category C j , the number of components m is set to 1 and the mixture model degenerates to a single vMF distribution. (2) For an internal category C j , we set the number of components to be the number of C j ’ s children in the label hierarchy . Giv en the enriched keyword set K j , we can deri ve µ j and κ j using Expectation Maximization (EM) [1]. Recall that the ke ywords of an internal cate gory are aggre gated from its children categories. In practice, we use the approximation procedure based on Newton’ s method [1] to deriv e κ j . Pseudo Document Generation. T o generate a pseudo docu- ment ˜ d for C j , we first sample a document vector e ˜ d from f ( ·| C j ) . Then we build a local vocabulary V ˜ d that contains top- τ words similar with ˜ d in the embedding space. ( τ = 50 in our model.) Giv en V ˜ d , we repeatedly generate a number of words from a background distribution with probability β and from the document-specific distribution with probability 1 − β . Formally , Pr( w | ˜ d ) = β p B ( w ) , w / ∈ V ˜ d β p B ( w ) + (1 − β ) exp( e T w e ˜ d ) P w 0 ∈ V ˜ d exp( e T w 0 e ˜ d ) , w ∈ V ˜ d where p B ( w ) is the background distribution (i.e., word distri- bution in the entire corpus). Here we generate the pseudo document in two steps: first sampling the document vector and then sampling words from a mixture of the document language model and a background language model. Compared to directly sampling words from f ( ·| C j ) , the two-step process ensures better coverage of the class distribution. In direct sampling, with high probability we will include words that are close to the centroid of the topic C j . The classifier may learn to ignore all other words and use only these words to determine the predicted class. By first sampling the document vector , we would like to lead the classifier to learn that all documents that fall within the topic distribution belong to the same class. The synthesized pseudo documents are then used as training data for a classifier . In H I G I T C L A S S , we adopt con volutional neural networks ( C N N) [16] for the classification task. One can refer to [16], [22] for more details of the network architecture. The embedding vectors of word nodes obtained by E S I M in the pre vious HIN module are used as pre-trained embeddings. Recall the process of generating pseudo documents, if we ev enly split the fraction of the background distribution into the m children categories of C j , the “true” label distribution (an m -dimensional vector) of a pseudo document ˜ d can be defined as lab el( ˜ d ) i = ( (1 − β ) + β /m, ˜ d is generated from child i β /m. otherwise Since our label is a distrib ution instead of a one-hot vector , we compute the loss as the KL div ergence between the output $Mac hine - Learning $Image - Ge ne r a ti on ( dc gan ) $ Objec t - De t ect i on ( r c nn ) $ Ima g e - Cl as sific a ti on ( de nse net ) $ Sem an ti c - Seg ment a ti on ( segme n t ati on ) $ P ose - Es ti ma ti on ( pose ) $ Supe r - R es ol uti on ( sr gan ) $T e xt - Gen er a ti on ( seqg an ) $ T e xt - Cl as sific a ti on ( vdcn n ) $ Named - En ti ty - R ec og niti on ( ner ) $ Ques ti on - Ans w eri ng ( sq uad ) $ Mac hine - T r ans l a ti on ( tr ans l ati on ) $ Lang uage - Modeli ng ( lm ) $ Spe ech - S yn thes i s ( wavene t ) $ Spe ech - R ec ogn i ti on ( dee p sp ee ch ) $ Na tur al - Lang uage - P r oc es sing $Compu t er - Vi sion $ Spe ech (a) M AC H IN E - L EA R N I NG $Bioi n f orma ti c s $Seq ue nce - Ana l y sis ( f as t q ) $ Ge nome - Ana l y sis ( genom i c ) $Gene - Expr es sion ( e xpr ess i on ) $ S y s t ems - Biol ogy ( ne tw ork ) $ Ge ne ti c s - and - P opula ti on - Ana l y sis ( gene ti c ) $ Str uct ur al - B i oin f ormati cs ( s tr uc tur e ) $ P h yl og en e ti c s ( ph yl ogene ti c ) $ Da t a - Analy ti c s $Compu t a ti onal - B i ology $ Biomedi c al - T e xt - Mi ning ( bi onl p ) $ Bioi mag i ng ( mic c ai ) $Da t aba se - and - On t ol ogies ( dat abas e ) (b) B I OI N F O RM ATI C S Fig. 4. Label hierarchy and provided keywords (in blue) on the two datasets. label distribution and the pseudo label. I V . E X P E R I M E N T S W e aim to answer two questions in our experiments. First, does H I G I T C L A S S achie ve supreme performance in compari- son with various baselines (Section IV -B)? Second, we propose three key modules in H I G I T C L A S S . Ho w do they contribute to the overall performance? (The effects of these three modules will be explored one by one in Sections IV -C, IV -D and IV -E). A. Experimental Setup Datasets. W e collect tw o datasets of GitHub repositories cov ering different domains. 5 Their statistics are summarized in T able I. T ABLE I D AT A S E T S TA T I ST I C S . Dataset #Repos #Classes (Lev el 1 + Lev el 2) M AC H IN E - L E AR N I N G 1,596 3 + 14 B I OI N F O RM ATI C S 876 2 + 10 • M AC H I N E - L E A R N I N G . This dataset is collected by the Paper W ith Code project 6 . It contains a list of GitHub repositories implementing state-of-the-art algorithms of various machine learning tasks, where the tasks are organized as a taxonomy . • B I O I N F O R M A T I C S . This dataset is e xtracted from re- search articles published on four venues Bioinformatics , BioNLP , MICCAI and Database from 2014 to 2018. In each article, authors may put a code link, and we extract the links pointing to a GitHub repository . Meanwhile, each article has an issue section, which is viewed as the topic label of the associated repository . Note that more than 73% (resp., 78%) of the repositories in our M A C H I N E - L E A R N I N G (resp., B I O I N F O R M AT I C S ) dataset hav e no tags. Baselines. W e e valuate the performance of H I G I T C L A S S against the following hierarchical classification algorithms: 5 Our code and datasets are a vailable at https://github.com/ yuzhimanhua/HiGitClass . 6 https://paperswithcode.com/media/about/ev aluation-tables.json.gz • HierSVM [7] decomposes the training tasks according to the label taxonomy , where each local SVM is trained to distinguish sibling categories that share the same parent node. 7 • HierDataless [33] embeds both class labels and doc- uments in a semantic space using Explicit Semantic Analysis on Wikipedia articles, and assigns the nearest label to each document in the semantic space. 8 Note that HierDataless uses Wikipedia as external knowledge in classification, whereas other baselines and H I G I T C L A S S solely reply on user-pro vided data. • W eSTClass [22] first generates pseudo documents and then trains a C N N based on the synthesized training data. 9 • W eSHClass [23] le verages a language model to generate synthesized data for pre-training and then iterativ ely refines the global hierarchical model on labeled docu- ments. 10 • PCNB [41] utilizes a path-generated probabilistic frame- work on the label hierarchy and trains a path-cost sensi- tiv e naive Bayes classifier . 11 • PCEM [41] makes use of the unlabeled data to amelio- rate the path-cost sensiti ve classifier and applies an EM technique for semi-supervised learning. Note that HierSVM, PCNB and PCEM can only take document-lev el supervision (i.e., labeled repositories). T o align the experimental settings, we first label all the repositories using TFIDF scores by treating the keyword set of each class as a query . Then, we select top-ranked repositories per class as the supervision to train HierSVM, PCNB and PCEM. Since the baselines are all text classification approaches, we append the information of user , tags and repository name to the end of the document for each repository so that the baselines can exploit these signals. 7 https://github .com/globality-corp/sklearn-hierarchical-classification 8 https://github .com/yqsong/DatalessClassification 9 https://github .com/yumeng5/W eSTClass 10 https://github .com/yumeng5/W eSHClass 11 https://github .com/HKUST -KnowComp/PathPredictionF orT extClassifica- tion T ABLE II P E RF O R M AN C E O F C O M PAR E D A L G OR I T H MS O N T H E M AC H I N E - L E A RN I N G D AT A S E T . H I E R D A TA L ES S D O ES N OT H A V E A S TA ND AR D D E VI ATI O N S I N C E I T I S A D E TE R M I NI S T I C A L G O RI T H M . Method Lev el-1 Micro Lev el-1 Macro Lev el-2 Micro Level-2 Macro Overall Micro Overall Macro HierSVM [7] 54.20 ± 4.53 46.58 ± 3.59 27.40 ± 3.55 31.99 ± 5.34 40.80 ± 1.20 34.57 ± 3.94 HierDataless [33] 76.63 33.44 13.72 8.80 45.18 13.15 W eSTClass [22] 61.78 ± 3.90 48.00 ± 2.04 37.71 ± 2.72 34.34 ± 1.70 49.75 ± 3.24 36.75 ± 1.67 W eSHClass [23] 70.69 ± 2.14 52.73 ± 2.18 38.08 ± 2.07 33.87 ± 2.23 54.39 ± 2.11 37.60 ± 1.67 PCNB [41] 77.79 ± 1.92 62.53 ± 2.55 26.77 ± 3.89 22.85 ± 1.98 52.28 ± 1.92 29.85 ± 1.74 PCEM [41] 77.28 ± 2.00 59.27 ± 2.29 22.34 ± 4.02 19.28 ± 2.25 49.81 ± 2.00 26.34 ± 1.83 H I G I T C L AS S W / O H I N 75.28 ± 6.99 60.85 ± 5.51 40.21 ± 2.91 39.77 ± 2.22 57.74 ± 4.07 43.49 ± 2.10 H I G I T C L AS S W / O E N R I CH 86.48 ± 1.41 72.19 ± 2.53 36.71 ± 1.13 43.75 ± 2.85 61.60 ± 0.25 48.77 ± 1.94 H I G I T C L AS S W / O H I E R 57.31 ± 1.63 59.30 ± 3.14 40.45 ± 2.51 44.41 ± 2.66 48.88 ± 2.07 47.04 ± 1.63 H I G I T C L AS S 87.68 ± 2.23 72.06 ± 4.39 43.93 ± 2.93 45.97 ± 2.29 65.81 ± 3.55 50.57 ± 2.98 T ABLE III P E RF O R M AN C E O F C O M P A R E D A L GO R I T HM S O N T H E B I O IN F O R MAT IC S D A TA SE T . H I E R D A TA LE S S D O E S N OT H A V E A S TAN D AR D D E V I A T I O N S I N C E I T I S A D E T E RM I N I ST I C A L G OR I T H M . Method Lev el-1 Micro Lev el-1 Macro Lev el-2 Micro Level-2 Macro Overall Micro Overall Macro HierSVM [7] 80.39 ± 2.72 70.16 ± 6.05 13.49 ± 10.2 10.04 ± 9.07 46.94 ± 4.66 20.06 ± 7.12 HierDataless [33] 81.39 78.75 39.27 36.57 60.33 43.60 W eSTClass [22] 61.78 ± 5.75 52.73 ± 4.86 20.39 ± 3.48 17.52 ± 2.59 41.09 ± 4.28 23.91 ± 2.82 W eSHClass [23] 63.17 ± 3.56 59.65 ± 3.51 26.44 ± 1.33 24.94 ± 0.98 44.80 ± 2.26 30.72 ± 1.30 PCNB [41] 77.03 ± 2.89 59.43 ± 3.51 31.77 ± 3.80 22.90 ± 4.84 54.40 ± 2.89 28.99 ± 4.82 PCEM [41] 78.51 ± 3.06 61.99 ± 4.18 32.80 ± 2.88 18.93 ± 5.28 55.66 ± 3.06 26.11 ± 5.41 H I G I T C L AS S W / O H I N 66.21 ± 8.33 64.39 ± 7.00 31.87 ± 3.65 30.47 ± 3.15 49.04 ± 5.75 36.13 ± 3.52 H I G I T C L AS S W / O E N R I CH 54.55 ± 10.0 53.57 ± 9.15 22.95 ± 1.46 23.18 ± 1.89 38.74 ± 4.30 28.24 ± 0.87 H I G I T C L AS S W / O H I E R 78.79 ± 2.57 73.71 ± 2.28 39.42 ± 4.47 41.58 ± 2.63 59.10 ± 3.51 46.94 ± 2.48 H I G I T C L AS S 81.71 ± 3.95 77.11 ± 3.89 42.44 ± 8.46 41.67 ± 8.04 62.08 ± 6.11 47.57 ± 7.34 Besides the baselines, we also include the following three ablation versions of H I G I T C L A S S into comparison. • w/o HIN skips the HIN embedding module and relies on word2vec [24] to generate word embeddings for the following steps. • w/o Enrich skips the keyword enrichment module and directly uses one single ke yword in spherical topic mod- eling. • w/o Hier directly classifies all repositories to the leaf layer and then assigns internal labels to each repository according to its leaf category . Evaluation Metrics. W e use F1 scores to e valuate the per- formance of all methods. Denote T P i , F P i and, F N i as the instance numbers of true-positi ve, false-positiv e and false negati ve for category C i . Let T 1 (resp., T 2 ) be the set of all Lev el-1 (resp., Lev el-2/leaf) categories. The Level-1 Micro- F1 is defined as 2 P R P + R , where P = P C i ∈T 1 T P i P C i ∈T 1 ( T P i + F P i ) and R = P C i ∈T 1 T P i P C i ∈T 1 ( T P i + F N i ) . The Lev el-1 Macro-F1 is defined as 1 |T 1 | P C i ∈T 1 2 P i R i P i + R i , where P i = T P i T P i + F P i and R i = T P i T P i + F N i . Accordingly , Lev el-2 Micro/Macro-F1 and Overall Micro/Macro-F1 can be defined on T 2 and T 1 ∪ T 2 . B. P erformance Comparison with Baselines T ables II and III demonstrate the performance of compared methods on two datasets. W e repeat each experiment 5 times (except HierDataless, which is a deterministic algorithm) with the mean and standard deviation reported. As we can observe from T ables II and III, on both datasets, a significant improvement is achiev ed by H I G I T C L A S S com- pared to the baselines. On M AC H I N E - L E A R N I N G , H I G I T - C L A S S notably outperforms the second best approach by 22.1% on av erage. On B I O I N F O R M A T I C S , the only metric in terms of which H I G I T C L A S S does not perform the best is Le vel-1 Macro-F1, and the main opponent of H I G I T - C L A S S is HierDataless. As mentioned above, HierDataless incorporates W ikipedia articles as its external knowledge. When user-provided keyw ords can be linked to W ikipedia (e.g., “ genomic ”, “ genetic ” and “ phylogenetic ” in B I O I N F O R - M A T I C S ), HierDataless can exploit the external information well. Howe ver , when the ke ywords cannot be wikified (e.g., names of new deep learning algorithms such as “ dcgan ”, “ r cnn ” and “ densenet ” in M AC H I N E - L E A R N I N G ), the help from W ikipedia is limited. In fact, on M A C H I N E - L E A R N I N G , HierDataless performs poorly . Note that on GitHub, it is common that names of recent algorithms or frame works are provided as keywords. Besides outperforming baseline approaches, H I G I T C L A S S shows a consistent and evident improvement against three ablation versions. The av erage boost of the HIN module over the six metrics is 15.0% (resp., 28.6%) on the M AC H I N E - L E A R N I N G (resp., B I O I N F O R M A T I C S ) dataset, indicating the importance of encoding multi-modal signals on GitHub. The Lev el-1 F1 scores of H I G I T C L A S S W / O E N R I C H is close to the full model on M AC H I N E - L E A R N I N G , but the ke yword en- richment module demonstrates its power when we go deeper . This finding is aligned with the fact that the topic distributions of coarse-grained categories are naturally distant from each other on the sphere. Therefore, one keyw ord per category may be enough to estimate the distributions approximately . 40 45 50 55 60 65 70 Ov e ra ll Micro - F1 me tap ath 2v e c as e mb e d d i n g H IN 2v e c as e mb e d d i n g N o W-D-W N o W-L -W N o W-T-W N o W-U-W N o W-N -W F u l l (a) M AC H IN E - L EA R N I N G , Micro 40 45 50 55 60 65 Ov e ra ll Micro - F1 me tap ath 2v e c as e mb e d d i n g H IN 2v e c as e mb e d d i n g N o W-D-W N o W-L -W N o W-T-W N o W-U-W N o W-N -W F u l l (b) B I OI N F O RM ATI C S , Micro 25 30 35 40 45 50 55 Ov e ra ll Ma cro - F1 me tap ath 2v e c as e mb e d d i n g H IN 2v e c as e mb e d d i n g N o W-D-W N o W-L -W N o W-T-W N o W-U-W N o W-N -W F u l l (c) M AC H IN E - L E AR N I NG , Macro 25 30 35 40 45 50 Ov e ra ll Ma cro - F1 me tap ath 2v e c as e mbedd i n g H IN 2v e c as e mbedd i n g No W -D-W No W -L -W No W -T-W No W -U -W No W -N-W F u l l (d) B I OI N F O RM ATI C S , Macro Fig. 5. Performance of algorithms with different HIN modules. Howe ver , when we aim at fine-grained classification, the topic distributions become closer , and the inference process may be easily interfered by a biased ke yword. H I G I T C L A S S W / O H I E R performs poorly on M A C H I N E - L E A R N I N G , which high- lights the importance of utilizing the label hierarchy during the training process. The same phenomenon occurs in the comparison between W eSTClass and W eSHClass. C. Effect of HIN Construction and Embedding W e have demonstrated the contribution of our HIN module by comparing H I G I T C L A S S and H I G I T C L A S S W / O H I N. T o explore the ef fectiv eness of HIN construction and embedding in a more detailed way , we perform an ablation study by changing one “factor” in the HIN and fixing all the other modules in H I G I T C L A S S . T o be specific, our HIN has five types of edges, each of which corresponds to a meta-path. W e consider fiv e ablation versions ( No W -D-W , No W-U-W , No W -T -W , No W-N-W and No W -L-W ). Each version ignores one edge type/meta-path. Moreover , given the complete HIN, we consider to use two popular approaches, M E TA PA T H 2 V E C [6] and H I N 2 V E C [9], as our embedding technique, which generates two variants metapath2vec as embedding and HIN2vec as embedding . Fig. 5 shows the performance of these variants and our Full model. W e have the follo wing findings from Fig. 5. First, our F U L L model outperforms the five ablation models ignoring different edge types, indicating that each meta-path (as well as each node type incorporated in the HIN construction step) plays a positive role in classification. Second, our F U L L model outperforms M E TA P AT H 2 V E C A S E M B E D D I N G and H I N 2 V E C A S E M B E D D I N G in most cases, which validates our choice of using E S I M as the embedding technique. The possible reason that E S I M is more suitable for our task may be that we hav e a simple word-centric star schema and a clear goal of embedding word nodes. Therefore, the choices of meta-paths can be explicitly specified (i.e., W –?– W ) and do not need to be inferred from data (as H I N 2 V E C does). Third, among 0 20 40 60 80 10 0 0 50 0 10 00 15 00 20 00 F1 # p s e u d o d o cu m e n ts p e r clas s L e v e l -1 M i c r o L e v e l -1 M ac r o L e v e l -2 M i c r o L e v e l -2 M ac r o O v e r al l M i c r o O v e r al l M ac r o (a) M AC H IN E - L EA R N I N G 0 20 40 60 80 10 0 0 50 0 10 00 15 00 20 00 F1 # p s e u d o d o cu m e n ts p e r clas s Le v el -1 Mi c r o L e v e l -1 M ac r o L e v e l -2 M i c r o L e v e l -2 M ac r o O v e r al l M i c r o O v e r al l M ac r o (b) B I OI N F O RM ATI C S Fig. 6. Performance of H I G IT C L A S S with different numbers of pseudo documents. the five ablation models ignoring edge types, N O W- U - W performs the worst on M A C H I N E - L E A R N I N G , which means W - U edges (i.e., the user information) contribute the most in repository classification. Meanwhile, on B I O I N F O R M A T I C S , W - T edges hav e the largest of fering. This can be explained by the following statistics: in the M AC H I N E - L E A R N I N G dataset, 348 pairs of repositories share the same user , out of which 217 (62%) ha ve the same leaf label; in the B I O I N F O R M A T I C S dataset, there are 356 pairs of repositories having at least two ov erlapping tags, among which 221 (62%) belong to the same leaf category . Fourth, W - D edges also contribute a lot to the performance. This observation is aligned with the results in [37], where document-le vel word co-occurrences play a crucial role in text classification. D. Effect of K e ywor d Enrichment Quantitativ ely , the keyword enrichment module has a posi- tiv e contribution to the whole framework according to previous experiments. W e now show its ef fect qualitati vely . T able IV lists top-5 words selected by H I G I T C L A S S during keyw ord enrichment. Besides topic-indicating words (e.g., “ tag ger ”, “ trait ”, “ trees ”, etc.), popular algorithm/tool names (e.g., “ bidaf ” and “ pymol ”), dataset names (e.g., “ mpii ”, “ pdb ”) and author names (e.g., “ papandreou ” and “ lample ”) are also in- cluded in the expanded ke yword set. Note that some provided keyw ords are more or less ambiguous (e.g., “ se gmentation ” and “ structur e ”), and directly using them for topic modeling may introduce noises. In contrast, the expanded set as a whole can better characterize the semantics of each topic category . E. Effect of Pseudo Documents In all pre vious experiments, when we build a classifier for an internal category C i , we generate 500 pseudo documents for each child of C i . What if we use less/more synthesized training data? Intuitiv ely , if the amount of generated pseudo documents is too small, signals in previous modules cannot fully propagate to the training process. On the contrary , if we hav e too many generated data, the training time will be unnecessarily long. T o see whether 500 is a good choice, we plot the performance of H I G I T C L A S S with 10, 50, 100, 500, 1000 and 2000 pseudo documents in Fig. 6. On the one side, when the number of pseudo documents is too small (e.g., 10, 50 or 100), information carried in the synthesized training data will be insufficient to train a good classifier . On the other side, when we generate too T ABLE IV E N TI T Y E N R I CH M E N T R E S U L T S O N T H E T WO DAT A S ET S . F O U R L E A F C ATE G O R IE S A R E S H OW N F O R E AC H DAT A S E T . Class $S E M A N TI C - S E GM E N TA T I O N $P O S E - E S T I M A T I O N $ N A M E D - E N T I TY -R E C O G NI T I O N $Q U E S TI O N - A N SW E R I N G Ke yword segmentation pose ner squad Enriched Ke ywords semantic estimation entity question papandreou person tagger answering scene human lample bidaf pixel mpii - - segment 3d - - Class $G E N E - E X P R E S SI O N $G E N E T IC S - A N D - P O P U L A T I O N $S T RU C T U R AL - B I O IN F O R M A T I C S $P H Y L O GE N E T I CS Ke yword expression genetic structure phylogenetic Enriched Ke ywords gene traits protein trees genes trait pdb newick rna markers residues phylogenetics cell phenotypes pymol phylogenies isoform associations residue e volution many pseudo documents (e.g, 1000 or 2000), putting ef ficiency aside, the performance is not guaranteed to increase. In f act, on both datasets, the F1 scores start to fluctuate when the number of pseudo documents becomes lar ge. In our task, generating 500 to 1000 pseudo documents for each class will strike a good balance. V . R E L A T E D W O R K GitHub Repository Mining. As a popular code collabo- ration community , GitHub presents many opportunities for researchers to learn how people write code and design tools to support the process. As a result, GitHub data has receiv ed attention from both software engineering and social comput- ing researchers. Analytic studies [5], [15], [21], [29], [39], [40] have in vestigated how user acti vities (e.g., collaboration, following and watching) affect development practice. Algo- rithmic studies [8], [28], [32], [44] exploit README files and repository metadata to perform data mining tasks such as similarity search [44] and clustering [32]. In this paper, we focus on the task of automatically classifying repositories whereas previous works [15], [29] have relied on human effort to annotate each repository with its topic. HIN Embeddings. Many node embeddings techniques have been proposed for HIN, including [6], [9], [31], [42]. From the application point of vie w , typical applications of learned em- beddings include node classification [6], [9], [31], [42], node clustering [6] and link prediction [9], [42]. Se veral studies apply HIN node embeddings into downstream classification tasks, such as malware detection [13] and medical diagnosis [12]. Different from the fully-supervised settings in [12], [13], our repository classification task relies on a very small set of guidance. Moreover , most information used in [12], [13] is structured. In contrast, we combine structured information such as user -repository ownership relation with unstructured text for classification. Dataless T ext Classification. Although deep neural architec- tures [14], [16], [43] demonstrate their advantages in fully- supervised text classification, their requirement of massiv e training data prohibits them from being adopted in some prac- tical scenarios. Under weakly-supervised or dataless settings, there have been solutions follo wing tw o directions: latent variable models e xtending topic models (e.g., PLSA and LD A) by incorporating user-pro vided seed information [4], [17], [18], [20] and embedding-based models deriving vectorized representations for words and documents [3], [22], [37]. There are also some work on semi-supervised text classification [25], [30], but they require a set of labeled documents instead of keyw ords. Hierarchical T ext Classification. Under fully-supervised set- tings, [7] and [19] first propose to train SVMs to distinguish the children classes of the same parent node. [2] further defines hierarchical loss function and applies cost-sensitive learning to generalize SVM learning for hierarchical classification. [26] proposes a graph-CNN based model to con vert text to graph-of-words, on which the graph con volution operations are applied for feature extraction. Under weakly-supervised or dataless settings, pre vious approaches include HierDataless [33], W eSHClass [23] and PCNB/PCEM [41], which have been introduced in Section IV -A. All abov e mentioned studies focus on text data without additional information. In H I G I T - C L A S S , we are able to go beyond plain text classification and utilize multi-modal signals. V I . C O N C L U S I O N S A N D F U T U R E W O R K In this paper, we hav e studied the problem of ke yword- driven hierar chical classification of GitHub repositories: the end user only needs to provide a label hierarchy and one keyw ord for each leaf category . Given such scarce supervision, we design H I G I T C L A S S with three modules: heterogeneous information network embedding; ke yword enrichment; pseudo document generation. Specifically , HIN embeddings take ad- vantage of the multi-modal nature of GitHub repositories; keyw ord enrichment alle viates the supervision scarcity of each category; pseudo document generation transforms the keyw ords into documents, enabling the use of po werful neural classifiers. Through experiments on two repository collections, we show that H I G I T C L A S S consistently outperforms all base- lines by a large margin, particularly on the lower lev els of the hierarchy . Further analysis sho ws that the HIN module contributes the most to the boost in performance and keyw ord enrichment demonstrates its power deeper do wn the hierarchy where the differences between classes become more subtle. For future work, we would like to explore the possibil- ity of integrating dif ferent forms of supervision (e.g., the combination of keyw ords and labeled repositories). The HIN embedding module may also be coupled more tightly with the document classification process by allo wing the document classifier’ s prediction results to propagate along the network. A C K N O W L E D G M E N T W e thank Xiaotao Gu for useful discussions. The re- search was sponsored in part by U.S. Army Research Lab . under Cooperativ e Agreement No. W911NF-09-2- 0053 (NSCT A), D ARP A under Agreement No. W911NF-17- C0099, National Science Foundation IIS 16-18481, IIS 17- 04532, and IIS-17-41317, DTRA HDTRA11810026, and grant 1U54GM114838 aw arded by NIGMS through funds provided by the trans-NIH Big Data to Knowledge (BD2K) initiativ e (www .bd2k.nih.gov). The views and conclusions contained in this paper are those of the authors and should not be interpreted as representing any funding agencies. W e thank anonymous revie wers for valuable and insightful feedback. R E F E R E N C E S [1] A. Banerjee, I. S. Dhillon, J. Ghosh, and S. Sra. Clustering on the unit hypersphere using von mises-fisher distributions. Journal of Machine Learning Resear ch , 6(Sep):1345–1382, 2005. [2] L. Cai and T . Hofmann. Hierarchical document categorization with support vector machines. In CIKM’04 , pages 78–87, 2004. [3] M.-W . Chang, L.-A. Ratinov , D. Roth, and V . Srikumar . Importance of semantic representation: Dataless classification. In AAAI’08 , pages 830–835, 2008. [4] X. Chen, Y . Xia, P . Jin, and J. Carroll. Dataless text classification with descriptiv e lda. In AAAI’15 , 2015. [5] L. Dabbish, C. Stuart, J. Tsay , and J. Herbsleb. Social coding in github: transparency and collaboration in an open software repository . In CSCW’12 , pages 1277–1286, 2012. [6] Y . Dong, N. V . Chawla, and A. Swami. metapath2v ec: Scalable representation learning for heterogeneous networks. In KDD’17 , pages 135–144, 2017. [7] S. Dumais and H. Chen. Hierarchical classification of web content. In SIGIR’00 , pages 256–263, 2000. [8] Y . Fan, Y . Zhang, S. Hou, L. Chen, Y . Y e, C. Shi, L. Zhao, and S. Xu. ide v: Enhancing social coding security by cross-platform user identification between github and stack overflow . In IJCAI’19 , pages 2272–2278, 2019. [9] T .-y . Fu, W .-C. Lee, and Z. Lei. Hin2vec: Explore meta-paths in heterogeneous information networks for representation learning. In CIKM’17 , pages 1797–1806, 2017. [10] S. Gopal and Y . Y ang. V on mises-fisher clustering models. In ICML’14 , pages 154–162, 2014. [11] A. Grover and J. Leskov ec. node2vec: Scalable feature learning for networks. In KDD’16 , pages 855–864, 2016. [12] A. Hosseini, T . Chen, W . W u, Y . Sun, and M. Sarrafzadeh. Heteromed: Heterogeneous information network for medical diagnosis. In CIKM’18 , pages 763–772, 2018. [13] S. Hou, Y . Y e, Y . Song, and M. Abdulhayoglu. Hindroid: An intelligent android malware detection system based on structured heterogeneous information network. In KDD’17 , pages 1507–1515, 2017. [14] J. Howard and S. Ruder . Universal language model fine-tuning for text classification. In ACL ’18 , pages 328–339, 2018. [15] E. Kalliamvakou, G. Gousios, K. Blincoe, L. Singer, D. M. German, and D. Damian. The promises and perils of mining github. In MSR’14 , pages 92–101, 2014. [16] Y . Kim. Conv olutional neural networks for sentence classification. In EMNLP’14 , pages 1746–1751, 2014. [17] C. Li, J. Xing, A. Sun, and Z. Ma. Effecti ve document labeling with v ery few seed words: A topic model approach. In CIKM’16 , pages 85–94, 2016. [18] X. Li, C. Li, J. Chi, J. Ouyang, and C. Li. Dataless text classification: A topic modeling approach with document manifold. In CIKM’18 , pages 973–982, 2018. [19] T .-Y . Liu, Y . Y ang, H. W an, H.-J. Zeng, Z. Chen, and W .-Y . Ma. Support vector machines classification with a very large-scale taxonomy . SIGKDD Explorations , 7(1):36–43, 2005. [20] Y . Lu and C. Zhai. Opinion integration through semi-supervised topic modeling. In WWW’08 , pages 121–130, 2008. [21] W . Ma, L. Chen, X. Zhang, Y . Zhou, and B. Xu. How do developers fix cross-project correlated b ugs? a case study on the github scientific python ecosystem. In ICSE’17 , pages 381–392, 2017. [22] Y . Meng, J. Shen, C. Zhang, and J. Han. W eakly-supervised neural text classification. In CIKM’18 , pages 983–992, 2018. [23] Y . Meng, J. Shen, C. Zhang, and J. Han. W eakly-supervised hierarchical text classification. In AAAI’19 , pages 6826–6833, 2019. [24] T . Mikolov , I. Sutskev er, K. Chen, G. S. Corrado, and J. Dean. Dis- tributed representations of words and phrases and their compositionality . In NIPS’13 , pages 3111–3119, 2013. [25] T . Miyato, A. M. Dai, and I. J. Goodfello w . Adversarial training methods for semi-supervised text classification. In ICLR’16 , 2016. [26] H. Peng, J. Li, Y . He, Y . Liu, M. Bao, L. W ang, Y . Song, and Q. Y ang. Large-scale hierarchical text classification with recursively regularized deep graph-cnn. In WWW’18 , pages 1063–1072, 2018. [27] B. Perozzi, R. Al-Rfou, and S. Skiena. Deepwalk: Online learning of social representations. In KDD’14 , pages 701–710, 2014. [28] G. A. A. Prana, C. T reude, F . Thung, T . Atapattu, and D. Lo. Categoriz- ing the content of github readme files. Empirical Softwar e Engineering , pages 1–32, 2018. [29] P . H. Russell, R. L. Johnson, S. Ananthan, B. Harnke, and N. E. Carlson. A large-scale analysis of bioinformatics code on github . PLOS One , 13(10):e0205898, 2018. [30] D. S. Sachan, M. Zaheer , and R. Salakhutdinov . Revisiting lstm networks for semi-supervised text classification via mixed objectiv e function. In AAAI’19 , pages 6940–6948, 2019. [31] J. Shang, M. Qu, J. Liu, L. M. Kaplan, J. Han, and J. Peng. Meta- path guided embedding for similarity search in large-scale heterogeneous information networks. arXiv preprint , 2016. [32] A. Sharma, F . Thung, P . S. Kochhar , A. Sulistya, and D. Lo. Cataloging github repositories. In EASE’17 , pages 314–319, 2017. [33] Y . Song and D. Roth. On dataless hierarchical text classification. In AAAI’14 , pages 1579–1585, 2014. [34] Y . Sun and J. Han. Mining heterogeneous information networks: principles and methodologies. Synthesis Lectur es on Data Mining and Knowledge Discovery , 3(2):1–159, 2012. [35] Y . Sun, J. Han, X. Y an, P . S. Y u, and T . Wu. Pathsim: Meta path-based top-k similarity search in heterogeneous information networks. PVLDB , 4(11):992–1003, 2011. [36] Y . Sun, Y . Y u, and J. Han. Ranking-based clustering of heterogeneous information networks with star network schema. In KDD’09 , pages 797–806. A CM, 2009. [37] J. T ang, M. Qu, and Q. Mei. Pte: Predictive text embedding through large-scale heterogeneous text networks. In KDD’15 , pages 1165–1174, 2015. [38] J. T ang, M. Qu, M. W ang, M. Zhang, J. Y an, and Q. Mei. Line: Large- scale information network embedding. In WWW’15 , pages 1067–1077, 2015. [39] J. Tsay , L. Dabbish, and J. Herbsleb. Influence of social and technical factors for e valuating contribution in github. In ICSE’14 , pages 356–366. A CM, 2014. [40] J. T . Tsay , L. Dabbish, and J. Herbsleb. Social media and success in open source projects. In CSCW’12 , pages 223–226, 2012. [41] H. Xiao, X. Liu, and Y . Song. Ef ficient path prediction for semi- supervised and weakly supervised hierarchical text classification. In WWW’19 , pages 3370–3376, 2019. [42] C. Y ang, Y . Feng, P . Li, Y . Shi, and J. Han. Meta-graph based hin spectral embedding: Methods, analyses, and insights. In ICDM’18 , pages 657– 666, 2018. [43] Z. Y ang, D. Y ang, C. Dyer, X. He, A. Smola, and E. Hovy . Hierarchical attention networks for document classification. In NAA CL ’16 , pages 1480–1489, 2016. [44] Y . Zhang, D. Lo, P . S. Kochhar , X. Xia, Q. Li, and J. Sun. Detecting similar repositories on github . In SANER’17 , pages 13–23, 2017.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment