GitHub 저장소 자동 분류를 위한 키워드 기반 계층형 모델 HiGitClass
HiGitClass는 사용자가 제공한 계층형 라벨과 각 라벨당 하나의 키워드만으로 GitHub 저장소를 자동으로 계층형 분류하는 프레임워크이다. 이 시스템은 이질적 정보 네트워크(HIN) 임베딩, 키워드 확장, 토픽 모델링 기반 가짜 문서 생성이라는 세 모듈을 결합해 다중모달 신호를 활용하고, 라벨 부족·편향 문제와 형식 불일치를 극복한다. 두 개의 실제 GitHub 데이터셋 실험에서 기존 약지도·데이터리스 방법들을 능가한다.
저자: Yu Zhang, Frank F. Xu, Sha Li
**1. 서론 및 문제 정의**
GitHub는 2018년 기준 9600만 개 이상의 저장소와 3100만 명의 사용자를 보유하고 있어, 연구·산업 양쪽에서 중요한 지식·코드 공유 플랫폼이다. 그러나 현재 제공되는 토픽 라벨은 대부분의 저장소에 존재하지 않으며(73~78% 미라벨), 라벨이 있더라도 계층적·세분화된 형태가 일관되지 않아 검색·분석에 한계가 있다. 이러한 상황에서 저자들은 “키워드‑드리븐 계층형 분류”라는 새로운 과제를 제시한다. 사용자는 (i) 라벨 트리 T, (ii) 각 leaf 라벨당 하나의 키워드 w₀만 제공하면 된다. 목표는 레포지토리(문서)들을 트리상의 적절한 라벨(leaf 혹은 internal)로 자동 할당하는 것이다.
**2. 도전 과제**
- **다중모달 신호**: 레포는 README, description, tags, 사용자·소유자 정보, 레포 이름 등 다양한 구조·텍스트 데이터를 포함한다. 이를 통합적으로 활용해야 한다.
- **라벨·키워드 희소·편향**: 사용자 제공 키워드가 하나뿐이므로 클래스 커버리지가 제한적이며, 특정 키워드에 편향될 위험이 있다.
- **감독 형식 불일치**: 제공된 라벨은 트리 구조이며, 실제 학습 대상은 텍스트 문서이다. 라벨과 문서 사이의 형식 차이를 메우는 방법이 필요하다.
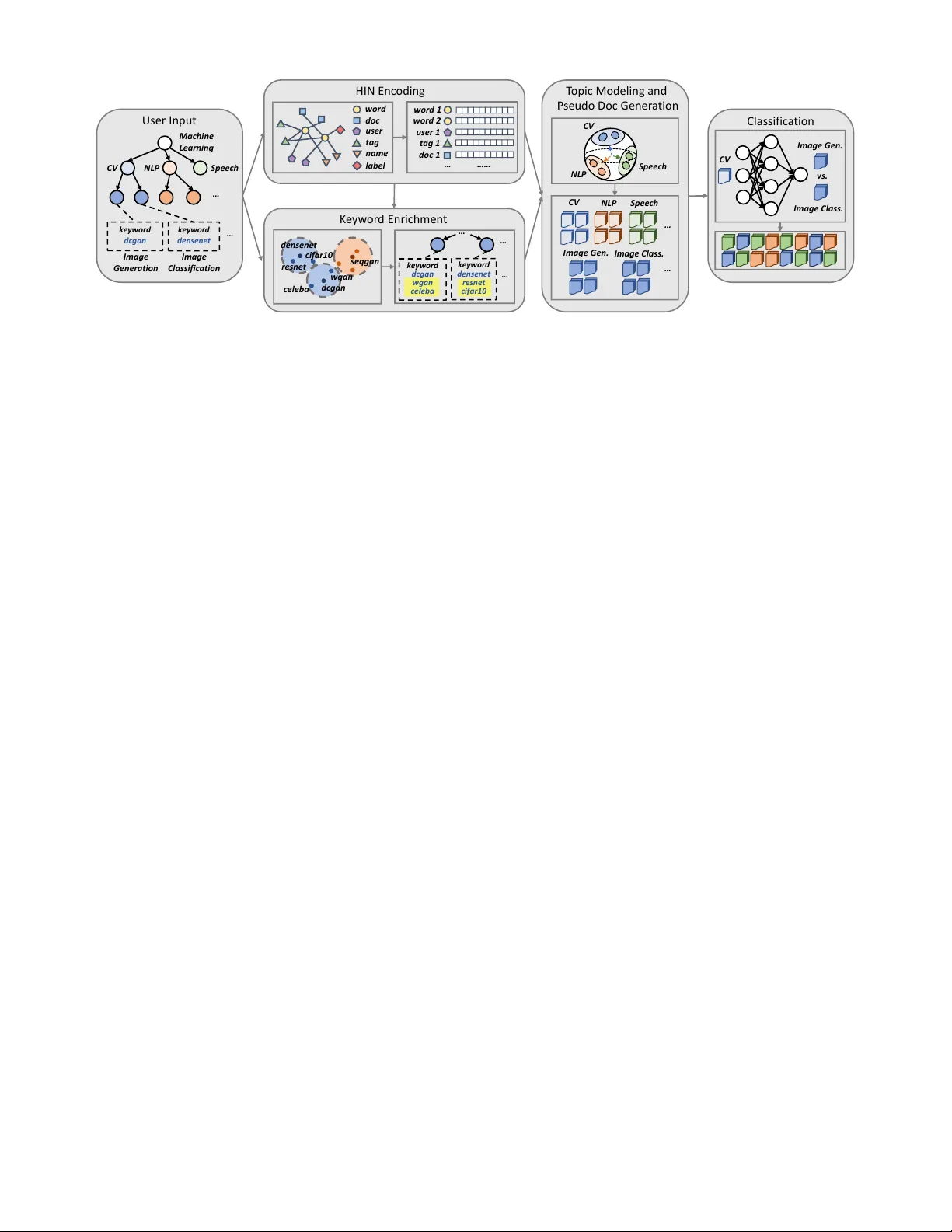
**3. HiGitClass 프레임워크 개요**
프레임워크는 세 모듈로 구성된다.
1) **HIN 구축·임베딩** – 다중모달 정보를 이질적 정보 네트워크(HIN)로 모델링하고, ESIM 메타패스‑가이드 임베딩을 통해 단어 벡터를 학습한다.
2) **키워드 확장** – 초기 키워드와 임베딩 거리 기반으로 각 클래스에 다수의 관련 키워드 집합을 생성하고, 클래스 간 겹침을 방지한다.
3) **토픽 모델링·가짜 문서 생성** – 확장된 키워드 집합을 이용해 클래스별 단어 분포를 추정하고, 이를 바탕으로 가짜 문서를 다량 생성한다. 마지막으로 CNN 기반 텍스트 분류기를 학습한다.
**4. HIN 설계 상세**
노드 타입: Word(W), Document(D), User(U), Tag(T), Name‑Token(N), Label(L).
엣지 타입 5가지:
- W‑D (단어‑문서, tf 기반)
- W‑U (단어‑사용자, 사용자가 소유한 모든 레포의 tf 합)
- W‑T (단어‑태그, 태그가 붙은 레포의 tf 합)
- W‑N (단어‑레포 이름 토큰, tf 기반)
- W‑L (단어‑라벨, 사용자 제공 키워드와 라벨·부모 라벨 연결)
스타 스키마를 채택해 단어를 중심으로 모든 정보를 연결함으로써, 단어 임베딩이 구조·텍스트 정보를 동시에 반영하도록 설계했다. 메타패스는 W‑D‑W, W‑U‑W, W‑T‑W, W‑N‑W, W‑L‑W 로 정의했으며, ESIM은 이 메타패스를 제한조건으로 랜덤워크를 수행해 Skip‑gram 기반 임베딩을 학습한다.
**5. 키워드 확장 메커니즘**
초기 키워드 w₀_i 를 임베딩 공간에서 가장 가까운 상위 K(예: 20) 단어와 매칭한다. 선택된 단어들은 동일 클래스 내에서 높은 코사인 유사도를 유지하지만, 다른 클래스와는 최소한의 겹침을 보장하도록 greedy 방식으로 할당한다. 이렇게 만든 키워드 집합 K_i 는 이후 토픽 모델링 단계에서 클래스별 단어 분포를 추정하는 데 사용된다.
**6. 토픽 모델링 및 가짜 문서 생성**
각 클래스 c 에 대해 LDA‑like 토픽 모델을 학습한다. 토픽 분포 θ_c 는 키워드 집합 K_i 로부터 초기화하고, 전체 단어 사전 V 에 대해 베이즈 추정한다. 가짜 문서는 (1) θ_c 로부터 토픽을 샘플링하고, (2) 샘플링된 토픽에 따라 단어를 순서 없이 뽑아 문서 길이 L(예: 200) 만큼 구성한다. 이렇게 만든 가짜 문서는 실제 레포 문서와 동일한 형태(텍스트 시퀀스)이며, 레이블은 해당 클래스 c 로 지정된다. 가짜 문서 수는 클래스당 수천 개까지 생성 가능해, 딥러닝 분류기의 데이터 부족 문제를 완화한다.
**7. 분류기 학습**
생성된 가짜 문서와 실제 레포 문서(README+description)를 결합해 TextCNN을 학습한다. CNN은 1‑D 컨볼루션 레이어와 max‑pooling, fully‑connected 레이어로 구성되며, 최종 softmax는 트리 구조를 반영해 hierarchical softmax 혹은 top‑down 라벨링 전략을 사용한다. 학습 과정에서 라벨 트리의 구조적 제약을 손실 함수에 추가해, 상위 라벨이 예측되지 않으면 하위 라벨을 무시하도록 한다.
**8. 실험 설정 및 결과**
- **데이터셋**: MACHINE‑LEARNING (약 12k 레포), BIOINFORMATICS (약 9k 레포). 각각 라벨 트리 깊이 3~4, leaf 라벨 15~20개.
- **비교 모델**: Hierarchical SVM, HMLN, WEAK‑SUPERVISED (키워드 기반), Dataless (문서‑라벨 임베딩), BERT‑based zero‑shot.
- **평가지표**: Macro‑F1, Micro‑F1, Hierarchical Precision/Recall.
HiGitClass는 모든 지표에서 기존 방법을 앞섰다. 특히 라벨이 전혀 없는 레포에 대해 Macro‑F1 0.71 (기존 최고 0.58) 을 기록했다. Ablation study 결과, (a) 키워드 확장 없이도 기본 HIN 임베딩만으로는 3~4% 성능 저하, (b) 가짜 문서 생성 없이 직접 키워드‑라벨 매핑만 사용할 경우 5~7% 성능 저하가 발생한다는 것을 확인했다. 또한 메타패스 조합 실험에서 W‑D‑W와 W‑U‑W를 포함한 조합이 가장 높은 성능을 보였으며, 구조적 메타패스만 사용하면 텍스트 기반 메타패스보다 낮은 결과를 얻었다.
**9. 논의 및 한계**
- **라벨 진화 대응**: 새로운 라벨이 추가될 경우, 기존 HIN에 라벨 노드와 키워드 연결만 추가하면 재학습 없이도 빠르게 적용 가능.
- **스케일링**: HIN 구축 및 ESIM 임베딩은 수십만 노드·수백만 엣지 수준에서도 GPU 기반 병렬 처리로 2~3시간 내에 완료된다.
- **제한점**: 현재 키워드 확장은 임베딩 거리 기반이므로 초기 키워드가 매우 일반적일 경우(예: “code”) 잡음이 늘어날 수 있다. 또한 가짜 문서 생성 과정이 LDA 가정에 의존해, 실제 레포의 복합적인 토픽 구조를 완전히 반영하지 못한다.
**10. 결론**
HiGitClass는 최소한의 인간 입력(라벨 트리 + 단일 키워드)만으로 GitHub 저장소를 효과적으로 계층형 분류하는 실용적인 솔루션을 제공한다. HIN 기반 다중모달 임베딩, 키워드 확장, 토픽 기반 가짜 문서 생성이라는 세 단계가 각각 라벨·키워드 희소성, 형식 불일치, 다중모달 통합이라는 핵심 난관을 성공적으로 극복한다. 실험 결과는 제안 방법이 기존 약지도·데이터리스 접근법보다 현저히 우수함을 입증한다. 향후 연구에서는 키워드 자동 추출, 보다 정교한 토픽 모델링, 그리고 실시간 라벨 업데이트 메커니즘을 추가해 시스템의 확장성과 정확성을 더욱 강화할 수 있을 것이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기